
Apa itu Vektor Kata & Bagaimana Markup Terstruktur membuatnya lebih mahal
Diterbitkan: 2021-07-28Bagaimana Anda mendefinisikan vektor kata? Dalam posting ini, saya akan memperkenalkan Anda pada konsep vektor kata. Kami akan membahas berbagai jenis penyisipan kata, dan yang lebih penting, cara kerja vektor kata. Kami kemudian akan dapat melihat dampak vektor kata pada SEO, yang akan mengarahkan kami untuk memahami bagaimana markup Schema.org untuk data terstruktur dapat membantu Anda memanfaatkan vektor kata dalam SEO.
Teruslah membaca posting ini jika Anda ingin mempelajari lebih lanjut tentang topik ini.
Mari kita selami.
Apa itu vektor kata?
Vektor kata (juga disebut Word embeddings) adalah jenis representasi kata yang memungkinkan kata-kata dengan arti yang sama memiliki representasi yang sama.
Secara sederhana: Vektor kata adalah representasi vektor dari kata tertentu.
Menurut Wikipedia:
Ini adalah teknik yang digunakan dalam pemrosesan bahasa alami (NLP) untuk mewakili kata-kata untuk analisis teks, biasanya sebagai vektor bernilai nyata yang mengkodekan arti kata sehingga kata-kata yang dekat dalam ruang vektor cenderung memiliki arti yang sama.
Contoh berikut akan membantu kita memahami hal ini dengan lebih baik:
Perhatikan kalimat serupa ini:
Semoga harimu menyenangkan . dan semoga harimu menyenangkan.
Mereka hampir tidak memiliki arti yang berbeda. Jika kita menyusun kosakata yang lengkap (sebut saja V), itu akan memiliki V = {Have, a, good, great, day} yang menggabungkan semua kata. Kita bisa mengkodekan kata sebagai berikut.
Representasi vektor dari sebuah kata mungkin merupakan vektor enkode satu-panas di mana 1 mewakili posisi di mana kata itu ada dan 0 mewakili sisanya
Memiliki = [1,0,0,0,0]
a=[0,1,0,0,0]
bagus=[0,0,1,0,0]
hebat=[0,0,0,1,0]
hari=[0,0,0,0,1]
Misalkan kosakata kita hanya memiliki lima kata: Raja, Ratu, Pria, Wanita, dan Anak. Kita bisa mengkodekan kata-kata sebagai:
Raja = [1,0,0,0,0]
Ratu = [0,1,0,0,0]
Pria = [0,0,1,00]
Wanita = [0,0,0,1,0]
Anak = [0,0,0,0,1]
Jenis Penyematan Kata (Vektor Kata)
Word Embedding adalah salah satu teknik di mana vektor mewakili teks. Berikut adalah beberapa jenis penyematan kata yang lebih populer:
- Penyematan berbasis frekuensi
- Penyematan berdasarkan prediksi
Kami tidak akan membahas lebih dalam tentang Penyematan Berbasis Frekuensi dan Penyematan Berbasis Prediksi di sini, tetapi Anda mungkin menemukan panduan berikut berguna untuk memahami keduanya:
Pemahaman Intuitif Penyematan Kata dan Pengenalan Singkat Bag-of-Words (BOW) dan TF-IDF untuk Membuat Fitur dari Teks
Pengantar singkat untuk WORD2Vec
Sementara Penyematan Berbasis Frekuensi telah mendapatkan popularitas, masih ada kekosongan dalam memahami konteks kata dan terbatas dalam representasi kata mereka.
Penyematan Berbasis Prediksi (WORD2Vec) dibuat, dipatenkan, dan diperkenalkan ke komunitas NLP pada tahun 2013 oleh tim peneliti yang dipimpin oleh Tomas Mikolov di Google.
Menurut Wikipedia, algoritma word2vec menggunakan model jaringan saraf untuk mempelajari asosiasi kata dari kumpulan teks yang besar (kumpulan teks yang besar dan terstruktur).
Setelah dilatih, model tersebut dapat mendeteksi kata-kata sinonim atau menyarankan kata-kata tambahan untuk kalimat parsial. Misalnya, dengan Word2Vec, Anda dapat dengan mudah membuat hasil seperti ini: Raja – pria + wanita = Ratu, yang dianggap sebagai hasil yang hampir ajaib.
