
Estrarre automaticamente concetti e parole chiave da un testo (Parte I: I metodi tradizionali)
Pubblicato: 2022-02-22Al dipartimento di ricerca e sviluppo di Oncrawl, cerchiamo sempre di più di migliorare il contenuto semantico delle tue pagine Web. Utilizzando i modelli di Machine Learning per l'elaborazione del linguaggio naturale (NLP), possiamo confrontare i contenuti delle tue pagine in dettaglio, creare riepiloghi automatici, completare o correggere i tag dei tuoi articoli, ottimizzare i contenuti in base ai dati di Google Search Console , ecc.
In un articolo precedente, abbiamo parlato dell'estrazione del contenuto di testo dalle pagine HTML. Questa volta, vorremmo parlare dell'estrazione automatica di parole chiave da un testo. Questo argomento sarà diviso in due post:
- la prima tratterà il contesto ei metodi cosiddetti “tradizionali” con alcuni esempi concreti
- il secondo a venire presto riguarderà approcci più semantici basati su trasformatori e metodi di valutazione al fine di confrontare questi diversi metodi
Contesto
Al di là di un titolo o di un abstract, quale modo migliore per identificare il contenuto di un testo, di un articolo scientifico o di una pagina web se non con poche parole chiave. È un modo semplice e molto efficace per identificare l'argomento ei concetti di un testo molto più lungo. Può anche essere un buon modo per classificare una serie di testi: identificarli e raggrupparli per parole chiave. I siti che offrono articoli scientifici come PubMed o arxiv.org possono offrire categorie e consigli basati su queste parole chiave.
Le parole chiave sono anche molto utili per l'indicizzazione di documenti molto grandi e per il reperimento di informazioni, un campo di competenza ben noto ai motori di ricerca
La mancanza di parole chiave è un problema ricorrente nella categorizzazione automatica degli articoli scientifici [1]: molti articoli non hanno parole chiave assegnate. Pertanto, è necessario trovare metodi per estrarre automaticamente concetti e parole chiave da un testo. Per valutare la pertinenza di un insieme di parole chiave estratte automaticamente, i set di dati spesso confrontano le parole chiave estratte da un algoritmo con parole chiave estratte da diversi esseri umani.
Come puoi immaginare, questo è un problema condiviso dai motori di ricerca quando si classificano le pagine web. Una migliore comprensione dei processi automatizzati di estrazione delle parole chiave consente di comprendere meglio perché una pagina web è posizionata per tale o tale parola chiave. Può anche rivelare lacune semantiche che gli impediscono di posizionarsi bene per la parola chiave che hai preso di mira.
Esistono ovviamente diversi modi per estrarre parole chiave da un testo o da un paragrafo. In questo primo post descriveremo gli approcci cosiddetti “classici”.
[Ebook] Data SEO: la prossima grande avventura
 Leggi l'ebook
Leggi l'ebookRestrizioni
Tuttavia, abbiamo alcuni limiti e prerequisiti nella scelta di un algoritmo:
- Il metodo deve essere in grado di estrarre parole chiave da un singolo documento. Alcuni metodi richiedono un corpus completo, cioè diverse centinaia o addirittura migliaia di documenti. Sebbene questi metodi possano essere utilizzati dai motori di ricerca, non saranno utili per un singolo documento.
- Siamo in un caso di Machine Learning non supervisionato. Non abbiamo a portata di mano un set di dati in francese, inglese o altre lingue con dati annotati. In altre parole, non abbiamo migliaia di documenti con parole chiave già estratte.
- Il metodo deve essere indipendente dal dominio/campo lessicale del documento. Vogliamo essere in grado di estrarre parole chiave da qualsiasi tipo di documento: articoli di notizie, pagine web, ecc. Si noti che alcuni set di dati che hanno già parole chiave estratte per ciascun documento sono spesso medicina, informatica, ecc.
