
Bagaimana membentuk cuplikan di era Google sebagai penerbit
Diterbitkan: 2019-10-22Google telah melihat dirinya sebagai penerbit konten untuk waktu yang lama sekarang, meskipun tren telah menjadi sulit untuk diabaikan dalam beberapa tahun terakhir. Ini sebagian telah difasilitasi oleh kemajuan dalam pembelajaran mesin dan oleh fitur halaman hasil mesin pencari (SERP) baru.
“Google sebagai penerbit konten” adalah masalah potensial bagi banyak pemilik situs web, karena menyajikan pilihan yang sulit. Seharusnya kamu:
- Lindungi konten Anda dan risiko dikeluarkan dari hasil Google?
- Berikan sumber konten gratis ke Google, mengetahui bahwa Google mungkin tidak mengirim pengunjung ke situs Anda?
Tag pengelolaan cuplikan baru yang mulai berlaku akhir Oktober 2019 dapat dilihat sebagai deklarasi niat oleh Google. Mereka juga merupakan langkah ke arah yang benar dalam memberikan pemilik situs web sarana untuk melindungi konten mereka dan untuk mengontrol bagaimana halaman mereka muncul di SERP.
Mengapa khawatir tentang konten berkualitas?
Properti Google masih menyediakan sekitar 60% lalu lintas ke situs web, bergantung pada vertikal, jadi tidak memainkan permainan Google berpotensi menimbulkan efek negatif yang sangat besar pada visibilitas dan lalu lintas situs web. Tetapi pada saat yang sama, melalui EAT dan Pedoman Penilai Kualitas, Google telah dengan jelas menetapkan bahwa konten berkualitas adalah apa yang dicari pengguna internet, dan bahwa situs web harus berinvestasi dalam memproduksinya agar dapat bertahan.
Investasi dalam konten unik dan berkualitas tinggi adalah sesuatu yang secara alami ingin dilindungi oleh pemilik situs web. Dalam memberikan konten, situs web memungkinkan penyedia lain (dalam hal ini: mesin pencari) untuk mendapatkan keuntungan dari waktu, uang, dan keahlian mereka.
Bagaimana cara Google menggunakan konten?
Google menggunakan, remix, dan menulis ulang konten untuk memberikan jawaban atas pertanyaan yang diajukan oleh pengguna mesin pencari. Jawaban-jawaban ini ditampilkan dalam berbagai bentuk di SERP.
Daftar hasil pencarian, atau “cuplikan”
Google menyusun cuplikan untuk halaman web tertentu dalam hasil pencarian menggunakan elemen berbeda yang awalnya diambil dari halaman web itu sendiri:
- tag <judul>
- <meta description=”Teks cuplikan”> tag
- Markup Schema.org untuk data terstruktur yang didukung
- URL
- Favicon (dalam hasil seluler di beberapa wilayah)
Saat ini, beberapa di antaranya digunakan apa adanya. Google berhak mengganti favicon. Google secara eksplisit menyatakan bahwa “pembuatan judul dan deskripsi halaman mereka sepenuhnya otomatis dan … [Google menggunakan] sejumlah sumber berbeda untuk informasi ini, termasuk informasi deskriptif dalam judul dan tag meta untuk setiap halaman”. Akhirnya, Google telah mulai menekan URL di SERPs seperti yang terlihat dalam pengujian baru-baru ini.
Google menghapus URL di SERP dapat sedikit membantu TLD "buruk".
Jika Anda tidak tahu apakah itu .io, .org, .net, .ie dll, dll, Anda tidak dapat menentang mereka dan mengklik .com yang tampaknya lebih sah. Mungkin bukan dampak yang besar, tetapi bisa menjadi dampak halus yang menjadi lebih besar dari waktu ke waktu. pic.twitter.com/CcQ2E0lVtZ
— Ross Hudgens (@RossHudgens) 21 Oktober 2019
Cuplikan unggulan
Google membuat cuplikan unggulan, yang muncul sebelum daftar hasil pencarian, dengan mengekstraksi konten dari halaman web yang muncul untuk menjawab pertanyaan pencari. Ada berbagai episode cuplikan unggulan yang muncul tanpa atribusi (atau tanpa atribusi yang terlihat atau dapat diakses dengan mudah) pada bulan Februari dan Juni 2019. Dalam setiap kasus, Google telah mencela niat untuk mengabaikan hak penerbit dan mengklaim bahwa kurangnya atribusi adalah sebuah kesalahan.
