
Controllo della scansione e dell'indicizzazione: una guida SEO a Robots.txt e tag
Pubblicato: 2019-02-19L'ottimizzazione per il crawl budget e il blocco dei bot dall'indicizzazione delle pagine sono concetti familiari a molti SEO. Ma il diavolo è nei dettagli. Soprattutto perché le migliori pratiche sono cambiate in modo significativo negli ultimi anni.
Una piccola modifica a un file robots.txt o ai tag robots può avere un impatto drammatico sul tuo sito web. Per garantire che l'impatto sia sempre positivo per il tuo sito, oggi approfondiremo:
Ottimizzazione del budget di scansione
Che cos'è un file Robots.txt
Cosa sono i tag Meta Robot
Cosa sono gli X-Robots-Tag
Direttive sui robot e SEO
Elenco di controllo dei robot per le migliori pratiche
Ottimizzazione del budget di scansione
Uno spider dei motori di ricerca ha una "indennità" per quante pagine può e vuole eseguire la scansione del tuo sito. Questo è noto come "crawl budget".
Trova il budget di scansione del tuo sito nel rapporto "Statistiche di scansione" di Google Search Console (GSC). Nota che il GSC è un aggregato di 12 bot che non sono tutti dedicati alla SEO. Raccoglie anche i bot AdWords o AdSense che sono bot SEA. Pertanto, questo strumento ti dà un'idea del tuo budget di scansione globale ma non della sua ripartizione esatta.
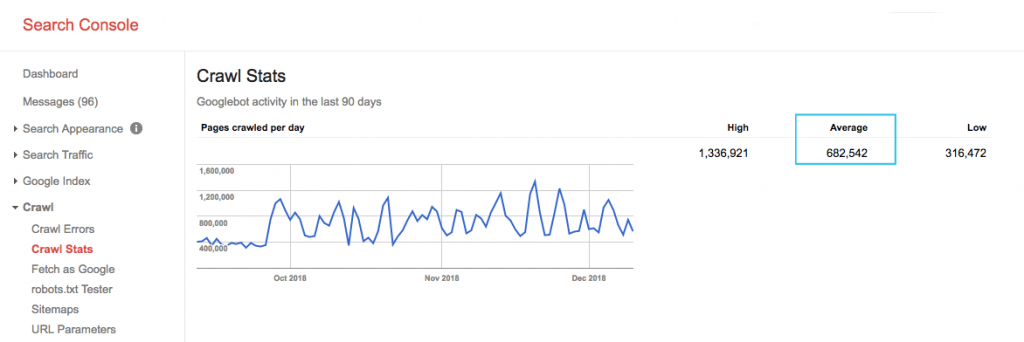
Per rendere il numero più perseguibile, dividi la media delle pagine scansionate al giorno per il totale delle pagine scansionabili sul tuo sito: puoi chiedere il numero al tuo sviluppatore o eseguire un crawler del sito illimitato. Questo ti darà un rapporto di scansione previsto per iniziare l'ottimizzazione.
Vuoi approfondire? Ottieni un'analisi più dettagliata dell'attività di Googlebot, ad esempio quali pagine vengono visitate, nonché statistiche per altri crawler, analizzando i file di registro del server del tuo sito.
Esistono molti modi per ottimizzare il crawl budget, ma un punto di partenza facile è controllare nel rapporto "Copertura" di GSC per comprendere il comportamento di scansione e indicizzazione corrente di Google.
