
10 problemi SEO tecnici comuni e come individuarli
Pubblicato: 2019-06-04Avendo svolto servizi SEO in una vasta gamma di settori, a volte sei in grado di affrontare problemi comuni soprattutto quando lavori su un CMS comune come WordPress, Shopify o SquareSpace.
Qui ho delineato 10 problemi SEO tecnici piuttosto comuni che potresti incontrare durante l'ottimizzazione di un sito web.
Non sto dicendo che questi problemi saranno sicuramente problematici per te o per il tuo cliente: molto spesso il contesto è ancora molto importante. Non esiste sempre una soluzione adatta a tutti, ma probabilmente è comunque bene diffidare degli scenari descritti di seguito.
1 – File Robots.txt che blocca l'accesso a Googlebot
Questa non è una novità per la maggior parte dei SEO tecnici, ma è comunque molto facile trascurare di controllare il file robots – e non solo al momento dell'esecuzione di un audit tecnico, ma come controllo ricorrente.
Puoi utilizzare uno strumento come Search Console (la vecchia versione) per verificare se Google ha problemi di accesso, oppure puoi semplicemente provare a eseguire la scansione del tuo sito come Googlebot con uno strumento come OnCrawl (basta selezionare il loro User Agent). OnCrawl obbedirà al robots.txt a meno che tu non dica diversamente.
Esporta i risultati della scansione e confrontali con un elenco noto di pagine del tuo sito e verifica che non ci siano punti ciechi del crawler.
Per dimostrare che ciò accade ancora abbastanza spesso, e ad alcuni siti abbastanza grandi, alcune settimane fa ho notato che lo strumento Speed Test di Pingdom era bloccato all'interno di Google.
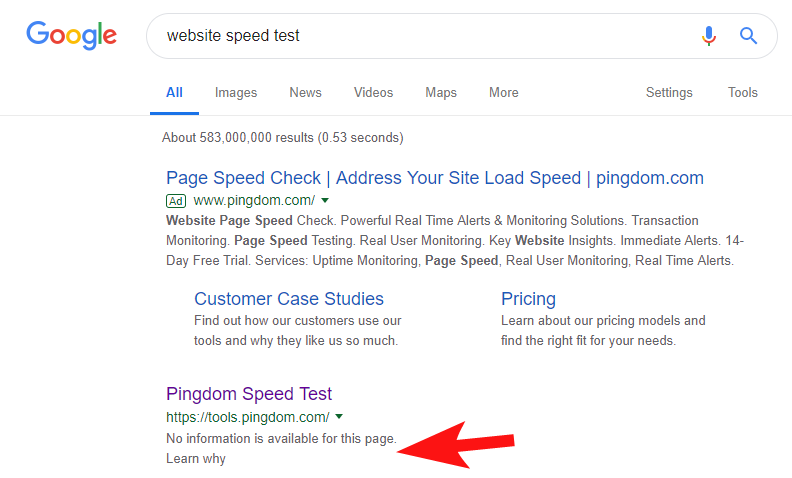
Guardare il loro file robots (e successivamente provare a eseguire la scansione della loro pagina da OnCrawl come Googlebot) ha confermato i miei sospetti che stessero bloccando l'accesso al loro sito.
Il file robots.txt colpevole è mostrato di seguito:

Li ho contattati con un "FYI" ma non ho avuto risposta, ma pochi giorni dopo ho visto che tutto era tornato alla normalità. Uff – potrei dormire di nuovo facilmente!
Nel loro caso sembrava che ogni volta che esegui la scansione del tuo sito come parte del loro controllo di velocità, stesse creando un URL che includeva quel carattere hash evidenziato nel file robots sopra.
Forse questi venivano scansionati e persino indicizzati in qualche modo, e volevano controllarlo (il che sarebbe molto comprensibile). In questo caso probabilmente non hanno testato completamente il potenziale impatto, che alla fine era probabilmente minimo.
Ecco i loro robot attuali per chiunque sia interessato.

Vale la pena notare che in alcuni casi è possibile accedere alle modifiche storiche del file robots.txt utilizzando Internet Wayback Machine. Dalla mia esperienza, funziona meglio su siti più grandi come puoi immaginare: sono molto più spesso scansionati dall'archiviatore di Wayback Machine.
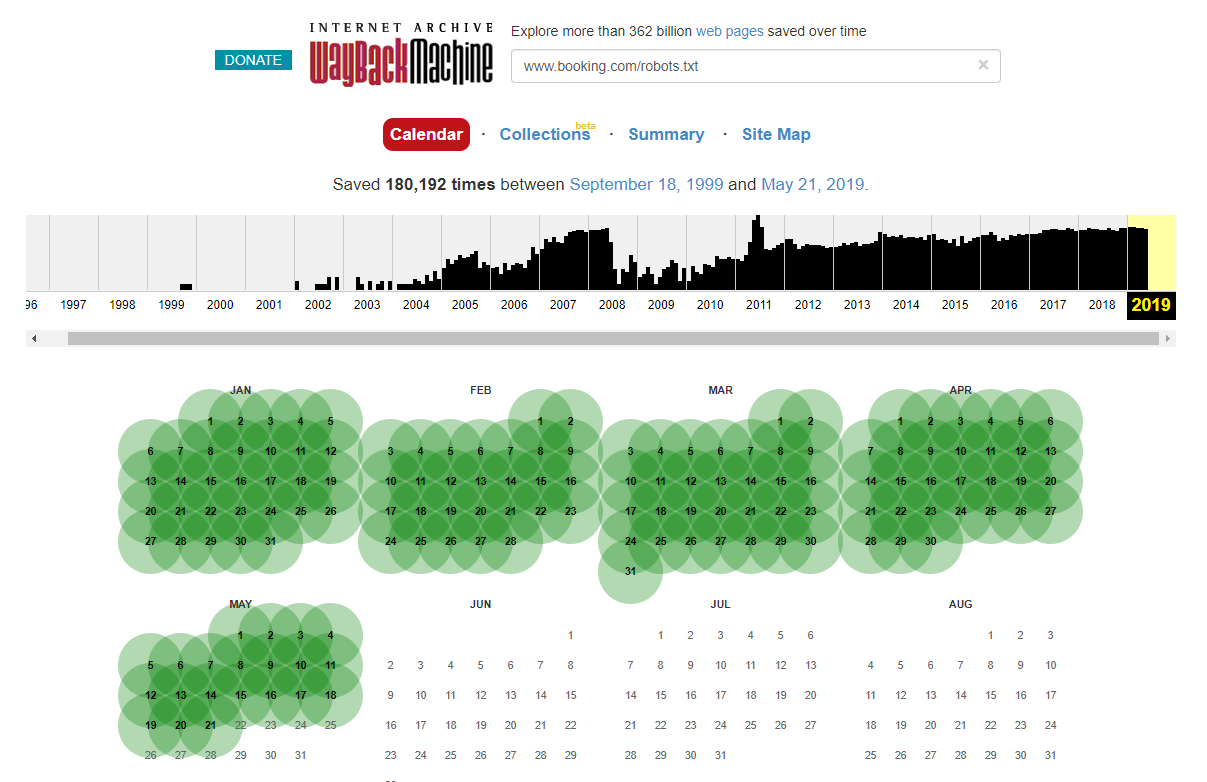
Non è la prima volta che vedo un robots.txt live in natura che causa un po' di scompiglio nella SERP. E sicuramente non sarà l'ultimo: è una cosa così semplice da trascurare (dopotutto è letteralmente un file) ma controllarlo dovrebbe far parte del programma di lavoro in corso di ogni SEO.
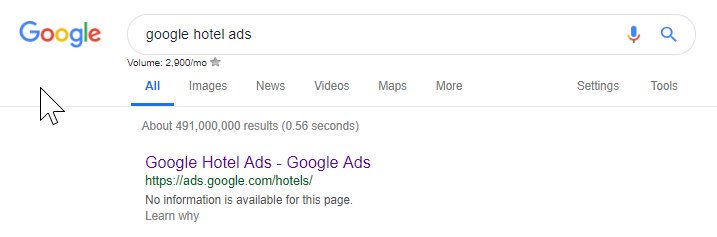
Da quanto sopra puoi vedere che anche Google a volte rovina i file dei robot, bloccandosi dall'accesso ai loro contenuti. Questo potrebbe essere stato intenzionale, ma guardando la lingua del loro file robot di seguito, in qualche modo ne dubito.
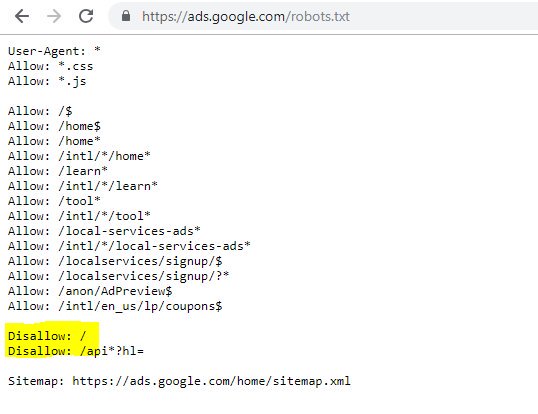
L'evidenziato Disallow: / in questo caso ha impedito l'accesso a eventuali percorsi URL; sarebbe stato più sicuro elencare le sezioni specifiche del sito che non dovrebbero essere sottoposte a scansione.
