
Apa Itu Pengindeksan Semantik Laten dan Bagaimana Cara Kerjanya?
Diterbitkan: 2020-04-02Latent Semantic Indexing (LSI) telah lama menjadi perdebatan di antara pemasar pencarian. Google istilah 'pengindeksan semantik laten' dan Anda akan menemukan pendukung dan skeptis dalam ukuran yang sama. Tidak ada konsensus yang jelas tentang manfaat mempertimbangkan LSI dalam konteks pemasaran mesin pencari. Jika Anda tidak terbiasa dengan konsep tersebut, artikel ini akan merangkum perdebatan tentang LSI, sehingga Anda diharapkan dapat memahami apa artinya bagi strategi SEO Anda.
Apa itu Pengindeksan Semantik Laten?
LSI adalah proses yang ditemukan di Natural Language Processing (NLP). NLP adalah bagian dari linguistik dan rekayasa informasi, dengan fokus pada bagaimana mesin menafsirkan bahasa manusia. Bagian penting dari penelitian ini adalah semantik distribusi. Model ini membantu kita memahami dan mengklasifikasikan kata-kata dengan makna kontekstual yang serupa dalam kumpulan data yang besar.
Dikembangkan pada 1980-an, LSI menggunakan metode matematika yang membuat pencarian informasi lebih akurat. Metode ini bekerja dengan mengidentifikasi hubungan kontekstual yang tersembunyi di antara kata-kata. Ini dapat membantu Anda untuk memecahnya seperti ini:
- Laten → Tersembunyi
- Semantik → Hubungan Antar Kata
- Pengindeksan → Pengambilan Informasi
Bagaimana Pengindeksan Semantik Laten Bekerja?
LSI bekerja menggunakan aplikasi parsial Singular Value Decomposition (SVD). SVD adalah operasi matematika yang mereduksi matriks menjadi bagian-bagian penyusunnya untuk perhitungan yang sederhana dan efisien.
Saat menganalisis rangkaian kata, LSI menghilangkan konjungsi, kata ganti, dan kata kerja umum, yang juga dikenal sebagai kata berhenti. Ini mengisolasi kata-kata yang terdiri dari 'isi' utama sebuah frase. Berikut adalah contoh singkat tentang tampilannya:
![]()
Kata-kata ini kemudian ditempatkan dalam Term Document Matrix (TDM). TDM adalah kisi 2D yang mencantumkan frekuensi setiap kata (atau istilah) tertentu muncul dalam dokumen dalam kumpulan data.
Fungsi penimbangan kemudian diterapkan ke TDM. Contoh sederhana adalah mengklasifikasikan semua dokumen yang berisi kata dengan nilai 1 dan semua yang tidak dengan nilai 0. Ketika kata-kata muncul dengan frekuensi umum yang sama dalam dokumen-dokumen ini, itu disebut co-occurrence . Di bawah ini Anda akan menemukan contoh dasar TDM, dan bagaimana TDM menilai kemunculan bersama di beberapa frasa:
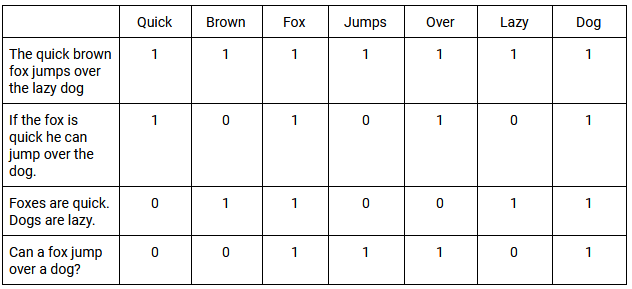
Menggunakan SVD memungkinkan kita untuk memperkirakan pola penggunaan kata di semua dokumen. Vektor SVD yang dihasilkan oleh LSI memprediksi makna lebih akurat daripada menganalisis istilah individu. Pada akhirnya, LSI dapat menggunakan hubungan antar kata untuk lebih memahami arti, atau maknanya, dalam konteks tertentu.
[Studi Kasus] Mendorong pertumbuhan di pasar baru dengan SEO pada halaman
 Baca studi kasus
Baca studi kasusBagaimana Pengindeksan Semantik Laten terlibat dengan SEO?
Pada tahun-tahun pembentukannya, Google menemukan bahwa mesin pencari memberi peringkat situs web berdasarkan frekuensi kata kunci tertentu. Namun, ini tidak menjamin hasil pencarian yang paling relevan. Google malah mulai memberi peringkat situs web yang mereka anggap sebagai penengah informasi tepercaya.
Seiring waktu, algoritme Google akan menyaring situs web berkualitas rendah dan tidak relevan dengan akurasi yang lebih tinggi. Oleh karena itu, pemasar harus memahami makna di balik pencarian, alih-alih mengandalkan kata-kata persis yang digunakan. Inilah sebabnya mengapa Roger Montti menggambarkan LSI sebagai “roda pelatihan untuk mesin telusur” dalam sebuah artikel tentang keyakinan SEO yang sudah ketinggalan zaman, menambahkan bahwa LSI memiliki “relevansi kecil hingga nol dengan bagaimana mesin telusur memberi peringkat situs web saat ini”.
Arti kueri penelusuran terkait erat dengan maksud di baliknya. Google mengelola dokumen yang disebut Pedoman Evaluator Kualitas Penelusuran. Dalam panduan ini, mereka memperkenalkan empat kategori bermanfaat untuk maksud pengguna:
- Know Query – Ini mewakili pencarian informasi tentang suatu topik. Varian dari ini adalah kueri 'Tahu Sederhana', yaitu saat pengguna menelusuri dengan mempertimbangkan jawaban tertentu.
