
Scansione, indicizzazione e Python: tutto quello che devi sapere
Pubblicato: 2021-05-31Vorrei iniziare questo articolo con una sorta di equazione molto semplice: se le tue pagine non vengono scansionate, non verranno mai indicizzate e quindi le tue prestazioni SEO ne risentiranno sempre (e puzzeranno).
Di conseguenza, i SEO devono sforzarsi di trovare il modo migliore per rendere i loro siti Web scansionabili e fornire a Google le loro pagine più importanti per indicizzarle e iniziare ad acquisire traffico attraverso di esse.
Per fortuna, abbiamo molte risorse che possono aiutarci a migliorare la scansione del nostro sito Web come Screaming Frog, Oncrawl o Python. Ti mostrerò come Python può aiutarti ad analizzare e migliorare la facilità di scansione e gli indicatori di indicizzazione. Il più delle volte, questo tipo di miglioramenti porta anche a classifiche migliori, maggiore visibilità nelle SERP e, infine, più utenti che atterrano sul tuo sito web.
1. Richiesta di indicizzazione con Python
1.1. Per Google
La richiesta dell'indicizzazione per Google può essere eseguita in diversi modi, anche se purtroppo non ne sono molto convinto. Ti guiderò attraverso tre diverse opzioni con i loro pro e contro:
- Selenium e Google Search Console: dal mio punto di vista e dopo averlo testato e il resto delle opzioni, questa è la soluzione più efficace. Tuttavia, dopo un certo numero di tentativi è possibile che venga visualizzato un pop-up captcha che lo interromperà.
- Ping di una mappa del sito: aiuta sicuramente a far scansionare le mappe del sito come richiesto, ma non URL specifici, ad esempio nel caso in cui siano state aggiunte nuove pagine al sito web.
- API di indicizzazione di Google: non è molto affidabile ad eccezione di emittenti e siti web di piattaforme di lavoro. Aiuta ad aumentare i tassi di scansione ma non a indicizzare URL specifici.
Dopo questa rapida panoramica su ciascun metodo, analizziamoli uno per uno.
1.1.1. Selenio e Google Search Console
In sostanza, quello che faremo in questa prima soluzione è accedere a Google Search Console da un browser con Selenium e replicare lo stesso processo che seguiremo manualmente per inviare molti URL per l'indicizzazione con Google Search Console, ma in modo automatizzato.
Nota: non abusare di questo metodo e inviare una pagina per l'indicizzazione solo se il contenuto è stato aggiornato o se la pagina è completamente nuova.
Il trucco per poter accedere a Google Search Console con Selenium è accedere prima a OUATH Playground, come ho spiegato in questo articolo su come automatizzare il download del rapporto delle statistiche di scansione di GSC.
#Importiamo questi moduli
tempo di importazione
dal driver web di importazione del selenio
da webdriver_manager.chrome importa ChromeDriverManager
da selenium.webdriver.common.keys importa le chiavi
#Installiamo il nostro driver Selenium
driver = webdriver.Chrome(ChromeDriverManager().install())
#Accediamo all'account del parco giochi OUATH per accedere ai servizi Google
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
#Aspettiamo un po' per assicurarci che il rendering sia completo prima di selezionare elementi con Xpath e introdurre il nostro indirizzo email.
tempo.sonno(10)
form1=driver.find_element_by_xpath('//*[@]')
form1.send_keys("<il tuo indirizzo email>")
form1.send_keys(Keys.ENTER)
#Stessa cosa qui, aspettiamo un po' e poi introduciamo la nostra password.
tempo.sonno(10)
form2=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
form2.send_keys("<la tua password>")
form2.send_keys(Keys.ENTER)
Successivamente, possiamo accedere al nostro URL di Google Search Console:
driver.get('https://search.google.com/search-console?resource_id=tuo_dominio'')
tempo.sonno(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div /div[1]/input[2]')
box.send_keys("il tuo_URL")
box.send_keys(Keys.ENTER)
tempo.sonno(5)
indexation = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div /div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indexation.click()
tempo.sonno(120)
Purtroppo, come spiegato nell'introduzione, sembra che dopo un certo numero di richieste inizi a richiedere un puzzle captcha per procedere con la richiesta di indicizzazione. Poiché il metodo automatizzato non può risolvere il captcha, questo è qualcosa che ostacola questa soluzione.
