
Meretas Grafik Topik dengan Wikipedia dan Google Language API
Diterbitkan: 2019-08-27Salah satu dek slide favorit saya dari sepuluh tahun terakhir dibuat oleh Mark Johnstone pada tahun 2014, saat dia masih bersama Distilled. Dek itu disebut Bagaimana Menghasilkan Ide Konten yang Lebih Baik dan saya menggunakannya sebagai Alkitab saya selama beberapa tahun sambil membangun tim untuk melakukan kerja keras promosi konten.
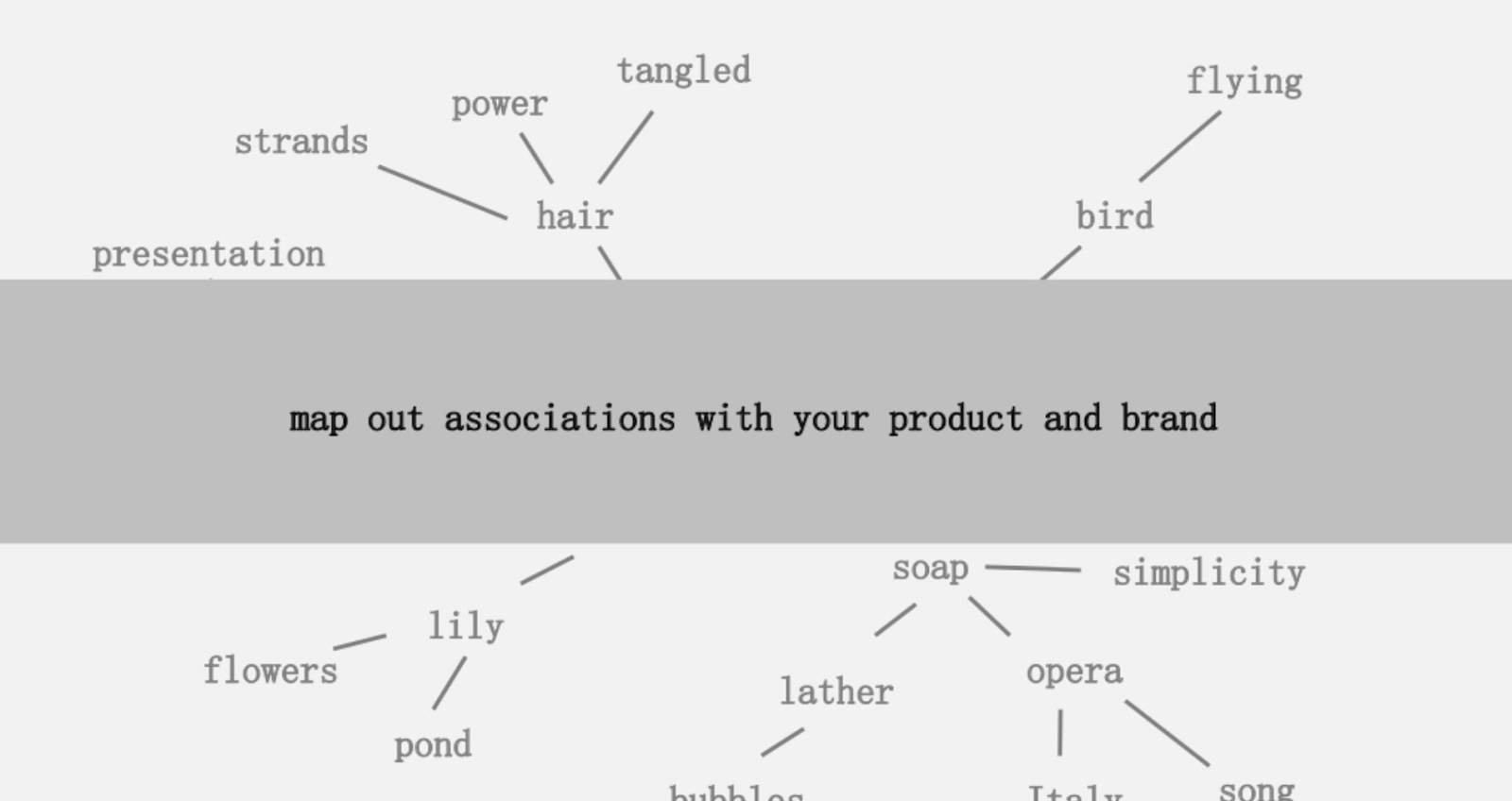
Salah satu ide yang ditawarkan adalah membuat pemetaan visual keterhubungan kata-kata yang terkait dengan produk atau merek Anda sehingga Anda dapat berdiri kembali, dan mencari cara untuk menggabungkan asosiasi tersebut menjadi sesuatu yang menarik. Tujuannya adalah produksi ide, yang ia definisikan sebagai " kombinasi baru dari elemen-elemen yang sebelumnya tidak terhubung dengan cara yang menambah nilai."
