
[Webinar Digest] SEO di Orbit: Perspektif baru tentang konten duplikat
Diterbitkan: 2019-11-20Webinar Perspektif baru tentang konten duplikat adalah episode terakhir dalam seri SEO in Orbit, dan ditayangkan pada 24 Juni 2019. Dalam episode ini, bergabunglah dengan Duta OnCrawl Omi Sido dan Alexis Sanders saat mereka mengeksplorasi pertanyaan tentang konten duplikat. Mereka menjawab pertanyaan seperti: Bagaimana faktor peringkat dan teknologi penelusuran yang berkembang memengaruhi cara kami menangani konten duplikat? Dan: Apa yang akan terjadi di masa depan untuk konten serupa di web?
SEO di Orbit adalah seri webinar pertama yang mengirimkan SEO ke luar angkasa. Sepanjang seri, kami membahas masa kini dan masa depan SEO teknis dengan beberapa spesialis SEO terbaik dan mengirimkan tip terbaik mereka ke luar angkasa pada 27 Juni 2019.
Tonton tayangan ulangnya di sini:
Mempersembahkan Alexis Sanders
Alexis Sanders bekerja sebagai Manajer Akun SEO Teknis di Merkle. Tim teknis SEO memastikan keakuratan, kelayakan, dan skalabilitas dari rekomendasi teknis agensi di semua vertikal. Dia adalah kontributor blog Moz dan pencipta tantangan TechnicalSEO.expert dan podcast SEO di Lab.
Episode ini dibawakan oleh Omi Sido. Omi adalah pembicara internasional yang berpengalaman dan dikenal di industri ini karena humornya dan kemampuannya untuk menyampaikan wawasan yang dapat ditindaklanjuti yang dapat segera digunakan oleh audiens. Dari konsultasi SEO dengan beberapa perusahaan telekomunikasi dan perjalanan terbesar di dunia hingga mengelola SEO internal di HostelWorld dan Daily Mail, Omi suka menyelami data yang kompleks dan menemukan titik terang. Saat ini, Omi adalah Senior Technical SEO di Canon Europe dan OnCrawl Ambassador.
Apa itu konten duplikat?
Omi memberikan definisi konten duplikat berikut:
Konten duplikat yang mirip atau hampir mirip dengan konten yang ada di URL berbeda di situs web yang sama (atau berbeda).
Mitos Penalti Konten Duplikat
Tidak ada hukuman duplikat konten.
Ini adalah masalah kinerja. Kami tidak ingin bot melihat dua URL tertentu dan berpikir bahwa itu adalah dua konten berbeda yang dapat diberi peringkat di samping satu sama lain.
Alexis membandingkan pemahaman bot tentang situs web Anda dengan gambar Joey dari 10 Hal yang Saya Benci Tentang Anda: bot tidak mungkin menemukan perbedaan material antara kedua versi.

Anda ingin menghindari dua hal yang sama persis yang harus bersaing satu sama lain dalam situasi peringkat mesin pencari. Sebaliknya, Anda ingin memiliki pengalaman tunggal yang terkonsolidasi yang dapat memberi peringkat dan kinerja di mesin telusur.
Perbedaan antara apa yang dilihat pengguna dan bot
Pengguna mungkin melihat satu URL yang meyakinkan, tetapi bot mungkin masih melihat beberapa versi yang pada dasarnya terlihat sama.
– Efek pada anggaran perayapan untuk situs yang sangat besar
Untuk situs yang sangat besar, seperti Zillow atau Walmart, anggaran perayapan dapat bervariasi untuk halaman yang berbeda.
Seperti yang dibahas Alexis dalam artikel 2018 berdasarkan presentasi oleh Frederic Dubut di SMX East, anggaran ditetapkan pada berbagai tingkat–di tingkat subdomain, di tingkat server yang berbeda. Mesin pencari, baik Google atau Bing, ingin menjadi perayap yang sopan; mereka tidak ingin memperlambat kinerja untuk pengguna yang sebenarnya. Setiap kali mereka merasakan perubahan dalam kinerja, mereka akan mundur. Ini dapat terjadi pada tingkat yang berbeda, bukan hanya tingkat situs.
Jika Anda memiliki situs besar, Anda ingin memastikan bahwa Anda memberikan pengalaman terkonsolidasi yang relevan bagi pengguna Anda.
Apakah duplikat konten merupakan konten atau masalah teknis?
Terlepas dari kata "konten" dalam "konten duplikat", itu sebagian merupakan masalah teknis.
