
Memberdayakan keamanan perbankan: pembelajaran mesin untuk deteksi penipuan
Diterbitkan: 2023-11-14Setiap peluang selalu disertai ancaman. Pergeseran menuju digitalisasi dalam industri perbankan meningkatkan pengalaman nasabah dan memperluas basis klien ke populasi yang sebelumnya tidak mempunyai rekening bank. Sisi negatifnya adalah transaksi online dan solusi pembayaran digital membuka jalan baru bagi penipu untuk mengeksploitasinya.
Temuan dari survei penipuan KMPG menunjukkan bahwa frekuensi dan tingkat keparahan serangan siber semakin meningkat, sehingga mengakibatkan kerugian miliaran dolar.
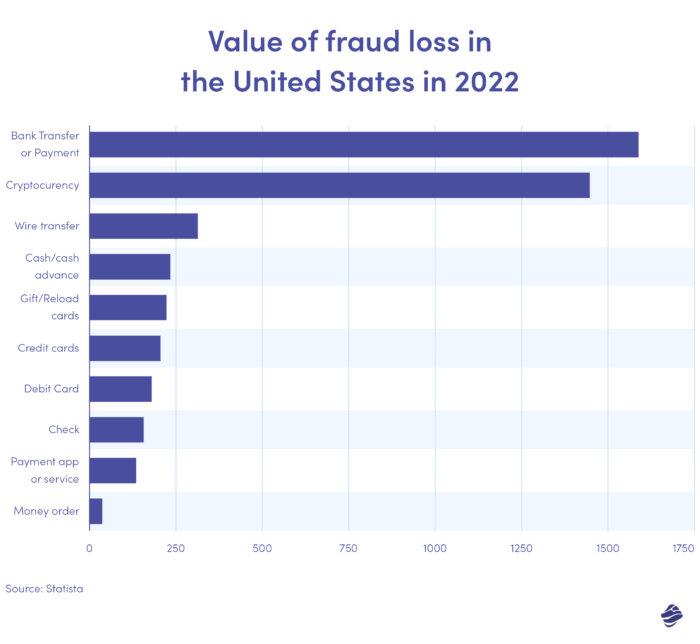
Grafik di atas menggambarkan nilai kerugian akibat penipuan berdasarkan metode pembayaran di Amerika Serikat pada tahun 2022. Transfer dan pembayaran bank merupakan yang tertinggi, dengan kerugian sebesar $1,59 miliar.
Kerugian ini memaksa lembaga perbankan untuk mengadopsi solusi baru untuk mendeteksi, memitigasi, dan mencegah penipuan keuangan. Salah satu metode tersebut adalah kecerdasan buatan (AI), khususnya pembelajaran mesin.
Dalam artikel ini, kami akan membahas semua yang perlu Anda ketahui tentang pembelajaran mesin untuk deteksi penipuan , termasuk manfaat dan penerapannya di kehidupan nyata.
Evolusi deteksi penipuan
Deteksi penipuan tradisional mengikuti pendekatan berbasis aturan. Seperti namanya, ini beroperasi berdasarkan serangkaian aturan atau ketentuan yang menentukan apakah suatu transaksi asli atau palsu. Kondisi umum mencakup lokasi (apakah pembelian di luar area biasanya pengguna?) dan frekuensi (apakah jumlah dan jenis pembelian biasa dilakukan pengguna?).
Suatu transaksi hanya dapat dilakukan jika memenuhi persyaratan. Misalnya, seorang pelanggan di Ohio tiba-tiba dikenakan biaya POS di Selandia Baru. Lokasinya berada di luar kode area pengguna, sehingga sistem menandai transaksi tersebut sebagai penipuan.
Ada beberapa kelemahan pada sistem deteksi penipuan jenis ini.
- Ini menghasilkan sejumlah besar kesalahan positif. Di sinilah Anda memblokir pembayaran dari pelanggan asli.
- Itu tidak fleksibel. Pendekatan berbasis aturan menggunakan hasil yang tetap, sehingga sulit untuk beradaptasi dengan tren perbankan digital. Anda harus mengubah aturan untuk menangkap bentuk penipuan baru.
- Itu tidak berskala. Ketika data meningkat, maka upaya yang diperlukan untuk mencegahnya pun ikut meningkat. Setiap perubahan pada sistem dilakukan secara manual, sehingga mahal dan memakan waktu.
