
Menggunakan Python dan Peta Situs untuk Mengaudit Strategi Konten
Diterbitkan: 2020-10-08Ketertarikan pada apa yang dapat dilakukan atas nama SEO dengan Perpustakaan Python bukan lagi rahasia. Namun, kebanyakan orang dengan sedikit pengalaman pemrograman mengalami kesulitan dalam mengimpor dan menggunakan sejumlah besar perpustakaan atau mendorong, hasil di luar apa yang dapat dilakukan perayap atau alat SEO biasa.
Inilah sebabnya mengapa pustaka Python yang dibuat khusus untuk SEO, SEM, SMO, pemeriksaan SERP, dan analisis konten berguna untuk semua orang.
Pada artikel ini, kita akan melihat beberapa hal yang dapat dilakukan dengan Advertools Python Library untuk SEO, dibuat dan dikembangkan oleh Elias Dabbas, dan untuk itu saya melihat potensi besar dalam SEO, PPC, dan kemampuan pengkodean dalam waktu yang sangat singkat. Selain itu, kami akan menggunakan skrip Python khusus bersama dengan pustaka Python lainnya dengan cara yang mendidik dan adaptif.
Kami akan memeriksa apa yang dapat dipelajari untuk SEO dari peta situs berkat fungsi sitemap_to_df Elias Dabbas yang membantu dalam mengunduh dan menganalisis peta situs XML (Peta situs adalah dokumen dalam format XML yang digunakan untuk melaporkan URL yang dapat dirayapi dan diindeks ke Mesin Pencari.)
Artikel ini akan menunjukkan kepada Anda bagaimana Anda dapat menulis kode Python khusus untuk menganalisis situs web yang berbeda sesuai dengan strukturnya yang berbeda, cara menginterpretasikan data dalam hal SEO, dan cara berpikir seperti mesin pencari dalam hal profil konten, URL, dan struktur situs .
Menganalisis Skala dan Strategi Konten Situs Web Berdasarkan Peta Situsnya
Peta situs adalah komponen situs web yang dapat menangkap berbagai jenis data, seperti seberapa sering situs web menerbitkan konten, kategori konten, tanggal penerbitan, informasi penulis, subjek konten…
Dalam kondisi normal, Anda dapat mengikis peta situs dengan scrapy, mengonversinya menjadi DataFrame dengan Pandas, dan menafsirkannya dengan banyak pustaka tambahan yang berbeda jika Anda mau.
Namun dalam artikel ini, kita hanya akan menggunakan Advertools dan beberapa metode dan atribut library Pandas. Beberapa library akan diaktifkan untuk memvisualisasikan data yang telah kita peroleh.
Mari selami dan pilih situs web untuk menggunakan peta situsnya untuk menyimpulkan beberapa wawasan SEO penting.
Mengekstrak dan Membuat Bingkai Data dari Peta Situs dengan Advertools
Di Advertools, Anda dapat menemukan, menelusuri, dan menggabungkan semua peta situs situs web hanya dengan satu baris kode.
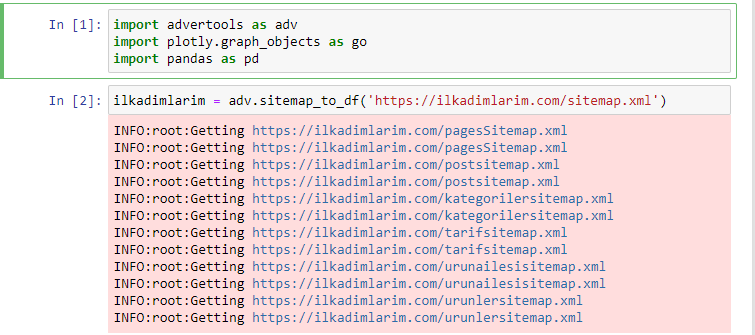
Saya suka menggunakan Jupyter Notebook daripada editor kode biasa atau IDE.
Di sel pertama kami telah mengimpor Pandas dan Advertools untuk mengumpulkan dan mengatur data dan Plotly.graph_objects untuk memvisualisasikan data.
perintah adv.sitemap_to_df('sitemap address') hanya mengumpulkan semua peta situs dan menyatukannya sebagai DataFrame.
Jika Anda melakukan hal yang sama menggunakan Pandas dan Advertools, Anda dapat menemukan URL mana yang tersedia di peta situs mana.
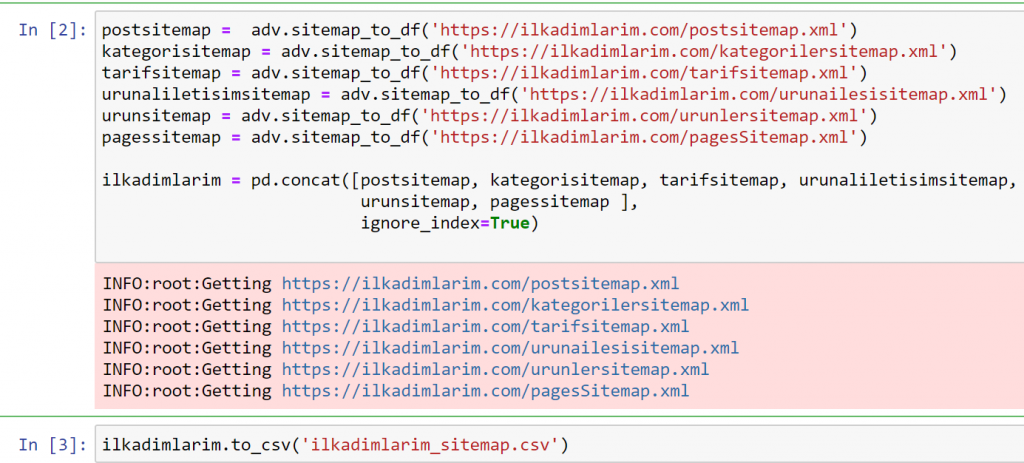
Pada contoh di atas, kami menarik peta situs yang sama secara terpisah dan kemudian menggabungkannya dengan perintah pd.concat dan mentransfer hasilnya ke CSV. Contoh sebelumnya menggunakan file indeks peta situs, dalam hal ini fungsinya digunakan untuk mengambil semua peta situs lainnya. Jadi Anda memiliki pilihan untuk memilih peta situs tertentu seperti yang kami lakukan di sini jika Anda tertarik pada bagian tertentu dari situs web.
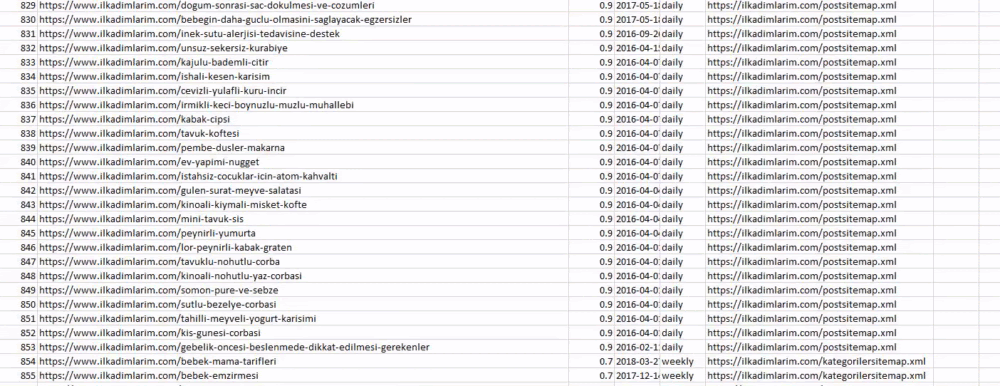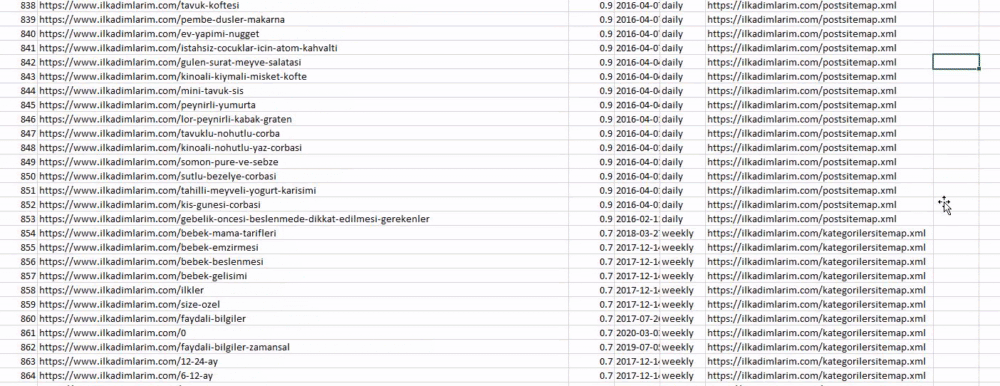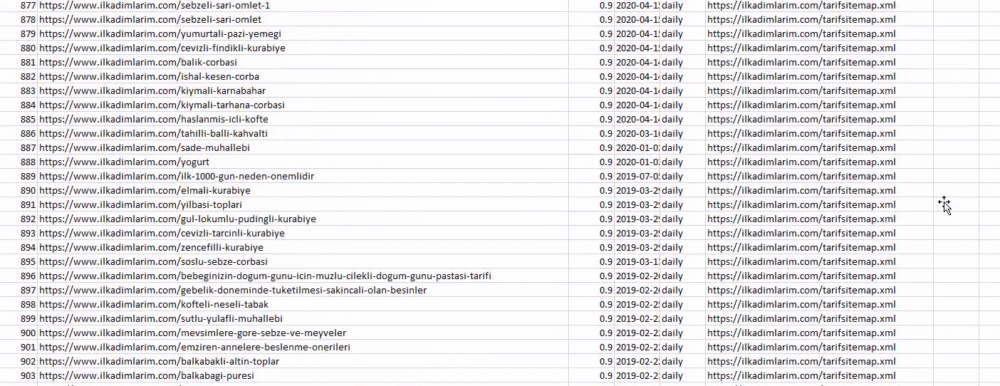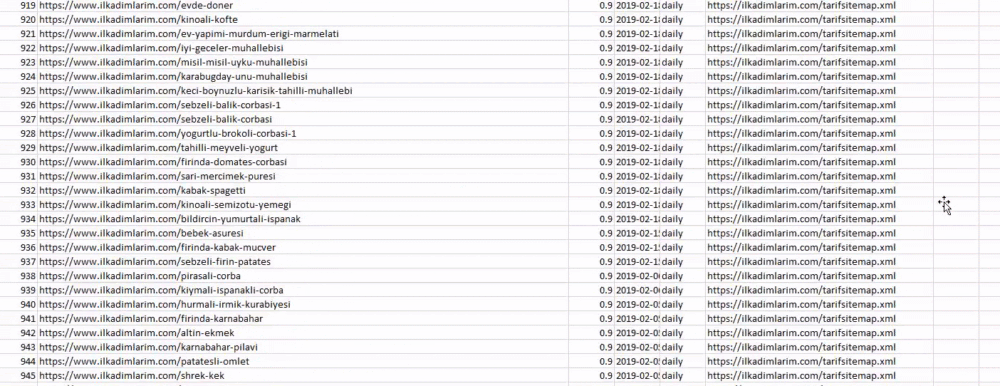
Anda dapat melihat kolom dengan nama peta situs yang berbeda di atas. abaikan_index=Bagian yang benar adalah untuk pengurutan rapi nomor indeks dari DataFrame yang berbeda, jika Anda telah menggabungkan beberapa.
Data Perayapan³
 Belajarlah lagi
Belajarlah lagiMembersihkan dan Mempersiapkan Bingkai Data Peta Situs untuk Analisis Konten dengan Python
Untuk memahami profil konten situs web melalui peta situs, kita perlu mempersiapkannya untuk meninjau DataFrame yang kita peroleh dengan Advertools.
Kami akan menggunakan beberapa perintah dasar dari perpustakaan Pandas untuk membentuk data kami:
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(kolom = 'Tidak disebutkan namanya: 0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('mod terakhir')
“Ilkadimlarim” berarti “langkah pertama saya” dalam bahasa Turki, dan seperti yang dapat Anda bayangkan, ini adalah situs untuk bayi, kehamilan, dan menjadi ibu.
Kami telah melakukan tiga operasi dengan jalur ini.
- Tanpa Nama: Kami menghapus kolom kosong bernama 0 dari DataFrame. Juga, jika Anda menggunakan 'index = False “ dengan fungsi pd.to_csv() , Anda tidak akan melihat kolom 'Unnamed 0' ini di awal.
- Kami mengonversi data di kolom Modifikasi Terakhir ke Tanggal Waktu.
- Kami membawa kolom "lastmod" ke posisi indeks.
Di bawah ini Anda dapat melihat versi final DataFrame.
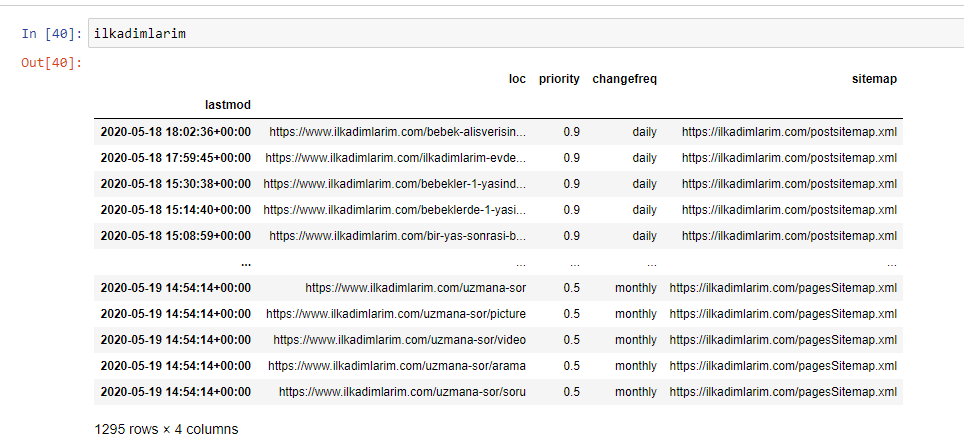
Kami tahu bahwa Google tidak menggunakan prioritas dan mengubah informasi frekuensi dari peta situs. Mereka menyebutnya "kantong kebisingan". Tetapi jika Anda mementingkan kinerja situs web Anda untuk mesin telusur lain, Anda mungkin perlu memeriksanya juga. Secara pribadi, saya tidak terlalu peduli dengan data ini, tetapi saya tetap tidak perlu menghapusnya dari DataFrame.