– Sumber duplikasi – [07:50]
Ada banyak faktor yang dapat menyebabkan duplikasi. Bahkan sebagian daftar tampaknya berlangsung selamanya:
- halaman berulang
- Situs pementasan
- URL HTTP vs HTTPS
- Subdomain yang berbeda
- kasus yang berbeda
- Ekstensi file yang berbeda
- Garis miring
- halaman indeks
- Parameter URL
- aspek
- mengurutkan
- Versi ramah-printer
- halaman pintu
- Inventaris
- Konten tersindikasi
- Rilis PR
- Menerbitkan ulang konten
- Konten yang dijiplak
- Konten yang dilokalkan
- konten tipis
- Hanya-gambar
- Pencarian situs internal
- Situs seluler terpisah
- Konten yang tidak unik
- …
– Distribusi masalah antara SEO teknis dan konten
Faktanya, sumber duplikat konten ini dapat dibagi menjadi sumber teknis dan pengembangan dan sumber berbasis konten, dan beberapa yang termasuk dalam zona tumpang tindih di antara keduanya.
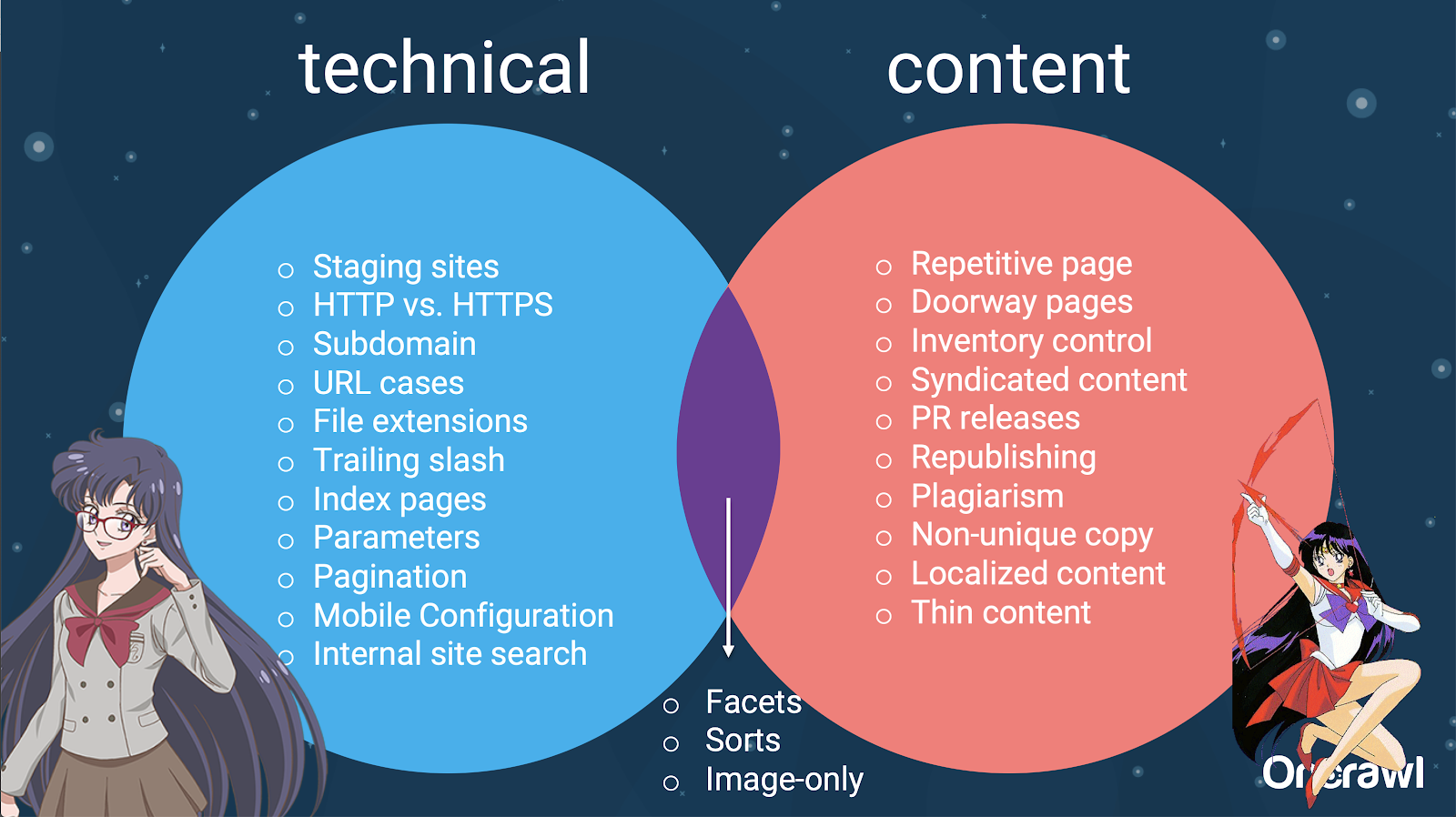
Hal ini membuat konten duplikat menjadi masalah lintas tim, yang merupakan bagian dari apa yang membuatnya begitu menarik.
