
Cara mengotomatiskan pemodelan bauran pemasaran dengan spreadsheet umpan data MMM
Diterbitkan: 2022-06-16Pemodelan bauran pemasaran atau MMM melihat kebangkitan, lebih dari 60 tahun sejak mulai digunakan secara umum. Tidak seperti kebanyakan metode atribusi pemasaran, MMM tidak memerlukan data tingkat pengguna, alih-alih memodelkan saluran apa yang layak mendapatkan kredit untuk penjualan dengan memetakan lonjakan dan penurunan pembelanjaan secara statistik ke tindakan dan peristiwa di saluran pemasaran Anda. Meningkatkan dari regresi linier sederhana ke teknik seperti regresi punggungan atau metode Bayesian, pemodelan bauran pemasaran sedang diciptakan kembali untuk zaman modern.

Ingin tahu lebih banyak tentang MMM?
Baca pro dan kontra tentang pemodelan bauran pemasaran vs. pemodelan atribusi
Namun, ada rintangan besar yang harus diatasi. Membangun model dapat memakan waktu 3 hingga 6 bulan, menurut Meta/Facebook, yang telah mengerjakan perpustakaan MMM open-source sejak Oktober 2021. Menurut perkiraannya, sekitar 50% waktu dihabiskan untuk mengumpulkan dan membersihkan data sebelum pemodelan dimulai. . Ini sesuai dengan pengalaman saya di Recast—dan sebelumnya Harry—serta hasil studi CrowdFlower yang menemukan bahwa 60% waktu ilmu data dihabiskan untuk membersihkan dan mengatur data.
Maju cepat >>
- Pembersihan data
- Membangun model bauran pemasaran
- Pemodelan otomatis
Pembersihan data adalah 60% dari pekerjaan, dan bagaimana membuatnya 0%
Untuk membangun model yang akurat, Anda memerlukan data dalam format tertentu. Menyiapkan data memakan waktu lama, sehingga proyek MMM membutuhkan waktu lebih lama dari yang seharusnya. Hal ini membuat MMM menjadi keahlian khusus dan mahal, sehingga sebagian besar perusahaan hanya dapat membuat satu hingga dua model dalam setahun. Jika Anda dapat mengotomatiskan proses menggunakan alat seperti Supermetrics untuk membuat umpan data MMM, model Anda dapat diperbarui secara berkala, sehingga Anda dapat mengoptimalkan anggaran pemasaran dengan lebih baik.
Format data tabel
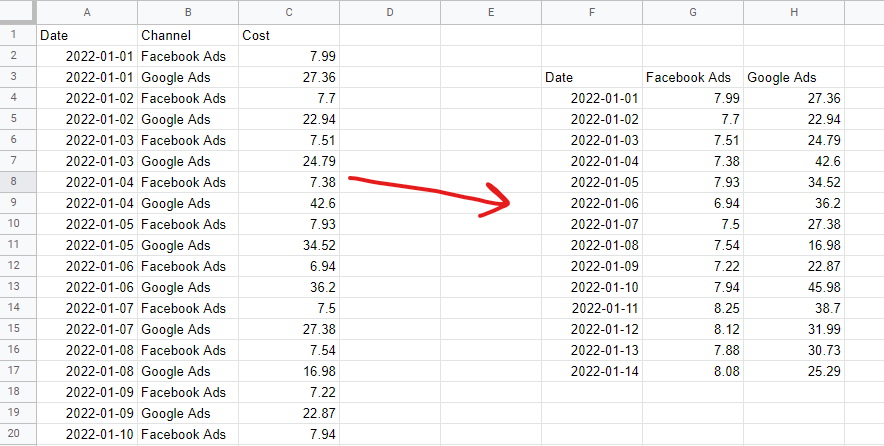
Untuk membangun model bauran pemasaran, Anda harus meletakkan data Anda dalam format tabel yang tidak ditumpuk. Ini berarti satu baris per pengamatan—biasanya berhari-hari atau berminggu-minggu—dan satu kolom per 'fitur' model—biasanya pengeluaran media dan variabel organik atau eksternal. Data kategoris—misalnya, daftar hari libur nasional—perlu dikodekan ke variabel dummy—1 saat hari libur itu, 0 saat tidak.
