
25 migliori strumenti di scansione Web per un'estrazione efficiente dei dati dai siti Web
Pubblicato: 2023-06-15Un'introduzione agli strumenti di scansione Web
Gli strumenti di scansione Web, noti anche come spider o web scraper, sono essenziali per le aziende che desiderano estrarre dati preziosi dai siti Web per scopi di analisi e data mining. Questi strumenti hanno una vasta gamma di applicazioni, dalle ricerche di mercato all'ottimizzazione dei motori di ricerca (SEO). Raccolgono dati da varie fonti pubbliche e li presentano in un formato strutturato e utilizzabile. Utilizzando gli strumenti di web crawling, le aziende possono tenere traccia di notizie, social media, immagini, articoli, concorrenti e molto altro.
25 migliori strumenti di scansione Web per estrarre rapidamente i dati dai siti Web
Raschiante
Scrapy è un popolare framework di web crawling basato su Python open source che consente agli sviluppatori di creare web crawler scalabili. Offre un set completo di funzionalità che semplificano l'implementazione dei web crawler e l'estrazione dei dati dai siti web. Scrapy è asincrono, il che significa che non effettua richieste una alla volta ma in parallelo, con conseguente scansione efficiente. In quanto strumento di web crawling consolidato, Scrapy è adatto a progetti di web scraping su larga scala.
Caratteristiche principali
- Genera esportazioni di feed in formati come JSON, CSV e XML.
- Ha il supporto integrato per la selezione e l'estrazione di dati da fonti tramite espressioni XPath o CSS.
- Consente di estrarre automaticamente i dati dalle pagine Web utilizzando gli spider.
- È veloce e potente , con un'architettura scalabile e tollerante ai guasti.
- È facilmente estendibile , con un sistema di plug-in e una ricca API.
- È portatile , funziona su Linux, Windows, Mac e BSD.
Prezzi
- È uno strumento gratuito.
ParseHub
ParseHub è uno strumento web crawler in grado di raccogliere dati da siti Web che utilizzano la tecnologia AJAX, JavaScript, cookie e altro. La sua tecnologia di apprendimento automatico può leggere, analizzare e quindi trasformare i documenti web in dati rilevanti. L'applicazione desktop di ParseHub supporta i sistemi operativi Windows, Mac OS X e Linux. Offrendo un'interfaccia user-friendly, ParseHub è progettato per i non programmatori che desiderano estrarre dati dai siti Web.

Caratteristiche principali
- Può eseguire lo scraping di siti Web dinamici che utilizzano AJAX, JavaScript, scorrimento infinito, impaginazione, menu a discesa, accessi e altri elementi.
- È facile da usare e non richiede abilità di programmazione.
- È basato su cloud e può archiviare i dati sui suoi server.
- Supporta la rotazione IP , la raccolta programmata , le espressioni regolari , API e web-hook.
- Può esportare i dati nei formati JSON ed Excel .
Prezzi
- ParseHub ha sia piani gratuiti che a pagamento. I prezzi per i piani a pagamento partono da $ 149 al mese e offrono velocità di progetto aggiornate, un limite più elevato al numero di pagine raschiate per esecuzione e la possibilità di creare più progetti.
Octoparse
Octoparse è uno strumento di scansione Web basato su client che consente agli utenti di estrarre i dati Web in fogli di calcolo senza la necessità di codifica. Con un'interfaccia punta e clicca, Octoparse è creato appositamente per i non programmatori. Gli utenti possono creare i propri web crawler per raccogliere dati da qualsiasi sito Web e Octoparse fornisce scraper predefiniti per siti Web popolari come Amazon, eBay e Twitter. Lo strumento offre anche funzionalità avanzate come l'estrazione pianificata dal cloud, la pulizia dei dati e l'esclusione del blocco con i server proxy IP.
Caratteristiche principali
- Interfaccia point-and-click : puoi selezionare facilmente gli elementi web che desideri raschiare facendo clic su di essi e Octoparse identificherà automaticamente i modelli di dati ed estrarrà i dati per te.
- Modalità avanzata : puoi personalizzare le tue attività di scraping con varie azioni, come inserire testo, fare clic su pulsanti, scorrere pagine, scorrere elenchi, ecc. Puoi anche utilizzare XPath o RegEx per individuare i dati con precisione.
- Servizio cloud : puoi eseguire le tue attività di scraping sui server cloud di Octoparse 24 ore su 24, 7 giorni su 7 e archiviare i tuoi dati nella piattaforma cloud. Puoi anche programmare le tue attività e utilizzare la rotazione automatica dell'IP per evitare di essere bloccato dai siti web.
