
Breadcrumb SEO, Python 3 e Oncrawl: verso l'automazione!
Pubblicato: 2021-04-14Impariamo come creare automaticamente una segmentazione basata su breadcrumb con OnCrawl e Python 3.
Che cos'è la segmentazione in Oncrawl?
Oncrawl utilizza le segmentazioni per dividere un insieme di pagine in gruppi. Ciò semplifica l'analisi dei dati dai rapporti di scansione, dall'analisi dei log e da altri rapporti di analisi incrociata che combinano i dati di scansione con Google Analytics, Google Search Console, AT Internet, Adobe Analytics o Majestic per i backlink.
Perché è importante creare segmentazioni?
Una volta completata la scansione, la creazione di una segmentazione personalizzata è la cosa più importante da fare. Questo ti permette di leggere le analisi dalla prospettiva che meglio si adatta al tuo sito e alla sua struttura.
Esistono molti modi per segmentare le pagine del tuo sito e non esiste un modo giusto o sbagliato per farlo. Ad esempio, è possibile tracciare la struttura del tuo sito in base alla struttura dell'URL.
Ad esempio, questo tipo di URL " https://www.mydomain.com/news/canada/politics ", potrebbe essere facilmente segmentato in questo modo:
- Un gruppo per isolare la home page
- Un gruppo per tutte le novità
- Un sottogruppo per la directory Canada
- Un sottogruppo per la directory Politica
Come puoi vedere, è possibile creare fino a 3 livelli di profondità per le tue segmentazioni. Ciò ti consente di concentrarti su determinati gruppi o sottogruppi nella tua analisi SEO, senza dover cambiare segmentazione.
Come si crea una segmentazione di base?
Dovresti sapere che Oncrawl si occupa di creare la prima segmentazione, tutto da solo. Questo si basa sul "Primo percorso" o sulla prima directory incontrata negli URL.
Ciò ti consente di avere un'analisi disponibile non appena la scansione è completa.
È possibile che questa segmentazione non rifletta la struttura del tuo sito o che tu voglia analizzare le cose da un'angolazione diversa.
Quindi creerai una nuova segmentazione usando ciò che chiamiamo OQL, che sta per Oncrawl Query Language. È un po' come SQL, solo molto più semplice e intuitivo: 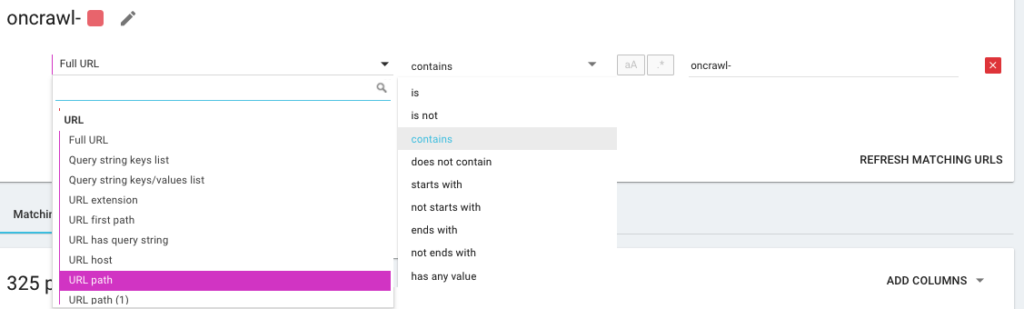
È inoltre possibile utilizzare gli operatori di condizione AND/OR per essere il più precisi possibile: 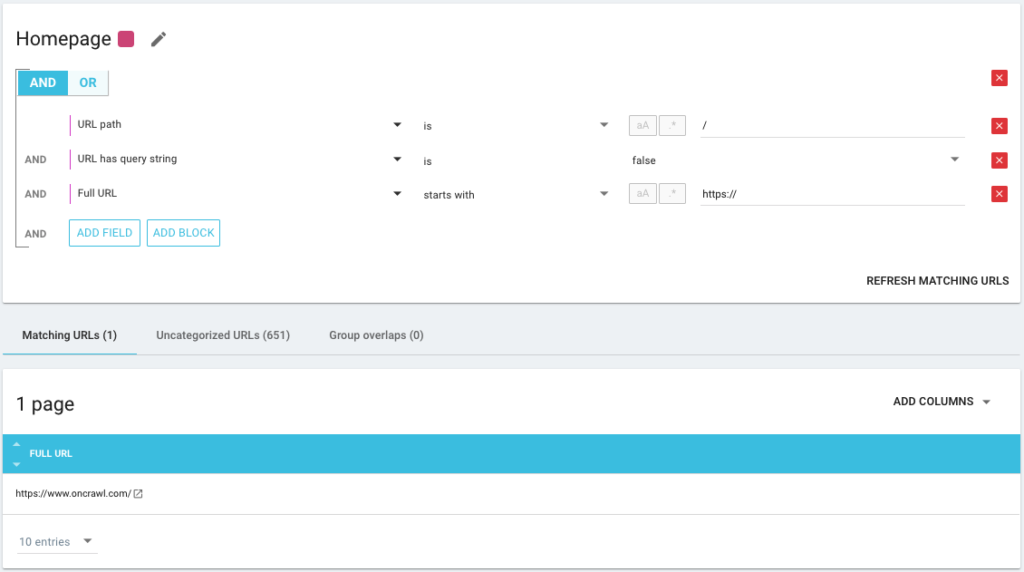
Segmentare le mie pagine usando metodi diversi
Utilizzo di altri KPI
Le segmentazioni basate sugli URL sono buone, ma sarebbe perfetto se potessimo anche combinare altri KPI, come raggruppare gli URL che iniziano con /car-noleggio/ e il cui H1 ha l'espressione " Agenzie di autonoleggio " e un altro gruppo in cui l'H1 sarebbe “ Agenzie di noleggio di utenze ”, è possibile?
