
Kunci untuk membuat Robots.txt yang berfungsi
Diterbitkan: 2020-02-18Bot, juga dikenal sebagai Crawler atau Spider, adalah program yang "berjalan" melintasi Web secara otomatis dari situs web ke situs web menggunakan tautan sebagai jalan. Meskipun mereka selalu menghadirkan keingintahuan tertentu, file robot.txt bisa menjadi alat yang sangat efektif. Mesin pencari seperti Google dan Bing menggunakan bot untuk merayapi konten web. File robots.txt memberikan panduan untuk bot yang berbeda mengenai halaman mana yang tidak boleh dirayapi di situs Anda. Anda juga dapat menautkan ke peta situs XML Anda dari robots.txt sehingga bot memiliki peta setiap halaman yang harus dirayapi.
Mengapa robots.txt berguna?
robots.txt membatasi jumlah halaman yang perlu dirayapi dan diindeks oleh bot untuk bot mesin telusur. Jika Anda ingin menghindari Google merayapi halaman admin, Anda dapat memblokirnya di robots.txt untuk mencoba dan menjauhkan halaman dari server Google.
Selain menjaga halaman agar tidak diindeks, robots.txt sangat bagus untuk mengoptimalkan anggaran perayapan. Anggaran perayapan adalah jumlah halaman yang telah ditentukan oleh Google untuk dirayapi di situs Anda. Biasanya situs web dengan otoritas lebih dan lebih banyak halaman memiliki anggaran perayapan yang lebih besar daripada situs web dengan jumlah halaman rendah dan otoritas rendah. Karena kami tidak tahu berapa banyak anggaran perayapan yang ditetapkan untuk situs kami, kami ingin memanfaatkan waktu ini sebaik-baiknya dengan mengizinkan Googlebot membuka halaman yang paling penting daripada merayapi halaman yang tidak ingin kami indeks.
Detail yang sangat penting yang perlu Anda ketahui tentang robots.txt adalah bahwa meskipun Google tidak akan merayapi laman yang diblokir oleh robots.txt, laman tersebut masih dapat diindeks jika laman tersebut ditautkan dari situs web lain. Untuk mencegah halaman Anda diindeks dan muncul di hasil Google Penelusuran dengan benar, Anda perlu melindungi file di server dengan kata sandi, menggunakan tag meta noindex atau header respons, atau menghapus halaman seluruhnya (respons dengan 404 atau 410). Untuk informasi lebih lanjut tentang perayapan dan pengontrolan pengindeksan, Anda dapat membaca panduan robots.txt OnCrawl.
[Studi Kasus] Mengelola perayapan bot Google
 Baca studi kasus
Baca studi kasusSintaks Robots.txt yang benar
Sintaks robots.txt terkadang bisa sedikit rumit, karena perayap yang berbeda menafsirkan sintaks secara berbeda. Selain itu, beberapa perayap yang tidak bereputasi baik melihat perintah robots.txt sebagai saran dan bukan sebagai aturan pasti yang harus mereka ikuti. Jika Anda memiliki informasi rahasia di situs Anda, penting untuk menggunakan perlindungan kata sandi selain memblokir perayap menggunakan robots.txt
Di bawah ini saya telah mencantumkan beberapa hal yang perlu Anda ingat saat mengerjakan robots.txt Anda:
- File robots.txt harus berada di bawah domain dan bukan di bawah subdirektori. Crawler tidak memeriksa file robots.txt di subdirektori.
