
Memahami AI: Bagaimana kami mengajarkan bahasa alami pada komputer
Diterbitkan: 2023-11-28Ungkapan “kecerdasan buatan” telah digunakan dalam kaitannya dengan komputer sejak tahun 1950-an, namun hingga tahun lalu, kebanyakan orang mungkin menganggap AI masih lebih bersifat fiksi ilmiah daripada realitas teknologi.
Hadirnya ChatGPT OpenAI pada bulan November 2022 tiba-tiba mengubah persepsi orang mengenai kemampuan pembelajaran mesin – namun apa sebenarnya ChatGPT yang membuat dunia tersadar dan menyadari bahwa kecerdasan buatan ada di sini secara besar-besaran?
Singkatnya, bahasa – alasan ChatGPT terasa seperti lompatan maju yang luar biasa adalah karena ia tampak fasih dalam bahasa alami dengan cara yang belum pernah dilakukan chatbot sebelumnya.
Hal ini menandai tahap baru yang luar biasa dalam “pemrosesan bahasa alami” (NLP), yaitu kemampuan komputer untuk menafsirkan bahasa alami dan menghasilkan respons yang meyakinkan. ChatGPT dibangun di atas “model bahasa besar” (LLM), yang merupakan jenis jaringan saraf menggunakan pembelajaran mendalam yang dilatih pada kumpulan data besar yang dapat memproses dan menghasilkan konten.
“Bagaimana program komputer mencapai kefasihan linguistik seperti itu?”
Tapi bagaimana kita sampai di sini? Bagaimana program komputer mencapai kefasihan linguistik seperti itu? Bagaimana kedengarannya sangat manusiawi?
ChatGPT tidak diciptakan dalam ruang hampa – ia dibangun berdasarkan berbagai inovasi dan penemuan selama beberapa dekade terakhir. Serangkaian terobosan yang menghasilkan ChatGPT merupakan tonggak sejarah dalam ilmu komputer, namun ada kemungkinan bahwa terobosan tersebut meniru tahap-tahap yang dilalui manusia dalam memperoleh bahasa.
Bagaimana kita belajar bahasa?
Untuk memahami bagaimana AI mencapai tahap ini, ada baiknya mempertimbangkan sifat pembelajaran bahasa itu sendiri – kita mulai dengan satu kata dan kemudian mulai menggabungkannya menjadi rangkaian yang lebih panjang hingga kita dapat mengkomunikasikan konsep, ide, dan instruksi yang kompleks.
Misalnya, beberapa tahapan umum pemerolehan bahasa pada anak-anak adalah:
- Tahap Holofrastik: Antara usia 9-18 bulan, anak belajar menggunakan satu kata yang menggambarkan kebutuhan atau keinginan dasar mereka. Berkomunikasi dengan satu kata berarti ada penekanan pada kejelasan dibandingkan kelengkapan konseptual. Jika seorang anak lapar, mereka tidak akan mengatakan “Saya ingin makan” atau “Saya lapar”, melainkan hanya mengatakan “makanan” atau “susu”.
- Tahap dua kata: Pada usia 18-24 bulan, anak mulai menggunakan pengelompokan dua kata sederhana untuk meningkatkan keterampilan komunikasinya. Kini mereka dapat mengomunikasikan perasaan dan kebutuhannya dengan ungkapan seperti “lebih banyak makanan” atau “baca buku”.
- Tahap telegraf: Antara usia 24-30 bulan, anak mulai merangkai beberapa kata menjadi satu untuk membentuk frasa dan kalimat yang lebih kompleks. Jumlah kata yang digunakan masih sedikit tetapi susunan kata yang benar dan kompleksitas mulai terlihat. Anak-anak mulai mempelajari konstruksi kalimat dasar, seperti “saya ingin menunjukkannya kepada ibu”.
- Tahap multi-kata: Setelah 30 bulan, anak-anak mulai beralih ke tahap multi-kata. Pada tahap ini anak-anak mulai menggunakan kalimat yang lebih benar secara tata bahasa, kompleks, dan multi-klausa. Ini adalah tahap akhir pemerolehan bahasa dan anak-anak pada akhirnya berkomunikasi dengan kalimat kompleks seperti “Jika hujan, saya ingin tetap di dalam dan bermain game.”
Salah satu tahapan penting pertama dalam penguasaan bahasa adalah kemampuan untuk mulai menggunakan satu kata dengan cara yang sangat sederhana. Jadi kendala pertama yang perlu diatasi oleh peneliti AI adalah bagaimana melatih model untuk mempelajari asosiasi kata sederhana.
Model 1 – Mempelajari Kata Tunggal dengan Word2Vec (kertas 1 dan kertas 2)
Salah satu model jaringan saraf awal yang mencoba mempelajari asosiasi kata dengan cara ini adalah Word2Vec, yang dikembangkan oleh Tomaš Mikolov dan sekelompok peneliti di Google. Hal ini diterbitkan dalam dua makalah pada tahun 2013 (yang menunjukkan betapa cepatnya perkembangan di bidang ini.)
Model-model ini dilatih dengan belajar mengasosiasikan kata-kata yang biasa digunakan bersama-sama. Pendekatan ini dibangun berdasarkan intuisi pionir linguistik awal seperti John R. Firth, yang mencatat bahwa makna dapat diperoleh dari asosiasi kata: “Anda akan mengetahui sebuah kata dari kata yang digunakannya.”
