
Memahami Laporan Cakupan Search Console
Diterbitkan: 2019-08-15Pengantar laporan cakupan dan cara menginterpretasikan data
Laporan Cakupan Search Console memberikan informasi tentang laman mana di situs Anda yang telah diindeks dan mencantumkan URL yang menimbulkan masalah saat Googlebot mencoba merayapi dan mengindeksnya.
Halaman utama dalam laporan cakupan menampilkan URL di situs Anda yang dikelompokkan berdasarkan status:
- Kesalahan: halaman tidak diindeks. Ada beberapa alasan untuk ini, antara lain halaman merespons dengan 404, halaman lunak 404.
- Valid dengan peringatan: halaman diindeks tetapi memiliki masalah.
- Valid: halaman diindeks.
- Dikecualikan: Halaman tidak diindeks, Google mengikuti aturan di situs seperti tag noindex di robots.txt atau tag meta, tag kanonik, dll. yang mencegah halaman diindeks.
Laporan cakupan ini memberikan lebih banyak informasi daripada konsol pencarian google lama. Google telah benar-benar meningkatkan data yang dibagikannya, tetapi masih ada beberapa hal yang perlu diperbaiki.
Seperti yang Anda lihat di bawah, Google menunjukkan grafik dengan jumlah URL di setiap kategori. Jika ada peningkatan kesalahan yang tiba-tiba, Anda dapat melihat bilah dan bahkan menghubungkannya dengan tayangan untuk menentukan apakah peningkatan URL dengan kesalahan atau peringatan dapat menurunkan tayangan.

Setelah situs diluncurkan atau Anda membuat bagian baru, Anda ingin melihat peningkatan jumlah halaman terindeks yang valid. Dibutuhkan beberapa hari untuk Google mengindeks halaman baru, tetapi Anda dapat menggunakan alat inspeksi URL untuk meminta pengindeksan dan mengurangi waktu bagi Google untuk menemukan halaman baru Anda.

Namun, jika Anda melihat penurunan jumlah URL yang valid atau melihat lonjakan tiba-tiba, penting untuk bekerja mengidentifikasi URL di bagian Kesalahan dan memperbaiki masalah yang tercantum dalam laporan. Google memberikan ringkasan item tindakan yang baik untuk dilakukan ketika ada peningkatan kesalahan atau peringatan.
Google memberikan informasi tentang kesalahan apa dan berapa banyak URL yang bermasalah:

Ingat bahwa Google Search Console tidak menampilkan informasi yang 100% akurat. Bahkan, ada beberapa laporan tentang bug dan anomali data. Selain itu, Google Search console membutuhkan waktu untuk memperbarui, diketahui bahwa datanya tertinggal 16 hari hingga 20 hari. Selain itu, laporan terkadang akan menampilkan daftar lebih dari 1000 halaman dalam kategori kesalahan atau peringatan seperti yang dapat Anda lihat pada gambar di atas, tetapi laporan tersebut hanya memungkinkan Anda untuk melihat dan mengunduh sampel 1000 URL untuk Anda audit dan periksa.
Namun demikian, ini adalah alat yang hebat untuk menemukan masalah pengindeksan di situs Anda:
Saat Anda mengeklik kesalahan tertentu, Anda akan dapat melihat laman detail yang mencantumkan contoh URL:

Seperti yang Anda lihat pada gambar di atas, ini adalah halaman detail untuk semua URL yang merespons dengan 404. Setiap laporan memiliki tautan "Pelajari Lebih Lanjut" yang membawa Anda ke halaman dokumentasi Google yang memberikan detail tentang kesalahan spesifik tersebut. Google juga menyediakan grafik yang menunjukkan jumlah halaman yang terpengaruh dari waktu ke waktu.
Anda dapat mengklik setiap URL untuk memeriksa URL yang mirip dengan fitur "fetch as Googlebot" lama dari Google Search Console lama. Anda juga dapat menguji apakah halaman tersebut diblokir oleh robots.txt Anda
Setelah Anda memperbaiki URL, Anda dapat meminta Google untuk memvalidasinya sehingga kesalahan tersebut hilang dari laporan Anda. Anda harus memprioritaskan perbaikan masalah yang berada dalam status validasi "gagal" atau "tidak dimulai".