1.1.2. Ping di una mappa del sito
Gli URL della Sitemap possono essere inviati a Google con il metodo ping. Fondamentalmente, dovresti solo fare una richiesta al seguente endpoint introducendo l'URL della tua mappa del sito come parametro:
http://www.google.com/ping?sitemap=URL/of/file
Questo può essere automatizzato molto facilmente con Python e le richieste, come ho spiegato in questo articolo.
import urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" risposta = urllib.request.urlopen(url)
1.1.3. API di indicizzazione di Google
L'API di indicizzazione di Google può essere una buona soluzione per migliorare le tue velocità di scansione, ma di solito non è un metodo molto efficace per indicizzare i tuoi contenuti poiché dovrebbe essere utilizzato solo se il tuo sito Web ha JobPosting o BroadcastEvent incorporati in un VideoObject. Tuttavia, se desideri provarlo e testarlo tu stesso, puoi seguire i passaggi successivi.
Prima di tutto, per iniziare con questa API devi andare su Google Cloud Console, creare un progetto e una credenziale dell'account di servizio. Successivamente, dovrai abilitare l'API di indicizzazione dalla Libreria e aggiungere l'account e-mail fornito con le credenziali dell'account di servizio come proprietario della proprietà su Google Search Console. Potrebbe essere necessario utilizzare la versione precedente di Google Search Console per poter aggiungere questo indirizzo email come proprietario di una proprietà.
Dopo aver seguito i passaggi precedenti, sarai in grado di iniziare a chiedere l'indicizzazione e la deindicizzazione con questa API utilizzando il prossimo pezzo di codice:
da oauth2client.service_account import ServiceAccountCredentials
importa httplib2
AMBITI = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "path_to_your_credentials.json"
credenziali = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
se le credenziali è Nessuna o credenziali.non valide:
credenziali = tools.run_flow(flusso, archiviazione)
http = credenziali.authorize(httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
per l'iterazione nell'intervallo (len(list_urls)):
contenuto = '''{
'url': "'''+str(list_urls[iterazione])+'''",
'tipo': "URL_AGGIORNATO"
}'''
risposta, contenuto = http.request(ENDPOINT, metodo="POST", body=contenuto)
stampa (risposta)
stampa (contenuto)Se desideri richiedere la deindicizzazione, devi modificare il tipo di richiesta da "URL_UPDATED" a "URL_DELETED". La parte di codice precedente stamperà le risposte dall'API con i tempi di notifica e i loro stati. Se lo stato è 200, la richiesta sarà stata effettuata correttamente.
1.2. Per Bing
Molto spesso quando si parla di SEO si pensa solo a Google, ma non possiamo dimenticare che in alcuni mercati ci sono altri motori di ricerca predominanti e/o altri motori di ricerca che hanno una quota di mercato di tutto rispetto come Bing.
È importante ricordare fin dall'inizio che Bing ha già una funzione molto utile su Bing Webmaster Tools che ti consente di richiedere l'invio di un massimo di 10.000 URL al giorno nella maggior parte dei casi. A volte, la tua quota giornaliera potrebbe essere inferiore a 10.000 URL, ma hai la possibilità di richiedere un aumento della quota se ritieni di aver bisogno di una quota maggiore per soddisfare le tue esigenze. Puoi leggere di più su questo in questa pagina.
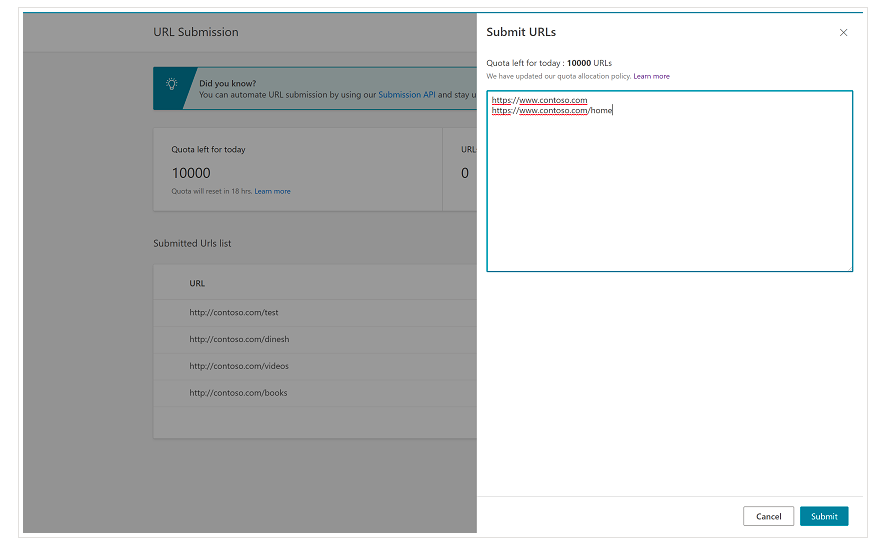
Questa funzione è davvero molto comoda per gli invii di URL in blocco poiché dovrai solo inserire i tuoi URL in righe diverse nello strumento di invio degli URL dalla normale interfaccia di Bing Webmaster Tools.