Sumber data yang digabungkan
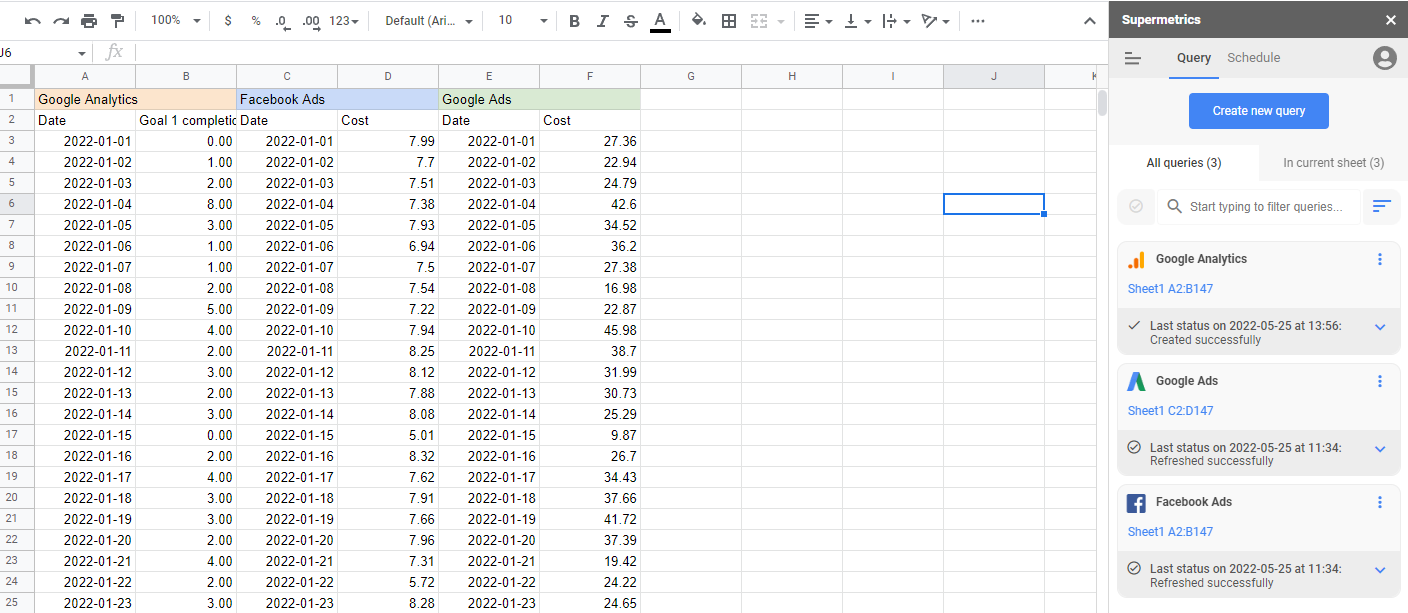
Untuk membangun model atribusi pemasaran, Anda harus memiliki semua data pemasaran di satu tempat. Inilah yang ditangani Supermetrics untuk Anda secara otomatis. Dengan lebih dari 90 konektor, semua pengeluaran pemasaran, acara, dan aktivitas Anda dapat digabungkan menjadi satu tempat, dimanipulasi sesuai kebutuhan, lalu diekspor ke format dan lokasi yang Anda butuhkan.
Mengekspor ke Google Spreadsheet
Setelah Anda memiliki akun Supermetrics, Anda hanya perlu membuka Extensions > Add-ons > Get add-ons dan menginstalnya. Ini akan meminta Anda untuk mengautentikasi dengan akun Google Anda yang ditautkan ke akun Supermetrics Anda, dan kemudian bilah sisi akan muncul di menu ekstensi.