Deteksi penipuan berbasis aturan berhasil. Namun, kelemahannya membuatnya tidak cocok untuk lingkungan digital modern. Ia tidak dapat mengenali pola dan bergantung pada campur tangan manusia.
Selain itu, peretas tidak mematuhi jadwal jam 9-5 dan dapat menggunakan metode canggih seperti spoofing lokasi dan peniruan perilaku pelanggan untuk mengelabui sistem deteksi penipuan. Oleh karena itu, Anda memerlukan sistem yang sama berkembangnya dan bekerja 24/7.
Masukkan pembelajaran mesin.
Pembelajaran mesin adalah kecerdasan buatan (AI) yang menggunakan data untuk melatih algoritme pendeteksi penipuan guna mengungkap pola dan hubungan data, mendapatkan wawasan, dan membuat prediksi.
Anda sudah familiar dengan pembelajaran mesin, meskipun Anda belum mengetahuinya. Misalnya, setiap kali Anda berinteraksi dengan postingan Instagram, Anda memberi informasi algoritme tentang jenis konten yang Anda sukai. Kemudian menjelajahi aplikasi untuk mencari konten serupa untuk ditambahkan ke feed Anda.
Bagaimana pembelajaran mesin akan mengubah deteksi penipuan
Deteksi penipuan di perbankan menggunakan pembelajaran mesin telah mengubah industri, dengan identifikasi dan respons terhadap penipuan yang lebih cepat, lebih fleksibel, dan lebih akurat.
Sistem AI menganalisis pola dalam data pelanggan dan secara otomatis mengubah aturan berdasarkan ancaman historis dan yang muncul.
Ingat biaya POS Selandia Baru yang kami sebutkan sebelumnya? Deteksi penipuan menggunakan pembelajaran mesin akan mempertimbangkan bahwa kartu bank yang sama memiliki pembelian untuk penerbangan ke lokasi tersebut. Oleh karena itu, kemungkinan besar debit baru tersebut sah.
Dua model digunakan untuk melatih algoritme guna mendeteksi penipuan: pembelajaran mesin yang diawasi dan pembelajaran mesin tanpa pengawasan.
Pembelajaran mesin yang diawasi
Model pembelajaran yang diawasi memberi algoritma sejumlah besar data yang ditandai sebagai penipuan atau non-penipuan. Algoritme mempelajari contoh-contoh ini dan mempelajari pola dan hubungan mana yang membedakan transaksi sah dan transaksi palsu.
Model pembelajaran ini memakan waktu karena memerlukan penandaan data secara manual. Selain itu, kumpulan data Anda harus diberi label dengan benar dan terorganisir dengan baik. Transaksi yang salah diberi tag akan mempengaruhi keakuratan algoritma.
Selain itu, ia hanya belajar dari masukan yang disertakan dalam set pelatihan. Jadi, transaksi melalui fitur aplikasi mobile banking Anda yang baru diluncurkan yang bukan merupakan bagian dari data historis tidak akan ditandai. Sekarang ada celah yang bisa dieksploitasi oleh penipu.
Pembelajaran mesin tanpa pengawasan
Model pembelajaran tanpa pengawasan hanya menggunakan masukan manusia yang minimal. Algoritme ini mempelajari pola dan hubungan dari sejumlah besar data yang tidak diberi tag, mengelompokkan kumpulan data berdasarkan persamaan dan perbedaan.
Tujuannya adalah untuk menemukan aktivitas tidak biasa yang tidak termasuk dalam kumpulan data pelatihan. Oleh karena itu, pembelajaran tanpa pengawasan melanjutkan pembelajaran yang diawasi dan mendeteksi penipuan baru.
Ingatlah bahwa Anda tidak harus memilih antara model pembelajaran mesin yang diawasi atau tidak diawasi. Anda dapat menggunakannya bersama-sama (model pembelajaran semi-supervisi) atau secara mandiri.
Manfaat menggunakan ML untuk deteksi penipuan
Kami telah mengisyaratkan manfaat deteksi penipuan menggunakan pembelajaran mesin di perbankan, namun mari kita bahas lebih lanjut.
- Kecepatan
Komputasi pembelajaran mesin terjadi dengan cepat dan memberikan keputusan penipuan secara real-time. Meskipun algoritme berbasis aturan juga mengambil keputusan secara real-time, algoritme tersebut mengandalkan aturan tertulis untuk menandai penipuan.