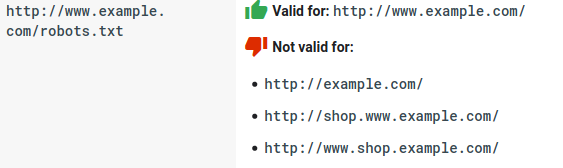
- Setiap subdomain membutuhkan file robots.txt sendiri:
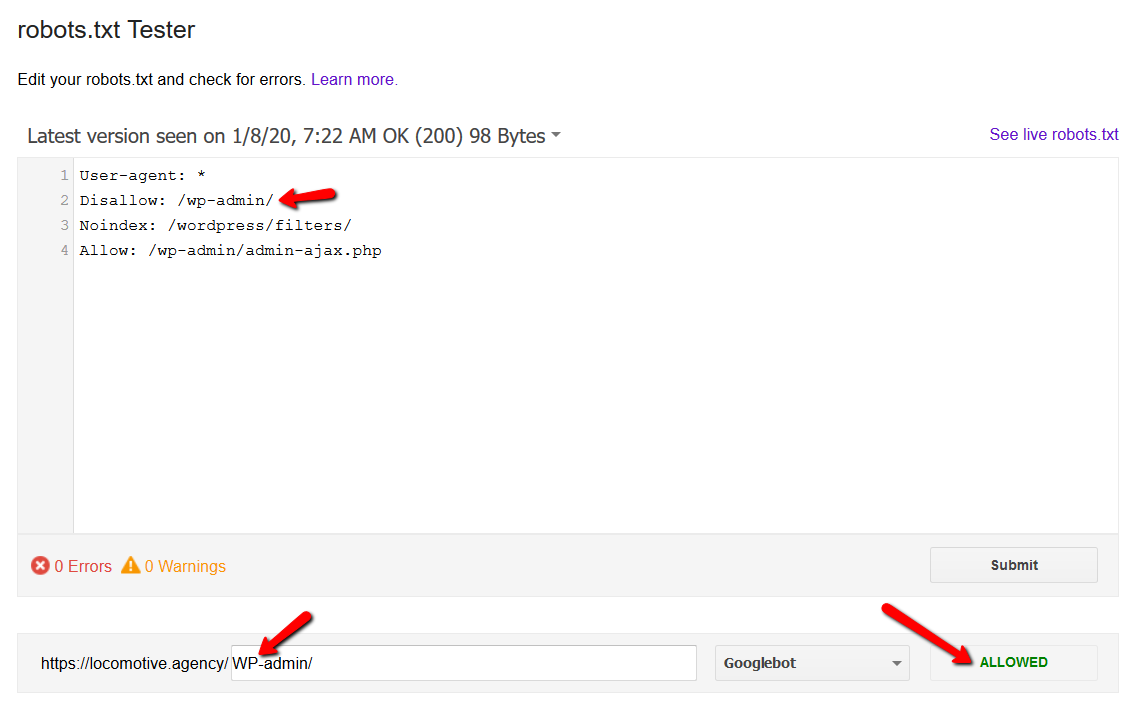
- Robots.txt peka huruf besar/kecil:
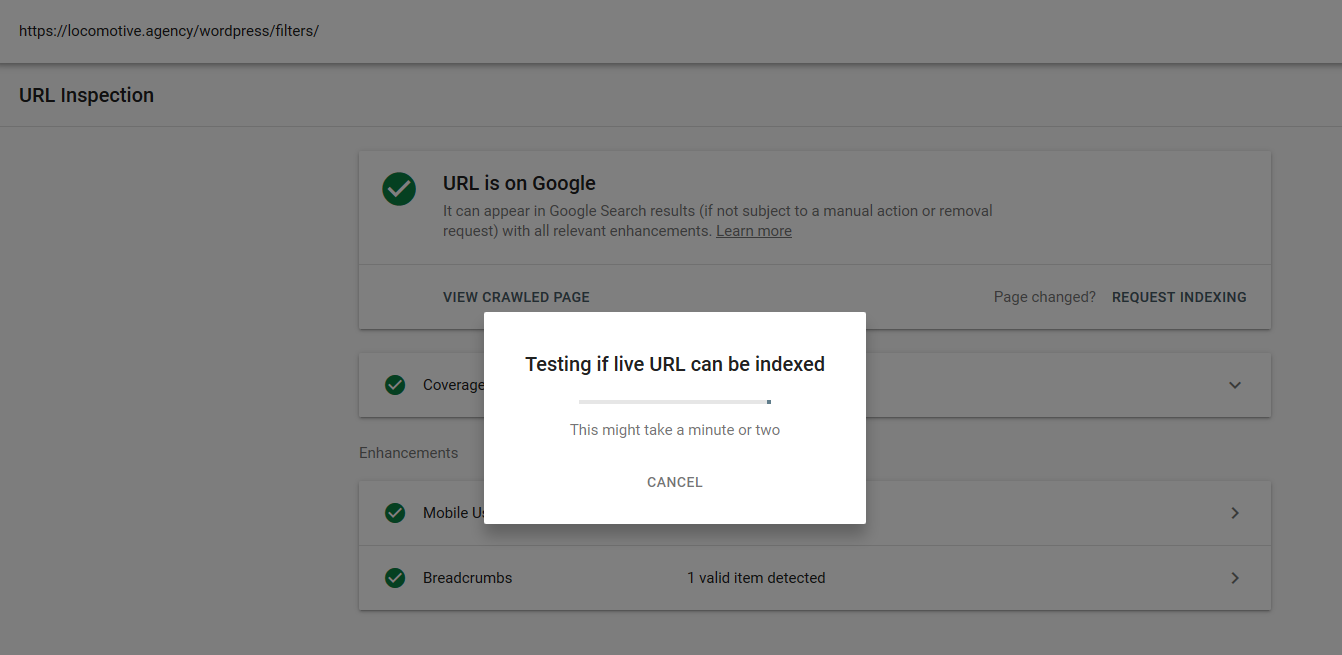
- Direktif noindex: Saat Anda menggunakan noindex di robots.txt, cara kerjanya sama seperti disallow. Google akan berhenti merayapi halaman tetapi akan menyimpannya dalam indeksnya. @jroakes dan saya membuat tes di mana kami menggunakan arahan Noindex pada artikel /wordpress/filters/ dan mengirimkan halaman di