1.2.1. API di indicizzazione di Bing
L'API Bing Indexing può essere utilizzata con una chiave API che deve essere introdotta come parametro. Questa chiave API può essere ottenuta su Bing Webmaster Tools, andando alla sezione Accesso API e, successivamente, generando la chiave API.
Una volta ottenuta la chiave API, possiamo giocare con l'API con il seguente pezzo di codice (dovresti solo aggiungere la tua chiave API e l'URL del tuo sito):
richieste di importazione
list_urls = ["https://www.example.com", "https://www.example/test2/"]
per y in list_urls:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
headers = {'Tipo di contenuto': 'applicazione/json; set caratteri=utf-8'}
x = request.post(url, data=myobj, headers=headers)
print(str(y) + ": " + str(x))Questo stamperà l'URL e il relativo codice di risposta su ogni iterazione. A differenza dell'API di indicizzazione di Google, questa API può essere utilizzata per qualsiasi tipo di sito Web.
[Case Study] Aumenta la visibilità migliorando la scansione del sito Web per Googlebot
 Leggi il caso di studio
Leggi il caso di studio2. Analisi, creazione e caricamento di mappe del sito
Come tutti sappiamo, le mappe dei siti sono elementi molto utili per fornire ai bot dei motori di ricerca gli URL di cui vorremmo scansionare. Per consentire ai bot dei motori di ricerca di sapere dove si trovano le nostre mappe del sito, devono essere caricate su Google Search Console e Bing Webmaster Tools e incluse nel file robots.txt per il resto dei bot.
Con Python possiamo lavorare principalmente su tre diversi aspetti legati alle sitemap: la loro analisi, creazione e caricamento e cancellazione da Google Search Console.
2.1. Importazione e analisi di Sitemap con Python
Advertools è una grande libreria creata da Elias Dabbas che può essere utilizzata per l'importazione di mappe del sito e per molte altre attività SEO. Sarai in grado di importare le mappe dei siti in Dataframe semplicemente usando:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
Questa libreria supporta le mappe dei siti XML regolari, le mappe dei siti di notizie e le mappe dei siti video.
Se invece sei interessato solo ad importare gli URL dalla mappa del sito, puoi utilizzare anche le richieste della libreria e BeautifulSoup.
richieste di importazione
da bs4 importa BeautifulSoup
r = request.get("https://www.example.com/your_sitemap.xml")
xml = r.testo
zuppa = BeautifulSoup(xml)
urls = zuppa.find_all("loc")
urls = [[x.text] per x negli URL]
Una volta che la mappa del sito è stata importata, puoi giocare con gli URL estratti ed eseguire un'analisi del contenuto come spiegato da Koray Tugberk in questo articolo.
2.2. Creazione di mappe del sito con Python
Puoi anche utilizzare Python per creare sitemaps.xml da un elenco di URL, come spiegato da JC Chouinard in questo articolo. Ciò può essere particolarmente utile per siti Web molto dinamici i cui URL cambiano rapidamente e, insieme al metodo ping spiegato sopra, può essere un'ottima soluzione per fornire a Google i nuovi URL e farli scansionare e indicizzare rapidamente.
Di recente, Greg Bernhardt ha anche creato un'APP con Streamlit e Python per generare mappe del sito.
2.3. Caricamento ed eliminazione delle mappe del sito da Google Search Console
Google Search Console ha un'API che può essere utilizzata principalmente in due modi diversi: per estrarre dati sulle prestazioni web e gestire le mappe dei siti. In questo post, ci concentreremo sull'opzione di caricare ed eliminare le mappe del sito.