2 – Problemi di configurazione del dominio a livello DNS
Questo è sorprendentemente comune, ma di solito è una soluzione rapida. Questo è uno di quei cambiamenti SEO a basso costo *potenzialmente* ad alto impatto che i SEO tecnici adorano.
Spesso con le implementazioni SSL non riesco a vedere la versione del dominio non WWW configurata correttamente, come il reindirizzamento 302 all'URL successivo e la formazione di una catena, o lo scenario peggiore non si carica affatto.
Un buon esempio qui è quello del sito web dell'Hotel Football.
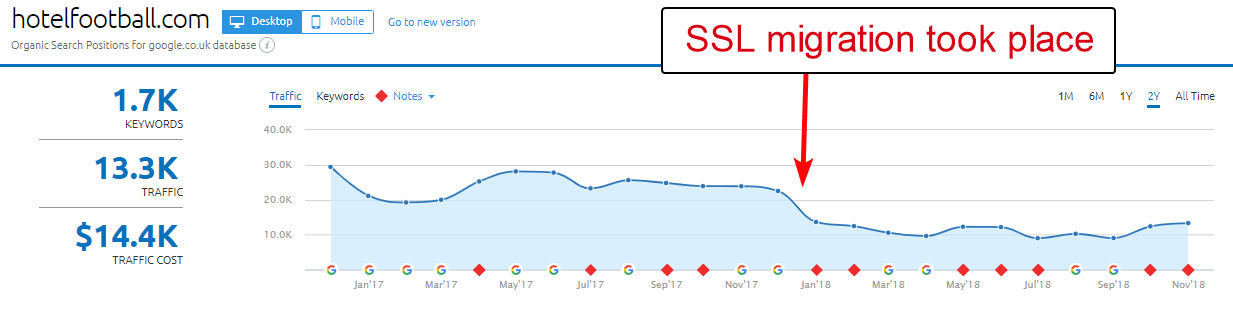
Hanno subito una migrazione SSL all'inizio dell'anno scorso, cosa che non è andata molto bene per loro a giudicare dal rapporto sulla panoramica del dominio di SEMRush sopra.
L'avevo notato tempo fa perché ho lavorato molto nel settore dei viaggi e dell'ospitalità - e con un profondo amore per il calcio ero interessato a vedere com'era il loro sito Web (oltre a come stava andando organicamente, ovviamente! ).
Questo è stato in realtà molto facile da diagnosticare: il sito aveva un sacco di backlink estremamente buoni, tutti che puntavano al dominio WWW non SSL all'indirizzo http://www.hotelfootball.com/
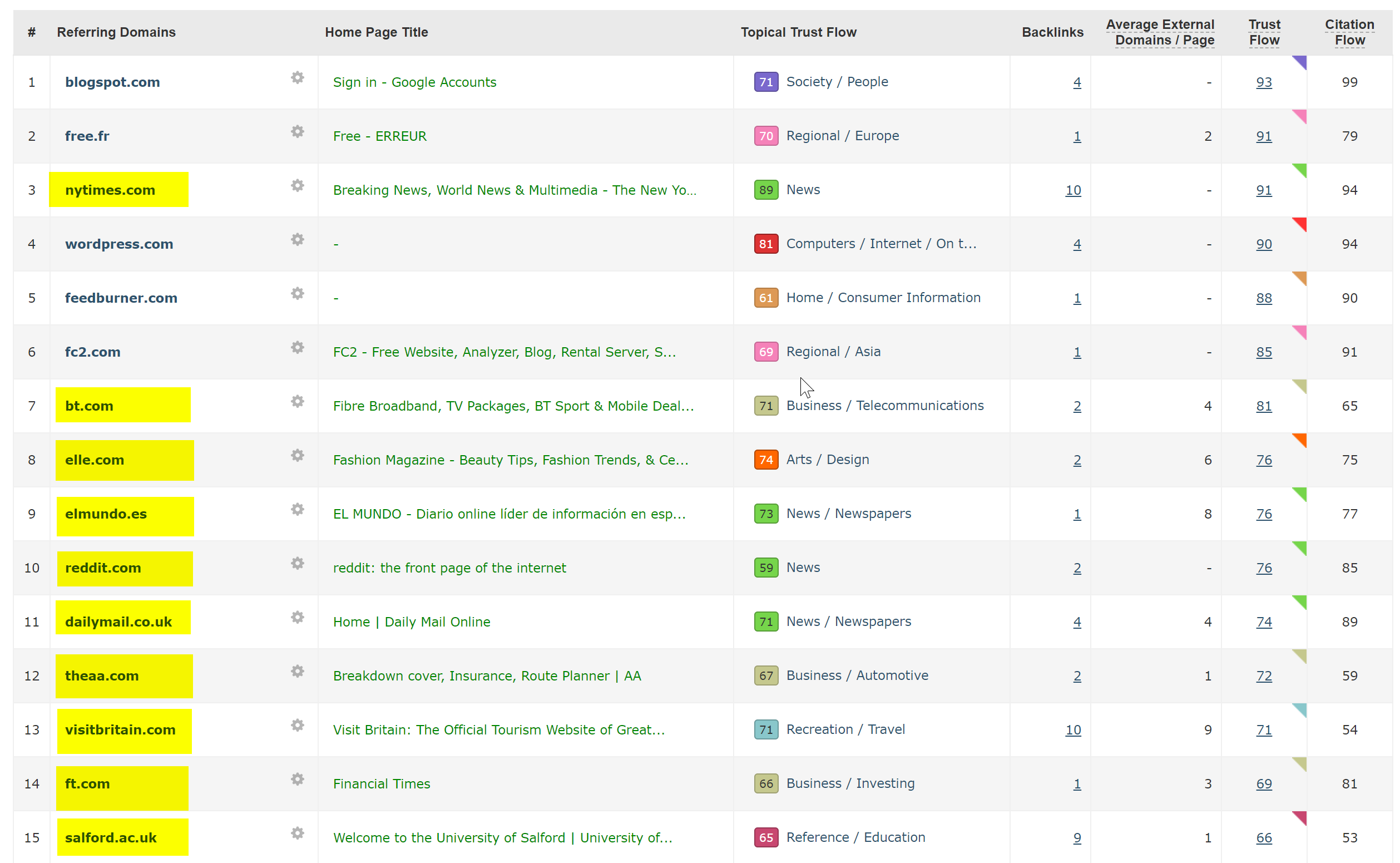
Se provi ad accedere a quell'URL sopra, tuttavia, non viene caricato. Ops. Ed è stato così per circa 18 mesi, almeno. Ho contattato l'agenzia che gestisce il sito tramite Twitter per farglielo sapere, ma non ho avuto risposta.
Con questo tutto ciò che devono fare è assicurarsi che le impostazioni della zona DNS siano corrette, con un record "A" in atto per la versione "WWW" del dominio, che punta all'indirizzo IP corretto (funziona anche un CNAME). Ciò impedirà al dominio di non risolversi.
L'unico aspetto negativo, o il motivo per cui questo richiede così tanto tempo per essere risolto, è che può essere complicato ottenere l'accesso al pannello di gestione del dominio di un sito, o anche che le password sono state perse o non è vista come priorità elevata.
Anche inviare istruzioni per risolvere il problema a una persona non tecnica che detiene le chiavi del nome di dominio non è sempre una buona idea.
Sarei molto curioso di vedere l'impatto organico se/quando saranno in grado di apportare le modifiche di cui sopra, soprattutto considerando tutti i backlink che il dominio non WWW ha accumulato da quando l'hotel è stato lanciato dagli ex calciatori del Manchester United Gary Neville, Ryan Giggs e compagnia.
Anche se si classificano al primo posto su Google per il nome del loro hotel (come puoi immaginare), non sembrano avere un buon posizionamento per nessuno dei loro termini di ricerca non di marca più competitivi (attualmente sono in posizione 10 su Google per "hotel vicino a Old Trafford").
Hanno segnato un po' di un autogol con quanto sopra, ma risolvere questo problema potrebbe almeno aiutare in qualche modo a risolverlo.
Crawler SEO Oncrawl
 Per saperne di più
Per saperne di più3 – Pagine canaglia all'interno della Sitemap XML
Anche in questo caso è piuttosto semplice, ma è stranamente comune: dopo aver esaminato la mappa del sito XML di un sito (che è quasi sempre su domain.com/sitemap.xml o domain.com/sitemap_index.xml, potrebbero esserci pagine elencate qui che davvero non non è necessario essere indicizzati.
I colpevoli tipici includono pagine di ringraziamento nascoste (grazie per aver inviato un modulo di contatto), pagine di destinazione PPC che potrebbero causare problemi di contenuto duplicato o altre forme di pagine/post/tassonomie che hai già non indicizzato altrove.
Includerli di nuovo all'interno della mappa del sito XML può inviare segnali contrastanti ai motori di ricerca: in realtà dovresti elencare solo le pagine che desideri che trovino e indicizzino, che è principalmente il punto della mappa del sito.