- API : puoi accedere ai tuoi dati tramite API e integrarli con altre applicazioni o piattaforme. Puoi anche trasformare qualsiasi dato in API personalizzate con Octoparse.
Prezzi
- Ha sia piani gratuiti che a pagamento. I piani a pagamento partono da $ 89 al mese.
WebHarvy
WebHarvy è un software di web scraping punta e clicca progettato per i non programmatori. Può eseguire automaticamente lo scraping di testo, immagini, URL ed e-mail da siti Web e salvarli in vari formati, come XML, CSV, JSON o TSV. WebHarvy supporta anche la scansione anonima e la gestione di siti Web dinamici utilizzando server proxy o servizi VPN per accedere ai siti Web di destinazione.
Caratteristiche principali
- Interfaccia point-and-click per la selezione dei dati senza codifica o scripting
- Estrazione di più pagine con scansione e scraping automatici
- Scraping di categoria per lo scraping di dati da pagine o elenchi simili
- Download di immagini dalle pagine dei dettagli del prodotto dei siti Web di e-commerce
- Rilevamento automatico del modello per lo scraping di elenchi o tabelle senza configurazione aggiuntiva
- Estrazione basata su parole chiave inviando parole chiave di input ai moduli di ricerca
- Espressioni regolari per una maggiore flessibilità e controllo sullo scraping
- Interazione automatizzata del browser per l'esecuzione di attività come fare clic su collegamenti, selezionare opzioni, scorrere e altro
Prezzi
- WebHarvy è un software di web scraping che prevede un canone una tantum.
- Il loro prezzo di licenza parte da $ 139 per un anno.
Bella zuppa
Beautiful Soup è una libreria Python open source utilizzata per l'analisi di documenti HTML e XML. Crea un albero di analisi che semplifica l'estrazione dei dati dal web. Sebbene non sia veloce come Scrapy, Beautiful Soup è principalmente elogiato per la sua facilità d'uso e per il supporto della community in caso di problemi.
Caratteristiche principali
- Analisi : puoi usare Beautiful Soup con vari parser, come html.parser, lxml, html5lib, ecc. per analizzare diversi tipi di documenti web.
- Navigazione : puoi navigare nell'albero di analisi usando metodi e attributi Pythonic, come find(), find_all(), select(), .children, .parent, .next_sibling, ecc.
- Ricerca : puoi cercare nell'albero di analisi utilizzando filtri, come nomi di tag, attributi, testo, selettori CSS, espressioni regolari, ecc. per trovare gli elementi desiderati.
- Modifica : è possibile modificare l'albero di analisi aggiungendo, eliminando, sostituendo o modificando gli elementi ei relativi attributi.
Prezzi
Beautiful Soup è una libreria gratuita e open source che puoi installare usando pip.
Nokogiri
Nokogiri è uno strumento web crawler che semplifica l'analisi di documenti HTML e XML utilizzando Ruby, un linguaggio di programmazione adatto ai principianti nello sviluppo web. Nokogiri si affida a parser nativi come libxml2 di C e xerces di Java, rendendolo un potente strumento per l'estrazione di dati dai siti web. È adatto per gli sviluppatori Web che desiderano lavorare con una libreria di scansione Web basata su Ruby.
Caratteristiche principali
- Parser DOM per XML, HTML4 e HTML5
- Parser SAX per XML e HTML4
- Push Parser per XML e HTML4
- Ricerca documenti tramite XPath 1.0
- Ricerca di documenti tramite selettori CSS3, con alcune estensioni simili a jquery
- Convalida dello schema XSD
- Trasformazione XSLT
- DSL “Builder” per documenti XML e HTML
Prezzi
- Nokogiri è un progetto open source gratuito.
Zyte (precedentemente Scrapinghub)
Zyte (precedentemente Scrapinghub) è uno strumento di estrazione dati basato su cloud che aiuta migliaia di sviluppatori a recuperare dati preziosi dai siti web. Il suo strumento di raschiamento visivo open source consente agli utenti di raschiare siti Web senza alcuna conoscenza di programmazione. Zyte utilizza Crawlera, un proxy rotator intelligente che supporta il bypass delle contromisure dei bot per eseguire facilmente la scansione di siti di grandi dimensioni o protetti da bot e consente agli utenti di eseguire la scansione da più IP e posizioni senza il problema della gestione del proxy tramite una semplice API HTTP.
Caratteristiche principali
- Dati su richiesta: fornisci siti Web e requisiti di dati a Zyte e loro forniscono i dati richiesti secondo il tuo programma.