Apa yang terjadi dalam skenario baru tanpa aturan yang telah ditentukan sebelumnya? Ini mengarah pada positif palsu atau negatif palsu.
Pembelajaran mesin mendeteksi pola baru secara otomatis, menganalisis aktivitas pelanggan reguler, dan menghitung hasil yang sesuai dalam hitungan milidetik.
- Ketepatan
Sistem deteksi berbasis aturan memblokir transaksi asli atau mengizinkan transaksi palsu karena tidak mendeteksi perbedaan dalam perilaku pelanggan.
Sistem pembelajaran mesin mempertimbangkan variabel di luar aturan tertulis, misalnya perilaku penipuan yang diketahui. Variabel-variabel ini membantu mengkontekstualisasikan transaksi, menurunkan tingkat kesalahan positif.
- Fleksibilitas
Pembelajaran mesin bersifat fleksibel dan reaktif. Kemampuan belajar mandiri memungkinkan sistem ini menyesuaikan diri dengan skenario baru dan mendeteksi ancaman baru. Sistem berbasis aturan bersifat kaku dan tidak memiliki kemampuan belajar. Oleh karena itu, pihaknya hanya dapat merespons aktivitas penipuan sesuai dengan aturan yang telah ditentukan sebelumnya.
- Efisiensi
Algoritme pembelajaran mesin dapat menganalisis ribuan data transaksi per detik. Daripada menghabiskan tenaga kerja dan biaya overhead untuk menyelidiki kasus penipuan tingkat rendah hingga sedang, pembelajaran mesin dapat memproses penipuan yang berulang atau jelas. Hal ini memungkinkan spesialis penipuan untuk fokus pada pola kompleks yang memerlukan wawasan manusia.
- Skalabilitas
Peningkatan volume data memberi tekanan pada sistem berbasis aturan. Peraturan baru menambah kompleksitas sistem, sehingga sulit untuk dipelihara. Kesalahan atau kontradiksi apa pun dapat menyebabkan keseluruhan model menjadi tidak efektif.
Sistem pembelajaran mesin justru sebaliknya. Mereka tidak hanya mengasimilasi data baru dalam jumlah besar, namun juga meningkatkan kualitasnya.
Teknik pembelajaran mesin yang digunakan dalam deteksi penipuan
Sebelum kita memeriksa berbagai algoritma yang digunakan dalam deteksi penipuan AI, mari kita lihat dulu cara kerja sistemnya.
Langkah pertama adalah input data. Akurasi model bergantung pada volume dan kualitas data. Semakin banyak data berkualitas tinggi yang Anda tambahkan, semakin akurat modelnya.
Selanjutnya, model tersebut menganalisis data dan mengekstrak fitur-fitur utama yang menggambarkan perilaku normal versus perilaku curang. Fitur-fitur ini mencakup identitas pelanggan (email atau nomor telepon), lokasi (IP atau alamat pengiriman), metode pembayaran (nama pemegang kartu dan negara asal), dan banyak lagi.
Langkah ketiga adalah melatih algoritma (dengan lebih banyak data) untuk membedakan antara transaksi asli dan palsu. Model tersebut menerima kumpulan data pelatihan dan memprediksi kemungkinan penipuan dalam berbagai kasus. Setelah algoritme cukup terlatih, Anda siap meluncurkannya.
Sekarang, mari kita lihat berbagai algoritma yang dapat Anda gunakan.
1. Regresi logistik
Regresi logistik adalah algoritma pembelajaran yang diawasi. Ini menghitung kemungkinan penipuan pada skala biner – penipuan atau non-penipuan – berdasarkan parameter model.
