
Audit SEO Teknis 11 Langkah Cepat & Kotor untuk Kesehatan Situs Web Secara Keseluruhan
Diterbitkan: 2020-02-27SEO teknis penting karena ini adalah titik awal dari proyek apa pun. Dari sudut pandang ahli SEO, setiap situs web adalah proyek baru. Sebuah situs web harus memiliki dasar yang kuat untuk mendapatkan hasil yang baik dan mencapai KPI terpenting dalam peringkat seperti SEO.
Setiap kali saya memulai dengan proyek baru, hal pertama yang saya lakukan adalah audit teknis SEO. Sebagian besar waktu memperbaiki masalah teknis bisa mendapatkan hasil yang menakjubkan segera setelah situs web di-crawl ulang.
Lucu bagi saya ketika orang berbicara tentang konten dan lebih banyak konten, tetapi mereka tidak mengatakan sepatah kata pun tentang SEO teknis. Satu hal yang pasti, kesehatan situs web dan Teknis SEO adalah dua hal penting yang akan sangat menentukan di tahun 2020. Saya tidak bermaksud mengatakan bahwa konten tidak penting. Memang, tetapi tanpa memperbaiki masalah teknis di situs web, saya tidak berpikir konten dapat membawa hasil.
Saya telah melihat kasus di mana halaman penting telah diblokir oleh arahan dalam file robots.txt, atau halaman kategori atau layanan yang paling penting rusak atau diblokir oleh robot meta seperti noindex, nofollow. Bagaimana mungkin sukses tanpa memprioritaskan dengan memperbaiki masalah ini?
Mungkin mengejutkan melihat jumlah SEO yang tidak tahu bagaimana mengidentifikasi masalah teknologi untuk dilaporkan ke spesialis pengembangan web untuk diperbaiki. Saya ingat suatu ketika ketika bekerja di bidang perusahaan, saya membuat lembar checklist audit Tech SEO untuk digunakan oleh tim saya. Pada saat itu, saya menyadari bahwa memiliki lembar perbaikan cepat seperti ini dapat sangat membantu tim dan menghasilkan dorongan cepat untuk klien. Itu sebabnya saya menganggap paling penting untuk berinvestasi dalam alat/perangkat lunak yang dapat membantu Anda dengan diagnostik dan rekomendasi SEO teknis.
Mari kita mulai proses langsung tentang cara melakukan audit SEO teknologi cepat yang akan membuat perbedaan besar. Ini adalah latihan cepat yang akan memakan waktu sekitar satu jam untuk Anda lakukan bahkan jika Anda bukan seorang profesional. Bagi saya menggunakan alat Tech SEO seperti OnCrawl untuk mempercepat semua hal dalam lima menit tanpa harus melakukan semua pekerjaan manual membuat hidup saya mudah.
Saya akan membahas hal-hal terpenting untuk diperiksa saat melakukan Audit Teknis SEO. Ada lebih banyak hal yang dapat kita periksa untuk masalah pada halaman, tetapi saya hanya ingin fokus pada hal-hal yang akan membuat masalah pengindeksan dan perayapan pemborosan anggaran. Memprioritaskan ini adalah cara untuk memastikan bahwa halaman yang paling penting akan dirayapi oleh Googlebot.
- indeksasi
- File robots.txt
- Tag robot meta
- 4xx kesalahan
- Peta Situs
- HTTP/HTTPS (keamanan situs web, konten campuran, dan masalah konten duplikat)
- paginasi
- 404 halaman
- Kedalaman dan struktur situs
- Rantai pengalihan panjang
- Implementasi tag kanonik
1) Pengindeksan
Ini adalah hal pertama yang harus diperiksa. Berkali-kali pengindeksan dapat dipengaruhi oleh konfigurasi plugin atau kesalahan kecil apa pun, tetapi dampaknya pada kemampuan untuk ditemukan bisa sangat besar, karena saat ini ada lebih dari 6,16 miliar halaman web yang diindeks. Anda perlu memahami bahwa setiap mesin pencari sedang berusaha dan bahkan Google perlu memprioritaskan halaman yang paling relevan untuk pengalaman pengguna. Jika Anda tidak mempertimbangkan untuk mempermudah Googlebot, pesaing Anda akan melakukannya dan mendapatkan lebih banyak kepercayaan yang datang dengan situs web yang sehat.
