
Come rispondere a domande complesse sui dati con i dati Oncrawl, al di fuori di Oncrawl
Pubblicato: 2022-01-04Uno dei vantaggi di Oncrawl per la SEO aziendale è l'accesso completo ai dati grezzi. Sia che tu stia collegando i tuoi dati SEO a un flusso di lavoro BI o data science, eseguendo le tue analisi o lavorando all'interno delle linee guida sulla sicurezza dei dati per la tua organizzazione, i dati SEO grezzi e di audit del sito Web possono servire a molti scopi.
Oggi vedremo come utilizzare i dati Oncrawl per rispondere a domande complesse sui dati.
Che cos'è una domanda sui dati complessi?
Le domande sui dati complessi sono domande a cui non è possibile rispondere con una semplice ricerca nel database, ma richiedono l'elaborazione dei dati per ottenere la risposta.
Ecco alcuni esempi comuni di domande sui dati "complesse" che spesso i SEO hanno:
- Creazione di un elenco di tutti i collegamenti che puntano a pagine che reindirizzano ad altre pagine con stato 404
- Creazione di un elenco di tutti i collegamenti e del relativo anchor text che puntano a pagine in una segmentazione basata su metriche non URL
Come rispondere a domande complesse sui dati in Oncrawl
La struttura dei dati di Oncrawl è costruita per consentire a quasi tutti i siti di cercare i dati quasi in tempo reale. Ciò comporta la memorizzazione di diversi tipi di dati in diversi set di dati al fine di garantire che i tempi di ricerca siano ridotti al minimo nell'interfaccia. Ad esempio, memorizziamo tutti i dati associati agli URL in un set di dati: codice di risposta, numero di link in uscita, tipo di dati strutturati presenti, numero di parole, numero di visite organiche... E memorizziamo tutti i dati relativi ai link in un set di dati separato: destinazione del collegamento, origine del collegamento, testo di ancoraggio...
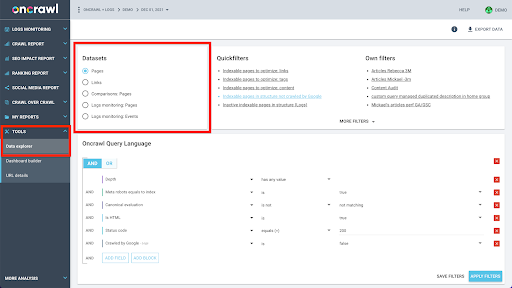
L'unione di questi set di dati è complessa dal punto di vista computazionale e non sempre è supportata nell'interfaccia dell'applicazione Oncrawl. Quando sei interessato a cercare qualcosa che richieda il filtraggio di un set di dati per cercare qualcosa in un altro, ti consigliamo di manipolare i dati grezzi da solo.
Poiché tutti i dati di Oncrawl sono disponibili, esistono molti modi per unire set di dati ed esprimere query complesse.
In questo articolo, ne esamineremo uno, utilizzando Google Cloud e BigQuery, che è appropriato per set di dati molto grandi come molti dei nostri clienti incontrano quando esaminano i dati per i siti con volumi elevati di pagine.
Di cosa avrai bisogno
Per seguire il metodo di cui parleremo in questo articolo, avrai bisogno dell'accesso ai seguenti strumenti:
- A gattonare
- L'API di Oncrawl con Big Data Export
- Archiviazione cloud di Google
- BigQuery
- Uno script Python per trasferire i dati da Oncrawl a BigQuery (lo realizzeremo durante l'articolo).
Prima di iniziare, devi avere accesso a un rapporto di scansione completato in Oncrawl.
Come sfruttare i dati Oncrawl in Google BigQuery
Il piano per l'articolo di oggi è il seguente:
- Innanzitutto, ci assicureremo che Google Cloud Storage sia configurato per ricevere dati da Oncrawl.
- Successivamente, utilizzeremo uno script Python per eseguire le esportazioni di Big Data di Oncrawl per esportare i dati da una determinata scansione in un bucket di Google Cloud Storage. Esporteremo due set di dati: pagine e collegamenti.
- Al termine, creeremo un set di dati in Google BigQuery. Creeremo quindi una tabella da ciascuna delle due esportazioni all'interno del set di dati BigQuery.
- Infine, sperimenteremo interrogando i singoli set di dati, quindi entrambi i set di dati insieme per trovare la risposta a una domanda complessa.
Configurazione all'interno di Google Cloud per ricevere i dati di Oncrawl
Per eseguire questa guida in un ambiente sandbox dedicato, ti consigliamo di creare un nuovo progetto Google Cloud per isolarlo dai progetti in corso esistenti.
Cominciamo dalla casa di Google Cloud.
Dalla tua home page di Google Cloud, hai accesso a molte cose oltre al Cloud Storage. Siamo interessati ai bucket Cloud Storage, disponibili all'interno del livello di archiviazione cloud di Google Cloud Platform: 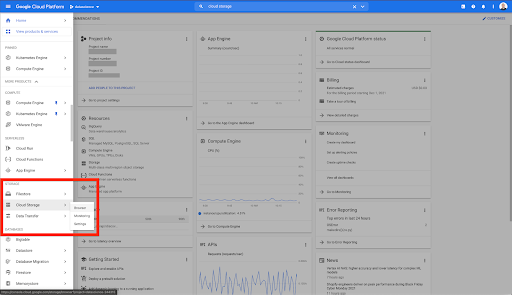
Puoi anche raggiungere il browser Cloud Storage direttamente all'indirizzo https://console.cloud.google.com/storage/browser.
È quindi necessario creare un bucket di Cloud Storage e concedere le autorizzazioni corrette in modo che l'account di servizio di Oncrawl possa scrivervi, con il prefisso di propria scelta.
Il bucket di Google Cloud Storage fungerà da spazio di archiviazione temporaneo per contenere le esportazioni di Big Data da Oncrawl prima di caricarle in Google BigQuery.
