
Mengevaluasi Kualitas Prediksi Dampak Kausal
Diterbitkan: 2022-02-15CausalImpact adalah salah satu paket paling populer yang digunakan dalam eksperimen SEO. Popularitasnya bisa dimengerti.
Eksperimen SEO memberikan wawasan dan cara menarik bagi SEO untuk melaporkan nilai pekerjaan mereka.
Namun, keakuratan model pembelajaran mesin apa pun bergantung pada informasi input yang diberikan.
Sederhananya, input yang salah dapat mengembalikan estimasi yang salah.
Dalam posting ini, kami akan menunjukkan seberapa andal (dan tidak dapat diandalkan) CausalImpact. Kami juga akan belajar bagaimana menjadi lebih percaya diri dengan hasil eksperimen Anda.
Pertama, kami akan memberikan gambaran singkat tentang cara kerja CausalImpact. Kemudian, kita akan membahas keandalan estimasi CausalImpact. Terakhir, kita akan belajar tentang metodologi yang dapat digunakan untuk memperkirakan hasil eksperimen SEO Anda sendiri.
Apa Itu CausalImpact Dan Bagaimana Cara Kerjanya?
CausalImpact adalah paket yang menggunakan statistik Bayesian untuk memperkirakan efek suatu peristiwa tanpa adanya eksperimen. Estimasi ini disebut inferensi kausal.
Inferensi kausal memperkirakan jika perubahan yang diamati disebabkan oleh peristiwa tertentu.
Ini sering digunakan untuk mengevaluasi kinerja eksperimen SEO.
Misalnya, ketika diberi tanggal suatu peristiwa, CausalImpact (CI) akan menggunakan titik data sebelum intervensi untuk memprediksi titik data setelah intervensi. Kemudian akan membandingkan prediksi dengan data yang diamati dan memperkirakan perbedaannya dengan ambang kepercayaan tertentu.
Selanjutnya, kelompok kontrol dapat digunakan untuk membuat prediksi lebih akurat.
Parameter yang berbeda juga akan berdampak pada keakuratan prediksi:
- Ukuran data uji.
- Lamanya periode sebelum percobaan.
- Pilihan kelompok kontrol untuk dibandingkan.
- Hyperparameter musiman.
- Jumlah iterasi.
Semua parameter ini membantu memberikan lebih banyak konteks pada model dan meningkatkan keandalannya.
Perayapan BI
 Menemukan
MenemukanMengapa Mengevaluasi Akurasi Eksperimen SEO Penting?
Dalam beberapa tahun terakhir, saya telah menganalisis banyak eksperimen SEO dan sesuatu mengejutkan saya.
Sering kali, menggunakan kelompok kontrol dan kerangka waktu yang berbeda pada set tes yang identik dan tanggal intervensi menghasilkan hasil yang berbeda.
Sebagai ilustrasi, di bawah ini adalah dua hasil dari peristiwa yang sama.
Yang pertama mengembalikan penurunan yang signifikan secara statistik. 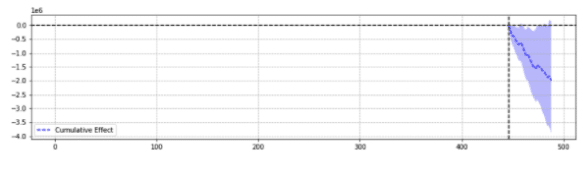
Yang kedua tidak signifikan secara statistik. 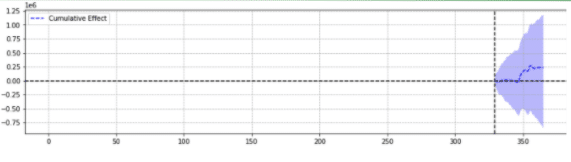
Sederhananya, untuk acara yang sama, hasil yang berbeda dikembalikan berdasarkan parameter yang dipilih.
Kita harus bertanya-tanya prediksi mana yang akurat.