Si è possibile! Durante la creazione delle tue segmentazioni, hai a disposizione tutti i KPI che utilizziamo, e non solo quelli del crawler, ma anche quelli dei connettori. Questo rende la creazione di segmentazioni molto potente e ti permette di avere angoli di analisi totalmente diversi!
Ad esempio, adoro creare una segmentazione utilizzando la posizione media degli URL grazie al connettore di Google Search Console.
In questo modo, posso identificare facilmente gli URL in profondità nella mia struttura che stanno ancora funzionando o gli URL vicini alla mia home page che si trovano a pagina 2 di Google.
Posso vedere se queste pagine hanno contenuti duplicati, un tag title vuoto, se ricevono abbastanza link... Posso anche vedere come si comporta il Googlebot su queste pagine. La frequenza di scansione è buona o cattiva? In breve, mi aiuta a stabilire le priorità e prendere decisioni che avranno un impatto reale sulla mia SEO e sul mio ROI.
Scansione dati³
 Scopri di più
Scopri di piùUtilizzo di acquisizione dati
Se non hai familiarità con la nostra funzione di acquisizione dati, ti invito a leggere prima questo articolo sull'argomento. Questo è un altro strumento molto potente che ti consente di aggiungere origini dati esterne a Oncrawl.
Ad esempio, puoi aggiungere dati da SEMrush, Ahrefs, Babbar.tech... Il vantaggio è che puoi raggruppare le tue pagine in base a metriche tratte da questi strumenti ed eseguire le tue analisi in base ai dati che ti interessano, anche se non lo sono nativamente in Oncrawl.
Di recente, ho lavorato con un gruppo alberghiero globale. Usano un metodo di punteggio interno per sapere se i record dell'hotel sono compilati correttamente, se hanno immagini, video, contenuti, ecc. Determinano una percentuale di completamento, che abbiamo utilizzato per analizzare in modo incrociato i dati del file di registro e di scansione.
Il risultato ci consente di sapere se Googlebot trascorre più tempo su pagine correttamente riempite, di sapere se alcune pagine con un punteggio superiore al 90% sono troppo profonde, non ricevono abbastanza link... Ci permette di mostrare che maggiore è il punteggio, più visite ricevono le pagine, più vengono esplorate da Google e migliore è la loro posizione nella SERP di Google. Un argomento inarrestabile per incoraggiare gli albergatori a compilare la loro scheda di hotel!
Crea una segmentazione basata sul percorso SEO breadcrumb
Questo è l'argomento di questo articolo, quindi entriamo nel vivo della questione. A volte è difficile segmentare le pagine del tuo sito, se la struttura degli URL non allega pagine a una determinata directory. Questo è spesso il caso dei siti di e-commerce, in cui le pagine dei prodotti sono tutte alla radice. È quindi impossibile sapere dall'URL a quale gruppo appartiene una pagina.