- Alcuni metodi si basano su modelli POS-tagging, ovvero la capacità di un modello NLP di identificare le parole in una frase in base al loro tipo grammaticale: un verbo, un sostantivo, un determinante. Determinare l'importanza di una parola chiave che è un sostantivo piuttosto che un determinante è chiaramente rilevante. Tuttavia, a seconda della lingua, i modelli di codifica POS a volte sono di qualità molto irregolare.
A proposito di metodi tradizionali
Distinguiamo tra i metodi cosiddetti “tradizionali” e quelli più recenti che utilizzano tecniche di NLP – Natural Language Processing – come word embedding e contestual embedding. Questo argomento sarà trattato in un prossimo post. Ma prima, torniamo agli approcci classici, ne distinguiamo due:
- l'approccio statistico
- l'approccio grafico
L'approccio statistico si baserà principalmente sulle frequenze delle parole e sulla loro co-occorrenza. Partiamo da semplici ipotesi per costruire euristiche ed estrarre parole importanti: una parola molto frequente, una serie di parole consecutive che compaiono più volte, ecc. I metodi basati su grafi costruiranno un grafico in cui ogni nodo può corrispondere a una parola, gruppo di parole o frase. Quindi ogni arco può rappresentare la probabilità (o frequenza) di osservare queste parole insieme.
Ecco alcuni metodi:
- Basato su statistiche
- TF-IDF
- RASTRELLO
- YAKE
- Basato su grafici
- TextRank
- Classifica argomento
- Classifica singola
Tutti gli esempi riportati utilizzano testo tratto da questa pagina web: Jazz au Tresor : John Coltrane – Impressions Graz 1962.
Approccio statistico
Ti presenteremo i due metodi Rake e Yake. In un contesto SEO, potresti aver sentito parlare del metodo TF-IDF. Ma poiché richiede un corpus di documenti, non lo tratteremo qui.
RASTRELLO
RAKE è l'acronimo di Rapid Automatic Keyword Extraction. Esistono diverse implementazioni di questo metodo in Python, incluso rake-nltk. Il punteggio di ciascuna parola chiave, detta anche keyphrase perché contiene più parole, si basa su due elementi: la frequenza delle parole e la somma delle loro co-occorrenze. La costituzione di ogni keyphrase è molto semplice, consiste in:
- taglia il testo in frasi
- taglia ogni frase in frasi chiave
Nella frase seguente, prenderemo tutti i gruppi di parole separati da elementi di punteggiatura o stopword:
Poco prima, Coltrane dirigeva un quintetto, con Eric Dolphy al suo fianco e Reggie Workman al contrabbasso.
Ciò potrebbe comportare le seguenti frasi chiave:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
Nota che le stopword sono una serie di parole molto frequenti come " the ", " in ", "and" or " it ". Poiché i metodi classici si basano spesso sul calcolo della frequenza di occorrenza delle parole, è importante scegliere attentamente le stopword. Il più delle volte, non vogliamo avere parole come >"to" , "the" or "di" nelle nostre proposte di frasi chiave. In effetti, queste stopword non sono associate a un campo lessicale specifico e sono quindi molto meno rilevanti delle parole “ jazz ” o “ saxophone ” per esempio.

Una volta che abbiamo isolato diverse frasi chiave candidate, assegniamo loro un punteggio in base alla frequenza delle parole e delle co-occorrenze. Più alto è il punteggio, più rilevanti dovrebbero essere le frasi chiave.
Proviamo velocemente con il testo dell'articolo su John Coltrane.