Pada akhirnya, bukankah “signifikan secara statistik” seharusnya meningkatkan kepercayaan pada estimasi kita?
definisi
Untuk lebih memahami dunia eksperimen SEO, pembaca harus mengetahui konsep dasar eksperimen SEO:
- Eksperimen : suatu prosedur yang dilakukan untuk menguji suatu hipotesis. Dalam kasus inferensi kausal, ia memiliki tanggal mulai yang spesifik.
- Test group : subset dari data yang perubahannya diterapkan. Ini bisa berupa seluruh situs web atau sebagian dari situs.
- Grup kontrol : subset data yang tidak ada perubahan yang diterapkan. Anda dapat memiliki satu atau beberapa grup kontrol. Ini bisa menjadi situs terpisah di industri yang sama atau bagian berbeda dari situs yang sama.
Contoh di bawah ini akan membantu mengilustrasikan konsep-konsep ini:
Memodifikasi judul (eksperimen) akan meningkatkan RKT organik sebesar 1% (hipotesis) dari halaman produk di lima kota (grup uji). Estimasi akan ditingkatkan menggunakan judul yang tidak berubah di semua kota lain (kelompok kontrol).
Pilar Prediksi Eksperimen SEO yang Akurat
- Untuk mempermudah, saya telah mengumpulkan beberapa wawasan menarik bagi para profesional SEO yang mempelajari cara meningkatkan akurasi eksperimen:
- Beberapa masukan di CausalImpact akan mengembalikan estimasi yang salah, bahkan jika signifikan secara statistik. Inilah yang kami sebut "positif palsu" dan "negatif palsu".
- Tidak ada aturan umum yang mengatur kontrol mana yang digunakan terhadap set tes. Eksperimen diperlukan untuk menentukan data kontrol terbaik yang akan digunakan untuk set pengujian tertentu.
- Menggunakan CausalImpact dengan kontrol yang tepat dan panjang yang tepat dari data pra-periode bisa sangat tepat, dengan kesalahan rata-rata serendah 0,1%.
- Atau, menggunakan CausalImpact dengan kontrol yang salah dapat menyebabkan tingkat kesalahan yang kuat. Eksperimen pribadi menunjukkan variasi yang signifikan secara statistik hingga 20%, padahal sebenarnya tidak ada perubahan.
- Tidak semuanya bisa diuji. Beberapa kelompok uji hampir tidak pernah mengembalikan estimasi yang akurat.
- Eksperimen dengan atau tanpa kelompok kontrol membutuhkan panjang data yang berbeda sebelum intervensi.
Tidak Semua Grup Tes Akan Mengembalikan Estimasi yang Akurat
Beberapa grup uji akan selalu mengembalikan prediksi yang tidak akurat. Mereka tidak boleh digunakan untuk eksperimen.
Kelompok uji dengan variasi lalu lintas abnormal yang besar sering kali memberikan hasil yang tidak dapat diandalkan.
Misalnya, pada tahun yang sama sebuah situs web mengalami migrasi situs, terkena dampak pandemi covid, dan sebagian situs "tidak diindeks" selama 2 minggu karena kesalahan teknis. Melakukan eksperimen di situs itu akan memberikan hasil yang tidak dapat diandalkan.
Kesimpulan di atas dikumpulkan melalui serangkaian tes ekstensif yang dibuat menggunakan metodologi yang dijelaskan di bawah ini.
Saat Tidak Menggunakan Grup Kontrol
- Menggunakan kontrol alih-alih pra-posting sederhana dapat meningkatkan hingga 18 kali ketepatan estimasi.
- Menggunakan data 16 bulan sebelumnya sama akuratnya dengan menggunakan 3 tahun.
Saat Menggunakan Grup Kontrol
- Menggunakan kontrol yang tepat seringkali lebih baik daripada menggunakan beberapa kontrol. Namun, satu kontrol meningkatkan risiko prediksi yang salah dalam kasus di mana lalu lintas kontrol sangat bervariasi.