Kami membutuhkan satu baris kode lagi untuk mengkategorikan peta situs di kolom lain.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
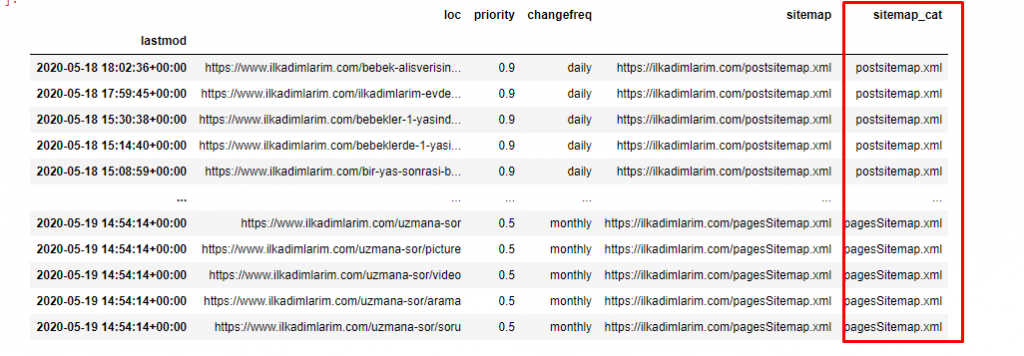
Di Pandas, Anda dapat menambahkan kolom atau baris baru ke DataFrame atau Anda dapat memperbaruinya dengan mudah. Kami telah membuat kolom baru dengan potongan kode DataFrame['new_columns'] . DataFrame['column_name'].str memungkinkan kita untuk melakukan operasi yang berbeda dengan mengubah tipe data dalam kolom. Kami membagi data string di kolom yang terkait dengan .split ('/') dengan karakter / dan memasukkannya ke dalam daftar. Dengan .str [number] , kami membuat konten kolom baru dengan memilih elemen tertentu dalam daftar itu.
Analisis Profil Konten menurut Jumlah dan Jenis Peta Situs
Setelah meletakkan peta situs di kolom yang berbeda sesuai dengan jenisnya, kita dapat memeriksa berapa % konten yang ada di setiap peta situs. Dengan demikian, kita juga dapat membuat kesimpulan tentang bagian mana dari situs web yang lebih penting.
ilkadimlarim['sitemap_cat'].value_counts(normalisasi = Benar) * 100
- DataFrame['column_name'] adalah memilih kolom yang ingin kita buat prosesnya.
- value_counts() menghitung frekuensi nilai dalam kolom.
- normalize=True mengambil rasio nilai dalam desimal.
- Kami membuatnya lebih mudah dibaca dengan memperbesar angka desimal dengan *100.
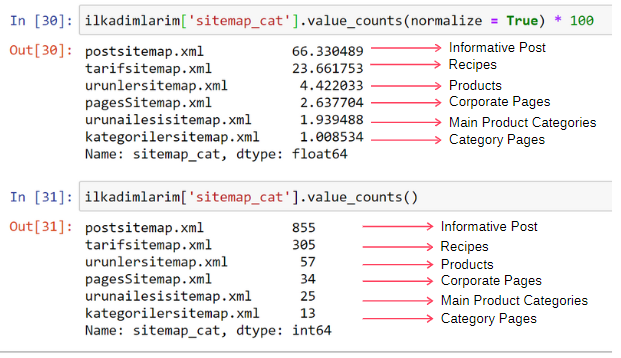
Kami melihat bahwa 65% konten ada di Peta Situs Postingan dan 23% ada di Peta Situs Resep. Peta Situs Produk hanya memiliki 2% konten.
Ini menunjukkan bahwa kami memiliki situs web yang harus membuat konten informatif untuk khalayak luas untuk memasarkan produknya sendiri. Mari kita periksa apakah tesis kita benar.
Sebelum melanjutkan, kita perlu mengubah nama kolom ilkadimlarim['sitemap_cat'] menjadi 'URL_Count' dengan kode di bawah ini:
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- Fungsi rename() berguna untuk mengubah nama kolom atau indeks Anda untuk menghubungkan data dan artinya pada tingkat yang lebih dalam.
- Kami telah mengubah nama kolom menjadi permanen berkat atribut 'inplace=True' .
- Anda juga dapat mengubah gaya huruf kolom dan indeks dengan ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) . Ini hanya menulis huruf pertama sebagai huruf besar dari setiap kolom di Ilkadimlarim.

Sekarang, kita dapat melanjutkan.
Untuk melihat informasi ini dalam satu frame, Anda dapat menggunakan kode di bawah ini:
(ilkadimlarim['sitemap_cat']
.nilai_jumlah()
.untuk membingkai()
.assign(persentase=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', persentase='{:.1%}')))
- to_frame() digunakan untuk membingkai nilai yang diukur oleh value_counts() di kolom yang dipilih.
- assign() digunakan untuk menambahkan nilai tertentu ke frame.
- lambda mengacu pada fungsi anonim di Python.
- Di sini, fungsi Lambda dan tipe peta situs dibagi dengan jumlah total peta situs dengan metode div() Pandas.
- style() menentukan bagaimana nilai akhir yang ditentukan ditulis.
- Di sini, kita mengatur berapa banyak digit yang ditulis setelah titik dengan metode format() .
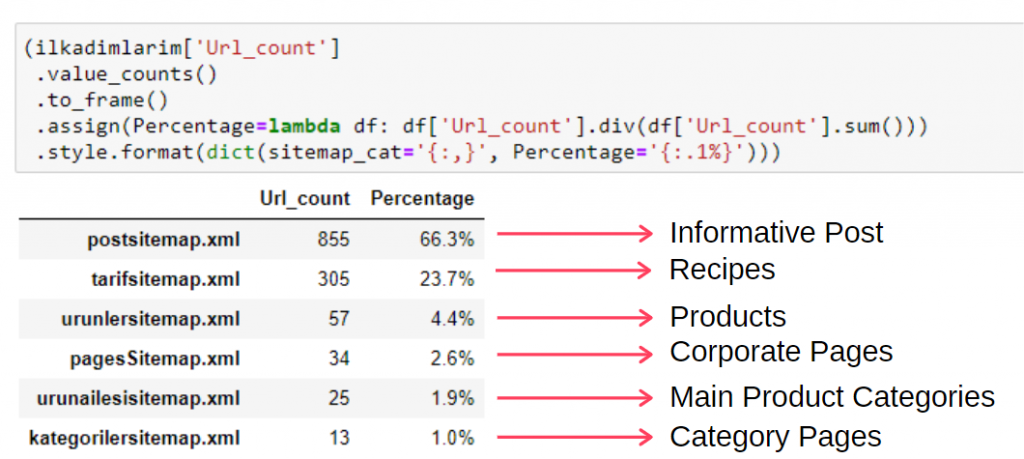
Dengan demikian, kami melihat pentingnya pemasaran konten untuk situs web ini. Kami juga dapat memeriksa tren penerbitan artikel mereka dari tahun ke tahun dengan dua baris kode tunggal untuk memeriksa situasi mereka lebih dalam.
Memeriksa dan Memvisualisasikan Tren Penerbitan Konten berdasarkan Tahun melalui Peta Situs dan Python
Kami melakukan pencocokan konten dan maksud dari situs web yang diperiksa sesuai dengan kategori peta situs, tetapi kami belum membuat klasifikasi berdasarkan waktu. Kami akan menggunakan metode sampel ulang() untuk mencapai ini.
post_per_month = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Contoh ulang adalah metode di perpustakaan Pandas. resample('A') memeriksa seri data untuk DataFrame tahunan. Selama berminggu-minggu, Anda dapat menggunakan 'W', selama berbulan-bulan, Anda dapat menggunakan 'M'.
Loc disini melambangkan indeks; count berarti Anda ingin menghitung jumlah contoh data.
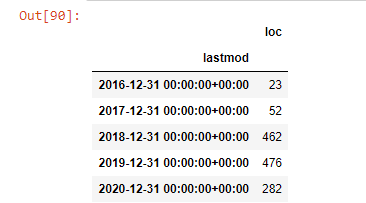
Kami melihat bahwa mereka mulai menerbitkan artikel pada tahun 2016 tetapi tren penerbitan utama mereka telah meningkat setelah tahun 2017. Kami juga dapat memasukkan ini ke dalam grafik dengan bantuan Objek Grafik Plotly.
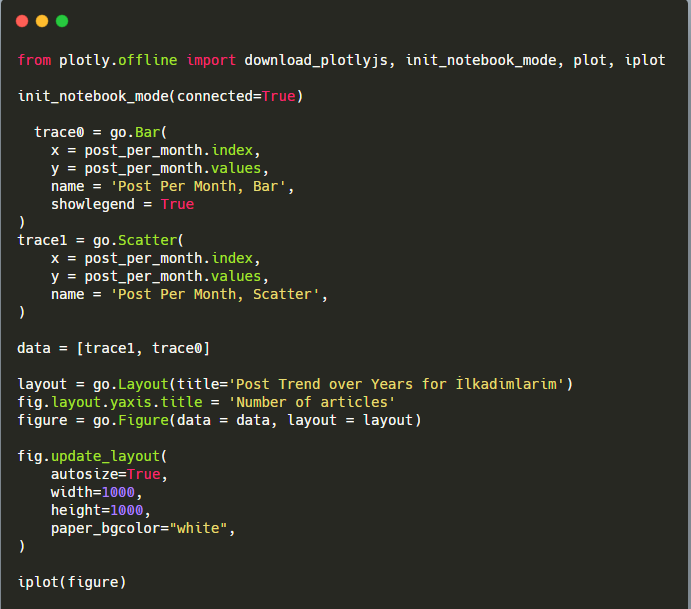
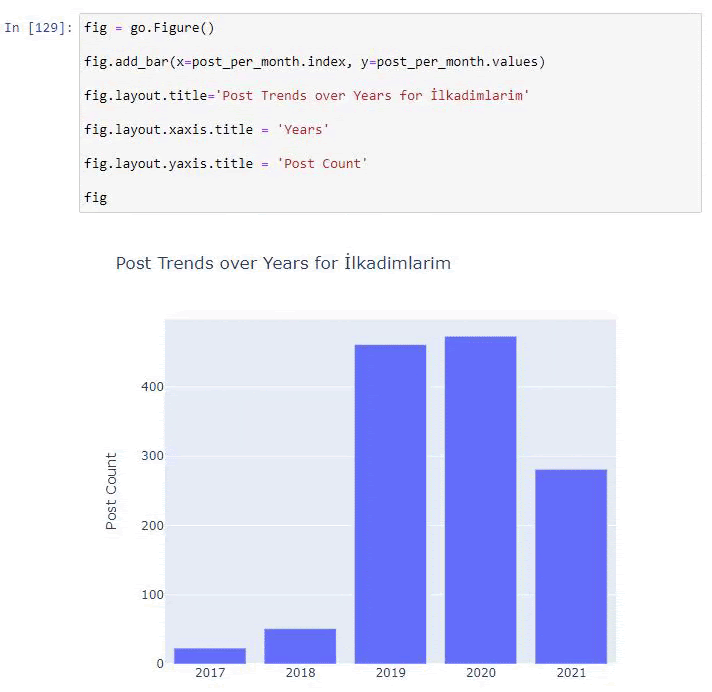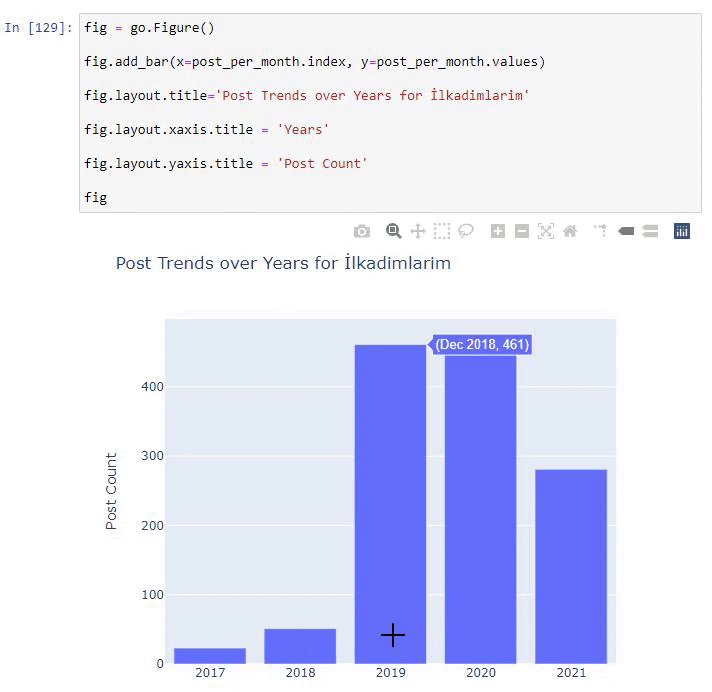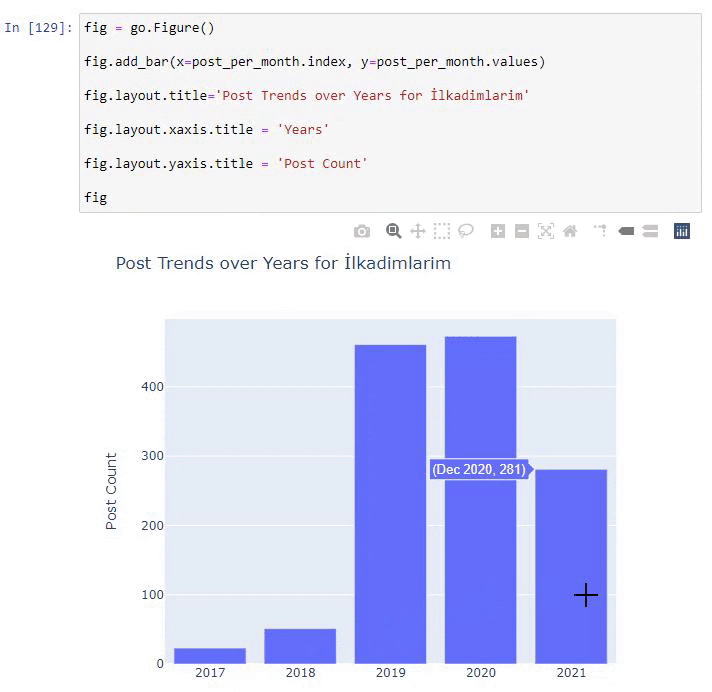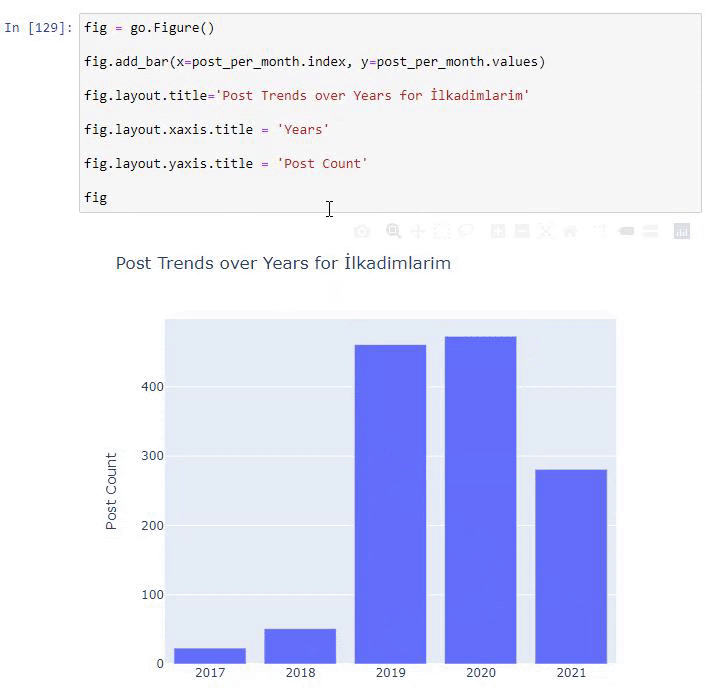
Penjelasan cuplikan kode Plotly Bar Plot ini:
- fig = go.Gambar() adalah untuk membuat gambar.