Penting untuk disebutkan bahwa Anda tidak boleh mengharapkan semua URL di situs Anda diindeks. Google menyatakan bahwa tujuan webmaster adalah agar semua URL kanonik diindeks. Halaman duplikat atau alternatif akan dikategorikan sebagai dikecualikan karena memiliki konten yang mirip dengan halaman kanonik.
Biasanya situs memiliki beberapa halaman yang termasuk dalam kategori yang dikecualikan. Sebagian besar situs web akan memiliki beberapa halaman tanpa tag meta indeks atau diblokir melalui robots.txt. Saat Google mengidentifikasi halaman duplikat atau alternatif, Anda harus memastikan halaman tersebut memiliki tag kanonik yang menunjuk ke URL yang benar dan mencoba menemukan padanan kanonik dalam kategori yang valid.
Google telah menyertakan filter tarik-turun di kiri atas laporan sehingga Anda dapat memfilter laporan untuk semua halaman yang diketahui, semua halaman yang dikirim, atau URL dalam peta situs tertentu. Laporan default mencakup semua halaman yang diketahui yang mencakup semua URL yang ditemukan oleh Google. Semua halaman yang dikirimkan mencakup semua URL yang telah Anda laporkan melalui peta situs. Jika Anda telah mengirimkan beberapa peta situs, Anda dapat memfilter menurut URL di setiap peta situs.
[Studi Kasus] Tingkatkan anggaran perayapan di halaman strategis
 Baca studi kasus
Baca studi kasusKesalahan, Peringatan, URL yang Valid dan yang Dikecualikan
Kesalahan
- Kesalahan server (5xx): Server mengembalikan kesalahan 500 saat Googlebot mencoba merayapi laman.
- Kesalahan pengalihan: Saat Googlebot merayapi URL, terjadi kesalahan pengalihan, baik karena rantai terlalu panjang, ada pengulangan pengalihan, URL melebihi panjang maksimum URL, atau ada URL yang buruk atau kosong dalam rantai pengalihan.
- URL yang dikirim diblokir oleh robots.txt: URL dalam daftar ini diblokir oleh file robts.txt Anda.
- URL yang dikirimkan bertanda 'noindex': URL dalam daftar ini memiliki tag meta robots 'noindex' atau header http.
- URL yang dikirimkan tampaknya adalah Soft 404: Kesalahan 404 lunak terjadi ketika halaman yang tidak ada (telah dihapus atau dialihkan) menampilkan pesan 'halaman tidak ditemukan' kepada pengguna tetapi gagal mengembalikan kode status HTTP 404. Soft 404 juga terjadi ketika halaman dialihkan ke halaman yang tidak relevan, misalnya halaman yang dialihkan ke halaman beranda alih-alih mengembalikan kode status 404 atau mengarahkan ulang ke halaman yang relevan.
- URL yang dikirim mengembalikan permintaan tidak sah (401): Halaman yang dikirimkan untuk pengindeksan mengembalikan respons HTTP 401 yang tidak sah.
- URL yang dikirim tidak ditemukan (404): Laman merespons dengan kesalahan 404 Tidak Ditemukan saat Googlebot mencoba merayapi laman.
- URL yang dikirimkan memiliki masalah perayapan: Googlebot mengalami kesalahan perayapan saat merayapi laman ini yang tidak termasuk dalam kategori lainnya. Anda harus memeriksa setiap URL dan menentukan apa masalahnya.
Peringatan
- Diindeks, meskipun diblokir oleh robots.txt: Halaman diindeks karena Googlebot mengaksesnya melalui tautan eksternal yang mengarah ke halaman, namun halaman tersebut diblokir oleh robots.txt Anda. Google menandai URL ini sebagai peringatan karena mereka tidak yakin apakah halaman tersebut benar-benar harus diblokir agar tidak muncul di hasil pencarian. Jika Anda ingin memblokir halaman, Anda harus menggunakan tag meta 'noindex', atau menggunakan header respons HTTP noindex.
Jika Google benar dan URL salah diblokir, Anda harus memperbarui file robots.txt agar Google dapat merayapi laman.
Sah
- Dikirim dan diindeks: URL yang Anda kirimkan ke Google melalui sitemap.xml untuk pengindeksan dan diindeks.
- Diindeks, tidak dikirimkan dalam peta situs: URL ditemukan oleh Google dan diindeks, tetapi tidak disertakan dalam peta situs Anda. Disarankan untuk memperbarui peta situs Anda dan menyertakan setiap halaman yang Anda ingin Google jelajahi dan indeks.