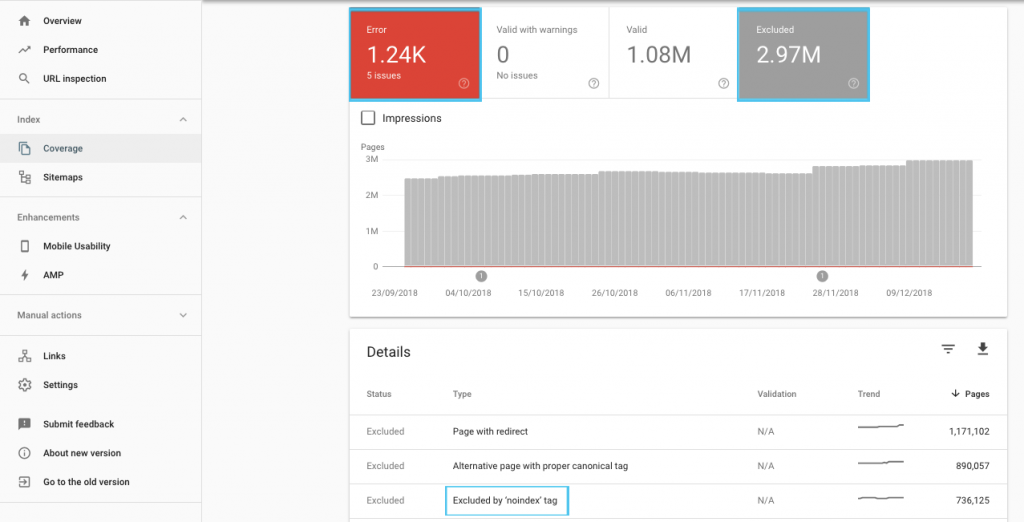
Se vedi errori come "URL inviato contrassegnato come 'noindex'" o "URL inviato bloccato da robots.txt", collabora con il tuo sviluppatore per risolverli. Per eventuali esclusioni di robot, esaminali per capire se sono strategici dal punto di vista SEO.
In generale, i SEO dovrebbero mirare a ridurre al minimo le restrizioni di scansione sui robot. Migliorare l'architettura del tuo sito web per rendere gli URL utili e accessibili ai motori di ricerca è la strategia migliore.
Gli stessi Google osservano che "è probabile che una solida architettura dell'informazione sia un uso molto più produttivo delle risorse rispetto a concentrarsi sulla definizione delle priorità di scansione".
Detto questo, è utile capire cosa si può fare con i file robots.txt e i tag robots per guidare la scansione, l'indicizzazione e il passaggio di link equity. E, soprattutto, quando e come sfruttarlo al meglio per la SEO moderna.
[Case Study] Gestione della scansione dei bot di Google
 Leggi il caso di studio
Leggi il caso di studioChe cos'è un file Robots.txt
Prima che un motore di ricerca raggiunga qualsiasi pagina, controllerà il file robots.txt. Questo file dice ai bot quali percorsi URL hanno il permesso di visitare. Ma queste voci sono solo direttive, non mandati.
Robots.txt non può impedire in modo affidabile la scansione come un firewall o una protezione con password. È l'equivalente digitale di un cartello "per favore, non entrare" su una porta sbloccata.
I crawler educati, come i principali motori di ricerca, generalmente obbediscono alle istruzioni. I crawler ostili, come scraper di posta elettronica, spambot, malware e spider che scansionano le vulnerabilità del sito, spesso non prestano attenzione.
Inoltre, è un file disponibile pubblicamente . Chiunque può vedere le tue direttive.
Non utilizzare il file robots.txt per:
- Per nascondere informazioni sensibili. Usa la protezione con password.
- Per bloccare l'accesso al tuo sito di staging e/o sviluppo. Usa l'autenticazione lato server.
- Per bloccare esplicitamente i crawler ostili. Usa il blocco IP o il blocco user-agent (ovvero precludi l'accesso a un crawler specifico con una regola nel tuo file .htaccess o uno strumento come CloudFlare).
Ogni sito web dovrebbe avere un file robots.txt valido con almeno un raggruppamento di direttive. Senza uno, a tutti i bot viene concesso l'accesso completo per impostazione predefinita, quindi ogni pagina viene trattata come scansionabile. Anche se questo è ciò che intendi, è meglio chiarirlo a tutte le parti interessate con un file robots.txt. Inoltre, senza uno, i registri del tuo server saranno pieni di richieste non riuscite per robots.txt.
Struttura di un file robots.txt
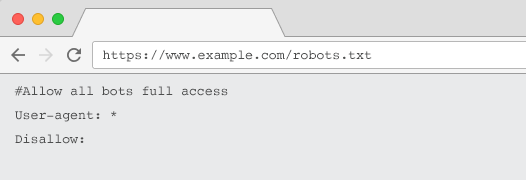
Per essere riconosciuto dai crawler, il tuo robots.txt deve:
- Sii un file di testo chiamato "robots.txt". Il nome del file fa distinzione tra maiuscole e minuscole. "Robots.TXT" o altre varianti non funzioneranno.
- Sii situato nella directory di primo livello del tuo dominio canonico e, se pertinente, dei sottodomini. Ad esempio, per controllare la scansione di tutti gli URL sotto https://www.example.com, il file robots.txt deve trovarsi all'indirizzo https://www.example.com/robots.txt e per subdomain.example.com all'indirizzo sottodominio.esempio.com/robots.txt.