Idenya adalah bahwa kata-kata yang memiliki makna semantik yang serupa cenderung lebih sering muncul bersamaan. Kata “kucing” dan “anjing” umumnya lebih sering muncul bersamaan dibandingkan dengan kata seperti “apel” atau “komputer”. Dengan kata lain, kata “kucing” seharusnya lebih mirip dengan kata “anjing” dibandingkan “kucing” dengan “apel” atau “komputer”.
Hal yang menarik tentang Word2Vec adalah bagaimana ia dilatih untuk mempelajari asosiasi kata berikut:
- Tebak kata target: Model diberikan sejumlah kata tetap sebagai masukan dengan kata target yang hilang dan model harus menebak kata target yang hilang. Ini dikenal sebagai Continuous Bag Of Words (CBOW).
- Tebak kata-kata di sekitarnya: Model diberikan satu kata dan kemudian ditugaskan untuk menebak kata-kata di sekitarnya. Ini dikenal sebagai Skip-Gram dan merupakan pendekatan kebalikan dari CBOW karena kita memprediksi kata-kata di sekitarnya.
Salah satu keuntungan dari pendekatan ini adalah Anda tidak perlu memiliki data berlabel apa pun untuk melatih model – memberi label pada data, misalnya mendeskripsikan teks sebagai “positif” atau “negatif” untuk mengajarkan analisis sentimen, merupakan pekerjaan yang lambat dan melelahkan.
Salah satu hal yang paling mengejutkan tentang Word2Vec adalah hubungan semantik kompleks yang ditangkap dengan pendekatan pelatihan yang relatif sederhana. Word2Vec mengeluarkan vektor yang mewakili kata masukan. Dengan melakukan operasi matematika pada vektor-vektor ini, penulis dapat menunjukkan bahwa vektor kata tidak hanya menangkap unsur-unsur yang mirip secara sintaksis tetapi juga hubungan semantik yang kompleks.
Hubungan ini berkaitan dengan bagaimana kata-kata tersebut digunakan. Contoh yang penulis catat adalah hubungan antara kata-kata seperti “Raja” dan “Ratu” dan “Pria” dan “Wanita”.
Namun meski merupakan sebuah langkah maju, Word2Vec memiliki batasan. Definisinya hanya satu untuk setiap kata – misalnya, kita semua tahu bahwa “bank” dapat memiliki arti yang berbeda-beda, bergantung pada apakah Anda berencana untuk mempertahankannya atau memancing dari bank tersebut. Word2Vec tidak peduli, ia hanya memiliki satu definisi kata “bank” dan akan menggunakannya dalam semua konteks.
Yang terpenting, Word2Vec tidak dapat memproses instruksi atau bahkan kalimat. Ia hanya dapat mengambil sebuah kata sebagai masukan dan keluarannya sebuah “penyematan kata”, atau representasi vektor, yang telah dipelajarinya untuk kata tersebut. Untuk membangun landasan kata tunggal ini, para peneliti perlu menemukan cara untuk merangkai dua kata atau lebih secara berurutan. Kita dapat membayangkan ini mirip dengan tahap pemerolehan bahasa dua kata.
Model 2 – Mempelajari urutan kata dengan RNN dan Urutan teks
Ketika anak-anak mulai menguasai penggunaan satu kata, mereka mencoba menyusun kata-kata untuk mengekspresikan pikiran dan perasaan yang lebih kompleks. Demikian pula, langkah selanjutnya dalam pengembangan NLP adalah mengembangkan kemampuan memproses rangkaian kata. Masalah dengan pemrosesan urutan teks adalah panjangnya tidak tetap. Sebuah kalimat dapat bervariasi panjangnya dari beberapa kata hingga paragraf yang panjang. Tidak semua rangkaian penting bagi keseluruhan makna dan konteks. Namun kita harus mampu memproses keseluruhan rangkaian untuk mengetahui bagian mana yang paling relevan.
Di situlah Recurrent Neural Networks (RNNs) muncul.
Dikembangkan pada tahun 1990-an, RNN bekerja dengan memproses masukannya dalam satu lingkaran di mana keluaran dari langkah-langkah sebelumnya dibawa melalui jaringan saat ia melakukan iterasi melalui setiap langkah dalam urutan.
