
Pengantar perayap web
Diterbitkan: 2016-03-08Ketika saya berbicara dengan orang-orang tentang apa yang saya lakukan dan apa itu SEO, mereka biasanya mendapatkannya dengan cukup cepat, atau mereka bertindak seperti yang mereka lakukan. Struktur situs web yang bagus, konten yang bagus, backlink pendukung yang bagus. Tetapi terkadang, ini menjadi sedikit lebih teknis dan saya akhirnya berbicara tentang mesin pencari yang merayapi situs web Anda dan saya biasanya kehilangannya…
Mengapa merayapi situs web?
Perayapan web dimulai sebagai pemetaan internet dan bagaimana setiap situs web terhubung satu sama lain. Itu juga digunakan oleh mesin pencari untuk menemukan dan mengindeks halaman online baru. Perayap web juga digunakan untuk menguji kerentanan situs web dengan menguji situs web dan menganalisis jika ada masalah yang ditemukan.
Sekarang Anda dapat menemukan alat yang merayapi situs web Anda untuk memberi Anda wawasan. Misalnya, OnCrawl menyediakan data mengenai konten Anda dan SEO di tempat atau Majestic yang memberikan wawasan tentang semua tautan yang mengarah ke suatu halaman.
Crawler digunakan untuk mengumpulkan informasi yang kemudian dapat digunakan dan diproses untuk mengklasifikasikan dokumen dan memberikan wawasan tentang data yang dikumpulkan.
Membangun crawler dapat diakses oleh siapa saja yang mengetahui sedikit kode. Namun, membuat perayap yang efisien lebih sulit dan membutuhkan waktu.
Bagaimana cara kerjanya ?
Untuk merayapi situs web atau web, Anda memerlukan titik masuk terlebih dahulu. Robot perlu mengetahui bahwa situs web Anda ada sehingga mereka dapat datang dan melihatnya. Kembali pada hari-hari Anda akan mengirimkan situs web Anda ke mesin pencari untuk memberi tahu mereka bahwa situs web Anda online. Sekarang Anda dapat dengan mudah membuat beberapa tautan ke situs web Anda dan Voila Anda berada di lingkaran!
Setelah perayap mendarat di situs web Anda, perayap menganalisis semua konten Anda baris demi baris dan mengikuti setiap tautan yang Anda miliki apakah itu internal atau eksternal. Dan seterusnya hingga mendarat di halaman tanpa tautan lagi atau jika menemukan kesalahan seperti 404, 403, 500, 503.
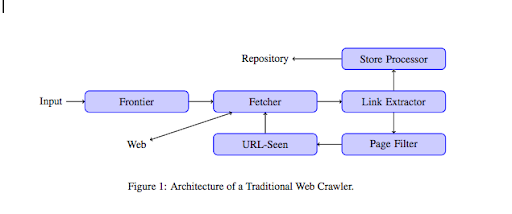
Dari sudut pandang yang lebih teknis, perayap bekerja dengan benih (atau daftar) URL. Ini diteruskan ke Pengambil yang akan mengambil konten halaman. Konten ini kemudian dipindahkan ke ekstraktor Tautan yang akan mengurai HTML dan mengekstrak semua tautan. Tautan ini dikirim ke kedua prosesor Store yang akan, seperti namanya, menyimpannya. URL ini juga akan melalui filter Halaman yang akan mengirim semua tautan menarik ke modul yang dilihat URL. Modul ini mendeteksi apakah URL sudah terlihat atau belum. Jika tidak, itu akan dikirim ke Pengambil yang akan mengambil konten halaman dan seterusnya.
Perlu diingat bahwa beberapa konten tidak mungkin dijelajahi laba-laba seperti Flash. Javascript sekarang sedang dirayapi dengan benar oleh GoogleBot, tetapi kadang-kadang tidak merayapi semua itu. Gambar bukanlah konten yang secara teknis dapat dirayapi oleh Google, tetapi gambar menjadi cukup pintar untuk mulai memahaminya !
Jika robot tidak diberitahu sebaliknya, mereka akan merayapi semuanya. Di sinilah file robots.txt menjadi sangat berguna. Ini memberi tahu perayap (bisa spesifik per perayap yaitu GoogleBot atau MSN Bot – cari tahu lebih lanjut tentang bot di sini) halaman apa yang tidak dapat mereka jelajahi. Katakanlah misalnya Anda memiliki navigasi menggunakan faset, Anda mungkin tidak ingin robot merayapi semuanya karena memiliki nilai tambah yang kecil dan akan menggunakan anggaran perayapan. Menggunakan garis sederhana ini akan membantu Anda mencegah robot apa pun merayapinya
Agen pengguna: *
Larang: /folder-a/
Ini memberitahu semua robot untuk tidak merayapi folder A.
Agen-pengguna: GoogleBot
Larang: /repertoar-b/
Ini di sisi lain menentukan bahwa hanya Google Bot yang tidak dapat merayapi folder B.
Anda juga dapat menggunakan indikasi dalam HTML yang memberi tahu robot untuk tidak mengikuti tautan tertentu menggunakan tag rel="nofollow". Beberapa pengujian telah menunjukkan bahwa penggunaan tag rel=”nofollow” pada tautan tidak akan memblokir Googlebot untuk mengikutinya. Ini bertentangan dengan tujuannya, tetapi akan berguna dalam kasus lain.
