
Bangkitnya Pencarian Multimodal dan Multibahasa
Diterbitkan: 2022-01-06Memperluas pencarian di luar kueri tekstual dan menghilangkan hambatan bahasa adalah tren terkini yang membentuk masa depan mesin pencari. Dengan fitur baru yang diberdayakan AI, mesin telusur berupaya untuk mempromosikan pengalaman penelusuran yang lebih baik dan, pada saat yang sama, menghadirkan alat baru untuk membantu pengguna mengambil informasi spesifik. Dalam artikel ini, kami akan membahas topik yang sedang naik daun tentang sistem pencarian multimodal dan multibahasa . Kami juga akan menampilkan hasil alat pencarian demo yang kami buat di Wordlift.
Generasi berikutnya dari mesin pencari
Pengalaman pengguna yang baik mencakup berbagai aspek interaksi antara pengguna dan mesin telusur. Dari desain antarmuka pengguna dan kegunaannya hingga pemahaman maksud penelusuran dan penyelesaian kueri ambigunya, mesin telusur besar sedang mempersiapkan generasi alat telusur berikutnya .
Pencarian multimodal
Salah satu cara untuk mendeskripsikan mesin pencari multimodal adalah dengan memikirkan sistem yang mampu menangani teks dan gambar dalam satu kueri . Mesin pencari semacam itu akan memungkinkan pengguna untuk mengekspresikan permintaan input mereka melalui antarmuka pencarian multimodal dan sebagai hasilnya memungkinkan pengalaman pencarian yang lebih alami dan intuitif.
Di situs web e-niaga, mesin pencari multimodal akan memungkinkan pengambilan dokumen yang relevan dari database yang diindeks. Relevansi dievaluasi dengan mengukur kesamaan produk yang tersedia dengan kueri tertentu dalam lebih dari satu format seperti teks, gambar, audio, atau video. Akibatnya, mesin pencari ini adalah sistem multimodal karena mekanisme dasarnya mampu menangani modal input yang berbeda, yaitu format, pada waktu yang sama.
Misalnya, kueri penelusuran dapat berupa "gaun bermotif bunga". Dalam hal ini, sejumlah besar gaun bunga tersedia di toko web. Namun, mesin pencari mengembalikan gaun yang tidak terlalu memuaskan pengguna seperti yang ditunjukkan pada gambar berikut.
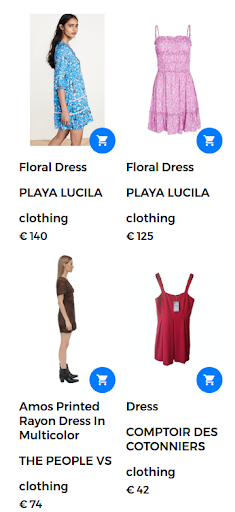
Menampilkan hasil pencarian "baju bunga".
Untuk memberikan pengalaman penelusuran yang baik dan mengembalikan hasil yang sangat relevan, mesin telusur multimodal mampu menggabungkan teks dan gambar dalam satu kueri . Dalam hal ini, pengguna memberikan contoh gambar produk yang diinginkan. Saat menjalankan pencarian ini sebagai pencarian multimodal, gambar input adalah gaun bunga yang ditunjukkan pada gambar berikut.

Gambar yang disediakan pengguna untuk kueri multimodal.
Dalam skenario ini, bagian pertama kueri tetap sama (gaun bunga) dan bagian kedua menambahkan aspek visual ke kueri multimodal. Hasil yang dikembalikan menghasilkan gaun yang mirip dengan gaun bunga yang diberikan pengguna. Dalam kasus penggunaan ini, gaun yang sama persis tersedia dan, oleh karena itu, adalah hasil pertama yang dikembalikan bersama gaun serupa lainnya.
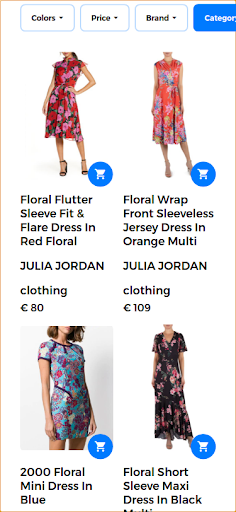
Hasil pencarian yang relevan dikembalikan sebagai tanggapan atas kueri multimodal.
BUNGKAM
Google memperkenalkan teknologi baru untuk membantu pengguna dengan tugas pencarian yang kompleks. Teknologi baru ini, yang disebut MUM, singkatan dari Multitask Unified Model dan mampu meruntuhkan hambatan bahasa dan menafsirkan informasi di berbagai format konten seperti halaman web dan gambar.