- Do Query – Ini mencerminkan keinginan untuk terlibat dalam aktivitas tertentu, seperti pembelian atau pengunduhan online. Semua pertanyaan ini dapat didefinisikan dengan rasa 'interaksi'.
- Permintaan Situs Web – Ini adalah saat pengguna mencari situs web atau halaman tertentu. Pencarian ini menunjukkan kesadaran sebelumnya dari situs web atau merek tertentu.
- Visit-in-Person Query – Pengguna mencari lokasi fisik, seperti toko fisik atau restoran.
Teori di balik LSI – mendefinisikan makna kontekstual kata di dalam frasa – memberi Google keunggulan kompetitif. Namun, ide mulai menyebar bahwa 'kata kunci LSI' tiba-tiba menjadi tiket emas menuju kesuksesan SEO.

Apakah 'Kata Kunci LSI' benar-benar ada?
Banyak publikasi terkenal tetap menjadi pendukung kuat dari kata kunci LSI. Namun beberapa sumber, seperti Google's Webmaster Trends Analyst John Mueller, menyatakan bahwa itu hanyalah mitos. Sumber-sumber ini mulai mengangkat poin-poin berikut:
- LSI dikembangkan sebelum World Wide Web dan tidak dimaksudkan untuk diterapkan pada kumpulan data yang begitu besar dan dinamis.
- Paten AS pada Latent Semantic Indexing, yang diberikan kepada sebuah organisasi bernama Bell Communications Research Inc. pada tahun 1989, akan berakhir pada tahun 2008. Oleh karena itu, menurut Bill Slawski, Google menggunakan LSI akan sama dengan 'menggunakan perangkat telegraf pintar untuk terhubung ke web seluler.'
- Google menggunakan RankBrain, metode pembelajaran mesin yang mengubah volume teks menjadi 'vektor' – entitas matematika yang membantu komputer memahami bahasa tertulis. RankBrain mengakomodasi web sebagai kumpulan data yang terus berkembang, membuatnya dapat digunakan oleh Google, tidak seperti LSI.
Pada akhirnya, LSI mengungkapkan kebenaran yang harus dipatuhi pemasar: menjelajahi konteks unik kata membantu kami memahami maksud pengguna lebih baik daripada kata kunci yang dimasukkan ke dalam konten. Namun, ini tidak serta merta mengkonfirmasi bahwa peringkat Google berdasarkan LSI. Oleh karena itu, dapatkah dikatakan bahwa LSI bekerja dalam SEO sebagai filosofi, bukan sebagai ilmu pasti?
Mari kembali ke kutipan Roger Montti tentang LSI sebagai “roda pelatihan untuk mesin pencari.” Setelah Anda belajar mengendarai sepeda, Anda cenderung melepas roda latihan. Bisakah kita berasumsi bahwa pada tahun 2020, Google tidak lagi menggunakan roda pelatihan?
Kami dapat mempertimbangkan pembaruan algoritma terbaru Google. Pada Oktober 2019 Pandu Nayak, Vice President of Search, mengumumkan bahwa Google telah mulai menggunakan sistem AI bernama BERT (Bidirectional Encoder Representations from Transformers). Mempengaruhi lebih dari 10% dari semua permintaan pencarian, ini adalah salah satu pembaruan Google terbesar dalam beberapa tahun terakhir.
Saat menganalisis permintaan pencarian, BERT mempertimbangkan satu kata dalam kaitannya dengan semua kata dalam frasa tertentu. Analisis ini bersifat dua arah, karena mempertimbangkan semua kata sebelum atau sesudah kata tertentu. Penghapusan satu kata secara drastis dapat memengaruhi cara BERT memahami konteks unik frasa.
Ini menandai kontras dari LSI, yang menghilangkan kata berhenti dari analisisnya. Contoh di bawah ini menunjukkan bagaimana menghapus stopwords dapat mengubah cara kita memahami sebuah frase:
![]()
Meskipun merupakan kata perhentian, 'temukan' adalah inti pencarian, yang akan kami definisikan sebagai kueri 'kunjungan langsung'.
Jadi apa yang harus dilakukan pemasar?
Awalnya, LSI dianggap dapat membantu Google mencocokkan konten dengan kueri yang relevan. Namun, tampaknya perdebatan dalam pemasaran seputar penggunaan LSI belum mencapai satu kesimpulan. Meskipun demikian, pemasar masih dapat mengambil banyak langkah untuk memastikan pekerjaan mereka tetap relevan secara strategis.
Pertama, artikel, salinan web, dan kampanye berbayar harus dioptimalkan untuk menyertakan sinonim dan varian. Ini menjelaskan cara orang-orang dengan maksud yang sama menggunakan bahasa secara berbeda.
Pemasar harus terus menulis dengan otoritas dan kejelasan. Ini adalah keharusan mutlak jika mereka ingin konten mereka memecahkan masalah tertentu. Masalah ini bisa berupa kurangnya informasi atau kebutuhan akan produk atau layanan tertentu. Setelah pemasar melakukan ini, ini menunjukkan bahwa mereka benar-benar memahami maksud pengguna.
Terakhir, mereka juga harus sering menggunakan data terstruktur. Baik itu situs web, resep, atau FAQ, data terstruktur menyediakan konteks bagi Google untuk memahami apa yang dirayapi.