Dalam artikel ini, kami mengambil pendekatan otak kiri yang jauh lebih banyak, dengan menggunakan Python, API Bahasa Google, bersama dengan Wikipedia, untuk menjelajahi asosiasi entitas yang ada dari topik awal. Tujuannya adalah tampilan tingkat tinggi dari hubungan entitas di sepanjang grafik topik. Artikel ini bukan untuk pembaca rata-rata. Pembaca yang akrab dengan Python dan memiliki setidaknya tingkat dasar kemampuan pengkodean akan merasa jauh lebih instruktif.
Ide
Menindaklanjuti ide pemetaan Mark Johnstone, saya pikir akan menarik untuk membiarkan Google dan Wikipedia mendefinisikan struktur topik mulai dari topik benih atau halaman web. Tujuannya adalah untuk membangun pemetaan hubungan ke topik utama secara visual, dalam grafik seperti pohon yang dapat ditinjau untuk mencari koneksi dan mungkin menghasilkan ide konten. Gambar berikut mewakili ide desain awal.
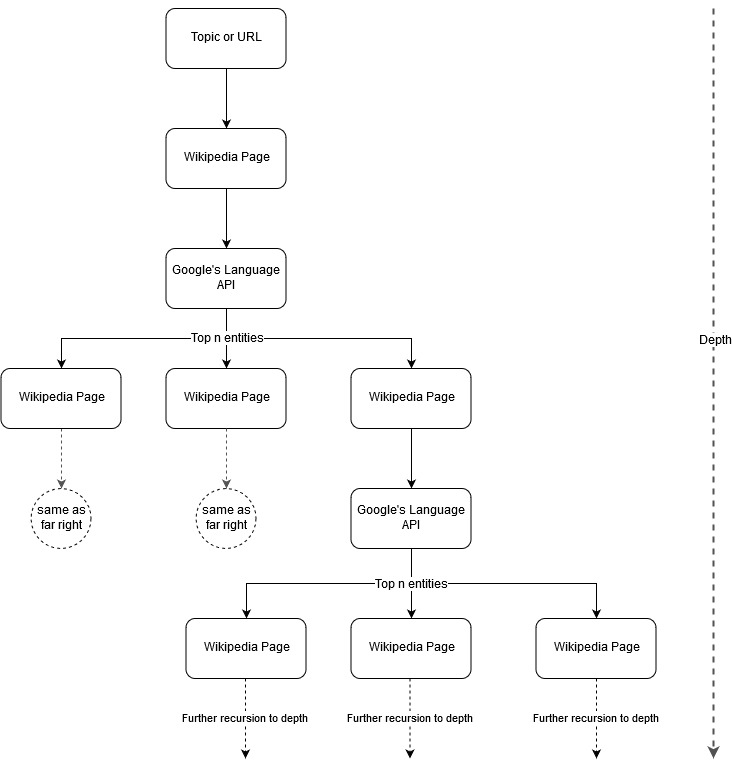
Pada dasarnya, kami memberikan alat ini sebuah topik atau URL, dan membiarkan Google's Language API memilih n (3 dalam contoh kami) entitas teratas (yang mencakup URL Wikipedia) untuk setiap halaman entitas dan kami secara rekursif terus membangun grafik jaringan untuk setiap entitas yang ditemukan sampai kedalaman maksimum.