Ora puoi utilizzare il pratico rapporto all'interno di Search Console per scoprire se le pagine sono state incluse o meno all'interno di una mappa del sito XML dei siti tramite l'opzione Ispeziona URL.
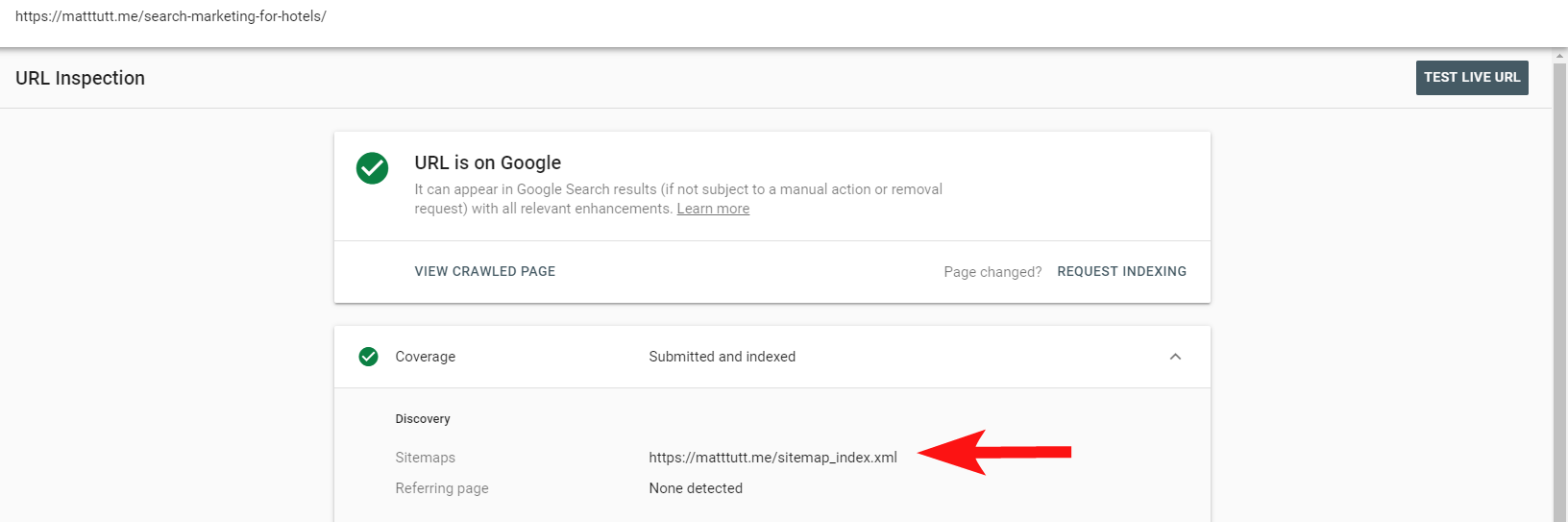
Se hai un sito abbastanza piccolo, probabilmente puoi semplicemente rivedere manualmente la tua mappa del sito XML all'interno del tuo browser, altrimenti scaricala e confrontala con una scansione completa dei tuoi URL indicizzabili.
Spesso puoi catturare questo tipo di contenuto prezioso e di bassa qualità eseguendo una ricerca su site:domain.com in Google per restituire tutto ciò che è stato indicizzato.
Vale la pena notare qui che questo può contenere vecchi contenuti e non dovrebbe essere considerato aggiornato al 100%, ma è un controllo facile per garantire che non ci siano carichi di contenuti che gonfiano i tuoi sforzi SEO e consumano i budget di scansione.
4 – Problemi con Googlebot durante il rendering dei tuoi contenuti
Questo è degno di un intero articolo dedicato ad esso e personalmente mi sento come se avessi passato una vita a giocare con lo strumento di recupero e rendering di Google.
Molto è stato detto su questo (e su JavaScript) già da alcuni SEO molto abili, quindi non approfondirò questo argomento troppo a fondo, ma controllare come Googlebot sta visualizzando il tuo sito sarà sempre degno del tuo tempo.
L'esecuzione di alcuni controlli tramite strumenti online può aiutare a scoprire i punti ciechi di Googlebot (aree del sito a cui non possono accedere), problemi con l'ambiente di hosting, JavaScript problematico che brucia risorse e persino problemi di ridimensionamento dello schermo.
Normalmente questi strumenti di terze parti sono abbastanza utili per diagnosticare il problema (Google ti dice anche quando una risorsa è bloccata a causa del tuo file robots, ad esempio), ma a volte potresti ritrovarti a girare in tondo.
Per mostrare un esempio dal vivo di un sito problematico ho intenzione di spararmi ai piedi e fare riferimento al mio sito Web personale e a un tema WordPress particolarmente frustrante che sto usando.
A volte, quando eseguo un'ispezione URL da Search Console, ricevo l'avviso "La pagina non è adatta ai dispositivi mobili" (vedi sotto).
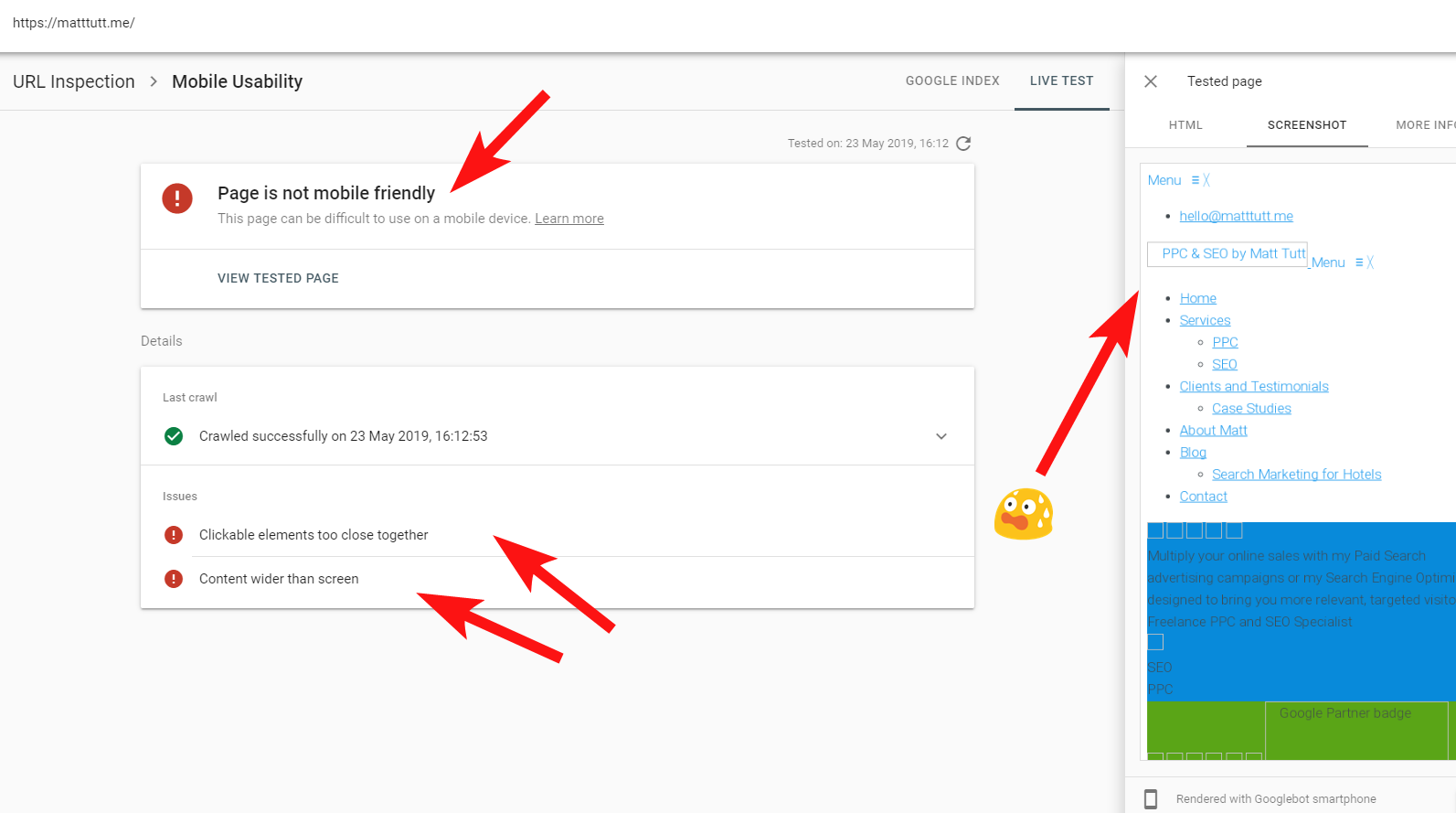
Facendo clic sulla scheda Ulteriori informazioni (in alto a destra) viene fornito un elenco di risorse a cui non è stato possibile accedere da Googlebot, che sono principalmente file CSS e immagini.
Ciò è probabilmente dovuto al fatto che Googlebot non può sempre dare tutta la sua "energia" nel rendering della pagina - a volte è perché Google è cauto nel mandare in crash il mio sito (che è tipo di loro), e altre volte potrei essere limitato perché hanno usato già molte risorse per recuperare e rendere il mio sito.