Definisi, cuaca, dan makanan
Mencari definisi kamus atau cuaca di lokasi tertentu menghasilkan jawaban di kotak pelengkapan otomatis, tanpa atribusi, dan tanpa perlu melakukan pencarian.
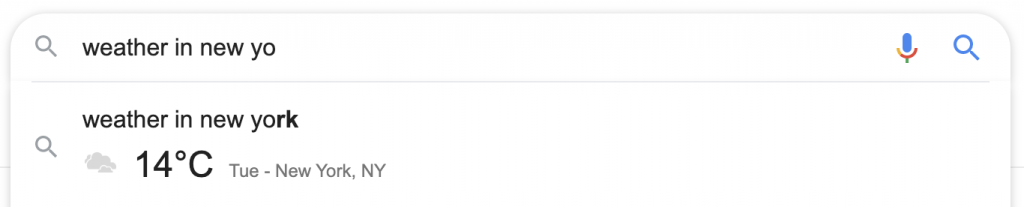
Dalam hal definisi, jika tombol pencarian ditekan, definisi lengkap, lengkap dengan suara, sinonim, dan fitur dalam SERP lainnya, tersedia. Pencari tidak perlu mengunjungi situs kamus Oxford, dan atribusi Oxford muncul dalam teks abu-abu kecil di bawah kotak definisi.
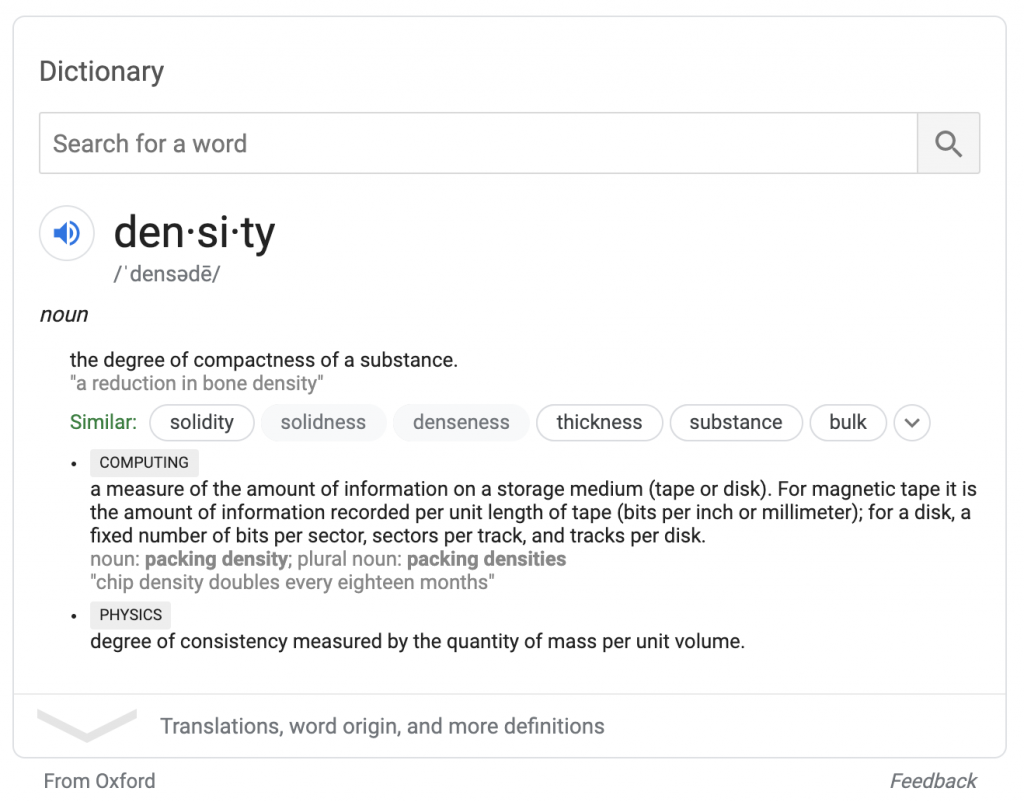
Pencarian cuaca lengkap menyediakan kotak ramalan serupa berdasarkan data dari weather.com. Seperti atribusi Oxford, atribusi weather.com muncul di bawah kotak; pencari dapat berinteraksi dengan data di dalam kotak tanpa pernah mengunjungi weather.com.
