
Pentingnya Otoritas Topikal: Studi Kasus SEO Semantik
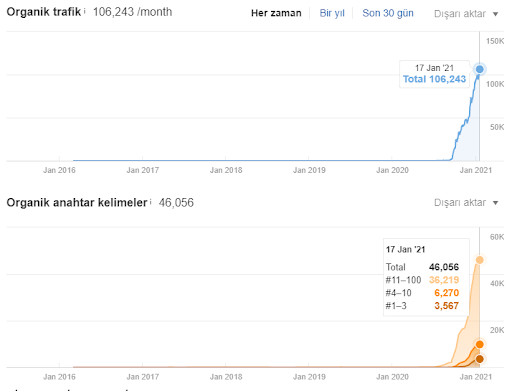
Diterbitkan: 2021-02-11Otoritas Topikal dan SEO Semantik akan lebih sering dibahas dengan konsep Mesin Pencari Terstruktur di tahun-tahun mendatang. Dalam artikel ini, saya akan menjelaskan bagaimana saya menggunakan teknik ini untuk meningkatkan lalu lintas organik bulanan dari 10.000 menjadi 200.000+ di Interingilizce.com hanya dalam 5 bulan.
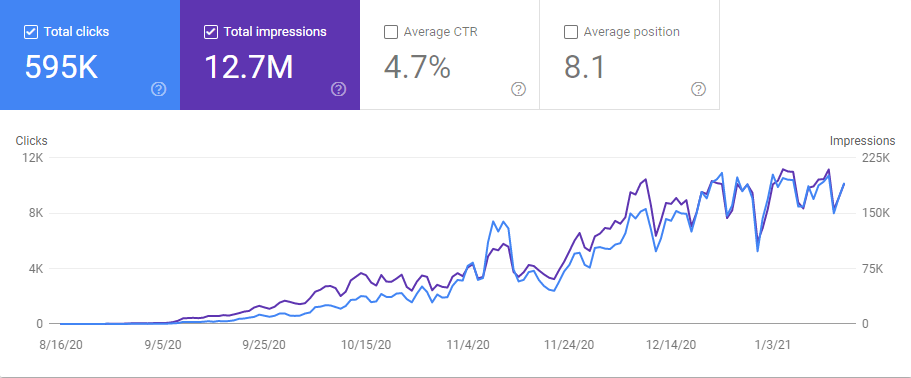
5 Bulan Terakhir. Grafik GetWordly.com. Proyek telah dimulai 6 bulan yang lalu.
Ketika Anda membaca studi kasus SEO ini, beberapa hal mungkin tampak aneh bagi Anda karena agak luar biasa. Oleh karena itu, kita perlu menyoroti konsep SEO semantik yang tidak begitu familiar.
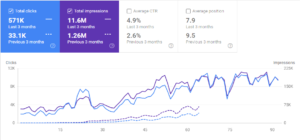
Membandingkan Tiga Bulan Terakhir dan Tiga Bulan Pertama dari Laporan Kinerja Lalu Lintas Organik GSC GetWordly.com.
Latar Belakang Studi Kasus dan Proyek SEO Semantik
Selama studi kasus SEO ini, tidak ada metode berikut yang digunakan, dan semua elemen SEO penting yang terlihat di bawah ini sengaja dikeluarkan dari proyek.
- Pengoptimalan Kecepatan Halaman
- Kekuatan Merek dan Pencitraan Merek
- SEO Teknis (Benar: Saya tidak menggunakannya.)
- Tata Letak dan Desain Halaman Web Berkualitas
- Server yang Sehat
- SEO Pada Halaman
Singkatnya, apa pun yang biasanya kami katakan adalah praktik bagus yang baik dalam studi kasus SEO normal tidak dilakukan di situs web ini. Oleh karena itu, Anda mungkin berpikir bahwa kesuksesan yang saya miliki adalah kebetulan. Tetapi Anda akan salah: dengan metodologi yang sama, saya telah membuat 4 studi kasus dan kisah sukses SEO terpisah dalam 5 bulan terakhir.