Innanzitutto, è importante creare o utilizzare un progetto esistente da Google Cloud Console per ottenere una credenziale OUATH e abilitare il servizio Google Search Console. JC Chouinard spiega molto bene i passaggi che devi seguire per accedere all'API di Google Search Console con Python e come effettuare la tua prima richiesta in questo articolo. Fondamentalmente, possiamo utilizzare completamente il suo codice ma solo introducendo una modifica, negli ambiti aggiungeremo “https://www.googleapis.com/auth/webmasters” invece di “https://www.googleapis.com /auth/webmasters.readonly” poiché utilizzeremo l'API non solo per leggere ma anche per caricare ed eliminare le mappe del sito.

Una volta che ci connettiamo con l'API, possiamo iniziare a giocarci ed elencare tutte le mappe dei siti dalle nostre proprietà di Google Search Console con il prossimo pezzo di codice:
per site_url in verificati_sites_urls:
stampa (URL_sito)
# Recupera l'elenco delle mappe dei siti inviate
sitemaps = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
se "mappa del sito" nelle mappe del sito:
sitemap_urls = [s['path'] for s in sitemaps['sitemap']]
print (" " + "\n ".join(sitemap_urls))
Quando si tratta di mappe del sito specifiche, possiamo svolgere tre attività che elaboreremo nelle prossime sezioni: caricare, eliminare e richiedere informazioni.
2.3.1. Caricamento di una mappa del sito
Per caricare una mappa del sito con Python dobbiamo solo specificare l'URL del sito e il percorso della mappa del sito ed eseguire questo pezzo di codice:
SITO WEB = 'la tua proprietà GSC' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.2. Eliminazione di una mappa del sito
L'altro lato della medaglia è quando vorremmo eliminare una mappa del sito. Possiamo anche eliminare le mappe dei siti da Google Search Console con Python utilizzando il metodo "cancella" invece di "invia".
SITO WEB = 'la tua proprietà GSC' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
2.3.3. Richiesta di informazioni dalle mappe del sito
Infine, possiamo richiedere informazioni anche dalla mappa del sito utilizzando il metodo “ottenere”.
SITO WEB = 'la tua proprietà GSC' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=WEBSITE, feedpath=SITEMAP_PATH).execute()
Questo restituirà una risposta in formato JSON come: 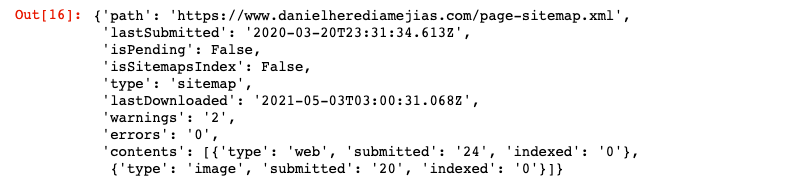
3. Analisi dei collegamenti interni e opportunità
Avere una struttura di collegamento interna adeguata è molto utile per facilitare la scansione del tuo sito web da parte dei bot dei motori di ricerca. Alcuni dei problemi principali che ho riscontrato controllando un certo numero di siti Web con configurazioni tecniche molto sofisticate sono:
- Link introdotti con eventi on-click: in breve, Googlebot non fa clic sui pulsanti, quindi se i tuoi link vengono inseriti con un evento on-click, Googlebot non potrà seguirli.
- Collegamenti renderizzati lato client: nonostante Googlebot e altri motori di ricerca stiano migliorando molto nell'esecuzione di JavaScript, è ancora qualcosa di piuttosto impegnativo per loro, quindi è molto meglio rendere questi collegamenti lato server e servirli nell'HTML grezzo per bot dei motori di ricerca piuttosto che aspettarsi che eseguano script JavaScript.
- Pop-up di accesso e/o età: i popup di accesso e i limiti di età possono impedire ai bot dei motori di ricerca di eseguire la scansione del contenuto che si trova dietro questi "ostacoli".
- Uso eccessivo degli attributi nofollow: l' utilizzo di molti attributi nofollow che puntano a pagine interne di valore impedirà ai bot dei motori di ricerca di scansionarle.
- Noindex e follow: tecnicamente la combinazione di noindex e le direttive follow dovrebbe consentire ai bot dei motori di ricerca di eseguire la scansione dei collegamenti che si trovano su quella pagina. Tuttavia, sembra che Googlebot smetta di eseguire la scansione di quelle pagine con le direttive noindex dopo un po'.