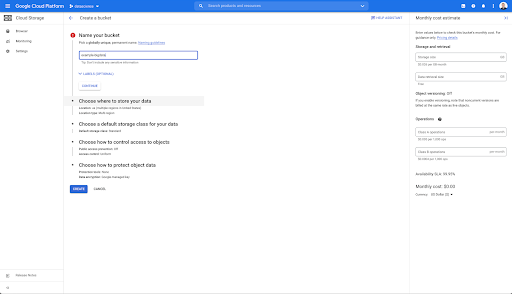
In questo bucket ho creato anche due cartelle: "links" e "pages": 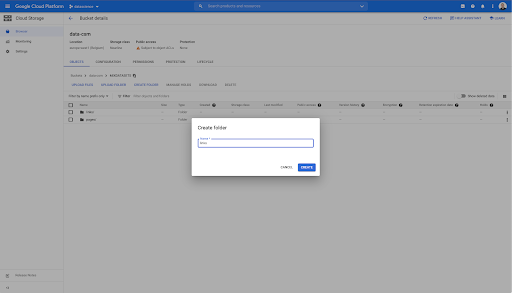
Esportazione di set di dati da Oncrawl
Ora che abbiamo impostato lo spazio in cui vogliamo salvare i dati, dobbiamo esportarlo da Oncrawl. L'esportazione in un bucket di Google Cloud Storage con Oncrawl è particolarmente semplice, poiché possiamo esportare i dati nel formato corretto e salvarli direttamente nel bucket. Questo elimina qualsiasi passaggio aggiuntivo.
Creazione di una chiave API
L'esportazione dei dati da Oncrawl nel formato Parquet per BigQuery richiederà l'uso di una chiave API per agire sull'API in modo programmatico, per conto del proprietario dell'account Oncrawl. L'applicazione Oncrawl consente agli utenti di creare chiavi API denominate in modo che il tuo account sia sempre ben organizzato e pulito. Le chiavi API sono anche associate a diverse autorizzazioni (ambito) in modo da poter gestire le chiavi e i loro scopi.
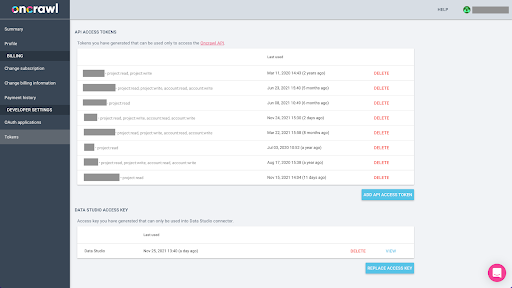
Diamo il nome alla nostra nuova chiave 'Chiave sessione di conoscenza'. La funzione di esportazione di Big Data richiede autorizzazioni di scrittura nell'account, perché stiamo creando le esportazioni di dati. Per eseguire questa operazione, è necessario disporre dell'accesso in lettura al progetto e all'accesso in lettura e scrittura sull'account.
Ora abbiamo una nuova chiave API, che copierò negli appunti.
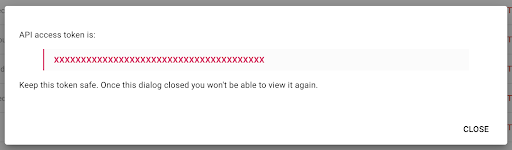
Tieni presente che, per motivi di sicurezza, hai la possibilità di copiare la chiave una sola volta . Se dimentichi di copiare la chiave, dovrai eliminarla e crearne una nuova.
Creazione del tuo script Python
Ho creato un taccuino Google Colab per questo, ma condividerò il codice di seguito in modo che tu possa creare i tuoi strumenti o il tuo taccuino.
1. Archivia la tua chiave API in una variabile globale
Innanzitutto, eseguiamo il bootstrap dell'ambiente e dichiariamo la chiave API in una variabile globale denominata "Oncrawl Token". Quindi, ci prepariamo per il resto dell'esperimento:
#@title Accedi all'API Oncrawl
#@markdown Fornisci il tuo token API di seguito per consentire a questo notebook di accedere ai tuoi dati Oncrawl:
# IL TUO TOKEN PER L'API ONCRAWL
ONCRAWL_TOKEN = "" #@param {tipo:"stringa"}
!pip installa prigione
da IPython.display import clear_output
clear_output()
print('Tutto caricato.') 
2. Crea un elenco a discesa per scegliere il progetto Oncrawl con cui vuoi lavorare
Quindi, usando quella chiave, vogliamo essere in grado di scegliere il progetto con cui vogliamo giocare ottenendo l'elenco dei progetti e creando un widget a discesa da quell'elenco. Eseguendo il secondo blocco di codice, effettuare le seguenti operazioni:
- Chiameremo l'API Oncrawl per ottenere l'elenco dei progetti sull'account utilizzando la chiave API che è stata appena inviata.
- Una volta ottenuto l'elenco del progetto dalla risposta dell'API, lo formattiamo come un elenco utilizzando il nome del progetto e l'URL di inizio del progetto.
- Memorizziamo l'ID del progetto fornito nella risposta.
- Costruiamo un menu a discesa e lo mostriamo sotto il blocco di codice.
#@title Seleziona il sito web da analizzare scegliendo il progetto Oncrawl corrispondente
richieste di importazione
prigione d'importazione
importa ipywidgets come widget
importa json
# Ottieni l'elenco dei progetti
response = request.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
limite=1000,
sort='nome:asc'
),
headers={ 'Autorizzazione': 'Portatore '+ONCRAWL_TOKEN }
)
json_res = risposta.json()
#prepara il menu a discesa per consentire all'utente di selezionare un progetto
progetti = []
per l'elemento in json_res['progetti']:
project.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
output = widget.Output()
dropdown_purpose = widgets.Dropdown(opzioni = progetti, descrizione="Progetto: ")
def dropdown_project_eventhandler(cambia):
output.clear_output()
con uscita:
esposizione(progetti)
dropdown_purpose.observe(dropdown_project_eventhandler, nomi='valore')
display (scopo_a discesa) Dal menu a tendina che questo crea, puoi vedere l'elenco completo del progetto a cui la chiave API ha accesso. 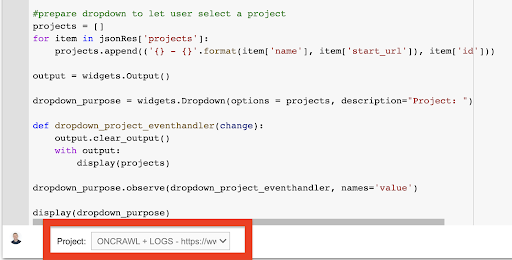
Ai fini della dimostrazione di oggi, utilizziamo un progetto demo basato sul sito Web di Oncrawl.