Setelah ini selesai, Anda dapat meluncurkan bilah sisi—jika belum diluncurkan—dan klik untuk membuat kueri baru. Kueri adalah bagaimana Anda memutuskan data apa yang akan diambil dan dari akun apa. Saat Anda memilih salah satu platform iklan seperti Iklan Facebook dan Iklan Google, Anda akan diminta untuk mengautentikasi dan memberikan akses Supermetrics.
Kemudian Anda akan memilih akun yang ingin Anda ambil datanya dan rentang tanggalnya. Terakhir, pilih metrik Anda—biasanya biaya atau tayangan untuk MMM—dan dimensi—hanya pilih tanggal agar konsisten dengan format tabel.
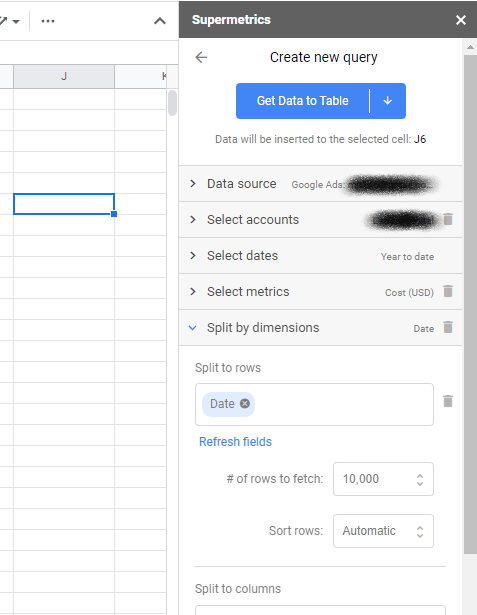
Secara opsional, Anda mungkin ingin menambahkan filter jika perlu memilih kumpulan kampanye tertentu. Misalnya, jika Anda memiliki 'YT: ' dalam nama kampanye YouTube, Anda mungkin ingin memilihnya sebagai sumber terpisah, lalu menduplikasi kueri dan memfilter untuk setiap jenis kampanye Anda yang lain.
Setelah Anda menyelesaikan kueri, pastikan Anda telah memilih sel tempat Anda ingin data ditarik, dan klik 'Dapatkan Data ke Tabel'. Jika Anda membuat kesalahan, cukup duplikat kueri dan letakkan di tempat yang tepat, hapus yang lain.
Saya merasa terbantu untuk meletakkan nama setiap sumber di sel di atas tabel sehingga saya tahu dari mana saya mengambil data. Hasilnya akan terlihat seperti ini:
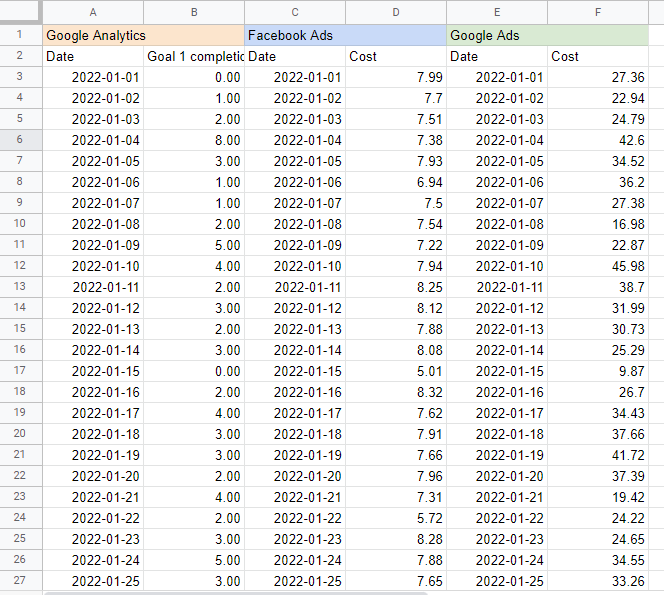
Membangun model bauran pemasaran di Google Spreadsheet
Pemodelan bauran pemasaran adalah alat yang ampuh untuk atribusi, tetapi sebenarnya lebih mudah diakses daripada yang Anda kira. Sebagian besar praktisi menggunakan kode khusus dan statistik lanjutan, tetapi Anda dapat melakukan dasar-dasarnya di sore hari dengan tidak lebih dari Excel atau Google Spreadsheet.