Con Python possiamo analizzare la nostra struttura di collegamento interna e trovare nuove opportunità di collegamento interno in modalità bulk.
3.1. Analisi dei collegamenti interni con Python
Alcuni mesi fa ho scritto un articolo su come usare Python e la libreria Networkx per creare grafici per visualizzare la struttura di collegamento interna in modo molto visivo:
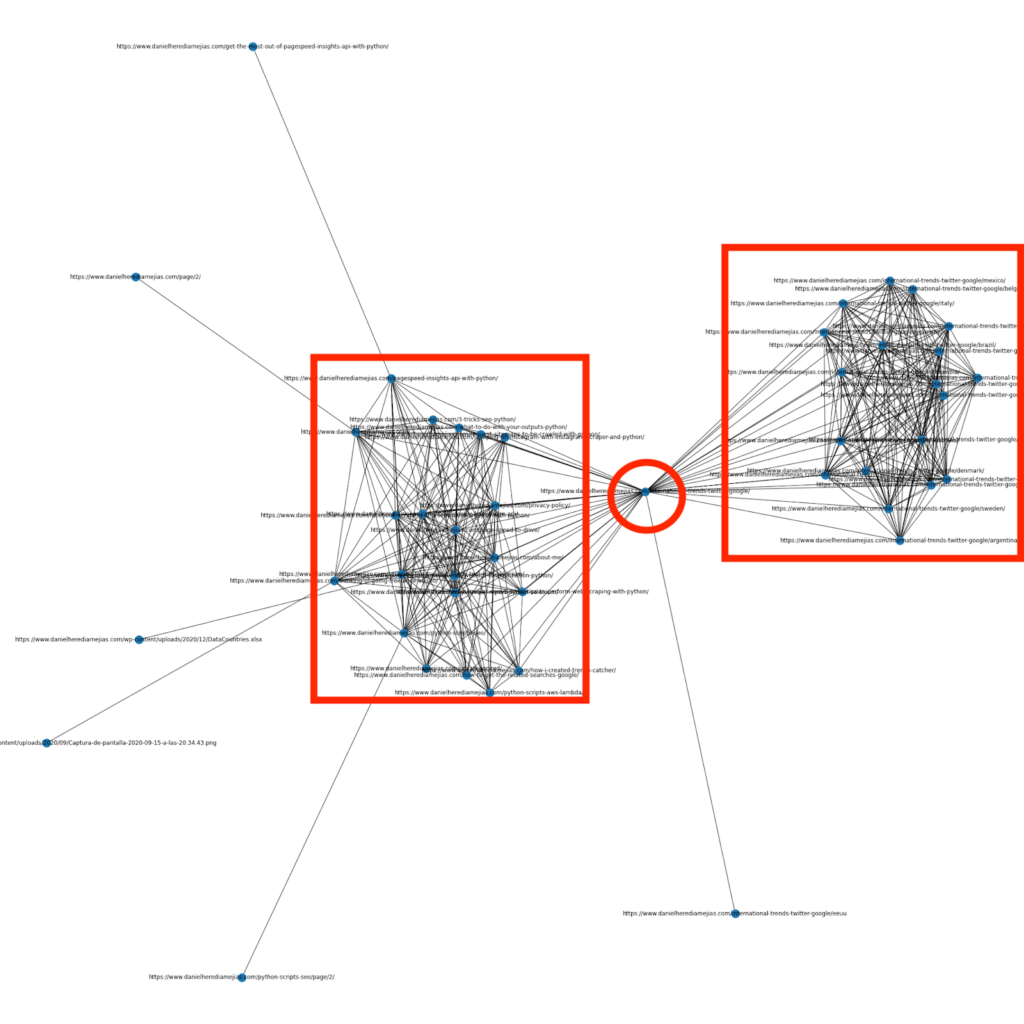
Questo è qualcosa di molto simile a quello che puoi ottenere da Screaming Frog, ma il vantaggio di usare Python per questo tipo di analisi è che sostanzialmente puoi scegliere i dati che vorresti includere in questi grafici e controllare la maggior parte degli elementi del grafico come come colori, dimensioni dei nodi o anche le pagine che vorresti aggiungere.