Ketika ada masalah pengindeksan, masalah kesehatan situs web Anda akan tercermin dalam hilangnya lalu lintas organik. Proses pengindeksan berarti bahwa mesin pencari merayapi halaman web dan mengatur informasi yang kemudian menawarkannya di SERP. Hasilnya bergantung pada relevansi untuk maksud pengguna. Jika halaman web tidak dapat atau memiliki masalah dengan perayapan, ini akan menguntungkan halaman lain di ceruk yang sama untuk mendapatkan keuntungan.
Menggunakan operator pencarian misalnya:
Situs: www.abc.com
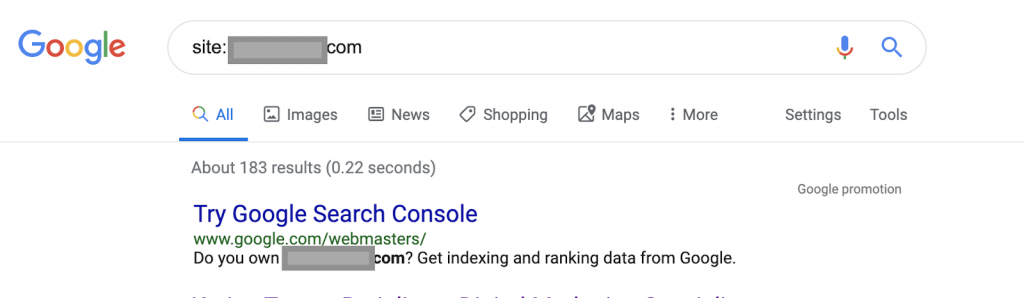
Kueri akan mengembalikan 183 halaman yang diindeks oleh Google. Ini adalah perkiraan kasar dari jumlah halaman yang telah diindeks oleh Google. Anda dapat memeriksa Google Search Console untuk jumlah pastinya.
Anda juga harus menggunakan perayap web seperti OnCrawl untuk mendaftar semua halaman yang dapat diakses oleh Google. Ini menunjukkan nomor yang berbeda seperti yang Anda lihat di bawah ini:
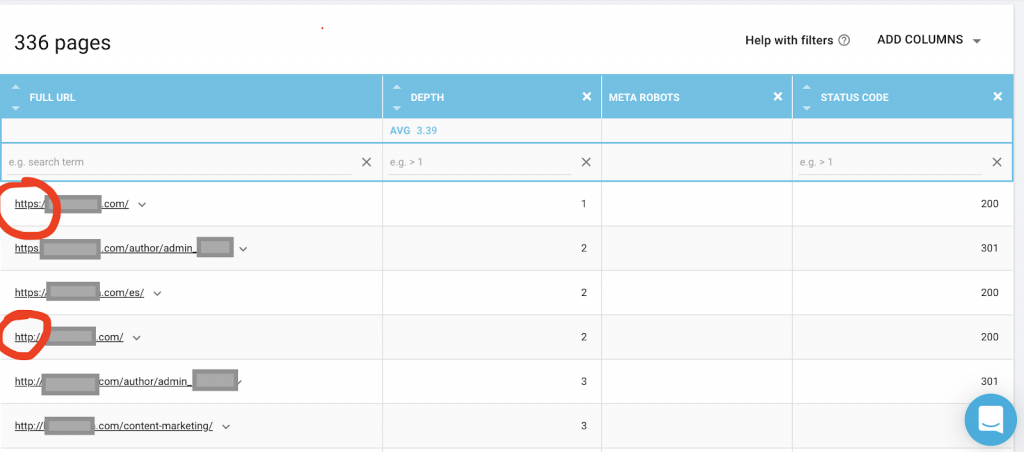
Situs web ini memiliki hampir dua kali lebih banyak halaman yang dapat dirayapi seperti halnya halaman yang diindeks.
