
Pipeline di business intelligence basata sui servizi AWS – case study
Pubblicato: 2019-05-16Negli ultimi anni abbiamo assistito a un crescente interesse per l'analisi dei big data. Dirigenti, manager e altri stakeholder aziendali utilizzano Business Intelligence (BI) per prendere decisioni informate. Consente loro di analizzare immediatamente le informazioni critiche e di prendere decisioni basate non solo sulla loro intuizione, ma su ciò che possono imparare dal comportamento reale dei loro clienti.
Quando si decide di creare una soluzione BI efficace e informativa, uno dei primi passi che il team di sviluppo deve compiere è pianificare l'architettura della pipeline di dati. Esistono diversi strumenti basati su cloud che possono essere applicati per creare tale pipeline e non esiste una soluzione che sarebbe la migliore per tutte le aziende. Prima di decidere su una particolare opzione, dovresti considerare il tuo attuale stack tecnologico, i prezzi degli strumenti e le competenze dei tuoi sviluppatori. In questo articolo mostrerò un'architettura creata con gli strumenti AWS che è stata distribuita con successo come parte dell'applicazione Timesheets.
Panoramica dell'architettura
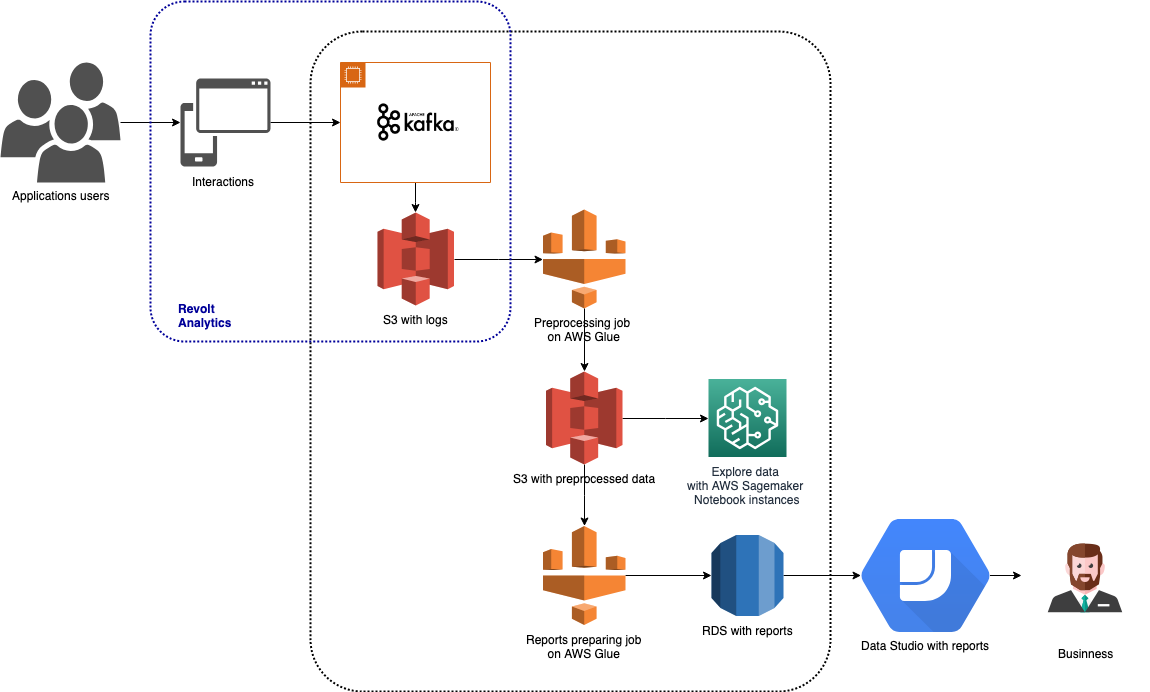
Le schede attività sono uno strumento per tenere traccia e segnalare il tempo dei dipendenti. Può essere utilizzato tramite web, iOS, applicazioni Android e desktop, chatbot integrato con Hangouts e Slack e azione su Google Assistant. Poiché sono disponibili molti tipi di app, ci sono anche molti dati diversi da monitorare. I dati vengono raccolti tramite Revolt Analytics, archiviati in Amazon S3 ed elaborati con AWS Glue e Amazon SageMaker. I risultati dell'analisi vengono archiviati in Amazon RDS e vengono utilizzati per creare report visivi in Google Data Studio. Questa architettura è presentata nel grafico sopra.
Nei paragrafi seguenti descriverò brevemente ciascuno degli strumenti Big Data utilizzati in questa architettura.
Analisi della rivolta
Revolt Analytics è uno strumento sviluppato da Miquido per tracciare e analizzare i dati da applicazioni di ogni tipo. Per semplificare l'implementazione di Revolt nei sistemi client, sono stati creati SDK iOS, Android, JavaScript, Go, Python e Java. Una delle caratteristiche principali di Revolt sono le sue prestazioni: tutti gli eventi vengono accodati, archiviati e inviati in pacchetti, il che garantisce che vengano consegnati in modo rapido ed efficiente. Revolt offre al proprietario dell'applicazione la possibilità di identificare gli utenti e tenere traccia del loro comportamento nell'app. Questo ci consente di creare modelli di Machine Learning che portano valore, come i sistemi di raccomandazione completamente personalizzati e i modelli di previsione dell'abbandono, e per la profilazione dei clienti in base al comportamento degli utenti. Revolt fornisce anche una funzione di sessione. La conoscenza dei percorsi e del comportamento degli utenti nelle applicazioni può aiutarti a comprendere gli obiettivi e le esigenze dei tuoi clienti.