Per raggruppare le pagine, dobbiamo trovare un modo per identificare il gruppo a cui appartengono. Abbiamo quindi avuto l'idea di recuperare il breadcrumb seo trail di ogni URL e classificarli in base ai valori nel breadcrumb seo, utilizzando la funzione Scraper offerta da Oncrawl.
SEO Breadcrumb Scraping con Oncrawl
Come abbiamo visto sopra, imposteremo una regola di scraping per recuperare la traccia di breadcrumb. Il più delle volte è abbastanza semplice perché possiamo andare a recuperare le informazioni in un div , quindi i campi di ogni livello sono in
liste ul e li : 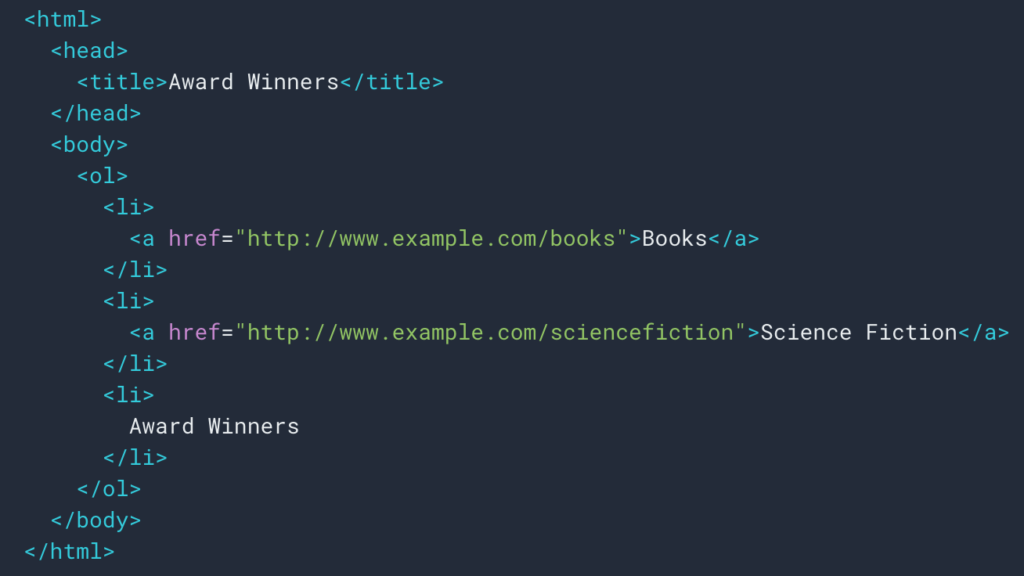
A volte possiamo anche recuperare facilmente le informazioni grazie al tipo di dati strutturati Breadcrumb. Sarà quindi facile recuperare il valore del campo “nome” per ogni posizione. 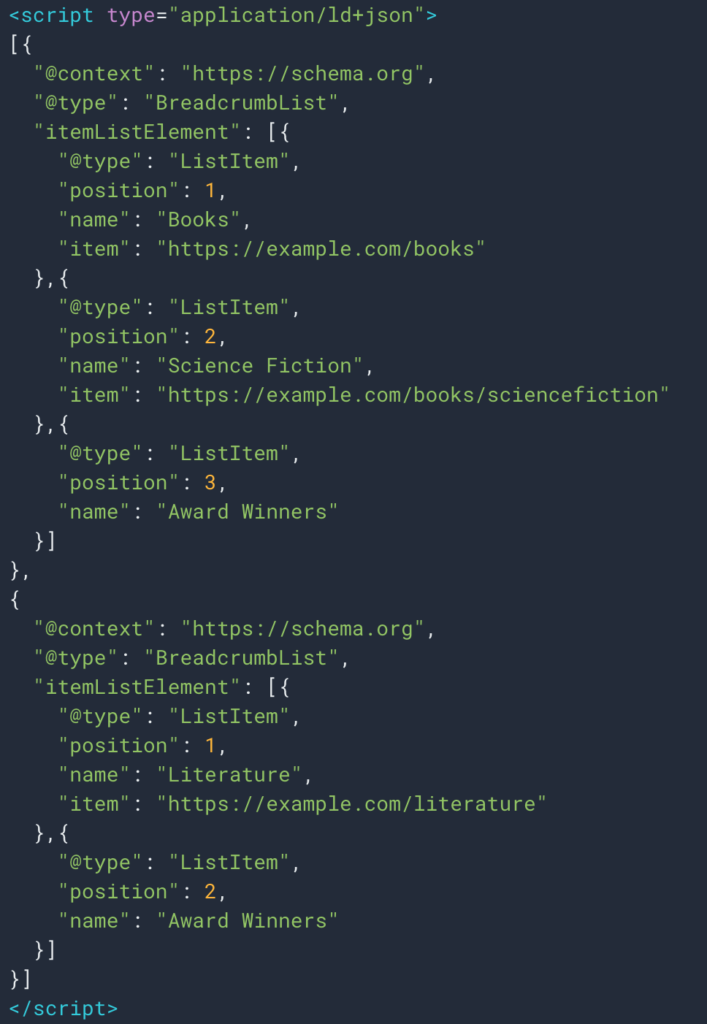
Ecco un esempio di una regola di scraping che utilizzo: 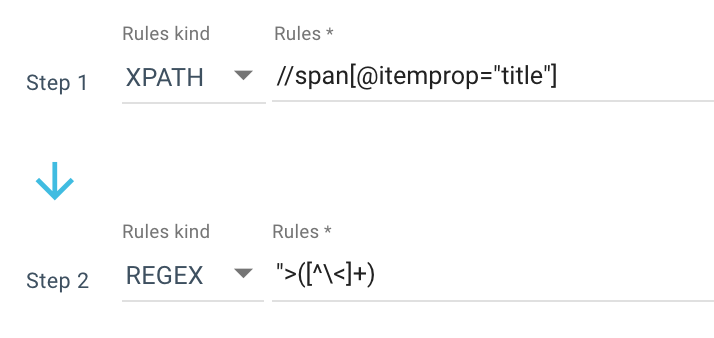
O questa regola: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()

Quindi ottengo tutto lo span itemprop=”title” con Xpath, quindi uso un'espressione regolare per estrarre tutto dopo “> che non è un > carattere. Se vuoi saperne di più su Regex, ti suggerisco di leggere questo articolo sull'argomento e il nostro Cheat sheet su Regex.
Ottengo diversi valori come questo come output: 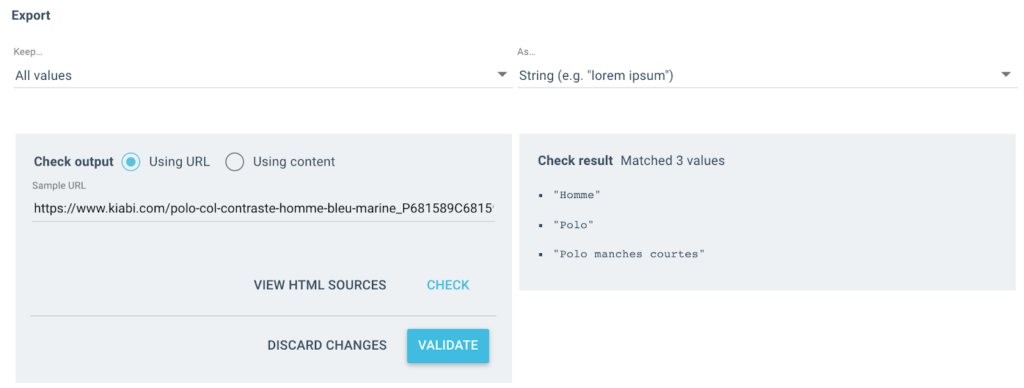