Pengecualian
- Dikecualikan oleh tag 'noindex': Saat Google mencoba mengindeks halaman, ia menemukan tag meta robot 'noindex' atau header HTTP.
- Diblokir oleh alat penghapusan halaman: Seseorang telah mengirimkan permintaan ke Google untuk tidak mengindeks halaman ini dengan menggunakan permintaan penghapusan URL di Google Search Console. Jika Anda ingin halaman ini diindeks, masuk ke Google Search Console dan hapus dari daftar halaman yang dihapus.
- Diblokir oleh robots.txt: File robots.txt memiliki baris yang mengecualikan URL agar tidak dirayapi. Anda dapat memeriksa baris mana yang melakukan ini dengan menggunakan penguji robots.txt.
- Diblokir karena permintaan yang tidak sah (401): Sama seperti dalam kategori Kesalahan, halaman di sini ditampilkan dengan header HTTP 401.
- Anomali perayapan: Ini adalah jenis kategori penampung semua, URL di sini merespons dengan kode respons level 4xx atau 5xx; Kode respons ini mencegah pengindeksan halaman.
- Dirayapi – saat ini tidak diindeks: Google tidak memberikan alasan mengapa URL tidak diindeks. Mereka menyarankan untuk mengirimkan kembali URL untuk pengindeksan. Namun, penting untuk memeriksa apakah halaman tersebut memiliki konten yang tipis atau duplikat, halaman tersebut dikanonisasi ke halaman yang berbeda, memiliki arahan noindex, metrik menunjukkan pengalaman pengguna yang buruk, waktu buka halaman yang tinggi, dll. Mungkin ada beberapa alasan mengapa Google tidak ingin mengindeks halaman.
- Ditemukan – saat ini tidak diindeks: Halaman ditemukan tetapi Google belum memasukkannya ke dalam indeksnya. Anda dapat mengirimkan URL untuk indeksasi untuk mempercepat proses seperti yang kami sebutkan di atas. Google menyatakan bahwa alasan umum hal ini terjadi adalah karena situs kelebihan beban dan Google menjadwal ulang perayapan.
- Halaman alternatif dengan tag kanonik yang tepat: Google tidak mengindeks halaman ini karena memiliki tag kanonik yang menunjuk ke URL yang berbeda. Google telah mengikuti aturan kanonik dan telah mengindeks URL kanonik dengan benar. Jika Anda bermaksud agar halaman ini tidak diindeks, maka tidak ada yang perlu diperbaiki di sini.
- Duplikat tanpa kanonik yang dipilih pengguna: Google telah menemukan duplikat untuk halaman yang tercantum dalam kategori ini dan tidak ada yang menggunakan tag kanonik. Google telah memilih versi yang berbeda sebagai tag kanonik. Anda perlu meninjau halaman ini dan menambahkan tag kanonik yang menunjuk ke URL yang benar.
- Duplikat, Google memilih kanonik yang berbeda dari pengguna: URL dalam kategori ini telah ditemukan oleh Google tanpa permintaan perayapan eksplisit. Google menemukan ini melalui tautan eksternal dan telah menentukan bahwa ada halaman lain yang membuat kanonik yang lebih baik. Google belum mengindeks halaman ini karena alasan ini. Google merekomendasikan untuk menandai URL ini sebagai duplikat dari kanonik.
- Tidak ditemukan (404): Saat Googlebot mencoba mengakses halaman ini, mereka merespons dengan kesalahan 404. Google menyatakan bahwa URL ini belum dikirimkan, URL ini telah ditemukan melalui tautan eksternal yang mengarah ke URL ini. Sebaiknya alihkan URL ini ke halaman serupa untuk memanfaatkan ekuitas tautan dan juga memastikan pengguna mendarat di halaman yang relevan.
- Halaman dihapus karena keluhan hukum: Seseorang telah mengeluh tentang halaman ini karena masalah hukum, seperti pelanggaran hak cipta. Anda dapat mengajukan banding atas keluhan hukum yang diajukan di sini.
- Halaman dengan pengalihan: URL ini mengalihkan, oleh karena itu mereka dikecualikan.