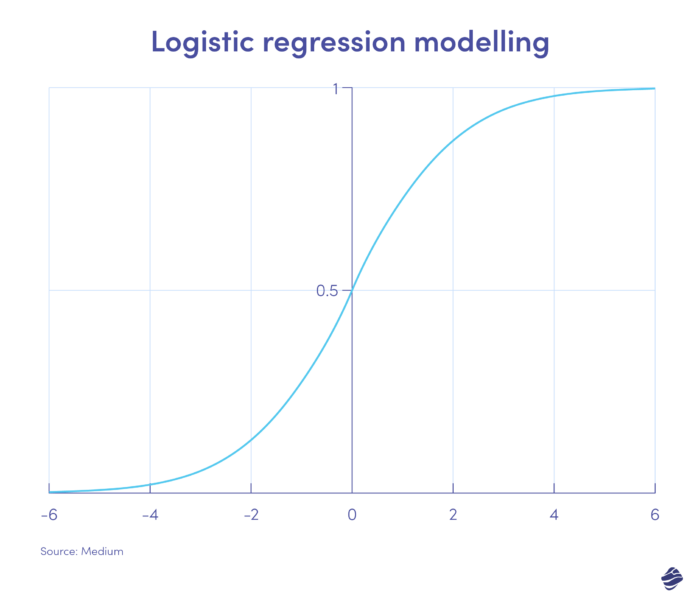
Transaksi yang berada pada sisi positif grafik kemungkinan besar merupakan transaksi penipuan, sedangkan transaksi yang berada pada sisi negatif kemungkinan besar sah.
2. Pohon keputusan
Pohon keputusan adalah algoritma pembelajaran yang diawasi tetapi lebih dari sekedar algoritma regresi logistik. Ini adalah struktur keputusan hierarki yang menganalisis data dalam beberapa tingkatan untuk menentukan apakah suatu transaksi asli atau palsu.
Di bawah ini adalah ilustrasi pohon keputusan untuk mendeteksi penipuan kartu kredit.
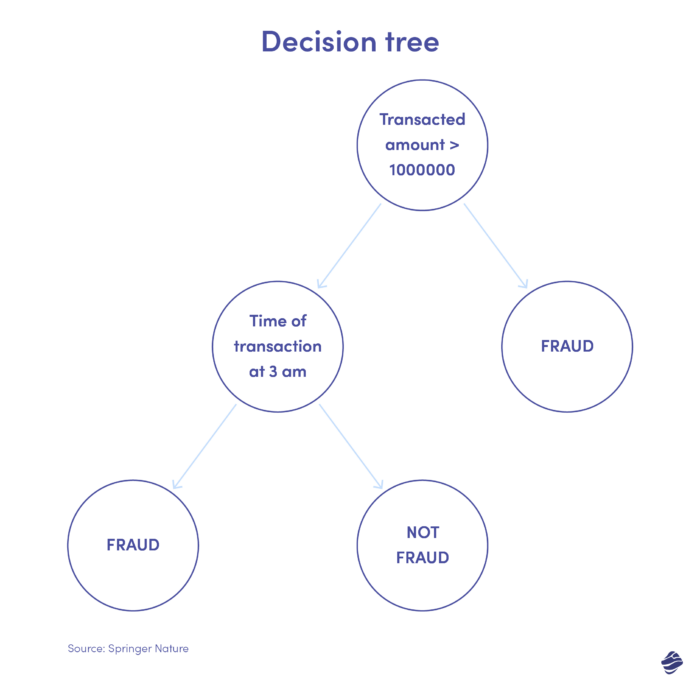
Syarat untuk mengetahui apakah transaksi tersebut penipuan adalah jumlah transaksinya. Jika nilai transaksi melebihi ambang batas yang ditetapkan, algoritme menganggapnya sebagai penipuan. Jika tidak, pohon akan memeriksa kondisi lain – waktu transaksi. Jika waktunya tidak biasa (di sini, jam 3 pagi), kemungkinan besar itu adalah penipuan. Jika tidak, ia memeriksa kondisi lain. Ini berlanjut.
3. Hutan Acak
Hutan acak adalah kombinasi dari banyak pohon keputusan, di mana setiap pohon keputusan memeriksa kondisi berbeda – identitas, lokasi, dll.
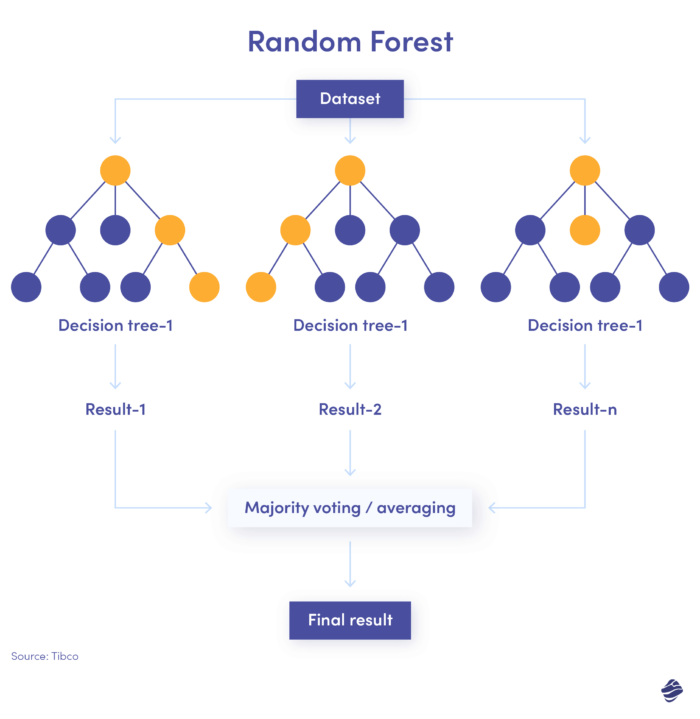
Setelah memeriksa semua parameter, setiap subpohon menawarkan keputusan. Total gabungan menentukan apakah transaksi tersebut asli atau palsu.