A volte, a causa di quanto sopra, vale la pena eseguire questi test alcune volte a intervalli sparsi per ottenere una storia più vera. Consiglio anche di controllare i log del server, se possibile, per verificare in che modo Googlebot ha effettuato l'accesso (o non ha avuto accesso) ai contenuti del tuo sito.
404 o altri stati negativi per queste risorse sarebbero chiaramente un brutto segno, soprattutto se coerente.
Nel mio caso, Google chiama il sito per non essere ottimizzato per i dispositivi mobili, il che è principalmente il risultato di alcuni file in stile CSS che non funzionano durante il rendering, il che può giustamente suonare campanelli d'allarme.
Per rendere le cose più confuse, quando si esegue il Mobile Friendly Test di Google, o quando si utilizza qualsiasi altro strumento di terze parti, non vengono rilevati problemi: il sito è mobile friendly.
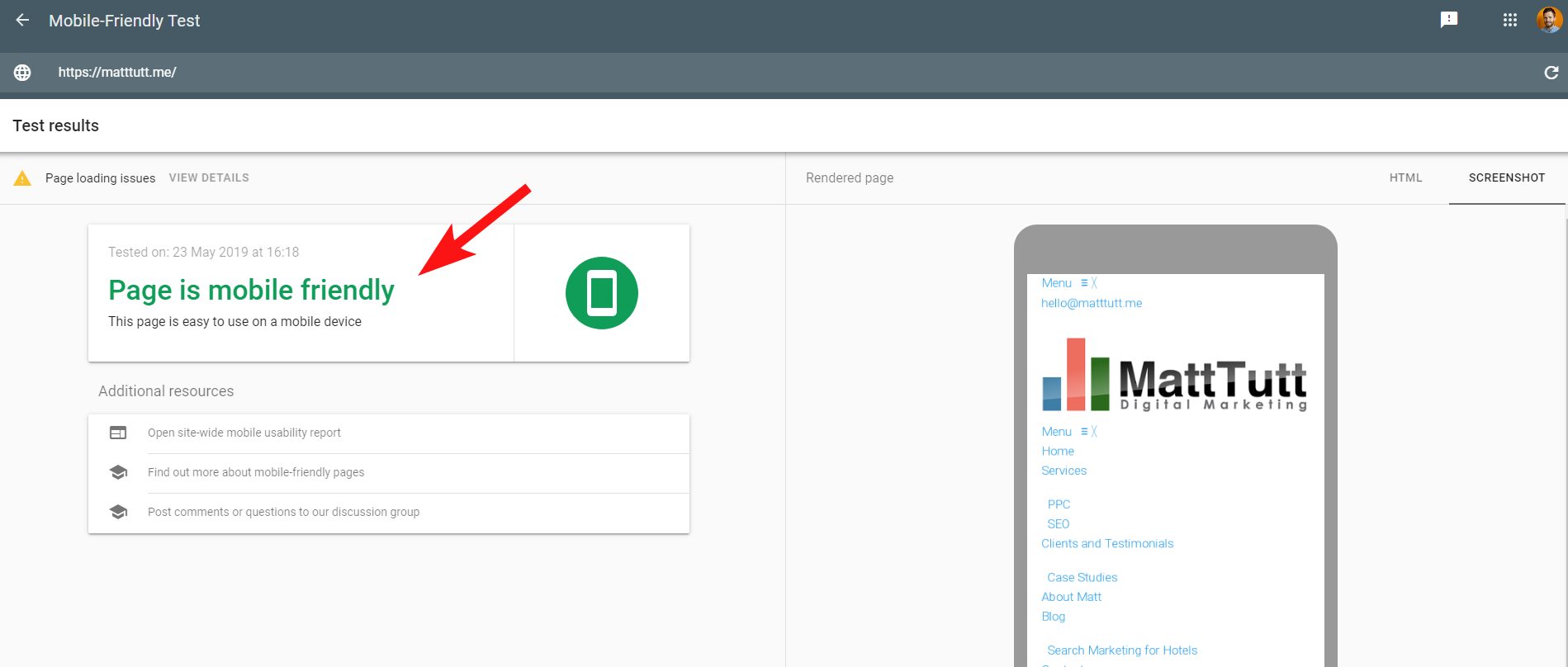
Questi messaggi contrastanti di Google possono essere difficili da decodificare per SEO e sviluppatori web. Per capire ulteriormente ho contattato John Mueller che mi ha suggerito di controllare il mio host web (nessun problema) e che il file CSS può effettivamente essere memorizzato nella cache da Google.
Search Console utilizza un Web Rendering Service (WRS) più vecchio rispetto al Mobile-Friendly Tool, quindi al giorno d'oggi tendo a dare più peso a quest'ultimo.
Con Google che annuncia un nuovo Googlebot con le ultime funzionalità di rendering, tutto ciò potrebbe essere impostato per cambiare, quindi vale la pena tenersi aggiornati su quali strumenti è meglio utilizzare per i controlli di rendering.
Un altro suggerimento qui: se vuoi vedere un rendering scorrevole completo di una pagina puoi passare alla scheda HTML dallo strumento di test mobile di Google, premere CTRL+A per evidenziare tutto il codice HTML visualizzato, quindi copiare e incollare in un editor di testo e salva come file HTML.
Aprendo quello nel tuo browser (incrociamo le dita, a volte dipende dal CMS utilizzato!) otterrai un rendering scorrevole. E il vantaggio di questo è che puoi controllare il rendering di qualsiasi sito: non è necessario l'accesso a Search Console.
5 – Siti compromessi e backlink di spam
Questo è piuttosto divertente da catturare e spesso può intrufolarsi in siti che sono in esecuzione su versioni precedenti di WordPress o altre piattaforme CMS che richiedono aggiornamenti di sicurezza regolari.
Con questo client (una spa di bellezza), ho notato alcuni strani termini di ricerca che appaiono all'interno di Search Console.
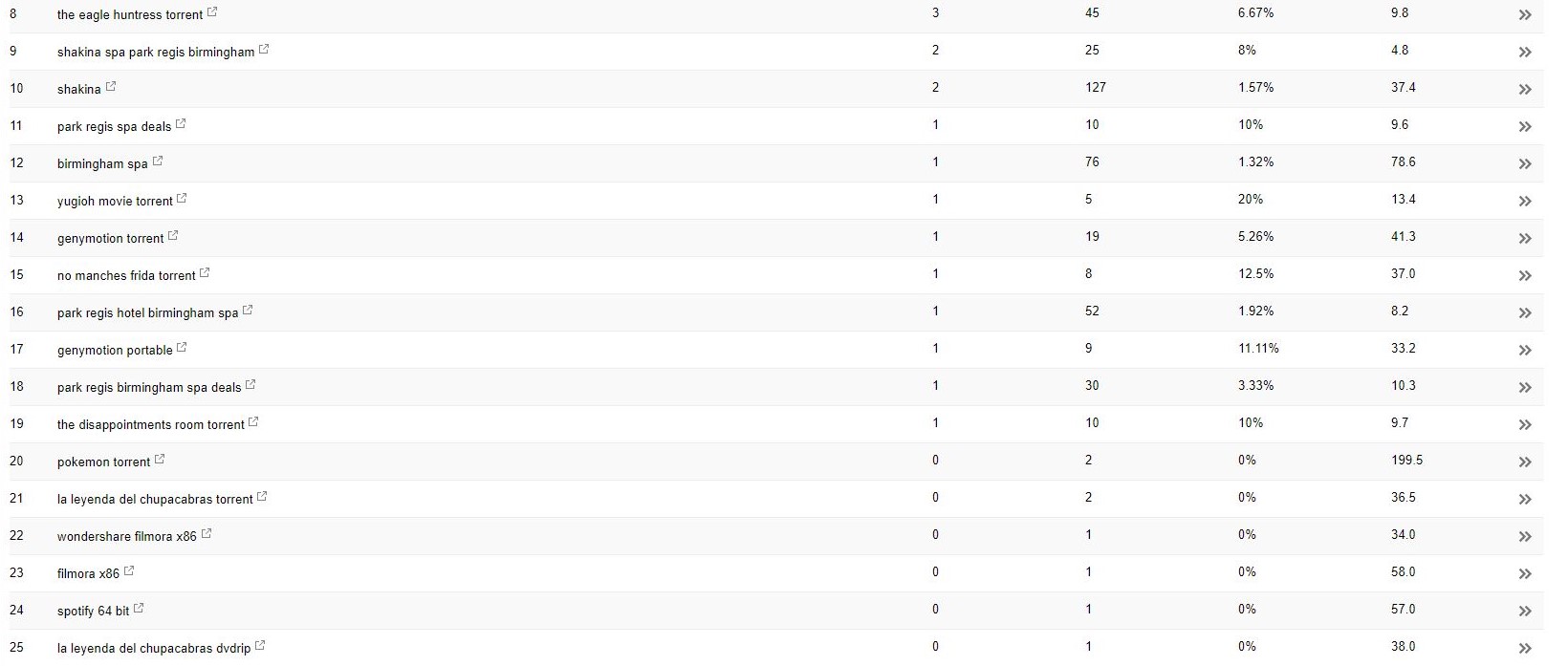
Sorprendentemente non solo hanno avuto impressioni all'interno di Search Console, ma anche clic, il che significa che qualcosa deve essere stato indicizzato sul dominio.