- fig.add_bar() adalah untuk menambahkan barplot ke dalam gambar. Kami juga menentukan sumbu X dan Y apa yang akan berada di dalam tanda kurung.
- Fig.layout adalah untuk membuat judul umum untuk gambar dan sumbu.
- Pada baris terakhir kita memanggil plot yang telah kita buat dengan perintah fig yang sama dengan go.Gambar()
Di bawah ini, Anda akan menemukan data yang sama berdasarkan bulan, dengan scatterplot dan barplot:
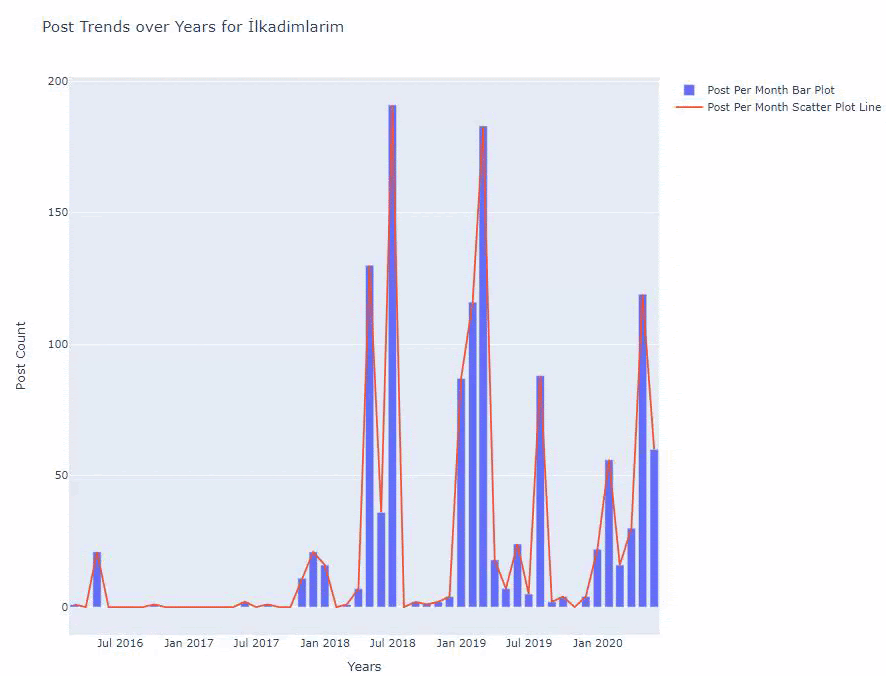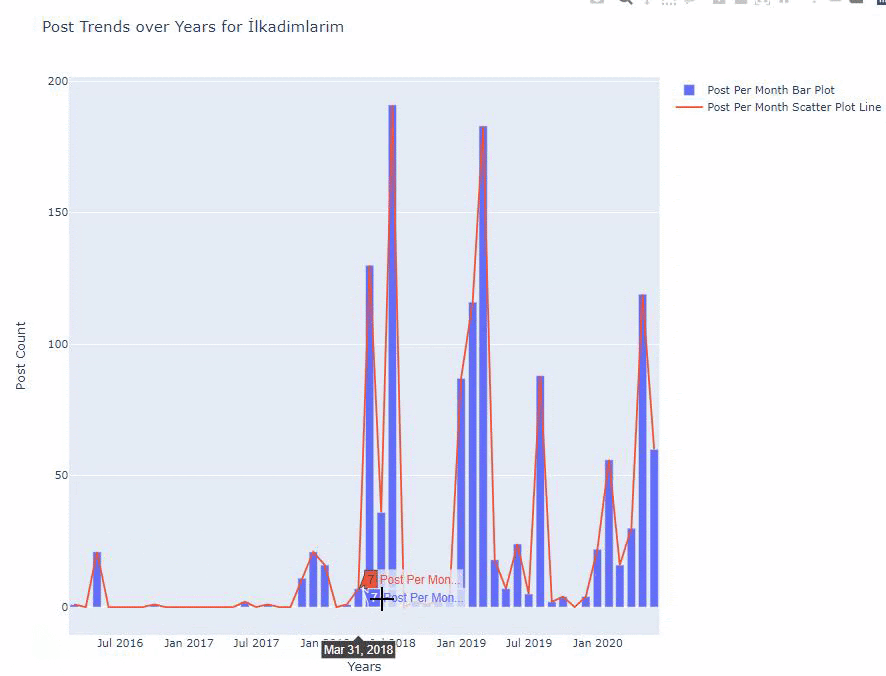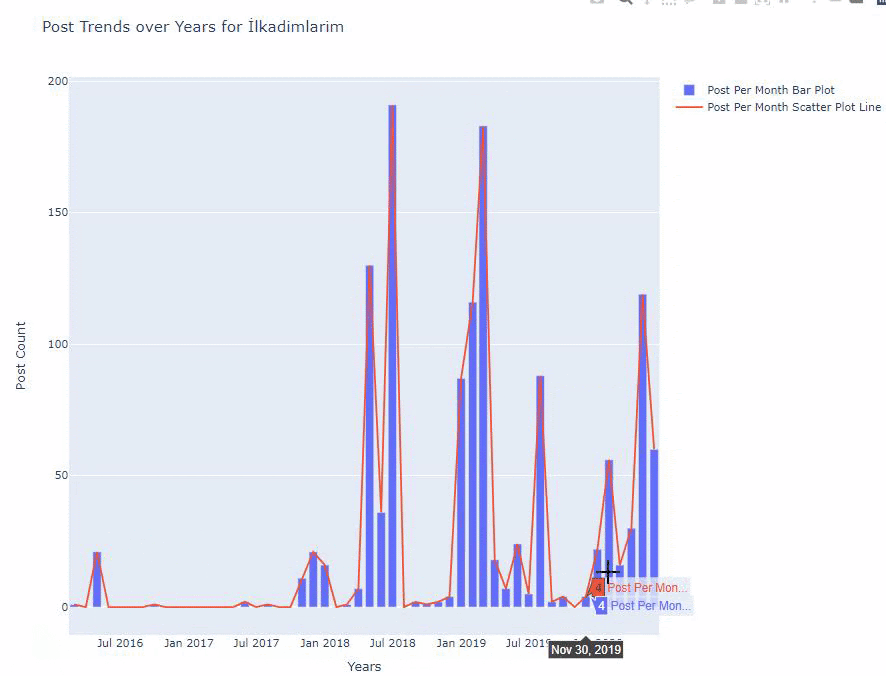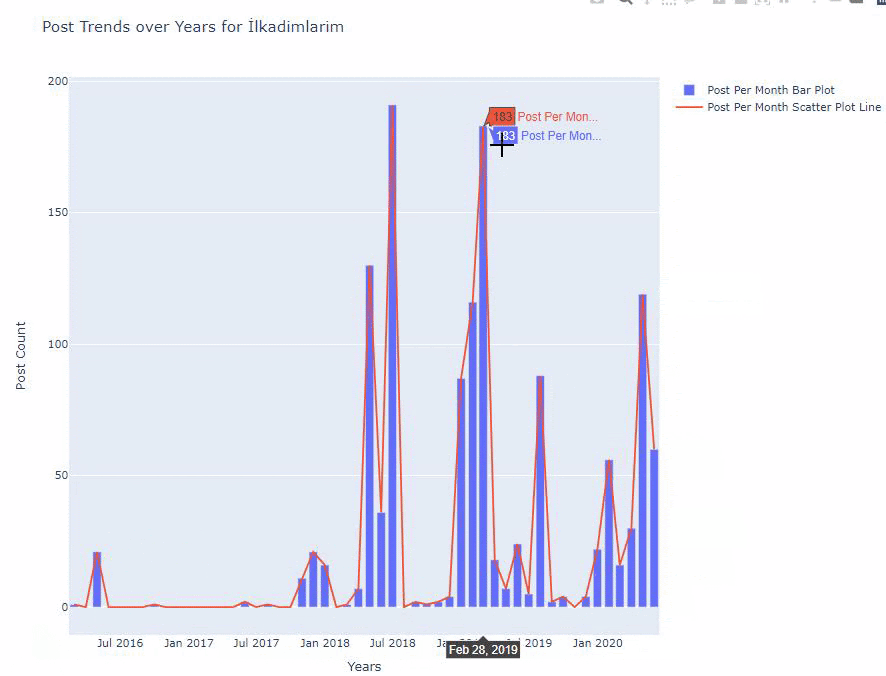
Berikut adalah kode untuk membuat gambar ini:
Kami telah menambahkan plot kedua dengan fig.add_scatter() , dan kami juga telah mengubah nama menggunakan atribut name. fig.update_layout() adalah untuk mengubah ukuran dan warna latar belakang plot.
Anda juga dapat mengubah mode hover, jarak antar bar, dan lainnya. Saya rasa cukup berbagi kode saja, karena menjelaskan setiap kode di sini secara terpisah dapat menyebabkan kita menjauh dari subjek utama.
Kami juga dapat membandingkan tren penerbitan konten pesaing menurut kategori seperti di bawah ini:
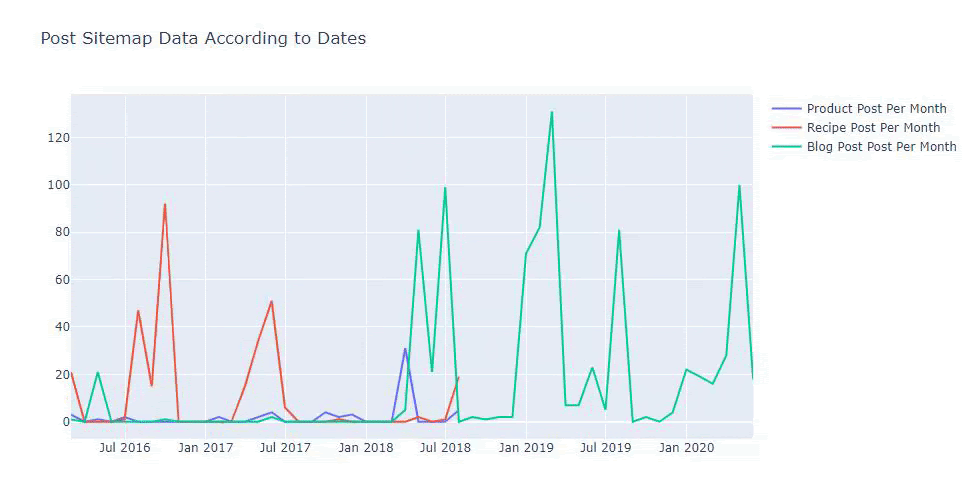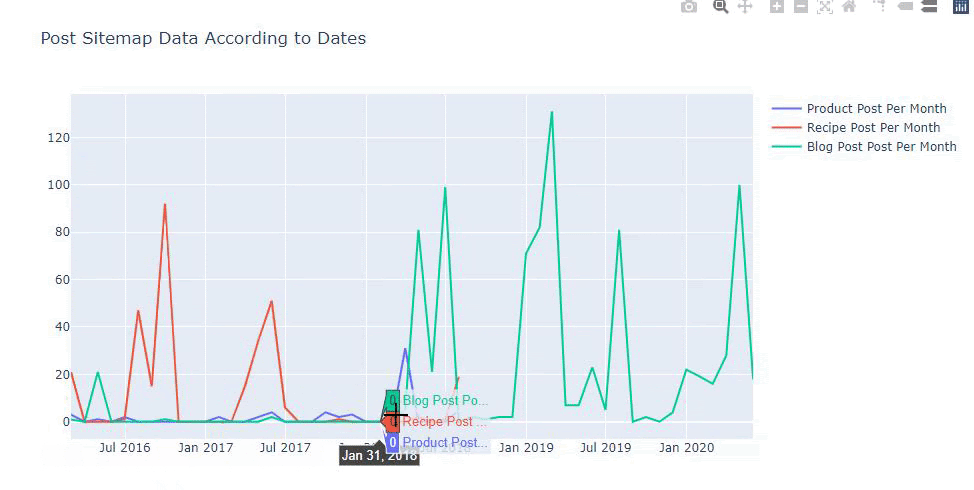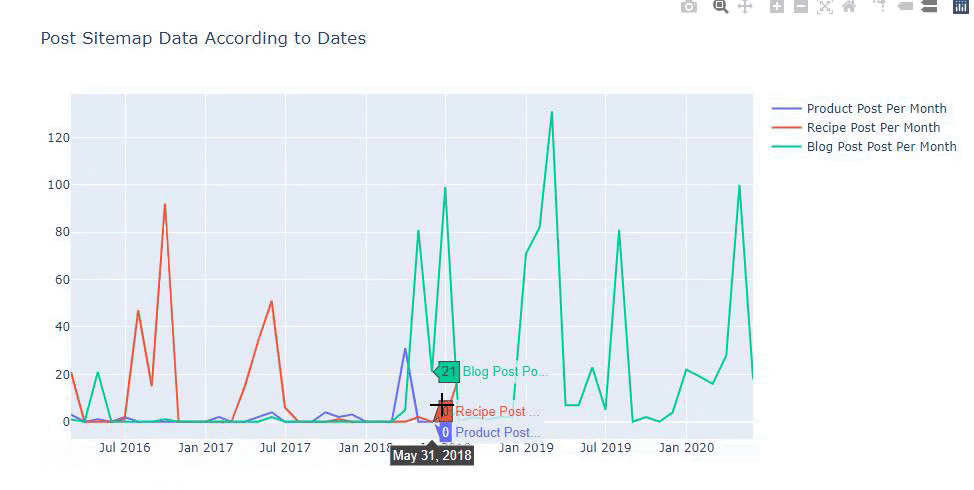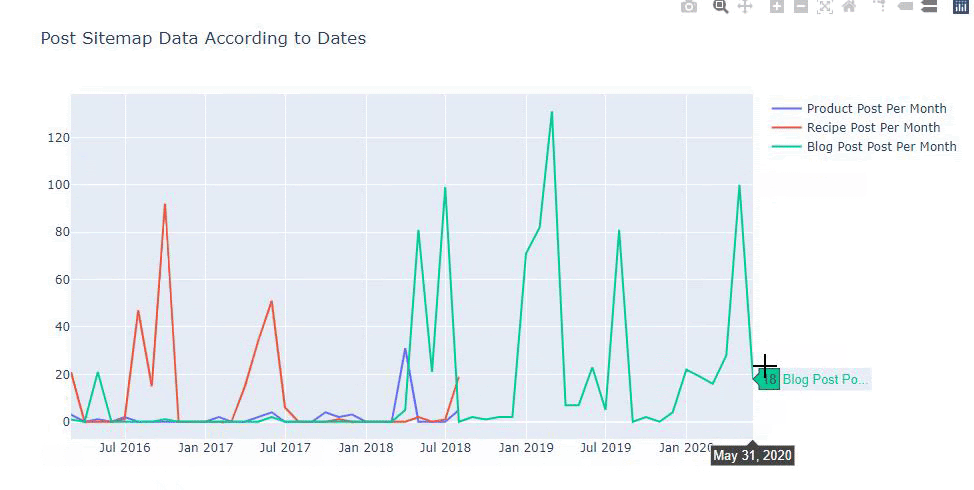
Bagan ini telah dibuat dengan metode kedua, karena Anda mungkin melihat tidak ada perbedaan tetapi salah satunya cukup sederhana.