Hasil pencarian serupa lainnya adalah untuk fakta nutrisi dan komposisi makanan:
Namun, dalam hal ini, atribusi dicantumkan sebagai "sumber termasuk". Jika sumber lain digunakan, sumber tersebut tidak terlihat atau dapat diakses.
Hasil berorientasi lokal
Banyak hasil terkait aktivitas lokal juga diambil dari berbagai sumber untuk membuat SERP yang menyediakan berbagai informasi agregat dan gabungan. Alih-alih mengunjungi situs web yang berbeda, seorang pencari dapat, misalnya, melihat daftar film yang sedang diputar di dekat mereka, mencari waktu tayang di bioskop yang berbeda, dan menemukan detail–ulasan, sinopsis, dan lebih banyak lagi–tentang masing-masing film. Pencari tidak perlu meninggalkan SERP yang dikuratori Google.
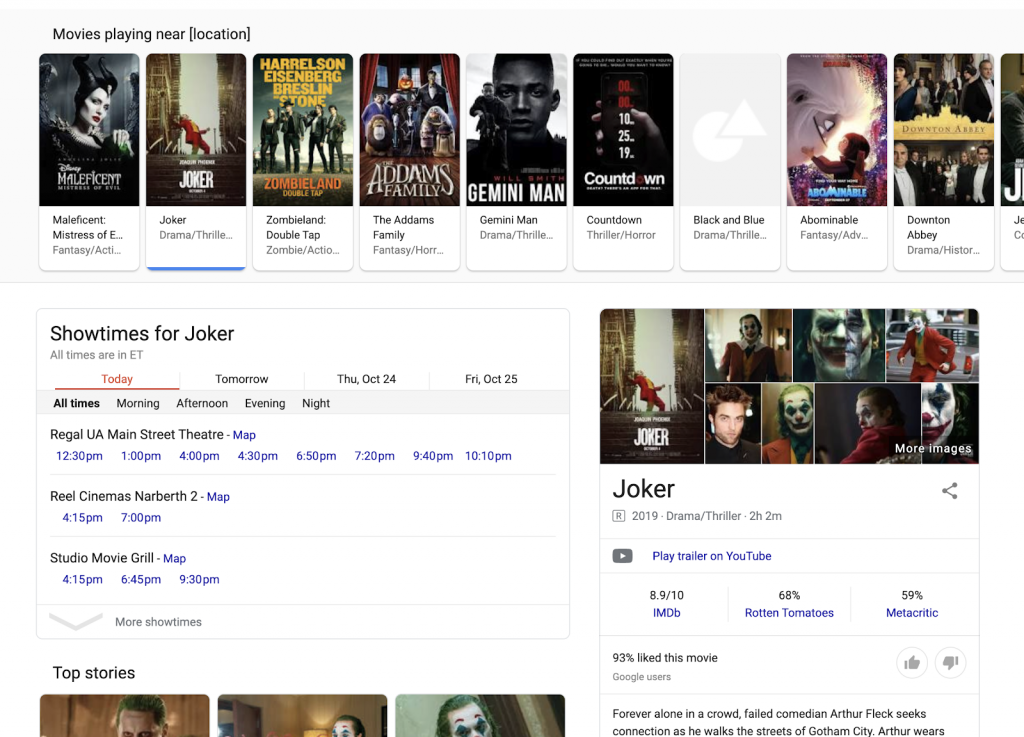
Jenis SERP ini berkembang ke berbagai bidang, termasuk perjalanan.
cerita AMP
Cerita AMP menyediakan mode "berfokus pada cerita" untuk "konsumsi berita di seluler". Mereka adalah contoh bagaimana pengindeksan berbasis entitas telah meningkatkan kemampuan Google untuk menarik konten dari sumber yang berbeda dan mencampurnya kembali. Dalam beberapa cerita buatan Google untuk penampilan selebritas, Google telah memasangkan gambar dari satu sumber dengan teks dari sumber lain, misalnya.