- Memilih kontrol yang tepat dapat meningkatkan presisi hingga 10 kali lipat (misalnya, satu melaporkan +3,1% dan yang lainnya +4,1% padahal sebenarnya +3%).
- Sebagian besar pola lalu lintas yang berkorelasi antara data uji dan data kontrol tidak selalu berarti estimasi yang lebih baik.
- Menggunakan data 16 bulan sebelumnya TIDAK seakurat menggunakan 3 tahun.
Waspadalah Terhadap Panjang Data Sebelum Eksperimen
Menariknya, ketika bereksperimen dengan kelompok kontrol, menggunakan data 16 bulan sebelumnya dapat menyebabkan tingkat kesalahan yang sangat tinggi.
Faktanya, kesalahan bisa sebesar memperkirakan peningkatan lalu lintas 3x ketika tidak ada perubahan yang sebenarnya.
Namun, menggunakan data 3 tahun menghapus tingkat kesalahan itu. Hal ini berbeda dengan eksperimen pra-pasca sederhana di mana tingkat kesalahan itu tidak meningkat dengan menambah panjang dari 16 menjadi 36 bulan.
Itu tidak berarti bahwa menggunakan kontrol itu buruk. Ini justru sebaliknya.
Ini hanya menunjukkan bagaimana menambahkan kontrol memengaruhi prediksi.

Ini adalah kasus ketika ada variasi besar dalam kelompok kontrol.
Takeaway ini sangat penting untuk situs web yang memiliki variasi lalu lintas abnormal dalam setahun terakhir (kesalahan teknis kritis, pandemi COVID, dll.).
Bagaimana Mengevaluasi Prediksi CausalImpact?
Sekarang, tidak ada skor akurasi yang dibangun di pustaka CausalImpact. Jadi, harus disimpulkan sebaliknya.
Seseorang dapat melihat bagaimana model pembelajaran mesin lain memperkirakan keakuratan prediksi mereka dan menyadari bahwa Jumlah Kesalahan Kuadrat (SSE) adalah metrik yang sangat umum.
Jumlah kesalahan kuadrat, atau jumlah sisa kuadrat, menghitung jumlah semua (n) perbedaan antara harapan (yi) dan hasil aktual (f(xi)), kuadrat. 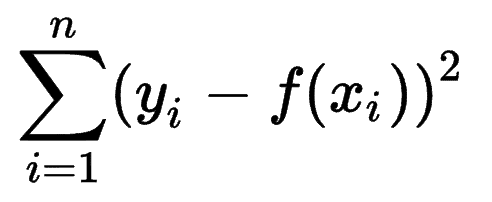
Semakin rendah SSE, semakin baik hasilnya.
Tantangannya adalah bahwa dengan eksperimen pra-posting pada lalu lintas SEO, tidak ada hasil yang sebenarnya.
Meskipun tidak ada perubahan yang dilakukan di tempat, beberapa perubahan mungkin terjadi di luar kendali Anda (misalnya, pembaruan Algoritma Google, pesaing baru, dll.). Lalu lintas SEO juga tidak bervariasi berdasarkan angka tetap tetapi bervariasi secara progresif naik dan turun.
Pakar SEO mungkin bertanya-tanya bagaimana cara mengatasi tantangan tersebut.
Memperkenalkan Variasi Palsu
Untuk memastikan ukuran variasi yang disebabkan oleh suatu peristiwa, eksperimen dapat memperkenalkan variasi tetap pada titik waktu yang berbeda, dan melihat apakah CausalImpact berhasil memperkirakan perubahan tersebut.
Bahkan lebih baik lagi, pakar SEO dapat mengulangi proses untuk kelompok pengujian dan kontrol yang berbeda.
Menggunakan Python, variasi tetap diperkenalkan ke data pada tanggal intervensi yang berbeda untuk periode pasca.