3.2. Trovare nuove opportunità di collegamento interno con Python
Oltre ad analizzare le strutture del sito, puoi anche utilizzare Python per trovare nuove opportunità di collegamento interno fornendo una serie di parole chiave e URL e scorrendo gli URL cercando i termini forniti nei loro contenuti.
Questo è qualcosa che può funzionare molto bene con le esportazioni Semrush o Ahrefs al fine di trovare potenti collegamenti interni contestuali da alcune pagine che sono già classificate per parole chiave e, quindi, che hanno già un qualche tipo di autorità.
Puoi leggere di più su questo metodo qui.
4. Velocità del sito Web, pagine di errore 5xx e soft
Come affermato da Google in questa pagina sul significato del crawl budget per Google, rendere più veloce il tuo sito migliora l'esperienza dell'utente e aumenta la velocità di scansione. D'altra parte, ci sono anche altri fattori che potrebbero incidere sul crawl budget come pagine di errore soft, contenuti di bassa qualità e contenuti duplicati sul sito.
4.1. Velocità della pagina e Python
4.2.1 Analizzare la velocità del tuo sito web con Python
L'API Page Speed Insights è molto utile per analizzare le prestazioni del tuo sito Web in termini di velocità della pagina e per ottenere molti dati su molte metriche di velocità della pagina diverse (quasi 50) oltre a Core Web Vitals.
Lavorare con Page Speed Insights con Python è molto semplice, sono necessarie solo una chiave API e richieste per farne uso. Per esempio:
import urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #Nota che puoi inserire il tuo URL con l'URL del parametro e puoi anche modificare il parametro del dispositivo se desideri ottenere i dati per desktop. risposta = urllib.request.urlopen(url) data = json.loads(response.read())
Inoltre, puoi anche prevedere con Python e il calcolatore del punteggio di Lighthouse quanto migliorerebbe il tuo punteggio complessivo delle prestazioni in caso di apportare le modifiche richieste per migliorare la velocità della tua pagina, come spiegato in questo articolo.
4.2.2 Ottimizzazione e ridimensionamento delle immagini con Python
In relazione alla velocità del sito Web, Python può essere utilizzato anche per ottimizzare, comprimere e ridimensionare le immagini come spiegato in questi articoli scritti da Koray Tugberk e Greg Bernhardt:
- Automatizza la compressione delle immagini con Python su FTP.
- Ridimensiona le immagini con Python in blocco.
- Ottimizza le immagini tramite Python per SEO e UX.
4.2. 5xx e altri errori di codice di risposta estrazione con Python
Gli errori del codice di risposta 5xx potrebbero indicare che il tuo server non è abbastanza veloce per far fronte a tutte le richieste che sta ricevendo. Ciò può avere un impatto molto negativo sulla velocità di scansione e può anche danneggiare l'esperienza dell'utente.
Per assicurarti che il tuo sito web funzioni come previsto, puoi automatizzare il download del rapporto sulle statistiche di scansione con Python e Selenium e puoi tenere d'occhio i tuoi file di registro.
4.3. Estrazione di pagine di errore soft con Python
Di recente, Jose Luis Hernando ha pubblicato un articolo in onore di Hamlet Batista su come automatizzare l'estrazione del report di copertura con Node.js. Questa può essere una soluzione straordinaria per estrarre le pagine di errore soft e persino gli errori di risposta 5xx che potrebbero influire negativamente sulla velocità di scansione.
Possiamo anche replicare questo stesso processo con Python in modo da compilare in una sola scheda di Excel tutti gli URL forniti da Google Search Console come errati, validi con avvisi, validi ed esclusi.
Innanzitutto, dobbiamo accedere a Google Search Console come spiegato in precedenza in questo articolo con Python con Selenium. Successivamente, selezioneremo tutte le caselle di stato degli URL, aggiungeremo fino a 100 righe per pagina e inizieremo a scorrere su tutti i tipi di URL segnalati da GSC e scaricheremo ogni singolo file Excel.