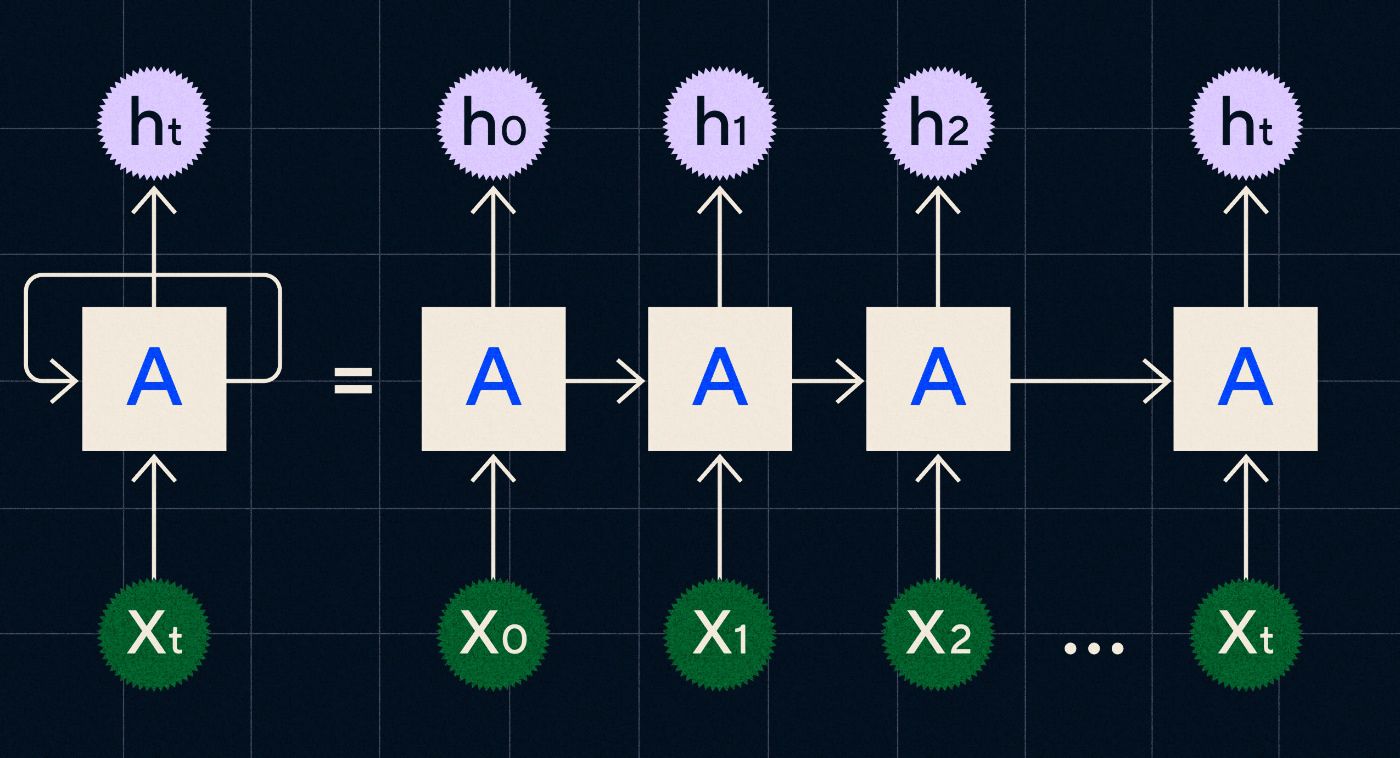
Sumber: Entri blog Christopher Olah di RNN
Diagram di atas menunjukkan bagaimana menggambarkan RNN sebagai rangkaian jaringan saraf (A) yang keluaran dari langkah sebelumnya (h0, h1, h2…ht) dibawa ke langkah berikutnya. Pada setiap langkah masukan baru (X0, X1, X2… Xt) juga diproses oleh jaringan.
RNN (dan khususnya jaringan Memori Jangka Pendek Panjang, atau LSTM, jenis RNN khusus yang diperkenalkan oleh Sepp Hochreiter dan Jurgen Schmidhuber pada tahun 1997) memungkinkan kami membuat arsitektur jaringan saraf yang dapat melakukan tugas yang lebih kompleks seperti penerjemahan.
Pada tahun 2014, sebuah makalah diterbitkan oleh Ilya Sutskever (salah satu pendiri OpenAI), Oriol Vinyals dan Quoc V Le di Google, yang menjelaskan model Sequence to Sequence (Seq2Seq). Makalah ini menunjukkan bagaimana Anda dapat melatih jaringan saraf untuk mengambil teks masukan dan mengembalikan terjemahan teks tersebut. Anda dapat menganggap ini sebagai contoh awal jaringan saraf generatif, di mana Anda memberikan perintah dan mengembalikan respons. Namun, tugasnya telah diperbaiki, jadi jika ia dilatih tentang penerjemahan, Anda tidak dapat “memintanya” untuk melakukan hal lain.
Ingatlah bahwa model sebelumnya, Word2Vec, hanya dapat memproses satu kata. Jadi jika Anda memberikan kalimat seperti “dokter gigi mencabut gigi saya”, itu hanya akan menghasilkan vektor untuk setiap kata seolah-olah tidak ada hubungannya.
Namun, urutan dan konteks penting untuk tugas-tugas seperti penerjemahan. Anda tidak bisa hanya menerjemahkan kata satu per satu, Anda perlu menguraikan rangkaian kata dan kemudian menampilkan hasilnya. Di sinilah RNN mengaktifkan model Seq2Seq untuk memproses kata-kata dengan cara ini.