Latar Belakang Alat yang Digunakan
API Bahasa Google
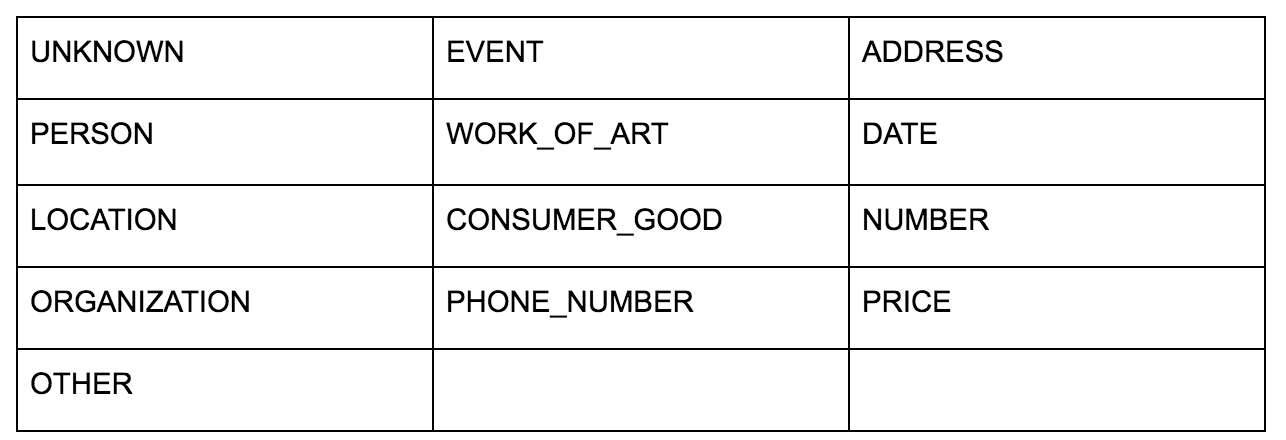
API Bahasa Google memungkinkan Anda untuk meneruskannya baik teks biasa atau HTML dan secara ajaib mengembalikan semua berbagai entitas yang terkait dengan konten. API melakukan lebih dari ini, tetapi untuk analisis ini, kami hanya akan fokus pada bagian ini. Berikut adalah daftar jenis entitas yang dikembalikannya:
Identifikasi entitas telah menjadi bagian mendasar dari Natural Language Processing (NLP) untuk waktu yang lama dan terminologi yang tepat untuk tugas tersebut adalah Named Entity Recognition (NER). NER adalah tugas yang sulit karena banyak kata memiliki arti yang berbeda berdasarkan konteks yang digunakan sehingga alat NLP atau API harus memahami konteks penuh seputar istilah untuk dapat mengidentifikasinya dengan benar sebagai entitas tertentu.
Saya memberikan gambaran yang cukup rinci tentang API ini, dan entitas khususnya, dalam sebuah artikel di opensource.com jika Anda ingin mengetahui beberapa konteks sebelum menyelesaikan artikel ini.
Salah satu fitur menarik dari Google's Language API adalah, selain menemukan entitas yang relevan, juga menandai seberapa terkaitnya mereka dengan keseluruhan dokumen (arti-penting), dan, untuk beberapa, menyediakan artikel Wikipedia (grafik pengetahuan) terkait yang mewakili entitas.