- Restituisce uno stato HTTP di 200 OK.
- Usa sintassi robots.txt valida: verifica utilizzando lo strumento di test robots.txt di Google Search Console.
Un file robots.txt è composto da raggruppamenti di direttive. Le iscrizioni consistono principalmente in:
- 1. User-agent: indirizza i vari crawler. Puoi avere un gruppo per tutti i robot o utilizzare i gruppi per nominare motori di ricerca specifici.
- 2. Non consentire: specifica i file o le directory da escludere dalla scansione da parte dell'agente utente di cui sopra. Puoi avere una o più di queste righe per blocco.
Per un elenco completo dei nomi degli user agent e altri esempi di direttive, consulta la guida robots.txt su Yoast.
Oltre alle direttive "User-agent" e "Disallow", ci sono alcune direttive non standard:
- Consenti: specifica le eccezioni a una direttiva di non autorizzazione per una directory padre.
- Crawl-delay: accelera i crawler pesanti dicendo ai robot quanti secondi devono attendere prima di visitare una pagina. Se stai ricevendo poche sessioni organiche, il crawl-delay può far risparmiare larghezza di banda del server. Ma investirei lo sforzo solo se i crawler stanno attivamente causando problemi di carico del server. Google non riconosce questo comando, offre l'opzione per limitare la velocità di scansione in Google Search Console.
- Clean-param: evita di eseguire nuovamente la scansione del contenuto duplicato generato da parametri dinamici.
- No-index: progettato per controllare l'indicizzazione senza utilizzare alcun crawl budget. Non è più ufficialmente supportato da Google. Sebbene ci siano prove che potrebbe ancora avere un impatto, non è affidabile e non è raccomandato da esperti come John Mueller.
@maxxeight @google @DeepCrawl Eviterei davvero di usare il noindex lì.
— ???? John ???? (@JohnMu) 1 settembre 2015
- Mappa del sito: il modo ottimale per inviare la tua mappa del sito XML è tramite Google Search Console e gli Strumenti per i Webmaster di altri motori di ricerca. Tuttavia, l'aggiunta di una direttiva sulla mappa del sito alla base del file robots.txt aiuta altri crawler che potrebbero non offrire un'opzione di invio.
Limitazioni di robots.txt per SEO
Sappiamo già che robots.txt non può impedire la scansione di tutti i bot. Allo stesso modo, disabilitare i crawler da una pagina non impedisce che venga inclusa nelle pagine dei risultati dei motori di ricerca (SERP).
Se una pagina bloccata ha altri forti segnali di posizionamento, Google potrebbe ritenere rilevante mostrarla nei risultati di ricerca. Nonostante non abbia eseguito la scansione della pagina.
Poiché il contenuto di tale URL è sconosciuto a Google, il risultato della ricerca è simile al seguente:

Per bloccare definitivamente la visualizzazione di una pagina nelle SERP, è necessario utilizzare un meta tag robots "noindex" o un'intestazione HTTP X-Robots-Tag.
In questo caso, non disabilitare la pagina in robots.txt , perché la pagina deve essere sottoposta a scansione affinché il tag "noindex" venga visualizzato e rispettato. Se l'URL è bloccato, tutti i tag robots sono inefficaci.
Inoltre, se una pagina ha accumulato molti link in entrata, ma a Google viene impedito di eseguire la scansione di quelle pagine da robots.txt, mentre i link sono noti a Google, l' equità del link viene persa.
Cosa sono i tag Meta Robot
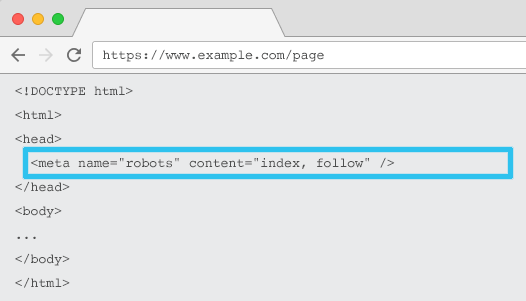
Inserito nell'HTML di ogni URL, il meta name="robots" dice ai crawler se e come "indicizzare" il contenuto e se "seguire" (cioè eseguire la scansione) tutti i link sulla pagina, trasmettendo l'equità del link.