Panel pengetahuan
Panel pengetahuan adalah "kotak informasi yang muncul di Google saat Anda mencari entitas" yang merupakan bagian dari Grafik Pengetahuan Google. Informasi yang ditampilkan di panel ini diambil dari berbagai sumber, yang dicantumkan oleh Google sebagai:
- mitra data yang memberikan data resmi tentang topik tertentu seperti film atau musik
- buka sumber web
- entitas terverifikasi yang telah menyarankan pengeditan fakta di panel pengetahuan mereka sendiri
- pratinjau hasil Gambar Google untuk entitas
Google sebelumnya telah mengindikasikan bahwa Grafik Pengetahuan mereka bergantung pada sumber seperti Wikipedia/Wikidata, CIA World Factbook, data terstruktur di seluruh web publik, Google Bisnisku, dan banyak lagi.
Mereka juga dapat menunjukkan entitas terkait, yang memungkinkan pengguna penelusuran untuk menavigasi Grafik Pengetahuan tanpa meninggalkan situs web mesin telusur.
Fitur SERP lainnya
Fitur SERP lainnya termasuk elemen prediksi kueri yang mencoba menjawab atau menyalurkan kembali aktivitas pencarian tanpa mengirim pengguna pencarian ke situs web yang berbeda. Contohnya termasuk jawaban tanpa hasil dalam penelusuran seluler atau pelengkapan otomatis, serta kotak “Orang juga bertanya” (PAA).


Contoh pencarian tanpa hasil (seluler), yang ditampilkan sebagai jawaban langsung di kotak pelengkapan otomatis di desktop
Manajemen konten dalam hasil pencarian
Markup Schema.org
Dengan sedikit kontrol langsung atas elemen lain yang membentuk daftar pencarian, SEO telah bersandar secara besar-besaran pada kekuatan cuplikan kaya melalui markup Schema.org untuk membuat daftar mereka menonjol di SERP.
Namun, Google telah menindak penyalahgunaan markup kaya, termasuk bintang ulasan dan markup FAQ:
Google Review Stars di hasil pencarian turun 14% sejak update:
— Situs keuangan turun 46%
— Situs Real Estat turun 46%
— Situs Hukum & Pemerintah turun 28%Data Baru melalui oleh @dr_pete https://t.co/DdlrCFIrsm pic.twitter.com/w2lj9WzpLR
— Cyrus (@CyrusShepard) 24 September 2019
Agar SERP tidak penuh dengan hasil #FAQ, #Google tampaknya telah menetapkan batas pada 3 hasil FAQ #SEO @brodieseo @sengineland https://t.co/V8vSiKwrrv pic.twitter.com/A0Spmu9iMg
— AJ Ghergich (@SEO) 8 Oktober 2019
Indikasi eksplisit tentang konten apa yang tidak dapat digunakan
Minggu ini, Google meluncurkan tag manajemen cuplikan yang dapat digunakan untuk menunjukkan kepada Google beberapa batasan tentang apa yang dapat digunakan untuk membuat cuplikan halaman di SERP.
Tag pengelolaan baru memiliki dua batasan utama:
- Mereka tidak berlaku untuk data terstruktur (markup Schema.org) di halaman . Data terstruktur Schema.org yang didukung oleh Google selalu memenuhi syarat untuk ditampilkan di hasil penelusuran.
- Mereka dapat mencegah halaman Anda digunakan dalam "fitur khusus" tertentu di SERP, termasuk cuplikan unggulan , jika tidak memenuhi panjang minimum yang diperlukan oleh fitur SERP. Karena panjangnya bervariasi menurut bahasa, Google tidak memublikasikan panjang minimum untuk cuplikan unggulan. Sebaliknya, “[t]selang yang tidak ingin konten muncul sebagai cuplikan unggulan dapat bereksperimen dengan panjang cuplikan maksimum yang lebih rendah.”
Pemilik situs web memiliki dua opsi untuk menerapkan tag ini:
1. Tag robot meta
Mulai akhir Oktober, di seluruh dunia, tag meta robots ini dapat ditambahkan ke halaman <head> atau di header HTTP x-robots.
- <meta name="robots" content=" nosnippet "> – jangan tampilkan teks cuplikan untuk halaman ini. Thumbnail gambar masih dapat digunakan.
- <meta name=”robots” content=" max-snippet: 50″> – atur panjang maksimum jumlah karakter untuk snippet. Panjang cuplikan "0" sama dengan "nosnippet"; panjang cuplikan “-1” ditafsirkan sebagai arti bahwa tidak ada batasan untuk panjang cuplikan.