A giudicare dalle domande, era chiaramente molto spam e non qualcosa a cui il cliente avrebbe voluto che la propria attività fosse associata.
Facendo una semplice ricerca "site:domain.com" in Google ha portato alla luce centinaia di pagine di presunti torrent che il client avrebbe ospitato sul proprio sito.
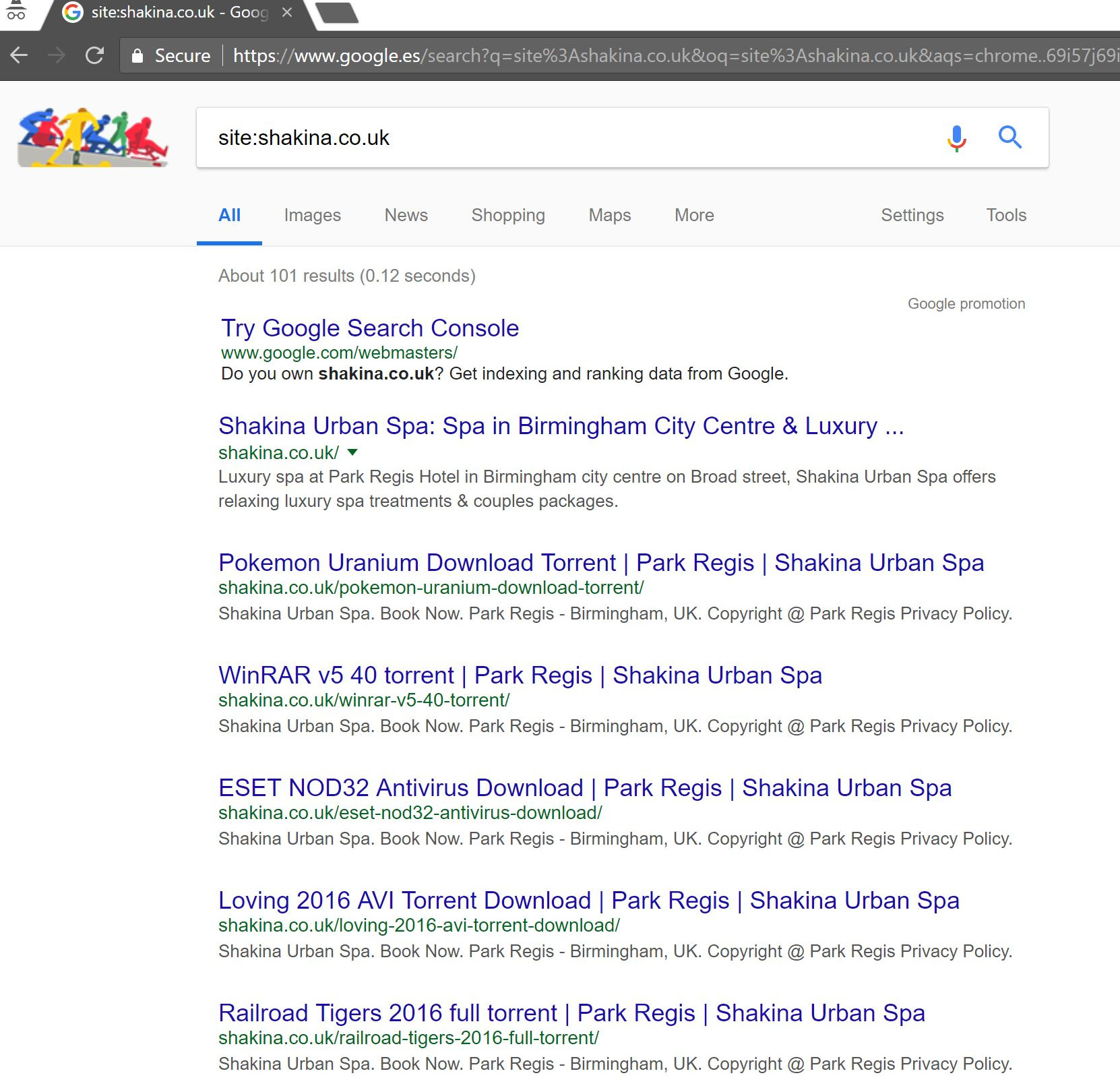
La visita di uno di quegli URL ha effettivamente prodotto un 404, ma erano ancora indicizzati (ho anche controllato vari User Agent e tutti hanno ottenuto lo stesso errore 404).
Successivamente ho eseguito il dominio attraverso il controllo dei backlink di Majestic e ha fornito un lungo elenco di backlink di qualità molto bassa che puntavano a queste pagine sui siti client, il che probabilmente stava aiutando a farli indicizzare.
Osservare l'Anchor Cloud di Majestic dei backlink ha mostrato davvero l'entità del problema.


L'unica soluzione qui è stata rinnegare tutti quei backlink per dominio, quindi eseguire una spazzata pulita dell'installazione di WordPress nella speranza di ripulire eventuali iniezioni di codice o installare una nuova copia di WordPress.
Se sei davvero preoccupato per il contenuto indicizzato in casi come quello sopra, potresti anche servire un codice di stato 410 per chiarire davvero le cose con i crawler di ricerca.
Quanto sopra si adatterebbe a quei siti a cui sono stati notificati avvisi legali a causa di rivendicazioni di copyright da parte dei produttori cinematografici, cosa che a volte può verificarsi in situazioni come questa se il problema non viene risolto rapidamente.
6 – Impostazioni SEO internazionali errate
Essendo residente in Spagna ma navigando in Internet nella mia madrelingua inglese, mi ritroverò spesso reindirizzato automaticamente a una versione spagnola di un sito web.
Anche se capisco la logica (sono residente in Spagna, quindi voglio navigare nel sito in spagnolo), è piuttosto fastidioso dal punto di vista dell'esperienza dell'utente e, se non eseguito correttamente, può anche causare un po' di scompiglio con la tua SEO internazionale.
Siti come Google Ads portano questo a un altro livello, utilizzando Angular JavaScript per generare dinamicamente contenuti in base alla mia posizione, senza nemmeno passare attraverso un reindirizzamento di pagina di alcun tipo e caricando il contenuto direttamente nel DOM.
Il mio metodo preferito di scelta quando sono disponibili più lingue è 302 reindirizzare un utente a una lingua in base alle impostazioni del browser Internet.
Pertanto, se qualcuno ha il tedesco come lingua predefinita in Google Chrome, è probabile che sia a suo agio nel leggere il sito in tedesco indipendentemente dalla sua posizione fisica.
Questo aiuta anche a superare le difficoltà quando qualcuno risiede in una regione in cui si parlano varie lingue, come in Svizzera, dove vengono utilizzati francese, italiano, tedesco e romancio.
È anche fondamentale ai fini dell'usabilità per garantire che ci sia un'opzione per cambiare lingua in base alle tue preferenze, nel caso in cui desiderino cambiare.
In un caso ho lavorato con un hotel con sede a Barcellona, dove uno script di reindirizzamento del linguaggio JavaScript è stato aggiunto a un sito senza considerare l'impatto SEO.
Questo script reindirizzava gli utenti in base all'impostazione della lingua del browser (che di per sé non è male) tramite un reindirizzamento JavaScript lato client.
Purtroppo in questo caso lo script non è stato impostato correttamente a causa di una strana configurazione dei permalink dei siti, e quando combinato con il fatto che il tag lang HTML mancava da tutte le pagine del sito, Googlebot è impazzito...