3. Crea un elenco a discesa per scegliere il profilo di scansione all'interno del progetto con cui vuoi lavorare
Successivamente, decideremo quale profilo di scansione utilizzare. Vogliamo scegliere un profilo di scansione all'interno di questo progetto. Il progetto demo ha molte diverse configurazioni di scansione: 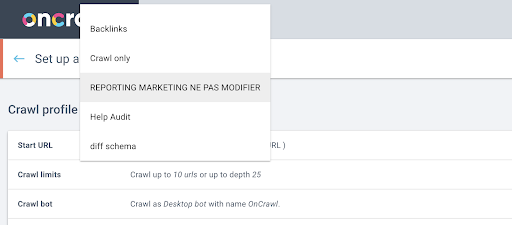
In questo caso, stiamo esaminando un progetto che i team di Oncrawl utilizzano spesso per gli esperimenti, quindi sceglierò il profilo di scansione utilizzato dal team di marketing per monitorare le prestazioni del sito Web di Oncrawl. Poiché questo dovrebbe essere il profilo di scansione più stabile, è una buona scelta per l'esperimento di oggi.
Per ottenere il profilo di scansione, utilizzeremo l'API Oncrawl, per richiedere l'ultima scansione all'interno di ogni singolo profilo di scansione nel progetto:
- Ci prepariamo a interrogare l'API Oncrawl per il progetto specificato.
- Chiederemo tutte le ricerche per indicizzazione restituite in ordine decrescente in base alla data "creata a".
richieste di importazione
importa json
importa ipywidgets come widget
project_id = dropdown_purpose.value
# Ottieni dettagli sui progetti (includi tutte le scansioni nel progetto)
progetto = request.get("https://app.oncrawl.com/api/v2/projects/{}".format(id_progetto),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ 'Autorizzazione': 'Portatore '+ONCRAWL_TOKEN }).json()
# Raggruppa le scansioni per profilo di scansione (nome della scansione)
crawls_by_config = {}
Tentativo:
per la scansione nel progetto['crawl']:
if crawl['status'] in ["done"]:
se crawl['crawl_config']['name'] non è in crawls_by_config.keys():
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
if len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
if crawl['status'] == "archived":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = True
tranne Eccezione come e:
raise Exception("errore {} , {}".format(e, progetto))
# Costruisci l'elenco per la selezione a discesa
list = [("{} ({})".format(k, len(v['crawl_ids'])), k) per k, v in crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(options = list, description="Crawl configs: ")
def dropdown_cc_eventhandler(cambia):
output.clear_output()
con uscita:
display(crawls_by_config)
if len(crawls_by_config.values()) == 0:
print('Nessuna scansione live trovata in questo progetto')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, names='valore')
display(dropdown_crawl_configs)Quando questo codice viene eseguito, l'API Oncrawl ci risponderà con l'elenco delle scansioni discendendo la proprietà "created at".
Quindi, poiché vogliamo concentrarci solo sulle scansioni terminate, analizzeremo l'elenco delle scansioni. Per ogni singola scansione con stato "fatto", salveremo il nome del profilo di scansione e memorizzeremo l'ID di scansione.
Manterremo al massimo un profilo di scansione per scansione in modo da non voler esporre troppe scansioni.
Il risultato è questo nuovo menu a discesa creato dall'elenco dei profili di scansione nel progetto. Sceglieremo quello che vogliamo. Questo richiederà l'ultima scansione eseguita dal team di marketing: 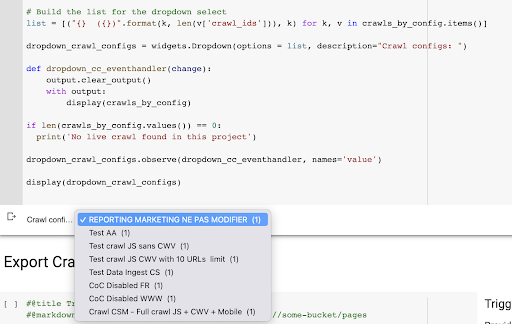
4. Identifica l'ultima scansione con il profilo che desideriamo utilizzare
Abbiamo già l'ID di scansione associato all'ultima scansione nel profilo scelto. È nascosto nel dizionario degli oggetti "crawl_by_config". 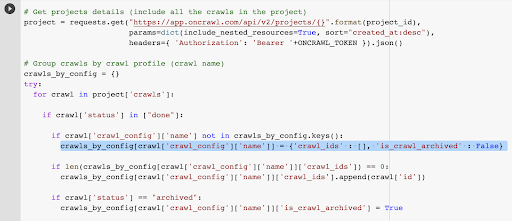
Puoi verificarlo facilmente nell'interfaccia: trova l'ultima scansione completata in questa analisi del profilo. 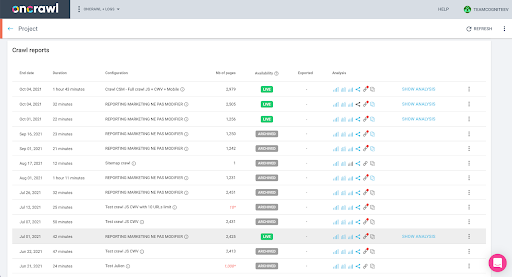
Se facciamo clic per visualizzare l'analisi, vedremo che l'ID di scansione termina con E617. 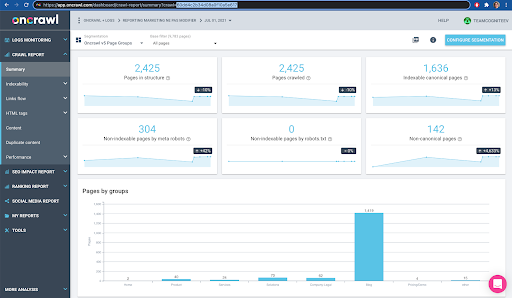
Prendiamo nota dell'ID di scansione ai fini della dimostrazione di oggi.