Cara menemukan konten duplikat
Sebagian besar duplikat konten tidak disengaja. Bagi Omi, ini menunjukkan bahwa ada tanggung jawab bersama antara konten dan tim teknis untuk menemukan dan memperbaiki konten duplikat.
– Alat favorit Omi: Grammarly
Grammarly adalah alat favorit Omi untuk menemukan duplikat konten–dan itu bahkan bukan alat SEO. Dia menggunakan pemeriksa plagiarisme. Dia meminta penerbit konten untuk memeriksa apakah ada konten baru yang telah diterbitkan di tempat lain.
– Volume konten duplikat yang tidak disengaja
Masalah konten duplikat yang tidak disengaja adalah masalah yang sangat akrab dengan para insinyur. Dalam buku berjudul Introduction to Information Retrieval (2008), yang jelas-jelas sudah ketinggalan zaman, mereka memperkirakan bahwa sekitar 40% web pada saat itu telah diduplikasi.

– Memprioritaskan strategi untuk menangani duplikat konten
Untuk menangani konten duplikat, Anda harus:
- Mulailah dengan mengetahui perjalanan pengguna Anda, yang akan membantu Anda memahami di mana setiap konten cocok. Ini bisa sangat sulit dilakukan, terutama ketika situs web dibuat 20 tahun yang lalu, ketika kita tidak tahu seberapa besar mereka nantinya, atau bagaimana skalanya. Mengetahui di mana pengguna Anda berada pada titik tertentu dalam perjalanan mereka akan membantu Anda memprioritaskan beberapa langkah selanjutnya.