4. Jaringan saraf
Jaringan saraf adalah algoritma yang kompleks dan tidak diawasi. Terinspirasi oleh otak manusia, jaringan saraf memproses data dalam beberapa lapisan untuk mengekstrak fitur tingkat tinggi. Algoritme ini sejalan dengan pembelajaran mendalam, yang dapat mengenali pola dalam gambar, teks, audio, dan data lainnya.
Berikut adalah versi sederhana dari jaringan saraf.
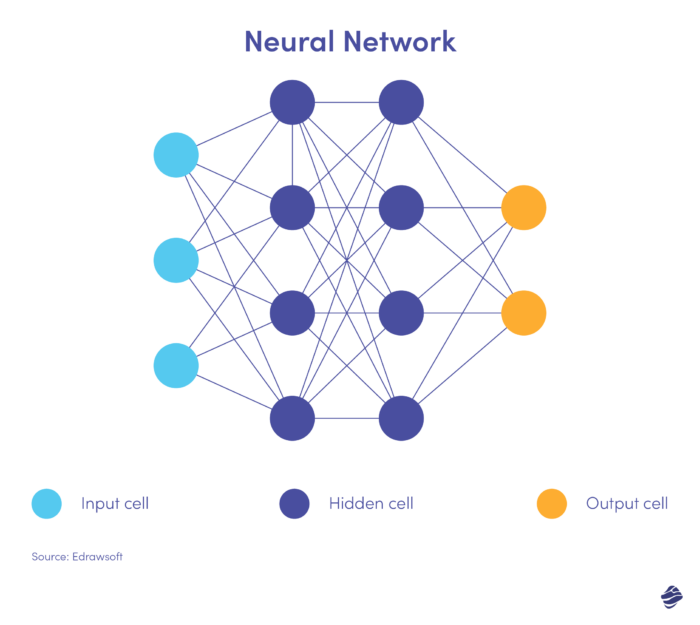
Jaringan saraf memiliki tiga lapisan: masukan, tersembunyi, dan keluaran. Lapisan masukan memproses data, lapisan tersembunyi menganalisis data dari lapisan masukan untuk mengidentifikasi pola tersembunyi, dan lapisan keluaran mengklasifikasikan data.
Jaringan saraf dalam memiliki beberapa lapisan tersembunyi. Mereka bagus untuk mengidentifikasi hubungan non-linier dan mendeteksi skenario penipuan yang belum pernah terjadi sebelumnya.
5. Mendukung mesin vektor
Mesin vektor dukungan (SVM) adalah algoritma pembelajaran yang diawasi yang memprediksi, mengklasifikasikan, dan mendeteksi outlier.
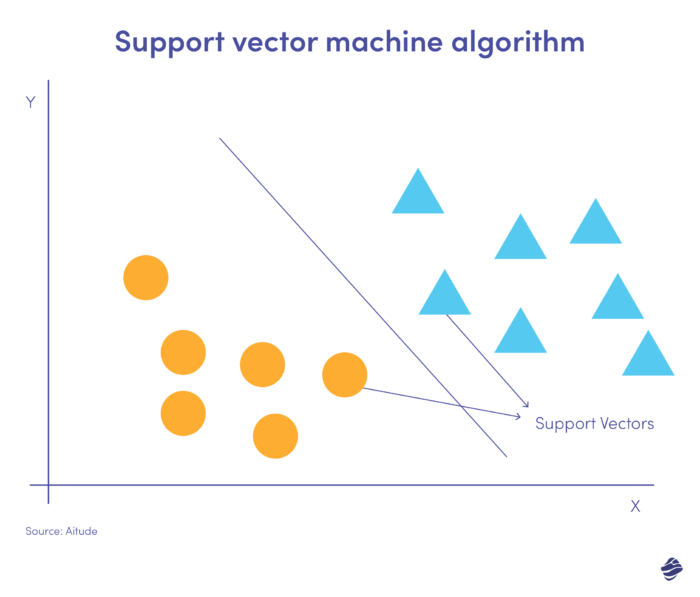
Ilustrasi SVM linier ini menunjukkan dua kumpulan data yang dipisahkan oleh garis lurus yang disebut hyperplane. Ini adalah batasan keputusan yang mengklasifikasikan data sebagai penipuan vs. non-penipuan.