Naturalmente, se sai già cosa stai facendo, puoi saltare i passaggi appena descritti per chiamare l'API Oncrawl in modo da ottenere l'elenco dei progetti e l'elenco delle scansioni per profilo di scansione: hai già l'ID di scansione dal interfaccia e questo ID è tutto ciò che serve per eseguire l'esportazione.
I passaggi che abbiamo eseguito finora sono semplicemente quelli di facilitare il processo di ottenimento dell'ultima scansione del profilo di scansione specificato del progetto specificato, in base a ciò a cui ha accesso la chiave API. Questo può essere utile se stai fornendo questa soluzione ad altri utenti o se stai cercando di automatizzarla.
5. Esporta i risultati della scansione
Ora esamineremo il comando di esportazione:
#@title Attiva l'esportazione di bigdata
#@markdown Fornisci il tuo bucket GCS e il prefisso gs://some-bucket/pages
# IL TUO SECCHIO GCS
gcs_bucket = #@param {tipo:"stringa"}
gcs_prefix = #@param {tipo:"stringa"}
# Ottieni l'ultimo ID di scansione da un determinato progetto/profilo di scansione
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# Carico utile del modello per la query di esportazione dei dati
carico utile = {
"esportazione_dati": {
"data_type": 'pagina',
"resource_id": last_crawl_id,
"output_format": 'parquet',
"bersaglio": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
# Attiva l'esportazione
export = request.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Autorizzazione': 'Bearer '+ONCRAWL_TOKEN }).json()
# Visualizza la risposta dell'API
visualizzare (esportare)
# Memorizza l'ID di esportazione per un utilizzo futuro
export_id = export['data_export']['id']Vogliamo esportare nel bucket Cloud Storage che abbiamo impostato in precedenza.
All'interno di ciò esporteremo le pagine per l'ultimo ID di scansione:
- L'ultimo ID di scansione è ottenuto dall'elenco di ID di scansione, che è archiviato da qualche parte nel dizionario "crawls_by_config", creato nel passaggio 3.
- Vogliamo scegliere quello corrispondente al menu a tendina del passaggio 4, quindi utilizziamo l'attributo value del menu a tendina.
- Quindi, estraiamo l'attributo crawl_ID. Questa è una lista. Manterremo i primi 50 elementi nell'elenco. Dobbiamo farlo perché nel passaggio 2, come ricorderete, quando abbiamo creato il dizionario crawls_by_config, abbiamo memorizzato solo un ID di scansione per nome di configurazione.
Ho impostato i campi di input per semplificare la fornitura del bucket e del prefisso di Google Cloud Storage, o cartella, a cui vogliamo inviare l'esportazione. 
Ai fini della dimostrazione, oggi scriveremo nella cartella "set di dati misti", in una delle cartelle che ho già impostato. Quando impostiamo il nostro bucket in Google Cloud Storage, ti ricorderai che ho preparato le cartelle per l'esportazione dei "link" e per l'esportazione delle "pagine".
Per la prima esportazione, vorremo esportare le pagine nella cartella "pagine" per l'ultimo ID di scansione utilizzando il formato di file Parquet. 
Nei risultati seguenti, vedrai il payload che deve essere inviato all'endpoint di esportazione dei dati, che è l'endpoint per richiedere un'esportazione di Big Data utilizzando una chiave API:
# Carico utile del modello per la query di esportazione dei dati
carico utile = {
"esportazione_dati": {
"data_type": 'pagina',
"resource_id": last_crawl_id,
"output_format": 'parquet',
"bersaglio": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
Questo contiene diversi elementi, incluso il tipo di set di dati che desideri esportare. È possibile esportare il set di dati della pagina, il set di dati del collegamento, il set di dati dei cluster o il set di dati dei dati strutturati. Se non sai cosa si può fare, puoi inserire qui un errore e quando chiami l'API riceverai un messaggio che indica che la scelta del tipo di dati deve essere pagina o collegamento o cluster o dati strutturati. Il messaggio si presenta così:

{'fields': [{'message': 'Scelta non valida. Deve essere uno di "page", "link", "cluster", "structured_data".',
'nome': 'tipo_dati',
'tipo': 'scelta_non valida'}],
'tipo': 'invalid_request_parameters'}
Ai fini dell'esperimento di oggi, esporteremo il set di dati della pagina e il set di dati del collegamento in esportazioni separate.
Iniziamo con il set di dati della pagina. Quando eseguo questo blocco di codice, ho stampato l'output della chiamata API, che assomiglia a questo:
{'data_export': {'data_type': 'pagina',
'export_failure_reason': Nessuno,
'id': 'XXXXXXXXXXXXXX',
'output_format': 'parquet',
'output_format_parameters': Nessuno,
'output_row_count': Nessuno,
'output_size_in_byte: 1634460016000,
'id_risorsa': '60dd4c2b34d08a0f10a5e617',
'stato': 'RICHIESTO',
'bersaglio': 'gcs',
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/pagine/'}}}
Questo mi permette di vedere che l'esportazione è stata richiesta.