Untuk memetakan frekuensi dan tren penerbitan konten dari tiga peta situs terpisah, kita harus menempatkan peta situs, yang memiliki interval terpanjang, pada sumbu X. Dengan demikian, kami dapat membandingkan frekuensi situs web yang kami periksa menerbitkan setiap jenis konten yang berbeda untuk maksud pencarian yang berbeda.
Ketika Anda memeriksa kode yang relevan di bawah ini, Anda akan melihat bahwa itu tidak jauh berbeda dari yang di atas.
Untuk membuat plot sebar dengan beberapa sumbu Y, Anda dapat menggunakan kode di bawah ini.
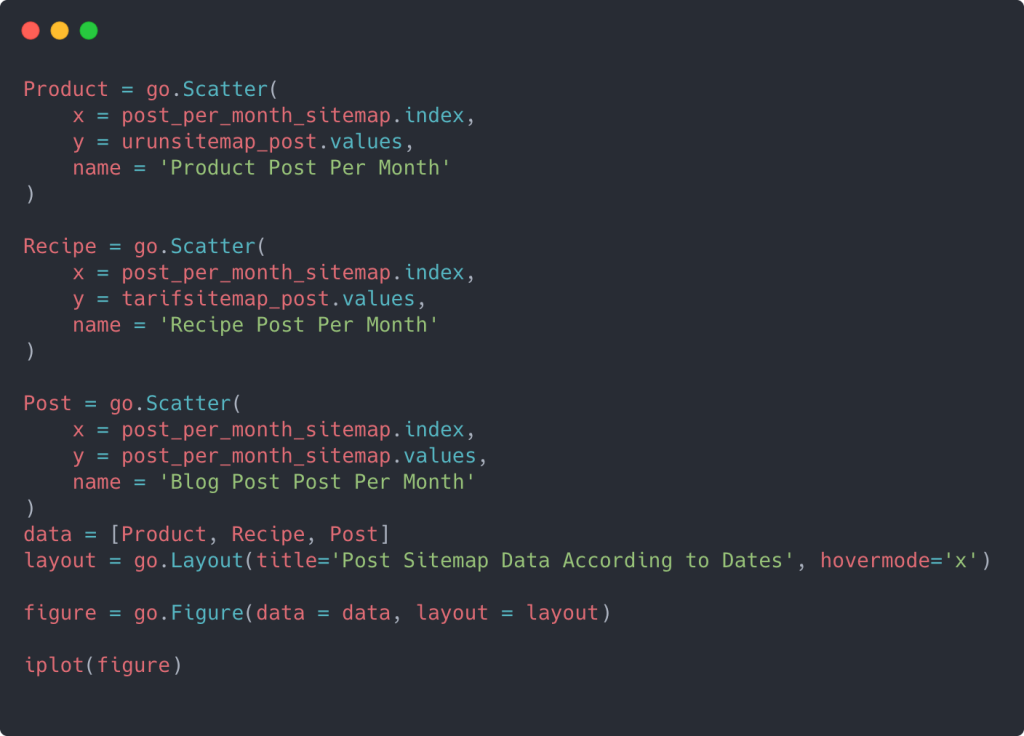
Ada metode lain seperti menyatukan peta situs yang berbeda dan menggunakan loop for untuk kolom untuk menggunakan beberapa Sumbu Y dalam plot pencar tetapi untuk situs sekecil itu kita tidak memerlukannya. Untuk sebagian besar, akan lebih logis untuk menggunakan metode ini di situs web dengan ratusan peta situs.
Juga, karena situs webnya kecil, grafiknya mungkin terlihat dangkal, tetapi seperti yang akan Anda lihat nanti di artikel di situs web dengan jutaan URL, grafik seperti itu adalah cara yang bagus untuk membandingkan situs yang berbeda serta untuk membandingkan kategori yang berbeda dari situs web. situs web yang sama.
Memeriksa dan Memvisualisasikan Kategori Konten, Maksud, dan Tren Penerbitan dengan Peta Situs dan Python
Di bagian ini, kami akan memeriksa apakah mereka menulis sejumlah besar konten dalam domain pengetahuan khusus untuk memasarkan sejumlah kecil produk, yang kami katakan di awal artikel. Berkat ini, kami dapat melihat apakah mereka memiliki kemitraan konten dengan merek lain atau tidak.
Untuk menunjukkan apa lagi yang dapat ditemukan di peta situs, kami akan melanjutkan penggalian lebih lanjut. Kami juga bisa mendapatkan beberapa informasi dari bagian 'loc' dari peta situs seperti yang lain.
Tidak ada perincian kategori dalam URL Ilkadimlarim. Jika sebuah situs web memiliki pengelompokan kategori di URL-nya, kita dapat belajar lebih banyak tentang distribusi konten. Jika tidak, kita dapat mengakses data yang sama dengan menulis kode tambahan, tetapi hanya dengan kepastian yang kurang.
Pada titik ini, Anda dapat membayangkan betapa jauh lebih murahnya perincian URL untuk mesin telusur yang merayapi miliaran situs untuk memahami situs web Anda.
a = ilkadimlarim['loc'].str.contains(“bebek|hamile|haftalik”)
Bebek: sayang
Hamil : hamil
Haftalik: mingguan atau "minggu hamil"
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
Metode str() di sini sekali lagi memungkinkan kita untuk menyetel kolom tempat kita memilih operasi tertentu.
Dengan metode berisi() , kami menentukan data untuk memeriksa apakah itu termasuk dalam data yang dikonversi ke string.
Di sini, "|" antara istilah berarti "atau" .
Kemudian kami menetapkan data yang kami filter ke variabel dan menggunakan metode sampel ulang () yang kami gunakan sebelumnya.
metode count , di sisi lain, mengukur data mana yang digunakan dan berapa kali.
Hasil yang diperoleh dengan count() sekali lagi diapit oleh to_frame() .
Selain itu, str.contains() mengambil nilai Regex secara default, yang berarti Anda dapat membuat kondisi pemfilteran yang lebih rumit dengan kode yang lebih sedikit.
Dengan kata lain, pada titik ini, kami menetapkan URL yang berisi kata "bayi", "mingguan", "hamil" ke variabel di ilkadimlarim , dan kemudian kami menempatkan tanggal publikasi URL dalam kondisi yang sesuai untuk filter ini. dibuat dalam sebuah bingkai.
Kemudian kita melakukan hal yang sama untuk URL yang mengandung kata 'aptamil'. Aptamil adalah nama produk nutrisi bayi yang diperkenalkan oleh Ilkadimlarim. Oleh karena itu, kita juga dapat memperhatikan kepadatan siaran konten informatif dan komersial.
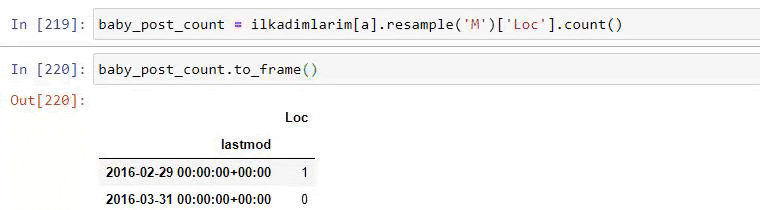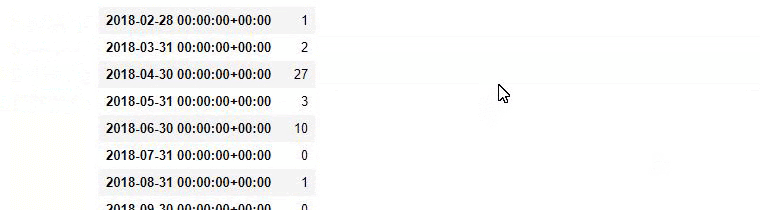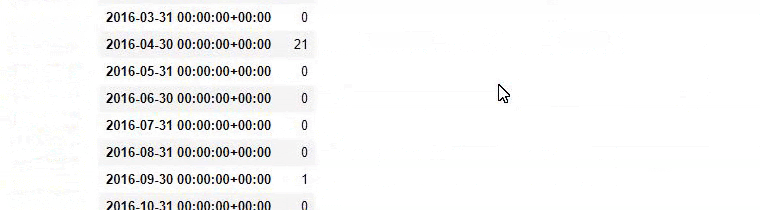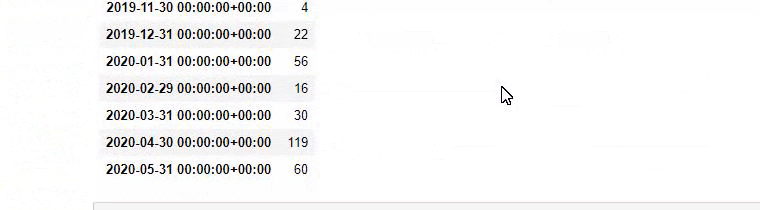
Dan Anda mungkin melihat dua grup konten yang berbeda jadwal penerbitan selama bertahun-tahun untuk maksud pencarian yang berbeda dengan lebih pasti dan informasi yang tepat dari URL.
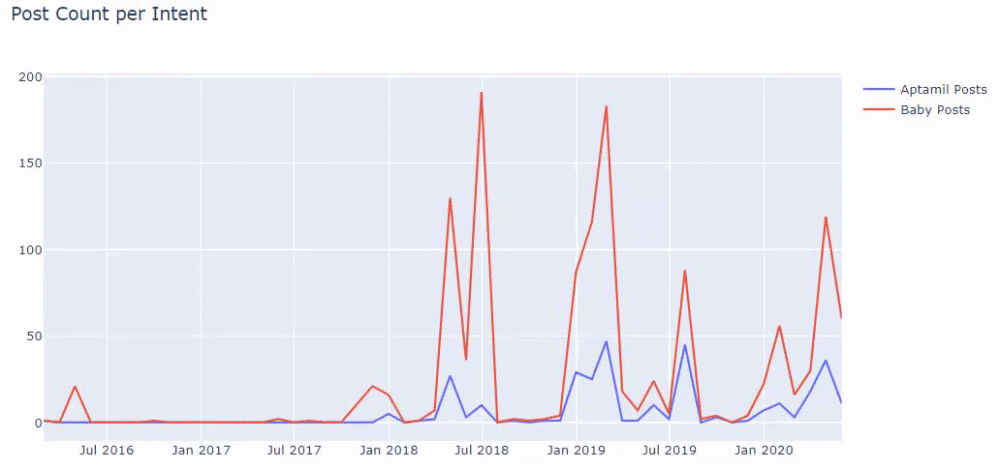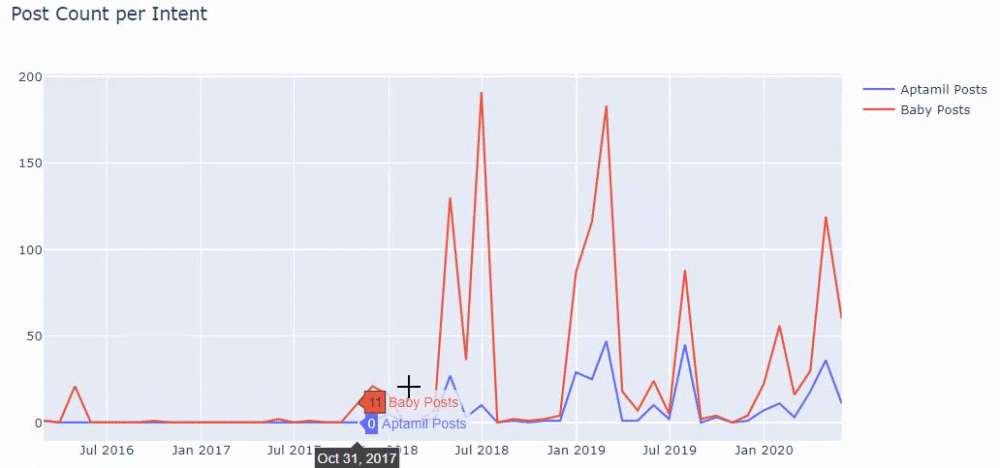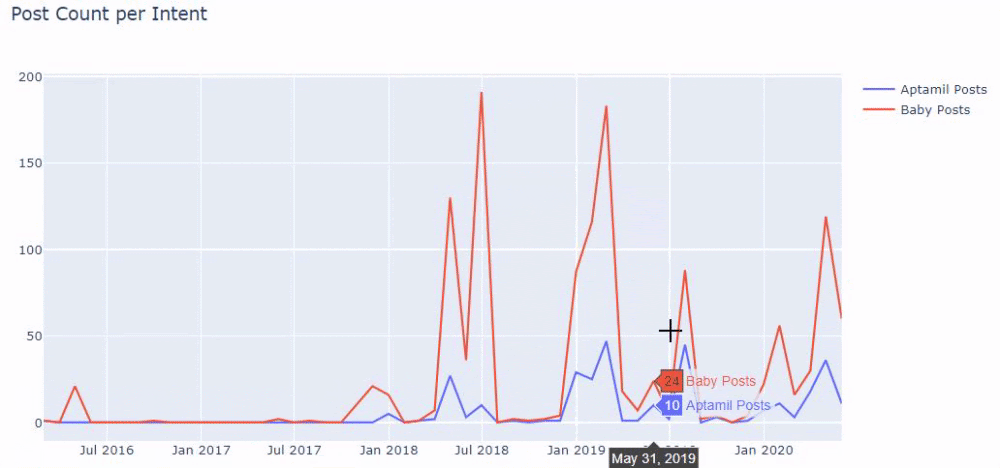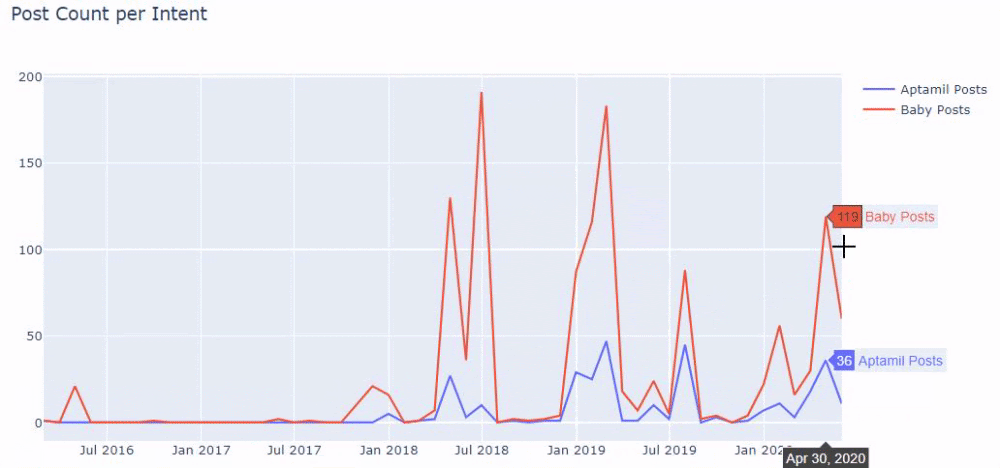
Kode untuk menghasilkan bagan ini tidak dibagikan karena sama dengan yang digunakan untuk bagan sebelumnya
Dengan bantuan operator pencarian di Google, saya mendapatkan 38 hasil ketika saya menginginkan halaman di mana kata Aptamil digunakan dalam teks jangkar di Ilkadimlarim.com. Sejumlah penting halaman ini bersifat informatif dan menghubungkan konten komersial.