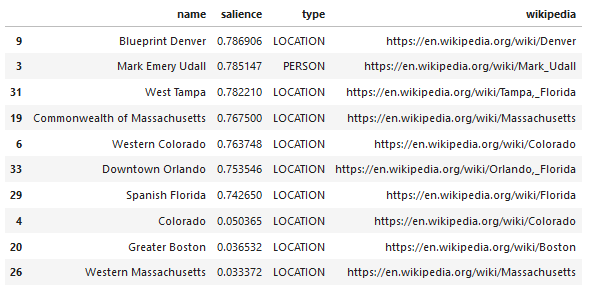
Berikut adalah contoh keluaran dari apa yang dikembalikan oleh API (diurutkan berdasarkan arti-penting):
Pengembang Perayapan
 Belajarlah lagi
Belajarlah lagiPython
Python adalah bahasa perangkat lunak yang telah menjadi populer di bidang ilmu data karena kumpulan perpustakaan yang besar dan terus bertambah yang memudahkan untuk mencerna, membersihkan, memanipulasi, dan menganalisis kumpulan data besar. Ini juga mendapat manfaat dari lingkungan kolaboratif yang disebut notebook Jupyter yang memungkinkan pengguna untuk dengan mudah menguji dan membubuhi keterangan kode mereka dengan cara yang mudah.
Untuk ulasan ini, kami akan menggunakan beberapa pustaka utama yang memungkinkan kami melakukan beberapa hal menarik dengan data NLP Google.
- Pandas: Pikirkan kemampuan untuk membuat skrip Microsoft Excel untuk membaca, menyimpan, mengurai, atau mengatur ulang spreadsheet dan Anda mendapatkan gambaran tentang apa yang dilakukan Pandas. Panda luar biasa. (tautan)
- Networkx: Networkx adalah alat untuk membuat grafik node dan edge yang menentukan hubungan antar node. Ini juga memiliki dukungan bawaan untuk memplot grafik sehingga mudah divisualisasikan. (tautan)
- Pywikibot: Pywikibot adalah perpustakaan yang memungkinkan Anda berinteraksi dengan Wikipedia untuk mencari, mengedit, menemukan hubungan, dll., dengan semua konten untuk setiap situs Wikipedia. (tautan)
Proses
Kami membagikan buku catatan Google Colab di sini yang dapat digunakan untuk mengikuti. (Terima kasih khusus kepada Tyler Reardon untuk pemeriksaan kewarasan pada artikel dan buku catatan ini.)
Pengaturan
Beberapa sel pertama di buku catatan berurusan dengan menginstal beberapa perpustakaan, membuat perpustakaan tersebut tersedia untuk Python, dan menyediakan kredensial dan file konfigurasi untuk Google's Language API dan Pywikibot, masing-masing. Berikut adalah semua perpustakaan yang perlu kita instal untuk memastikan alat dapat berjalan:
- panda
- permintaan
- httplib2
- google-cloud-bahasa
- pywikibot
- jaringanx
- validator
- Bs4
Catatan: Bagian tersulit untuk dapat menjalankan notebook ini adalah mendapatkan kredensial dari Google untuk mengakses API mereka. Bagi mereka yang tidak berpengalaman dengan ini, ini akan memakan waktu sekitar satu jam untuk mencari tahu. Kami menautkan Instruksi untuk mendapatkan kredensial Akun Layanan di bagian atas buku catatan untuk membantu Anda. Di bawah ini adalah contoh bagaimana kami memasukkan milik kami.
Fungsi untuk Menang
Di sel yang ditunjukkan oleh "Tentukan beberapa fungsi untuk Google NLP," kami mengembangkan delapan fungsi yang menangani hal-hal seperti menanyakan API Bahasa, berinteraksi dengan Wikipedia, mengekstraksi teks halaman web, dan membuat serta membuat grafik. Fungsi pada dasarnya adalah unit kode kecil yang mengambil beberapa data pengaturan, melakukan beberapa pekerjaan, dan menghasilkan sesuatu. Semua fungsi dikomentari untuk memberi tahu variabel yang mereka ambil, dan apa yang mereka hasilkan.

Menguji API
Dua sel berikut mengambil URL, mengekstrak teks dari URL, dan menarik entitas dari Google's Language API. Satu hanya menarik entitas yang memiliki URL Wikipedia dan yang lainnya menarik semua entitas dari halaman itu.