Utilizzando il meta name=“robot” generale, la direttiva si applica a tutti i crawler. È inoltre possibile specificare un programma utente specifico. Ad esempio, meta name="googlebot". Ma è raro dover utilizzare più tag meta robot per impostare istruzioni per ragni specifici.
Ci sono due considerazioni importanti quando si utilizzano i meta tag robots:
- Simile a robots.txt, i meta tag sono direttive, non mandati, quindi potrebbero essere ignorati da alcuni bot.
- La direttiva robots nofollow si applica solo ai link in quella pagina. È possibile che un crawler segua il collegamento da un'altra pagina o sito Web senza un nofollow. Quindi il bot potrebbe ancora arrivare e indicizzare la tua pagina indesiderata.
Ecco l'elenco di tutte le direttive dei tag meta robots:
- indice: indica ai motori di ricerca di mostrare questa pagina nei risultati di ricerca. Questo è lo stato predefinito se non viene specificata alcuna direttiva.
- noindex: indica ai motori di ricerca di non mostrare questa pagina nei risultati di ricerca.
- segui: indica ai motori di ricerca di seguire tutti i collegamenti in questa pagina e di passare l'equità, anche se la pagina non è indicizzata. Questo è lo stato predefinito se non viene specificata alcuna direttiva.
- nofollow: indica ai motori di ricerca di non seguire alcun collegamento in questa pagina o di non passare l'equità.
- tutto: equivalente a "indicizza, segui".
- nessuno: equivalente a "noindex, nofollow".
- noimageindex: dice ai motori di ricerca di non indicizzare nessuna immagine in questa pagina.
- noarchive: indica ai motori di ricerca di non mostrare un collegamento memorizzato nella cache a questa pagina nei risultati di ricerca.
- nocache: come noarchive, ma utilizzato solo da Internet Explorer e Firefox.
- nosnippet: indica ai motori di ricerca di non mostrare una meta descrizione o un'anteprima video per questa pagina nei risultati di ricerca.
- notranslate: dice al motore di ricerca di non offrire la traduzione di questa pagina nei risultati di ricerca.
- unavailable_after: indica ai motori di ricerca di non indicizzare più questa pagina dopo una data specificata.
- noodp: ora deprecato, una volta impediva ai motori di ricerca di utilizzare la descrizione della pagina da DMOZ nei risultati di ricerca.
- noydir: ora deprecato, una volta impediva a Yahoo di utilizzare la descrizione della pagina dalla directory di Yahoo nei risultati di ricerca.
- noyaca: impedisce a Yandex di utilizzare la descrizione della pagina dalla directory Yandex nei risultati di ricerca.
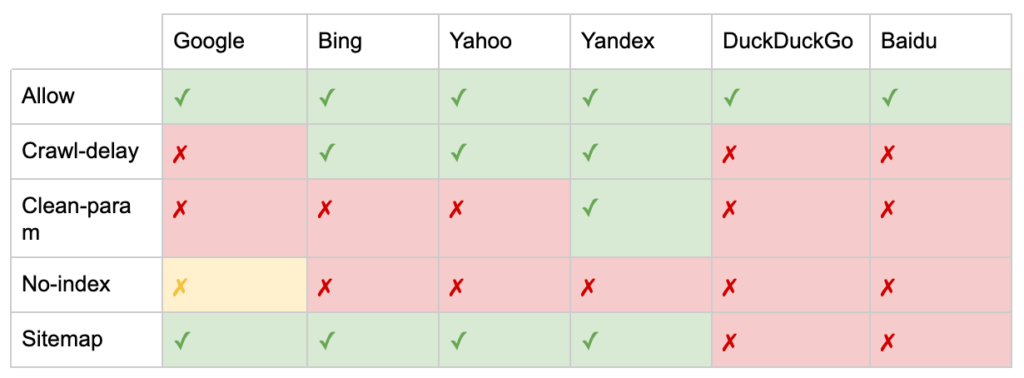
Come documentato da Yoast, non tutti i motori di ricerca supportano tutti i meta tag dei robot, o sono anche chiari su cosa fanno e cosa non supportano.