- Zyte AP I: recupera automaticamente l'HTML dai siti Web utilizzando la configurazione proxy ed estrazione più efficiente, consentendoti di concentrarti sui dati senza problemi tecnici.
- Scrapy Cloud : hosting scalabile per i tuoi spider Scrapy, dotato di un'interfaccia web intuitiva per la gestione, il monitoraggio e il controllo dei tuoi crawler, completo di strumenti di monitoraggio, registrazione e controllo qualità dei dati.
- API di estrazione automatica dei dati : accedi istantaneamente ai dati Web tramite l'API di estrazione basata sull'intelligenza artificiale di Zyte, fornendo rapidamente dati strutturati di qualità. L'onboarding di nuove fonti diventa più semplice con questa tecnologia brevettata.
Prezzi
Zyte ha un modello di prezzo flessibile che dipende dalla complessità e dal volume dei dati di cui hai bisogno. Puoi scegliere tra tre piani:
- Sviluppatore: $ 49 al mese per 250.000 richieste
- Business: $ 299/mese per 2 milioni di richieste
- Enterprise: prezzi personalizzati per oltre 10 milioni di richieste
- Puoi anche provare Zyte gratuitamente con 10.000 richieste al mese.
HTTrack
HTTrack è uno strumento di scansione Web gratuito e open source che consente agli utenti di scaricare interi siti Web o pagine Web specifiche sul proprio dispositivo locale per la navigazione offline. Offre un'interfaccia a riga di comando e può essere utilizzato su sistemi Windows, Linux e Unix.
Caratteristiche principali
- Conserva la relativa struttura di collegamento del sito originale.
- Può aggiornare un sito con mirroring esistente e riprendere i download interrotti.
- È completamente configurabile e dispone di un sistema di guida integrato.
- Supporta varie piattaforme come Windows, Linux, OSX, Android, ecc.
- Ha una versione della riga di comando e una versione dell'interfaccia utente grafica.
Prezzi
- HTTrack è un software libero con licenza GNU GPL.
Apache Nutch
Apache Nutch è un web crawler open source estensibile spesso utilizzato in campi come l'analisi dei dati. Può recuperare contenuti tramite protocolli come HTTPS, HTTP o FTP ed estrarre informazioni testuali da formati di documenti come HTML, PDF, RSS e ATOM.
Caratteristiche principali
- Si basa su strutture dati Apache Hadoop, ottime per l'elaborazione in batch di grandi volumi di dati.
- Ha un'architettura altamente modulare, che consente agli sviluppatori di creare plug-in per l'analisi del tipo di supporto, il recupero dei dati, l'interrogazione e il clustering.
- Supporta varie piattaforme come Windows, Linux, OSX, Android, ecc.
- Ha una versione della riga di comando e una versione dell'interfaccia utente grafica.
- Si integra con Apache Tika per l'analisi, Apache Solr ed Elasticsearch per l'indicizzazione e Apache HBase per l'archiviazione.
Prezzi
- Apache Nutch è un software gratuito concesso in licenza con Apache License 2.0.
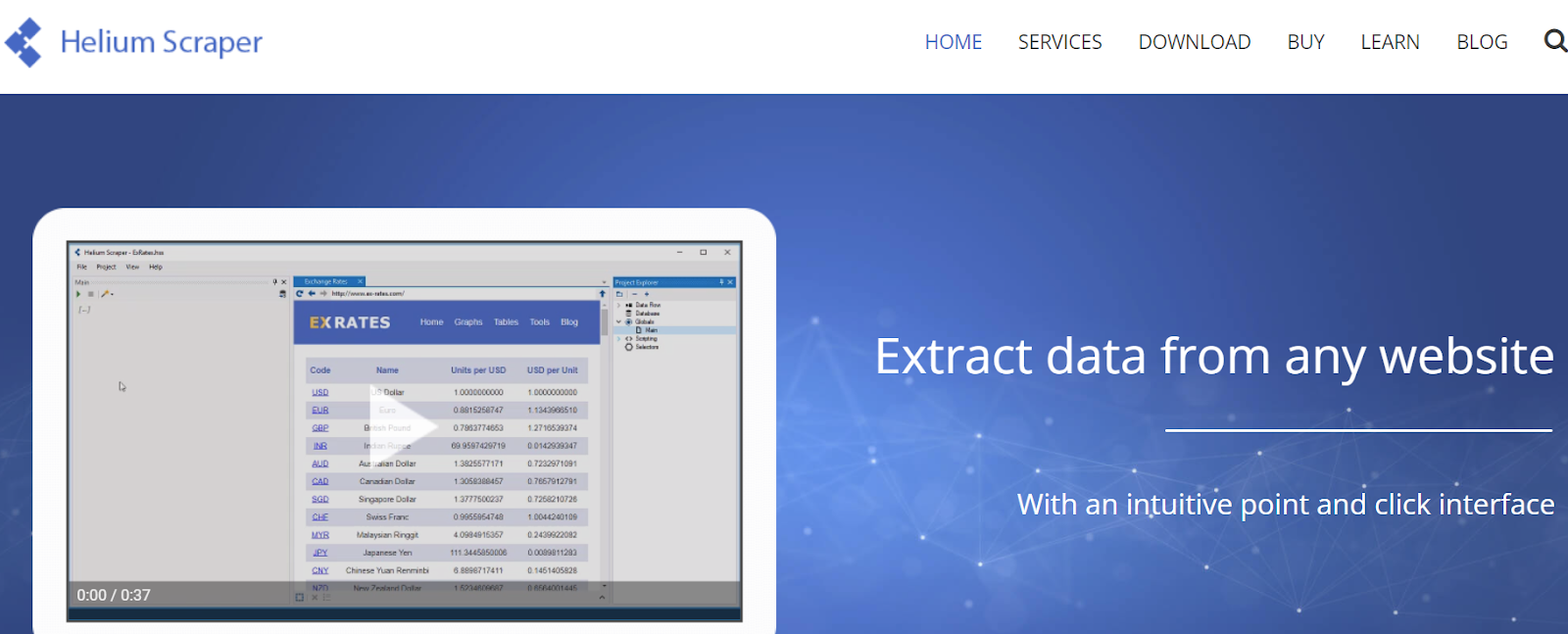
Raschietto per elio
