
Autenticità, Dalle-2 e Midjourney e il nostro fascino per le immagini e l'arte generate dall'intelligenza artificiale
Pubblicato: 2022-08-04Questo articolo riguarda la tecnologia alla base di piattaforme come Dalle-2 e Midjourney e perché i creatori di Open AI dovrebbero potenzialmente pagarti dei soldi, non addebitarti ...
Sempre più persone su Internet chiamano Dalle-2 e Open AI una truffa. Il motivo è che Dalle-2 ora si sta trasformando improvvisamente in un servizio monetizzato, dove è necessario acquistare crediti, se si utilizza la piattaforma oltre il limite beta.
DALLE 2 è solo una delle tante nuove piattaforme che ti offrono l'accesso a contenuti generati dall'intelligenza artificiale e afferma che puoi utilizzarli per scopi commerciali. Altre piattaforme includono Midjourney, Jasper Art, Nightcafe, Starry AI e Craiyon. Ci concentreremo su Dalle 2 in questo post sul blog, ma sono quasi identificativi, quando si tratta di sfide e problemi legali.
Truffa è un'affermazione piuttosto dura secondo noi, ma c'è un problema evidente nell'usare i dati che altre persone hanno creato (foto, video, annotazioni, persone sulle immagini ecc.) E poi iniziare a rivenderli alle stesse persone.
Questo problema potrebbe essere trascurato da molti di noi, perché siamo semplicemente affascinati dalla nuova tecnologia. Qualcosa di totalmente comprensibile.
Tuttavia, anche se DALL-E 2 alla fine della giornata è solo una macchina avanzata per il riconoscimento dei modelli, il suo output non è neutro e i modelli non provengono da aria fresca.
Si basano su tonnellate di dati, in cui ci sono più domande legali da porre. Domande importanti per te come potenziale utente delle immagini che generi.
 Immagine creata da DALLE-2
Immagine creata da DALLE-2
I modelli di intelligenza artificiale non possono essere paragonati agli esseri umani
Dovresti iniziare leggendo questo brillante articolo su Engadget, prima di iniziare a considerare l'utilizzo delle immagini DALL-E 2 per scopi commerciali.
Nell'articolo di Engadget sottolineano un'altra cosa molto importante. Vale a dire il fatto che DALL-E 2 e OpenAI NON stanno rinunciando al proprio diritto di commercializzare le immagini che gli utenti creano utilizzando DALL-E. Fondamentalmente significa che puoi generare immagini che poi venderanno commercialmente ad altri.
Ciò mostra che le intenzioni sono molto diverse dall'analogia talvolta utilizzata, dove i promotori DALLE-2 la confronteranno con uno studente che legge l'opera di un autore affermato. In questo esempio lo studente può apprendere gli stili ei modelli dell'autore e in seguito trovarli applicabili in altri contesti e riutilizzarli lì.
Tuttavia, non si tratta di un cervello umano che utilizza la memoria creativa per creare nuove opere creative. Si tratta di una macchina per il riconoscimento dei modelli che riutilizza e in alcuni casi riproduce i dati di addestramento in immagini che vengono poi utilizzate o addirittura vendute commercialmente. Sono semplicemente due mondi diversi, sia metaforicamente che letteralmente.
 Foto reale dal mondo reale
Foto reale dal mondo reale
La promessa dell'autenticità di JumpStory
Questo articolo è per le persone che vogliono capire a un livello più profondo, come funziona questa nuova tecnologia di generazione di immagini AI. Ma prima di iniziare, solo poche parole sul motivo per cui JumpStory non sta attualmente costruendo una macchina simile.
Naturalmente, ci è stata posta questa domanda più volte. Non ultimo considerando che stiamo già utilizzando l'IA nella nostra azienda e poiché abbiamo accesso a milioni di immagini autentiche.
Tuttavia, questa non è una discussione tecnologica per noi, ma etica. Una discussione che ha portato alla nostra Promessa di Autenticità.
Siamo fondamentalmente contrari a un futuro, in cui le immagini generate dall'intelligenza artificiale diventano la norma piuttosto che l'eccezione. Chiamaci vecchio stile, ma crediamo che il mondo REALE sia bello.
