
Pengelompokan Kata Kunci Semantik dengan Python
Diterbitkan: 2021-04-19Di dunia yang penuh dengan mitos pemasaran digital, kami percaya bahwa solusi praktis untuk masalah sehari-hari adalah yang kami butuhkan.
Di PEMAVOR, kami selalu berbagi keahlian dan pengetahuan untuk memenuhi kebutuhan para penggemar digital marketing. Jadi, kami sering memposting skrip Python gratis untuk membantu Anda meningkatkan ROI Anda.
Pengelompokan Kata Kunci SEO kami dengan Python membuka jalan untuk mendapatkan wawasan baru untuk proyek SEO besar, hanya dengan kurang dari 50 baris kode Python.
Ide di balik skrip ini adalah untuk memungkinkan Anda mengelompokkan kata kunci tanpa membayar 'biaya berlebihan' ke… yah, kami tahu siapa…
Tapi kami menyadari skrip ini tidak cukup dengan sendirinya. Ada kebutuhan untuk skrip lain, sehingga kalian dapat lebih memahami kata kunci Anda: Anda harus dapat “ mengelompokkan kata kunci berdasarkan makna dan hubungan semantik. ”
Sekarang, saatnya membawa Python untuk SEO selangkah lebih maju.
Data Perayapan³
 Belajarlah lagi
Belajarlah lagiCara tradisional pengelompokan semantik
Seperti yang Anda ketahui, metode tradisional untuk semantik adalah membangun model word2vec , lalu mengelompokkan kata kunci dengan Word Mover's Distance .
Tapi model ini membutuhkan banyak waktu dan usaha untuk membangun dan melatih. Jadi, kami ingin menawarkan solusi yang lebih mudah kepada Anda. 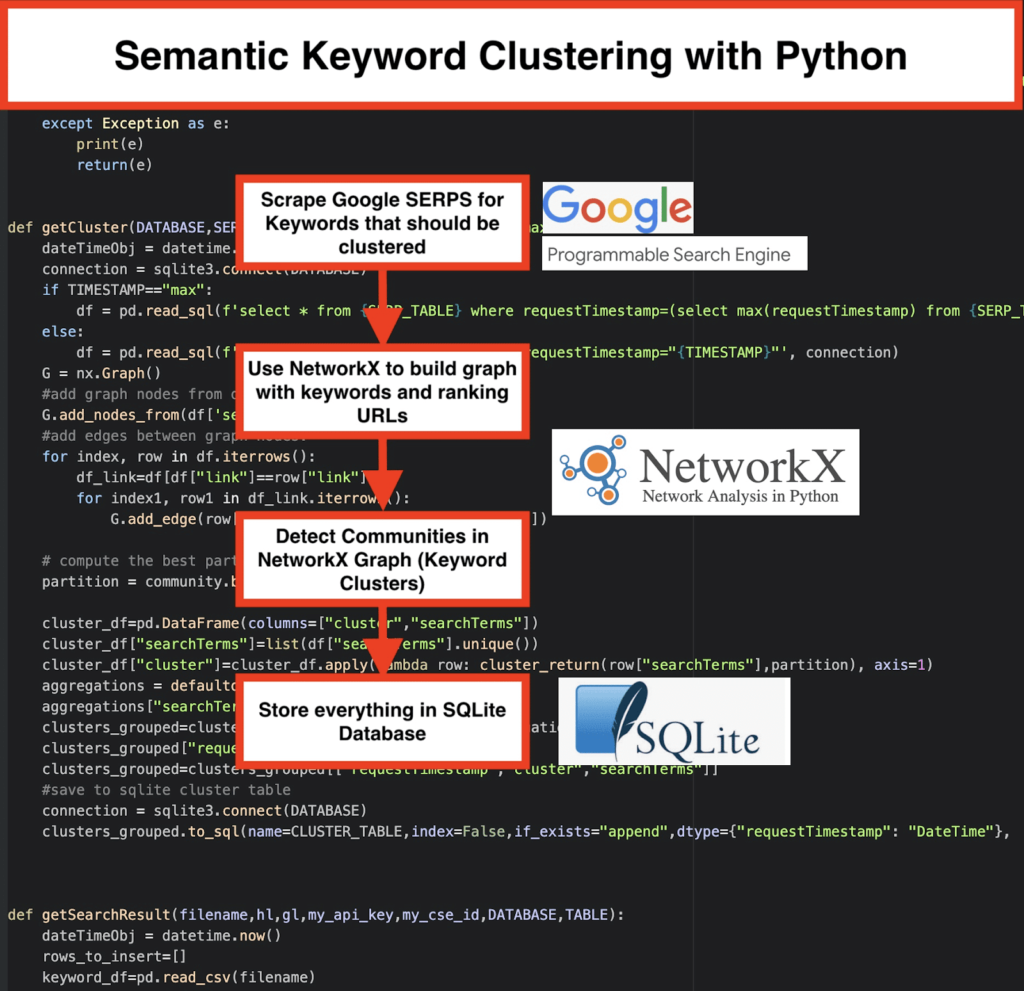
Hasil SERP Google dan menemukan semantik
Google menggunakan model NLP untuk menawarkan hasil pencarian terbaik. Ini seperti kotak Pandora yang akan dibuka, dan kita tidak tahu persisnya.