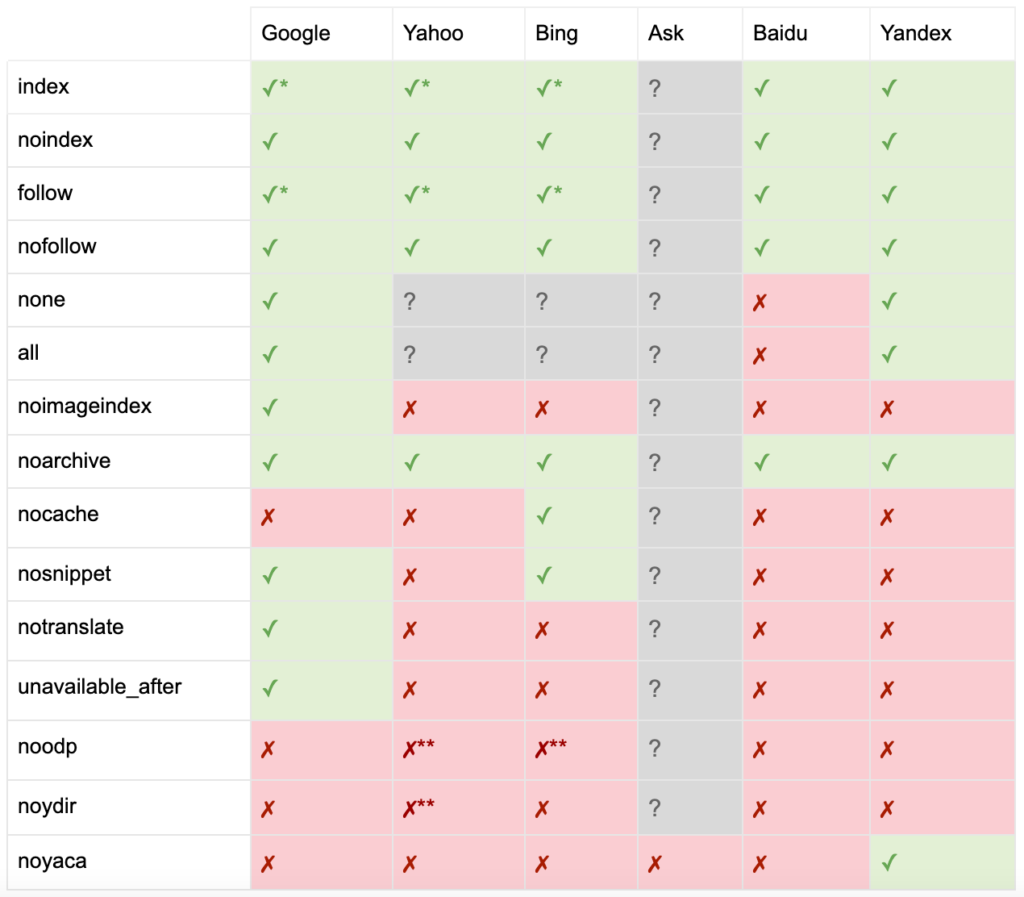
* La maggior parte dei motori di ricerca non ha una documentazione specifica per questo, ma si presume che il supporto per l'esclusione di parametri (es. nofollow) implichi il supporto per l'equivalente positivo (es. follow).
** Sebbene gli attributi noodp e noydir possano essere ancora "supportati", le directory non esistono più ed è probabile che questi valori non facciano nulla.
Di solito, i tag robots vengono impostati su "indicizza, segui". Alcuni SEO vedono l'aggiunta di questo tag nell'HTML come ridondante in quanto è l'impostazione predefinita. L'argomento opposto è che una chiara specificazione delle direttive può aiutare a evitare qualsiasi confusione umana.

Nota: gli URL con un tag "noindex" verranno scansionati meno frequentemente e, se è presente per molto tempo, alla fine porterà Google a non seguire i link della pagina.
È raro trovare un caso d'uso per "nofollow" tutti i collegamenti su una pagina con un tag meta robots. È più comune vedere "nofollow" aggiunto su singoli collegamenti utilizzando un attributo di collegamento rel="nofollow". Ad esempio, potresti prendere in considerazione l'aggiunta di un attributo rel="nofollow" ai commenti generati dagli utenti o ai link a pagamento.
È ancora più raro avere un caso d'uso SEO per le direttive dei tag robot che non affrontano l'indicizzazione di base e seguono il comportamento, come la memorizzazione nella cache, l'indicizzazione delle immagini e la gestione degli snippet, ecc.
La sfida con i tag meta robot è che non possono essere utilizzati per file non HTML come immagini, video o documenti PDF. È qui che puoi rivolgerti a X-Robots-Tags.