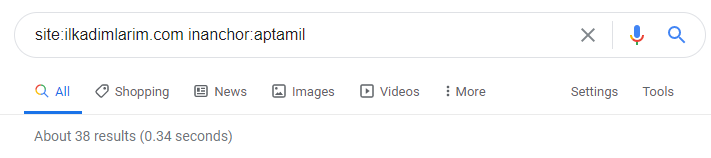
Tesis kami telah terbukti.
“Langkah Pertama Saya” menggunakan ratusan konten informatif tentang ibu, perawatan bayi, dan kehamilan untuk menjangkau audiens targetnya. "Ilkadimlarim" menautkan halaman yang berisi produk Aptamil dari konten ini dan mengarahkan pengguna ke sana.
Perbandingan Profil Konten dan Menganalisis Strategi Konten melalui Peta Situs dengan Python
Sekarang, jika Anda mau, mari lakukan hal yang sama untuk perusahaan dari industri yang sama dan buat perbandingan untuk memahami aspek umum industri ini dan perbedaan strategi antara kedua merek ini.

Sebagai contoh kedua, saya memilih Prima.com.tr, yaitu Pampers, tetapi menggunakan nama merek Prima di Turki. Karena Prima memiliki satu peta situs, kami tidak akan dapat mengklasifikasikan berdasarkan peta situs, tetapi setidaknya mereka memiliki jeda yang berbeda di URL-nya. Jadi kita sangat beruntung: kita harus menulis lebih sedikit kode.
Bayangkan betapa lebih mahalnya algoritme yang harus dijalankan Google untuk Anda saat Anda membuat situs yang sulit dipahami! Ini dapat membantu membuat, perhitungan biaya perayapan menjadi lebih nyata dalam pikiran Anda, bahkan hanya berkenaan dengan struktur URL.
Agar tidak menambah volume artikel lebih jauh, kami tidak menempatkan kode proses yang serupa dengan yang telah kami lakukan.
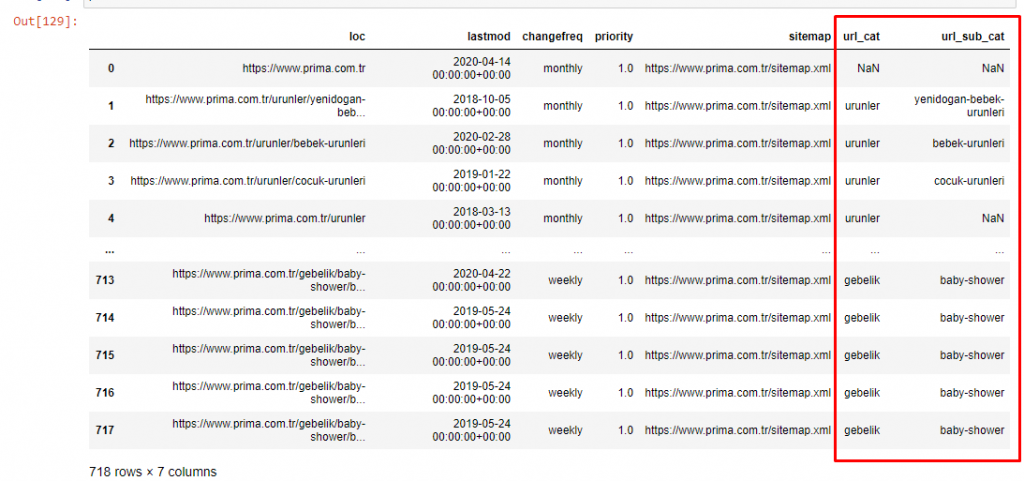
Sekarang, kita dapat memeriksa distribusi kategori konten mereka berdasarkan kategori URL dan subkategori URL. Kami melihat bahwa mereka memiliki jumlah halaman web perusahaan yang berlebihan. Halaman web perusahaan ini ditempatkan di bagian “prima-hakkinda” (“Tentang Prima”). Tetapi ketika saya memeriksanya dengan Python, saya melihat bahwa mereka telah menyatukan produk dan halaman web perusahaan mereka dalam satu kategori. Anda dapat melihat distribusi konten mereka di bawah ini:

Kita dapat melakukan hal yang sama untuk subkategori berikut.
Sangat menarik untuk dicatat bahwa Prima menggunakan "gebelik" (kehamilan dalam bahasa Turki) yang merupakan varian dari "hamilelik" (kehamilan dalam bahasa Arab), dan keduanya berarti masa kehamilan.

Sekarang kita melihat kategorisasi yang lebih dalam pada konten mereka. 9,2% konten tentang kehamilan yang sehat, 7,3% tentang proses tumbuh kembang bayi, 8,3% konten tentang aktivitas yang dapat dilakukan bersama bayi, 0,7% tentang urutan tidur bayi. Bahkan ada topik seperti tumbuh gigi 3,9%, keamanan bayi 1,9%, dan mengungkapkan kehamilan kepada keluarga dengan 1,4%. Seperti yang Anda lihat, Anda dapat mengenal industri hanya dengan URL dan persentase distribusinya.
Ini bukan kategorisasi yang sempurna tapi setidaknya kita bisa melihat pola pikir kompetitor kita dan tren content marketing, serta konten website mereka sesuai kategori. Sekarang mari kita periksa frekuensi penerbitan konten berdasarkan bulan.
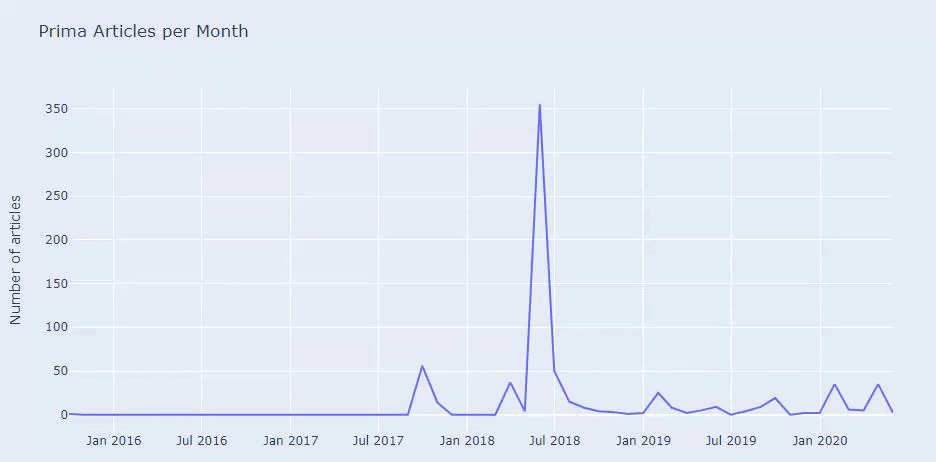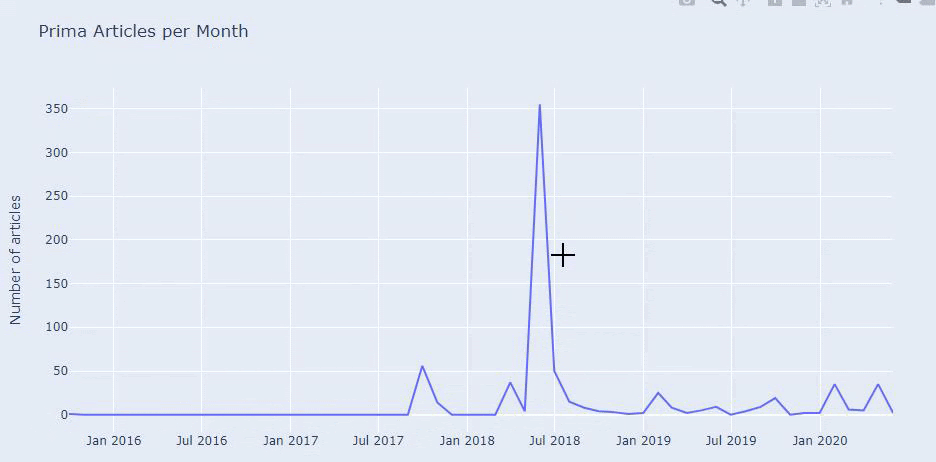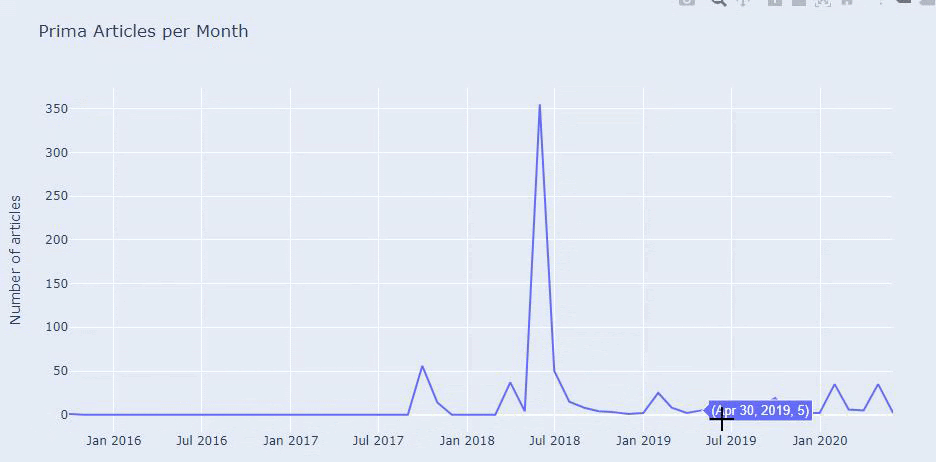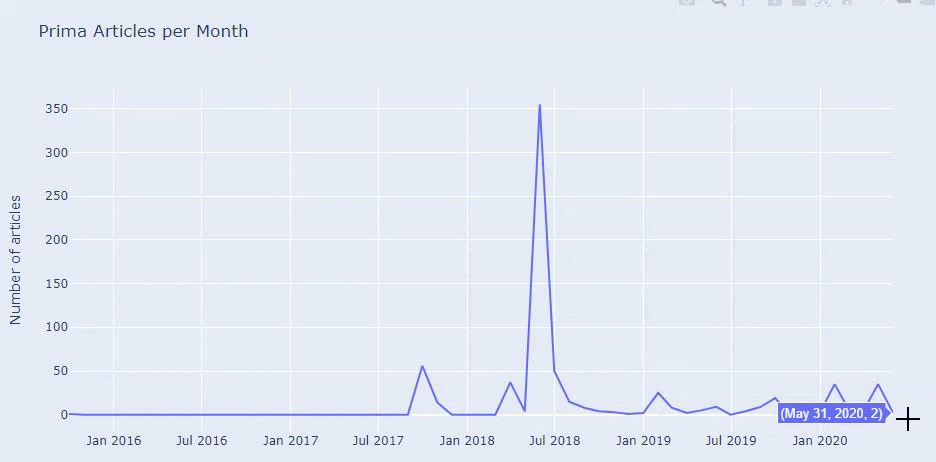
Kami melihat bahwa mereka telah menerbitkan 355 artikel pada Juli 2018 dan menurut Peta Situs, kontennya tidak diperbarui sejak saat itu. Kami juga dapat membandingkan tren penerbitan konten mereka menurut kategori selama bertahun-tahun. Seperti yang Anda lihat, konten mereka terutama terletak di empat kategori berbeda dan sebagian besar diterbitkan di bulan yang sama.
Sebelum melanjutkan, saya harus mengatakan bahwa data peta situs mungkin tidak selalu benar. Misalnya, data Lastmod mungkin telah diperbarui untuk semua URL karena mereka memperbarui semua peta situs pada tanggal ini. Untuk menyiasatinya, kami juga dapat memeriksa bahwa mereka tidak mengubah konten mereka sejak saat itu menggunakan Mesin Wayback.
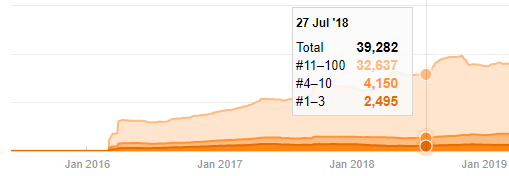
Meski terlihat mencurigakan, data ini bisa jadi nyata. Banyak perusahaan di Turki memiliki kecenderungan untuk memberikan jumlah pesanan yang tinggi dan mempublikasikan konten beberapa saat sebelumnya. Ketika saya memeriksa jumlah kata kunci mereka, saya melihat lompatan pada periode waktu ini. Jadi, jika Anda melakukan profil konten komparatif dan analisis strategi, Anda juga harus memikirkan masalah ini.