Namun, daripada membangun model kami, kami dapat menggunakan kotak ini untuk mengelompokkan kata kunci berdasarkan semantik dan artinya.
Inilah cara kami melakukannya:
️ Pertama, buat daftar kata kunci untuk suatu topik.
️ Kemudian, kikis data SERP untuk setiap kata kunci.
️ Selanjutnya, dibuat grafik dengan hubungan antara halaman peringkat dan kata kunci.
️ Selama peringkat halaman yang sama untuk kata kunci yang berbeda, itu berarti mereka terkait bersama. Ini adalah prinsip inti di balik pembuatan kluster kata kunci semantik.
Saatnya menyatukan semuanya dengan Python
Script Python menawarkan fungsi-fungsi di bawah ini:
- Dengan menggunakan mesin pencari khusus Google, unduh SERP untuk daftar kata kunci. Data disimpan ke database SQLite . Di sini, Anda harus menyiapkan API pencarian khusus.
- Kemudian, manfaatkan kuota gratis 100 permintaan setiap hari. Tetapi mereka juga menawarkan paket berbayar seharga $5 per 1000 pencarian jika Anda tidak ingin menunggu atau jika Anda memiliki kumpulan data yang besar.
- Lebih baik menggunakan solusi SQLite jika Anda tidak terburu-buru – hasil SERP akan ditambahkan ke tabel pada setiap proses. (Cukup ambil rangkaian 100 kata kunci baru ketika Anda memiliki kuota lagi keesokan harinya.)
- Sementara itu, Anda perlu mengatur variabel-variabel ini dalam Python Script .
- CSV_FILE=”keywords.csv” => simpan kata kunci Anda di sini
- BAHASA = “id”
- NEGARA = “id”
- API_KEY="xxxxxxx"
- CSE_ID="xxxxxxx"
- Menjalankan
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)akan menulis hasil SERP ke database. - Clustering dilakukan oleh networkx dan modul deteksi komunitas. Data diambil dari database SQLite – pengelompokan disebut dengan
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - Hasil Clustering dapat ditemukan di tabel SQLite – selama Anda tidak mengubahnya, namanya adalah “keyword_clusters” secara default.
Di bawah ini, Anda akan melihat kode lengkapnya:
# Pengelompokan Kata Kunci Semantik oleh Pemavor.com # Penulis: Stefan Neefischer ([email protected]) dari googleapiclient.discovery impor build impor panda sebagai pd impor Levenshtein dari datetime impor datetime dari fuzzywuzzy impor fuzz dari urllib.parse impor urlparse dari tld impor get_tld impor langid impor json impor panda sebagai pd impor numpy sebagai np impor networkx sebagai nx komunitas impor impor sqlite3 impor matematika impor io dari koleksi impor defaultdict def cluster_return(searchTerm,partisi): kembalikan partisi[searchTerm] def language_detection(str_lan): lan=langid.classify(str_lan) kembali lan[0] def extract_domain(url, remove_http=True): uri = urlparse(url) jika hapus_http: domain_name = f"{uri.netloc}" kalau tidak: domain_name = f"{uri.netloc}://{uri.netloc}" kembali domain_name def extract_mainDomain(url): res = get_tld(url, as_object=True) kembali res.fld def fuzzy_ratio(str1,str2): kembali fuzz.ratio(str1,str2) def fuzzy_token_set_ratio(str1,str2): kembalikan fuzz.token_set_ratio(str1,str2) def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): mencoba: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() kembalikan res kecuali Pengecualian sebagai e: cetak (e) kembali (e) def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs): mencoba: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute() kembalikan res kecuali Pengecualian sebagai e: cetak (e) kembali (e) def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"): dateTimeObj = datetime.now() koneksi = sqlite3.connect(DATABASE) jika TIMESTAMP="maks": df = pd.read_sql(f'select * from {SERP_TABLE} di mana requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', koneksi) kalau tidak: df = pd.read_sql(f'select * from {SERP_TABLE} dimana requestTimestamp="{TIMESTAMP}"', koneksi) G = nx.Graph() #tambahkan simpul grafik dari kolom kerangka data G.add_nodes_from(df['searchTerms']) #menambahkan tepi di antara simpul grafik: untuk indeks, baris di df.iterrows(): df_link=df[df["tautan"]==baris["tautan"]] untuk indeks1, baris1 di df_link.iterrows(): G.add_edge(row["searchTerms"], row1['searchTerms']) # menghitung partisi terbaik untuk komunitas (cluster) partisi = community.best_partition(G) cluster_df=pd.DataFrame(columns=["cluster","searchTerms"]) cluster_df["searchTerms"]=daftar(df["searchTerms"].unique()) cluster_df["cluster"]=cluster_df.apply(baris lambda: cluster_return(row["searchTerms"],partisi), axis=1 agregasi = defaultdict() agregasi["searchTerms"]=' | '.Ikuti clusters_grouped=cluster_df.groupby("cluster").agg(aggregations).