Siamo orgogliosi che le nostre foto e i nostri video ritraggono esseri umani reali in diverse forme e dimensioni. Non siamo contrari all'uso dell'IA, ma non pensiamo che dovrebbe essere usata per generare persone o realtà false.
Tecnologie come i supporti sintetici e DALL-E 2 possono essere affascinanti in superficie, ma rappresentano anche un rischio reale. Rischiano di offuscare il confine tra reale e falso, che sarà una minaccia fondamentale alla fiducia tra gli esseri umani.
Questo è il motivo per cui JumpStory non utilizza l'intelligenza artificiale per generare immagini false, ma utilizza invece l'IA per identificare quali immagini sono originali, autentiche e, ovviamente, legali da utilizzare per scopi commerciali.

Queste sono le immagini che trovi utilizzando il nostro servizio e abbiamo chiamato il nostro approccio "Intelligenza Autentica".
Capire come vengono generate le immagini AI
Per ora basta parlare di JumpStory e dei problemi legali con DALL-E 2. Diamo un'occhiata a come le immagini AI vengono generate su piattaforme come DALLE-2, Imagen, Crayion (ex Dall-E Mini), Midjourney ecc. … Usando DALLE-2 come esempio attualmente più pubblicizzato.
Per cominciare, DALLE-2 può eseguire diversi tipi di attività, ma in questo post del blog ci concentreremo sull'attività di generazione delle immagini.
Come funziona è che un prompt di testo viene inserito in un codificatore di testo. Questo codificatore è addestrato per mappare il prompt in uno spazio di rappresentazione. Successivamente, un cosiddetto modello a priori associa il testo codificato a una codifica dell'immagine corrispondente che acquisisce le informazioni semantiche del prompt di codifica del testo.
(Se questo sta già diventando un po' geek, mi dispiace molto, ma andrà anche peggio)
Il passaggio finale per il codificatore di immagini è generare un'immagine che visualizzi le informazioni semantiche che il codificatore ha ricevuto. Queste sono le basi di macchine come Open AI.
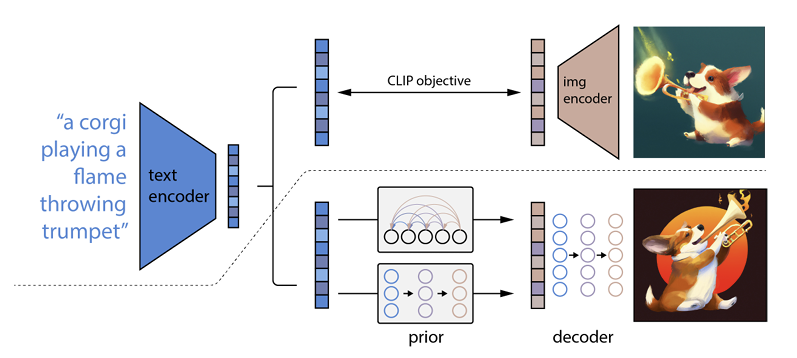
Il rapporto tra testo e immagini
DALL-E 2 e tecnologie simili sono spesso indicate come generatori di testo in immagini. Il motivo è la loro capacità di ricevere un input di testo e fornire un output di immagine.
Per farti un esempio, questo è "Un astronauta a cavallo nello stile di Andy Warhol:

fonte: DALLE-2
Quello che succede qui si basa sul modello di Open AI chiamato CLIP. CLIP è l'abbreviazione di "Contrastive Language-Image Pre-training" ed è un modello molto complesso addestrato su milioni di immagini e didascalie.
Ciò in cui CLIP è particolarmente bravo è capire quanto un particolare testo sia correlato a una particolare immagine. La chiave qui non è la didascalia, ma quanto è correlata una certa didascalia a una determinata immagine.