- Anda memerlukan hierarki yang berfungsi, untuk menyediakan tempat bagi setiap jenis konten. Memahami arsitektur informasi Anda sangat penting dalam langkah-langkah untuk menangani konten duplikat.
- Prioritaskan duplikat konten yang memengaruhi kinerja. Sebagian daftar sumber di atas terlalu panjang untuk menjadi sesuatu yang dapat Anda serang secara realistis sekaligus.
- Menangani duplikasi 100%
- Sinyal duplikat konten
- Buat pilihan strategis tentang cara menangani duplikasi: konsolidasi, buat, hapus, optimalkan
- Berurusan dengan konten yang dicuri

– Alat: Menggunakan segmentasi di OnCrawl
Alexis sangat menyukai kemampuan untuk mengelompokkan situs web Anda di OnCrawl, yang memungkinkan Anda menyelami hal-hal yang berarti bagi Anda.
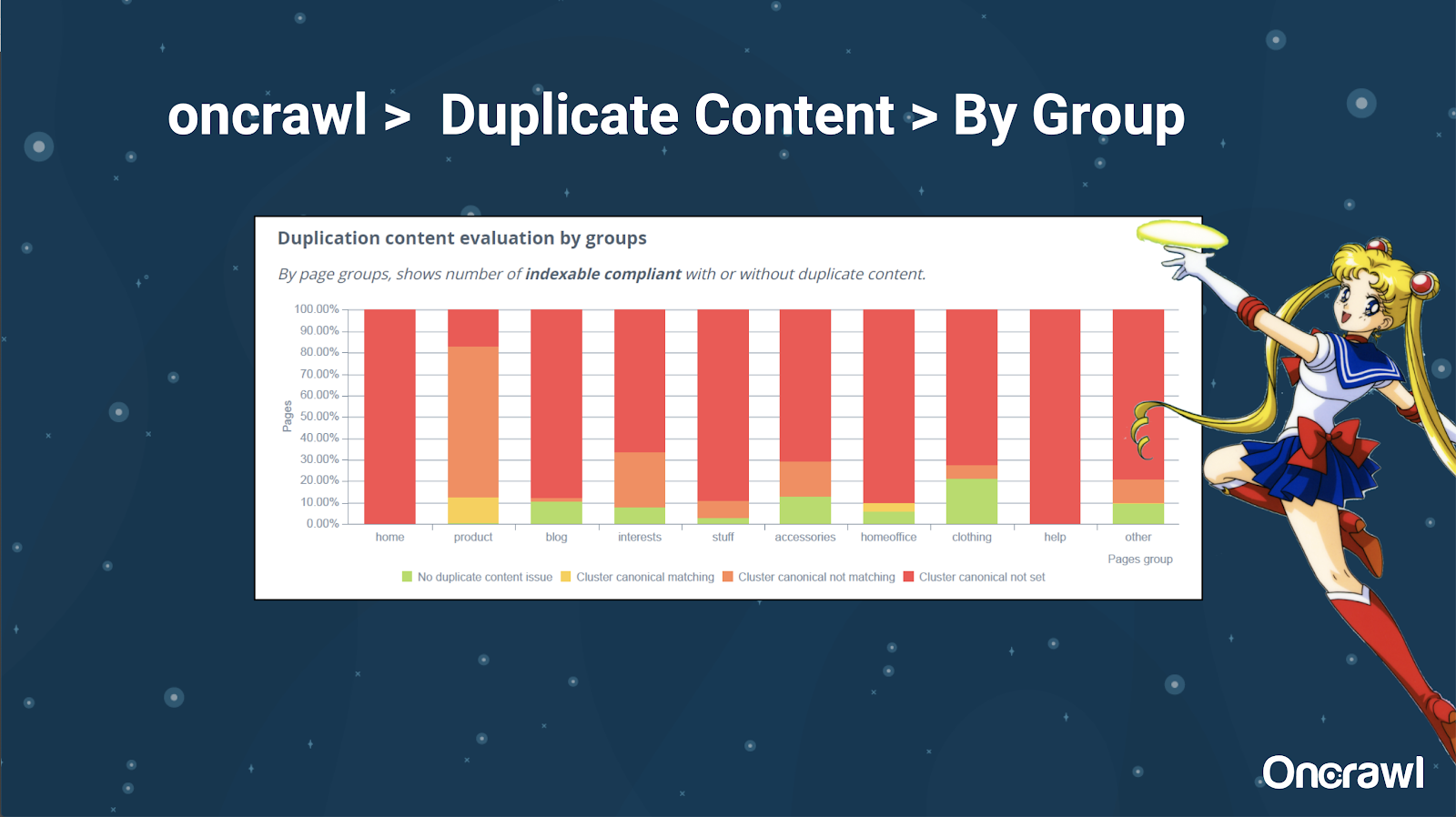
Jenis halaman yang berbeda memiliki jumlah duplikasi yang berbeda; ini memungkinkan untuk mendapatkan tampilan bagian yang memiliki masalah paling banyak. Dalam contoh di atas, situs membutuhkan banyak perhatian.
– Alat: Pencarian Google dan GSC
Anda juga dapat memeriksa duplikat konten menggunakan mesin pencari itu sendiri. Di Google Anda dapat:
- Gunakan kutipan langsung
- Gunakan situs: pencarian
- Menggunakan operator tambahan seperti inurl:, intitle:, atau filetype:

Google Search Console juga telah menambahkan laporan duplikat konten, yang sangat berguna dalam mengidentifikasi apa yang diyakini Google sebagai konten duplikat dari pihak mereka.