Kunci dari model Seq2Seq adalah desain jaringan saraf, yang menggunakan dua RNN secara berurutan. Salah satunya adalah encoder yang mengubah masukan dari teks menjadi penyematan, dan yang lainnya adalah decoder yang mengambil masukan dari penyematan yang dihasilkan oleh encoder:
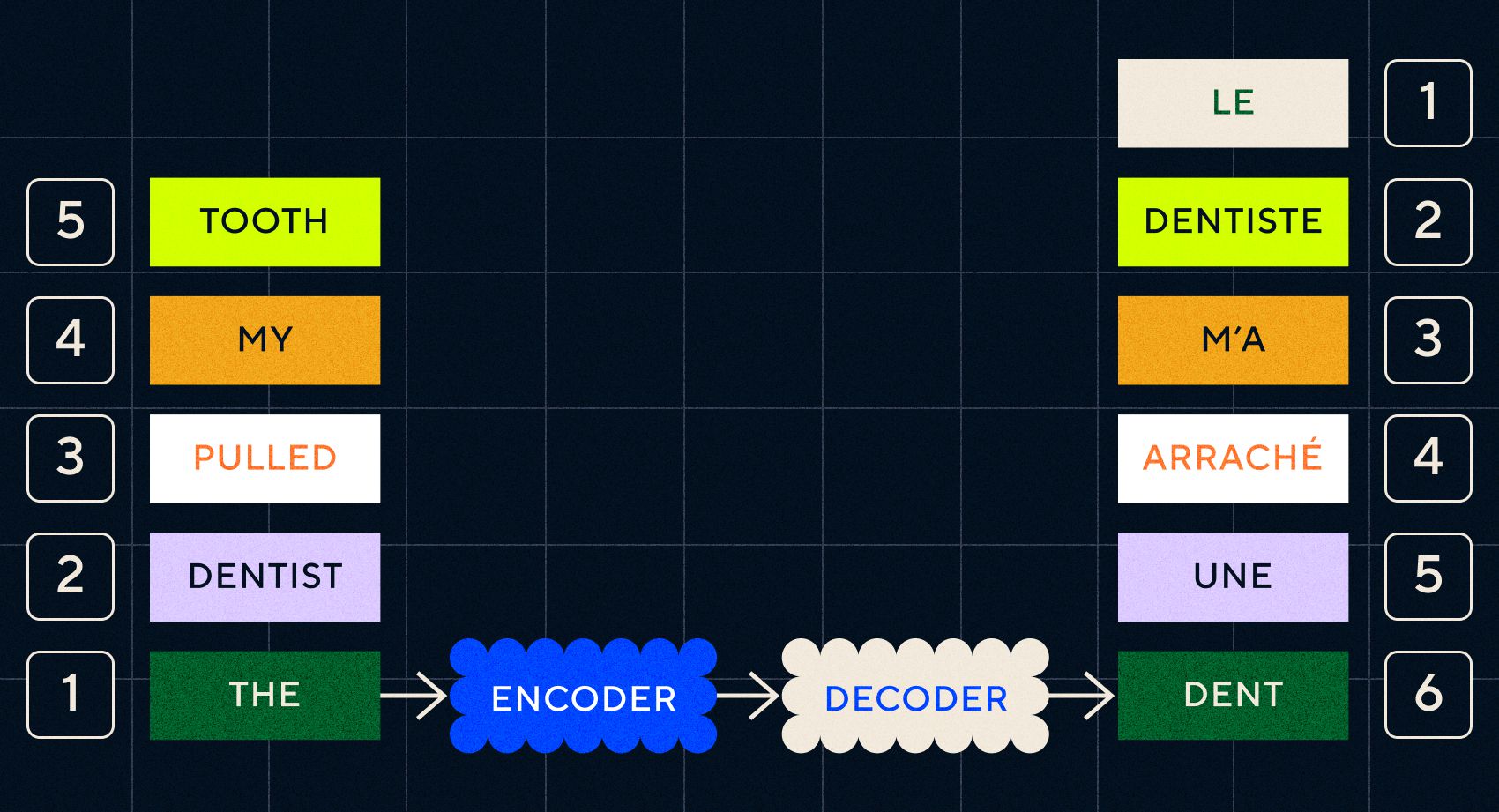
Setelah pembuat enkode memproses masukan di setiap langkah, ia kemudian mulai meneruskan keluaran ke dekoder yang mengubah penyematan menjadi teks terjemahan.
Kita dapat melihat evolusi model-model ini yang mulai menyerupai, dalam beberapa bentuk sederhana, apa yang kita lihat saat ini dengan ChatGPT. Namun, kita juga dapat melihat betapa terbatasnya model-model ini jika dibandingkan. Seperti halnya perkembangan bahasa kita sendiri, untuk benar-benar meningkatkan kemampuan linguistik kita perlu mengetahui dengan tepat apa yang harus diperhatikan untuk membuat frasa dan kalimat yang lebih kompleks.
Model 3 – Belajar dengan perhatian dan penskalaan dengan Transformers
Kami telah mencatat sebelumnya bahwa tahap telegraf adalah saat anak-anak mulai membuat kalimat pendek dengan dua kata atau lebih. Salah satu aspek kunci dari tahap pemerolehan bahasa ini adalah anak-anak mulai belajar bagaimana menyusun kalimat yang tepat.
Model RNN dan Seq2Seq membantu model bahasa memproses beberapa rangkaian kata, tetapi panjang kalimat yang dapat diproses masih terbatas. Seiring bertambahnya panjang kalimat, kita perlu memperhatikan sebagian besar hal dalam kalimat.
Misalnya, ambil kalimat berikut “Ada begitu banyak ketegangan di ruangan itu sehingga Anda bisa memotongnya dengan pisau”. Ada banyak hal yang terjadi di sana. Untuk mengetahui bahwa kita tidak benar-benar memotong sesuatu dengan pisau di sini kita perlu menghubungkan “memotong” dengan “ketegangan” di awal kalimat.