Cosa sono gli X-Robots-Tag
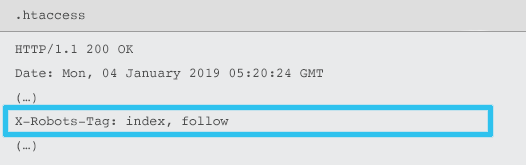
Gli X-Robots-Tag vengono inviati dal server come elemento dell'intestazione della risposta HTTP per un determinato URL utilizzando i file .htaccess e httpd.conf.
Qualsiasi direttiva di meta tag robots può anche essere specificata come X-Robots-Tag. Tuttavia, un X-Robots-Tag offre ulteriore flessibilità e funzionalità.
Utilizzeresti X-Robots-Tag su meta tag robots se desideri:
- Controlla il comportamento dei robot per i file non HTML, piuttosto che per i soli file HTML.
- Controlla l'indicizzazione di un elemento specifico di una pagina, piuttosto che della pagina nel suo insieme.
- Aggiungi regole per indicizzare o meno una pagina. Ad esempio, se un autore ha pubblicato più di 5 articoli, indicizza la pagina del suo profilo.
- Applica le direttive indicizza e segui a livello di sito, anziché a livello di pagina.
- Usa le espressioni regolari.
Evita di usare entrambi i meta robot e il tag x-robots sulla stessa pagina: farlo sarebbe ridondante.
Per visualizzare X-Robots-Tag, puoi utilizzare la funzione "Visualizza come Google" in Google Search Console.
Direttive sui robot e SEO
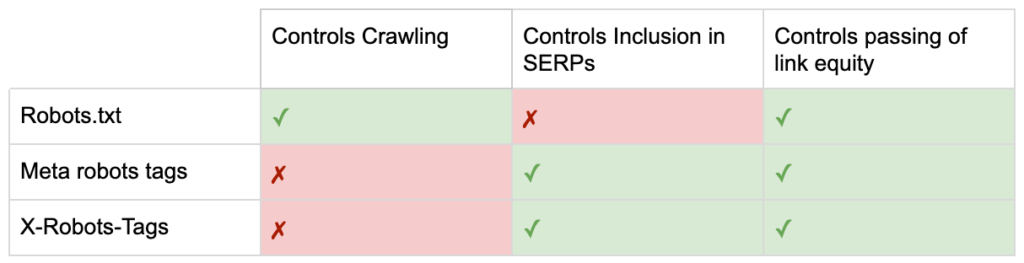
Quindi ora conosci le differenze tra le tre direttive sui robot.
robots.txt è incentrato sul risparmio del budget di scansione, ma non impedisce la visualizzazione di una pagina nei risultati di ricerca. Agisce come il primo gatekeeper del tuo sito Web, indirizzando i robot a non accedere prima che la pagina venga richiesta.
Entrambi i tipi di tag robot si concentrano sul controllo dell'indicizzazione e sul passaggio dell'equità del collegamento. I meta tag Robots sono efficaci solo dopo che la pagina è stata caricata . Mentre le intestazioni X-Robots-Tag offrono un controllo più granulare e sono efficaci dopo che il server ha risposto a una richiesta di pagina.
Con questa comprensione, i SEO possono evolvere il modo in cui utilizziamo le direttive dei robot per risolvere le sfide di scansione e indicizzazione.
Blocco dei bot per risparmiare larghezza di banda del server
Problema: analizzando i tuoi file di registro, vedrai molti user-agent che prendono la larghezza di banda ma restituiscono poco valore.
- SEO crawler, come MJ12bot (di Majestic) o Ahrefsbot (di Ahrefs).
- Strumenti che salvano contenuti digitali offline, come Webcopier o Teleport.
- Motori di ricerca non rilevanti nel tuo mercato, come Baiduspider o Yandex.
Soluzione non ottimale: bloccare questi spider con robots.txt poiché non è garantito che venga rispettato ed è una dichiarazione piuttosto pubblica, che potrebbe fornire alle parti interessate informazioni sulla concorrenza.
Approccio di best practice: la direttiva più sottile del blocco degli user-agent. Questo può essere ottenuto in diversi modi, ma comunemente viene fatto modificando il tuo file .htaccess per reindirizzare eventuali richieste spider indesiderate a una pagina 403 - Proibita.