Per l'URL testato, avrò un campo "Breadcrumb" con 3 valori:
- Uomo
- Polo
- Polo manica corta
importa json
importa a caso
richieste di importazione
# Autentico
# In due modi, con x-oncrawl-token puoi ottenere le intestazioni delle richieste dal browser
# o con il token API qui: https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = ' '
# Imposta l'id di scansione dove è presente un campo personalizzato breadcrumb
STRISCIARE_
# Aggiorna gli elementi breadcrumb proibiti che non vuoi inserire nella segmentazione
FORBIDDEN_BREADCRUMB_ITEMS = ('Accueil',)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.striscia()
per v in FORBIDDEN_BREADCRUMB_ITEMS.split(',')
]
def random_color():
random_number = random.randint(0, 16777215)
numero_esadecimale = str(hex(numero_casuale))
numero_esadecimale = numero_esadecimale[2:].ljust(6, '0')
restituisce f'#{hex_number}'
def valore_in_gruppo(valore):
Restituzione {
'colore': random_color(),
'nome': valore,
'oql': {'or': [{'field': ['custom_Breadcrumb', 'equals', value]}]}
}
def walk_dict(dizionario, livello=0):
ret = {
"icon": "cruscotto",
"trasponibile": Falso,
"name": "Breadcrumb"
}Ora che la regola è definita, posso avviare la mia scansione e Oncrawl recupererà automaticamente i valori breadcrumb e li assocerà a ogni URL scansionato.