Seiring bertambahnya panjang kalimat, semakin sulit untuk mengetahui kata mana yang mengacu pada kata tertentu untuk menyimpulkan makna yang tepat. Di sinilah RNN mulai menemui keterbatasan dan kami membutuhkan model baru untuk melanjutkan ke tahap pemerolehan bahasa berikutnya.
“Pikirkan untuk mencoba meringkas percakapan yang semakin panjang dengan batasan kata yang tetap. Di setiap langkah Anda mulai kehilangan lebih banyak informasi”
Pada tahun 2017, sekelompok peneliti di Google menerbitkan makalah yang mengusulkan teknik yang memungkinkan model lebih memperhatikan konteks penting dalam sebuah teks.
Apa yang mereka kembangkan adalah cara model bahasa agar lebih mudah mencari konteks yang mereka perlukan saat memproses rangkaian masukan teks. Mereka menyebut pendekatan ini “arsitektur transformator”, dan ini mewakili lompatan maju terbesar dalam pemrosesan bahasa alami hingga saat ini.
Mekanisme pencarian ini memudahkan model untuk mengidentifikasi kata mana yang lebih banyak memberikan konteks pada kata yang sedang diproses. RNN mencoba memberikan konteks dengan meneruskan keadaan agregat dari semua kata yang telah diproses di setiap langkah. Pikirkan untuk mencoba meringkas percakapan yang semakin lama semakin panjang dengan batasan kata yang tetap. Di setiap langkah Anda mulai kehilangan lebih banyak informasi. Sebaliknya, transformator memberi bobot pada kata-kata (atau token, yang bukan keseluruhan kata melainkan bagian dari kata) berdasarkan kepentingannya terhadap kata saat ini dalam kaitannya dengan konteksnya. Hal ini mempermudah pemrosesan rangkaian kata yang semakin panjang tanpa hambatan yang terlihat di RNN. Mekanisme perhatian baru ini juga memungkinkan teks diproses secara paralel, bukan berurutan seperti RNN.
Jadi bayangkan sebuah kalimat seperti “Hewan itu tidak menyeberang jalan karena terlalu lelah”. Untuk RNN, ia harus mewakili semua kata sebelumnya di setiap langkah. Ketika jumlah kata antara “itu” dan “hewan” meningkat, RNN menjadi lebih sulit untuk mengidentifikasi konteks yang tepat.

Dengan arsitektur transformator, model kini memiliki kemampuan untuk mencari kata yang paling mungkin merujuk pada “itu”. Diagram di bawah menunjukkan bagaimana model transformator dapat fokus pada bagian “hewan” dari teks saat mereka mencoba memproses sebuah kalimat.
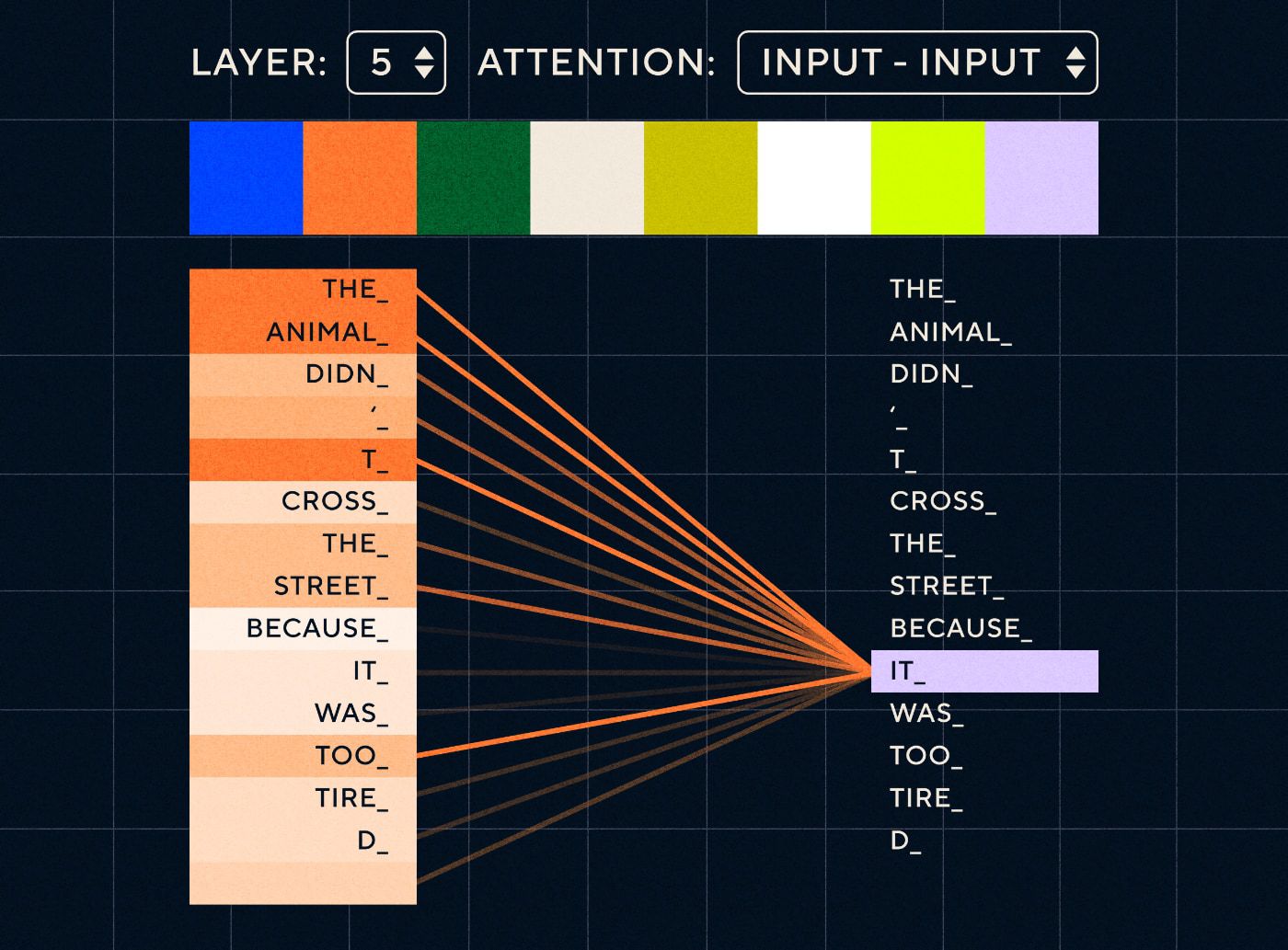
Sumber: Transformator Bergambar
Diagram di atas menunjukkan perhatian pada lapisan 5 jaringan. Pada setiap lapisan, model membangun pemahamannya terhadap kalimat dan “memperhatikan” bagian tertentu dari masukan yang dianggap lebih relevan dengan langkah yang sedang diproses pada saat itu, yaitu model memberikan perhatian lebih pada “the animal” untuk “itu” di lapisan ini. Sumber: Transformer bergambar
Anggap saja seperti database yang dapat mengambil kata dengan skor tertinggi yang kemungkinan besar terkait dengan “itu”.
