
Scienza dei dati orientata al business
Pubblicato: 2018-12-13Dicono che il Data Scientist sia il lavoro più sexy del 21° secolo (e tutti i Data Scientist che ho incontrato in varie conferenze lo sanno). Ma quando parlano solo della parte teorica dell'apprendimento automatico, a volte mi chiedo se sanno perché il loro lavoro è caldo. Il motivo è che un Data Scientist sa come combinare dati, competenze tecniche e conoscenze statistiche per raggiungere gli obiettivi di business. Quindi, per fare bene la scienza dei dati, devi prima pensare al business.
Conosco casi in cui le aziende hanno aggiunto strumenti analitici per tracciare il tocco di ogni utente senza alcuna considerazione su ciò che effettivamente vogliono ottenere. Hanno raccolto molti dati che non comprendevano e non potevano utilizzare per far avanzare la propria attività.
Non commettere errori del genere! Pensa ai tuoi obiettivi e alle specificità del settore in ogni fase del processo di Data Science. Più sei creativo, maggiori sono le tue possibilità di successo. Per dimostrarlo, ti mostrerò alcuni esempi stimolanti di Data Science nelle applicazioni dei giganti...
Come iniziare la tua avventura nella scienza dei dati
Hai sentito che molte aziende utilizzano il ML per aumentare le proprie entrate, ma non hai idea di come iniziare? Per non ritrovarti con infrastrutture costose e dati inutili (per soddisfare le tue esigenze aziendali), dovresti iniziare fornendo risposte alle seguenti domande:
Quali sono gli obiettivi di business del cliente? Come possiamo utilizzare i dati per raggiungerli?
Quindi puoi iniziare a pianificare quali dati possono essere tracciati e utilizzati.
Raccolta di dati
Quali dati dovremmo raccogliere? La risposta a questa domanda potrebbe davvero sorprenderti. Secondo Todd Yellin (VP of Product Innovation di Netflix), ci sono due tipi di dati che possono essere utilizzati: espliciti e impliciti [1]. Nel caso di Netflix, l'esplicito è quando l'utente valuta letteralmente un film. Implicito, d'altra parte, sono i dati comportamentali, basati sui clic degli utenti e sull'utilizzo dell'app. Quale tipo è più prezioso?
Non esiste una risposta universale a questa domanda, ma nella maggior parte dei casi i dati impliciti sarebbero più utili . E questo perché... le persone mentono.
Considera l'esempio dell'uomo che dice di amare i documentari e che li valuta 5/5. Ma, come mostrano i dati, guarda questo genere una volta all'anno. Allo stesso tempo, guarda le serie popolari ogni venerdì sera. Ed è perché è stanco dopo il lavoro e vuole solo rilassarsi sul divano. Quindi quali dati dovrebbero essere utilizzati per preparare un tale sistema di raccomandazione: valutazione o comportamento dell'utente?
Per rispondere a questa domanda, dobbiamo pensare all'obiettivo aziendale del suo sviluppo. L'obiettivo di Netflix è incoraggiare un utente a guardare più film. Hanno iniziato con il popolare sistema di valutazione a cinque stelle. Quando si sono resi conto che era più probabile che gli utenti menzionati vedessero Friends invece di un film sulla seconda guerra mondiale, hanno sviluppato il sistema di raccomandazione basato sul comportamento degli utenti. Hanno anche abbandonato la valutazione a cinque stelle e l'hanno sostituita con un sistema binario pollice in su e pollice in giù più semplice.
Come mostra questo esempio, i dati raccolti dovrebbero essere selezionati tenendo conto della specificità del settore e dovrebbero fornire informazioni sufficienti per comprendere le decisioni e le esigenze degli utenti. Ma qui incontriamo un altro problema: dati comportamentali, testi e altri dati non strutturati sono più difficili da analizzare e utilizzare nei modelli di Machine Learning rispetto a quelli strutturati. Quindi ora è il momento di parlare di ingegneria delle funzionalità.
Ingegneria delle funzionalità
Per mostrare quanto sia importante l'ingegneria delle funzionalità in Data Science, vorrei citare Andrew Ng, co-fondatore di Google Brain e fondatore di deeplearning.ai:
Trovare funzionalità è difficile, richiede tempo e richiede conoscenze specialistiche. L'apprendimento automatico applicato è fondamentalmente l'ingegneria delle funzionalità. [2].
https://forum.stanford.edu/events/2011/2011slides/plenary/2011plenaryNg.pdf
Un interessante esempio di approccio mirato all'elaborazione dei dati è Booking.com, dove gli utenti possono valutare gli hotel da 0 a 10. Ma se un animale da festa valuta molto l'hotel, è una buona scelta per le famiglie con bambini? Non necessariamente.