Google Lens adalah salah satu produk pertama yang memanfaatkan keunggulan menggabungkan gambar dan teks ke dalam satu kueri. Dalam konteks pencarian, MUM akan memudahkan pengguna untuk menemukan pola seperti pola bunga tertentu dalam gambar yang disediakan pengguna.
MUM adalah tonggak AI baru untuk memahami informasi seperti yang disajikan di sini:
“Meskipun kami berada di hari-hari awal menjelajahi MUM, ini merupakan tonggak penting menuju masa depan di mana Google dapat memahami semua cara yang berbeda orang berkomunikasi dan menafsirkan informasi secara alami.”
Untuk mempelajari lebih lanjut tentang pencarian multimodal MUM Google, periksa cerita web ini: 
Memperluas pencarian lintas bahasa
Meskipun gambarnya agnostik bahasa, istilah penelusurannya khusus bahasa. Tugas merancang sistem multibahasa bermuara pada membangun model bahasa di berbagai bahasa.
Pencarian multibahasa
Salah satu batasan utama dari sistem pencarian saat ini adalah mereka mengambil dokumen yang ditulis, atau dijelaskan, dalam bahasa yang digunakan pengguna untuk menulis permintaan pencarian. Secara umum, mesin ini hanya dalam bahasa Inggris. Mesin pencari monolingual seperti itu membatasi kegunaan sistem ini dalam menemukan informasi bermanfaat yang ditulis dalam bahasa yang berbeda.
Di sisi lain, sistem multibahasa menerima permintaan dalam satu bahasa dan mengambil dokumen yang diindeks dalam bahasa lain. Pada kenyataannya, sistem pencarian multibahasa jika mampu mengambil dokumen yang relevan dari database dengan mencocokkan konten dokumen, atau keterangan, yang ditulis dalam satu bahasa dengan query teks dalam bahasa lain. Teknik pencocokan berkisar dari mekanisme sintaksis hingga pendekatan pencarian semantik.
Memasangkan kalimat dalam bahasa yang berbeda dengan konsep visual adalah langkah pertama untuk mempromosikan penggunaan model visi-bahasa lintas bahasa . Kabar baiknya adalah bahwa konsep visual diinterpretasikan dengan cara yang hampir sama oleh semua manusia. Sistem ini, yang mampu menggabungkan informasi dari lebih dari satu sumber dan melintasi lebih dari satu bahasa, disebut sistem multimodal multibahasa . Namun, memasangkan gambar-teks tidak selalu layak untuk semua bahasa dalam skala besar seperti yang dibahas di bagian berikut.
[Studi Kasus] Mendorong pertumbuhan di pasar baru dengan SEO pada halaman
 Baca studi kasus
Baca studi kasusDari MUM ke MURAL
Ada upaya yang berkembang untuk menerapkan pembelajaran mendalam yang canggih dan teknik pemrosesan bahasa alami ke mesin pencari. Google mempresentasikan karya penelitian baru yang memungkinkan pengguna untuk mengekspresikan kata-kata menggunakan gambar. Misalnya, kata "valiha" mengacu pada alat musik yang terbuat dari tabung sitar dan dimainkan oleh orang Malagasi. Kata ini tidak memiliki terjemahan langsung ke sebagian besar bahasa, tetapi dapat dengan mudah dijelaskan menggunakan gambar.
Sistem baru, yang disebut MURA, adalah singkatan dari Multimodal, Multi-task Retrieval Across Languages. Hal ini memungkinkan mengatasi masalah kata-kata dalam satu bahasa yang mungkin tidak memiliki terjemahan langsung ke dalam bahasa target. Dengan masalah seperti itu, banyak model multibahasa yang telah dilatih sebelumnya akan gagal menemukan kata yang terkait secara semantik atau menerjemahkan kata secara akurat ke atau dari bahasa yang kurang sumber daya. Faktanya, MURAL dapat mengatasi banyak masalah dunia nyata:

- Kata-kata yang menyampaikan makna mental yang berbeda dalam bahasa yang berbeda: Salah satu contoh adalah kata "pernikahan" dalam bahasa Inggris dan Hindi yang menyampaikan gambaran mental yang berbeda seperti yang ditunjukkan pada gambar berikut dari blog Google.
- Kelangkaan data untuk bahasa dengan sumber daya rendah di web: 90% dari pasangan teks-gambar di web termasuk dalam 10 bahasa dengan sumber daya tinggi teratas.

Gambar diambil dari wikipedia, dikreditkan ke Psoni2402 (kiri) dan David McCandless (kanan) dengan lisensi CC BY-SA 4.0.