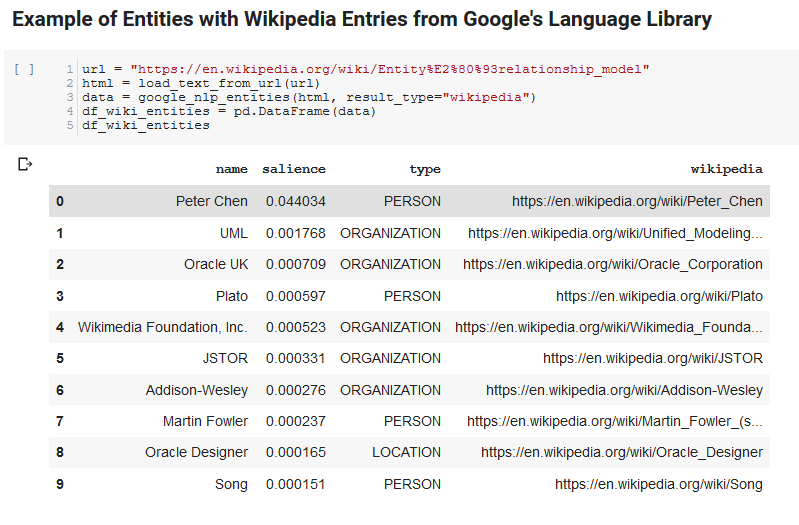
Ini adalah langkah pertama yang penting hanya untuk mendapatkan bagian ekstraksi konten yang benar dan memahami cara kerja API Bahasa dan mengembalikan data.
Jaringanx
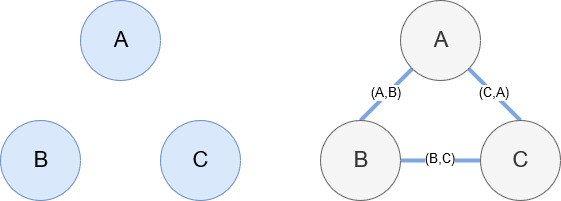
Networkx, seperti yang disebutkan sebelumnya, adalah perpustakaan luar biasa yang cukup intuitif untuk dimainkan. Pada dasarnya, Anda harus memberi tahu apa node Anda dan bagaimana node terhubung. Misalnya, pada gambar di bawah ini, kami memberikan Networkx tiga node (A,B,C). Kami kemudian memberitahu Networkx bahwa mereka terhubung oleh tepi (A,B), (B,C), (C,A) mendefinisikan hubungan antara node. Untuk penggunaan kami, entitas dengan URL Wikipedia akan menjadi simpul dan tepinya ditentukan oleh entitas baru yang ditemukan di halaman entitas saat ini. Jadi, jika kita meninjau halaman Wikipedia untuk Entitas A, dan di halaman itu, Entitas B ditemukan, maka itu adalah keunggulan antara Entitas A dan Entitas B.
Menyatukan semuanya
Bagian berikutnya dari buku catatan ini disebut Percabangan Topik Wikipedia berdasarkan URL. Ini adalah dimana keajaiban terjadi. Kami telah mendefinisikan fungsi khusus (recurse_entities) sebelumnya yang berulang melalui halaman di Wikipedia mengikuti entitas baru yang ditentukan oleh API bahasa Google. Kami juga menambahkan fungsi yang sangat canggung untuk dipahami (hierarchy_pos) yang kami angkat dari Stack Overflow yang berfungsi dengan baik dalam menyajikan grafik seperti pohon dengan banyak node. Di sel di bawah ini, kami mendefinisikan input sebagai "Optimasi Mesin Pencari" dan menentukan kedalaman 3 (ini adalah berapa banyak halaman yang diikuti secara rekursif), dan batas 3 (ini adalah berapa banyak entitas yang ditarik per halaman).