Fortunatamente, ci sono anche i commenti degli utenti che contengono più informazioni di cui abbiamo bisogno. Booking.com utilizza l'analisi del sentiment e la modellazione degli argomenti per estrarre i punti di forza e di debolezza dell'hotel commentato e le preferenze degli utenti in merito all'alloggio.
Consideriamo questo esempio:
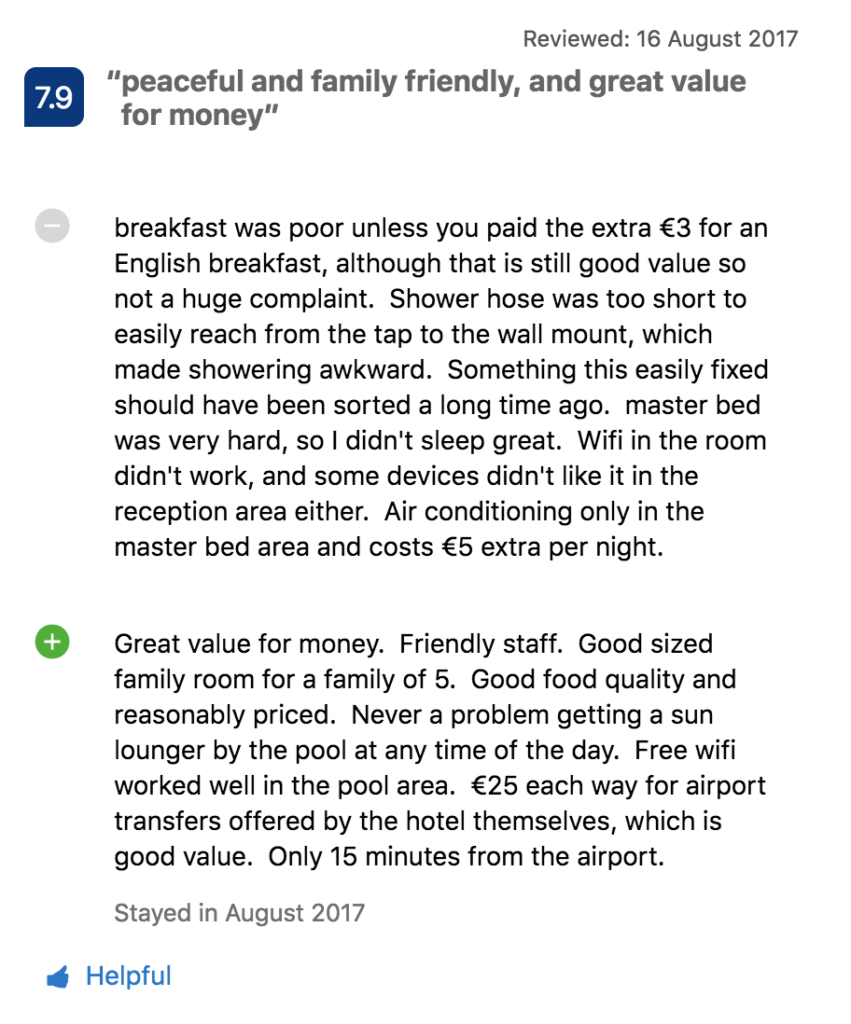
Un argomento Servizi in camera ha un sentimento negativo (l'utente si lamenta di doccia, letto, wifi e aria condizionata). Allo stesso tempo, questo utente elogia il rapporto qualità-prezzo dell'hotel, del personale e del cibo. Il sistema analizza anche ciò che non è stato menzionato nel commento e quindi probabilmente non è importante per l'utente – nel nostro esempio può essere la vita notturna.
Con questi approfondimenti, la piattaforma può offrire hotel più adatti agli utenti con un profilo simile, in questo caso una famiglia con bambini che cerca un posto dove trascorrere le vacanze in un hotel tranquillo a un prezzo ragionevole. Inoltre, Booking.com ordina i commenti per mostrare le informazioni più interessanti per lo spettatore in alto.
Ciò porta a una situazione vantaggiosa per tutti: gli utenti possono trovare offerte su misura per le loro esigenze specifiche in modo più rapido e semplice e la piattaforma realizza un profitto perché queste offerte sono quelle che gli utenti sono più propensi ad acquistare.

Curioso di scienza dei dati?
Scopri di piùProdotto di dati
Hai distribuito il prodotto dati con risultati soddisfacenti? Non è il momento di compiacersi. Come mostra l'esempio di Netflix [3] , il lavoro continuo per migliorare il sistema può portare guadagni significativi. È sufficiente una raccomandazione adeguata per un film? Cosa potremmo fare di più?
Uno degli approcci out-of-the-box di Netflix non è solo quello di consigliare i film, ma anche di illustrarli con un'immagine che sarebbe più attraente per un determinato utente. Diciamo che ti consigliano Good Will Hunting . Se hai visto molte romcom in passato, potresti vedere l'immagine di una coppia che si bacia, mentre se sei un fan della commedia, molto probabilmente otterrai una ripresa di un famoso comico americano:

Con questo approccio, un utente che scorre una miriade di scelte ha molte più probabilità di individuare un film che cattura la sua attenzione.
Questa e altre strategie di raccomandazione hanno risultati sorprendenti: oltre l'80% del contenuto della piattaforma si basa su raccomandazioni algoritmiche . Significa che è difficile per un utente rimanere senza cose da guardare. Quando uno spettacolo è finito, Netflix è lì per suggerire il prossimo.
Nella loro attività ciò offre un vantaggio competitivo perché è molto meno probabile che gli utenti annullino i propri abbonamenti. Questa applicazione di grande successo di Data Science è stata realizzata principalmente grazie alla buona comprensione della loro attività e degli utenti dell'app.
Il riassunto
In una delle conferenze di Data Science di quest'anno, un relatore impegnato nelle previsioni del rischio di credito ha dichiarato:
Quando le persone mi chiedono qual è fondamentalmente il mio lavoro, rispondo: porto i valori aziendali basandomi sui dati.
Per me, questa è una delle migliori definizioni di Data Science. Non dovrebbe essere orientato solo sui suoi fondamenti teorici, ma soprattutto sul business. Se vuoi creare una buona applicazione di Machine Learning, devi pensare a come si comportano gli utenti nel tuo sistema e di cosa hanno bisogno. Con questo in mente, raggiungerai i tuoi obiettivi di business con successo.