Regresi linier dengan fungsi LINEST
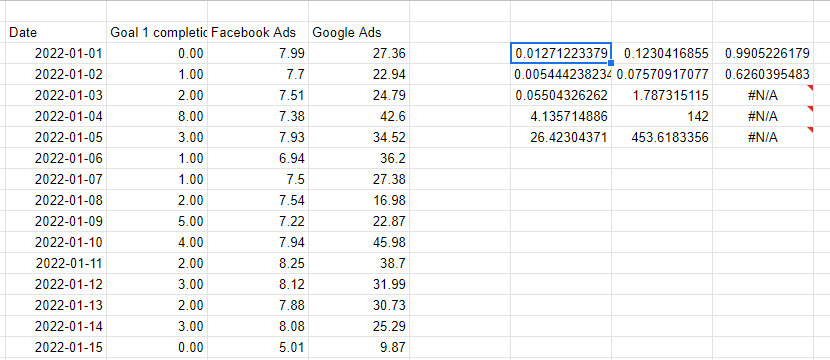
Excel dan Google Sheets keduanya menyediakan metode sederhana, fungsi LINEST, untuk melakukan regresi linier multi-variabel. LINEST bekerja dengan melewati kolom yang kita coba prediksi, lalu beberapa kolom yang mewakili variabel yang kita gunakan untuk membuat prediksi. Dua parameter terakhir adalah apakah kita menginginkan garis intersep—biasanya 1 untuk ya—dan apakah kita ingin output menjadi verbose—yang berisi semua statistik untuk model, bukan hanya koefisien.
Perhatikan bahwa variabel X yang kita gunakan untuk membuat prediksi harus berurutan, jadi saya baru saja mereferensikan kolom di sebelah kiri untuk mengulang nilai di samping satu sama lain.
Peramalan ulang dengan koefisien model
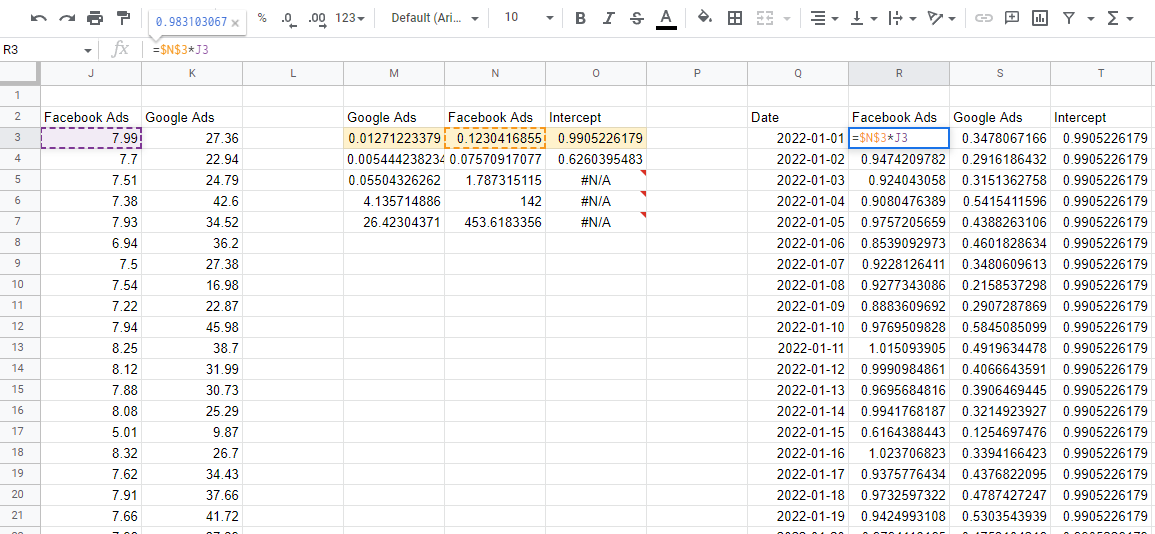
Sekarang kita memiliki model, kita perlu menggunakan koefisien untuk memperkirakan dampak dari setiap saluran. Jika kita mengambil baris angka teratas, itu adalah koefisiennya, dan mengalikannya dengan nilai input yang sesuai dari data kita—kita akan mendapatkan kontribusi dari setiap variabel terhadap total penjualan.