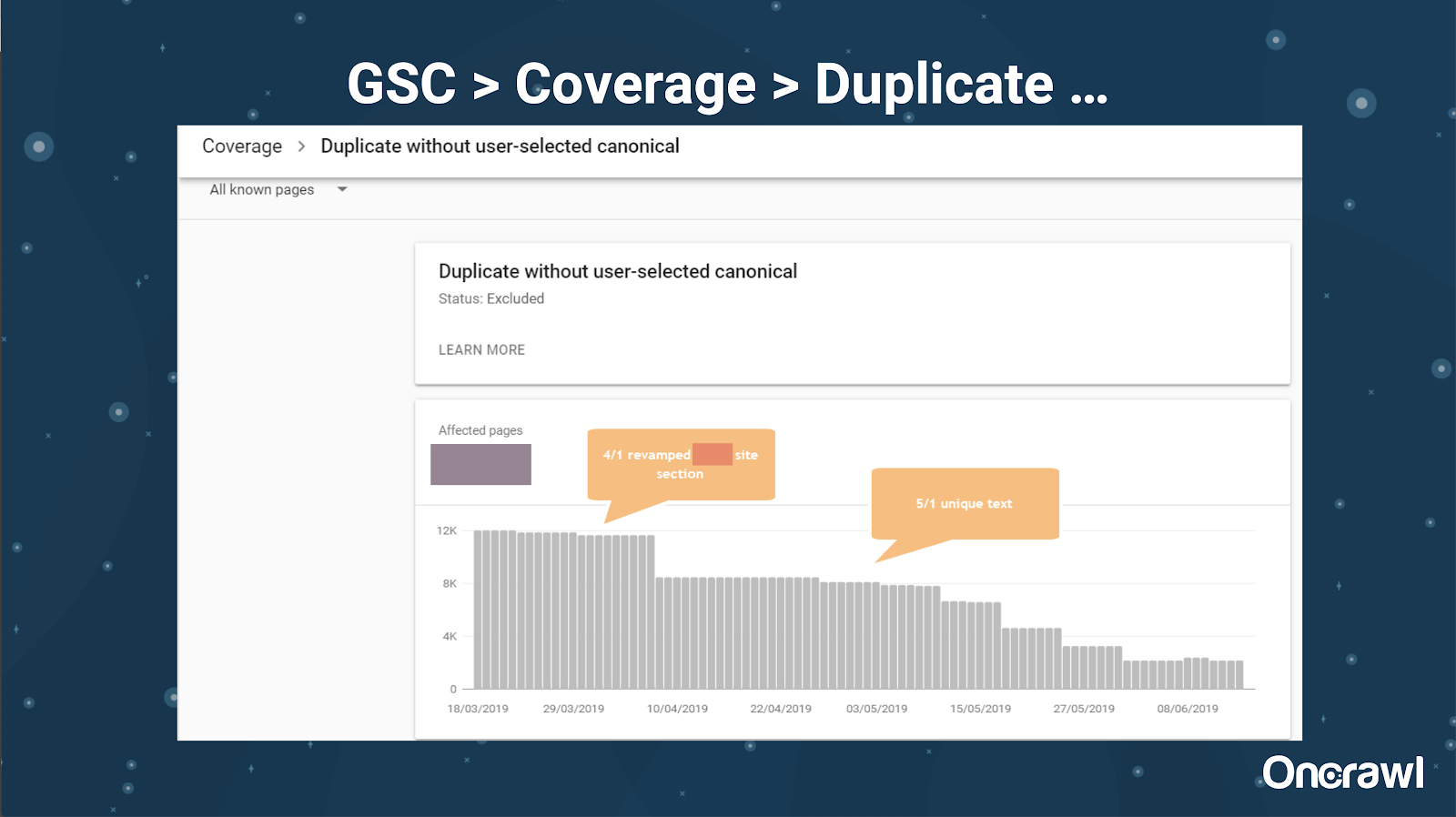
– Alat: Alat plagiarisme
Seperti Omi, Alexis juga menggunakan alat plagiarisme yang berbeda:
quetext
Noplag
Penilai Kertas
tata bahasa
CopyScape
Anda ingin memastikan bahwa konten Anda tidak hanya asli, tetapi juga dari sudut pandang bot, bahwa konten tersebut tidak dianggap diambil dari sumber lain.
Ini juga dapat membantu Anda menemukan segmen dalam artikel yang mungkin mirip dengan konten di tempat lain di internet.
Alexis menyukai bagaimana kami memiliki alat ini yang memungkinkan kami untuk "berempati terhadap bot mesin telusur", karena tidak satu pun dari kami adalah robot. Ketika alat memberi kita sinyal bahwa konten terlalu mirip, meskipun kita tahu ada perbedaan, itu pertanda baik ada sesuatu untuk digali di sana.
– Alat: Alat kepadatan kata kunci
Dua contoh alat kepadatan kata kunci yang digunakan Alexis adalah:
TagKerumunan
buku SEO

Masalah tergantung pada jenis situs
Menyelesaikan konten duplikat sangat bergantung pada jenis konten yang Anda terbitkan dan jenis masalah yang Anda hadapi. Blog tidak menghadapi kasus duplikat konten yang sama seperti situs e-niaga, misalnya.
Kasus-kasus yang berkesan
Alexis berbagi kasus klien baru-baru ini di mana dia menemukan masalah konten duplikat yang mudah diingat.