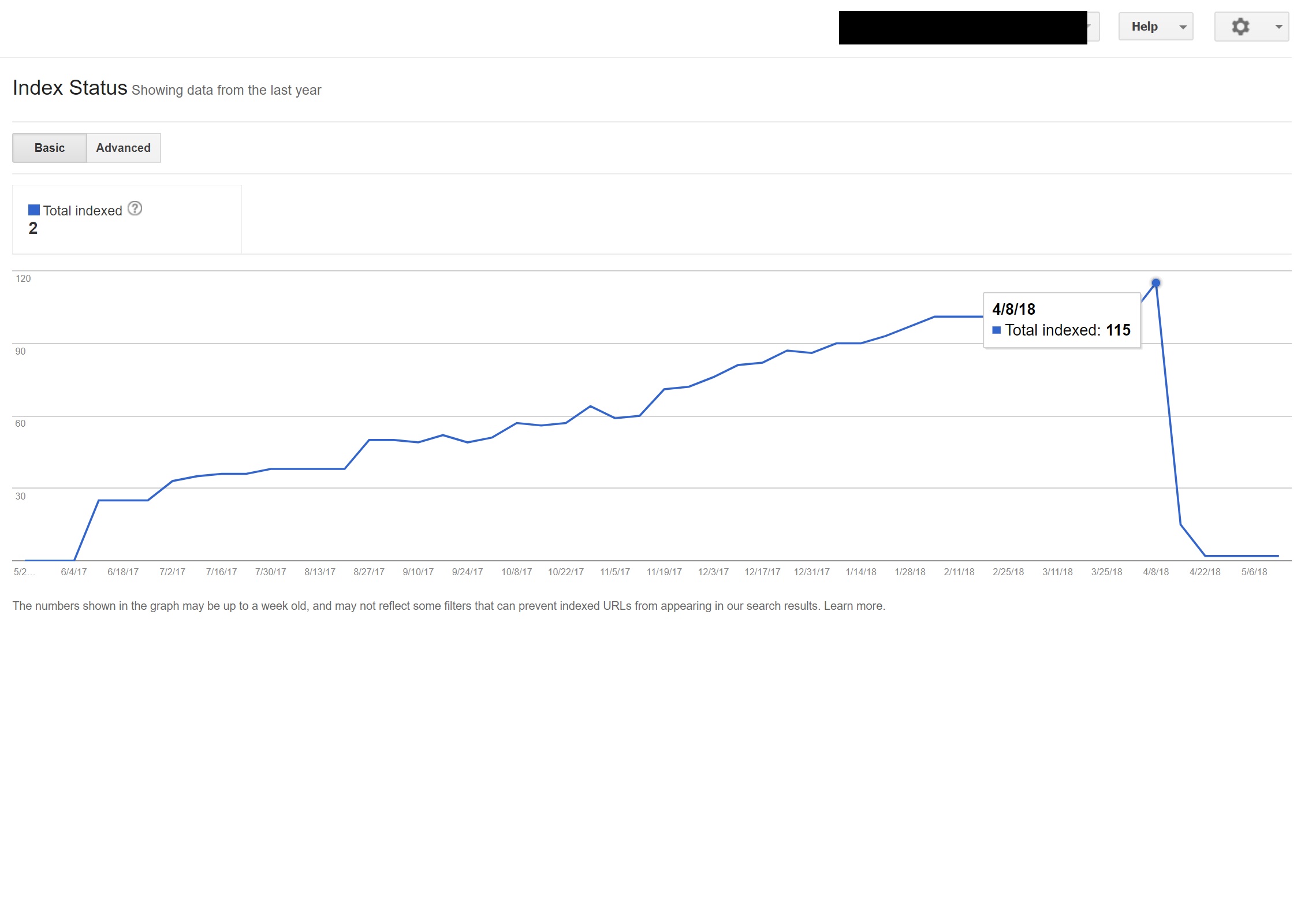
In questo esempio, quasi tutti i contenuti non in inglese sul sito sono stati dei-indicizzati da Google, perché venivano reindirizzati a pagine che non esistevano, fornendo così più errori 404.
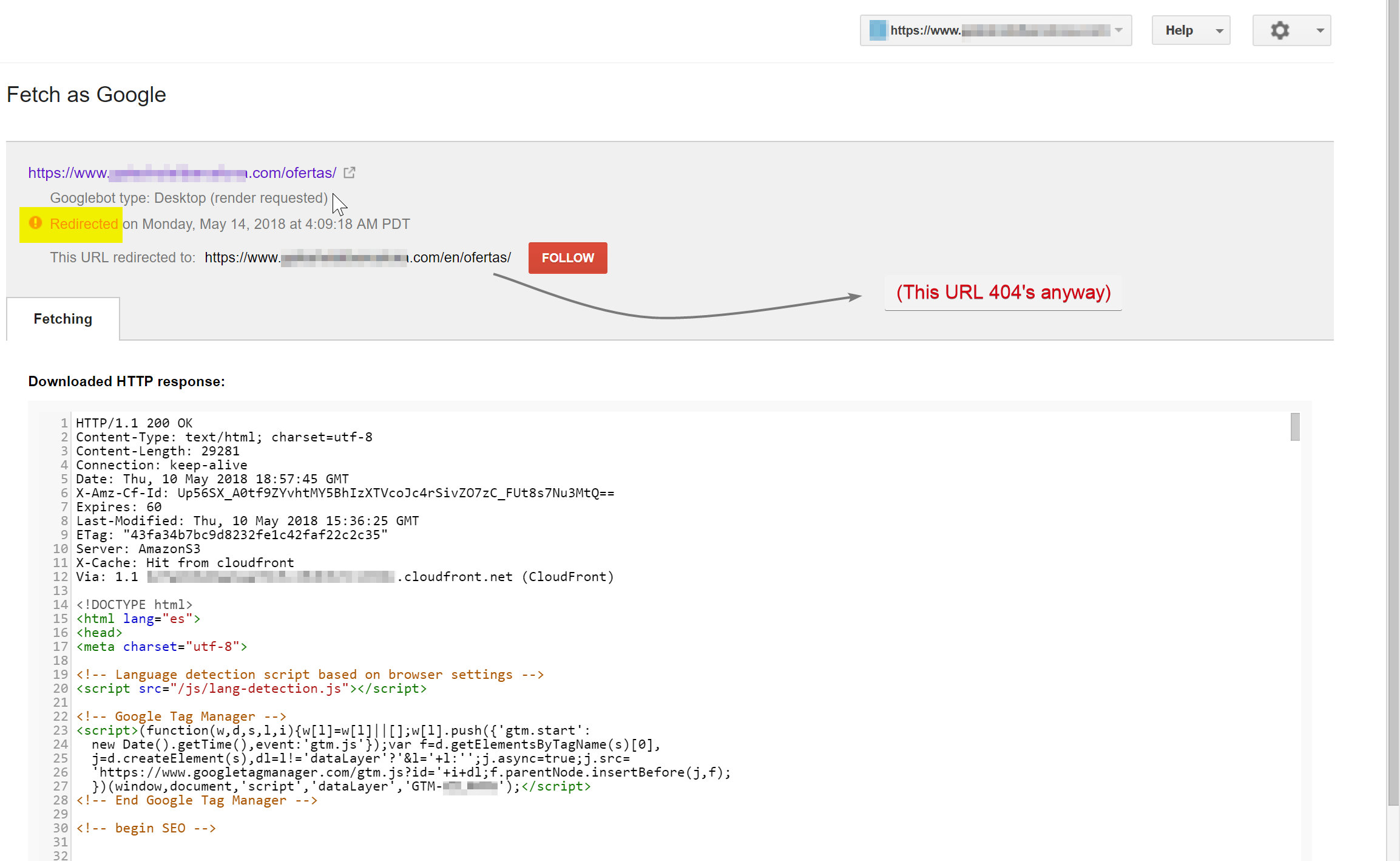
Googlebot stava tentando di eseguire la scansione del contenuto spagnolo (che esisteva su hotelname.com/ofertas) e veniva reindirizzato a hotelname.com/en/ofertas, un URL inesistente.
Sorprendentemente in questo caso Googlebot stava seguendo tutti questi reindirizzamenti JavaScript e, poiché non riusciva a trovare questi URL, è stato costretto a eliminarli dal suo indice.
Nel caso precedente sono stato in grado di confermarlo accedendo ai log del server del sito, filtrando fino a Googlebot e controllando dove veniva servito 404.
La rimozione dello script di reindirizzamento JavaScript difettoso ha risolto il problema e fortunatamente le pagine tradotte non sono state deindicizzate a lungo.
È sempre una buona idea testare le cose a fondo: investire in una VPN può aiutare a diagnosticare questi tipi di scenari o persino a cambiare la tua posizione e/o lingua all'interno del browser Chrome.
[Case Study] Gestione di più audit di siti
 Leggi il caso di studio
Leggi il caso di studio7 – Contenuto duplicato
I contenuti duplicati sono un problema abbastanza comune e ben discusso e ci sono molti modi per verificare la presenza di contenuti duplicati sul tuo sito: Richard Baxter ha recentemente scritto un ottimo pezzo sull'argomento.
Nel mio caso il problema è probabilmente un po' più semplice. Ho visto regolarmente siti che pubblicano ottimi contenuti, spesso come post di blog, ma poi condividono quasi istantaneamente alcuni contenuti su un sito Web di terze parti come Medium.com.
Medium è un ottimo sito per riproporre contenuti esistenti per raggiungere un pubblico più ampio, ma occorre prestare attenzione a come questo viene affrontato.
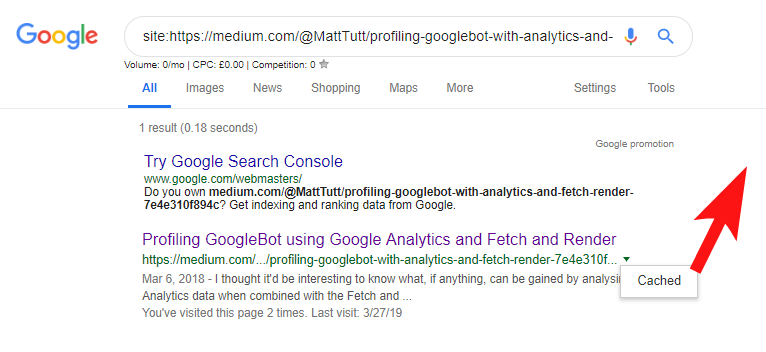
Durante l'importazione di contenuti da WordPress su Medium, durante questo processo Medium utilizzerà l'URL del tuo sito Web come tag canonico. Quindi, in teoria, dovrebbe aiutare a dare al tuo sito Web il merito del contenuto, come fonte originale.