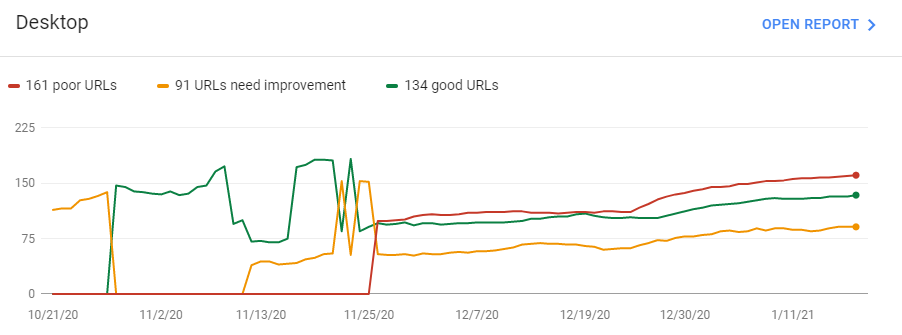
Sebagai contoh, “Saya bahkan memiliki banyak “URL buruk di desktop”.
Artikel ini adalah ringkasan eksekutif metodologi saya dan juga manifesto untuk SEO semantik dan nilai-nilai sebenarnya dari teori SEO dengan pemikiran analitis gratis.
Ini berarti saya telah memutuskan untuk tidak membahas topik dan pengalaman terkait, seperti:
- Pembaruan Google kecil
- Alasan saya kehilangan semua cuplikan unggulan dalam satu hari
- Bagaimana server kami runtuh karena lalu lintas yang berlebihan
- Pengaruh kegagalan server pada algoritma mesin pencari.
Dengan mengingat hal itu, izinkan saya menyajikan metodologinya.
4 Proyek SEO Berbeda, Metodologi Sama, dan Sukses Sama dengan SEO Semantik
Pada artikel ini, saya akan fokus pada Interingilizce.com dengan ringkasan eksekutif SEO semantik sederhana. Namun, untuk mengurangi pertanyaan yang mungkin Anda miliki dan menjamin bahwa "Teori SEO dan Paten Google" memiliki nilai yang konkret dan dapat ditindaklanjuti (terima kasih kepada Bill Slawski), saya ingin merangkum 4 perjalanan proyek SEO yang berbeda hanya dengan hasilnya.
Jika Anda ingin membaca semua istilah, teori, paten, dan detail praktis SEO yang berat tentang studi kasus dan proyek SEO ini, saya sarankan Anda membaca artikel Otoritas Topik, Cakupan, dan Hirarki Kontekstual saya untuk SEO. (Ini panjang dan memiliki lebih dari 14.000 kata.)
“Kami bertujuan untuk sukses dalam waktu singkat dengan efek cepat dalam proyek baru kami. Dan kami melampaui target kami dalam proyek baru kami.”
Rustem Ersoyleyen
Kepala Pemasaran, Konusarak Ogren
Proyek Pertama: Peningkatan Traffic Organik 1100% dalam 5 Bulan, Interingilizce.com
Interingilizce.com sebenarnya berusia 2 tahun, tetapi tidak ada konten di situs web atau lalu lintas organik. Saya telah meningkatkan Org. Lalu lintas sebesar 1100% dalam 145 hari. Dari 10.000 hingga 200.000 klik. Karena Anda sudah melihat hasil "lalu lintas organik 6 bulan terakhir" di bagian pendahuluan, Anda dapat melihat perbandingan "Mei 2020" dan "November 2020" di bawah.
Saya tahu, sebenarnya, ini jauh lebih dari sekadar peningkatan lalu lintas organik 1100%, tetapi saya tidak dapat menggunakan tanda "%" untuk peningkatan semacam ini untuk membuat Anda membayangkan sesuatu yang cukup konkret.
Di bawah, Anda akan melihat grafik Perbandingan 3 Bulan Terakhir Interingilizce.com untuk lalu lintas organik.