Ini mungkin mengungkapkan masalah konten duplikat atau bahkan masalah versi keamanan situs web antara masalah HTTP dan HTTPS. Saya akan membicarakannya nanti di artikel ini.
Dalam hal ini, situs web dimigrasikan dari HTTP ke HTTPS. Kita dapat melihat di OnCrawl bahwa halaman HTTP telah dialihkan. Versi HTTP dan HTTPS masih dapat diakses oleh Googlebot, dan mungkin merayapi semua laman duplikat, alih-alih memprioritaskan laman terpenting yang ingin diberi peringkat oleh pemilik, yang menyebabkan pemborosan anggaran perayapan.
Masalah umum lainnya di antara situs web yang diabaikan atau situs web besar seperti situs e-niaga adalah masalah konten campuran. Singkatnya, masalah muncul ketika halaman aman Anda memiliki sumber daya seperti file media (paling sering: gambar) dimuat dari versi tidak aman.
Bagaimana memperbaikinya:
Anda dapat meminta pengembang web untuk memaksa semua halaman HTTP ke versi HTTPS, dan mengalihkan alamat HTTP ke HTTPS sekali menggunakan kode status 301.
Untuk masalah konten campuran, Anda dapat secara manual memeriksa sumber halaman dan mencari sumber daya yang dimuat sebagai “src=http://example.com/media/images” yang hampir gila untuk melakukannya terutama untuk situs web besar. Itu sebabnya kita perlu menggunakan alat SEO teknis.
2) File Robots.txt:
File robots.txt memberi tahu agen perayapan halaman apa yang tidak boleh dirayapi. Panduan spesifikasi robots.txt menunjukkan bahwa format file harus berupa teks biasa dengan ukuran maksimum 500KB.
Saya akan merekomendasikan menambahkan peta situs ke robots.txt.file. Tidak semua orang melakukan ini, tetapi saya percaya ini adalah praktik yang baik. File robots.txt harus ditempatkan di server host Anda di public_html dan mengikuti domain root.
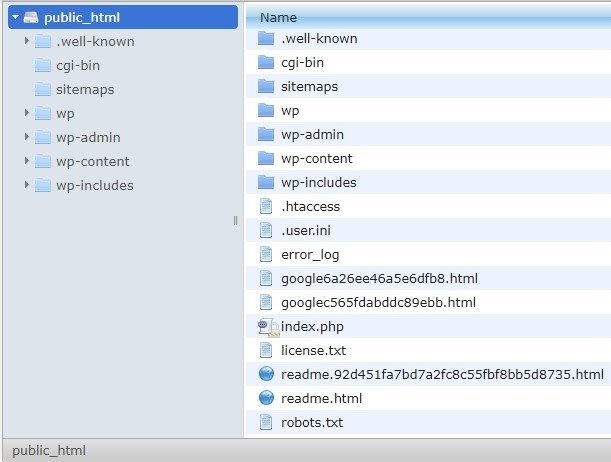
Kita dapat menggunakan arahan dalam file robots.txt untuk mencegah mesin pencari merayapi halaman yang tidak perlu atau halaman dengan informasi sensitif, seperti halaman admin, template atau keranjang belanja (/cart, /checkout, /login, folder seperti /tag yang digunakan di blog) , dengan menambahkan halaman ini pada file robots.txt.
Saran : Pastikan Anda tidak memblokir folder file media karena ini akan mengecualikan gambar, video, atau media lain yang di-hosting sendiri agar tidak diindeks. Media dapat menjadi sangat penting untuk relevansi halaman serta untuk peringkat organik dan lalu lintas untuk gambar atau video.