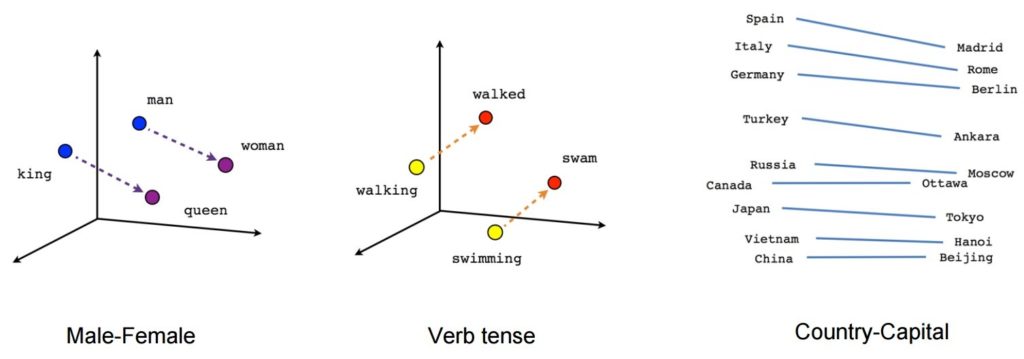 Sumber gambar: Tensorflow
Sumber gambar: Tensorflow
- [raja] – [pria] + [wanita] ~= [ratu] (cara berpikir lain tentang ini adalah bahwa [raja] – [ratu] hanya mengkodekan bagian gender dari [raja])
- [berjalan] – [berenang] + [berenang] ~= [berjalan] (atau [berenang] – [berenang] hanya menyandikan “past-tense-ness” dari kata kerja)
- [madrid] – [spanyol] + [perancis] ~= [paris] (atau [madrid] – [spanyol] ~= [paris] – [perancis] yang kira-kira kira-kira “ibu kota”)
Sumber: Brainslab Digital
Saya tahu ini sedikit teknis, tetapi Stitch Fix menyusun posting fantastis tentang hubungan semantik dan vektor kata.
Algoritma Word2Vec bukanlah algoritma tunggal tetapi kombinasi dari dua teknik yang menggunakan beberapa metode AI untuk menjembatani pemahaman manusia dan pemahaman mesin. Teknik ini penting dalam memecahkan banyak NLP masalah.
Kedua teknik tersebut adalah:
- – CBOW (Kantong kata terus menerus) atau model CBOW
- - Model lewati gram.
Keduanya adalah jaringan saraf dangkal yang memberikan probabilitas untuk kata-kata dan telah terbukti membantu dalam tugas-tugas seperti perbandingan kata dan analogi kata.
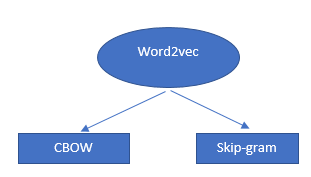
Cara kerja vektor kata dan word2vecs
Word Vector adalah model AI yang dikembangkan oleh Google, dan membantu kami menyelesaikan tugas NLP yang sangat kompleks.
“Model Word Vector memiliki satu tujuan utama yang harus Anda ketahui:
Ini adalah algoritme yang membantu Google dalam mendeteksi hubungan semantik antar kata.”
Setiap kata dikodekan dalam vektor (sebagai angka yang diwakili dalam beberapa dimensi) untuk mencocokkan vektor kata yang muncul dalam konteks yang sama. Oleh karena itu vektor padat dibentuk untuk teks.
Model vektor ini memetakan frasa yang mirip secara semantik ke titik terdekat berdasarkan kesetaraan, kesamaan, atau keterkaitan ide dan bahasa
[Studi Kasus] Mendorong pertumbuhan di pasar baru dengan SEO pada halaman
 Baca studi kasus
Baca studi kasusWord2Vec- Bagaimana cara kerjanya?