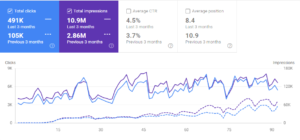
Dan, Grafik Lalu Lintas Organik 6 Bulan terakhir untuk Interingilizce.com.
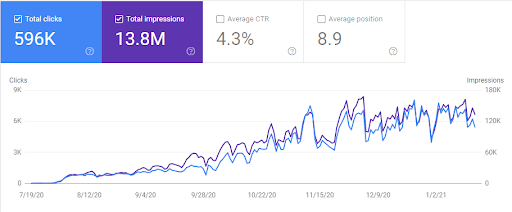
Anda mungkin bingung dengan Laporan GSC GetWordly.com, tetapi keduanya berbeda. Karena, saya menggunakan metodologi yang sama, mereka memiliki refleks yang sama terhadap algoritma dan pembaruan Google.
Proyek Kedua: Dari 0 hingga 330.000 Lalu Lintas Organik Bulanan, dan 10.000+ Klik Per Hari: GetWordly.com
GetWordly.com adalah situs kedua, situs web murni dalam hal visibilitas dan sejarah organik. Di GetWordly.com, saya mencapai level 11.000 klik organik per hari dan 330.000 klik organik per bulan hanya dalam 6 bulan.
Anda akan melihat grafik lalu lintas organik 6 bulan terakhir GetWordly.com dari Google Search Console di bawah ini.
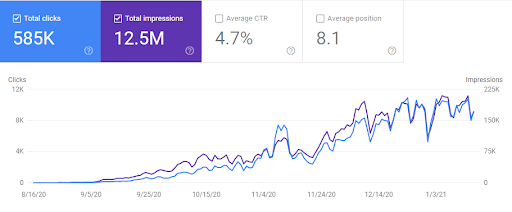
Di bawah, Anda akan melihat grafik Ahrefs GetWordly.com.
Dan, di bawah, Anda akan melihat Grafik SEMRush untuk GetWordly.com.
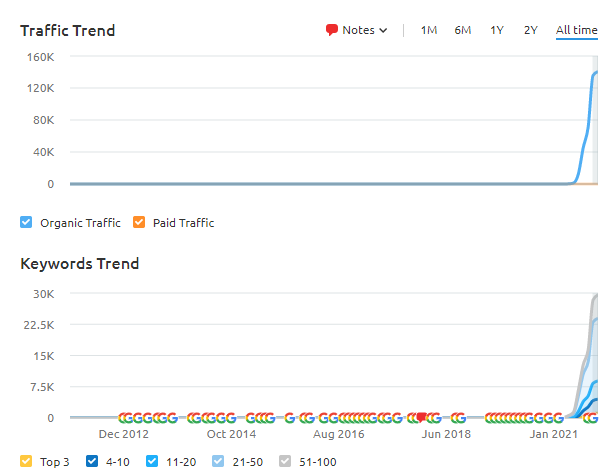
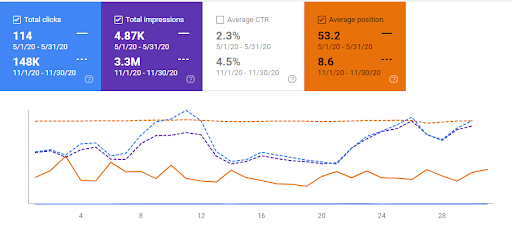
Proyek Ketiga: Peningkatan Lalu Lintas Organik 600% dalam 5 Bulan: Berfokus pada Azerbaijan
Situs web ketiga (Nama belum diungkapkan) mencapai pertumbuhan 600%. Dalam 5 bulan, lalu lintas organik bulanan meningkat menjadi 70.000 dari 10.000. (Volume lalu lintas lebih rendah dari contoh sebelumnya karena situs web ketiga hanya menargetkan Azerbaijan.)
Di bawah ini, Anda akan melihat grafik 6 bulan terakhir untuk Grafik GSC situs ketiga.