– Situs yang sangat besar: hasil setelah menambahkan konten unik
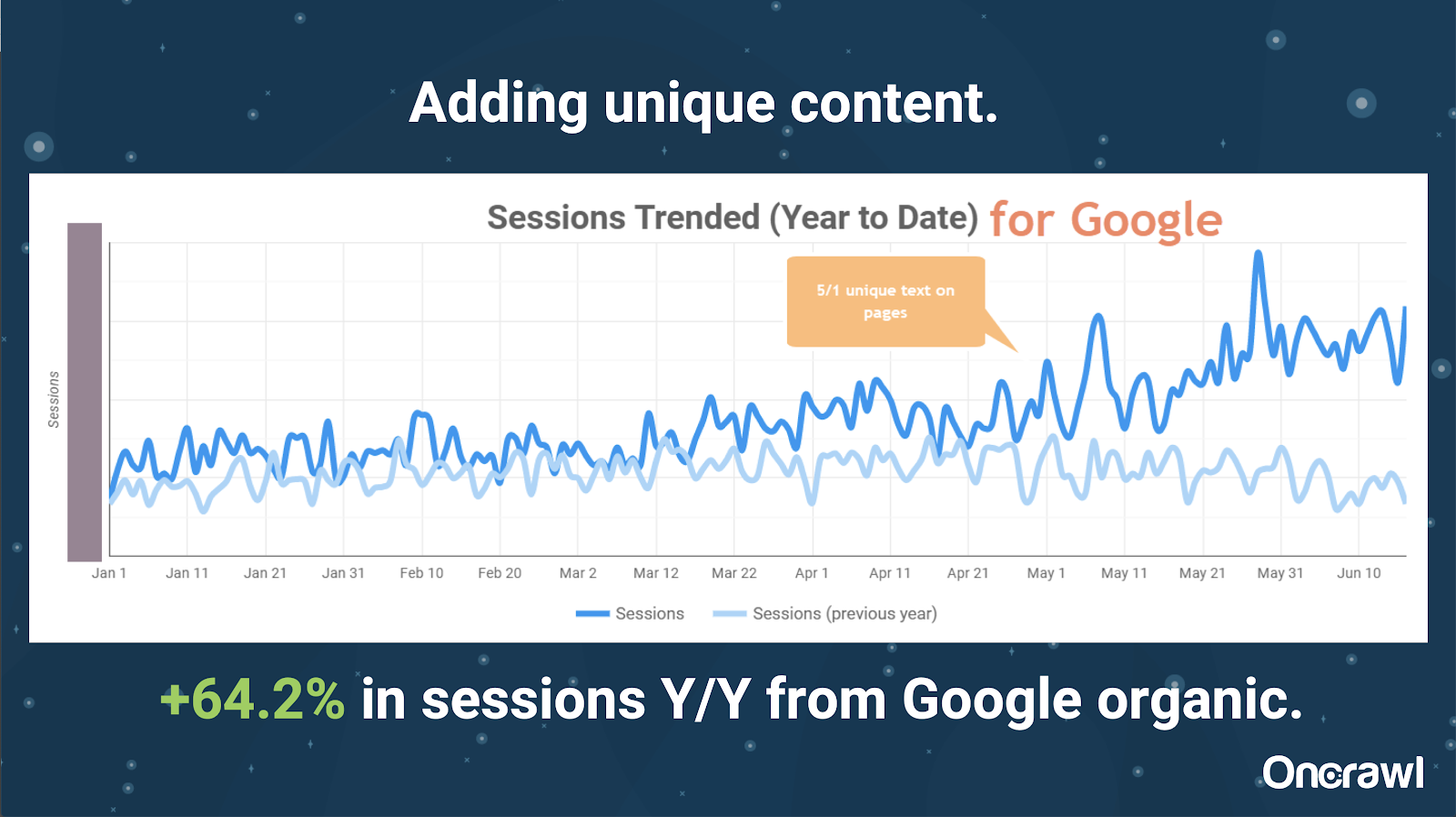
Situs ini sangat besar, dan mengalami masalah anggaran perayapan. Ini memiliki 86 juta halaman yang belum diindeks, dan hanya sekitar 1% dari halamannya yang telah diindeks.
Ini adalah situs real estat, begitu banyak konten yang tidak terlalu unik, dan banyak halaman mereka sangat, sangat mirip. Alexis akhirnya menambahkan konten ke halaman untuk menambahkan informasi spesifik lokasi untuk membedakan halaman. Mengejutkan betapa cepatnya ini menghasilkan hasil. (Ini hanya data organik Google.)
Bagi Alexis, ini adalah studi kasus yang cukup umum. Sebanyak yang kita bicarakan tentang EAT dan hal-hal serupa hari ini, ini menunjukkan bahwa begitu mesin pencari melihat konten sebagai unik dan berharga, itu masih dihargai.