Mengurangi ambiguitas kueri dan memberikan solusi untuk masalah kelangkaan pasangan gambar-teks untuk bahasa yang kurang sumber daya adalah peningkatan lain menuju mesin telusur generasi berikutnya yang didukung oleh AI.
Pencarian multibahasa dan multimodal sedang beraksi
Dalam pekerjaan ini, kami menggunakan alat yang ada dan model bahasa dan visi yang tersedia untuk merancang sistem multibahasa multimodal yang melampaui satu bahasa dan dapat menangani lebih dari satu modalitas pada satu waktu .
Pertama-tama, untuk merancang sistem multibahasa, penting untuk menghubungkan kata-kata yang berasal dari bahasa yang berbeda secara semantik. Kedua, untuk membuat sistem multimodal, perlu menghubungkan representasi bahasa dengan gambar. Akibatnya, ini adalah langkah besar menuju tujuan lama dari pencarian multimodal multibahasa.
Isi
Kasus penggunaan utama dari sistem multibahasa multimodal ini adalah untuk mengembalikan gambar yang relevan dari kumpulan data yang diberikan kueri yang menggabungkan gambar dan teks pada saat yang bersamaan. Dalam nada ini, kami akan menunjukkan beberapa contoh yang menggambarkan berbagai skenario multimodal dan multibahasa.
Tulang punggung aplikasi demo ini didukung oleh Jina AI, ekosistem pencarian saraf open-source. Pencarian saraf, didukung oleh pengambilan informasi jaringan saraf dalam (atau IR saraf), adalah solusi yang menarik untuk membangun sistem multimodal. Dalam demo ini, kami menggunakan arsitektur MPNet Transformer dari Hugging Face, multibahasa-mpnet-base-v2, untuk memproses deskripsi dan teks teks. Sedangkan untuk bagian visualnya kami menggunakan MobileNetV2.
Berikut ini, kami menyajikan serangkaian tes untuk menunjukkan kekuatan mesin pencari multibahasa dan multimodal . Sebelum menyajikan hasil alat demo kami, berikut adalah daftar elemen kunci yang menjelaskan pengujian ini:
- Basis data terdiri dari 1k gambar yang menggambarkan orang-orang yang memainkan musik. Gambar-gambar ini diambil dari kumpulan data publik Flickr30K.
- Setiap gambar memiliki keterangan yang ditulis dalam bahasa Inggris.
Langkah 1: Dimulai dengan kueri tekstual dalam bahasa Inggris
Pertama, kita mulai dengan kueri tekstual yang mencerminkan cara sebagian besar mesin telusur saat ini beroperasi. Pertanyaannya adalah "kelompok musisi".
Pertanyaan 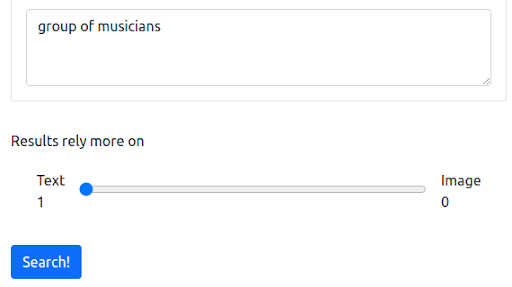
Hasil 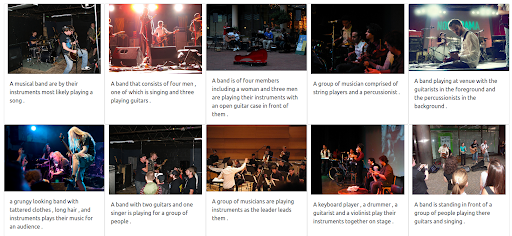
Mesin pencari demo kami yang berbasis di Jina menampilkan gambar musisi yang secara semantik terkait dengan kueri masukan. Namun, ini mungkin bukan tipe musisi yang kita inginkan.
Langkah 2: Menambahkan multimodality
Sekarang mari kita tambahkan beberapa multimodalitas dengan mengeluarkan kueri yang menggabungkan kueri tekstual sebelumnya dan sebuah gambar. Gambar tersebut mewakili representasi yang lebih akurat dari musisi yang kami cari.
Pertama-tama, UI perlu mendukung penerbitan jenis kueri semacam itu. Kemudian, kita harus menetapkan bobot untuk menyeimbangkan pentingnya setiap modalitas saat mengambil hasil. Dalam hal ini, baik teks maupun gambar memiliki bobot yang sama (0,5). Seperti yang dapat kita lihat di bawah, hasil pencarian baru menyertakan sejumlah gambar yang secara visual mirip dengan kueri gambar masukan.