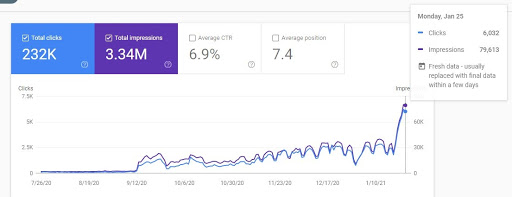
Dan, di bawah ini Anda akan melihat 7 bulan terakhir dari "bagian kamus".
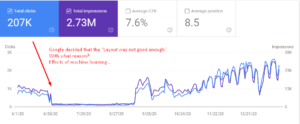
Anda dapat melihat bahwa "dalam satu hari" "bagian kamus" situs web telah kehilangan semua lalu lintasnya. Kami tidak mengubah apa pun. Semua perbedaan datang dari sistem internal Google sendiri. Sejak Google mulai sepenuhnya mengandalkan "Pembelajaran Mendalam" dan "Pembelajaran Mesin", saya tahu bahwa mereka juga mengevaluasi "tata letak halaman" sesuai dengan "umpan balik umum" yang mereka kumpulkan dari web.
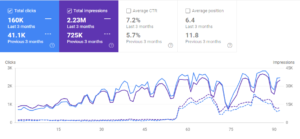
Perbandingan 3 Bulan Terakhir untuk Proyek Ketiga.
Jadi, kami baru saja mengubah tata letak halaman, dengan beberapa "perubahan warna latar belakang" dan hanya "urutan elemen halaman", dan semuanya kembali normal, dalam dua hari.
Meskipun bagian dari studi kasus dan eksperimen SEO ini bukan tentang SEO semantik, sebagai SEO Holistik, saya hanya ingin mengatakan bahwa terkadang Anda harus fokus pada "hal yang berbeda". Di bawah ini, Anda akan melihat “Vektor Representasi Situs Web” dari Google Patents.
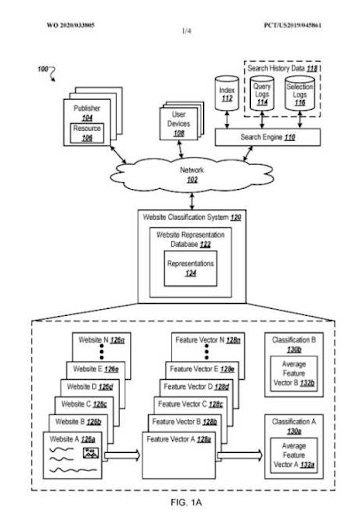
Vektor Representasi Situs Web dapat digunakan untuk memahami “kemungkinan kepuasan pengguna” setelah diklik oleh mesin pencari.
Proyek Keempat: Pertumbuhan Lalu Lintas Organik 400% – Berfokus pada Negara-negara Arab
Situs web keempat (Nama Belum Diungkapkan) menargetkan seluruh Dunia Arab. Karena fokus utama saya bukan pada situs web (karena saya tidak berbicara bahasa Arab), hanya pertumbuhan 400% yang tercapai.
Di bawah ini, Anda akan melihat grafik 6 bulan terakhir untuk Grafik GSC situs keempat.
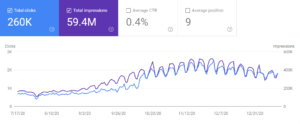
Menurut pendapat saya, untuk situs web ini, kami tidak memiliki peningkatan lalu lintas yang cukup sesuai dengan kekuatan SEO semantik. Itu karena kurangnya kemampuan bahasa Arab. SEO teknis adalah "agnostik bahasa" sementara SEO semantik sangat terikat pada sifat kata, istilah, konsep, dan bahasa.
Sebagai bukti terakhir dari SEO semantik, Anda akan melihat Perbandingan Kinerja Lalu Lintas Organik GSC 3 Bulan untuk proyek keempat.