Satu hal yang harus diperhatikan adalah bahwa LINEST mengeluarkan koefisien ke belakang. Nilai pertama dimulai dari kiri selalu merupakan variabel terakhir yang Anda masukkan, kemudian dilanjutkan dalam urutan terbalik hingga Anda mendapatkan nilai terakhir, yaitu intersep. Jika Anda menjumlahkan semua nilai kontribusi ini, ini memberi Anda prediksi dari model, yang dapat Anda bandingkan dengan yang sebenarnya untuk memastikan modelnya akurat.
Memeriksa metrik akurasi model
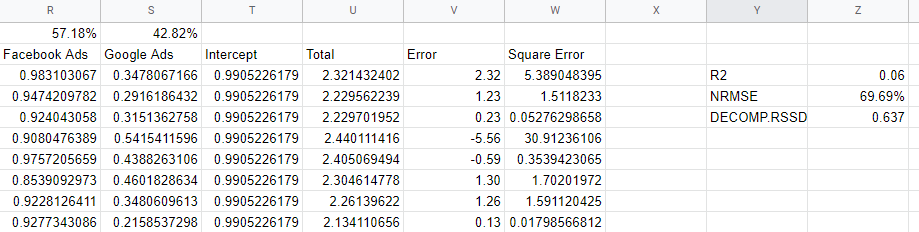
Bagaimana kita tahu apakah model kita dapat diandalkan? Model harus sesuai dengan data dengan baik, harus dapat memprediksi data baru yang belum terlihat, dan harus memiliki koefisien yang masuk akal. Beberapa metrik validasi menangkap persyaratan ini.
Periksa fungsi di template untuk melihat cara menghitung metrik ini.
Untuk menggunakan template, buka 'File' > 'Buat salinan' > 'Luncurkan Supermetrik' dari daftar add-on > duplikat file ini untuk akun lain, lalu lanjutkan ke pemilihan akun.
R2 atau R-Squared adalah ukuran seberapa banyak varians dalam data dijelaskan oleh model, dan itu antara 0 dan 1: model yang baik akan berada di atas 0,7, tetapi apa pun yang mendekati 1 mungkin mencurigakan. Mendekati 0, seperti model kami, adalah tanda bahwa kami tidak memasukkan cukup variabel dalam model kami dan perlu memasukkan hal-hal seperti saluran organik, liburan, dan faktor ekonomi makro.
'Normalized Root Mean Square Error' adalah cara kami mengukur akurasi, dan ini ditemukan dengan mengambil perbedaan antara prediksi model dan aktual, kemudian menemukan akar dari nilai kuadrat sebagai persentase dari nilai sebenarnya. Idealnya, ini dilakukan berdasarkan data yang tidak terlihat—grup ketidaksepakatan—tetapi dalam model sederhana kami, kami hanya menghitung kesalahan terhadap data dalam sampel.