Di situs ini, masalah tag kanonik yang tidak disengaja menyebabkan sekitar 250 halaman dikirim ke protokol yang salah.
Ini adalah satu kasus di mana tag kanonik menunjukkan halaman utama yang salah, mendorong halaman HTTP menggantikan halaman HTTPS.
Perubahan dalam 18 bulan terakhir
Alexis menulis artikel yang sangat lengkap, Duplikat konten dan resolusi strategis, sekitar 18 bulan sebelum webinar ini. SEO berubah dengan cepat, dan Anda terus-menerus perlu memperbarui dan menilai kembali pengetahuan Anda.
Bagi Alexis, sebagian besar dari apa yang disebutkan dalam artikel tersebut masih relevan hingga saat ini, dengan pengecualian untuk rel=next/prev. Dia berharap hal itu tidak lagi relevan dalam lima hingga sepuluh tahun ke depan.
Masalah teknis yang ditangani oleh pengembang: terlalu manual
Banyak masalah terkait duplikat konten yang ditangani oleh pengembang terlalu manual. Alexis percaya bahwa mereka seharusnya ditangani oleh CMS dan Adobe. Misalnya, Anda tidak harus melalui secara manual dan memastikan bahwa semua kanonik diatur, dan koheren.
– Peluang otomatisasi/pemberitahuan
Ada banyak peluang untuk otomatisasi di bidang masalah teknis dengan konten duplikat. Sebagai contoh: kita harus dapat segera mendeteksi jika ada tautan yang masuk ke HTTP padahal seharusnya ada di HTTPS, dan memperbaikinya.
– Usia situs dan infrastruktur lama sebagai penghalang
Beberapa sistem back-end terlalu tua untuk mendukung perubahan dan otomatisasi tertentu. Sangat sulit untuk memigrasikan CMS lama ke yang baru. Omi memberikan contoh migrasi situs web Canon ke CMS baru yang dibuat khusus. Itu tidak hanya mahal, tapi butuh waktu 12 bulan.
Rel prev/next dan komunikasi dari Google
Terkadang komunikasi dari Google agak membingungkan. Omi mengutip contoh di mana, dalam menerapkan rel=prev/next, kliennya melihat peningkatan kinerja yang signifikan pada tahun 2018, meskipun pengumuman Google tahun 2019 bahwa tag ini tidak digunakan selama bertahun-tahun.
– Kurangnya solusi satu ukuran untuk semua
Kesulitan dengan SEO adalah bahwa apa yang diamati satu orang terjadi di situs web mereka belum tentu sama dengan apa yang dilihat SEO lain di situs web mereka sendiri; tidak ada satu ukuran untuk semua SEO.
Kemampuan Google untuk membuat pengumuman yang berkaitan dengan semua SEO harus diakui sebagai prestasi besar, bahkan beberapa pernyataan mereka salah, seperti dalam kasus rel=next/prev.
Harapan untuk masa depan manajemen konten duplikat
Harapan Alexis untuk masa depan:
- Konten duplikat berbasis teknis yang lebih sedikit (seperti yang dilakukan CMS).
- Lebih banyak otomatisasi (pengujian unit dan pengujian eksternal). Misalnya, alat seperti OnCrawl mungkin secara teratur merayapi situs Anda dan memberi tahu Anda segera setelah mereka melihat kesalahan tertentu.
- Secara otomatis mendeteksi halaman dengan kemiripan tinggi dan jenis halaman untuk penulis dan pengelola konten. Ini akan mengotomatiskan beberapa verifikasi yang saat ini dilakukan secara manual di alat seperti Grammarly: ketika seseorang mencoba untuk memublikasikan, CMS akan mengatakan “ini serupa–apakah Anda yakin ingin memublikasikan ini?” Ada banyak nilai dalam melihat situs web tunggal serta perbandingan lintas situs web.
- Google terus meningkatkan sistem dan deteksi yang ada.
- Mungkin sistem peringatan untuk mengeskalasi masalah Google tidak menggunakan kanonik yang tepat. Akan berguna untuk dapat mengingatkan Google tentang masalah ini dan menyelesaikannya.
Kami membutuhkan alat yang lebih baik, alat internal yang lebih baik, tetapi mudah-mudahan saat Google mengembangkan sistem mereka, mereka akan menambahkan elemen untuk membantu kami sedikit.