Automatizza la creazione della segmentazione multilivello con Python
Ora che ho tutti i valori di breadcrumb SEO per ogni URL, utilizzeremo uno script python di automazione seo in Google Colab per creare automaticamente una segmentazione compatibile con Oncrawl.
Per lo script stesso, utilizziamo 3 librerie che sono:
- json (Per generare la nostra segmentazione scritta in Json)
- csv
- casuale (per generare codici colore esadecimali per ciascun gruppo)
Una volta lanciato lo script, si occupa automaticamente di creare la segmentazione nel tuo progetto! 
Anteprima dei dati nelle analisi
Ora che la nostra segmentazione è stata creata, è possibile accedere alle diverse analisi con una vista segmentata basata sul mio percorso breadcrumb. 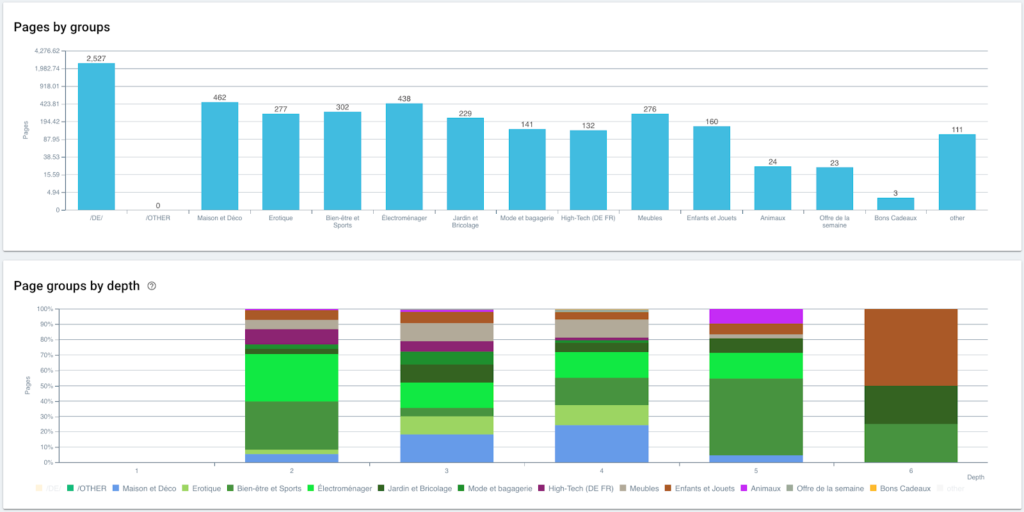
Distribuzione delle pagine per gruppo e per profondità
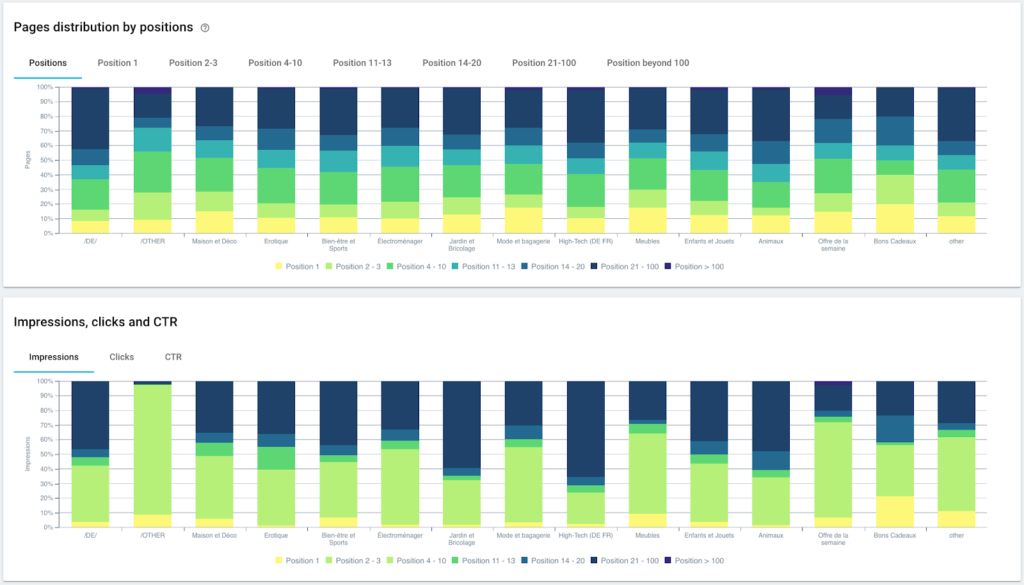