Pagine interne di ricerca del sito utilizzando il budget di scansione
Problema: in molti siti Web, le pagine dei risultati di ricerca interna del sito vengono generate dinamicamente su URL statici, che quindi consumano il budget di scansione e possono causare contenuti sottili o problemi di contenuto duplicati se indicizzati.
Soluzione non ottimale: non consentire la directory con robots.txt. Sebbene ciò possa prevenire le trappole dei crawler, limita la tua capacità di classificarti per le ricerche chiave dei clienti e per tali pagine di passare l'equità dei link.
Approccio di best practice: mappare le query rilevanti e ad alto volume agli URL esistenti adatti ai motori di ricerca. Ad esempio, se cerco "telefono samsung", invece di creare una nuova pagina per /search/samsung-phone, reindirizzare a /phones/samsung.
Se ciò non è possibile, creare un URL basato su parametri. Puoi quindi specificare facilmente se desideri che il parametro venga scansionato o meno all'interno di Google Search Console.
Se consenti la scansione, analizza se tali pagine sono di qualità sufficientemente elevata per essere classificate. In caso contrario, aggiungi una direttiva "noindex, segui" come soluzione a breve termine mentre definisci una strategia per migliorare la qualità dei risultati per assistere sia la SEO che l'esperienza dell'utente.
Blocco dei parametri con i robot
Problema: i parametri della stringa di query, come quelli generati dalla navigazione o dal monitoraggio in base a facet, sono noti per consumare il budget di scansione, creare URL di contenuto duplicati e dividere i segnali di ranking.
Soluzione non ottimale: non consentire la scansione dei parametri con robots.txt o con un meta tag robots "noindex", poiché entrambi (il primo immediatamente, il secondo per un periodo più lungo) impediranno il flusso dell'equità del collegamento.
Approccio di best practice: assicurarsi che ogni parametro abbia una chiara ragione per esistere e implementare regole di ordinamento, che utilizzano le chiavi una sola volta e impediscono valori vuoti. Aggiungi un attributo di collegamento rel=canonical alle pagine dei parametri adatte per combinare la capacità di posizionamento. Quindi configura tutti i parametri in Google Search Console, dove sono disponibili opzioni più dettagliate per comunicare le preferenze di scansione. Per maggiori dettagli, consulta la guida alla gestione dei parametri di Search Engine Journal.
Blocco delle aree di amministrazione o account
Problema: impedisce ai motori di ricerca di eseguire la scansione e l'indicizzazione di qualsiasi contenuto privato.
Soluzione non ottimale: utilizzare robots.txt per bloccare la directory poiché non è garantito che le pagine private siano lontane dalle SERP.
Approccio di best practice: utilizzare la protezione con password per impedire ai crawler di accedere alle pagine e un fallback della direttiva "noindex" nell'intestazione HTTP.
Blocco delle pagine di destinazione del marketing e delle pagine di ringraziamento
Problema: spesso è necessario escludere URL non destinati alla ricerca organica, come e-mail dedicate o pagine di destinazione delle campagne CPC. Allo stesso modo, non vuoi che le persone che non si sono convertite visitino le tue pagine di ringraziamento tramite SERP.
Soluzione non ottimale: non consentire i file con robots.txt in quanto ciò non impedirà l'inclusione del collegamento nei risultati della ricerca.
Approccio di best practice: utilizzare un meta tag "noindex".
Gestisci i contenuti duplicati in loco
Problema: alcuni siti Web richiedono una copia di contenuti specifici per motivi di esperienza dell'utente, ad esempio una versione stampabile di una pagina, ma desiderano garantire che la pagina canonica, non la pagina duplicata, venga riconosciuta dai motori di ricerca. Su altri siti Web, il contenuto duplicato è dovuto a pratiche di sviluppo inadeguate, come il rendering dello stesso articolo in vendita su URL di più categorie.
Soluzione non ottimale: non consentire gli URL con robots.txt impedirà alla pagina duplicata di trasmettere segnali di ranking. Il noindexing per i robot, alla fine porterà Google a trattare anche i link come "nofollow", impedirà alla pagina duplicata di trasmettere qualsiasi link equity.
Approccio di best practice: se il contenuto duplicato non ha motivo di esistere, rimuovi la fonte e reindirizza 301 all'URL adatto ai motori di ricerca. Se c'è una ragione per esistere, aggiungi un attributo link rel=canonical per consolidare i segnali di ranking.