3) tag Meta Robot
Ini adalah bagian dari kode HTML yang menginstruksikan mesin pencari apakah akan merayapi dan mengindeks halaman, dengan semua tautan di dalam halaman itu. Tag HTML berada di bagian atas halaman web Anda. Ada 4 tag HTML umum untuk robot:
- Tidak mengikuti
- Mengikuti
- Indeks
- Tidak ada indeks
Ketika tidak ada tag meta robot, mesin pencari akan mengikuti dan mengindeks konten secara default.
Anda dapat menggunakan kombinasi apa pun yang paling sesuai dengan kebutuhan Anda. Misalnya, dengan menggunakan OnCrawl saya menemukan bahwa "halaman penulis" dari situs web ini tidak memiliki robot meta. Ini berarti bahwa secara default arahnya adalah ("ikuti, indeks")
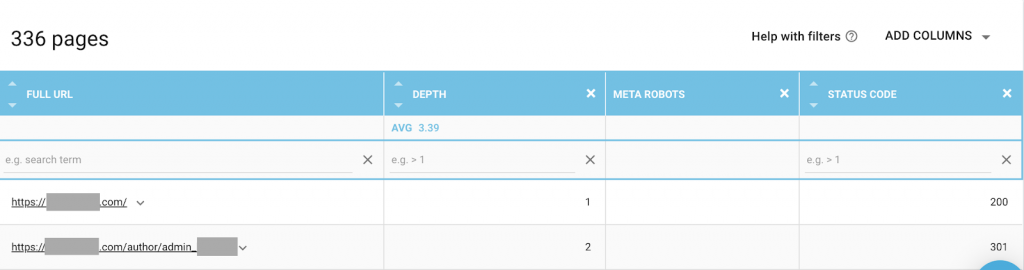
Ini seharusnya (“noindex, nofollow”).
Mengapa?
Setiap kasus berbeda, tetapi situs web ini adalah blog pribadi kecil. Hanya ada satu penulis yang mempublikasikan di blog, dan domainnya adalah nama penulis. Dalam hal ini, halaman "penulis" tidak memberikan informasi tambahan meskipun dibuat oleh platform blogging.
Skenario lain dapat berupa situs web di mana kategori di blog penting. Ketika pemilik ingin menentukan peringkat untuk kategori di blognya, maka robot meta harus (“ikuti, indeks”) atau default pada halaman kategori.
Dalam skenario yang berbeda, untuk situs web besar dan terkenal di mana pakar SEO utama menulis artikel yang diikuti oleh komunitas, nama penulis di Google bertindak sebagai merek. Dalam hal ini Anda mungkin ingin mengindeks beberapa nama penulis.
Seperti yang Anda lihat, robot meta dapat digunakan dengan berbagai cara.
Bagaimana memperbaikinya:
Minta pengembang web untuk mengubah tag robot meta sesuai kebutuhan. Dalam kasus di atas untuk situs web kecil, saya dapat melakukannya sendiri dengan membuka setiap halaman dan mengubahnya secara manual. Jika Anda menggunakan WordPress, Anda dapat mengubahnya dari pengaturan RankMath atau Yoast.
4) kesalahan 4xx:
Ini adalah kesalahan di sisi klien, dan bisa berupa 401, 403, dan 404.
- 404 halaman tidak ditemukan:
Kesalahan ini terjadi ketika halaman tidak tersedia di alamat URL yang diindeks. Itu bisa saja dipindahkan atau dihapus, dan alamat lama belum dialihkan dengan benar menggunakan fungsi server web 301. Kesalahan 404 adalah pengalaman buruk bagi pengguna dan merupakan masalah teknis SEO yang harus diatasi. Adalah hal yang baik untuk sering memeriksa 404 dan memperbaikinya, dan tidak membiarkannya dicoba lagi dan lagi karena agen perayapan membuang-buang anggaran mereka.
Bagaimana memperbaikinya:
Kita perlu menemukan alamat yang mengembalikan 404 dan memperbaikinya menggunakan pengalihan 301 jika konten masih ada. Atau, jika berupa gambar, dapat diganti dengan yang baru dengan nama file yang sama.