Helium Scraper è uno strumento di scansione dei dati Web visivi che può essere personalizzato e controllato dagli utenti senza la necessità di codifica. Offre funzionalità avanzate come la rotazione proxy, l'estrazione rapida e il supporto per più formati di dati come Excel, CSV, MS Access, MySQL, MSSQL, XML o JSON.
Caratteristiche principali
- Estrazione rapida : delega automaticamente le attività di estrazione a browser separati
- Big Data : il database SQLite può contenere fino a 140 terabyte
- Generazione di database : le relazioni tra tabelle vengono generate in base ai dati estratti
- Generazione SQL : unisci e filtra rapidamente le tabelle per l'esportazione o per i dati di input
- Chiamate API : integra il web scraping e le chiamate API in un unico progetto
- Manipolazione del testo : genera funzioni per abbinare, dividere o sostituire il testo estratto
- Supporto JavaScript: inserisci ed esegui codice JavaScript personalizzato su qualsiasi sito web
- Rotazione proxy : inserisci un elenco di proxy e ruotali a un determinato intervallo
- Rilevamento di elementi simili : rileva elementi simili da uno o due campioni
- Rilevamento elenco : rileva automaticamente elenchi e righe di tabelle sui siti Web
- Esportazione dei dati : esporta i dati in CSV, Excel, XML, JSON o SQLite
- Pianificazione : avviabile dalla riga di comando o dall'Utilità di pianificazione di Windows
Prezzi
- La licenza di base costa $ 99 per utente.
Grabber di contenuti (Sequentum)
Content Grabber è un software di web crawling destinato alle aziende, che consente agli utenti di creare agenti di web crawling autonomi. Offre funzionalità avanzate come l'integrazione con analisi dei dati di terze parti o applicazioni di reportistica, potenti interfacce di editing di script e debug e supporto per l'esportazione di dati in report Excel, XML, CSV e la maggior parte dei database.

Caratteristiche principali
- Interfaccia punta e clicca facile da usare : rileva automaticamente le azioni in base agli elementi HTML
- API robusta : supporta una facile integrazione drag-and-drop con le pipeline di dati esistenti
- Personalizzazione : personalizza i tuoi agenti di scraping con linguaggi di codifica comuni come Python, C#, JavaScript, espressioni regolari
- Integrazione : integra AI, ML, librerie NLP o API di terze parti per l'arricchimento dei dati
- Affidabilità e scalabilità : Mantieni bassi i costi dell'infrastruttura mentre ti godi il monitoraggio in tempo reale delle operazioni end-to-end
- Conformità legale : ridurre la responsabilità e mitigare il rischio associato a costose azioni legali e sanzioni normative
- Esportazione dei dati : esporta i dati in qualsiasi formato e inviali a qualsiasi endpoint
- Pianificazione : avvia i tuoi agenti di scraping dalla riga di comando o dall'Utilità di pianificazione di Windows
Prezzi
- La licenza di base costa $ 27.500 all'anno e ti consente di utilizzare il software su un computer.