[Studi Kasus] Tingkatkan visibilitas dengan meningkatkan kemampuan perayapan situs web untuk Googlebot
 Baca studi kasus
Baca studi kasus
Anda menyebutkan anggaran perayapan tetapi apa itu?
Katakanlah Anda memiliki situs web yang telah ditemukan oleh mesin pencari. Mereka secara teratur datang untuk melihat apakah Anda telah membuat pembaruan di situs web Anda dan membuat halaman baru.
Setiap situs web memiliki anggaran perayapan sendiri tergantung pada beberapa faktor seperti jumlah halaman yang dimiliki situs web Anda dan kewarasannya (jika memiliki banyak kesalahan misalnya). Anda dapat dengan mudah mengetahui anggaran perayapan dengan mudah dengan masuk ke Search Console.
Anggaran perayapan Anda akan memperbaiki jumlah halaman yang dirayapi robot di situs web Anda setiap kali datang berkunjung. Ini terkait secara proporsional dengan jumlah halaman yang Anda miliki di situs web Anda dan telah dirayapi. Beberapa halaman dirayapi lebih sering daripada yang lain terutama jika mereka diperbarui secara teratur atau jika mereka ditautkan dari halaman penting.
Misalnya rumah Anda adalah titik masuk utama Anda yang akan sering dirayapi. Jika Anda memiliki blog atau halaman kategori, mereka akan sering dirayapi jika ditautkan ke navigasi utama. Sebuah blog juga akan sering dirayapi karena diperbarui secara berkala. Sebuah posting blog mungkin sering dirayapi saat pertama kali diterbitkan, tetapi setelah beberapa bulan mungkin tidak akan diperbarui.
Semakin sering halaman dirayapi, semakin penting robot menganggapnya penting dibandingkan dengan yang lain. Inilah saatnya Anda harus mulai bekerja untuk mengoptimalkan anggaran perayapan Anda.
Mengoptimalkan anggaran perayapan Anda
Untuk mengoptimalkan anggaran Anda dan memastikan halaman terpenting Anda mendapatkan perhatian yang layak, Anda dapat menganalisis log server Anda dan melihat bagaimana situs web Anda dirayapi:
- Seberapa sering halaman teratas Anda dirayapi?
- Dapatkah Anda melihat halaman yang kurang penting dirayapi lebih dari halaman lain yang lebih penting?
- Apakah robot sering mendapatkan kesalahan 4xx atau 5xx saat merayapi situs web Anda?
- Apakah robot menghadapi perangkap laba-laba? (Matthew Henry menulis artikel bagus tentang mereka)
Dengan menganalisis log Anda, Anda akan melihat halaman mana yang Anda anggap kurang penting sedang banyak dirayapi. Anda kemudian perlu menggali lebih dalam struktur tautan internal Anda. Jika sedang dirayapi, pasti ada banyak tautan yang mengarah ke sana.
Anda juga dapat memperbaiki semua kesalahan ini (4xx dan 5xx) dengan OnCrawl. Ini akan meningkatkan kemampuan perayapan serta pengalaman pengguna, ini adalah kasus yang saling menguntungkan.
Merangkak VS Menggores?
Merangkak dan menggores adalah dua hal berbeda yang digunakan untuk tujuan berbeda. Merangkak situs web mendarat di halaman dan mengikuti tautan yang Anda temukan saat memindai konten. Crawler kemudian akan pindah ke halaman lain dan seterusnya.
Menggores di sisi lain memindai halaman dan mengumpulkan data spesifik dari halaman: tag judul, deskripsi meta, tag h1 atau area spesifik situs web Anda seperti daftar harga. Scraper biasanya bertindak sebagai "manusia", mereka akan mengabaikan aturan apa pun dari file robots.txt, file dalam formulir dan menggunakan agen pengguna browser agar tidak terdeteksi.
Perayap mesin pencari biasanya bertindak sebagai scrapper dan juga mereka perlu mengumpulkan data untuk memprosesnya untuk algoritme peringkat mereka. Mereka tidak mencari data spesifik dibandingkan dengan scrapper, mereka hanya menggunakan semua data yang tersedia di halaman dan bahkan lebih (waktu memuat adalah sesuatu yang tidak bisa Anda dapatkan dari halaman). Perayap mesin pencari akan selalu mengidentifikasi diri mereka sebagai perayap sehingga pemilik situs web dapat mengetahui kapan terakhir kali mereka mengunjungi situs web mereka. Ini bisa sangat membantu saat Anda melacak aktivitas pengguna yang sebenarnya.
Jadi sekarang Anda tahu lebih banyak tentang perayapan, cara kerjanya dan mengapa itu penting, langkah selanjutnya adalah mulai menganalisis log server. Ini akan memberi Anda wawasan mendalam tentang bagaimana robot berinteraksi dengan situs web Anda, halaman mana yang sering mereka kunjungi, dan berapa banyak kesalahan yang mereka temui saat mengunjungi situs web Anda.
Untuk informasi teknis dan historis lebih lanjut tentang perayap web, Anda dapat membaca "Sejarah Singkat Perayap Web"