- <meta name=”robots” content=” max-video-preview: 3″> – atur durasi maksimum, dalam detik, untuk pratinjau video. Panjang video "0" akan mencegah pratinjau video ditampilkan; panjang video "-1" ditafsirkan sebagai arti bahwa tidak ada batasan untuk panjang pratinjau video.
- <meta name=”robots” content=” max-image-preview: standard”> – atur ukuran gambar maksimum untuk gambar dari halaman ini. Pilihannya adalah: "tidak ada", "standar", atau "besar".
Anda dapat menggunakan lebih dari satu operator pengelolaan cuplikan di tag meta robot yang sama. Pisahkan setiap operator dengan koma.
2. Atribut HTML data-nosnippet
Pada akhir 2019, atribut HTML baru akan dikenali oleh Google: data-nosnippet . Ini dapat diterapkan ke tag <span>, <div> atau <selection>.
Atribut data-nosnippet mencegah teks dalam tag yang diterapkan agar tidak muncul di cuplikan halaman.
Izin eksplisit untuk penggunaan kembali konten untuk pers Eropa di Prancis
Pencampuran ulang dan penerbitan ulang konten berita Google telah melewati batas undang-undang hak cipta di beberapa lokasi. Prancis baru-baru ini menjadi sorotan:
Karena perubahan undang-undang hak cipta di Prancis, Google Penelusuran tidak akan menampilkan cuplikan teks atau gambar mini untuk publikasi pers Eropa yang terpengaruh di Prancis, kecuali situs web telah menerapkan tag meta untuk mengizinkan pratinjau penelusuran. (Sumber)
Dengan kata lain, Google akan mengecualikan dari hasil pencarian di Prancis setiap publikasi Eropa yang tidak secara eksplisit mengizinkannya untuk memublikasikan ulang dan akhirnya membuat remix konten.
Ironisnya, cara pemberian izin tidak terlalu jelas: satu-satunya tag meta robots yang permisif secara eksplisit adalah “semua”, yang “adalah nilai default dan tidak berpengaruh jika dicantumkan secara eksplisit” kecuali, sekarang, pada SERP Prancis.
Jika tidak, penerbit hanya dapat menunjukkan kurangnya batasan pada panjang pratinjau teks dan video melalui konvensi yang tidak termasuk dalam pengumuman tentang pengelolaan cuplikan, atau mereka dapat menerapkan batasan sewenang-wenang untuk memberi sinyal bahwa mereka tidak ingin melarang pratinjau penelusuran .
Berjalan di atas tali
Setiap situs web perlu menemukan keseimbangan yang tepat antara melindungi kontennya dan membentuk kehadirannya di SERP Google.
Karena Google semakin berperilaku sebagai penerbit konten, kami dapat mengharapkan lebih banyak fitur SERP dengan atribusi minimal, serta lebih banyak negara di mana undang-undang hak cipta – yang dimaksudkan untuk melindungi pemilik dan pembuat konten – berdampak pada apa yang dapat dan tidak dapat ditampilkan oleh Google.
Apa yang menurut saya menarik adalah implikasi hak cipta dari ini… Orang-orang mengeluh tentang G mengambil konten tanpa izin – tag cuplikan akan menjadi izin diam-diam. Apakah akan lama sebelum mereka diperlukan?
— Jenny Halasz (@jennyhalasz) 15 Oktober 2019
Untungnya, alat manajemen cuplikan baru memberi pemilik situs web awal kotak alat untuk membentuk bagian mana – dan seberapa banyak – konten mereka dapat digunakan kembali oleh Google di SERP.
Untuk saat ini, saya yakin akan bijaksana untuk menerapkan tag pengelolaan cuplikan sebagaimana mestinya di situs web dengan konten asli yang substansial, meskipun saya khawatir bahwa tag yang hanya membatasi tidak akan berguna untuk semua situs web. Terlepas dari peringatan ini, masih ada cara untuk menggunakannya untuk mengoptimalkan pengalaman di SERP dan mendapatkan lebih banyak lalu lintas.
Saya pikir orang akan mengadopsi tag baru. Saya pikir ada beberapa peluang untuk "membentuk" cuplikan dengan tag tersebut untuk memberikan pengalaman yang lebih baik daripada apa yang ditarik Google secara otomatis dan mengoptimalkan RKT.
— Kevin_Indig (@Kevin_Indig) 16 Oktober 2019
Saya tak sabar untuk melihat eksperimen di vertikal yang berbeda untuk menemukan apa yang terbaik.