Cyotek Web Copy
Cyotek WebCopy è un crawler di siti Web gratuito che consente agli utenti di copiare siti Web parziali o completi localmente nel proprio disco rigido per riferimento offline. Può rilevare e seguire i collegamenti all'interno di un sito Web e rimappare automaticamente i collegamenti in modo che corrispondano al percorso locale. Tuttavia, WebCopy non include un DOM virtuale o alcuna forma di analisi JavaScript, quindi potrebbe non gestire correttamente i layout di siti Web dinamici a causa dell'uso intenso di JavaScript.
Caratteristiche principali
- Interfaccia point-and-click facile da usare con rilevamento automatico delle azioni basato su elementi HTML
- API robusta per una perfetta integrazione con le pipeline di dati esistenti tramite una semplice funzionalità di trascinamento della selezione
- Opzioni di personalizzazione che utilizzano linguaggi di codifica popolari come Python, C#, JavaScript ed espressioni regolari per personalizzare gli agenti di scraping in base a esigenze specifiche
- Funzionalità di integrazione con AI di terze parti, ML, librerie NLP o API per arricchire i dati raccolti
- Infrastruttura affidabile e scalabile con monitoraggio in tempo reale per operazioni convenienti
- Funzionalità di conformità legale per ridurre la responsabilità e mitigare il rischio di azioni legali e sanzioni normative
- Esportazione dei dati in qualsiasi formato desiderato e consegna a vari endpoint
- Le opzioni di pianificazione consentono di avviare agenti di scraping dalla riga di comando o dall'Utilità di pianificazione di Windows
Prezzi
- La licenza di base costa $ 27.500 all'anno e ti consente di utilizzare il software su un computer.
80 gambe
80legs è un potente strumento di web crawling che può essere configurato in base a requisiti personalizzati. Supporta il recupero di grandi quantità di dati insieme alla possibilità di scaricare istantaneamente i dati estratti. Lo strumento offre agli utenti un'API per creare crawler, gestire dati e altro ancora. Alcune delle sue caratteristiche principali includono la personalizzazione dello scraper, i server IP per le richieste di web scraping e un framework di app basato su JS per la configurazione di web crawling con comportamenti personalizzati.

Caratteristiche principali
- Scalabile e veloce : puoi scansionare fino a 2 miliardi di pagine al giorno con oltre 50.000 richieste simultanee.
- Flessibile e personalizzabile: puoi utilizzare il tuo codice per controllare la logica di scansione e l'estrazione dei dati oppure utilizzare gli strumenti e i modelli integrati.
Prezzi
- Puoi scegliere tra diversi piani tariffari in base alle tue esigenze, a partire da $ 29/mese per 100.000 URL/crawl a $ 299/mese per 10 milioni di URL/crawl.
Webhose.io
Webhose.io consente agli utenti di ottenere dati in tempo reale eseguendo la scansione di fonti online da tutto il mondo e presentandoli in vari formati puliti. Questo strumento web crawler può eseguire la scansione dei dati ed estrarre ulteriormente le parole chiave in diverse lingue utilizzando più filtri che coprono un'ampia gamma di fonti. Gli utenti possono salvare i dati raschiati nei formati XML, JSON e RSS e accedere ai dati della cronologia dal suo archivio. Webhose.io supporta fino a 80 lingue con i suoi risultati di scansione dei dati, consentendo agli utenti di indicizzare e cercare facilmente i dati strutturati scansionati dallo strumento.

Caratteristiche principali
- Formati multipli : puoi ottenere dati nei formati XML, JSON, RSS o Excel.
- Risultati strutturati : puoi ottenere dati normalizzati, arricchiti e classificati in base alle tue esigenze.
- Dati storici : è possibile accedere ai dati archiviati degli ultimi 12 mesi o più.
- Ampia copertura : puoi ottenere dati da oltre un milione di fonti in 80 lingue e 240 paesi.
- Varietà di fonti : puoi ottenere dati da siti di notizie, blog, forum, bacheche, commenti, recensioni e altro ancora.
- Integrazione rapida : puoi integrare Webhose.io con i tuoi sistemi in pochi minuti con una semplice API REST.
Prezzi
- Ha un piano gratuito che ti permette di effettuare 1000 richieste al mese senza alcun costo. Ha anche piani personalizzati che puoi contattare per un preventivo.