# frammento di Python per rake da rake_nltk import Rake # supponiamo di avere già l'articolo nella variabile 'text' rake = Rake(stopwords=FRENCH_STOPWORDS, max_length=4) rake.extract_keywords_from_text(testo) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
Ecco le prime 5 frasi chiave:
“radio pubblica nazionale austriaca”, “cime liriche più celestiali”, “graz ha due particolarità”, “sassofono tenore john coltrane”, “solo versione registrata”
Ci sono alcuni svantaggi di questo metodo. Il primo è l'importanza della scelta delle stopword perché vengono utilizzate per suddividere una frase in frasi chiave candidate. La seconda è che quando le frasi chiave sono troppo lunghe, avranno spesso un punteggio più alto a causa della co-occorrenza delle parole presenti. Per limitare la lunghezza delle frasi chiave, abbiamo impostato il metodo con max_length=4 .
YAKE
YAKE sta per Yet Another Keyword Extractor. Questo metodo si basa sul seguente articolo YAKE! Estrazione di parole chiave da singoli documenti utilizzando più funzionalità locali che risale al 2020. È un metodo più recente di RAKE i cui autori hanno proposto un'implementazione Python disponibile su Github.
Come per RAKE, faremo affidamento sulla frequenza delle parole e sulla co-occorrenza. Gli autori aggiungeranno anche alcune euristiche interessanti:
- distingueremo tra parole in minuscolo e parole in maiuscolo (o la prima lettera o l'intera parola). Assumiamo qui che le parole che iniziano con una lettera maiuscola (tranne all'inizio di una frase) siano più rilevanti di altre: nomi di persone, città, paesi, marchi. Questo è lo stesso principio per tutte le parole in maiuscolo.
- il punteggio di ogni frase chiave candidata dipenderà dalla sua posizione nel testo. Se le frasi chiave candidate compaiono all'inizio del testo, avranno un punteggio più alto che se compaiono alla fine. Ad esempio, gli articoli di notizie spesso menzionano concetti importanti all'inizio dell'articolo.
# frammento di pitone per yake da yake import KeywordExtractor come Yake yake = Yake(lan="fr", stopwords=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords (testo)
Come RAKE, ecco i primi 5 risultati:
“Treasure Jazz”, “John Coltrane”, “Impressions Graz”, “Graz”, “Coltrane”
Nonostante alcune duplicazioni di alcune parole in alcune frasi chiave, questo metodo sembra piuttosto interessante.
Approccio grafico
Questo tipo di approccio non è troppo lontano dall'approccio statistico, nel senso che calcoleremo anche le co-occorrenze di parole. Il suffisso Rank associato ad alcuni nomi di metodi come TextRank si basa sul principio dell'algoritmo PageRank per calcolare la popolarità di ogni pagina in base ai suoi collegamenti in entrata e in uscita.
[Ebook] Automatizzare la SEO con Oncrawl
 Leggi l'ebook
Leggi l'ebookTextRank
Questo algoritmo deriva dal documento TextRank: Bringing Order into Texts del 2004 e si basa sugli stessi principi dell'algoritmo PageRank . Tuttavia, invece di costruire un grafico con pagine e link, costruiremo un grafico con parole. Ogni parola sarà collegata ad altre parole in base alla loro co-occorrenza.
Ci sono diverse implementazioni in Python. In questo articolo introdurrò pytextrank. Spezzeremo uno dei nostri vincoli sulla codifica POS. Infatti, quando costruiamo il grafico, non includeremo tutte le parole come nodi. Verranno presi in considerazione solo verbi e nomi. Come i metodi precedenti che utilizzano le stopword per filtrare i candidati irrilevanti, l'algoritmo TextRank utilizza il tipo grammaticale delle parole.