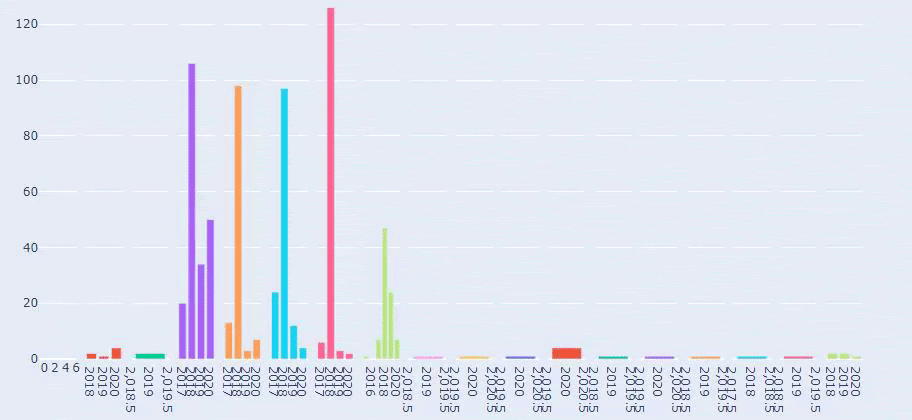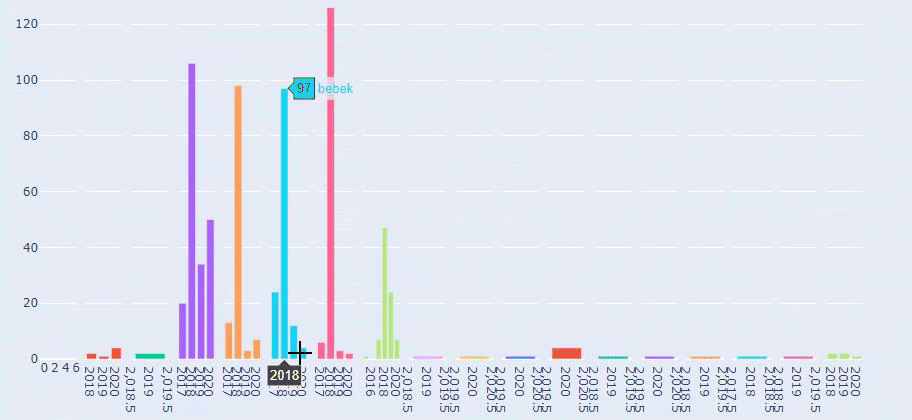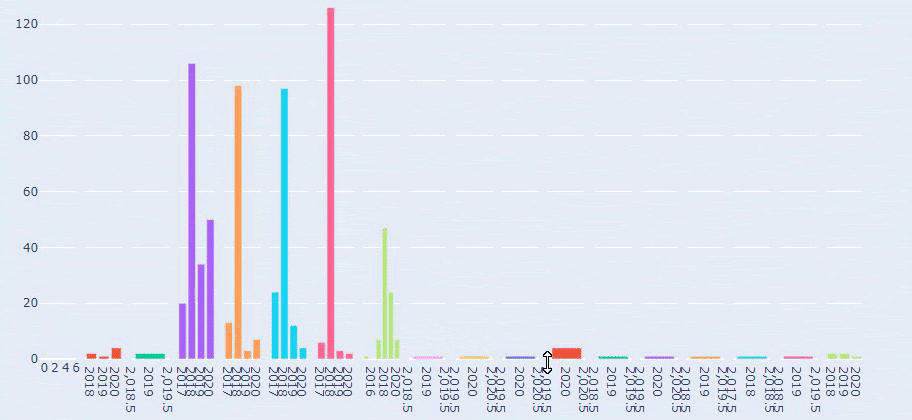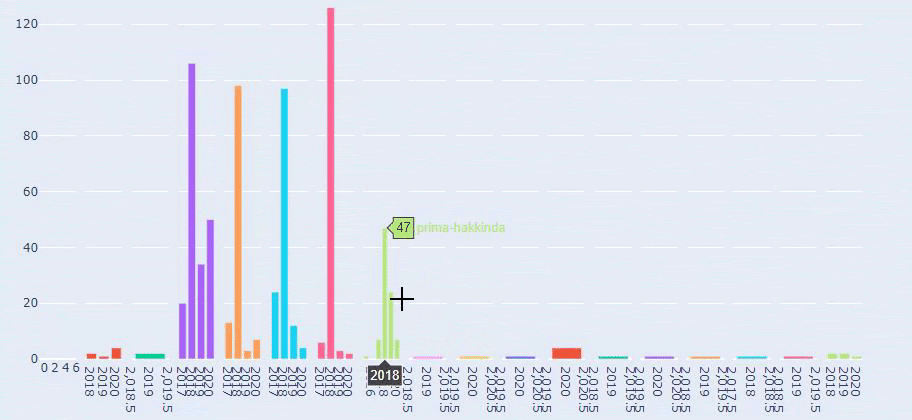
Ini adalah perbandingan antara Tren Penerbitan Konten setiap Kategori dari Tahun ke Tahun untuk Prima.com.tr
Sekarang, kita dapat membandingkan dua kategori konten situs web yang berbeda dan tren penerbitannya.
Jika dilihat dari frekuensi Prima menerbitkan artikel tentang tumbuh kembang bayi, kehamilan dan keibuan, kita melihat kesamaan dengan Ilkadimlarim:
- Sebagian besar artikel diterbitkan pada waktu tertentu.
- Mereka tidak diperbarui untuk waktu yang lama.
- Jumlah produk dan halaman sangat sedikit dibandingkan dengan jumlah halaman konten informatif.
- Baru-baru ini, mereka baru saja menambahkan produk baru ke situs mereka.
Kami dapat menganggap keempat fitur ini sebagai pola pikir default industri dan kami dapat menggunakan kelemahan ini untuk mendukung kampanye kami. Bagaimanapun, kualitas menuntut kesegaran (seperti yang dinyatakan oleh Amit Singhal, Google Fellow).
Pada titik ini, kami juga melihat bahwa industri tidak terbiasa dengan perilaku Googlebot. Daripada mengunggah 250 konten dalam satu hari dan kemudian tidak melakukan perubahan selama setahun, lebih baik menambahkan konten baru secara berkala dan memperbarui konten lama secara berkala. Dengan demikian, Anda dapat menjaga kualitas konten, Googlebot dapat memahami situs Anda dengan lebih mudah, dan nilai frekuensi permintaan perayapan Anda akan lebih tinggi daripada pesaing Anda.
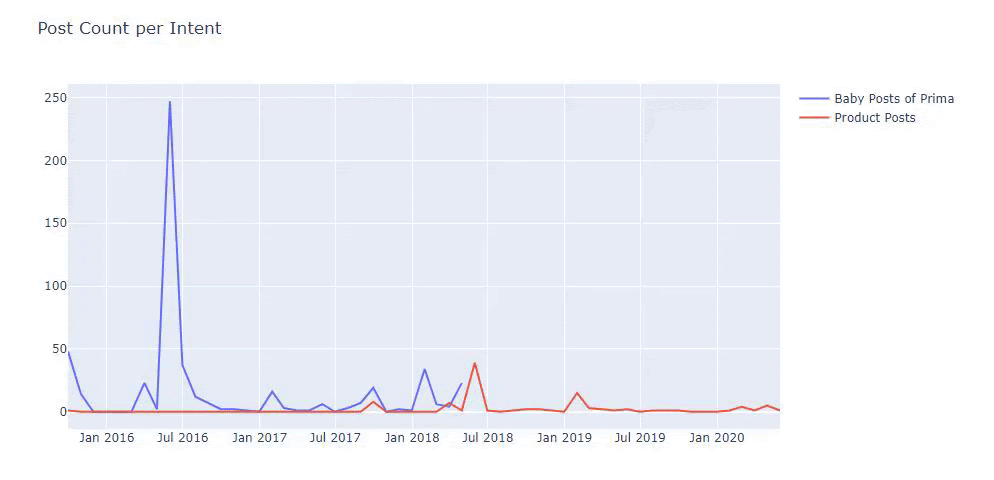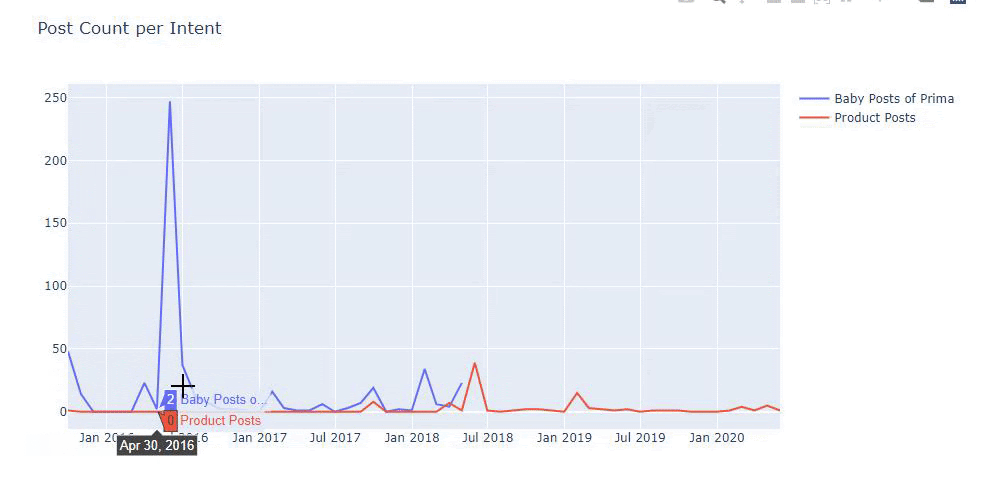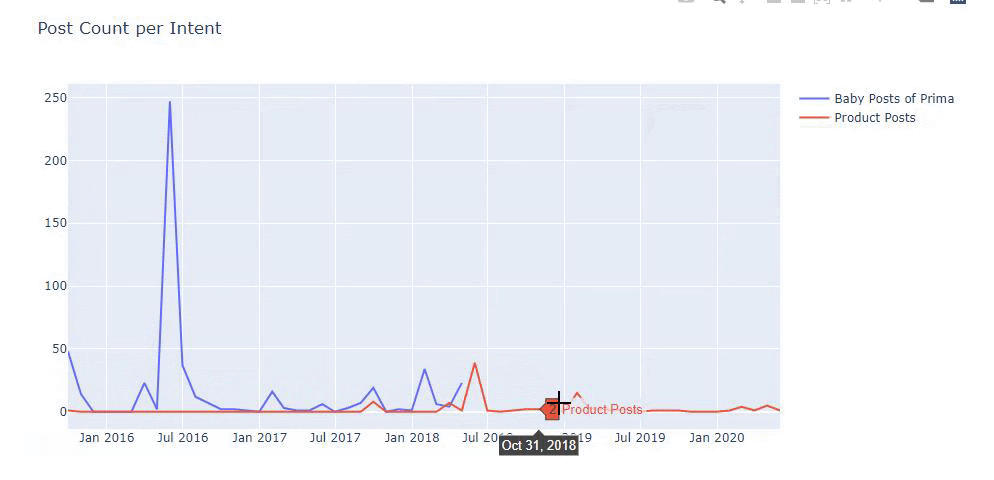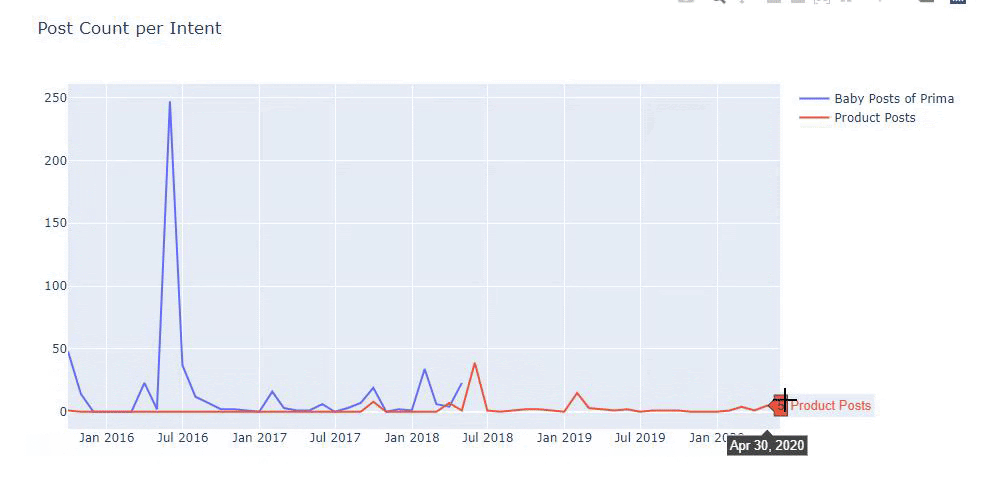
Saya menggunakan metode sebelumnya untuk membedakan antara halaman produk dan konten informatif dan membuat profil kata-kata yang paling sering digunakan di URL. Baby Posts di sini berarti bahwa ini adalah konten yang informatif.
Seperti yang Anda lihat, mereka telah menambahkan 247 konten dalam satu hari. Selain itu, mereka tidak mempublikasikan atau memperbarui konten informatif selama lebih dari satu tahun, dan mereka hanya sesekali menambahkan beberapa halaman produk baru.
Sekarang mari kita bandingkan tren penerbitan mereka dalam satu gambar tetapi dengan dua plot yang berbeda. Saya telah menggunakan kode di bawah ini untuk membuat gambar ini:
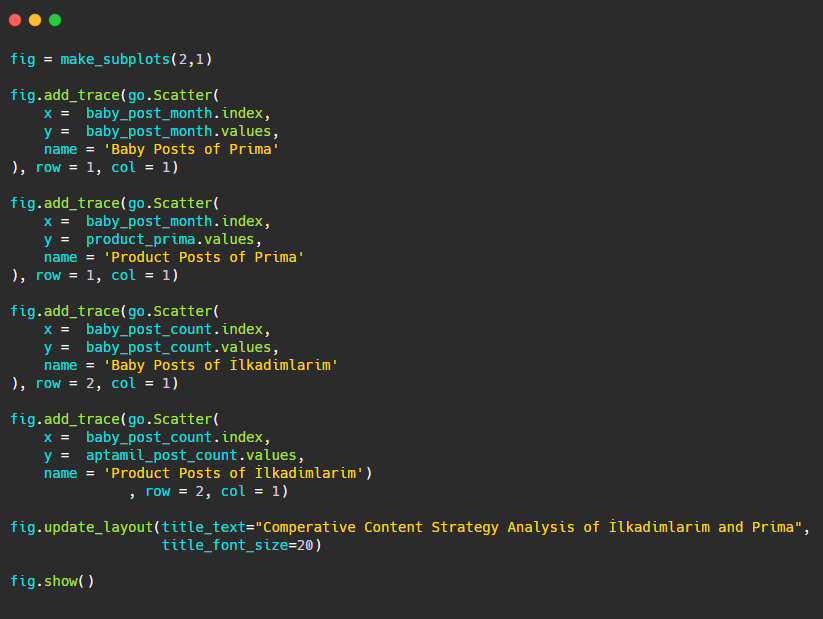
Karena grafik ini berbeda dari yang sebelumnya, saya ingin menunjukkan kodenya kepada Anda. Di sini, dua plot terpisah ditempatkan pada gambar yang sama. Untuk ini, metode make_subplots dipanggil dengan perintah dari plotly.subplots import make_subplots.
Itu dibuat sebagai gambar dua baris dan satu kolom dengan make_subplots (2,1) .
Oleh karena itu, col dan row ditulis di akhir jejak dan posisinya ditentukan. Ini adalah sistem yang siapa pun yang akrab dengan sistem grid di CSS dapat dengan mudah mengenalinya.