- 401 Tidak Sah
Ini adalah masalah izin. Kesalahan 401 biasanya terjadi ketika otentikasi diperlukan seperti nama pengguna dan kata sandi.
Bagaimana memperbaikinya:
Berikut adalah dua opsi: Yang pertama adalah memblokir halaman dari mesin pencari menggunakan robots.txt. Opsi kedua adalah menghapus persyaratan otentikasi.
- 403 Dilarang
Kesalahan ini mirip dengan kesalahan 401. Kesalahan 403 terjadi karena halaman tersebut memiliki tautan yang tidak dapat diakses oleh publik.

Bagaimana memperbaikinya:
Ubah persyaratan di server untuk mengizinkan akses ke halaman (hanya jika ini adalah kesalahan). Jika Anda ingin halaman ini tidak dapat diakses, hapus semua tautan internal dan eksternal dari halaman.
- 400 permintaan Buruk
Ini terjadi ketika browser tidak dapat berkomunikasi dengan server web. Kesalahan ini biasanya terjadi untuk sintaks URL yang buruk.
Bagaimana memperbaikinya:
Temukan tautan ke URL ini dan perbaiki sintaksnya. Jika ini tidak dapat diperbaiki, Anda perlu menghubungi pengembang web untuk memperbaikinya.
Catatan: Kami dapat menemukan 400 kesalahan dengan alat atau di Google Console

5) Peta Situs
Peta situs adalah daftar semua URL yang berisi situs web. Memiliki peta situs meningkatkan kemampuan untuk ditemukan karena membantu perayap menemukan dan memahami konten Anda.
Kami memiliki berbagai jenis peta situs dan kami perlu memastikan semuanya dalam kondisi baik.
Sitemap yang harus kita miliki adalah:
- Peta situs HTML: Ini akan ada di situs web Anda dan akan membantu pengguna menavigasi dan menemukan halaman di situs web Anda
- Peta situs XML: Ini adalah file yang akan membantu mesin telusur merayapi situs web Anda (sebagai praktik terbaik, file ini harus disertakan dalam file robots.txt Anda).
- Peta situs XML video: Sama seperti di atas.
- Gambar peta situs XML: Ini juga sama seperti di atas. Disarankan untuk membuat peta situs terpisah untuk gambar, video, dan konten.
Untuk situs web besar, disarankan untuk memiliki beberapa peta situs untuk perayapan yang lebih baik karena peta situs tidak boleh berisi lebih dari 50.000 URL.
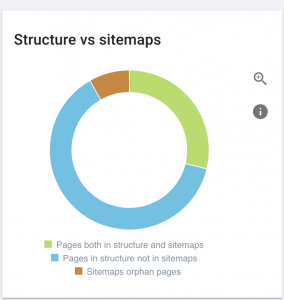
Situs web ini memiliki masalah peta situs.
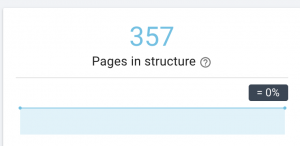
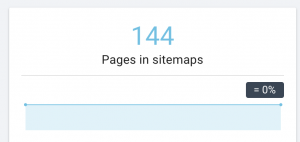
Bagaimana kami memperbaikinya:
Kami memperbaikinya dengan membuat peta situs yang berbeda untuk: konten, gambar, dan video. Kemudian, kami mengirimkannya melalui Google Search Console dan juga membuat peta situs HTML untuk situs web. Kami tidak membutuhkan pengembang web untuk ini. Kita dapat menggunakan alat online gratis untuk menghasilkan peta situs.
6) HTTP/HTTPS (konten duplikat)
Banyak situs web mengalami masalah ini sebagai akibat dari migrasi dari HTTP ke HTTPS. Jika demikian, situs web akan menampilkan versi HTTP dan HTTPS di mesin telusur. Sebagai konsekuensi dari masalah teknis umum ini, peringkat diencerkan. Masalah ini juga menghasilkan masalah duplikat konten.