- Soft 404: Seperti yang dijelaskan di atas, URL ini dikecualikan karena seharusnya merespons dengan 404. Periksa halaman dan pastikan jika ada pesan 'tidak ditemukan' agar mereka merespons dengan header HTTP 404.
- Duplikat, URL yang dikirimkan tidak dipilih sebagai kanonik: Mirip dengan "Google memilih kanonik yang berbeda dari pengguna", namun URL dalam kategori ini dikirimkan oleh Anda. Sebaiknya periksa peta situs Anda dan pastikan tidak ada halaman duplikat yang disertakan.
Cara menggunakan data dan item tindakan untuk meningkatkan situs
Bekerja di agensi, saya memiliki akses ke banyak situs berbeda dan laporan liputannya. Saya telah menghabiskan waktu menganalisis kesalahan yang dilaporkan Google dalam berbagai kategori.
Sangat membantu untuk menemukan masalah dengan kanonikalisasi dan konten duplikat, namun terkadang Anda menemukan perbedaan seperti yang dilaporkan oleh @jroakes:

Sepertinya Google Search Console > Inspeksi URL > Uji Langsung salah melaporkan semua file JS dan CSS sebagai Perayapan diizinkan: Tidak: diblokir oleh robots.txt. Uji sekitar 20 file di 3 domain. pic.twitter.com/fM3WAcvK8q
— JR%20Oakes ???? (@jroakes) 16 Juli 2019
AJ Koh, menulis artikel yang bagus segera setelah Google Search Console baru tersedia di mana dia menjelaskan bahwa nilai sebenarnya dalam data menggunakannya untuk melukiskan gambaran kesehatan untuk setiap jenis konten di situs Anda:
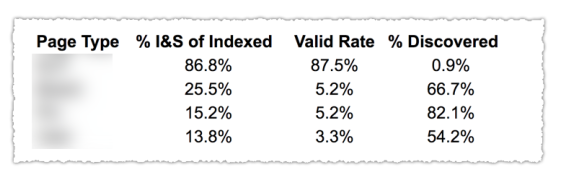
Seperti yang Anda lihat pada gambar di atas, URL dari berbagai kategori dalam laporan cakupan telah diklasifikasikan berdasarkan template halaman seperti blog, halaman layanan, dll. Menggunakan beberapa peta situs untuk berbagai jenis URL dapat membantu tugas ini karena Google mengizinkan Anda untuk memfilter informasi cakupan berdasarkan peta situs. Kemudian dia memasukkan tiga kolom dengan informasi berikut % halaman yang Diindeks dan Dikirim, Tarif Valid dan % ditemukan.
Tabel ini benar-benar memberi Anda gambaran yang bagus tentang kesehatan situs Anda. Sekarang jika Anda ingin menggali bagian yang berbeda, saya sarankan untuk meninjau laporan dan memeriksa ulang kesalahan yang disajikan google.
Anda dapat mengunduh semua URL yang disajikan dalam Kategori yang berbeda dan menggunakan OnCrawl untuk memeriksa status HTTP, tag kanonik, dll. dan membuat spreadsheet seperti ini:
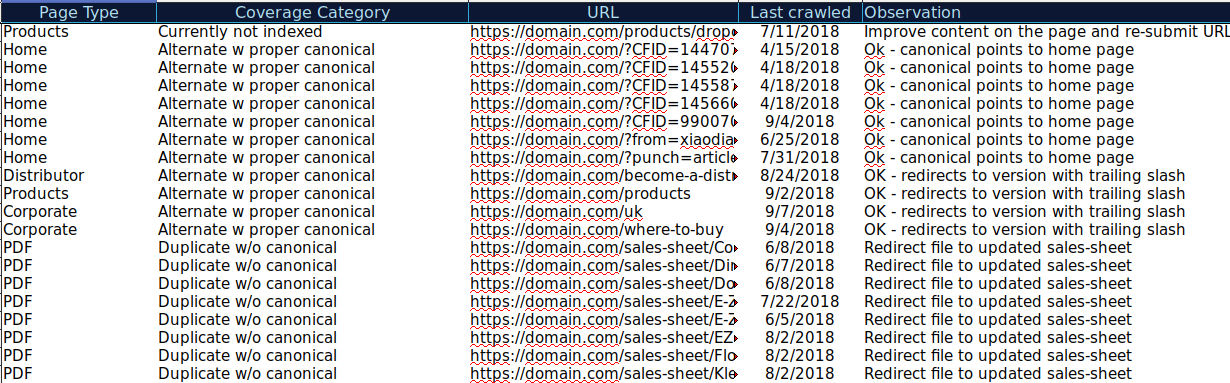
Mengatur data Anda seperti ini dapat membantu melacak masalah serta menambahkan item tindakan untuk URL yang perlu ditingkatkan atau diperbaiki. Selain itu, Anda dapat memeriksa URL yang benar dan tidak ada item tindakan yang diperlukan untuk URL tersebut dengan parameter dengan penerapan tag kanonik yang benar.