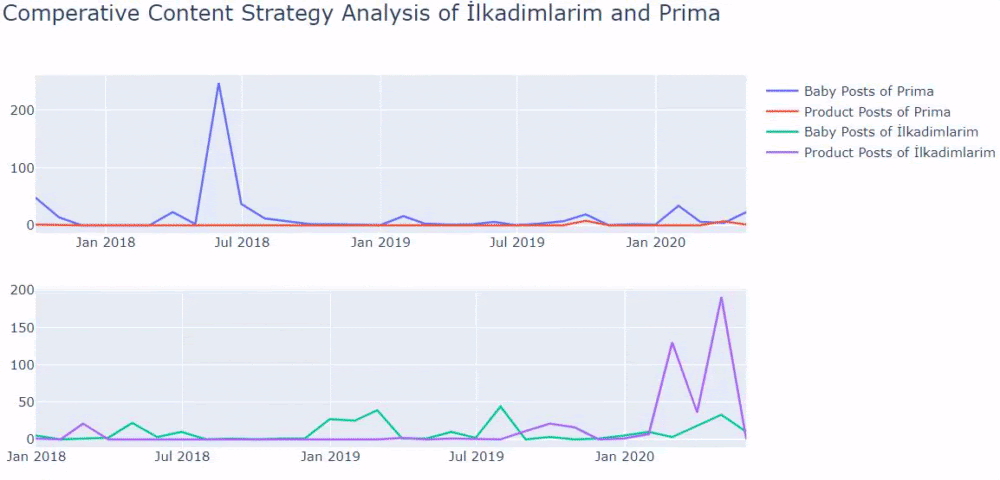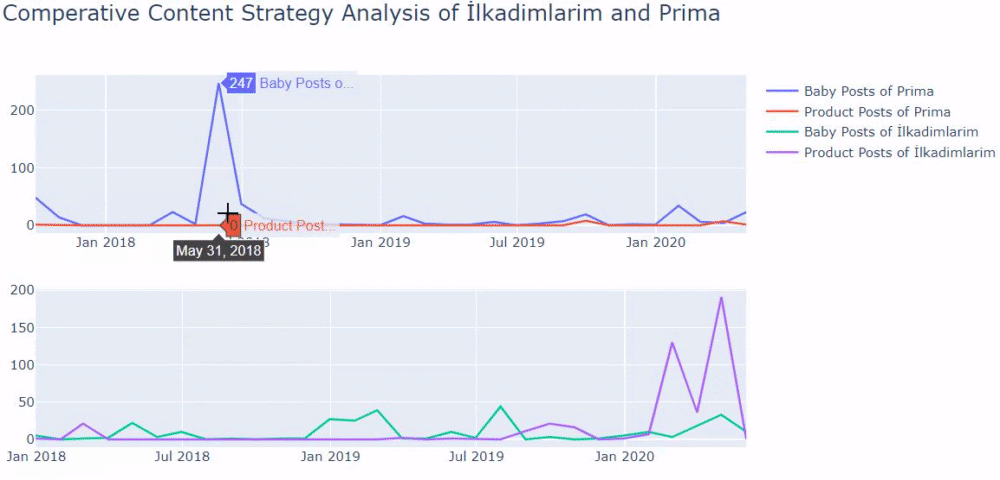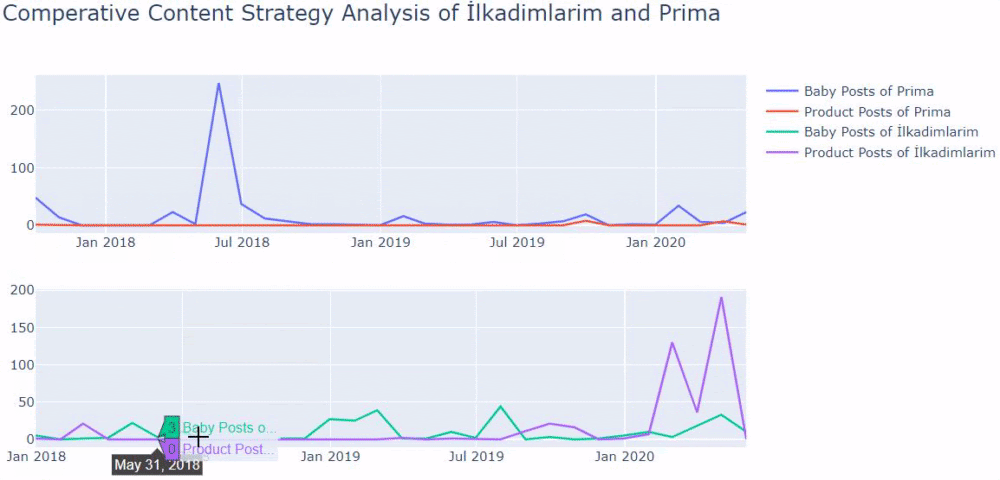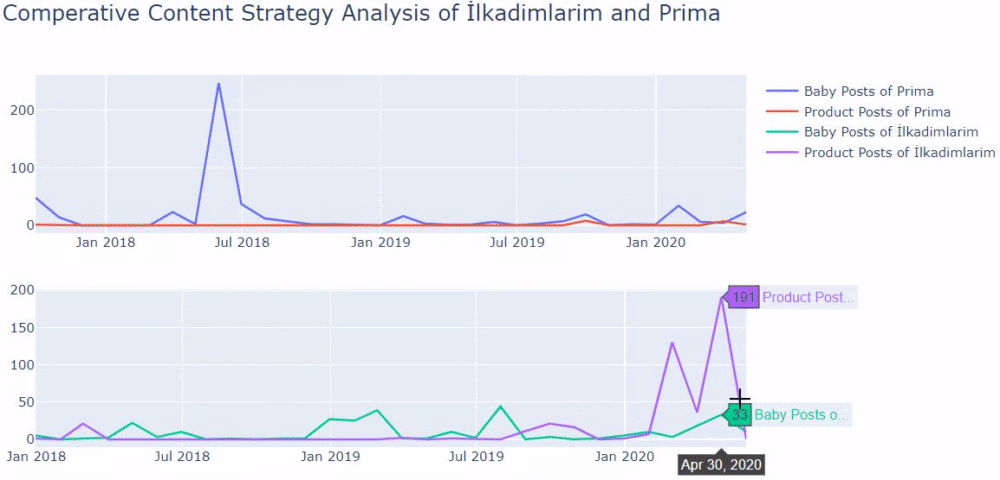
Jika Anda memiliki pelanggan di sektor yang sama, Anda dapat menggunakan data ini untuk membuat strategi konten, untuk melihat kelemahan pesaing Anda dan jaringan kueri/halaman arahan mereka melalui SERP. Selain itu, Anda dapat memahami jumlah konten yang harus Anda publikasikan dalam domain pengetahuan yang sama atau untuk maksud pengguna yang sama.
Sebelum mengakhiri dengan apa yang dapat kita pelajari dari peta situs sebagai bagian dari analisis strategi konten, kita dapat memeriksa satu situs web terakhir dengan jumlah URL yang jauh lebih tinggi dari industri lain.
Analisis Strategi Konten Entitas Web Berita melalui Mata Uang dengan Python dan Peta Situs
Di bagian ini kita akan menggunakan plot peta panas Seaborn dan juga beberapa pembingkaian yang lebih bagus dan metode ekstraksi data.

Elias Dabbas memiliki Arsip Kaggle yang menarik dan sangat berguna dalam hal Ilmu Data dan SEO. Bulan ini, dia telah membuka Bagian Dataset Kaggle baru untuk Situs Berita Turki bagi saya untuk menulis kode yang diperlukan dan melakukan analisis strategi konten dengan Advertools melalui peta situs.
Sebelum saya mulai menggunakan teknik ini di Kaggle, saya ingin menunjukkan beberapa contoh tentang apa yang akan terjadi jika kita menggunakan teknik yang sama pada entitas web yang lebih besar dalam artikel ini.
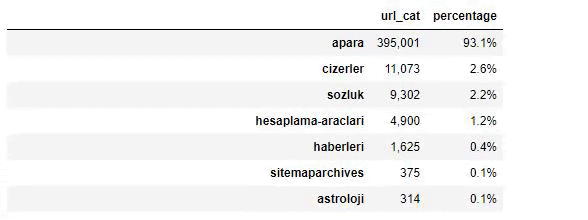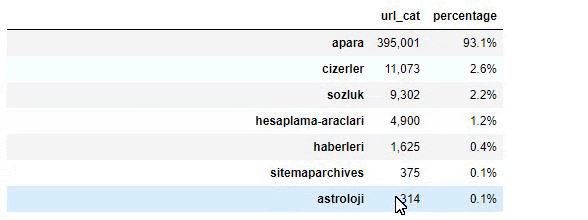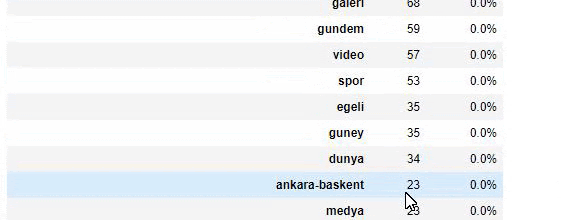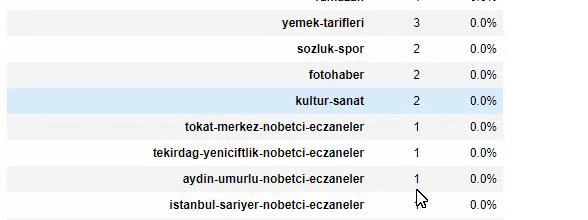
Ketika kita menganalisis isi Surat Kabar Sabah, kita melihat bahwa sebagian besar isinya (81%) berada dalam kategori yang disebut “apara”. Juga, mereka memiliki beberapa kategori besar untuk Astrologi, Perhitungan, Kamus, Cuaca, dan berita Dunia. (Para berarti uang dalam bahasa Turki)
Untuk Surat Kabar Sabah, kami juga dapat menganalisis konten dengan peta situs yang telah kami kumpulkan hanya dengan Advertools, tetapi karena surat kabar yang dimaksud sangat besar, saya tidak menyukainya karena banyaknya peta situs dan konten dari peta situs berbeda yang berisi URL yang sama Kategori.
Di bawah ini Anda juga dapat melihat kelebihan peta situs dengan Advertools.
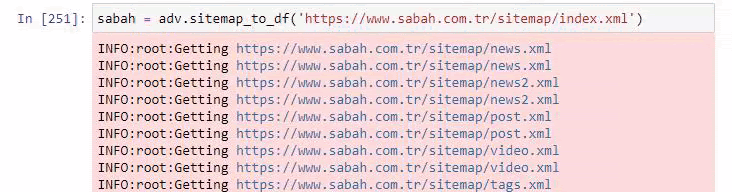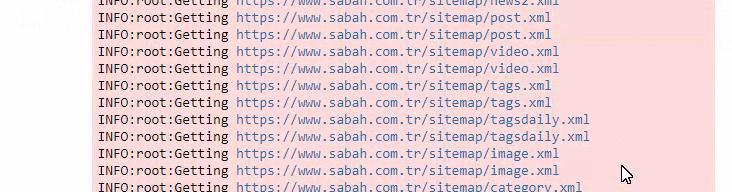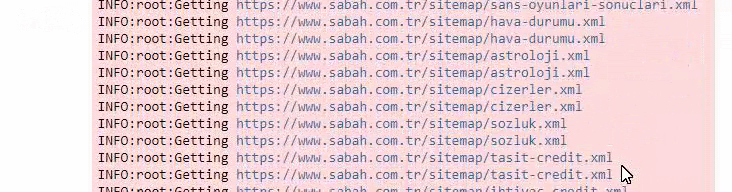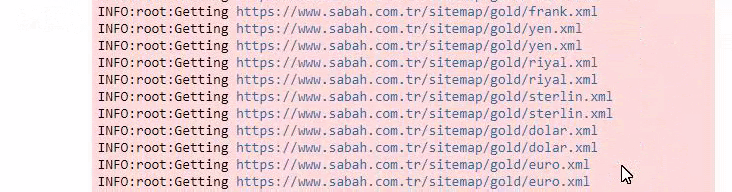
Kami mungkin melihat bahwa mereka memiliki peta situs yang berbeda untuk Kategori URL yang sama seperti Emas, Kredit, Mata Uang, Tag, Waktu Sholat dan Jam Kerja Apotek, dll…
Singkatnya, kami dapat mencapai detail ini dengan berfokus pada subkategori URL. Alih-alih menyatukan peta situs yang berbeda melalui variabel. Jadi, saya telah menyatukan semua peta situs dengan metode sitemap_to_df() Advertools seperti di awal artikel.
Kita juga dapat menggunakan kumpulan fungsi lain yang dibuat oleh Elias Dabbas untuk membuat bingkai data yang lebih baik. Jika Anda memeriksa fungsi dataset_utitilites, Anda dapat melihat beberapa contoh. Kode di bawah ini memberikan total dan persentase dari ekspresi reguler URL yang ditentukan bersama dengan jumlah kumulatif dengan menyesuaikan gaya.
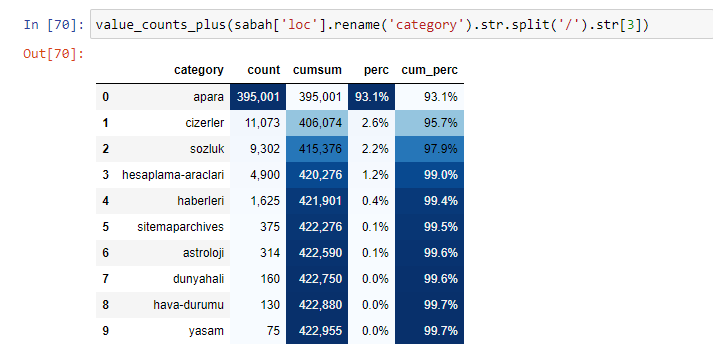
Jika kita melakukan hal yang sama pada perincian sub-URL Koran Sabah, kita akan mendapatkan hasil sebagai berikut.
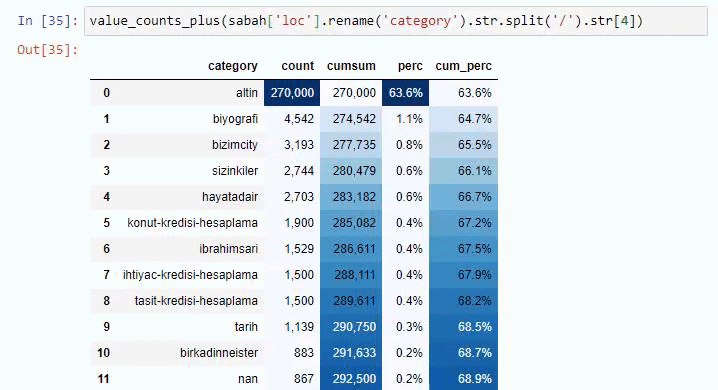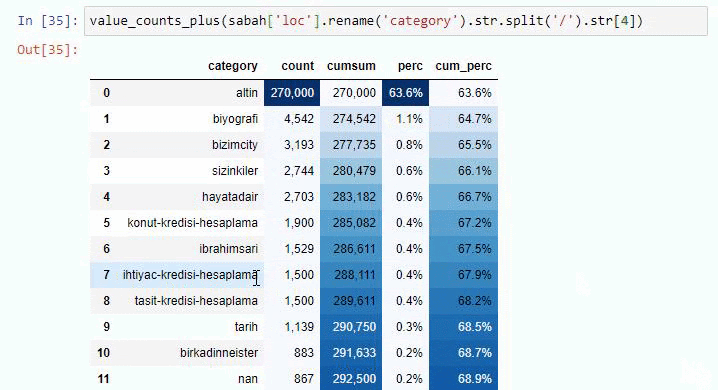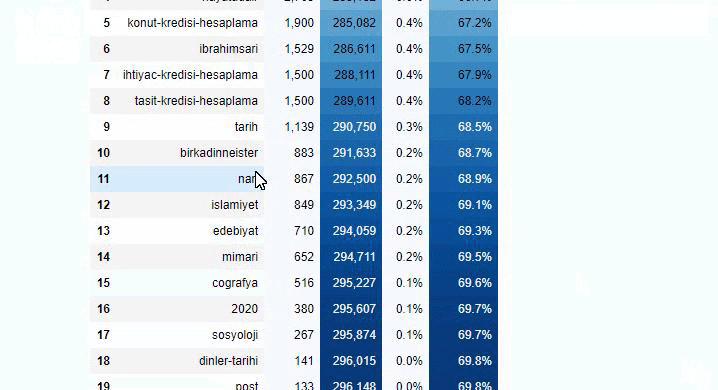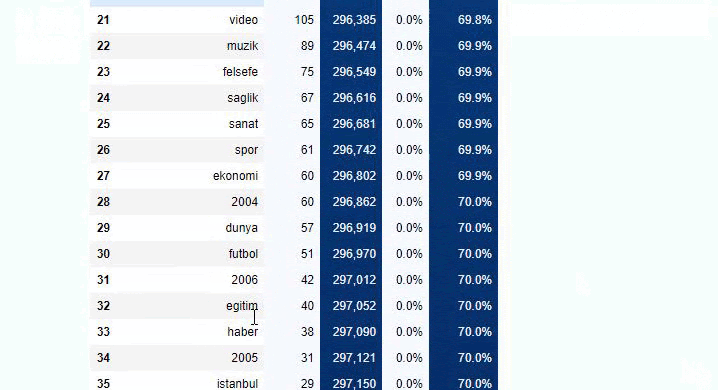
Anda dapat menambah jumlah baris yang akan dihasilkan oleh fungsi tersebut dengan mengubah baris di bawah ini. Juga, jika Anda memeriksa konten fungsi, Anda akan melihat bahwa itu mirip dengan yang kami gunakan sebelumnya.