Dengan perkembangan ini, model bahasa tidak terbatas pada penguraian rangkaian tekstual pendek. Sebagai gantinya, Anda dapat menggunakan urutan teks yang lebih panjang sebagai masukan. Kita tahu bahwa memperkenalkan lebih banyak kata kepada anak-anak melalui “percakapan yang menarik” membantu meningkatkan perkembangan bahasa mereka.
Demikian pula, dengan mekanisme perhatian baru, model bahasa mampu mengurai jenis data pelatihan tekstual yang lebih banyak dan bervariasi. Ini termasuk artikel Wikipedia, forum online, Twitter, dan data teks lainnya yang dapat Anda urai. Seperti halnya perkembangan masa kanak-kanak, paparan terhadap semua kata-kata ini dan penggunaannya dalam konteks yang berbeda membantu model bahasa mengembangkan kemampuan linguistik yang baru dan lebih rumit.
Pada fase inilah kami mulai melihat perlombaan penskalaan di mana orang-orang memasukkan lebih banyak data ke model ini untuk melihat apa yang dapat mereka pelajari. Data ini tidak perlu diberi label oleh manusia – peneliti cukup mengambil data dari internet dan memasukkannya ke model dan melihat apa yang dipelajarinya.
“Model seperti BERT memecahkan setiap rekor pemrosesan bahasa alami yang ada. Faktanya, kumpulan data pengujian yang digunakan untuk tugas-tugas ini terlalu sederhana untuk model transformator ini”
Model BERT (BiDirectional Encoder Representations from Transformers) patut mendapat perhatian khusus karena beberapa alasan. Ini adalah salah satu model pertama yang memanfaatkan fitur perhatian yang merupakan inti arsitektur Transformer. Pertama, BERT bersifat dua arah karena dapat melihat teks di kiri dan kanan input saat ini. Berbeda dengan RNN yang hanya bisa memproses teks secara berurutan dari kiri ke kanan. Kedua, BERT juga menggunakan teknik pelatihan baru yang disebut “masking” yang memaksa model untuk mempelajari arti dari input yang berbeda dengan “menyembunyikan” atau “menutupi” token acak untuk memastikan model tidak dapat “mencurangi” dan fokus pada satu token di setiap iterasi. Dan terakhir, BERT dapat disesuaikan untuk melakukan tugas NLP yang berbeda. Ia tidak harus dilatih dari awal untuk tugas-tugas ini.
Hasilnya luar biasa. Model seperti BERT memecahkan setiap rekor pemrosesan bahasa alami yang tersedia. Faktanya, kumpulan data pengujian yang digunakan untuk tugas-tugas ini terlalu sederhana untuk model transformator ini.
Sekarang kami memiliki kemampuan untuk melatih model bahasa besar yang berfungsi sebagai model dasar untuk tugas pemrosesan bahasa alami yang baru. Sebelumnya kebanyakan orang melatih modelnya dari awal. Namun sekarang model terlatih seperti BERT dan model GPT awal sudah sangat bagus sehingga tidak ada gunanya melakukannya sendiri. Faktanya, model-model ini sangat baik sehingga orang dapat melakukan tugas-tugas baru dengan contoh yang relatif sedikit – mereka digambarkan sebagai “pembelajar beberapa kali”, serupa dengan bagaimana kebanyakan orang tidak memerlukan terlalu banyak contoh untuk memahami konsep-konsep baru.
Hal ini merupakan titik perubahan besar dalam pengembangan model dan kemampuan linguistiknya. Sekarang kami hanya perlu menjadi lebih baik dalam instruksi kerajinan.