Titik data yang jauh dari hyperplane mudah diklasifikasikan. Vektor pendukung (yang paling dekat dengan hyperplane) sulit untuk dikategorikan. Outlier ini dapat mempengaruhi posisi hyperplane jika dihilangkan.
6. K-tetangga terdekat
K-nearest neighbour (KNN) adalah algoritma pembelajaran yang diawasi. Ini beroperasi dengan asumsi bahwa barang-barang serupa ada berdekatan satu sama lain.
Di bawah ini adalah ilustrasi sederhana.
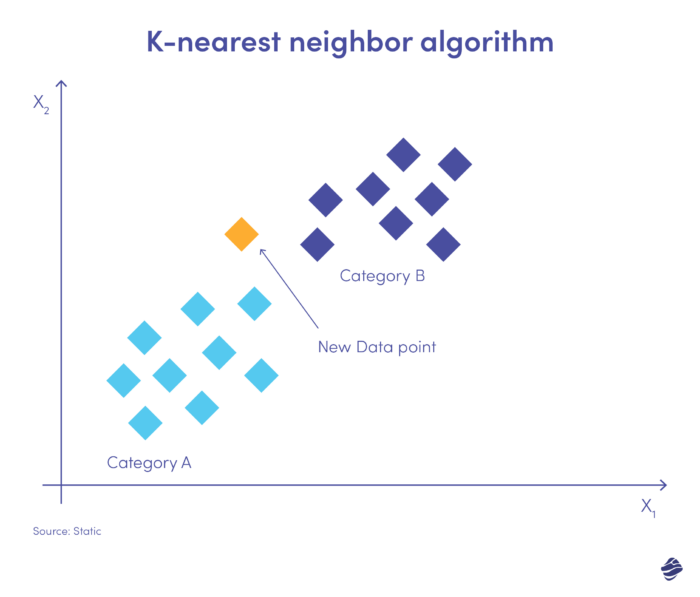
Entri data baru perlu ditempatkan dalam kategori A atau B. Algoritme menghitung jarak antar titik data menggunakan persamaan matematika yang disebut jarak Euclidean. Titik data baru masuk dalam kelompok dengan tetangga terbanyak. Jika kumpulan data terdekat diberi tanda 'penipuan', maka transaksi tersebut diklasifikasikan sebagai penipuan.
Menavigasi tantangan dan pertimbangan strategis
Seperti semua teknologi, ada kesulitan yang semakin besar terkait dengan pengintegrasian pembelajaran mesin untuk mendeteksi penipuan. Berikut beberapa tantangan umum yang mungkin Anda hadapi.
Infrastruktur yang tidak memadai
Banyak sistem perbankan tidak dapat menganalisis data kompleks dalam jumlah besar. Selain itu, sebagian besar data disimpan dan disimpan di fasilitas penyimpanan terpisah.
Sayangnya, tidak ada solusi cepat untuk mengatasi masalah ini. Anda harus berinvestasi pada perangkat keras dan perangkat lunak yang sesuai.
Anda harus bermitra dengan agen pengembangan aplikasi Fintech yang berpengalaman dan menyiapkan infrastruktur untuk secara otomatis memilih algoritme yang sesuai untuk kumpulan data tertentu, mengimpor data mentah dan mempersiapkannya untuk pembelajaran mesin, memvisualisasikan data, menguji algoritme, dan banyak lagi.
Kualitas dan keamanan data
Kualitas data merupakan masalah penting bagi lembaga keuangan yang ingin menerapkan pembelajaran mesin untuk mendeteksi penipuan. Model pembelajaran mesin tidak membedakan data yang baik dan buruk. Jadi, jika algoritme tercemar dengan data yang tidak relevan atau tidak lengkap, keakuratan model Anda akan salah.