Pertanyaan 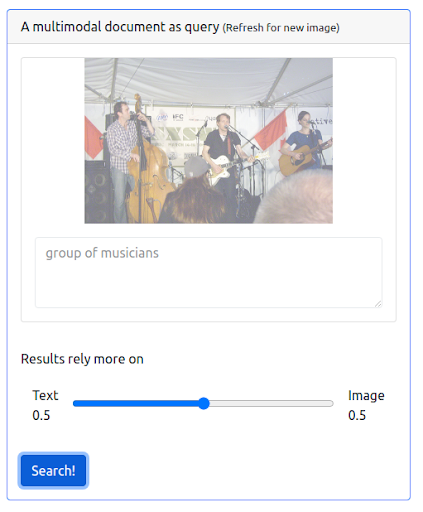
Hasil 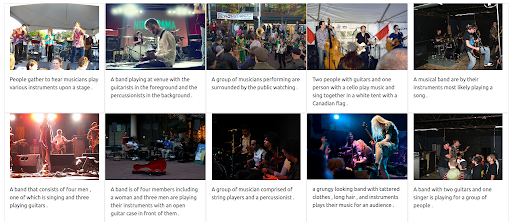
Langkah 3: Menetapkan bobot maksimum pada gambar
Dimungkinkan juga untuk memberikan bobot maksimum pada gambar. Melakukannya akan mengecualikan teks input dari kueri. Dalam hal ini, lebih banyak gambar yang secara visual mirip dengan gambar input dikembalikan dan diberi peringkat di posisi pertama. Satu hal yang perlu diingat adalah bahwa hasilnya terbatas pada gambar yang tersedia di dataset.
Pertanyaan 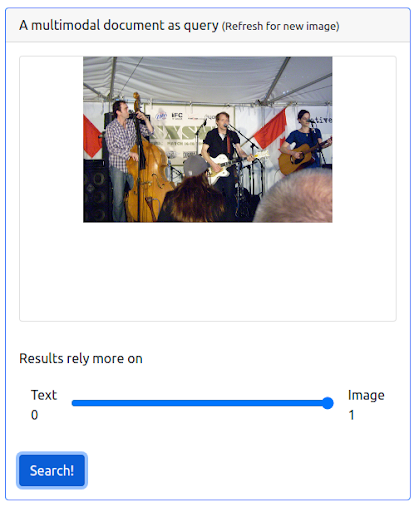
Hasil 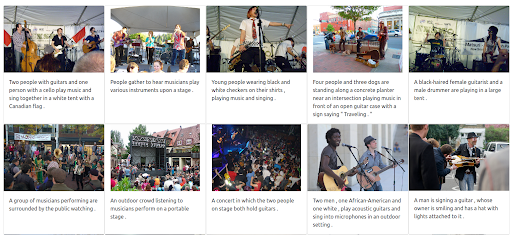
Langkah 4: Menguji pencarian multibahasa
Sekarang mari kita coba mengeluarkan kueri yang sama tetapi menggunakan bahasa yang berbeda. Bobot teks dimaksimalkan untuk menggambarkan kekuatan penuh dari sistem multibahasa ini. Harap diingat bahwa keterangan gambar hanya dalam bahasa Inggris. Pencarian diulang untuk mencakup bahasa-bahasa berikut:
- Prancis: Groupe de musiciens
- Italia: Gruppo di musicisti
- Jerman: Gruppe von Musikern
Terlepas dari bahasa kueri input, hasil yang dikembalikan relevan dan konsisten di ketiga bahasa. Hasilnya ditunjukkan di bawah ini.
Hasil kueri dalam bahasa Prancis 
Hasil kueri dalam bahasa Italia 
Hasil kueri dalam bahasa Jerman 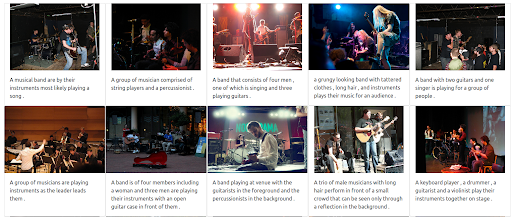
Masa depan pencarian multimodal multibahasa
Di tahun-tahun mendatang, kecerdasan buatan akan semakin mengubah pencarian dan membuka cara yang sama sekali baru bagi orang-orang untuk mengekspresikan pertanyaan mereka dan menjelajahi informasi. Seperti yang telah diumumkan Google, memahami informasi dengan MUM merupakan tonggak sejarah AI. Lebih banyak sistem yang diberdayakan AI di masa depan akan mencakup fitur dan peningkatan yang berkisar dari memberikan pengalaman pencarian yang lebih baik hingga menjawab pertanyaan-pertanyaan canggih dan dari meruntuhkan hambatan bahasa hingga menggabungkan berbagai mode pencarian ke dalam satu kueri.