Jumlah kesalahan kuadrat kemudian diperkirakan antara variasi yang dilaporkan oleh CausalImpact dan variasi yang diperkenalkan.
Idenya seperti ini:
- Pilih data uji dan kontrol.
- Perkenalkan intervensi palsu dalam data nyata pada tanggal yang berbeda (misalnya, peningkatan 5%).
- Bandingkan estimasi CausalImpact dengan masing-masing variasi yang diperkenalkan.
- Hitung Jumlah Kesalahan Kuadrat (SSE).
- Ulangi langkah 1 dengan beberapa kontrol.
- Pilih kontrol dengan SSE terkecil untuk eksperimen dunia nyata
Metodologi
Dengan metodologi di bawah ini, saya membuat tabel yang dapat saya gunakan untuk mengidentifikasi kontrol mana yang memiliki tingkat kesalahan terbaik dan terburuk pada titik waktu yang berbeda.
Pertama, pilih data uji dan kontrol dan perkenalkan variasi dari -50% hingga 50%.
Kemudian, jalankan CausalImpact (CI) dan kurangi variasi yang dilaporkan oleh CI dengan variasi yang sebenarnya Anda perkenalkan.
Setelah itu, hitung kuadrat dari perbedaan ini dan jumlahkan semua nilainya.
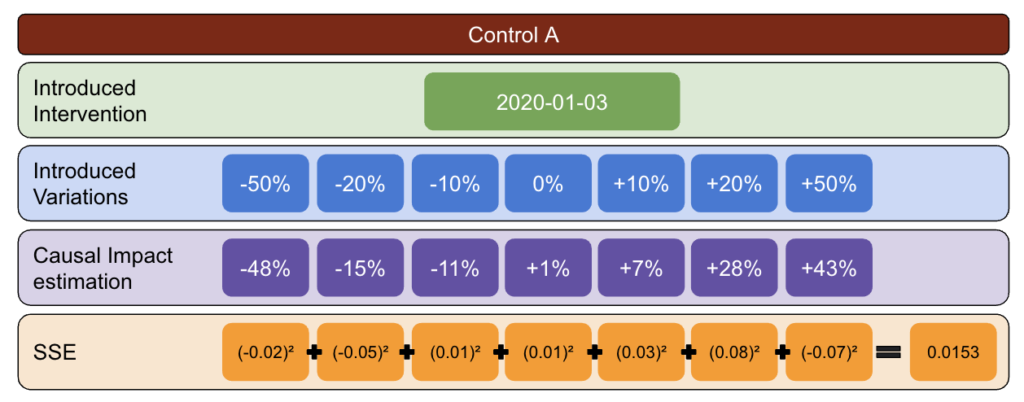
Selanjutnya, ulangi proses yang sama pada tanggal yang berbeda untuk mengurangi risiko bias yang disebabkan oleh variasi nyata pada tanggal tertentu.