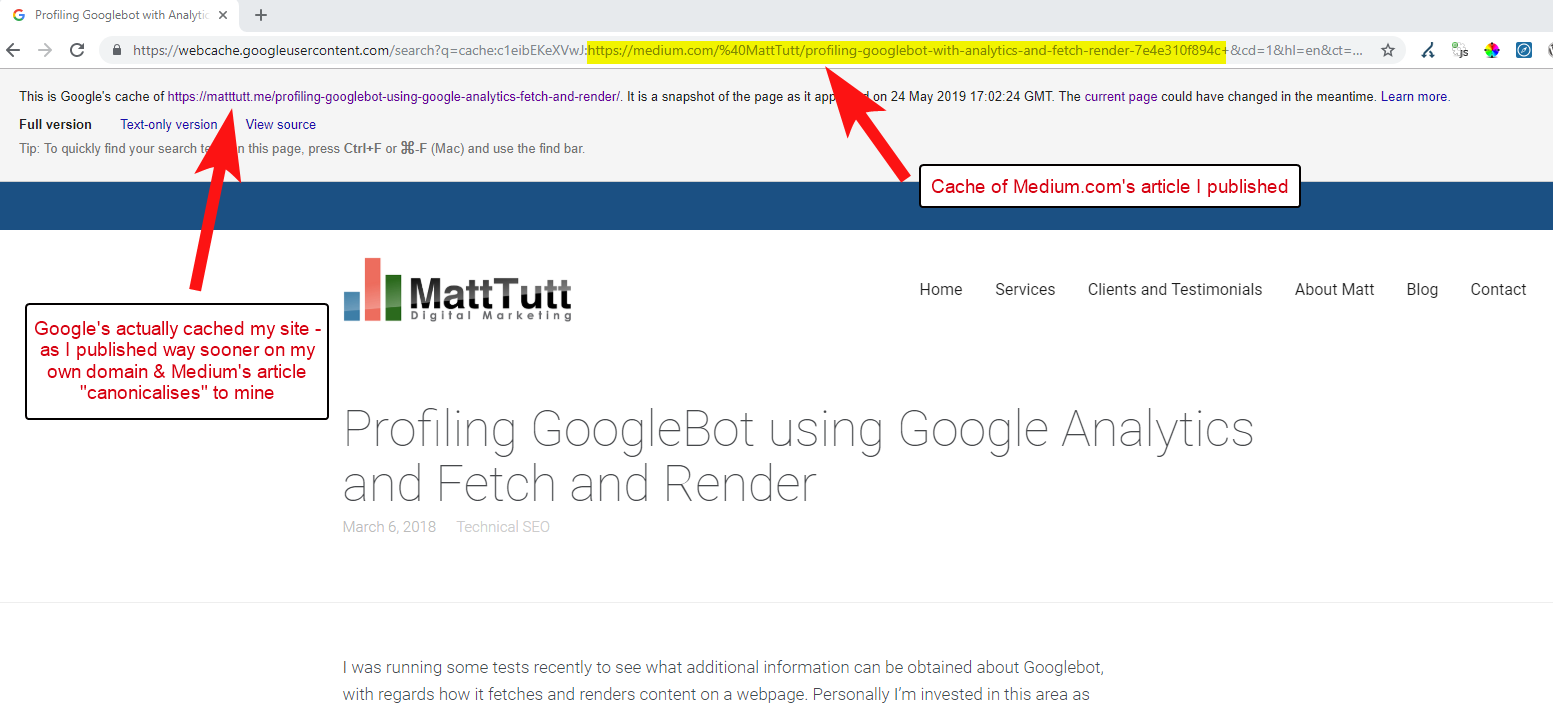
Da alcune delle mie analisi però non funziona sempre in questo modo.
Credo che sia così perché quando un articolo viene pubblicato su Medium senza prima concedere a Google il tempo di eseguire la scansione e l'indicizzazione dell'articolo sul tuo dominio, se l'articolo va bene su Medium (che è un po' incostante) i tuoi contenuti vengono indicizzati e associati al sito di Medium nonostante il loro riferimento canonico al tuo.
Una volta che il contenuto viene aggiunto a Medium (e in particolare se è popolare), puoi praticamente garantire che il pezzo verrà raschiato e ripubblicato sul Web altrove quasi istantaneamente, quindi di nuovo i tuoi contenuti vengono duplicati altrove.
Mentre tutto questo sta succedendo, è probabile che se il tuo dominio è piuttosto piccolo in termini di autorità, Google potrebbe non avere nemmeno la possibilità di eseguire la scansione e l'indicizzazione dei contenuti che hai pubblicato, e potrebbe anche accadere che l'elemento di rendering del scansione/indicizzazione non è stata ancora completata oppure c'è JavaScript pesante che causa un grande ritardo tra la scansione, il rendering e l'indicizzazione di quel contenuto.
Ho visto situazioni in cui una grande azienda pubblica un ottimo articolo, ma poi il giorno successivo lo pubblicano come articolo di riflessione su un enorme blog di notizie del settore. Inoltre, il loro sito ha riscontrato un problema per cui il contenuto è stato duplicato (e indicizzato) su https://domain.com e https://www.domain.com.
Pochi giorni dopo la pubblicazione, durante la ricerca di una frase esatta dell'articolo tra virgolette all'interno di Google, il sito Web dell'azienda non si vedeva da nessuna parte. Invece, l'autorevole blog del settore era al primo posto e altri rieditori stavano assumendo le posizioni successive.
In tal caso, il contenuto è stato associato al blog del settore e quindi tutti i collegamenti guadagnati dal pezzo andranno a beneficio di quel sito Web, non dell'editore originale.
Se intendi riproporre contenuti ovunque sul Web, è probabile che vengano indicizzati, dovresti davvero aspettare fino a quando non sei completamente sicuro che sia stato indicizzato da Google sul tuo dominio.
Probabilmente lavori sodo per creare e creare i tuoi contenuti: non buttarli via essendo troppo desideroso di ripubblicare altrove!
8 – Configurazione AMP errata (dichiarazione URL AMP mancante)
Solo una manciata di clienti che ho assistito ha deciso di provare AMP, forse sulla base di alcuni dei tanti casi di studio finanziati da Google sul suo utilizzo.
A volte non ero nemmeno a conoscenza del fatto che un cliente avesse una versione AMP del proprio sito - c'era del traffico strano che veniva visualizzato nei rapporti sui referral di Analytics - in cui la versione AMP del sito si ricollegava alla versione del sito non AMP.
In tal caso, le versioni della pagina AMP non sono state configurate correttamente poiché non vi era alcun riferimento all'URL dall'intestazione delle pagine non AMP.

Senza dire ai motori di ricerca che una pagina AMP esiste in un determinato URL, non ha molto senso avere una configurazione AMP: il punto è che viene indicizzata e restituita nella SERPS per gli utenti mobili.
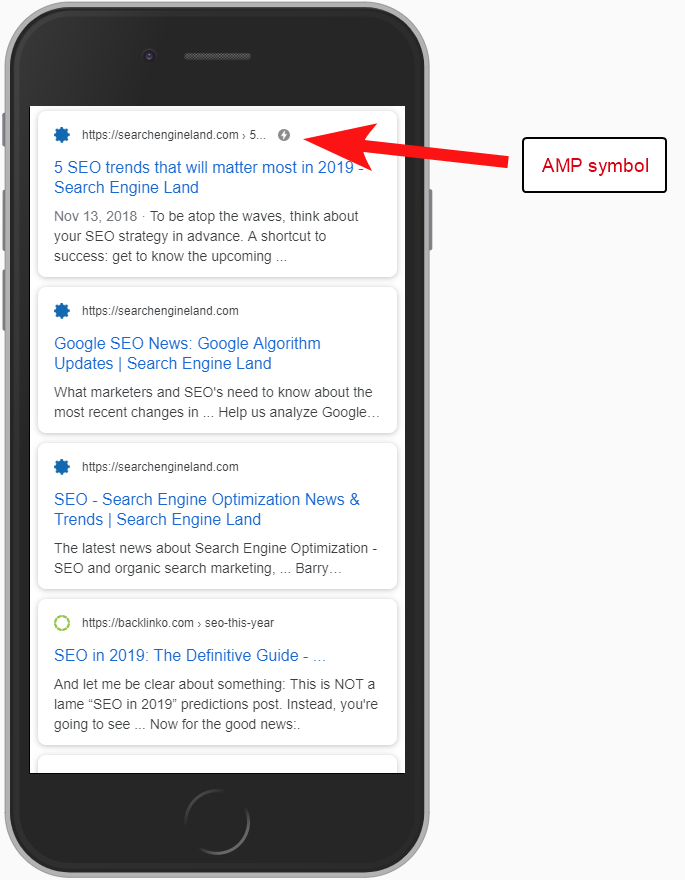
L'aggiunta del riferimento alla tua pagina non AMP è un modo importante per informare Google della pagina AMP ed è importante ricordare che i tag canonici sulle pagine AMP non dovrebbero essere autoreferenziali: si collegano alla pagina non AMP.
E sebbene non sia davvero una considerazione tecnica SEO, vale la pena notare che devi comunque includere il codice di monitoraggio nelle pagine AMP se vuoi essere in grado di segnalare qualsiasi informazione sul traffico e sul comportamento degli utenti.