Solusi penyerapan data seperti Amazon Kinesis mengumpulkan, membersihkan, dan mengubah data mentah, sehingga cocok untuk model pembelajaran mesin. Setelah data dibersihkan dan diatur, Anda harus memisahkan data sensitif dan tidak sensitif. Enkripsi informasi rahasia dan simpan di fasilitas aman. Anda juga harus membatasi akses ke data ini.
Kurangnya bakat
Terlepas dari ketakutan banyak orang, pembelajaran mesin tidak mencuri pekerjaan. Justru sebaliknya. Kita masih memerlukan analis penipuan untuk menangani kasus-kasus kompleks yang memerlukan wawasan dan pengalaman manusia. Selain itu, pembelajaran mesin adalah teknologi baru, dan jumlah ahli di bidangnya masih terbatas.
Ini merupakan kabar baik bagi pencari kerja, namun tidak bagi institusi yang tidak dapat memanfaatkan potensi pembelajaran mesin secara maksimal. Anda dapat mengatasi hambatan ini dengan bermitra dengan bisnis yang memiliki keahlian untuk menerapkan pembelajaran mesin.
Studi kasus deteksi penipuan di perbankan menggunakan pembelajaran mesin
Sekarang, mari kita lihat contoh nyata pendeteksian penipuan di perbankan menggunakan pembelajaran mesin.
Deteksi penipuan
Danske Bank adalah perusahaan keuangan multinasional Denmark. Ini adalah bank terbesar di Denmark dan bank ritel terkemuka di Eropa Utara. Di bawah sistem deteksi berbasis aturan, bank berjuang untuk memitigasi penipuan. Itu memiliki tingkat deteksi penipuan 40% dan tingkat positif palsu 99,5%.
Bekerja sama dengan Teradata, sebuah perusahaan perangkat lunak data, Danske mengintegrasikan perangkat lunak pembelajaran mendalam untuk membantu mengidentifikasi potensi aktivitas penipuan. Hasilnya adalah pengurangan 60% pada hasil positif palsu dan peningkatan 50% pada hasil positif sebenarnya.
Anti pencucian Uang
OakNorth adalah bank pemberi pinjaman komersial di Inggris, yang menyediakan layanan keuangan bisnis dan pribadi kepada perusahaan skala besar. Bank tersebut memiliki proses penyaringan yang retak, dengan satu penyedia untuk cek anti pencucian uang dan satu lagi untuk pelanggan. Selain itu, pemeriksaan terhadap orang-orang yang terpapar politik (PEP) menghasilkan banyak hasil positif palsu.
Bekerja sama dengan ComplyAdvantage, sebuah perusahaan pendeteksi penipuan dan AML, bank ini mengintegrasikan solusi penyaringan dan pemantauan berkelanjutan untuk menyederhanakan kepatuhan dan mengkonsolidasikan data. Hal ini memfasilitasi transfer data yang cepat antara operasi peminjaman dan penyimpanan bank.
Penjaminan kredit
Credit Union Hawaii USA adalah credit union terbesar di Hawaii dan salah satu credit union terbaik Majalah Forbes. Perusahaan ingin bersaing dengan perusahaan Fintech dan mengembangkan portofolio pinjaman pribadinya tanpa meningkatkan risiko.
Bekerja sama dengan Zest AI, credit union mengotomatiskan proses pengambilan keputusannya menggunakan model pinjaman pribadi berbasis AI. Model ini menggunakan 278 variabel untuk memberikan wawasan yang lebih mendalam dibandingkan sistem penilaian kredit VantageScore. Hasilnya adalah peningkatan tingkat persetujuan sebesar 21% dan tingkat penipuan permohonan pinjaman/gagal bayar sebesar 0%.
Pertimbangan utama saat menggunakan ML untuk deteksi penipuan
Meskipun deteksi penipuan di perbankan menggunakan pembelajaran mesin cukup efisien, hal ini juga merupakan hal yang menakutkan. Sistem ini menuntut banyak data yang akurat, atau modelnya tidak akan berfungsi sebagaimana mestinya.
Berikut beberapa tips untuk mengoptimalkan proses pembelajaran mesin.