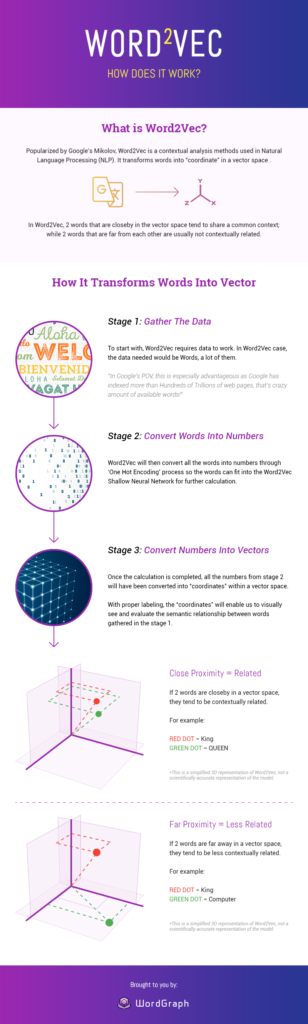
Sumber gambar: Seopressor
Pro dan Kontra Word2Vec
Kita telah melihat bahwa Word2vec adalah teknik yang sangat efektif untuk menghasilkan kesamaan distribusi. Saya telah mencantumkan beberapa keunggulan lainnya di sini:
- Tidak ada kesulitan memahami konsep Word2vec. Word2Vec tidak begitu rumit sehingga Anda tidak menyadari apa yang terjadi di balik layar.
- Arsitektur Word2Vec sangat kuat dan mudah digunakan. Dibandingkan dengan teknik lain, ini cepat untuk dilatih.
- Pelatihan hampir seluruhnya otomatis di sini, sehingga data yang diberi tag manusia tidak lagi diperlukan.
- Teknik ini bekerja untuk kumpulan data kecil dan besar. Akibatnya, ini adalah model skala yang mudah.
- Jika Anda mengetahui konsepnya, Anda dapat dengan mudah mereplikasi seluruh konsep dan algoritme.
- Ini menangkap kesamaan semantik dengan sangat baik.
- Akurat dan efisien secara komputasi
- Karena pendekatan ini tanpa pengawasan, sangat menghemat waktu dalam hal usaha.
Tantangan Word2Vec
Konsep Word2vec sangat efisien, tetapi Anda mungkin menemukan beberapa poin yang sedikit menantang. Berikut adalah beberapa tantangan yang paling umum.
- Saat mengembangkan model word2vec untuk kumpulan data Anda, debugging bisa menjadi tantangan besar, karena model word2vec mudah dikembangkan tetapi sulit untuk di-debug.
- Itu tidak berurusan dengan ambiguitas. Jadi, dalam kasus kata-kata dengan banyak arti, Embedding akan mencerminkan rata-rata arti ini dalam ruang vektor.
- Tidak dapat menangani kata-kata yang tidak dikenal atau OOV: Masalah terbesar dengan word2vec adalah ketidakmampuan untuk menangani kata-kata yang tidak dikenal atau out-of-vocabulary (OOV).
Word Vectors: Game-changer dalam Search Engine Optimization?
Banyak pakar SEO percaya Word Vector mempengaruhi peringkat situs web dalam hasil mesin pencari.
Selama lima tahun terakhir, Google telah memperkenalkan dua pembaruan algoritme yang memberikan fokus yang jelas pada kualitas konten dan kelengkapan bahasa.
Mari kita mundur selangkah dan berbicara tentang pembaruan:
burung kolibri
Pada tahun 2013, Hummingbird memberi mesin pencari kemampuan analisis semantik. Dengan memanfaatkan dan memasukkan teori semantik dalam algoritma mereka, mereka membuka jalan baru ke dunia pencarian.
Google Hummingbird adalah perubahan terbesar pada mesin pencari sejak Kafein pada tahun 2010. Ini mendapatkan namanya dari "tepat dan cepat".
Menurut Search Engine Land, Hummingbird lebih memperhatikan setiap kata dalam kueri, memastikan bahwa seluruh kueri dipertimbangkan, bukan hanya kata-kata tertentu.

Tujuan utama Hummingbird adalah untuk memberikan hasil yang lebih baik dengan memahami konteks kueri daripada mengembalikan hasil untuk kata kunci tertentu.
“Google Hummingbird dirilis pada September 2013.”
RankBrain
Pada tahun 2015, Google mengumumkan RankBrain, sebuah strategi yang menggabungkan kecerdasan buatan (AI).
RankBrain adalah algoritme yang membantu Google memecah kueri penelusuran yang kompleks menjadi yang lebih sederhana. RankBrain mengonversi kueri penelusuran dari bahasa "manusia" ke dalam bahasa yang dapat dengan mudah dipahami oleh Google.