Mozenda
Mozenda è un software di web scraping basato su cloud che consente agli utenti di estrarre dati web senza scrivere una sola riga di codice. Automatizza il processo di estrazione dei dati e offre funzionalità come l'estrazione dei dati pianificata, la pulizia dei dati e l'esclusione del blocco con i server proxy IP. Mozenda è progettato per le aziende, con un'interfaccia user-friendly e potenti funzionalità di scraping.
Caratteristiche principali
- Analisi del testo: puoi estrarre e analizzare i dati di testo da qualsiasi sito Web utilizzando tecniche di elaborazione del linguaggio naturale.
- Estrazione di immagini: è possibile scaricare e salvare immagini da pagine Web o estrarre metadati dell'immagine come dimensioni, formato, risoluzione, ecc.
- Raccolta di dati disparati: puoi raccogliere dati da più fonti e formati come HTML, XML, JSON, RSS, ecc.
- Estrazione di documenti: è possibile estrarre dati da PDF, Word, Excel e altri tipi di documenti utilizzando il riconoscimento ottico dei caratteri (OCR) o metodi di estrazione del testo.
- Estrazione dell'indirizzo e-mail : puoi trovare ed estrarre indirizzi e-mail da pagine Web o documenti utilizzando espressioni regolari o modelli di corrispondenza.
Prezzi
- Il piano a pagamento parte da $ 99 al mese.
UiPath
UiPath è un software di automazione dei processi robotici (RPA) per il web scraping gratuito. Automatizza la scansione dei dati Web e desktop dalla maggior parte delle app di terze parti. Compatibile con Windows, UiPath può estrarre dati tabulari e basati su pattern su più pagine Web. Il software offre anche strumenti integrati per ulteriori scansioni e gestione di interfacce utente complesse.

Caratteristiche principali
- Analisi del testo : estrai e analizza i dati del testo utilizzando l'elaborazione del linguaggio naturale, le espressioni regolari e la corrispondenza dei modelli per attività come l'estrazione dell'indirizzo e-mail.
- Estrazione di immagini : scarica e salva immagini da pagine Web, estrai i metadati dell'immagine tra cui dimensioni, formato e risoluzione.
- Raccolta di dati disparati : raccogli dati da varie fonti e formati come HTML, XML, JSON, RSS, con funzionalità di integrazione per la connessione ad altri servizi online e API.
- Estrazione di documenti : estrai dati da PDF, Word, Excel e altri tipi di documenti utilizzando OCR o metodi di estrazione del testo. Elabora ed estrai informazioni da diversi tipi e strutture di documenti con funzionalità di comprensione dei documenti.
- Automazione Web : automatizza le attività basate sul Web come l'accesso, la navigazione tra le pagine, la compilazione di moduli, il clic sui pulsanti. Utilizza la funzione di registrazione per acquisire azioni e generare script di automazione.
Prezzi
- Il pagato il piano parte da $ 420 al mese.
OutWit Hub
OutWit Hub è un componente aggiuntivo di Firefox con dozzine di funzionalità di estrazione dei dati per semplificare le ricerche web degli utenti. Questo strumento web crawler può navigare tra le pagine e memorizzare le informazioni estratte in un formato appropriato. OutWit Hub offre un'unica interfaccia per lo scraping di piccole o enormi quantità di dati per necessità e può creare agenti automatici per estrarre dati da vari siti Web in pochi minuti.
Caratteristiche principali
- Visualizzare ed esportare contenuti Web: è possibile visualizzare collegamenti, documenti, immagini, contatti, tabelle di dati, feed RSS, indirizzi e-mail e altri elementi contenuti in una pagina Web. Puoi anche esportarli in HTML, SQL, CSV, XML, JSON o altri formati.
- Organizza i dati in tabelle ed elenchi: puoi ordinare, filtrare, raggruppare e modificare i dati raccolti in tabelle ed elenchi. Puoi anche utilizzare più criteri per selezionare i dati che desideri estrarre.
- Imposta funzioni automatizzate : puoi utilizzare la funzione scraper per creare scraper personalizzati in grado di estrarre dati da qualsiasi sito Web utilizzando comandi semplici o avanzati. Puoi anche utilizzare la funzione macro per automatizzare la navigazione web e le attività di scraping.
- Genera query e URL: puoi utilizzare la funzione di query per generare query basate su parole chiave o pattern. Puoi anche utilizzare la funzione URL per generare URL in base a pattern o parametri.
Prezzi
- La licenza Light è gratuita e completamente operativa, ma non include le funzionalità di automazione e limita l'estrazione a una o poche centinaia di righe, a seconda dell'estrattore.