Dalam sub-breaking, kita melihat rincian yang berbeda seperti “Riwayat Agama”, “Biografi”, “Nama Kota”, “Sepak Bola”, “Bizimcity (Karikatur)”, “Kredit Hipotek”. Breakdown terbesar ada di kategori “Emas”.
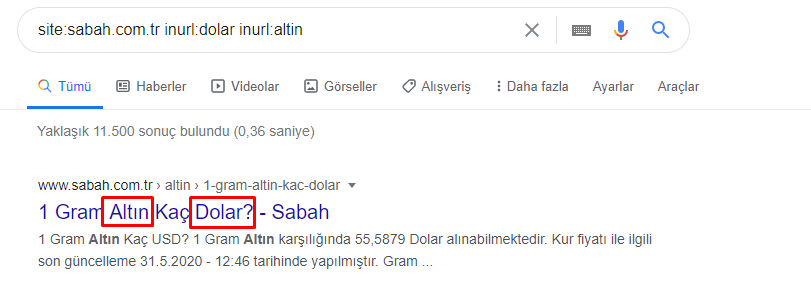
Jadi bagaimana surat kabar memiliki 295.000 URL untuk Harga Emas?
Pertama-tama, saya membuang semua URL yang berisi "apara" dalam pemecahan URL pertama Koran Sabah ke dalam sebuah variabel.
apara = sabah[sabah['loc'].str.contains('apara')]
Inilah hasilnya:
Kami juga dapat memfilter kolom dengan metode .filter():
Sekarang, kita dapat melihat di bagian bawah DataFrame mengapa Surat Kabar Sabah memiliki jumlah URL Apara yang berlebihan karena mereka telah membuka halaman web yang berbeda untuk setiap jumlah perhitungan mata uang seperti 5000 Euro, 4999 Euro, 4998 Euro dan banyak lagi…
Namun, sebelum menyimpulkan apa pun, kita perlu yakin karena lebih dari 250.000 URL ini termasuk dalam kategori 'altin (emas)'.
apara.filter(['loc', 'url_sub_cat' ]).tail(60) akan menunjukkan 60 baris terakhir dari Data Frame ini:

Kita dapat melakukan hal yang sama untuk perincian URL emas dalam grup Apara.
emas = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
Pada titik ini, kita melihat bahwa Koran Sabah telah membuka 5000 halaman berbeda untuk mengkonversi setiap mata uang menjadi Dolar, Euro, Emas, dan TL (Lira Turki). Ada halaman perhitungan terpisah untuk setiap unit uang antara 1 dan 5000. Anda dapat melihat contoh 85 baris pertama dan 85 terakhir dari kelompok emas di bawah ini. Halaman terpisah telah dibuka untuk setiap gram harga emas.


Kami yakin bahwa halaman-halaman ini tidak diperlukan, dengan banyak konten duplikat, dan terlalu besar, tetapi Sabah Newspaper adalah situs web yang sangat kuat sehingga Google terus menampilkannya di hampir setiap kueri, peringkat teratas.
Pada titik ini, kita juga dapat melihat bahwa Toleransi Biaya Perayapan tinggi untuk situs berita lama dengan otoritas tinggi.
Namun, ini tidak menjelaskan mengapa kategori emas memiliki lebih banyak URL daripada yang lain.
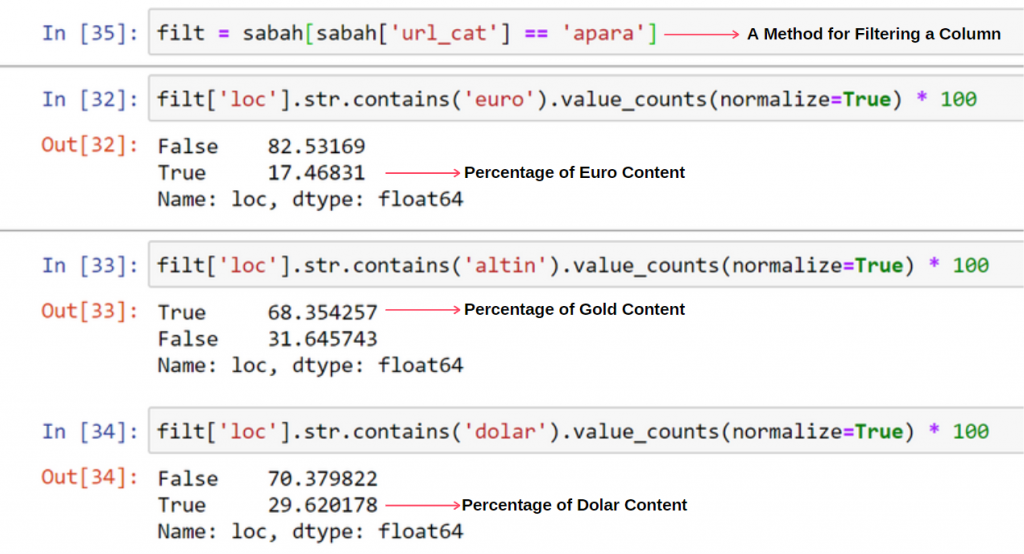
Saya tidak melihat sesuatu yang aneh tentang nilai yang tumpang tindih yang bertambah hingga lebih dari 100%.
Kecuali aku kehilangan sesuatu?
Seperti yang akan Anda perhatikan, ketika kami menambahkan semua Nilai Sejati, kami mendapatkan hasil 115,16%. Alasannya ada di bawah ini.
Bahkan kelompok utama memiliki persimpangan satu sama lain seperti ini. Kami juga dapat menganalisis persimpangan ini, tetapi itu bisa menjadi subjek artikel lain.
Kami melihat bahwa 68% konten dalam grup URL Apara terkait dengan EMAS.
Untuk lebih memahami situasi ini, hal pertama yang perlu kita lakukan adalah memindai URL di refraksi emas.
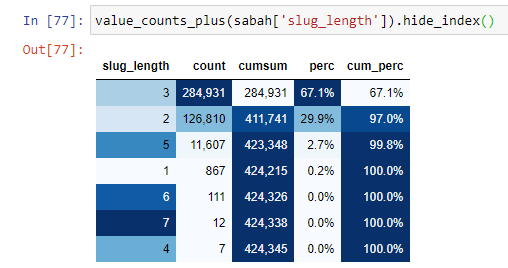
Ketika kami mengklasifikasikan URL menurut jumlah '/' yang mereka miliki sejak bagian root, kami melihat bahwa jumlah URL dengan maksimum 3 jeda tinggi. Saat kami menganalisis URL ini, kami melihat bahwa 270.000 dari 3 URL slug_length berada dalam kategori Emas.
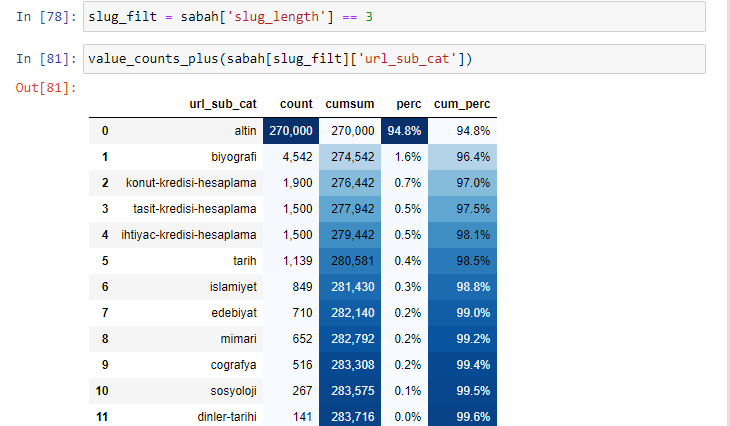
morning_filt = morning ['slug_length'] == 3 Artinya Anda hanya mendapatkan yang sama dengan 3 dari grup data tipe data int di kolom tertentu dari bingkai data tertentu. Kemudian, berdasarkan informasi ini, kami membingkai URL yang sesuai dengan kondisi dengan jumlah, jumlah, dan tingkat agregasi dengan jumlah kumulatif.
Saat kami mengekstrak kata-kata yang paling umum digunakan di URL emas, kami menemukan kata-kata yang mewakili "penuh", "republik", "seperempat", "gram", "setengah", "leluhur". Jenis emas Ata dan Republik unik untuk Turki. Salah satunya mewakili Kedaulatan Turki dan yang lainnya adalah Pendiri Republik, Kemal Ataturk. Itu sebabnya volume pencarian kueri mereka tinggi.
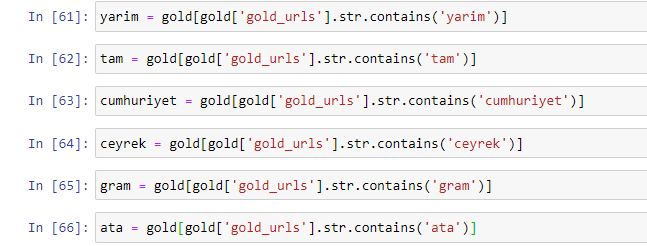
Pertama-tama, kami telah menghapus kata-kata umum yang ditemukan di URL dan menetapkannya ke variabel terpisah. Selanjutnya, kita akan menggunakan variabel-variabel ini di Gold DataFrame untuk membuat kolom khusus untuk tipenya.
Setelah membuat kolom baru melalui variabel, kita harus memfilternya bersama dengan nilai boolean.
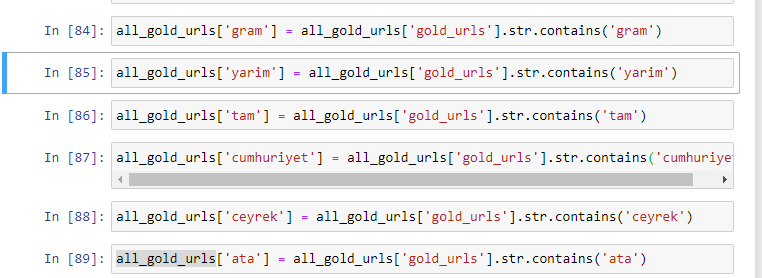
Seperti yang Anda lihat, kami dapat mengkategorikan semua URL emas dengan 270.000 baris dan 6 kolom. Alasan utama tingginya jumlah halaman khusus emas adalah karena Dolar atau Euro tidak memiliki jenis yang terpisah, sedangkan emas memiliki jenis yang terpisah. Pada saat yang sama, keragaman halaman persilangan antara emas dan mata uang yang berbeda lebih tinggi daripada mata uang lainnya karena kepercayaan tradisional mereka pada orang Turki.
Menurut saya, semua jenis halaman emas harus didistribusikan secara merata, bukan?
Kita dapat dengan mudah menguji ini dengan fitur Heatmap Seaborn.
impor seaborn sebagai sns
impor matplotlib.pyplot sebagai plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.tampilkan()
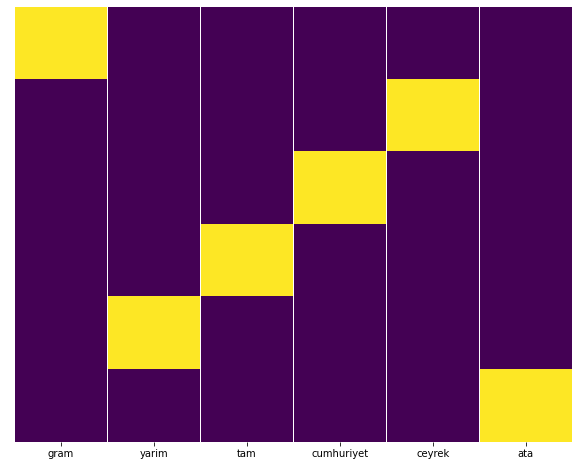
Di sini, di Heat Map, Trues di setiap kolom hanya ditandai. Seperti dapat dilihat, ukuran masing-masing simetris satu sama lain dan tersusun rapi di peta.
Dengan demikian, kami telah mengambil perspektif yang luas tentang kebijakan konten Surat Kabar Sabah.com.tr tentang Mata Uang dan Perhitungan Mata Uang.
Di masa depan, saya akan menulis Situs Web Berita Turki dan strategi kontennya berdasarkan Peta Situs Kaggle, yang diluncurkan oleh Elias Dabbas, tetapi dalam artikel ini, kita sudah cukup berbicara tentang apa yang dapat ditemukan di situs web besar dan kecil dengan peta situs .
Kesimpulan dan Takeaways
Saya rasa kita telah melihat betapa mudahnya memahami sebuah situs web, berkat struktur URL yang halus dan semantik. Kita juga harus ingat betapa berharganya struktur URL yang tepat bagi Google.
Di masa depan, kita akan melihat banyak SEO yang semakin akrab dengan ilmu data, visualisasi data, pemrograman front-end, dan banyak lagi… Saya melihat proses ini sebagai awal dari perubahan yang tak terhindarkan: kesenjangan antara SEO dan pengembang akan tertutup sepenuhnya dalam beberapa tahun.
Dengan Python, Anda dapat melakukan analisis semacam ini lebih jauh: dimungkinkan untuk mendapatkan data dari memahami pandangan politik situs berita, hingga siapa yang menulis tentang apa, seberapa sering, dan dengan perasaan apa. Saya lebih suka untuk tidak membahasnya di sini karena proses ini lebih tentang ilmu data murni daripada SEO (dan artikel ini sudah cukup panjang).
Tetapi jika Anda tertarik, ada banyak jenis audit lain yang dapat dilakukan melalui Peta Situs dan Python, seperti memeriksa kode status URL di peta situs.
Saya menantikan untuk bereksperimen dan berbagi tugas SEO lain yang dapat Anda lakukan dengan Python dan Advertools.