Se vogliamo controllare lo stato dell'esportazione, è molto semplice. Utilizzando l'ID di esportazione che abbiamo salvato alla fine di questo blocco di codice, possiamo richiedere lo stato dell'esportazione in qualsiasi momento con la seguente chiamata API:
# STATO DELL'ESPORTAZIONE
export_status = request.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Autorizzazione': 'Bearer '+ONCRAWL_TOKEN }).json ()
display(export_status)
Ciò indicherà uno stato come parte dell'oggetto JSON restituito:
{'data_export': {'data_type': 'pagina',
'export_failure_reason': Nessuno,
'id': 'XXXXXXXXXXXXXX',
'output_format': 'parquet',
'output_format_parameters': Nessuno,
'output_row_count': Nessuno,
'output_size_in_bytes': Nessuno,
'richiesto_a': 1638350549000,
'id_risorsa': '60dd4c2b34d08a0f10a5e617',
'stato': 'ESPORTAZIONE',
'bersaglio': 'gcs',
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASETS/pagine/'}}} Quando l'esportazione è completa ( 'status': 'DONE' ), possiamo tornare a Google Cloud Storage.
Se guardiamo nel nostro secchio e andiamo nella cartella "links", non c'è ancora nulla qui perché abbiamo esportato le pagine. 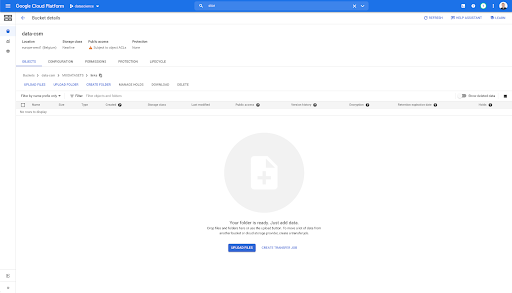
Tuttavia, quando guardiamo nella cartella "pagine", possiamo vedere che l'esportazione è riuscita. Abbiamo un file Parquet: 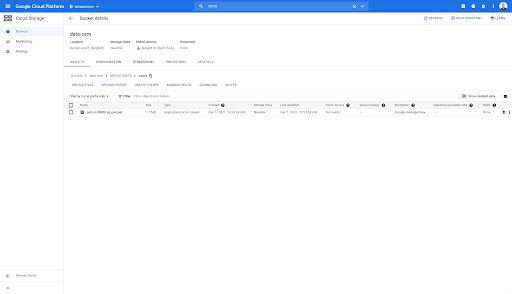
A questo punto, il set di dati delle pagine è pronto per l'importazione in BigQuery, ma prima ripeteremo i passaggi precedenti per ottenere il file Parquet per i collegamenti:
- Assicurati di impostare il prefisso dei collegamenti.
- Scegli il tipo di dati "link".
- Esegui nuovamente questo blocco di codice per richiedere la seconda esportazione.

Questo produrrà un file Parquet nella cartella "links".
Creazione di set di dati BigQuery
Durante l'esportazione, possiamo andare avanti e iniziare a creare set di dati in BigQuery e importare i file Parquet in tabelle separate. Quindi uniremo i tavoli insieme.
Quello che vogliamo fare ora è giocare con Google Big Query, che è qualcosa disponibile come parte di Google Cloud Platform. Puoi utilizzare la barra di ricerca nella parte superiore dello schermo o andare direttamente su https://console.cloud.google.com/bigquery.
Creazione di un set di dati per il tuo lavoro
Dovremo creare un set di dati all'interno di Google BigQuery: 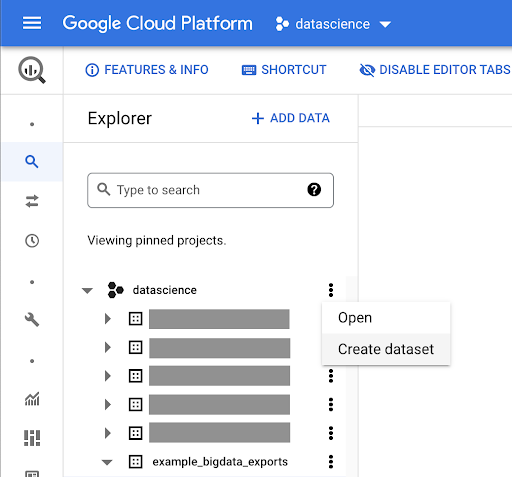
Dovrai fornire un nome al set di dati e scegliere la posizione in cui verranno archiviati i dati. Questo è importante perché condizionerà il luogo in cui vengono elaborati i dati e non può essere modificato. Ciò può avere un impatto se i tuoi dati includono informazioni coperte dal GDPR o da altre leggi sulla privacy. 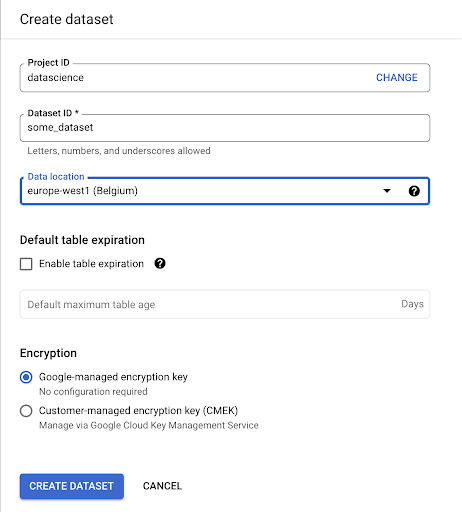
Questo set di dati è inizialmente vuoto. Quando lo apri, sarai in grado di creare una tabella, condividere il set di dati, copiare, eliminare e così via.