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=cluster_grouped[["requestTimestamp","cluster","searchTerms"]] #simpan ke tabel cluster sqlite koneksi = sqlite3.connect(DATABASE) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) def getSearchResult(nama file,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE): dateTimeObj = datetime.now() rows_to_insert=[] kata kunci_df=pd.read_csv(nama file) kata kunci=keyword_df.iloc[:,0].tolist() untuk kueri dalam kata kunci: jika hl="default": hasil = google_search_default_language(query, my_api_key, my_cse_id,gl) kalau tidak: hasil = google_search(query, my_api_key, my_cse_id,hl,gl) jika "item" di hasil dan "permintaan" di hasil: untuk posisi dalam range(0,len(result["items"])): hasil["item"][posisi]["posisi"]=posisi+1 result["items"][position]["main_domain"]= extract_mainDomain(result["items"][position]["link"]) result["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],kueri) result["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],kueri) result["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],kueri) result["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query) result["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"]) untuk posisi dalam range(0,len(result["items"])): rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"], "displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"], "position":result["items"][position]["position"],"snippet":result["items"][position]["snippet"], "snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], "snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"], "title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"], }) df=pd.DataFrame(rows_to_insert) #simpan hasil serp ke database sqlite koneksi = sqlite3.connect(DATABASE) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=koneksi) ############################################################# ############################################################# ##################################################### #Baca aku: # ############################################################# ############################################################# ##################################################### #1- Anda perlu menyiapkan mesin pencari khusus google. # # Harap Berikan Kunci API dan SearchId. # # Juga atur negara dan bahasa Anda di mana Anda ingin memantau Hasil SERP. # # Jika Anda belum memiliki Kunci API dan Id Pencarian, # # Anda dapat mengikuti langkah-langkah di bawah bagian Prasyarat di halaman ini https://developers.google.com/custom-search/v1/overview#prasyarat # # # #2- Anda juga perlu memasukkan nama database, tabel serp dan tabel cluster yang akan digunakan untuk menyimpan hasil. # # # #3- masukkan nama file csv atau path lengkap yang berisi kata kunci yang akan digunakan untuk serp# # # #4- Untuk pengelompokan kata kunci masukkan stempel waktu untuk hasil serp yang akan digunakan untuk pengelompokan. # # Jika Anda perlu mengelompokkan hasil serp terakhir, masukkan "maks" untuk stempel waktu. # # atau Anda dapat memasukkan stempel waktu tertentu seperti "2021-02-18 17:18:05.195321" # # # #5- Telusuri hasil melalui browser DB untuk program Sqlite # ############################################################# ############################################################# ##################################################### #csv nama file yang memiliki kata kunci untuk serp CSV_FILE="kata kunci.csv" # tentukan bahasa BAHASA = "id" #tentukan kota NEGARA = "id" #google pencarian kustom kunci json api API_KEY="MASUKKAN KUNCI DI SINI" #ID mesin pencari MTU_ #nama database sqlite DATABASE="kata kunci.db" #nama tabel untuk menyimpan hasil serp ke dalamnya SERP_TABLE="kata kunci_serps" # jalankan serp untuk kata kunci getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) #nama tabel yang akan disimpan oleh hasil cluster. CLUSTER_TABLE="keyword_cluster" #Silakan masukkan timestamp, jika Anda ingin membuat cluster untuk timestamp tertentu #Jika Anda perlu membuat cluster untuk hasil serp terakhir, kirimkan dengan nilai "max" #TIMESTAMP="2021-02-18 17:18:05.195321" TIMESTAMP="maks" #jalankan kluster kata kunci sesuai dengan jaringan dan algoritme komunitas getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

Hasil SERP Google dan menemukan semantik
Kami harap Anda menikmati skrip ini dengan pintasannya untuk mengelompokkan kata kunci Anda ke dalam kelompok semantik tanpa bergantung pada model semantik. Karena model ini seringkali rumit dan mahal, penting untuk melihat cara lain untuk mengidentifikasi kata kunci yang memiliki properti semantik.
Dengan memperlakukan kata kunci yang terkait secara semantik bersama-sama, Anda dapat meliput subjek dengan lebih baik, menautkan artikel di situs Anda dengan lebih baik satu sama lain, dan meningkatkan peringkat situs web Anda untuk topik tertentu.