Prosedur root dan squaring menangani nilai negatif bagi kami dan bertindak untuk menghukum kesalahan yang sangat besar. Ini dapat diartikan sebagai persentase model mati pada hari tertentu, jadi ini adalah ukuran intuitif yang berguna.
Masuk akal adalah topik besar, dan biasanya itu adalah sesuatu yang harus diputuskan oleh seorang analis. Namun, ada baiknya memiliki metrik yang dapat Anda hitung secara terprogram sehingga Anda memiliki pemahaman tentang seberapa jauh model menyimpang dalam hal temuannya dari campuran saluran Anda saat ini.
Decomp RSSD adalah metrik yang ditemukan oleh tim Robyn di Facebook yang mengukur perbedaan antara alokasi pengeluaran Anda saat ini dan saluran apa yang mendorong efek terbesar, seperti yang diprediksi oleh model. Jika model tersebut mengatakan bahwa saluran terbesar Anda tidak benar-benar mendorong penjualan sebanyak itu, maka Anda akan memiliki RSSD Decomp yang tinggi.
Dalam kasus kami, kami memiliki nilai 0,6 yang tinggi karena model tersebut memberikan terlalu banyak kredit ke Facebook, yang mewakili sejumlah kecil pembelanjaan.
Mengirimkan MMM secara otomatis dan dalam skala besar
Pemodelan bauran pemasaran adalah salah satu aktivitas yang skalabelnya tak terhingga. Anda bisa mendapatkan hasil yang layak di sore hari dengan Excel atau Google Sheets dan Supermetrics, seperti yang telah kami lakukan di sini, tetapi Anda juga bisa menghabiskan 3 bulan dengan tim yang terdiri dari 6 ilmuwan data yang menulis kode khusus dengan algoritme canggih seperti Bayesian MCMC untuk membangun sesuatu yang lebih kuat dan akurat.
Ada daftar fitur yang digunakan untuk membangun model tingkat lanjut, beberapa di antaranya memerlukan pengetahuan statistik tingkat lanjut. Tambahkan ke dalam campuran beberapa insinyur data mahal untuk membangun saluran data jika Anda tidak menggunakan Supermetrics untuk mengotomatiskan bagian itu untuk Anda.
Ingin mempelajari lebih lanjut tentang pemodelan otomatisasi campuran?
Lihat artikel pemodelan bauran pemasaran otomatis kami
Berhati-hatilah: MMM itu sulit. Anda dapat menghabiskan $ 500, $ 5.000, atau $ 50rb untuk pemodelan dan melihat hasil yang sangat berbeda dalam akurasi dan ketahanan. Yang benar-benar penting adalah biaya peluang untuk membuat alokasi pengeluaran pemasaran Anda salah.
Jika Anda menghabiskan $10ka per bulan, maka model spreadsheet sekali seperempat akan baik-baik saja. Namun, jika Anda menghabiskan lebih dari $ 100.000 per bulan, bahkan turun 5% dapat menghabiskan biaya puluhan ribu dolar selama setahun.
Tidak yakin model akses data mana yang Anda butuhkan untuk umpan MMM Anda?
Lihat artikel kami untuk memilih yang tepat untuk bisnis Anda
Saat itulah masuk akal untuk berinvestasi dalam pemodelan yang lebih maju. Lakukan analisis build vs. buy untuk memutuskan antara solusi kustom yang dibangun di perpustakaan sumber terbuka seperti Robyn Facebook atau perangkat lunak atribusi lanjutan seperti yang kami buat di Recast.
Tentang Penulis
Michael Kaminsky adalah ahli ekonometrika terlatih dengan latar belakang kesehatan dan ekonomi lingkungan. Dia sebelumnya membangun tim ilmu pemasaran di merek perawatan pria Harry's sebelum ikut mendirikan Recast.

Tingkatkan kinerja bisnis Anda
dengan menggabungkan intelijen pemasaran dan bisnis di gudang data Anda