- La licenza Pro costa $ 110 all'anno e include tutte le funzionalità della licenza Light più le funzionalità di automazione e l'estrazione illimitata.
Raschietto visivo
Visual Scraper, oltre ad essere una piattaforma SaaS, offre anche servizi di web scraping come servizi di consegna dati e creazione di estrattori software per i clienti. Questo strumento di scansione web copre l'intero ciclo di vita di un crawler, dal download, alla gestione degli URL fino all'estrazione dei contenuti. Consente agli utenti di programmare progetti da eseguire in orari specifici o di ripetere sequenze ogni minuto, giorno, settimana, mese o anno. Visual Scraper è l'ideale per gli utenti che desiderano estrarre frequentemente notizie, aggiornamenti e forum. Tuttavia, il sito Web ufficiale sembra non essere aggiornato ora e queste informazioni potrebbero non essere aggiornate.
Caratteristiche principali
- Interfaccia facile da usare
- Supporta più formati di dati (CSV, JSON, XML, ecc.)
- Supporta impaginazione, AJAX e siti web dinamici
- Supporta server proxy e rotazione IP
- Supporta la pianificazione e l'automazione
Prezzi
- Ha un piano gratuito e piani a pagamento a partire da $ 39,99 al mese.
Importa.io
Import.io è uno strumento di web scraping che consente agli utenti di importare dati da una pagina Web specifica ed esportarli in CSV senza scrivere alcun codice. Può facilmente eseguire lo scraping di migliaia di pagine Web in pochi minuti e creare oltre 1000 API in base alle esigenze degli utenti. Import.io integra i dati Web nell'app o nel sito Web di un utente con pochi clic, semplificando il web scraping.
Caratteristiche principali
- Selezione e formazione punta e clicca
- Estrazione autenticata e interattiva
- Download di immagini e screenshot
- Proxy premium ed estrattori specifici per paese
- Output CSV, Excel, JSON e accesso API
- SLA e reporting sulla qualità dei dati
- E-mail, ticket, chat e supporto telefonico
Prezzi
- Antipasto: $ 199 al mese per 5.000 query
Dexi.io
Dexi.io è un web crawler basato su browser che consente agli utenti di raccogliere dati in base al proprio browser da qualsiasi sito Web e fornisce tre tipi di robot per creare un'attività di scraping: Extractor, Crawler e Pipes. Il freeware fornisce server proxy web anonimi e i dati estratti saranno ospitati sui server di Dexi.io per due settimane prima che i dati vengano archiviati, oppure gli utenti possono esportare direttamente i dati estratti in file JSON o CSV. Offre servizi a pagamento per gli utenti che richiedono l'estrazione dei dati in tempo reale.

Caratteristiche principali
- Selezione e formazione punta e clicca
- Estrazione autenticata e interattiva
- Download di immagini e screenshot
- Proxy premium ed estrattori specifici per paese
- Output CSV, Excel, JSON e accesso API
- SLA e reporting sulla qualità dei dati
- E-mail, ticket, chat e supporto telefonico
Prezzi
- Standard: $ 119 al mese o $ 1.950 all'anno per 1 lavoratore
Burattinaio
Puppeteer è una libreria Node sviluppata da Google, che fornisce un'API ai programmatori per controllare Chrome o Chromium tramite il protocollo DevTools. Consente agli utenti di creare uno strumento di web scraping con Puppeteer e Node.js. Puppeteer può essere utilizzato per vari scopi come l'acquisizione di schermate o la generazione di PDF di pagine Web, l'automazione dell'invio di moduli/l'inserimento di dati e la creazione di strumenti per test automatizzati.
Caratteristiche principali
- Genera screenshot e PDF di pagine web
- Eseguire la scansione e lo scraping dei dati dai siti web
- Automatizza l'invio di moduli, i test dell'interfaccia utente, l'input da tastiera, ecc.
- Cattura metriche e tracce delle prestazioni
- Prova le estensioni di Chrome
- Esegui in modalità headless o headful
Prezzi
- Puppeteer è gratuito e open-source.
Crawler4j
Crawler4j è un web crawler Java open source con una semplice interfaccia per eseguire la scansione del Web. Consente agli utenti di creare crawler multi-thread pur essendo efficiente nell'utilizzo della memoria. Crawler4j è adatto per gli sviluppatori che desiderano una soluzione di web crawling basata su Java semplice e personalizzabile.

Caratteristiche principali
- Ti consente di specificare quali URL devono essere sottoposti a scansione e quali devono essere ignorati utilizzando espressioni regolari.