Penjelasan Singkat Web Semantik, Pencarian Semantik, dan Otoritas Topik
Web semantik adalah keadaan organisasi informasi di web. Web semantik menggunakan dua elemen dasar yang berasal dari alam otak manusia dan alam semesta: taksonomi dan ontologi.
Taksonomi berasal dari "taksi" + "nomia", yang berarti "pengaturan sesuatu". Ontologi berasal dari kata “ont” + “logi” yang berarti “esensi dari segala sesuatu”. Keduanya merupakan sarana untuk mendefinisikan entitas dengan mengklasifikasikannya ke dalam kelompok dan kategori. Bersama-sama, taksonomi dan ontologi membentuk web semantik.
Selama sepuluh tahun terakhir, Google telah menciptakan beberapa inisiatif yang bergerak menuju web semantik.
Pada tahun 2011, Google mengumumkan "Mesin Pencari Terstruktur" untuk menyusun informasi di web.
Dan, pada Mei 2012, mereka meluncurkan Grafik Pengetahuan untuk lebih memahami informasi tentang entitas dunia nyata.
Pada 2019, mereka meluncurkan BERT, sebuah model untuk pemahaman yang lebih baik tentang hubungan antara kata, konsep, dan entitas dalam bahasa dan persepsi manusia.
Semua proses ini menciptakan web semantik, pencarian semantik, Google sebagai mesin pencari semantik, dan akibatnya SEO semantik.
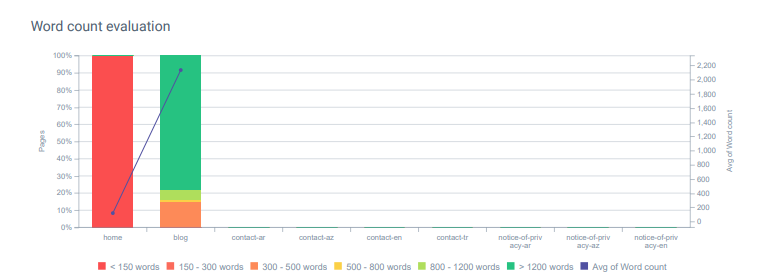
Evaluasi jumlah kata GetWordly.com di OnCrawl. Sebagian besar konten dari proyek ini mencakup lebih banyak detail dan informasi daripada pesaingnya.
Apa yang dimaksud dengan Otoritas Topik dan Cakupan Topik dalam Konteks ini?
Dalam web semantik dan terorganisir, setiap sumber informasi memiliki tingkat cakupan yang berbeda untuk topik yang berbeda. Benda atau entitas terhubung satu sama lain melalui atribut bersama mereka. Atribut ini mewakili "Ontologi". Hal-hal juga terhubung satu sama lain dalam hierarki klasifikasi . Hirarki ini mewakili "Taksonomi". Untuk menjadi otoritas untuk suatu topik di mata mesin pencari semantik, sumber harus mencakup atribut yang berbeda dari suatu hal dalam konteks yang berbeda. Itu juga harus merujuk pada hal-hal serupa, dan hal-hal dalam kategori induk dan anak.
Membuat jaringan konten untuk setiap "sub-topik", untuk setiap pertanyaan yang mungkin, dalam relevansi kontekstual dan hierarki dengan tautan internal logis dan teks jangkar adalah kunci untuk studi kasus SEO ini.
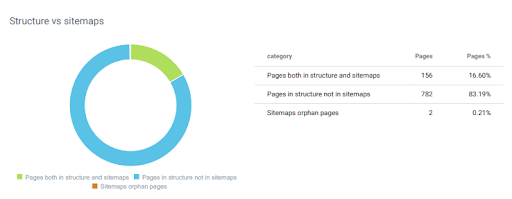
Seperti yang dikatakan OnCrawl, saya tidak menggunakan peta situs yang sehat selama studi kasus SEO ini. Situs di sini lagi GetWordly.com
Otoritas Topik dan Cakupan Topik dapat diperoleh dengan jaringan konten komprehensif yang paling rinci, berorientasi entitas, dan terorganisir secara semantik. Setiap bagian konten yang berhasil meningkatkan peluang keberhasilan konten lain untuk entitas yang terhubung dan kueri terkait.