Model 4 – Instruksi pembelajaran dengan InstructGPT
Salah satu hal yang dipelajari anak pada tahap akhir pemerolehan bahasa, tahap multikata, adalah kemampuan menggunakan kata-kata fungsi untuk menghubungkan unsur-unsur pembawa informasi dalam sebuah kalimat. Kata-kata fungsi memberi tahu kita tentang hubungan antara kata-kata yang berbeda dalam sebuah kalimat. Jika kita ingin membuat instruksi, maka model bahasa harus mampu membuat kalimat dengan kata isi dan kata fungsi yang menangkap hubungan kompleks. Misalnya, instruksi berikut memiliki kata-kata fungsi yang dicetak tebal:
- “ Aku ingin kamu menulis surat…”
- “ Ceritakan pendapatmu tentang teks di atas ”
Namun sebelum kami dapat mencoba dan melatih model bahasa untuk mengikuti instruksi, kami perlu memahami dengan tepat apa yang sudah mereka ketahui tentang instruksi.
GPT-3 OpenAI dirilis pada tahun 2020. Ini adalah sekilas tentang kemampuan model-model ini, tetapi kami masih perlu memahami cara membuka kemampuan dasar model-model ini. Bagaimana kita dapat berinteraksi dengan model-model ini agar mereka dapat melakukan tugas yang berbeda?
Misalnya, GPT-3 menunjukkan bahwa peningkatan ukuran model dan data pelatihan memungkinkan apa yang penulis sebut sebagai “meta-learning” – yaitu saat model bahasa mengembangkan serangkaian kemampuan linguistik, yang banyak di antaranya tidak terduga, dan dapat menggunakan kemampuan tersebut. keterampilan untuk memahami tugas yang diberikan.
“Apakah model dapat memahami maksud dari instruksi dan melaksanakan tugas, bukan sekadar memprediksi kata berikutnya?”
Ingat, GPT-3 dan model bahasa sebelumnya tidak dirancang untuk mengembangkan keterampilan ini – model tersebut sebagian besar dilatih untuk sekadar memprediksi kata berikutnya dalam rangkaian teks. Namun, melalui kemajuan RNN, Seq2Seq, dan jaringan perhatian, model ini mampu memproses lebih banyak teks, dalam urutan yang lebih panjang, dan lebih fokus pada konteks yang relevan.
Anda dapat menganggap GPT-3 sebagai ujian untuk melihat sejauh mana kami dapat mengambil tindakan ini. Seberapa besar kita dapat membuat model dan berapa banyak teks yang dapat kita masukkan ke dalamnya? Kemudian setelah melakukan itu, alih-alih hanya memberi model beberapa teks masukan agar model dapat diselesaikan, kita dapat menggunakan teks masukan tersebut sebagai instruksi. Akankah model dapat memahami maksud instruksi dan melaksanakan tugas, bukan sekadar memprediksi kata berikutnya? Di satu sisi, hal ini seperti mencoba memahami tahap penguasaan bahasa yang telah dicapai oleh model-model ini.
Kami sekarang menggambarkan hal ini sebagai “prompting”, tetapi pada tahun 2020, ketika makalah ini diterbitkan, ini adalah konsep yang sangat baru.
Halusinasi dan keselarasan
Masalah dengan GPT-3, seperti yang kita ketahui sekarang, adalah bahwa GPT-3 kurang baik dalam mengikuti instruksi dalam teks masukan. GPT-3 dapat mengikuti instruksi tetapi mudah kehilangan perhatian, hanya dapat memahami instruksi sederhana dan cenderung mengada-ada. Dengan kata lain, model tersebut tidak “selaras” dengan niat kita. Jadi masalahnya sekarang bukan pada peningkatan kemampuan bahasa model, melainkan kemampuan mereka untuk mengikuti instruksi.
Perlu dicatat bahwa GPT-3 tidak pernah benar-benar dilatih berdasarkan instruksi. Tidak dijelaskan apa itu instruksi, atau apa bedanya dengan teks lain, atau bagaimana seharusnya mengikuti instruksi. Di satu sisi, ia “ditipu” untuk mengikuti instruksi dengan membuatnya “menyelesaikan” perintah seperti rangkaian teks lainnya. Oleh karena itu, OpenAI perlu melatih model yang mampu mengikuti instruksi seperti manusia dengan lebih baik. Dan mereka melakukannya dalam makalah yang berjudul Pelatihan model bahasa untuk mengikuti instruksi dengan umpan balik manusia yang diterbitkan pada awal tahun 2022. InstructGPT akan terbukti menjadi pendahulu ChatGPT pada akhir tahun yang sama.
Langkah-langkah yang diuraikan dalam makalah tersebut juga digunakan untuk melatih ChatGPT. Pelatihan instruksi mengikuti 3 langkah utama:
- Langkah 1 – Menyempurnakan GPT-3: Karena GPT-3 tampaknya berfungsi dengan baik dalam pembelajaran beberapa tahap, maka akan lebih baik jika GPT-3 disesuaikan dengan contoh instruksi berkualitas tinggi. Tujuannya adalah untuk mempermudah menyelaraskan maksud dalam instruksi dengan respon yang dihasilkan. Untuk melakukan hal ini, OpenAI meminta pemberi label manusia untuk membuat respons terhadap beberapa perintah yang dikirimkan oleh orang-orang yang menggunakan GPT-3. Dengan menggunakan instruksi nyata, penulis berharap dapat menangkap “distribusi” tugas yang realistis yang coba dilakukan oleh pengguna di GPT-3. Ini digunakan untuk menyempurnakan GPT-3 guna membantunya meningkatkan kemampuan respons cepatnya.