tempo di importazione
dal driver web di importazione del selenio
da webdriver_manager.chrome importa ChromeDriverManager
da selenium.webdriver.common.keys importa le chiavi
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
tempo.sonno(5)
searchBox=driver.find_element_by_xpath('//*[@]')
searchBox.send_keys("<indirizzoemail>")
searchBox.send_keys(Keys.ENTER)
tempo.sonno(5)
searchBox=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
searchBox.send_keys("<password>")
searchBox.send_keys(Keys.ENTER)
tempo.sonno(5)
tuodominio = str(input("Inserisci qui la tua proprietà http o dominio. Se è un dominio includi: 'sc-dominio':"))
driver.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems[x] for i in range(len(df1["URL"]))]
df1['Tipo'] = listvalues
list_results = df1.values.tolist()
altro:
df2 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Coverage-Drilldown-" + oggi + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df2["URL"]))]
df2['Tipo'] = listvalues
list_results = list_results + df2.values.tolist()
df = pd.DataFrame(list_results, columns= ["URL","TimeStamp", "Tipo"])
df.to_csv('<nomefile>.csv', header=True, index=False, encoding = "utf-8")
L'output finale è simile a: 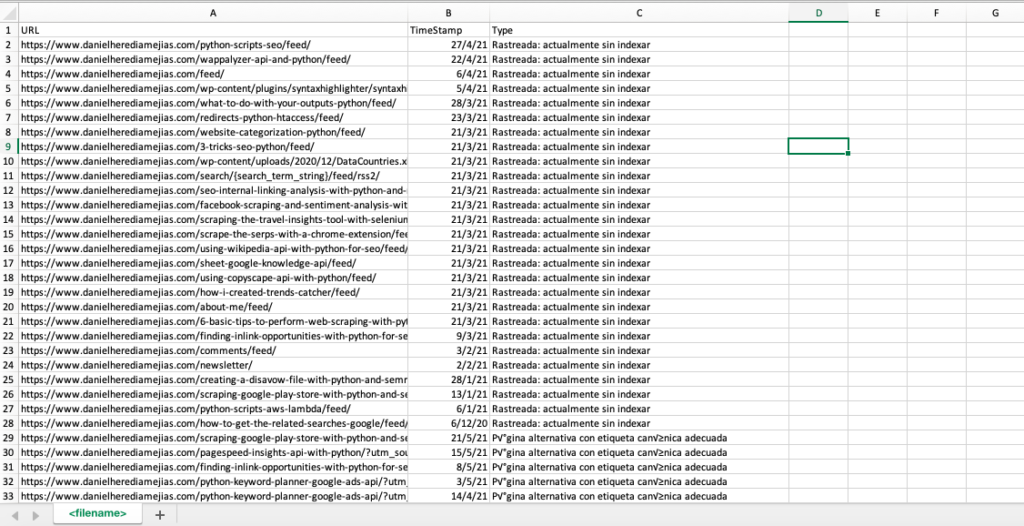
4.4. Analisi dei file di registro con Python
Oltre ai dati disponibili nel rapporto sulle statistiche di scansione di Google Search Console, puoi anche analizzare i tuoi file utilizzando Python per ottenere molte più informazioni su come i bot dei motori di ricerca eseguono la scansione del tuo sito web. Se non stai già utilizzando un analizzatore di log per SEO, puoi leggere questo articolo di SEO Garden in cui viene spiegata l'analisi dei log con Python.
[Ebook] Quattro casi d'uso per sfruttare l'analisi dei log SEO
Scarica gratis5. Conclusioni finali
Abbiamo visto che Python può essere una grande risorsa per analizzare e migliorare la scansione e l'indicizzazione dei nostri siti Web in molti modi diversi. Abbiamo anche visto come rendere la vita molto più semplice automatizzando la maggior parte delle attività noiose e manuali che richiederebbero migliaia di ore del tuo tempo.
Devo dire che purtroppo non sono del tutto convinto dalle soluzioni che vengono proposte in questo momento da Google per richiedere l'indicizzazione di un gran numero di URL, anche se posso capire in qualche misura la sua paura di proporre una soluzione migliore: molti SEO potrebbero tendere per abusarne.
In contrasto c'è Bing, che offre soluzioni eccezionali e convenienti per richiedere l'indicizzazione degli URL tramite API e anche tramite la normale interfaccia su Bing Webmaster Tools.
A causa del fatto che l'API di indicizzazione di Google ha margini di miglioramento, altri elementi come avere una mappa del sito accessibile e aggiornata, i tuoi collegamenti interni, la velocità della tua pagina, le tue pagine di errore morbido e i tuoi contenuti duplicati e di bassa qualità diventano ancora più importanti per garantire che il tuo sito web sia scansionato correttamente e che le tue pagine più importanti siano indicizzate.