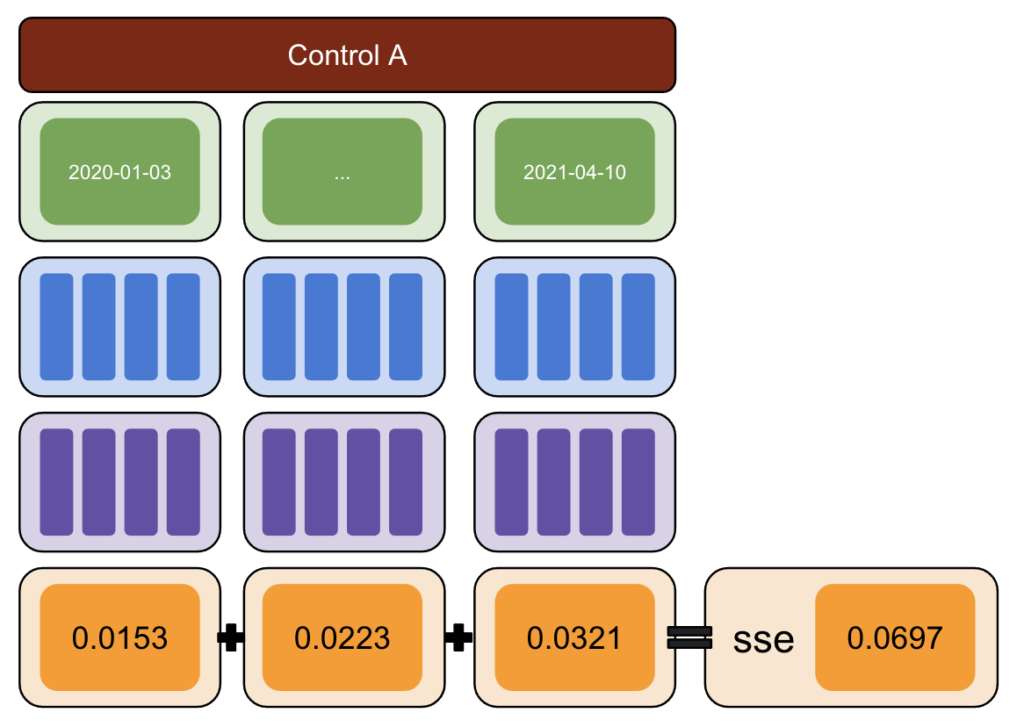
Sekali lagi, ulangi dengan beberapa grup kontrol.
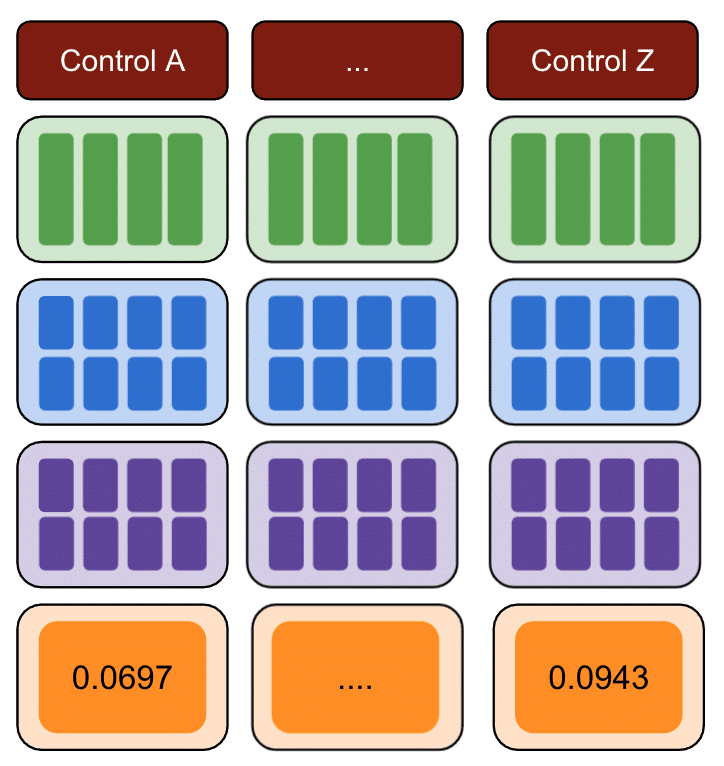
Terakhir, kontrol dengan jumlah kesalahan kuadrat terkecil adalah grup kontrol terbaik yang digunakan untuk data pengujian Anda.
Jika Anda mengulangi setiap langkah untuk setiap data pengujian, hasilnya akan bervariasi.
Pada tabel yang dihasilkan, setiap baris mewakili grup kontrol, setiap kolom mewakili grup uji. Data di dalamnya adalah SSE.