Untuk membuat semuanya singkat, saya akan beralih ke bagian "lakukan" dan "jangan". Jika Anda membutuhkan lebih banyak detail atau pemahaman tentang topik ini, saya sarankan Anda membaca artikel yang saya sebutkan sebelumnya.
Apa yang Harus Anda Lakukan untuk Menerapkan SEO Semantik?
Untuk memahami konsep SEO semantik sepenuhnya, Anda perlu memahami mengapa mesin pencari membutuhkan web untuk menjadi semantik. Apalagi dengan dominasi sistem peringkat mesin pencari berbasis pembelajaran mesin alih-alih sistem peringkat mesin pencari berbasis aturan dan penggunaan teknologi pemrosesan & pemahaman bahasa alami, kebutuhan ini semakin meningkat. Jadi pendekatan konsep-konsep ini melalui mata mesin pencari untuk memahami saran di bawah ini.
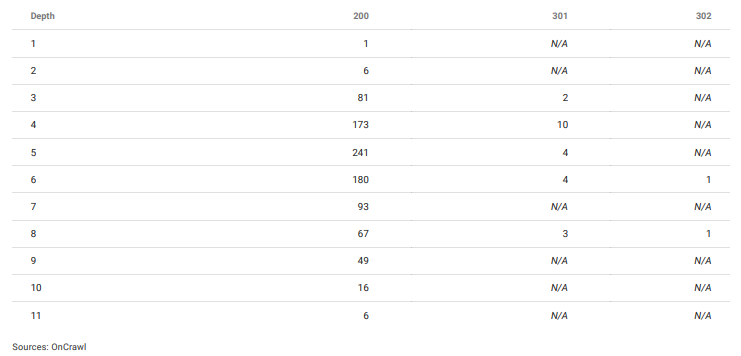
Karena saya tidak menggunakan menu "header" atau "footer" apa pun, sebagian besar halaman benar-benar sangat dalam.
1- Buat Peta Topik Sebelum Mulai Mempublikasikan Artikel Pertama
Ingat ontologi dan taksonomi? Anda harus memeriksa Grafik Pengetahuan Google karena untuk Google, hal-hal dapat terhubung satu sama lain dengan cara yang berbeda dari menurut Kamus atau Ensiklopedia. Google menggunakan web dan informasi yang disediakan oleh para insinyur untuk pengenalan entitas dan perhitungan vektor kontekstualnya.
Dengan demikian, Anda juga harus memeriksa SERP untuk melihat entitas mana yang telah terhubung ke mana dan dengan cara apa untuk kueri mana…
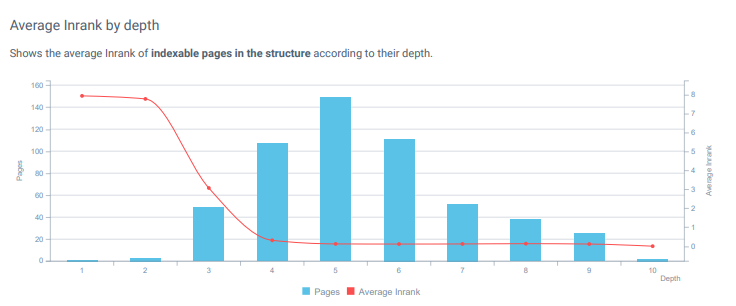
Inrank adalah formula Distribusi "Internal PageRank" OnCrawl yang terinspirasi oleh formula PageRank pertama dan asli Google. Dan kami melihat bahwa Inrank telah jatuh ke halaman yang jauh dari beranda.
Ini mungkin sedikit melelahkan tetapi setelah beberapa saat, Anda akan melihat bagaimana Google berpikir, bertindak, dan menghubungkan berbagai hal satu sama lain. Ada beberapa praktik cepat yang dapat Anda lakukan untuk memeriksa niche dan grup kueri untuk membuat peta topikal.