Google mengkonfirmasi penggunaan RankBrain pada 26 Oktober 2015 dalam sebuah artikel yang diterbitkan oleh Bloomberg.
BERT
Pada 21 Oktober 2019, BERT mulai diluncurkan di sistem pencarian Google
BERT adalah singkatan dari Bidirectional Encoder Representations from Transformers, teknik berbasis jaringan saraf yang digunakan oleh Google untuk pra-pelatihan dalam pemrosesan bahasa alami (NLP).
Singkatnya, BERT membantu komputer memahami bahasa lebih seperti manusia, dan ini adalah perubahan terbesar dalam pencarian sejak Google memperkenalkan RankBrain.
Ini bukan pengganti RankBrain, melainkan metode tambahan untuk memahami konten dan kueri.
Google menggunakan BERT dalam sistem peringkatnya sebagai tambahan. Algoritme RankBrain masih ada untuk beberapa kueri dan akan terus ada. Tetapi ketika Google merasa bahwa BERT dapat lebih memahami kueri, mereka akan menggunakannya.
Untuk informasi lebih lanjut tentang BERT, lihat posting ini oleh Barry Schwartz, serta penyelaman mendalam Dawn Anderson.
Beri peringkat situs Anda dengan Word Vectors
Saya berasumsi Anda telah membuat dan menerbitkan konten unik, dan bahkan setelah memolesnya berulang kali, itu tidak meningkatkan peringkat atau lalu lintas Anda.
Apakah Anda bertanya-tanya mengapa ini terjadi pada Anda?
Mungkin karena Anda tidak menyertakan Word Vector: model AI Google.
- Langkah pertama adalah Mengidentifikasi Vektor Kata dari 10 peringkat SERP teratas untuk niche Anda.
- Ketahui kata kunci apa yang digunakan pesaing Anda dan apa yang mungkin Anda abaikan.
Dengan menerapkan Word2Vec, yang memanfaatkan teknik pemrosesan Bahasa Alami tingkat lanjut dan kerangka kerja pembelajaran mesin, Anda akan dapat melihat semuanya secara detail.
Tetapi ini mungkin jika Anda mengetahui teknik pembelajaran mesin dan NLP, tetapi kita dapat menerapkan vektor kata dalam konten menggunakan alat berikut:
WordGraph, Alat Vektor Kata Pertama di Dunia
Alat kecerdasan buatan ini dibuat dengan Neural Networks for Natural Language Processing dan dilatih dengan Machine Learning.
Berdasarkan Kecerdasan Buatan, WordGraph menganalisis konten Anda dan membantu Anda meningkatkan relevansinya dengan 10 situs web peringkat teratas.
Ini menyarankan kata kunci yang secara matematis dan kontekstual terkait dengan kata kunci utama Anda.
Secara pribadi, saya memasangkannya dengan BIQ, alat SEO yang kuat yang bekerja dengan baik dengan WordGraph.
Tambahkan konten Anda ke alat kecerdasan konten yang ada di Biq. Ini akan menunjukkan kepada Anda seluruh daftar tips SEO di halaman yang dapat Anda tambahkan jika Anda ingin peringkat di posisi teratas.
Anda dapat melihat bagaimana kecerdasan konten bekerja dalam contoh ini. Daftar ini akan membantu Anda menguasai SEO di halaman dan memberi peringkat menggunakan metode yang dapat ditindaklanjuti!
Cara Membebani Vektor Kata: Menggunakan Markup Data Terstruktur
Schema markup, atau data terstruktur, adalah jenis kode (ditulis dalam JSON, Java-Script Object Notation) yang dibuat menggunakan kosakata schema.org yang membantu mesin telusur merayapi, mengatur, dan menampilkan konten Anda.
Bagaimana cara menambahkan data terstruktur
Data terstruktur dapat dengan mudah ditambahkan ke situs web Anda dengan menambahkan skrip sebaris di html Anda
Contoh di bawah ini menunjukkan cara menentukan data terstruktur organisasi Anda dalam format sesederhana mungkin.
Untuk menghasilkan Schema Markup, saya menggunakan Schema Markup Generator (JSON-LD).