Google. Anda dapat melihat pada tangkapan layar di bawah ini yang menunjukkan bahwa URL telah diblokir:
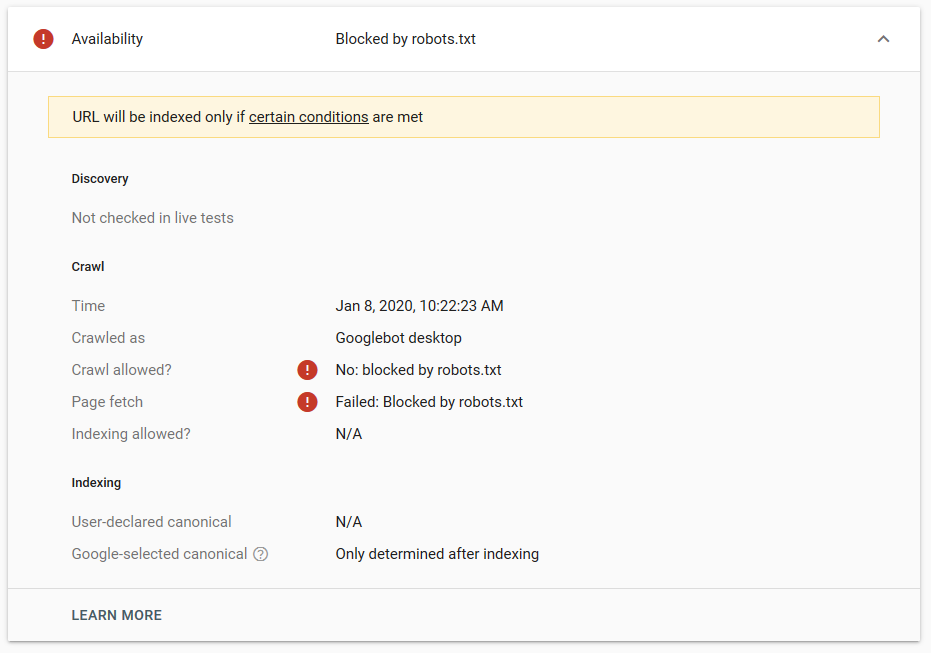
Kami melakukan beberapa pengujian di Google dan halaman tersebut tidak pernah dihapus dari indeks:

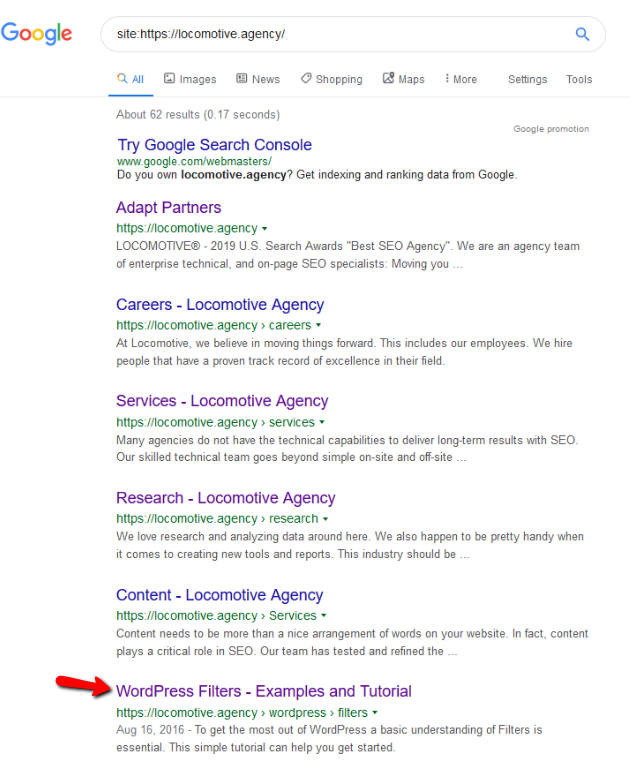
Ada diskusi tahun lalu tentang arahan noindex yang bekerja di robots.txt, menghapus halaman selain Google. Ini adalah utas di mana Gary Illyes menyatakan bahwa itu akan pergi. Pada pengujian ini kita dapat melihat bahwa solusi Google telah tersedia, karena arahan noindex tidak menghapus halaman dari hasil pencarian.