Trik teknis favorit Alexis
Alexis memiliki beberapa trik teknis favorit:
- Contoh komputer jarak jauh EC2. Ini adalah cara yang sangat bagus untuk mengakses komputer nyata untuk perayapan yang sangat besar, atau apa pun yang membutuhkan banyak daya komputasi. Ini sangat cepat setelah Anda mengaturnya. Pastikan Anda menghentikannya setelah selesai, karena ini membutuhkan biaya.
- Periksa alat pengujian pertama seluler. Google telah menyebutkan bahwa ini adalah gambaran paling akurat dari apa yang mereka lihat. Itu terlihat di DOM.
- Alihkan agen pengguna ke Googlebot. Ini akan memberi Anda gambaran tentang apa yang sebenarnya dilihat oleh Googlebots.
- Menggunakan alat robots.txt TechnicalSEO.com. Ini adalah salah satu alat Merkle, tetapi Alexis sangat menyukainya karena robots.txt terkadang sangat membingungkan.
- Gunakan penganalisis log.
- Dibuat dengan pemeriksa htaccess Love.
- Menggunakan Google Data Studio untuk melaporkan perubahan (menyinkronkan Spreadsheet dengan pembaruan, memfilter setiap halaman menurut pembaruan yang relevan).
Kesulitan SEO teknis: robots.txt
Robots.txt benar-benar membingungkan.
Ini adalah file kuno yang sepertinya dapat mendukung RegEx, tetapi tidak.
Ini memiliki aturan prioritas yang berbeda untuk aturan larang dan izinkan, yang bisa membingungkan.
Bot yang berbeda dapat mengabaikan hal yang berbeda, meskipun tidak seharusnya demikian.
Asumsi Anda tentang apa yang benar tidak selalu benar.

T&J
– HSTS: apakah protokol split diperlukan?
Anda harus memiliki semua HTTPS untuk konten duplikat jika Anda memiliki HSTS.
– Apakah konten yang diterjemahkan merupakan konten duplikat?
Seringkali, saat Anda menggunakan hreflang, Anda menggunakannya untuk membedakan antara versi lokal dalam bahasa yang sama, seperti halaman berbahasa Inggris AS dan Irlandia. Alexis tidak akan mempertimbangkan konten duplikat ini, tetapi dia pasti akan merekomendasikan untuk memastikan bahwa Anda telah menyiapkan tag hreflang dengan benar untuk menunjukkan bahwa ini adalah pengalaman yang sama, dioptimalkan untuk audiens yang berbeda.
– Bisakah Anda menggunakan tag kanonik alih-alih pengalihan 301 untuk migrasi HTTP/HTTPS?
Akan berguna untuk memeriksa apa yang sebenarnya terjadi di SERP. Naluri Alexis adalah mengatakan bahwa ini akan baik-baik saja, tetapi itu tergantung pada bagaimana Google sebenarnya berperilaku. Idealnya, jika ini adalah halaman yang sama persis, Anda ingin menggunakan 301, tetapi dia telah melihat tag kanonik berfungsi di masa lalu untuk jenis migrasi ini. Dia sebenarnya bahkan melihat ini terjadi secara tidak sengaja.
Berdasarkan pengalaman Omi, dia sangat menyarankan penggunaan 301 untuk menghindari masalah: jika Anda memigrasikan situs web, sebaiknya Anda memigrasikannya dengan benar untuk menghindari kesalahan saat ini dan di masa mendatang.
– Efek judul halaman duplikat
Katakanlah Anda memiliki judul yang sangat mirip untuk lokasi yang berbeda, tetapi kontennya sangat berbeda. Meskipun itu bukan duplikat konten untuk Alexis, dia melihat mesin pencari memperlakukan ini sebagai jenis "keseluruhan", dan judul adalah sesuatu yang dapat digunakan untuk mengidentifikasi area dengan kemungkinan masalah.
Di sinilah Anda mungkin ingin menggunakan pencarian [site: + intitle: ].
Namun, hanya karena Anda memiliki tag judul yang sama, itu tidak akan menyebabkan masalah duplikat konten.
Anda tetap harus membidik judul dan deskripsi meta yang unik, bahkan pada halaman yang diberi halaman atau halaman lain yang sangat mirip. Ini bukan karena duplikat konten, tetapi lebih pada cara untuk mengoptimalkan bagaimana Anda menampilkan halaman Anda di SERPs.
Tip teratas
“Konten duplikat adalah tantangan teknis dan pemasaran konten.”
SEO di Orbit pergi ke luar angkasa
Jika Anda melewatkan perjalanan kami ke luar angkasa pada tanggal 27 Juni, tangkap di sini dan temukan semua tip yang kami kirimkan ke luar angkasa.