![]()

Bagaimana memperbaikinya:
Minta pengembang web untuk memperbaiki masalah ini dengan memaksa semua HTTP ke HTTPS.
Catatan : Jangan pernah mengarahkan ulang semua HTTP ke halaman beranda HTTPS karena akan menghasilkan kesalahan 404 lunak. (Anda harus mengatakan ini kepada pengembang web; ingat mereka bukan SEO.)
7) paginasi
Ini adalah penggunaan tag HTML (“rel = prev” dan “rel = next”) yang membangun hubungan antar halaman, dan ini menunjukkan kepada mesin pencari bahwa konten yang disajikan di halaman yang berbeda harus diidentifikasi atau terkait dengan satu halaman. Pagination digunakan untuk membatasi konten untuk UX dan berat halaman untuk bagian teknis, menjaganya di bawah 3MB. Kita dapat menggunakan alat gratis untuk memeriksa pagination.
Pagination harus memiliki referensi kanonik mandiri dan menunjukkan "rel = prev" dan "rel = next". Satu-satunya informasi duplikat adalah judul meta dan deskripsi meta, tetapi ini dapat diubah oleh pengembang untuk membuat algoritme kecil sehingga setiap halaman akan memiliki judul meta dan deskripsi meta yang dihasilkan.
Bagaimana memperbaikinya:
Minta pengembang web untuk menerapkan tag HTML pagination dengan tag self-canonical.
Perayap SEO Oncrawl
 Decouvrir
Decouvrir8) Halaman Kustom 404 Tidak Ditemukan
Respons 404 seperti yang telah kita bahas sebelumnya adalah kesalahan “ Tidak Ditemukan ” yang membawa pengguna ke tautan rusak atau halaman yang tidak ada. Ini adalah kesempatan untuk mengarahkan pengguna ke tempat yang tepat. Ada banyak contoh halaman 404 khusus. Ini harus dimiliki.
Berikut adalah contoh halaman kustom 404 yang bagus:

Bagaimana memperbaikinya:
Buat halaman 404 khusus: pikirkan sesuatu yang luar biasa untuk ditambahkan ke dalamnya. Jadikan kesalahan ini sebagai peluang bisnis Anda.
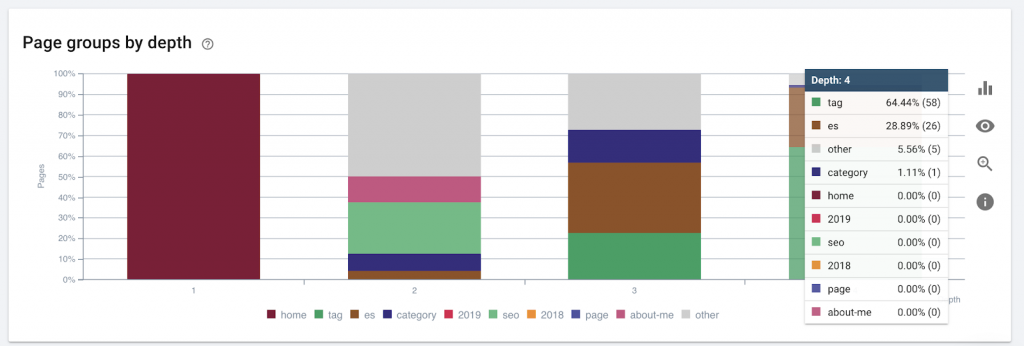
9) Kedalaman / struktur situs
Kedalaman halaman adalah jumlah klik di mana halaman Anda berada dari domain root. John Mueller dari Google mengatakan "halaman yang lebih dekat ke halaman beranda memiliki bobot lebih". Sebagai contoh, mari kita bayangkan bahwa halaman di sini memerlukan navigasi berikut untuk dapat dijangkau:

Halaman "karpet" berjarak 4 klik dari halaman beranda. Disarankan untuk tidak memiliki halaman yang terletak lebih dari 4 klik dari beranda, karena mesin pencari kesulitan merayapi halaman yang lebih dalam.