Questo tipo di tecnologia è chiamato "contrassivo" e ciò che CLIP è in grado di fare è imparare la semantica dal linguaggio naturale. Il modo in cui CLIP ha appreso questo è attraverso un processo, in cui l'obiettivo è (ora citando la documentazione tecnologica): "massimizzare simultaneamente la somiglianza del coseno tra Ncorrette coppie immagine codificata/didascalia e ridurre al minimo la somiglianza del coseno tra N 2 – N immagine codificata errata /coppie didascalie.”
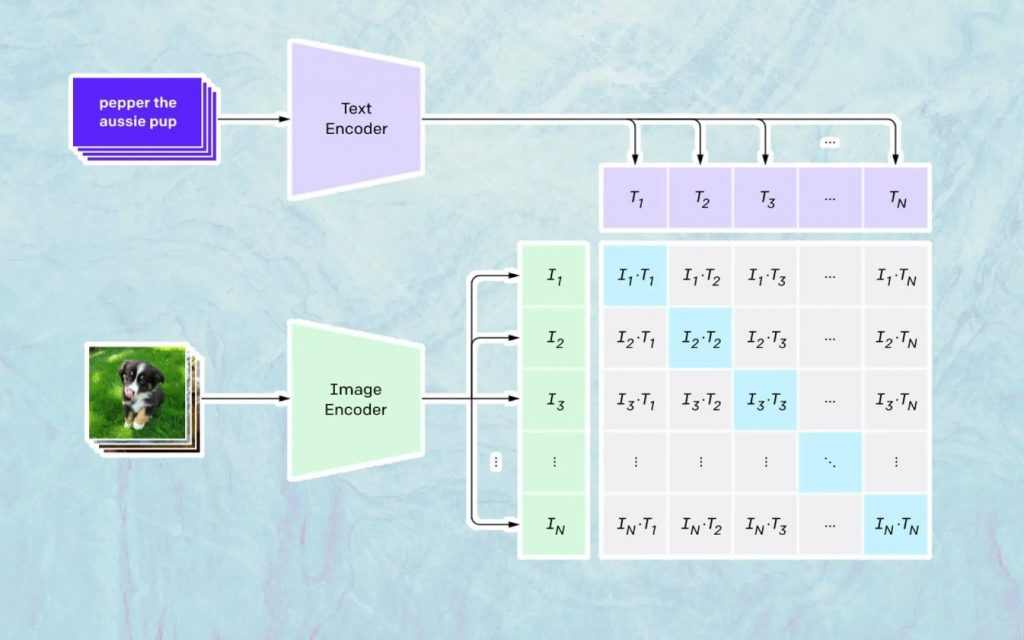
Generazione delle immagini
Come descritto sopra, il modello CLIP apprende uno spazio di rappresentazione in cui può determinare come sono correlate le codifiche di immagini e testi.
Il prossimo compito è usare questo spazio per generare immagini. A tale scopo Open AI ha sviluppato un altro modello denominato GLIDE, che è in grado di utilizzare l'input di CLIP e, utilizzando un modello di diffusione, eseguire la generazione dell'immagine.
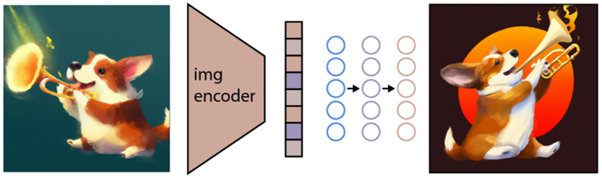
Per spiegare brevemente cos'è un modello di diffusione, è fondamentalmente un modello che impara a generare dati invertendo un processo di rumore graduale. Ci scusiamo per questo che ora sta diventando molto tecnico, quindi per citare una descrizione trovata nella documentazione di Open AI:
“Il processo di rumore è visto come una catena di Markov parametrizzata che aggiunge gradualmente rumore a un'immagine per corromperla, risultando infine (asintoticamente) in puro rumore gaussiano. Il modello di diffusione impara a navigare all'indietro lungo questa catena, rimuovendo gradualmente il rumore in una serie di passaggi temporali per invertire questo processo".

Se vuoi approfondire ulteriormente la tecnologia, ti consigliamo di leggere questo eccellente articolo di Ryan O'Connor.