- Merangkak peta situs pesaing Anda untuk memahami peta topikal mereka.
- Tarik kueri terkait Google Trends dan topik terkait.
- Kumpulkan data dari pelengkapan otomatis dan saran penelusuran.
- Perhatikan bagaimana pesaing Anda menghubungkan hub konten.
- Gunakan Grafik Pengetahuan Google untuk menarik entitas yang relevan.
- Gunakan sumber daya non-web untuk melihat properti entitas serta hierarki dan koneksinya.
Item terakhir juga penting untuk menjadi sumber yang menyediakan informasi asli dan otoritatif untuk basis pengetahuan mesin pencari.
PS: Gunakan juga mesin pencari lainnya. Saya terutama menyarankan Anda memeriksa Swisscows untuk memahami sifat mesin pencari semantik. Jangan hanya fokus pada Google untuk memahami pencarian semantik.
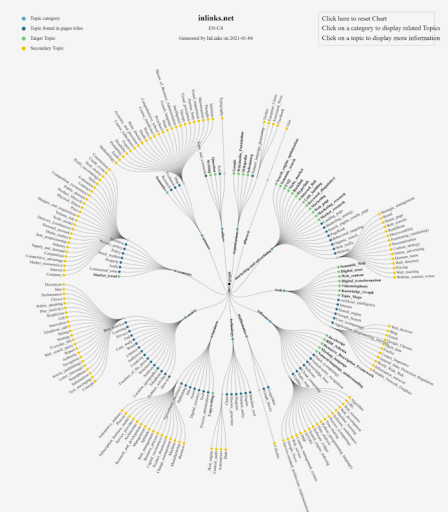
Ini adalah contoh Topical Map (Grafik Topikal) dari Inlinks.net. Karena, ini adalah teknologi unik dan InLinks adalah satu-satunya Perusahaan SEO yang berfokus pada SEO semantik , saya sarankan Anda memeriksa teknologi mereka.
2- Tentukan Jumlah Tautan per Halaman
Dalam semua studi kasus dan pencapaian SEO ini, jumlah total tautan di setiap halaman web paling banyak 15.
Sebagian besar tautan ini ada di konten utama, dengan teks jangkar yang relevan dan alami. Saya tidak menggunakan menu footer atau header. Ini bertentangan dengan rekomendasi tradisional dalam SEO teknis. Saya harus menerimanya dan saya tidak mengatakan bahwa Anda harus menggunakan tidak lebih dari 15 tautan per halaman web. Saya mengatakan bahwa Anda harus menyimpan tautan yang relevan dan kontekstual di dalam konten utama, dan mencoba membuat mesin pencari fokus pada tautan tersebut.
Anda dapat menggunakan item berikut untuk menentukan jumlah tautan internal yang benar yang akan muncul di halaman web:
- Standar industri untuk jumlah tautan internal untuk memahami nilai minimum dan maksimum.
- Jumlah Entitas yang Dinamakan dalam konten
- Jumlah konteks untuk Entitas Bernama
- Tingkat "perincian" konten
- Maksimal 1 link di setiap bagian heading
- Menghubungkan entitas dengan tipe yang sama ke halaman masing-masing jika mereka berada dalam "format daftar".
[Studi Kasus] Mendorong pertumbuhan di pasar baru dengan SEO pada halaman
 Baca studi kasus
Baca studi kasus3- Menentukan Anchor Text dengan Cara yang Alami dan Relevan dalam hal Jumlah, Kata, dan Posisi
Saya tidak akan membahas kebutuhan tautan internal yang alami dan bagaimana mereka melewati PageRank. Saya telah membahas ini secara rinci di “Cara Menjadi Pemenang dari Setiap Pembaruan Algoritma Inti Google”, yang saya sarankan Anda baca.
Namun, saya akan memberi tahu Anda secara singkat bahwa saya tidak pernah menggunakan teks jangkar lebih dari tiga kali untuk halaman web dalam konten utama. Dengan kata lain, untuk keempat kalinya, saya sarankan Anda menambahkan lebih banyak kata atau mengubah beberapa kata di dalam teks jangkar.