In genere, come parte dei miei audit SEO, mi piace anche eseguire alcuni controlli di base dell'implementazione dell'analisi, altrimenti i dati che ti sono stati forniti potrebbero non essere poi così utili, specialmente se c'è stata una configurazione di analisi ingombrante.
9 – Domini legacy che reindirizzano 302 o formano una catena di reindirizzamenti
Quando si lavora con un grande marchio alberghiero indipendente negli Stati Uniti, che negli ultimi anni ha subito diversi rebranding (abbastanza comuni nel settore dell'ospitalità), è importante monitorare il comportamento delle precedenti richieste di nomi di dominio.
Questo è facile da dimenticare, ma potrebbe essere un semplice controllo semi-regolare del tentativo di eseguire la scansione del loro vecchio sito utilizzando uno strumento come OnCrawl o anche un sito di terze parti che verifica i codici di stato e i reindirizzamenti.
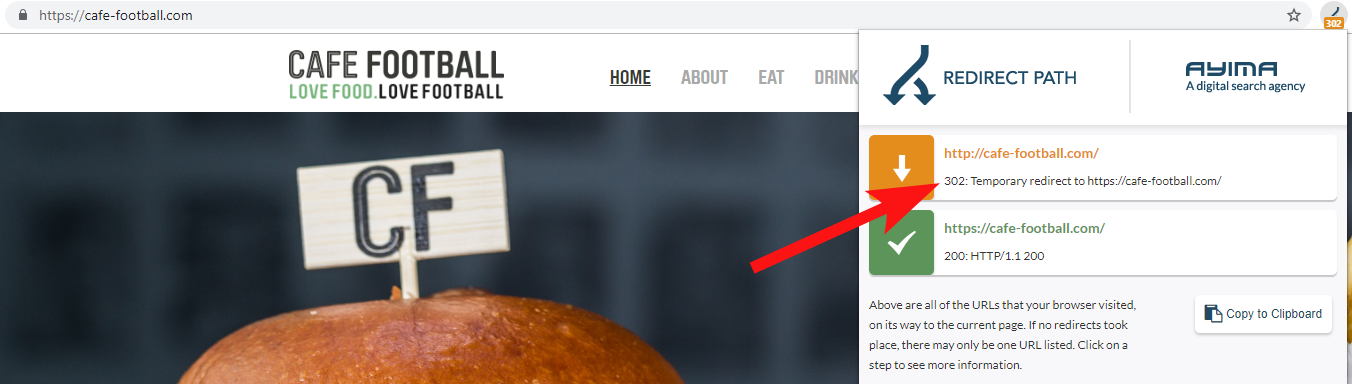
Il più delle volte troverai il dominio 302 reindirizza alla destinazione finale (301 è sempre la soluzione migliore qui) o 302 a una versione non WWW dell'URL prima di saltare attraverso molti altri reindirizzamenti prima di raggiungere l'URL finale.
John Mueller di Google aveva affermato in precedenza che seguono solo 5 reindirizzamenti prima di rinunciare, mentre è anche noto che per ogni reindirizzamento passato parte del valore del collegamento viene perso. Per questi motivi preferisco attenermi a reindirizzamenti 301 il più puliti possibile.
Redirect Path di Ayima è un'ottima estensione del browser Chrome che ti mostrerà gli stati di reindirizzamento mentre navighi sul Web.
Un altro modo in cui ho rilevato vecchi nomi di dominio appartenenti a un cliente è cercare su Google il suo numero di telefono, utilizzando virgolette di corrispondenza esatta o parti del suo indirizzo.
Un'attività come un hotel non cambia spesso indirizzo (almeno parte di esso comunque) e potresti trovare vecchie directory/profili aziendali che si collegano a un vecchio dominio.
L'uso di uno strumento di backlink come Majestic o Ahrefs potrebbe anche mostrare alcuni vecchi collegamenti da domini precedenti, quindi anche questo è un buon punto di riferimento, soprattutto se non sei in contatto diretto con il cliente.
10 – Gestire male i contenuti della ricerca interna
Questo è in realtà un argomento di cui ho già scritto qui su OnCrawl, ma lo includo di nuovo perché vedo ancora contenuti interni problematici che si verificano molto spesso "in natura".
Ho iniziato questo pezzo parlando del problema della direttiva robots.txt di Pingdom che dal mio esterno sembrava essere una soluzione per impedire che il contenuto che stavano emettendo venisse scansionato e indicizzato.
Qualsiasi sito che fornisce risultati di ricerca interni a Google come contenuto o che genera molti contenuti generati dagli utenti, deve prestare molta attenzione al modo in cui lo fa.
Se un sito fornisce risultati di ricerca interni a Google in modo molto diretto, ciò potrebbe comportare una sanzione manuale di qualche tipo. Google probabilmente la considererebbe un'esperienza utente negativa: cercano X, quindi atterrano su un sito in cui devono filtrare manualmente per ciò che vogliono.
In alcuni casi credo che possa andare bene servire contenuti interni, dipende solo dal contesto e dalle circostanze. Un sito di lavoro, ad esempio, potrebbe voler fornire gli ultimi risultati di lavoro che si aggiornano quasi quotidianamente, quindi devono quasi affrontarlo.
Indeed è un famoso esempio di un sito di lavoro che forse si spinge troppo oltre, generando tutti i tipi di contenuti basati su query di ricerca popolari (vedi sotto per cosa può succedere se usi questa tattica).
Nonostante ciò, secondo i dati di SEMRush, il loro traffico organico sta andando alla grande, ma queste sono linee sottili e comportarsi in questo modo ti mette ad alto rischio di una sanzione di Google.
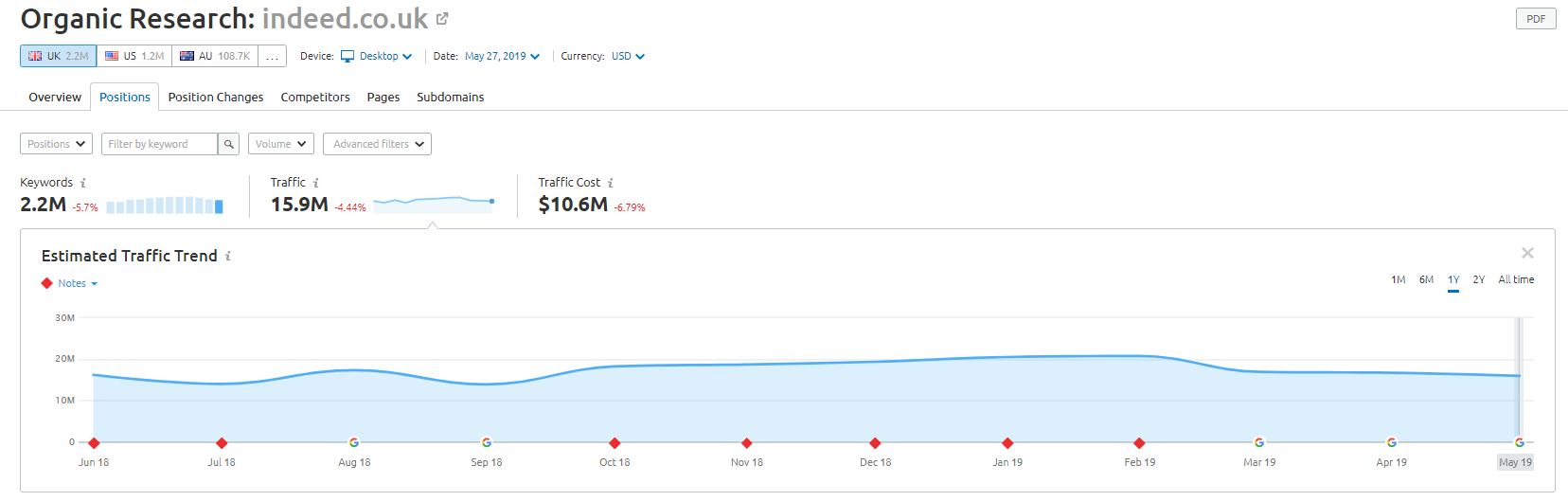
Il rivenditore online Wayfair.com è un altro marchio a cui piace navigare vicino al vento. Con milioni di URL indicizzati (e un sacco di URL di parole chiave generati automaticamente) stanno andando alla grande in termini di traffico organico, ma sono ad alto rischio di essere penalizzati per aver fornito contenuti in questo modo ai motori di ricerca.
Implementando una struttura del sito adeguata che comporti la categorizzazione di tutti i contenuti, la costruzione delle diverse gerarchie padre/figlio e persino l'uso di tag o altre tassonomie personalizzate, è possibile aiutare i clienti e la navigazione del crawler di ricerca.
L'uso di trucchi come quelli sopra potrebbe vincere a breve termine, ma è improbabile che faccia molto per te a lungo termine. Questo rende fondamentale ottenere la struttura del sito fin dall'inizio, o almeno pianificarla adeguatamente in anticipo.
Avvolgendo
I 10 errori discussi in questo articolo sono alcuni dei problemi tecnici più comuni che incontro durante gli audit del sito.
La correzione di questi errori sul tuo sito è un primo passo per assicurarti che il tuo sito sia tecnicamente integro. Una volta corretti questi problemi, gli audit tecnici possono concentrarsi su problemi specifici del tuo sito.