Performance in classifica (GSC)
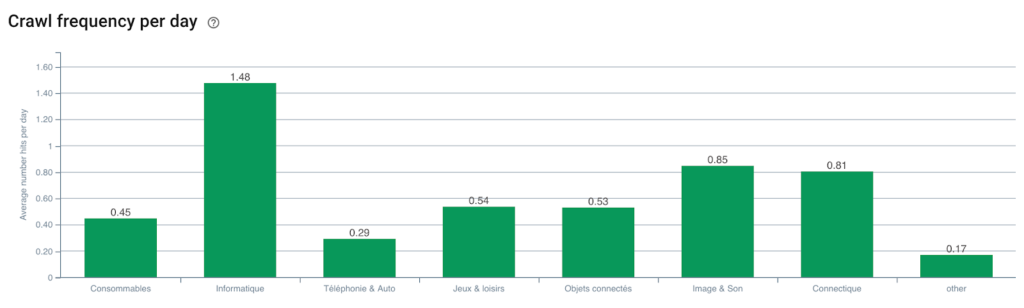
Frequenza di scansione di Googlebot
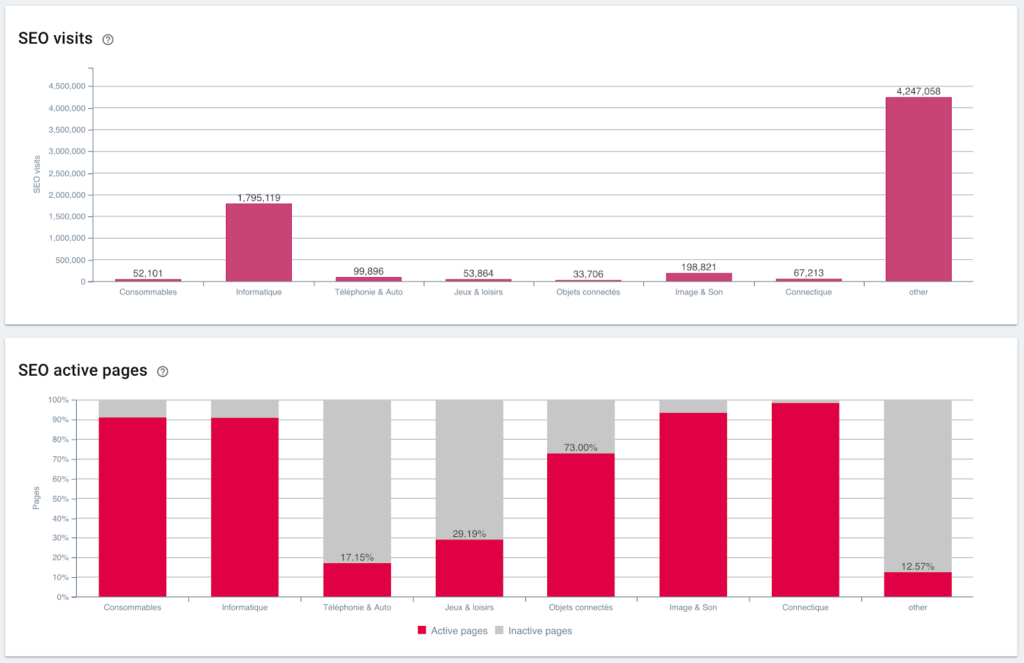
Visite SEO e rapporto pagine attive
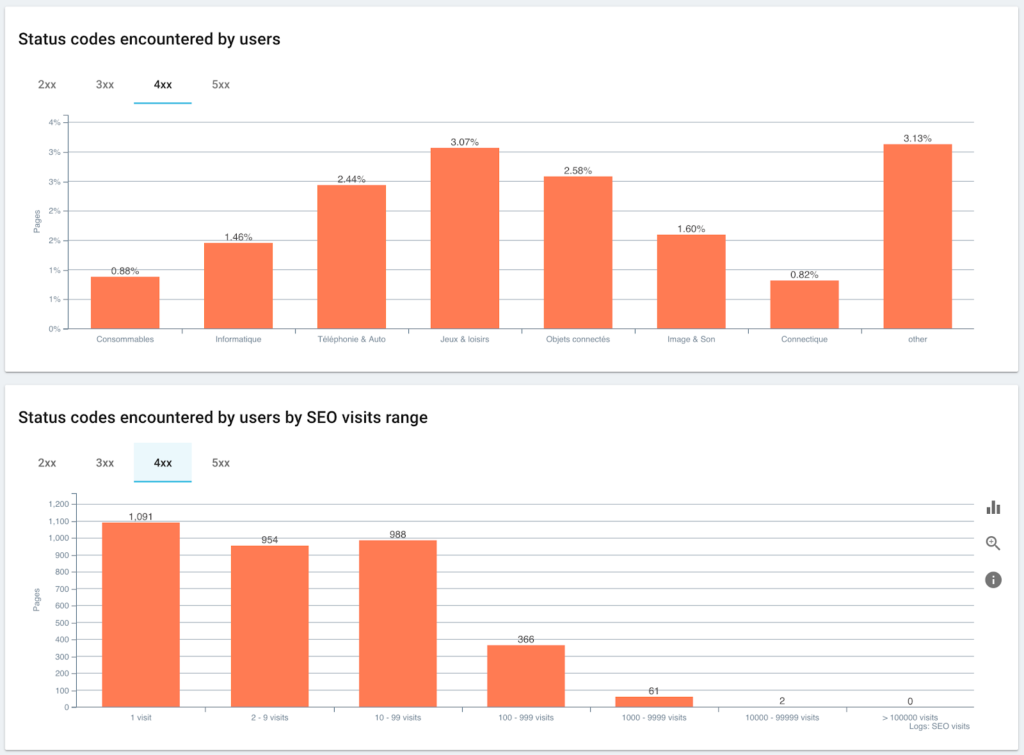
Codici di stato incontrati dagli utenti rispetto alle sessioni SEO
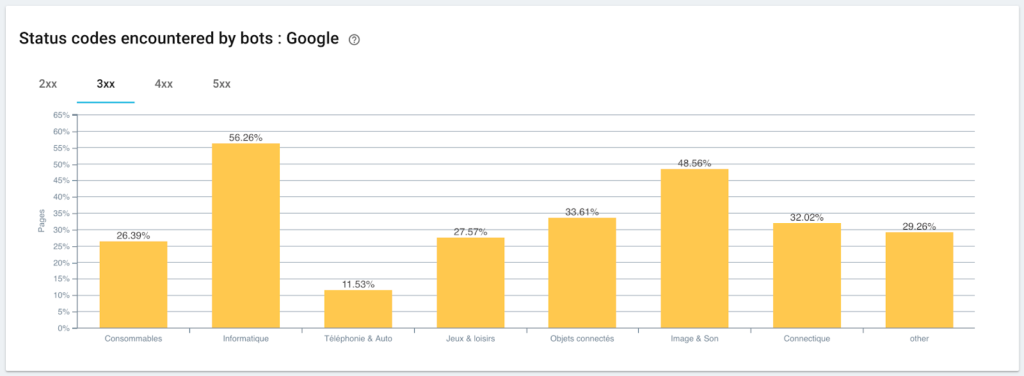
Monitoraggio dei codici di stato rilevati da Googlebot
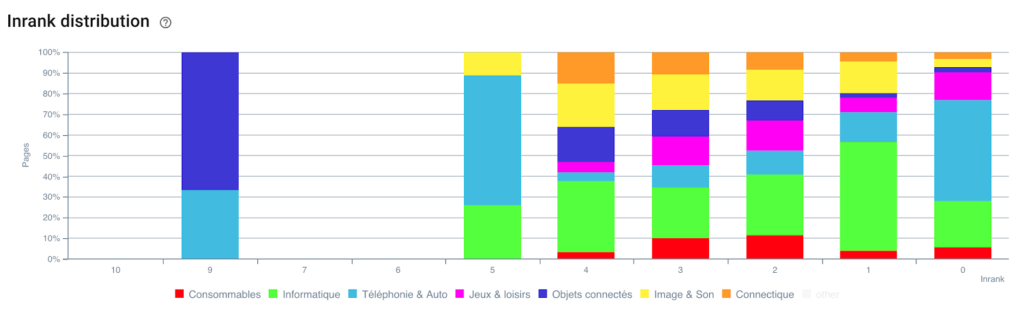
Distribuzione dell'Inrank
Ed eccoci qua, abbiamo appena creato una segmentazione in automatico grazie ad uno script che utilizza Python e OnCrawl. Tutte le pagine sono ora raggruppate in base al percorso breadcrumb e questo su 3 livelli di profondità: 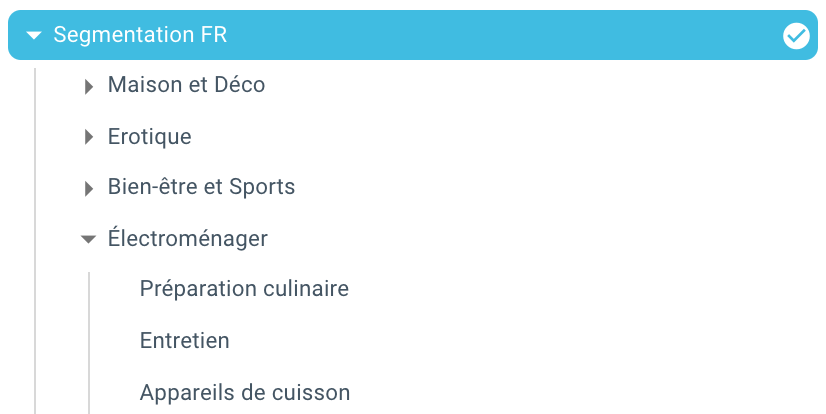
Il vantaggio è che ora possiamo monitorare i diversi KPI (crawl, profondità, link interni, Crawl budget, sessioni SEO, visite SEO, performance di ranking, tempo di caricamento) per ogni gruppo e sottogruppo di pagine.