Creazione di tabelle per i tuoi dati
Creeremo una tabella in questo set di dati. 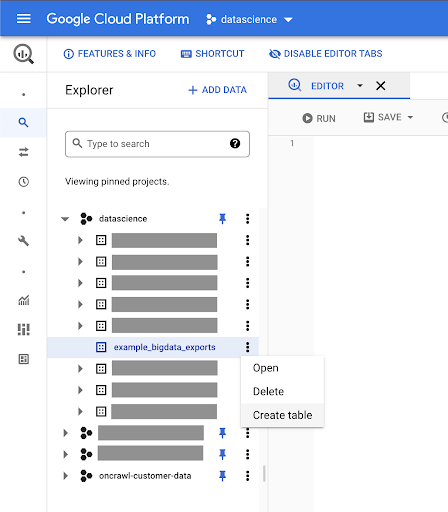
Puoi creare una tabella vuota e quindi fornire lo schema. Lo schema è la definizione delle colonne nella tabella. Puoi definirne uno tuo oppure sfogliare Google Cloud Storage per scegliere uno schema da un file.
Useremo quest'ultima opzione. Passeremo al nostro secchio, quindi alla cartella "pagine". Scegliamo il file delle pagine. C'è un solo file, quindi possiamo selezionarne solo uno, ma se l'esportazione avesse generato più file, avremmo potuto sceglierli tutti. 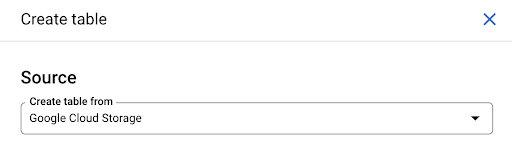
Quando selezioniamo il file, rileva automaticamente che è in formato file Parquet. Vogliamo creare una tabella denominata "pagine" e lo schema sarà definito dal file di origine. 
Quando carichiamo un file Parquet, incorpora uno schema. In altre parole, la definizione delle colonne della tabella che stiamo creando sarà dedotta dallo schema già esistente all'interno del file Parquet. È qui che avviene effettivamente una parte della magia.
Andiamo avanti e creiamo semplicemente la tabella dal file Parquet. 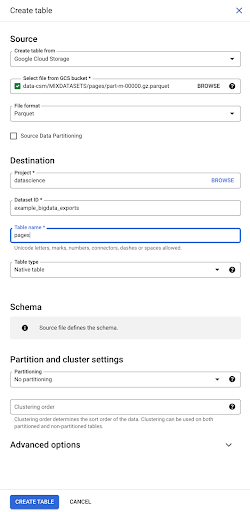
Nella barra laterale di sinistra, ora possiamo vedere che una tabella è apparsa nel nostro set di dati, che è esattamente quello che vogliamo:
Quindi, abbiamo ora lo schema della tabella delle pagine con tutti i campi che sono stati automaticamente dedotti dal file Parquet. Abbiamo l'Inrank, la profondità della pagina, se la pagina è un reindirizzamento e così via: 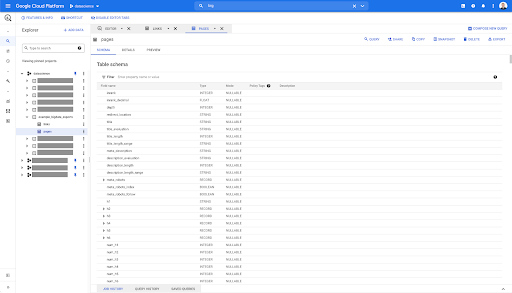
La maggior parte di questi campi sono gli stessi di quelli resi disponibili in Data Studio tramite il connettore Oncrawl Data Studio e gli stessi che vedi in Esplora dati nell'interfaccia di Oncrawl. 
Tuttavia, ci sono alcune differenze. Quando giochiamo con l'esportazione di big data grezzi, hai tutti i dati grezzi.
- In Data Studio, alcuni campi vengono rinominati, alcuni campi vengono nascosti e alcuni campi vengono aggiunti, ad esempio lo stato.
- In Esplora dati, alcuni campi sono quelli che chiamiamo "campi virtuali", il che significa che possono essere una sorta di collegamento a un campo sottostante. Questi campi virtuali disponibili in Esplora dati non verranno elencati nello schema, ma possono essere ricreati in base a ciò che è disponibile nel file Parquet.
Ora chiudiamo questa tabella e facciamolo di nuovo per i collegamenti.
Per la tabella dei collegamenti, lo schema è un po' più piccolo. 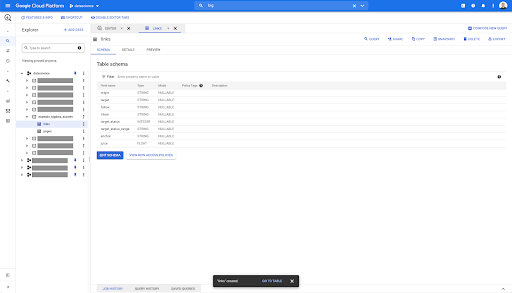
Contiene solo i seguenti campi:
- L'origine del collegamento,
- La destinazione del collegamento,
- La seguente proprietà,
- La proprietà interna,
- Lo stato di destinazione,
- L'intervallo dello stato di destinazione,
- Il testo di ancoraggio, e
- Il succo o l'equità acquistata dal collegamento.
In qualsiasi tabella in BigQuery, quando fai clic sulla scheda di anteprima, hai un'anteprima della tabella senza eseguire query sul database: 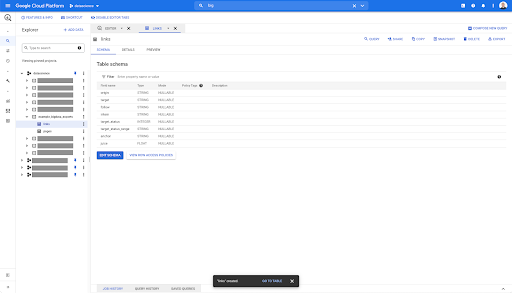
Questo ti dà una rapida visione di ciò che è disponibile in esso. Nell'anteprima per la tabella dei collegamenti sopra, hai un'anteprima di ogni singola riga e di tutte le colonne.
In alcuni set di dati Oncrawl, potresti vedere alcune righe che si estendono su più righe. Non ho un esempio per te, ma se questo è il caso, è perché alcuni campi contengono un elenco di valori. Ad esempio, nell'elenco delle intestazioni h2 di una pagina, una singola riga si estenderà su più righe in Big Query. Lo vedremo più avanti se vediamo un esempio.