Grafik ini menunjukkan grup halaman berdasarkan kedalaman. Ini membantu kita untuk memahami jika struktur situs web perlu dikerjakan ulang.
Bagaimana memperbaikinya:
Halaman yang paling penting harus paling dekat dengan beranda untuk UX, agar mudah diakses oleh pengguna dan untuk struktur situs web yang lebih baik. Sangat penting untuk mempertimbangkan hal ini pada saat membuat struktur situs web atau merestrukturisasi situs web.
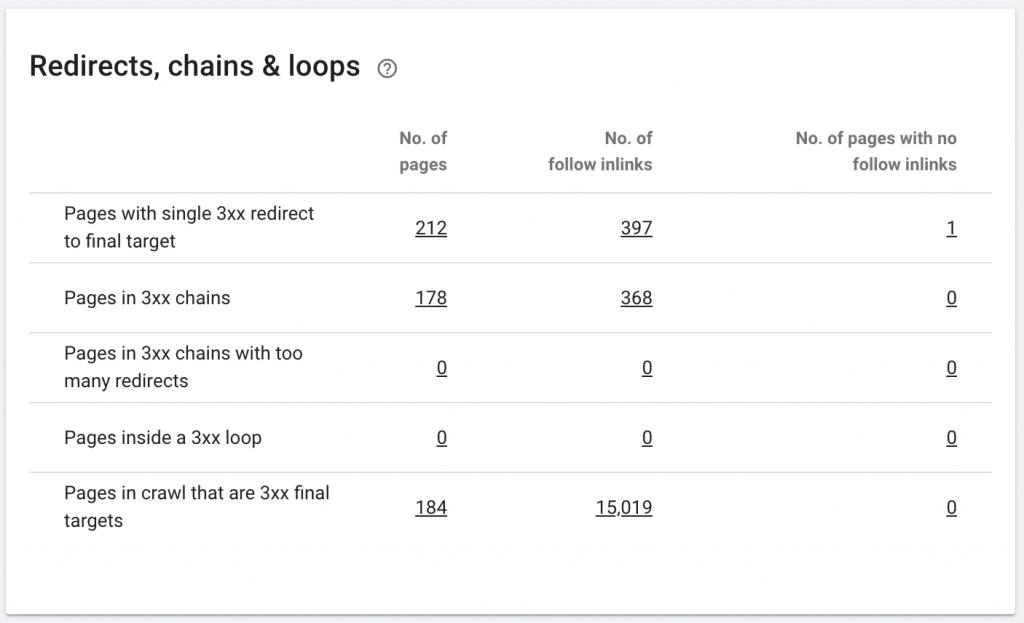
10. Redirect Rantai
Rantai pengalihan adalah ketika serangkaian pengalihan terjadi di antara URL. Rantai pengalihan ini juga dapat membuat loop. Ini juga menimbulkan masalah bagi Googlebot dan menghabiskan anggaran perayapan.
Kami dapat mengidentifikasi rantai pengalihan dengan menggunakan jalur Pengalihan ekstensi Chrome, atau di OnCrawl.
Bagaimana memperbaikinya:
Memperbaiki ini sangat mudah jika Anda bekerja dengan situs web WordPress. Pergi saja ke pengalihan dan cari rantai- hapus semua tautan yang terlibat dalam rantai jika perubahan itu terjadi lebih dari 2-3 bulan yang lalu dan biarkan pengalihan terakhir ke URL saat ini. Pengembang web juga dapat membantu dengan membuat semua perubahan yang diperlukan dalam file .htacces, jika diperlukan. Anda dapat memeriksa dan mengubah rantai pengalihan panjang di plugin SEO Anda.
11) Canonicals
Sebuah tag kanonik memberitahu mesin pencari bahwa URL adalah salinan dari halaman lain. Ini adalah masalah besar yang ada di banyak situs web. Tidak menerapkan kanonik dengan cara yang benar, atau menerapkannya sama sekali, akan menimbulkan masalah konten duplikat.