Mulai uji coba gratis selama 14 hari
 Mulai uji coba Anda
Mulai uji coba AndaAnda bahkan dapat menambahkan lebih banyak informasi ke spreadsheet ini dari sumber lain seperti ahrefs, Majestic, dan Google Analytics dengan integrasi OnCrawl. Ini akan memungkinkan Anda untuk mengekstrak data tautan serta lalu lintas dan data konversi untuk setiap URL di Google Search Console. Semua data ini dapat membantu Anda membuat keputusan yang lebih baik tentang apa yang harus dilakukan untuk setiap halaman, misalnya jika Anda memiliki daftar halaman dengan 404, Anda dapat mengikat ini dengan tautan balik untuk menentukan apakah Anda kehilangan ekuitas tautan dari domain yang tertaut ke halaman rusak di situs Anda. Atau Anda dapat memeriksa halaman yang diindeks dan berapa banyak lalu lintas organik yang mereka peroleh. Anda dapat mengidentifikasi halaman yang diindeks yang tidak mendapatkan lalu lintas organik dan berupaya mengoptimalkannya (meningkatkan konten dan kegunaan) untuk membantu mengarahkan lebih banyak lalu lintas ke halaman tersebut.
Dengan data tambahan ini, Anda dapat membuat tabel ringkasan di spreadsheet lain. Anda dapat menggunakan rumus =COUNTIF(rentang, kriteria) untuk menghitung URL di setiap jenis halaman (tabel ini dapat melengkapi tabel yang disarankan AJ Kohn di atas). Anda juga dapat menggunakan rumus lain untuk menambahkan tautan balik, kunjungan, atau konversi yang Anda ekstrak untuk setiap URL dan menampilkannya di tabel ringkasan dengan rumus berikut =SUMIF (rentang, kriteria, [jumlah_rentang]). Anda akan mendapatkan sesuatu seperti ini:
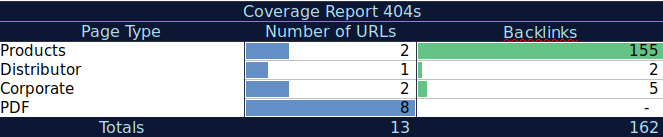
Saya sangat suka bekerja dengan tabel ringkasan yang dapat memberi saya tampilan ringkasan data dan dapat membantu saya mengidentifikasi bagian yang perlu saya fokuskan untuk diperbaiki terlebih dahulu.
Pikiran terakhir
Apa yang perlu Anda pikirkan saat memperbaiki masalah dan melihat data dalam laporan ini adalah: Apakah situs saya dioptimalkan untuk perayapan? Apakah halaman terindeks dan valid saya bertambah atau berkurang? Halaman dengan kesalahan apakah bertambah atau berkurang? Apakah saya mengizinkan Google untuk menghabiskan waktu di URL yang akan memberikan nilai lebih bagi pengguna saya atau apakah Google menemukan banyak halaman yang tidak berharga? Dengan jawaban atas pertanyaan-pertanyaan ini, Anda dapat mulai melakukan perbaikan pada situs Anda sehingga Googlebot dapat menghabiskan anggaran perayapannya pada halaman yang dapat memberikan nilai bagi pengguna Anda, bukan halaman yang tidak berharga. Anda dapat menggunakan robots.txt untuk membantu meningkatkan efisiensi perayapan, menghapus URL yang tidak berguna jika memungkinkan, atau menggunakan tag kanonik atau noindex untuk mencegah konten duplikat.
Google terus menambahkan fungsionalitas dan memperbarui akurasi data ke laporan yang berbeda di konsol pencarian Google, jadi semoga kami akan terus melihat lebih banyak data di setiap kategori dalam laporan cakupan serta laporan lainnya di Google Search Console.