- Ti consente di gestire le pagine scaricate ed estrarre i dati da esse.
- Rispetta il protocollo robots.txt ed evita la scansione di pagine non consentite.
- Può eseguire la scansione di HTML, immagini e altri tipi di file.
- Può raccogliere statistiche ed eseguire più crawler contemporaneamente.
Prezzi
- Crawler4j è un progetto Java open source che ti consente di configurare ed eseguire facilmente i tuoi web crawler.
Scansione comune
Common Crawl è uno strumento web crawler che fornisce un corpus aperto di dati web per scopi di ricerca, analisi e istruzione.

Caratteristiche principali
- Offre agli utenti l'accesso a dati di scansione Web come dati di pagine Web non elaborati, metadati estratti e testo, nonché al Common Crawl Index.
Prezzi
- Questi dati di scansione Web gratuiti e pubblicamente accessibili possono essere utilizzati da sviluppatori, ricercatori e aziende per varie attività di analisi dei dati.
Zuppa Meccanica
MechanicalSoup è una libreria Python utilizzata per l'analisi di siti Web, basata sulla libreria Beautiful Soup, con ispirazione dalla libreria Mechanize. È ottimo per memorizzare cookie, seguire reindirizzamenti, collegamenti ipertestuali e gestire moduli su un sito Web.

Caratteristiche principali
- MechanicalSoup offre un modo semplice per navigare ed estrarre dati dai siti Web senza dover affrontare complesse attività di programmazione.
Prezzi
- È uno strumento gratuito.
Crawler del nodo
Node Crawler è un pacchetto popolare e potente per la scansione di siti Web con la piattaforma Node.js. Funziona sulla base di Cheerio e include molte opzioni per personalizzare il modo in cui gli utenti eseguono la scansione o lo scraping del Web, inclusa la limitazione del numero di richieste e del tempo impiegato tra di esse. Node Crawler è l'ideale per gli sviluppatori che preferiscono lavorare con Node.js per i loro progetti di web crawling.

Caratteristiche principali
- Facile da usare
- API basata sugli eventi
- Tentativi e timeout configurabili
- Rilevamento automatico della codifica
- Gestione automatica dei cookie
- Gestione del reindirizzamento automatico
- Gestione automatica gzip/deflate
Prezzi
- È uno strumento gratuito.
Fattori da considerare quando si sceglie uno strumento di scansione Web
Prezzi
Considera la struttura dei prezzi dello strumento scelto e assicurati che sia trasparente, senza costi nascosti. Scegli un'azienda che offra un modello di prezzo chiaro e fornisca informazioni dettagliate sulle funzionalità disponibili.
Facilità d'uso
Scegli uno strumento di scansione del Web che sia intuitivo e non richieda conoscenze tecniche approfondite. Molti strumenti offrono interfacce punta e clicca, rendendo più facile per i non programmatori estrarre dati dai siti web.
Scalabilità
Considera se lo strumento di scansione del Web è in grado di gestire il volume di dati che devi estrarre e se può crescere con la tua attività. Alcuni strumenti sono più adatti a progetti su piccola scala, mentre altri sono progettati per l'estrazione di dati su larga scala.
Qualità e accuratezza dei dati
Assicurati che lo strumento di scansione del Web sia in grado di pulire e organizzare i dati estratti in un formato utilizzabile. La qualità dei dati è fondamentale per un'analisi accurata, quindi scegli uno strumento che offra funzionalità efficienti di organizzazione e pulizia dei dati.
Servizio Clienti
Scegli uno strumento di scansione del Web con un'assistenza clienti reattiva e disponibile per assisterti in caso di problemi. Metti alla prova l'assistenza clienti contattandoli e notando quanto tempo impiegano a rispondere prima di prendere una decisione informata.
Conclusione
Gli strumenti di scansione del Web sono essenziali per le aziende che desiderano estrarre dati preziosi dai siti Web per vari scopi, come ricerche di mercato, SEO e analisi della concorrenza. Considerando fattori quali prezzi, facilità d'uso, scalabilità, qualità e accuratezza dei dati e assistenza clienti, puoi scegliere lo strumento di scansione web adatto alle tue esigenze. I 25 migliori strumenti di scansione web sopra menzionati si rivolgono a una vasta gamma di utenti, dai non programmatori agli sviluppatori, garantendo che ci sia uno strumento adatto a tutti. Puoi anche registrarti per una prova gratuita di 7 giorni con Scalenut per ottimizzare i contenuti del tuo sito web e migliorare il tuo posizionamento.