Canonicals biasanya digunakan di situs web e-niaga di mana suatu produk dapat ditemukan beberapa kali dalam berbagai kategori seperti: ukuran, warna, dll.

Anda dapat menggunakan OnCrawl untuk mengetahui apakah halaman Anda memiliki tag kanonik, dan apakah tag tersebut diterapkan dengan benar atau tidak. Anda kemudian dapat menjelajahi dan memperbaiki masalah apa pun.
Bagaimana kami memperbaikinya:
Kami dapat memperbaiki masalah kanonik dengan menggunakan Yoast SEO jika kami bekerja di WordPress. Kami pergi ke dashboard WordPress dan kemudian ke Yoast -setting – lanjutan.
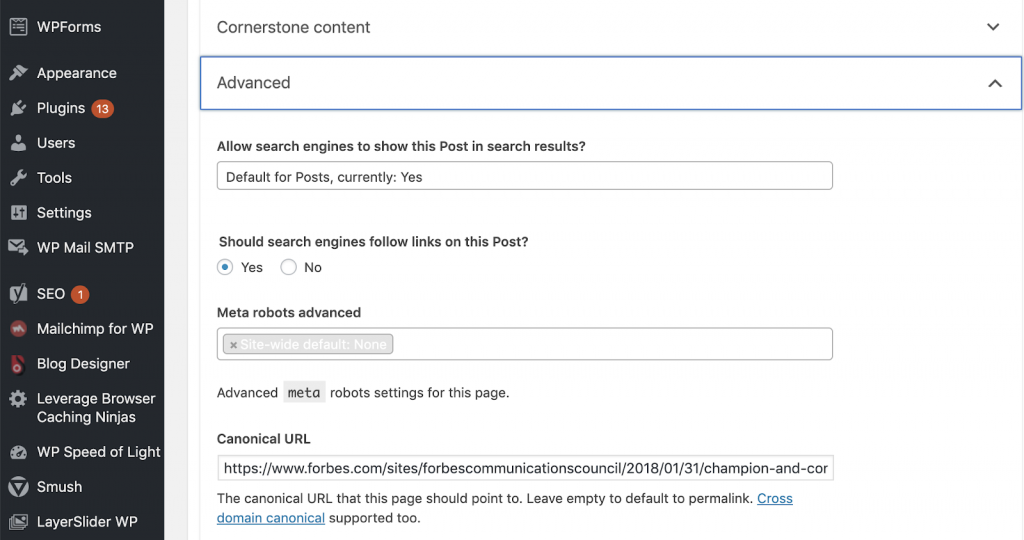
Menjalankan audit Anda sendiri
SEO yang ingin mulai menyelami SEO teknis memerlukan panduan langkah cepat yang harus diikuti untuk meningkatkan kesehatan SEO. Berbicara tentang SEO Teknis dengan John Shehata, Wakil Presiden Pertumbuhan Pemirsa di Conde Nast dan pendiri NewzDash pada Hari Pemasaran Global di NYC pada Oktober 2019 lalu.
Inilah yang dia katakan kepada saya:
“Banyak orang di industri SEO tidak teknis. Sekarang, tidak semua SEO mengerti cara membuat kode dan sulit untuk meminta orang melakukan ini. Beberapa perusahaan, yang mereka lakukan adalah merekrut pengembang dan melatih mereka menjadi SEO untuk memenuhi kesenjangan teknis SEO.”
Menurut pendapat saya, SEO yang tidak memiliki pengetahuan kode penuh masih bisa melakukan yang terbaik di Tech SEO dengan mengetahui cara menjalankan audit, mengidentifikasi elemen kunci, melaporkan, meminta pengembang web untuk implementasi, dan akhirnya menguji perubahannya.
Siap untuk memulai? Unduh daftar periksa untuk masalah teratas ini.