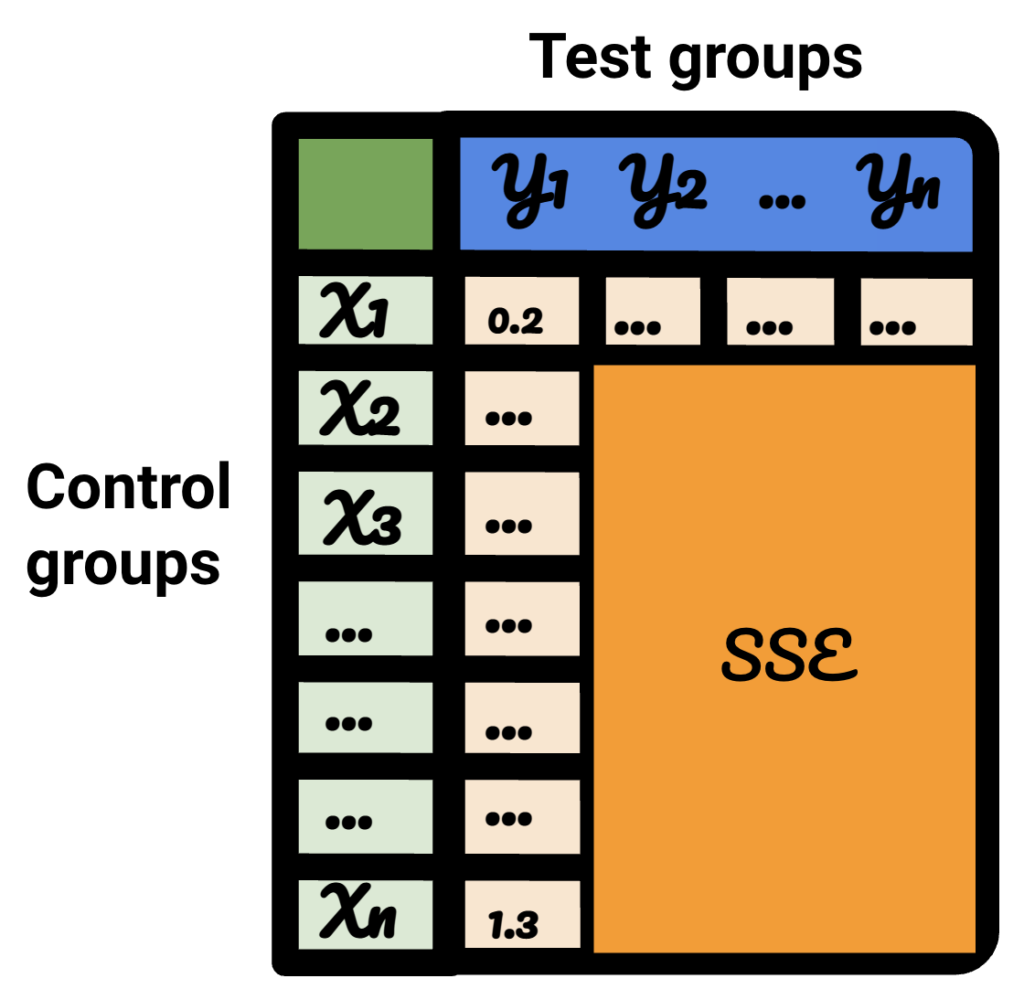
Menyortir tabel itu, saya sekarang yakin bahwa, untuk setiap grup uji, saya dapat memilih grup kontrol terbaik untuknya.
Haruskah Kita Menggunakan Grup Kontrol Atau Tidak?
Bukti menunjukkan bahwa menggunakan kelompok kontrol membantu untuk memiliki estimasi yang lebih baik daripada pra-posting sederhana.
Namun, ini benar hanya jika kita memilih grup kontrol yang tepat.
Berapa Lama Seharusnya Periode Estimasi?
Jawabannya tergantung pada kontrol yang kita pilih.
Bila tidak menggunakan kontrol, percobaan 16 bulan sebelumnya tampaknya cukup.