Baru-baru ini, ada utas menarik lainnya di twitter dari Christian Oliveira, di mana ia membagikan beberapa detail untuk dipertimbangkan saat mengerjakan robots.txt Anda.
- Jika kita ingin memiliki aturan dan aturan umum hanya untuk Googlebot, kita perlu menduplikasi semua aturan umum di bawah Agen pengguna: Kumpulan aturan bot Google. Jika tidak disertakan, Googlebot akan mengabaikan semua aturan:

- Perilaku membingungkan lainnya adalah bahwa prioritas aturan (di dalam grup Agen-pengguna yang sama) tidak ditentukan oleh urutannya, tetapi oleh panjang aturan.
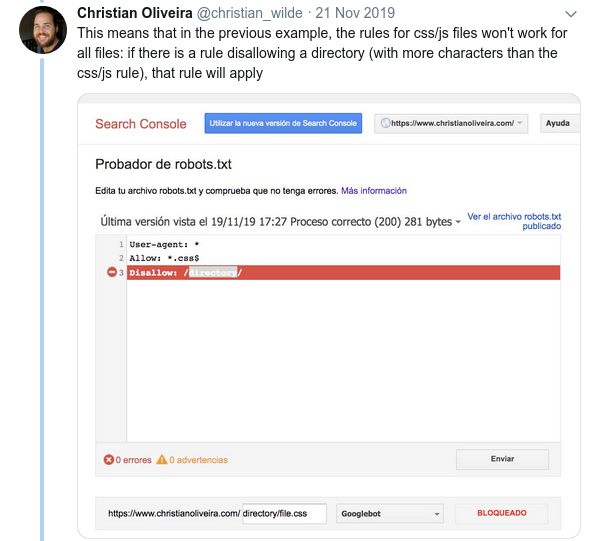
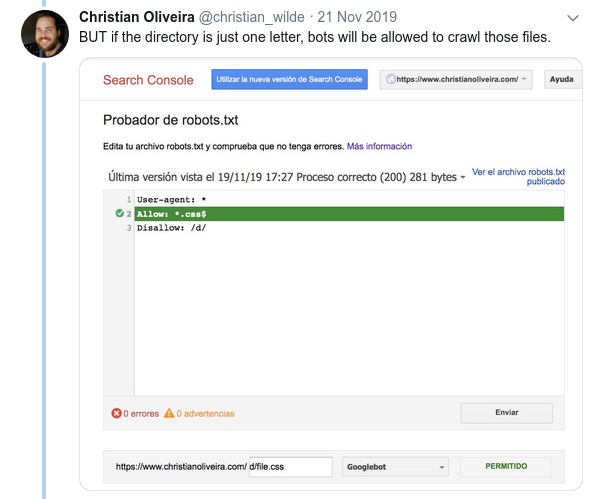
- Sekarang, ketika Anda memiliki dua aturan, dengan panjang yang sama dan perilaku yang berlawanan (satu mengizinkan perayapan dan yang lainnya melarangnya), aturan yang tidak terlalu ketat berlaku:
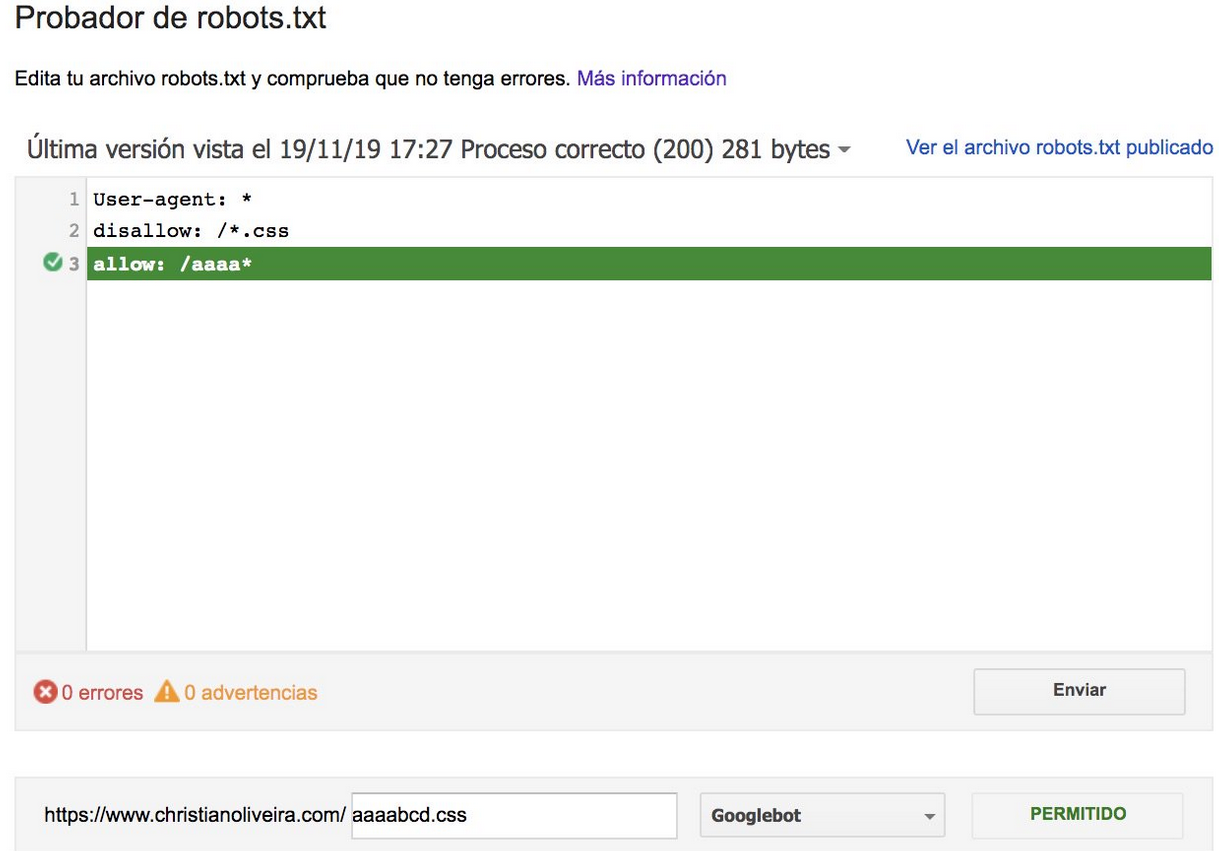
Untuk contoh lainnya, silakan baca spesifikasi robots.txt yang disediakan oleh Google.