- Langkah 2 – Minta manusia memberi peringkat pada GPT-3 yang baru dan lebih baik: Untuk menilai instruksi baru yang telah menyempurnakan GPT-3, pelabel kini menilai kinerja model pada perintah yang berbeda tanpa respons yang telah ditentukan sebelumnya. Pemeringkatan tersebut terkait dengan faktor penyelarasan yang penting seperti bermanfaat, jujur, dan tidak beracun, bias, atau merugikan. Jadi, berikan tugas pada model tersebut dan nilai performanya berdasarkan metrik ini. Keluaran dari latihan pemeringkatan ini kemudian digunakan untuk melatih model terpisah guna memprediksi keluaran mana yang mungkin lebih disukai oleh pemberi label. Model ini dikenal sebagai model penghargaan (RM).
- Langkah 3 – Gunakan RM untuk melatih lebih banyak contoh: Terakhir, RM digunakan untuk melatih model instruksi baru agar dapat menghasilkan respons yang selaras dengan preferensi manusia dengan lebih baik.
Sulit untuk memahami sepenuhnya apa yang terjadi di sini dengan Reinforcement Learning From Human Feedback (RLHF), model penghargaan, pembaruan kebijakan, dan sebagainya.
Salah satu cara sederhana untuk memikirkannya adalah bahwa ini hanyalah cara untuk memungkinkan manusia menghasilkan contoh yang lebih baik tentang cara mengikuti instruksi. Misalnya, pikirkan bagaimana Anda mencoba mengajari seorang anak mengucapkan terima kasih:
- Orang Tua : “Ketika seseorang memberimu X, kamu mengucapkan terima kasih”. Ini adalah langkah 1, contoh kumpulan data perintah dan respons yang sesuai
- Orang Tua : “Sekarang, apa yang kamu katakan pada Y di sini?”. Ini adalah langkah 2 di mana kita meminta anak untuk membuat respons dan kemudian orang tua akan menilainya. "Ya itu bagus."
- Terakhir, pada pertemuan berikutnya, orang tua akan memberi penghargaan kepada anak berdasarkan contoh baik atau buruk dari respons dalam skenario serupa di masa depan. Ini adalah langkah 3, dimana perilaku penguatan terjadi.
OpenAI mengklaim bahwa yang dilakukannya hanyalah membuka kemampuan yang sudah ada dalam model seperti GPT-3, “tetapi sulit diperoleh hanya melalui rekayasa cepat,” seperti yang dinyatakan dalam makalah tersebut.
Dengan kata lain, ChatGPT tidak benar-benar mempelajari kemampuan “ baru ”, namun sekadar mempelajari “ antarmuka ” linguistik yang lebih baik untuk memanfaatkannya.
Keajaiban bahasa
ChatGPT terasa seperti lompatan maju yang ajaib, namun sebenarnya ini adalah hasil kemajuan teknologi yang melelahkan selama beberapa dekade.
Dengan melihat beberapa perkembangan besar di bidang AI dan NLP dalam dekade terakhir, kita dapat melihat bagaimana ChatGPT “berdiri di atas bahu para raksasa”. Model sebelumnya pertama kali belajar mengidentifikasi arti kata. Kemudian model selanjutnya menggabungkan kata-kata ini dan kami dapat melatihnya untuk melakukan tugas seperti penerjemahan. Begitu mereka dapat memproses kalimat, kami mengembangkan teknik yang memungkinkan model bahasa ini memproses lebih banyak teks dan mengembangkan kemampuan untuk menerapkan pembelajaran ini pada tugas-tugas baru dan tak terduga. Lalu, dengan ChatGPT kami akhirnya mengembangkan kemampuan untuk berinteraksi lebih baik dengan model ini dengan menentukan instruksi kami dalam format bahasa alami.
“Karena bahasa adalah sarana pemikiran kita, akankah mengajarkan komputer tentang kekuatan penuh bahasa akan menghasilkan kecerdasan buatan yang mandiri?”
Namun, evolusi NLP mengungkap keajaiban yang lebih dalam yang biasanya kita buta – keajaiban bahasa itu sendiri dan cara kita, sebagai manusia, memperolehnya.
Masih banyak pertanyaan terbuka dan kontroversi tentang bagaimana anak-anak belajar bahasa. Ada juga pertanyaan tentang apakah ada struktur dasar yang sama untuk semua bahasa. Apakah manusia berevolusi untuk menggunakan bahasa atau sebaliknya?
Hal yang aneh adalah, seiring ChatGPT dan turunannya meningkatkan perkembangan linguistiknya, model ini dapat membantu menjawab beberapa pertanyaan penting ini.
Terakhir, karena bahasa adalah sarana pemikiran kita, akankah mengajarkan komputer tentang kekuatan penuh bahasa akan menghasilkan kecerdasan buatan yang mandiri? Seperti biasa dalam hidup, masih banyak yang harus dipelajari.