Contenuto sottile delle pagine relative all'account accessibile
Problema: le pagine relative all'account come login, registrazione, carrello degli acquisti, checkout o moduli di contatto sono spesso di contenuto leggero e offrono poco valore ai motori di ricerca, ma sono necessarie per gli utenti.
Soluzione non ottimale: non consentire i file con robots.txt in quanto ciò non impedirà l'inclusione del collegamento nei risultati della ricerca.
Approccio di best practice: per la maggior parte dei siti Web, queste pagine dovrebbero essere molto poche e potresti non vedere alcun impatto sui KPI dell'implementazione della gestione dei robot. Se ne senti il bisogno, è meglio usare una direttiva "noindex", a meno che non ci siano query di ricerca per tali pagine.
Tagga le pagine utilizzando il budget di scansione
Problema: la codifica incontrollata consuma il budget di scansione e spesso porta a problemi di contenuto sottile.
Soluzioni non ottimali: non consentire con robots.txt o aggiungere un tag "noindex", poiché entrambi ostacoleranno il posizionamento dei tag SEO rilevanti e (immediatamente o eventualmente) impediranno il passaggio dell'equità del collegamento.
Approccio di best practice: valutare il valore di ciascuno dei tag correnti. Se i dati mostrano che la pagina aggiunge poco valore ai motori di ricerca o agli utenti, 301 li reindirizza. Per le pagine che sopravvivono all'abbattimento, lavora per migliorare gli elementi sulla pagina in modo che diventino preziosi sia per gli utenti che per i bot.
Scansione di JavaScript e CSS
Problema: in precedenza, i bot non potevano eseguire la scansione di JavaScript e altri contenuti multimediali. Questo è cambiato e ora è fortemente consigliato consentire ai motori di ricerca di accedere ai file JS e CSS per visualizzare le pagine opzionalmente.
Soluzione non ottimale: non consentire i file JavaScript e CSS con robots.txt per risparmiare il budget di scansione può comportare una scarsa indicizzazione e un impatto negativo sulle classifiche. Ad esempio, il blocco dell'accesso del motore di ricerca a JavaScript che offre un annuncio interstitial o reindirizza gli utenti può essere visto come cloaking.
Approccio di best practice: verifica eventuali problemi di rendering con lo strumento "Visualizza come Google" o ottieni una rapida panoramica di quali risorse sono bloccate con il rapporto "Risorse bloccate", entrambi disponibili in Google Search Console. Se vengono bloccate risorse che potrebbero impedire ai motori di ricerca di visualizzare correttamente la pagina, rimuovere il robots.txt non consentito.
Crawler SEO Oncrawl
 Per saperne di più
Per saperne di piùElenco di controllo dei robot per le migliori pratiche
È spaventosamente comune che un sito Web sia stato rimosso accidentalmente da Google da un errore di controllo del robot.
Tuttavia, la gestione dei robot può essere una potente aggiunta al tuo arsenale SEO quando sai come usarlo. Assicurati solo di procedere con saggezza e cautela.
Per aiutare, ecco una rapida lista di controllo:
- Proteggi le informazioni private utilizzando la protezione con password
- Blocca l'accesso ai siti di sviluppo utilizzando l'autenticazione lato server
- Limita i crawler che prendono larghezza di banda ma offrono poco valore con il blocco dello user-agent
- Assicurati che il dominio principale e tutti i sottodomini dispongano di un file di testo denominato "robots.txt" nella directory di livello superiore che restituisca un codice 200
- Assicurati che il file robots.txt abbia almeno un blocco con una riga agente utente e una riga non consentita
- Assicurati che il file robots.txt abbia almeno una riga della mappa del sito, inserita come ultima riga
- Convalida il file robots.txt nel tester robots.txt di GSC
- Assicurati che ogni pagina indicizzabile specifichi le sue direttive tag robots
- Assicurati che non ci siano direttive contraddittorie o ridondanti tra robots.txt, robots meta tag, X-Robots-Tags, file .htaccess e gestione dei parametri GSC
- Correggi eventuali errori "URL inviato contrassegnato come 'noindex'" o "URL inviato bloccato da robots.txt" nel rapporto sulla copertura GSC
- Comprendere il motivo di eventuali esclusioni relative ai robot nel rapporto sulla copertura GSC
- Assicurarsi che solo le pagine pertinenti siano mostrate nella relazione "Risorse bloccate" dell'SGC
Vai a controllare la gestione dei tuoi robot e assicurati di farlo bene.