Berikut adalah contoh langsung dari markup skema untuk https://www.telecloudvoip.com/. Periksa kode sumber dan cari JSON.
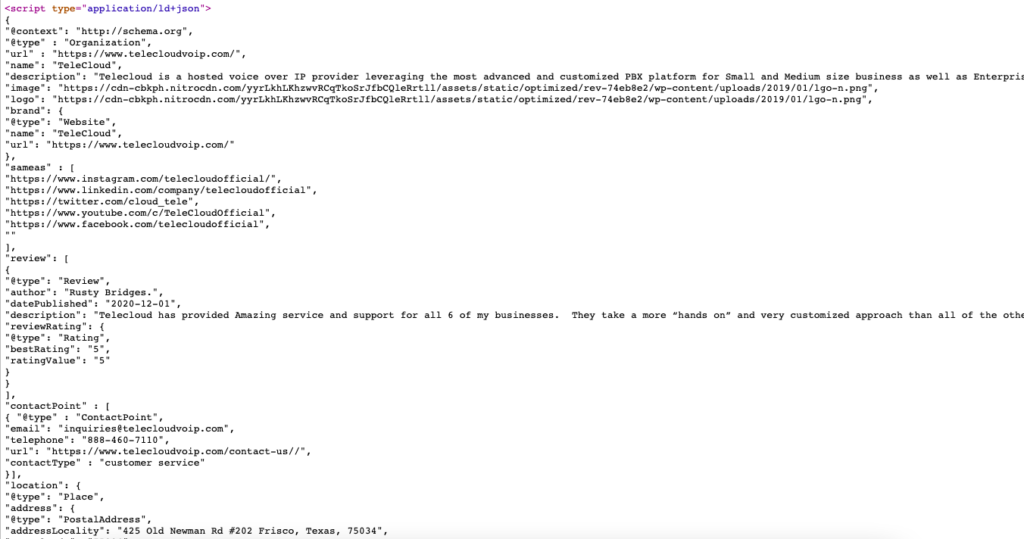
Setelah kode markup skema dibuat, gunakan Pengujian Hasil Kaya Google untuk melihat apakah halaman mendukung hasil kaya.
Anda juga dapat menggunakan alat Audit Situs Semrush untuk menjelajahi item Data Terstruktur untuk setiap URL dan mengidentifikasi halaman mana yang memenuhi syarat untuk berada di Hasil Kaya. 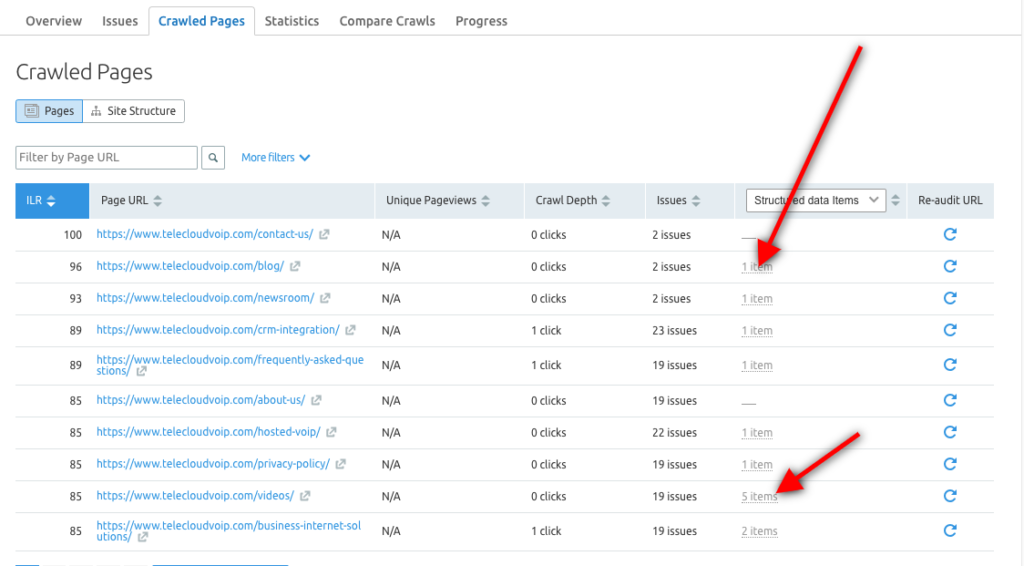
Mengapa Data Terstruktur Penting untuk SEO?