Alat untuk menguji Robots.txt Anda
Jika Anda ingin menguji file robots.txt Anda, ada beberapa alat yang dapat membantu Anda dan juga beberapa repositori github jika Anda ingin membuatnya sendiri:
- sulingan
- Google telah meninggalkan alat penguji robots.txt dari Google Search Console lama di sini
- Di Python
- Di C++
Contoh Hasil: penggunaan Robots.txt yang efektif untuk e-niaga
Di bawah ini saya telah menyertakan kasus di mana kami bekerja dengan situs Magento yang tidak memiliki file robots.txt. Magento serta CMS lainnya memiliki halaman dan direktori admin dengan file yang tidak ingin dirayapi oleh Google. Di bawah ini, kami telah menyertakan contoh beberapa direktori yang kami sertakan di robots.txt:
# # Direktori Magento Umum Larang: / aplikasi / Larang: / pengunduh / Larang: / kesalahan / Larang: / termasuk / Larang: / lib / Larang: / pkginfo / Larang: / cangkang / Larang: / var / # # Jangan mengindeks halaman pencarian dan kategori tautan yang tidak dioptimalkan Larang: /catalog/product_compare/ Larang: /catalog/category/view/ Larang: /catalog/product/view/ Larang: /catalog/produk/galeri/ Larang: /catalogsearch/
Banyaknya halaman yang tidak dimaksudkan untuk dirayapi memengaruhi anggaran perayapan mereka dan Googlebot tidak dapat merayapi semua halaman produk di situs.
Anda dapat melihat pada gambar di bawah ini bagaimana halaman yang diindeks meningkat setelah 25 Oktober, yaitu saat robots.txt diimplementasikan:
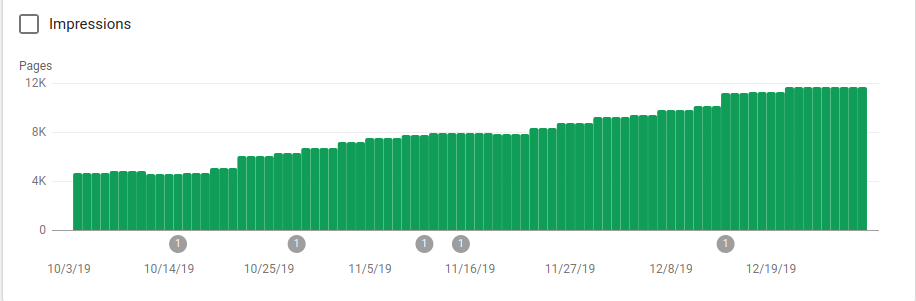
Selain memblokir beberapa direktori yang tidak dimaksudkan untuk dirayapi, robot menyertakan tautan ke peta situs. Pada tangkapan layar di bawah, Anda dapat melihat bagaimana jumlah halaman yang diindeks meningkat dibandingkan dengan halaman yang dikecualikan:
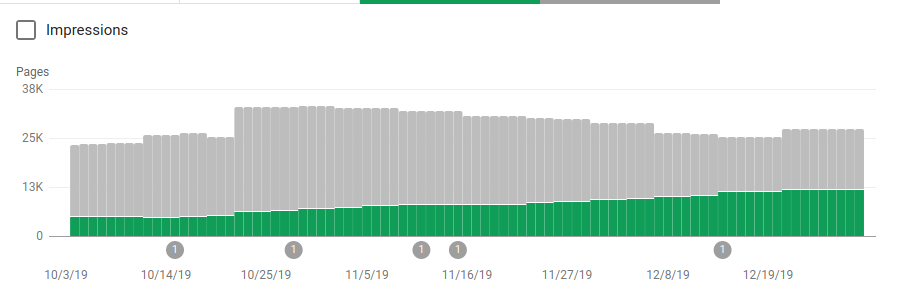
Ada tren positif pada halaman valid yang diindeks seperti yang ditunjukkan oleh bilah hijau dan tren negatif pada halaman yang dikecualikan yang ditunjukkan oleh bilah abu-abu.
Membungkus
Pentingnya robots.txt terkadang dapat diremehkan dan seperti yang Anda lihat dari posting ini ada banyak detail yang perlu dipertimbangkan saat membuatnya. Tetapi pekerjaan itu membuahkan hasil: Saya telah menunjukkan beberapa hasil positif yang dapat Anda peroleh dari menyiapkan robots.txt dengan benar.