Revolt può essere installato su qualsiasi infrastruttura tu scelga. Questo approccio ti dà il controllo totale sui costi e sugli eventi monitorati. Nel caso Timesheet presentato in questo articolo, è stato costruito sull'infrastruttura AWS. Grazie all'accesso completo all'archiviazione dei dati, i proprietari dei prodotti possono facilmente ottenere informazioni dettagliate sulla loro applicazione e utilizzare tali dati in altri sistemi.
Gli SDK Revolt vengono aggiunti a ogni componente del sistema dei fogli presenze, che consiste in:
- App Android e iOS (create con Flutter)
- App desktop (creata con Electron)
- App Web (scritta in React)
- Backend (scritto in Golang)
- Hangout e chat online Slack
- Azione sull'Assistente Google
Revolt fornisce agli amministratori di Timesheet la conoscenza dei dispositivi (ad es. marca del dispositivo, modello) e sistemi (ad es. versione del sistema operativo, lingua, fuso orario) utilizzati dai clienti dell'app. Inoltre, invia vari eventi personalizzati associati all'attività degli utenti nelle app. Di conseguenza, gli amministratori possono analizzare il comportamento degli utenti e comprendere meglio i loro obiettivi e aspettative. Possono anche verificare l'usabilità delle funzionalità implementate e valutare se queste funzionalità soddisfano le ipotesi del Product Owner su come verrebbero utilizzate.

Colla AWS
AWS Glue è un servizio ETL (estrazione, trasformazione e caricamento) che aiuta a preparare i dati per le attività analitiche. Esegue lavori ETL in un ambiente serverless Apache Spark. Solitamente si compone dei seguenti tre elementi:
- Definizione del crawler : un crawler viene utilizzato per scansionare i dati in tutti i tipi di repository e origini, classificarli, estrarne le informazioni sullo schema e archiviare i relativi metadati nel Catalogo dati. Può, ad esempio, scansionare i log archiviati nei file JSON su Amazon S3 e archiviare le informazioni sullo schema nel Catalogo dati.
- Script di lavoro : i lavori di AWS Glue trasformano i dati nel formato desiderato. AWS Glue può generare automaticamente uno script per caricare, pulire e trasformare i tuoi dati. Puoi anche fornire il tuo script Apache Spark scritto in Python o Scala che eseguirebbe le trasformazioni desiderate. Potrebbero includere attività come la gestione di valori nulli, sessioni, aggregazioni, ecc.
- Trigger : i crawler e i lavori possono essere eseguiti su richiesta o possono essere impostati per l'avvio quando si verifica un trigger specifico. Un trigger può essere una pianificazione basata sul tempo o un evento (ad es. l'esecuzione riuscita di un lavoro specifico). Questa opzione ti dà la possibilità di gestire facilmente l'aggiornamento dei dati nei tuoi rapporti.
Nella nostra architettura Timesheet, questa parte della pipeline si presenta come segue:
- Un trigger basato sul tempo avvia un processo di preelaborazione, che esegue la pulizia dei dati, assegna i registri degli eventi appropriati alle sessioni e calcola le aggregazioni iniziali. I dati risultanti di questo lavoro sono archiviati su AWS S3.
- Il secondo trigger è impostato per essere eseguito dopo l'esecuzione completa e corretta del lavoro di preelaborazione. Questo trigger avvia un lavoro che prepara i dati che vengono utilizzati direttamente nei report analizzati dai Product Owner.
- I risultati del secondo lavoro vengono archiviati in un database AWS RDS. Ciò li rende facilmente accessibili e utilizzabili in strumenti di Business Intelligence come Google Data Studio, PowerBI o Tableau.
AWS SageMaker
Amazon SageMaker fornisce moduli per creare, addestrare e distribuire modelli di machine learning.
Consente l'addestramento e l'ottimizzazione dei modelli su qualsiasi scala e consente l'utilizzo di algoritmi ad alte prestazioni forniti da AWS. Tuttavia, puoi anche utilizzare algoritmi personalizzati dopo aver fornito un'immagine docker adeguata. AWS SageMaker semplifica anche l'ottimizzazione degli iperparametri con lavori configurabili che confrontano i parametri per diversi set di parametri del modello.
In Timesheet, le istanze di SageMaker Notebook ci aiutano a esplorare i dati, testare gli script ETL e preparare prototipi di grafici di visualizzazione da utilizzare in uno strumento BI per la creazione di report. Questa soluzione supporta e migliora la collaborazione dei data scientist in quanto garantisce che lavorino nello stesso ambiente di sviluppo. Inoltre, questo aiuta a garantire che nessun dato sensibile (che può far parte dell'output delle celle dei notebook) venga archiviato oltre l'infrastruttura AWS perché i notebook sono archiviati solo nei bucket AWS S3 e non è necessario alcun repository git per condividere il lavoro tra colleghi .
Incartare
Decidere quali strumenti Big Data e Machine Learning utilizzare è fondamentale nella progettazione di un'architettura di pipeline per una soluzione di Business Intelligence. Questa scelta può avere un impatto sostanziale sulle capacità del sistema, sui costi e sulla facilità di aggiungere nuove funzionalità in futuro. Gli strumenti AWS meritano sicuramente di essere presi in considerazione, ma dovresti selezionare una tecnologia adatta al tuo attuale stack tecnologico e alle competenze del tuo team di sviluppo.
Approfitta della nostra esperienza nella costruzione di soluzioni orientate al futuro e contattaci!