Creazione della tua richiesta
Se non hai mai creato una query in BigQuery, ora è il momento di giocarci per familiarizzare con il suo funzionamento. BigQuery utilizza SQL per cercare i dati.
Come funzionano le query
Ad esempio, diamo un'occhiata a tutti gli URL e al loro inrank...
SELEZIONA URL, inrank...
dal dataset delle pagine…
SELECT URL, inrank DA `datascience-oncrawl.example_bigdata_exports.pages` ...
dove il codice di stato della pagina è 200...
SELECT url, inrank DA `datascience-oncrawl.example_bigdata_exports.pages` DOVE status_code = 200 ...
e mantieni solo i primi 10 risultati:
SELECT url, inrank DA `datascience-oncrawl.example_bigdata_exports.pages` DOVE status_code = 200 LIMITE 10
Quando eseguiamo questa query, otterremo le prime 10 righe dell'elenco di pagine in cui il codice di stato è 200.
Ognuna di queste proprietà può essere modificata. f Voglio 1000 righe invece di 10, posso impostare 1000 righe:
SELECT url, inrank DA `datascience-oncrawl.example_bigdata_exports.pages` DOVE status_code = 200 LIMITE 1000
Se voglio ordinare, posso farlo con "order-by": questo mi darà tutte le righe ordinate in ordine decrescente Inrank.
SELECT url, inrank DA `datascience-oncrawl.example_bigdata_exports.links` ORDINA PER inrank DESC LIMITE 1000
Questa è la mia prima domanda. Posso salvarlo se voglio, il che mi darà la possibilità di riutilizzare questa query in seguito se voglio: 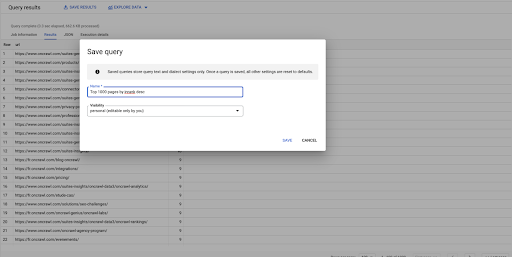
Utilizzo di query per rispondere a semplici domande: elenco di tutti i collegamenti interni a pagine con stato 301
Ora che sappiamo come comporre una query, torniamo al nostro problema originale.
Volevamo rispondere a domande sui dati, semplici o complesse. Iniziamo con una semplice domanda, ad esempio "quali sono tutti i link interni che puntano a pagine con stato 301 (reindirizzato) e dove posso trovarli?"
Creazione di una nuova query
Inizieremo esplorando come funziona.
Voglio colonne per i seguenti elementi dal database "link":
- Origine
- Obbiettivo
- Codice di stato della destinazione
SELEZIONA origine, destinazione, stato_destinazione DA `datascience-oncrawl.example_bigdata_exports.links`
Voglio limitarli ai soli collegamenti interni, ma immaginiamo di non ricordare il nome della colonna o il valore che indica se il collegamento è interno o esterno. Posso andare allo schema per cercarlo e utilizzare l'anteprima per visualizzare il valore: 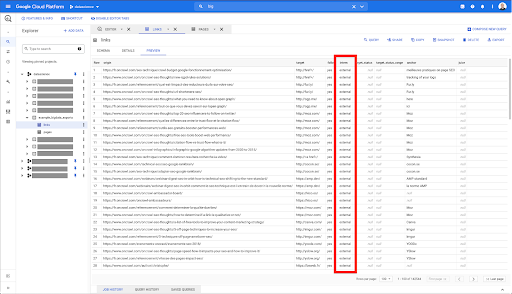
Questo mi dice che la colonna si chiama "interni" e il possibile intervallo di valori è "esterno" o "interno".
Nella mia query, voglio specificare "dove lo stagista è interno" e per ora limitare i risultati ai primi 100:
SELECT origine, destinazione, target_status DA `datascience-oncrawl.example_bigdata_exports.links` DOVE stagista LIKE 'interno' LIMITE 100
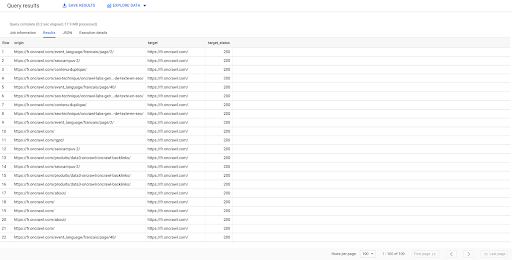
Il risultato sopra mostra l'elenco dei collegamenti con il loro stato di destinazione. Abbiamo solo collegamenti interni e ne abbiamo 100, come specificato nella query.
Se vogliamo avere solo collegamenti interni a quel punto verso pagine reindirizzate, potremmo dire "dove stagista come interno e lo stato target è uguale a 301":
SELEZIONA origine, destinazione, target_status DA `datascience-oncrawl.example_bigdata_exports.links` DOVE stagista COME 'interno' AND target_status = 301
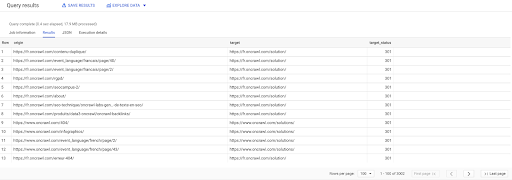
Se non sappiamo quanti ne esistono, possiamo eseguire questa nuova query e vedremo che ci sono 3002 collegamenti interni con uno stato target di 301.
Unirsi ai tavoli: trovare i codici di stato finali dei collegamenti che puntano a pagine reindirizzate
Su un sito web, hai spesso collegamenti a pagine che vengono reindirizzate. Vogliamo conoscere il codice di stato della pagina a cui vengono reindirizzati (o l'URL di destinazione finale).