1. Batasi jumlah variabel masukan
Sepanjang artikel ini, kami telah mengatakan lebih banyak lebih banyak. Hal ini tetap berlaku mengenai volume data. Namun, lebih sedikit berarti lebih baik jika dikaitkan dengan jumlah variabel pendeteksi penipuan.
Fitur umum yang perlu dipertimbangkan ketika menyelidiki penipuan meliputi:
- alamat IP
- Alamat email
- Alamat pengiriman
- Rata-rata nilai pesanan/transaksi
Keuntungan dari lebih sedikit fitur adalah waktu pelatihan algoritme yang lebih singkat. Anda juga terhindar dari masalah kumpulan data yang tumpang tindih atau tidak relevan.
2. Memastikan kepatuhan terhadap peraturan
Mencegah penipuan adalah salah satu bagian dari keamanan data. Yang lainnya adalah privasi data. Banyak negara mempunyai undang-undang tentang bagaimana institusi dapat mengumpulkan, menggunakan, dan menyimpan data pelanggan. Ada Undang-Undang Perlindungan Informasi Pribadi (PIPL) di Tiongkok, Undang-Undang Privasi Konsumen California (CCPA), dan Peraturan Perlindungan Data Umum (GDPR) Uni Eropa.
Undang-undang ini berdampak pada data yang digunakan dalam pembelajaran mesin. Prinsip utama di sebagian besar peraturan kepatuhan privasi data adalah pemberitahuan/persetujuan. Anda harus memberi tahu dan menerima izin untuk menggunakan data pelanggan untuk tujuan selain permintaan pengguna, termasuk data untuk melatih algoritme pembelajaran mesin.
Cara paling sederhana untuk memastikan kepatuhan terhadap standar privasi adalah dengan menggunakan mitra teknis yang memiliki fitur yang mematuhi peraturan. Misalnya, Anda harus bermitra dengan perusahaan pengembang aplikasi perbankan yang memahami cara menjaga privasi dan keamanan data.
3. Tetapkan ambang batas yang masuk akal
Aturan nilai transaksi memiliki persyaratan minimum untuk memicu respons terima atau tolak. Anda menginginkan ambang batas yang menyeimbangkan keamanan dan pengalaman pengguna. Jika ambang batasnya terlalu ketat, Anda berisiko memblokir transaksi yang sah. Jika ambang batasnya terlalu longgar, Anda akan meningkatkan tingkat keberhasilan penipuan.
Hitung selera risiko Anda untuk menemukan keseimbangan yang tepat. Tingkat risiko berbeda untuk setiap lembaga atau produk keuangan. Misalnya, penawaran bank pinjaman mikro dapat menetapkan ambang batas yang tinggi untuk pinjaman bernilai rendah. Bank komersial tidak bisa bermurah hati dengan pinjaman hipotek.
Mengantisipasi masa depan
Masa depan adalah masa kini, namun hanya 17% organisasi yang menggunakan pembelajaran mesin dalam program anti-penipuan. Jangan ketinggalan.
Berikut beberapa terobosan yang dapat Anda harapkan dalam keamanan bank Anda melalui pembelajaran mesin.
- Pembuatan profil perangkat : mengidentifikasi berbagai perangkat yang terhubung ke jaringan perbankan Anda, menganalisis fitur dan perilaku perangkat tertentu.
- Deteksi dan respons anomali otomatis : mengidentifikasi perilaku penipuan dari perangkat yang diketahui dan mengisolasi sistem yang terpengaruh.
- Deteksi zero-day : mengidentifikasi kerentanan dan malware yang sebelumnya tidak diketahui untuk melindungi organisasi dari serangan siber.
- Penyembunyian data : secara otomatis mendeteksi dan menganonimkan data rahasia.
- Wawasan berskala : mengidentifikasi tren penipuan di berbagai perangkat dan lokasi.
- Kebijakan inovatif : menggunakan wawasan pembelajaran mesin untuk mendorong kebijakan keamanan yang relevan.
Baik Anda adalah lembaga pengelolaan kekayaan atau credit union, AI dan pembelajaran mesin memiliki peluang besar untuk mendeteksi penipuan.
Namun, penting untuk diingat bahwa peretas juga menggunakan teknologi ini untuk menghindari tindakan perlindungan. Perbarui model pembelajaran mesin Anda agar tetap terdepan dalam menghadapi serangan ini. Anda juga dapat memperkuat keamanan berbasis AI Anda dengan kecerdasan manusia yang baik.