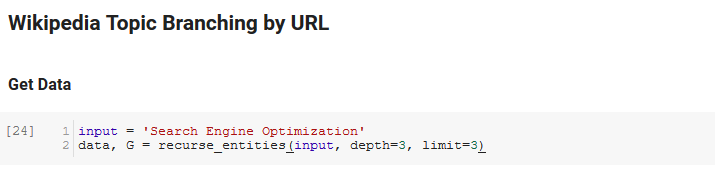
Menjalankannya untuk istilah "Optimasi Mesin Pencari" kita dapat melihat jalur berikut yang diambil alat tersebut, mulai dari halaman Pengoptimalan Mesin Pencari Wikipedia (Level 0) dan mengikuti, secara rekursif, halaman hingga kedalaman maksimal yang ditentukan (3).

Kami kemudian mengambil semua entitas yang ditemukan dan menambahkannya ke Pandas DataFrame, yang membuatnya sangat mudah untuk disimpan sebagai CSV. Kami mengurutkan data ini berdasarkan arti-penting (yang merupakan seberapa penting entitas tersebut ke halaman tempat ia ditemukan), tetapi skor ini agak menyesatkan dalam konteks ini karena tidak memberi tahu Anda seberapa terkait entitas tersebut dengan istilah asli Anda (“ Optimisasi Mesin Pencari"). Kami akan menyerahkan pekerjaan lebih lanjut itu kepada pembaca.

Terakhir, kami memplot grafik yang dibuat oleh alat untuk menunjukkan keterhubungan semua entitas. Dalam sel di bawah ini, parameter yang dapat Anda berikan ke fungsi adalah: ( G : Grafik yang dibuat sebelumnya oleh fungsi recurse_entities, w: lebar plot, h: tinggi plot, c: persen lingkaran dari plot, dan nama file: file PNG yang disimpan ke folder gambar.)