In un set di dati, hai le informazioni sui collegamenti: la pagina di origine, la pagina di destinazione e il suo codice di stato (come 301), ma non l'URL a cui punta una pagina reindirizzata. E nell'altro, hai le informazioni sui reindirizzamenti e sui loro target finali, ma non la pagina originale in cui è stato trovato il collegamento ad essi.
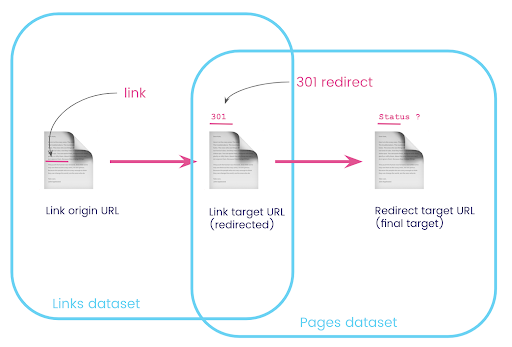
Analizziamo questo:
Innanzitutto, vogliamo collegamenti ai reindirizzamenti. Scriviamo questo. Vogliamo:
- L'origine.
- Il bersaglio. Il target deve avere un codice di stato 301.
- L'obiettivo finale del reindirizzamento.
In altre parole, nel dataset links, vogliamo:
- L'origine del collegamento
- La destinazione del collegamento
Nel dataset delle pagine, vogliamo:
- Tutti i target che vengono reindirizzati
- L'obiettivo finale del reindirizzamento
Questo ci darà una domanda come:
SELECT url, final_redirect_location, final_redirect_status DA `datascience-oncrawl.example_bigdata_exports.pages` COME pagine DOVE status_code = 301 OR status_code = 302
Questo dovrebbe darmi la prima parte dell'equazione.
Ora ho bisogno di tutti i collegamenti che collegano alla pagina che sono i risultati della query che ho appena creato, utilizzando alias per i miei set di dati e unendoli sull'URL di destinazione del collegamento e sull'URL della pagina. Ciò corrisponde all'area di sovrapposizione dei due set di dati nel diagramma all'inizio di questa sezione.
SELEZIONARE link.origine, pagine.url, pages.final_redirect_location, pagine.final_redirect_status DA Pagine AS `datascience-oncrawl.example_bigdata_exports.pages` GIUNTURA Collegamenti AS `datascience-oncrawl.example_bigdata_exports.links` SU links.target = pagine.url DOVE pagine.codice_stato = 301 OPPURE pages.status_code = 302 ORDINATO DA origine ASC
Nei risultati della query, posso rinominare le colonne per rendere le cose più chiare, ma posso già vedere che ho un collegamento da una pagina nella prima colonna, che va alla pagina nella seconda colonna, che a sua volta viene reindirizzata a la pagina nella terza colonna. Nella quarta colonna, ho il codice di stato del target finale: 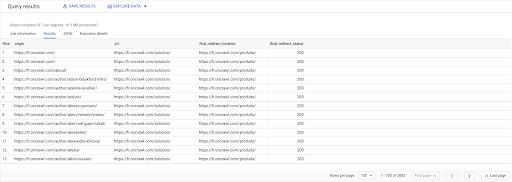
Ora posso dire quali collegamenti puntano a pagine reindirizzate che non risolvono a 200 pagine. Forse sono 404, ad esempio, il che mi dà un elenco prioritario di collegamenti da correggere.
Abbiamo visto in precedenza come salvare una query. Possiamo anche salvare i risultati, per un massimo di 16000 righe di risultati: 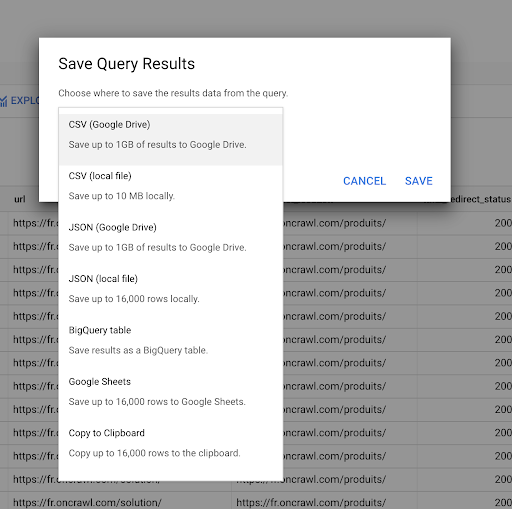
Possiamo quindi utilizzare questi risultati in molti modi diversi. Ecco alcuni esempi:
- Possiamo salvarlo come file CSV o JSON localmente.
- Possiamo salvarlo come foglio di lavoro di Fogli Google e condividerlo con il resto del team.
- Possiamo anche esportarlo direttamente in Data Studio.
I dati come vantaggio strategico
Con tutte queste possibilità, utilizzare strategicamente le risposte alle tue domande complesse è facile. Potresti già avere esperienza nella connessione dei risultati di BigQuery a Data Studio o ad altre piattaforme di visualizzazione dei dati, oppure potresti già disporre di un processo in atto che invia le informazioni a un team di ingegneri o persino a un flusso di lavoro di business intelligence o analisi dei dati.
Se hai incluso i passaggi in questo articolo come parte di un processo, ricorda che puoi automatizzare tutti i passaggi in BigQuery: tutte le azioni che abbiamo eseguito in questo articolo sono accessibili anche tramite l'API BigQuery. Ciò significa che possono essere eseguiti a livello di codice come parte di uno script o di uno strumento personalizzato.
Qualunque siano i tuoi prossimi passi, il primo passo è sempre l'accesso alla SEO grezza e ai dati del sito web. Crediamo che questo accesso ai dati sia una delle parti più importanti dell'analisi tecnica: con Oncrawl avrai sempre pieno accesso ai tuoi dati grezzi.
L'accesso ai dati significa anche che puoi andare oltre ciò che è possibile nell'interfaccia di Oncrawl ed esplorare tutte le relazioni tra i tuoi dati, indipendentemente dalla complessità delle domande che stai ponendo.