Saat menggunakan kontrol, hanya menggunakan 16 bulan dapat menyebabkan tingkat kesalahan besar. Menggunakan 3 tahun membantu mengurangi risiko salah tafsir.
Haruskah Kita Menggunakan 1 Kontrol Atau Beberapa Kontrol?
Jawaban atas pertanyaan itu tergantung pada data uji.
Data uji yang sangat stabil dapat bekerja dengan baik jika dibandingkan dengan beberapa kontrol. Dalam hal ini, ini bagus karena menggunakan banyak kontrol membuat model tidak terlalu terpengaruh oleh fluktuasi yang tidak terduga di salah satu kontrol.
Pada kumpulan data lain, menggunakan beberapa kontrol dapat membuat model 10-20 kali lebih akurat daripada menggunakan satu kontrol.
Pekerjaan Menarik Di Komunitas SEO
CausalImpact bukan satu-satunya library yang dapat digunakan untuk pengujian SEO, juga bukan metodologi di atas satu-satunya solusi untuk menguji akurasinya.
Untuk mempelajari solusi alternatif, baca beberapa artikel luar biasa yang dibagikan oleh orang-orang di komunitas SEO.
Pertama, Andrea Volpini menulis artikel menarik tentang mengukur efektivitas SEO menggunakan Analisis CausalImpact.
Kemudian, Daniel Heredia telah membahas paket Nabi Facebook untuk meramalkan lalu lintas SEO dengan Nabi dan Python.
Sementara perpustakaan Nabi lebih tepat untuk peramalan daripada untuk eksperimen, ada baiknya mempelajari berbagai perpustakaan untuk mendapatkan pemahaman yang kuat tentang dunia prediksi.
Akhirnya, saya sangat senang dengan presentasi Sandy Lee di Brighton SEO di mana dia berbagi wawasan Ilmu Data untuk Pengujian SEO dan mengangkat beberapa jebakan pengujian SEO.
Hal Yang Perlu Dipertimbangkan Saat Melakukan Eksperimen SEO
- Alat pengujian split SEO pihak ketiga sangat bagus tetapi bisa juga tidak akurat. Berhati-hatilah saat memilih solusi Anda.
- Meskipun saya pernah menulis tentangnya, Anda tidak dapat melakukan eksperimen pengujian terpisah SEO dengan Google Pengelola Tag, kecuali sisi server. Cara terbaik adalah menyebarkan melalui CDN.
- Berani saat menguji. Perubahan kecil biasanya tidak diambil oleh CausalImpact.
- Pengujian SEO tidak harus selalu menjadi pilihan pertama Anda.
- Ada alternatif untuk menguji perubahan yang lebih kecil seperti tag judul. Pengujian A/B Google Ads atau pengujian A/B di platform. Pengujian A/B yang sebenarnya lebih akurat daripada pengujian terpisah SEO dan biasanya memberikan lebih banyak wawasan tentang kualitas judul Anda.
Hasil yang Dapat Direproduksi
Dalam tutorial ini, saya ingin fokus pada bagaimana seseorang dapat meningkatkan akurasi eksperimen SEO tanpa beban untuk mengetahui cara membuat kode. Apalagi sumber datanya bisa berbeda-beda, dan setiap situs berbeda.
Oleh karena itu, kode Python yang saya gunakan untuk membuat konten ini bukan bagian dari cakupan artikel ini.
Namun, dengan logika, Anda dapat mereproduksi eksperimen di atas.
Kesimpulan
Jika Anda hanya memiliki satu takeaway untuk mendapatkan dari artikel ini, analisis CausalImpact bisa sangat akurat, tetapi selalu bisa jauh.
Sangat penting bagi SEO yang ingin menggunakan paket ini untuk memahami apa yang mereka hadapi. Hasil dari perjalanan saya sendiri adalah bahwa saya tidak akan mempercayai CausalImpact tanpa menguji keakuratan model pada data input terlebih dahulu.