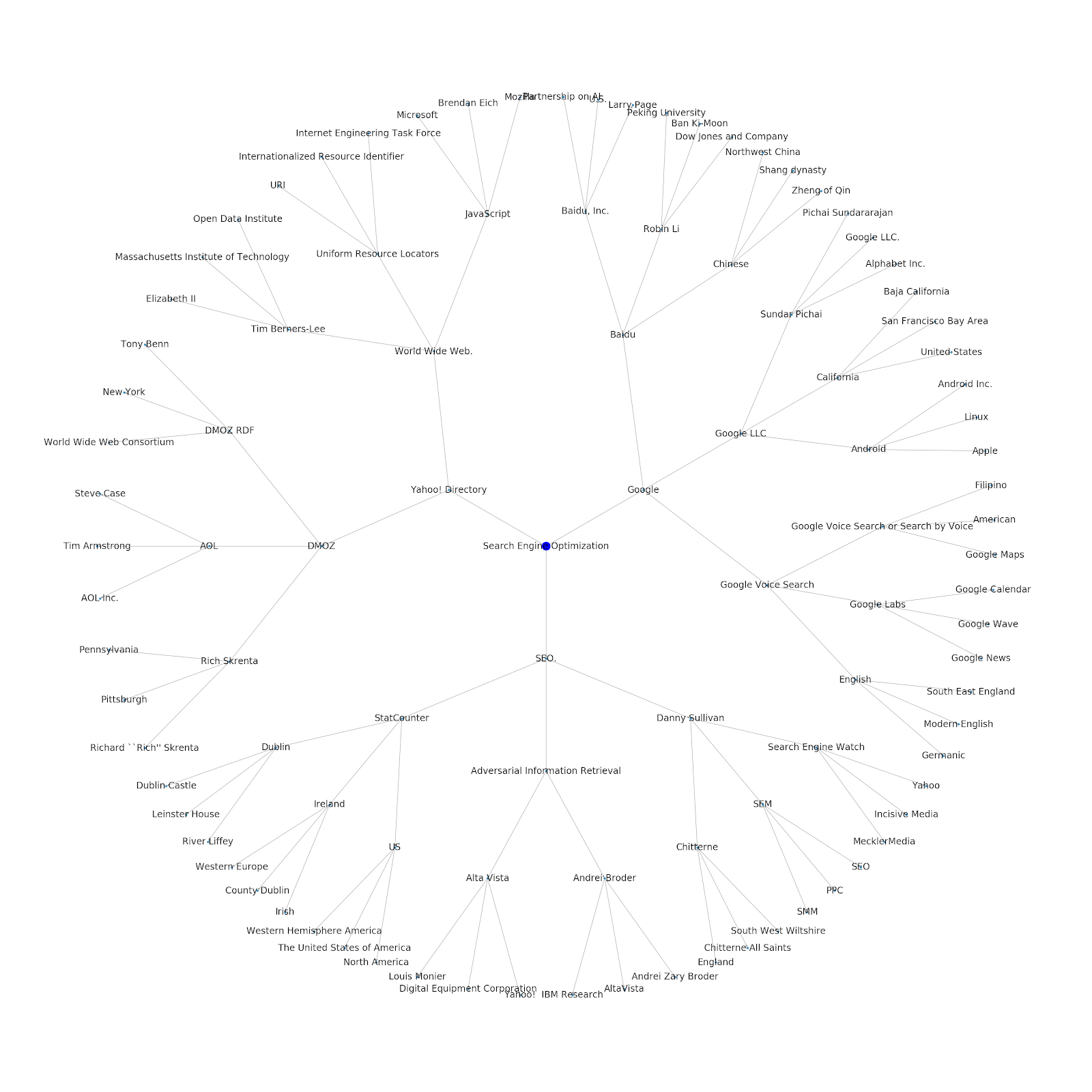
Kami menambahkan kemampuan untuk memberikan topik benih atau URL benih. Dalam hal ini, kami melihat entitas yang terkait dengan artikel Masalah Pengindeksan Google Berlanjut Tapi Yang Ini Berbeda
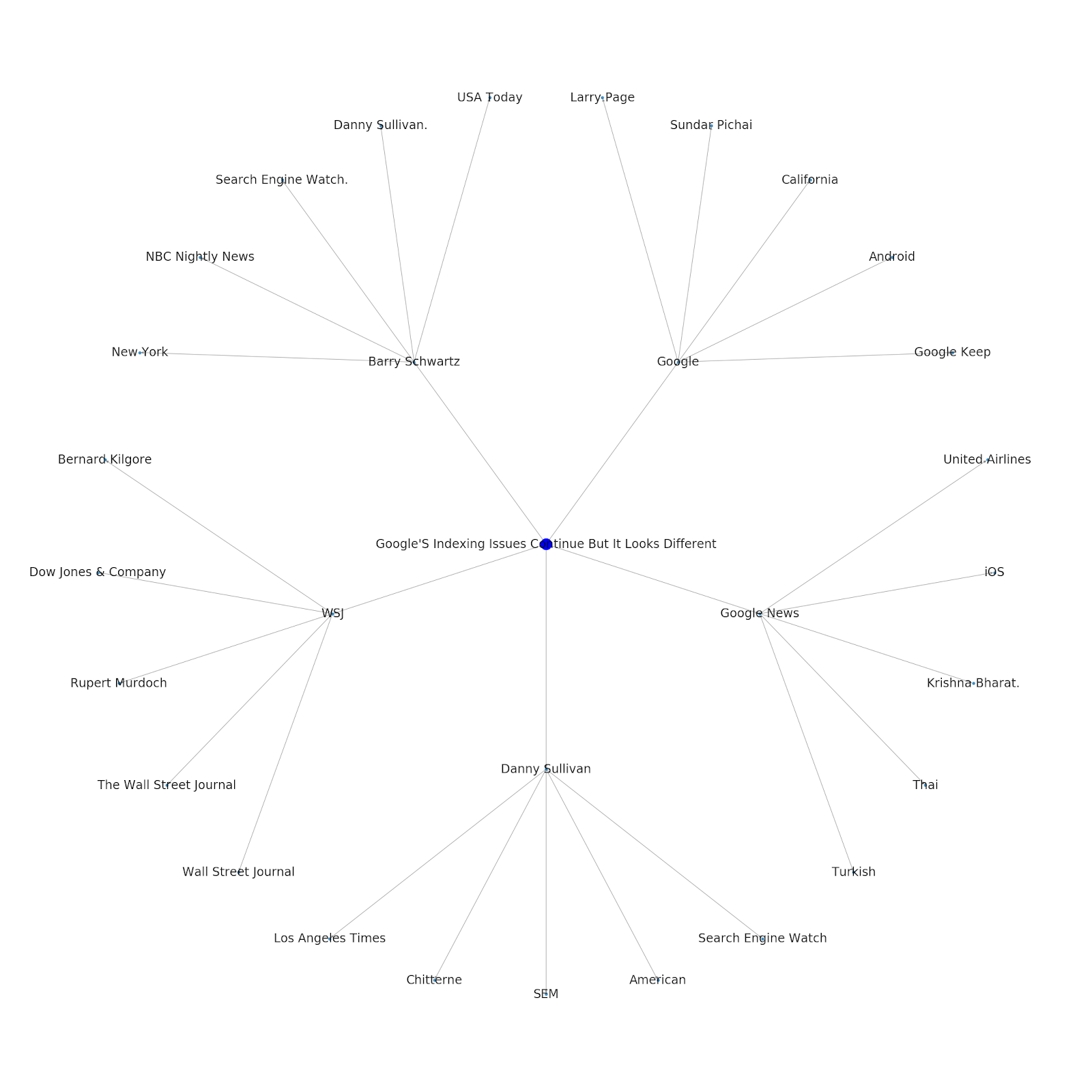
Berikut adalah grafik entitas Google/Wikipedia untuk Python.
Apa Artinya?
Memahami lapisan topik internet menarik dari sudut pandang SEO karena memaksa Anda untuk berpikir tentang bagaimana segala sesuatunya terhubung dan tidak hanya pada kueri individual. Karena Google menggunakan lapisan ini untuk mencocokkan afinitas pengguna individu dengan topik, seperti yang disebutkan dalam pengenalan kembali Google Discover mereka, ini mungkin menjadi alur kerja yang lebih penting untuk SEO yang berfokus pada data. Dalam grafik "Python" di atas, dapat disimpulkan bahwa keakraban pengguna dengan topik yang terkait dengan topik benih mungkin merupakan ukuran yang wajar dari tingkat keahlian mereka dengan topik benih.