Data Terstruktur penting untuk SEO karena membantu Google memahami tentang apa situs web dan halaman Anda, sehingga menghasilkan peringkat konten yang lebih akurat.
Data Terstruktur meningkatkan pengalaman Bot Pencarian serta pengalaman pengguna dengan meningkatkan SERP (halaman hasil mesin pencari) dengan lebih banyak informasi dan akurasi.
Untuk melihat pengaruhnya di penelusuran Google, buka Search Console dan di bawah Performance > Search Result > Search Appearance, Anda dapat melihat perincian semua jenis hasil kaya seperti "video" dan "FAQ" serta melihat tayangan organik dan klik yang didorongnya untuk konten Anda.
Berikut ini adalah beberapa keuntungan dari data terstruktur:
- Data terstruktur mendukung pencarian semantik
- Ini juga mendukung E‑AT Anda (keahlian, otoritas, dan kepercayaan)
- Memiliki data terstruktur juga dapat meningkatkan rasio konversi, karena lebih banyak orang akan melihat cantuman Anda, yang meningkatkan kemungkinan mereka akan membeli dari Anda.
- Menggunakan data terstruktur, mesin pencari lebih mampu memahami merek Anda, situs web Anda, dan konten Anda.
- Mesin pencari akan lebih mudah membedakan antara halaman kontak, deskripsi produk, halaman resep, halaman acara, dan ulasan pelanggan.
- Dengan bantuan data terstruktur, Google membuat grafik pengetahuan dan panel pengetahuan yang lebih baik dan lebih akurat tentang merek Anda.
- Peningkatan ini dapat menghasilkan lebih banyak tayangan organik dan klik organik.
Data terstruktur saat ini digunakan oleh Google untuk menyempurnakan hasil penelusuran. Saat orang menelusuri halaman web Anda menggunakan kata kunci, data terstruktur dapat membantu Anda mendapatkan hasil yang lebih baik. Mesin pencari akan lebih memperhatikan konten Anda jika kami menambahkan markup Skema.
Anda dapat menerapkan markup skema pada sejumlah item yang berbeda. Tercantum di bawah ini adalah beberapa area di mana skema dapat diterapkan:
- Artikel
- Postingan Blog
- Artikel berita
- Acara
- Produk
- Video
- Jasa
- Ulasan
- Peringkat Agregat
- Restoran
- Bisnis Lokal
Berikut daftar lengkap item yang dapat Anda tandai dengan skema.
Data Terstruktur dengan Penyematan Entitas
Istilah "entitas" mengacu pada representasi dari semua jenis objek, konsep, atau subjek. Entitas dapat berupa orang, film, buku, ide, tempat, perusahaan, atau acara.
Meskipun mesin tidak dapat benar-benar memahami kata-kata, dengan penyematan entitas, mesin dapat dengan mudah memahami hubungan antara raja – ratu = suami – istri
Penyematan entitas berkinerja lebih baik daripada enkode one-hot
Algoritma vektor kata digunakan oleh Google untuk menemukan hubungan semantik antar kata, dan ketika digabungkan dengan data terstruktur, kita akan mendapatkan web yang disempurnakan secara semantik.
Dengan menggunakan data terstruktur, Anda berkontribusi pada web yang lebih semantik. Ini adalah web yang disempurnakan tempat kami mendeskripsikan data dalam format yang dapat dibaca mesin.
Data semantik terstruktur di situs web Anda membantu mesin telusur mencocokkan konten Anda dengan audiens yang tepat. Penggunaan NLP, Machine Learning, dan Deep Learning membantu mengurangi kesenjangan antara apa yang dicari orang dan judul yang tersedia.
Pikiran Akhir
Saat Anda sekarang memahami konsep vektor kata dan pentingnya, Anda dapat membuat strategi pencarian organik Anda lebih efektif dan lebih efisien dengan memanfaatkan vektor kata, embeddings entitas dan data semantik terstruktur.
Untuk mencapai peringkat, lalu lintas, dan konversi tertinggi, Anda harus menggunakan vektor kata, penyematan entitas, dan data semantik terstruktur untuk menunjukkan kepada Google bahwa konten di halaman web Anda akurat, tepat, dan dapat dipercaya.