Ecco un esempio di una parte del grafico che verrà costruita dall'algoritmo: 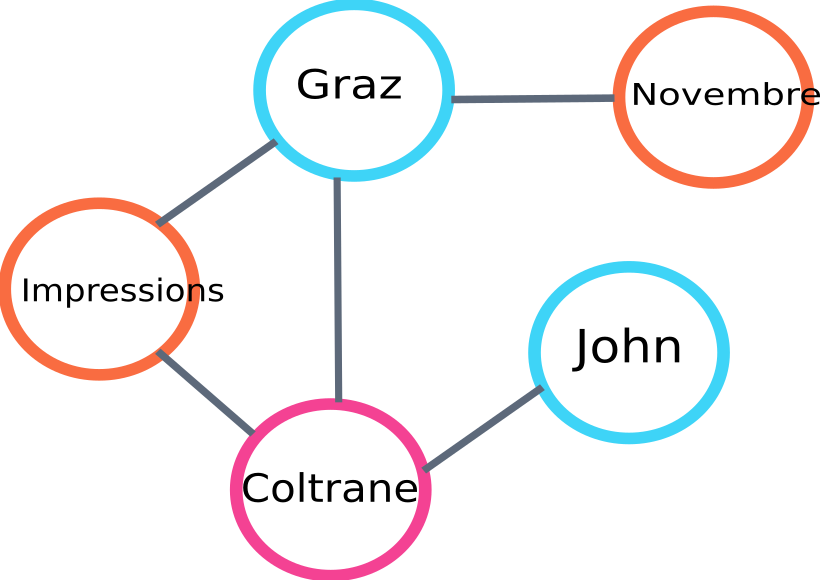
esempio di grafico di classificazione del testo
Ecco un esempio di utilizzo in Python. Si noti che questa implementazione utilizza il meccanismo della pipeline della libreria spaCy. È questa libreria che è in grado di eseguire il tagging POS.
# frammento di python per pytextrank
spazio di importazione
importa pytextrank
# carica un modello francese
nlp = spacy.load("fr_core_news_sm")
# aggiungi pytextrank alla pipe
nlp.add_pipe("textrank")
doc = nlp(testo)
textrank_keyphrases = doc._.phrases
Ecco i primi 5 risultati:
“Copenhague”, “novembre”, “Impressions Graz”, “Graz”, “John Coltrane”
Oltre ad estrarre le frasi chiave, TextRank estrae anche le frasi. Questo può essere molto utile per fare i cosiddetti “riassunti estrattivi” – questo aspetto non sarà trattato in questo articolo.
Conclusioni
Tra i tre metodi qui testati, gli ultimi due ci sembrano abbastanza attinenti all'argomento del testo. Per confrontare meglio questi approcci, dovremmo ovviamente valutare questi diversi modelli su un numero maggiore di esempi. Esistono infatti metriche per misurare la pertinenza di questi modelli di estrazione delle parole chiave.
Gli elenchi di parole chiave prodotti da questi cosiddetti modelli tradizionali forniscono un'ottima base per verificare che le tue pagine siano ben mirate. Inoltre, forniscono una prima approssimazione di come un motore di ricerca potrebbe comprendere e classificare il contenuto.
D'altra parte, per estrarre concetti da un documento possono essere utilizzati anche altri metodi che utilizzano modelli NLP pre-addestrati come BERT. Contrariamente al cosiddetto approccio classico, questi metodi di solito consentono una migliore acquisizione della semantica.
I diversi metodi di valutazione, embedding contestuali e trasformatori saranno presentati in un secondo articolo di approfondimento!
Ecco l'elenco delle parole chiave estratte da questo articolo con uno dei tre metodi citati:
“metodi”, “parole chiave”, “frasi chiave”, “testo”, “parole chiave estratte”, “Elaborazione del linguaggio naturale”
Riferimenti bibliografici
- [1] Estrazione automatica delle parole chiave migliorata data una maggiore conoscenza linguistica, Anette Hulth, 2003
- [2] Estrazione automatica di parole chiave da singoli documenti, Stuart Rose et. al, 2010
- [3] YAKE! Estrazione di parole chiave da singoli documenti utilizzando più funzionalità locali, Ricardo Campos et. al, 2020
- [4] TextRank: Mettere ordine nei testi, Rada Mihalcea et. al, 2004
Inizia la tua prova gratuita di 14 giorni
 Inizia la tua prova
Inizia la tua prova