Contoh di bawah menunjukkan dua pengguna dengan sorotan hijau yang menunjukkan minat atau ketertarikan historis mereka dengan topik terkait. Pengguna di sebelah kiri, memahami apa itu IDE, dan memahami apa arti PyPy dan CPython, akan menjadi pengguna yang jauh lebih berpengalaman dengan Python, daripada seseorang yang tahu itu bahasa, tetapi tidak banyak yang lain. Ini akan mudah diubah menjadi skor numerik untuk setiap topik, untuk setiap pengguna.

Kesimpulan
Tujuan saya hari ini adalah untuk membagikan proses standar yang saya lalui untuk menguji dan meninjau keefektifan berbagai alat atau API menggunakan Jupyter Notebooks. Menjelajahi grafik topik sangat menarik dan kami harap Anda menemukan alat yang dibagikan memberi Anda awal yang Anda butuhkan untuk mulai menjelajahi sendiri. Dengan alat ini Anda dapat membuat grafik topik yang menjelajahi banyak tingkat hubungan, hanya sebatas kuota Google Language API (yaitu 800.000 per hari). (Pembaruan: Harga didasarkan pada unit 1.000 karakter unicode yang dikirim ke API dan gratis hingga 5k unit. Karena artikel Wikipedia bisa panjang, Anda ingin memperhatikan pengeluaran Anda. Kiat topi untuk John Murch untuk menunjukkan hal ini.) Jika Anda menyempurnakan buku catatan atau menemukan kasing yang menarik, saya harap Anda memberi tahu saya. Anda dapat menemukan saya di @jroakes di Twitter.