Il futuro della SEO con Oncrawl
Probabilmente stai pensando che è fantastico avere questa capacità "fuori dagli schemi", ma non hai necessariamente il tempo per fare tutto. La buona notizia è che stiamo lavorando per integrare direttamente questa funzionalità nel prossimo futuro.
Ciò significa che presto sarai in grado di creare automaticamente una segmentazione su qualsiasi campo scartato o campo da Data Ingest con un semplice clic. E questo ti farà risparmiare un sacco di tempo, permettendoti di eseguire incredibili analisi SEO trasversali.
Immagina di poter estrarre qualsiasi dato dal codice sorgente delle tue pagine o integrare qualsiasi KPI per ogni URL. L'unico limite è la tua immaginazione!
Ad esempio, puoi recuperare il prezzo di vendita dei prodotti e vedere la profondità, l'Inrank, i backlink, il crawl budget in base al prezzo.
Ma possiamo anche recuperare i nomi degli autori dei tuoi articoli multimediali e vedere chi si comporta meglio e applicare i metodi di scrittura che funzionano meglio.
Possiamo recuperare le recensioni e le valutazioni dei tuoi prodotti e vedere se i migliori prodotti sono accessibili in un minimo di clic, ricevono link sufficienti, hanno backlink, sono ben scansionati da Googlebot, ecc...
Possiamo integrare i tuoi dati aziendali come fatturato, margine, tasso di conversione, le tue spese di Google Ads.
Ora sta a te immaginare come puoi incrociare i dati per espandere la tua analisi e prendere le giuste decisioni SEO.
Vuoi testare la segmentazione automatica sulla traccia breadcrumb? Contattaci tramite la chatbox direttamente da Oncrawl.
Goditi la tua scansione!