Saya juga memiliki beberapa jenis aturan lain untuk teks jangkar:
- Saya tidak pernah menggunakan teks di paragraf pertama halaman sebagai teks jangkar di tautan ke halaman itu.
- Saya tidak pernah menggunakan kata pertama dari paragraf mana pun di halaman sebagai teks jangkar ke halaman itu.
- Jika saya menautkan artikel ke artikel lain dari konteks atau topik sampingan yang berbeda, saya selalu menggunakan salah satu paragraf judul terakhir (Google menyebut jenis koneksi ini "Konten Tambahan".)
- Saya selalu memeriksa teks jangkar pesaing untuk artikel tertentu secara internal dan eksternal.
- Saya selalu mencoba menggunakan sinonim untuk suatu topik saat membuat teks jangkar.
- Saya selalu memeriksa apakah "anchor text" ada di konten halaman web yang ditargetkan dan teks judul terkait sumber tautan atau tidak.
PS: Saya tidak mengatakan bahwa Anda harus melakukan ini untuk melakukan SEO semantik yang sukses. Ini hanyalah beberapa contoh pedoman yang saya ikuti ketika saya memperoleh hasil ini. Jika Anda menemukan beberapa contoh yang tidak sesuai dengan pedoman ini, mungkin karena penulis saya yang baik.
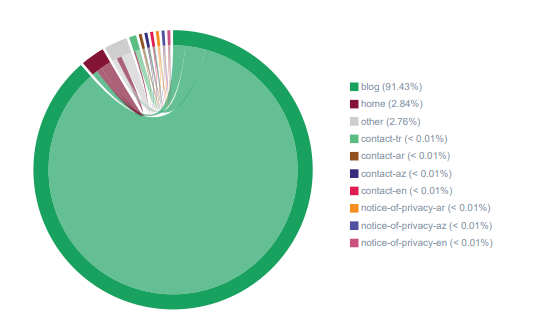
Distribusi Aliran Inrank OnCrawl untuk Kategori URL yang berbeda. Karena saya tidak mengkategorikan apa pun pada proyek-proyek ini, sebagian besar "hijau" dan berarti bahwa bagian terpenting adalah blog.
4- Tentukan Vektor Kontekstual
Terminologi ini bisa menjadi sedikit "garing" di telinga Anda, sekali lagi. Ini adalah istilah dari Google Patents, bagi saya. Vektor kontekstual, domain kontekstual, frasa kontekstual… Ada banyak hal yang perlu digali di Google Patents (terima kasih lagi kepada Bill Slawski, pendidik kami).
Sederhananya, vektor kontekstual adalah sinyal untuk menentukan sudut konten. Topik dapat berupa “gempa” dan konteks dapat berupa “membandingkan gempa”, “menebak gempa”, atau “kronologi gempa”.
Misalnya, "apel" (buah) adalah entitas dan juga topik, dan Healthline memiliki lebih dari 265 artikel hanya untuk "apel". Manfaat apel, nutrisi apel, jenis apel, pohon apel (pada dasarnya, entitas dan topik yang berbeda, tetapi cukup dekat.)
Jadi, dalam konteks ini, semua situs ini berasal dari industri pendidikan bahasa kedua. “Pembelajaran Bahasa Inggris” adalah topik utama; belajar bahasa Inggris dari game, video, film, lagu, teman… adalah konteks yang berbeda.
Untuk membuat koneksi yang lebih kontekstual, saya selalu mencoba mengisi kesenjangan antara berbagai topik dan entitas di dalamnya dengan bantuan berbagai jenis konten klaster pilar. Saya juga menyarankan Anda untuk membaca tentang vektor kontekstual dan domain pengetahuan Google dari paten mereka.

Tabel status tautan internal OnCrawl. Tidak ada kode status "tautan internal" yang jelas dan jalur perayapan untuk mesin telusur.
5- Tentukan Jumlah Konten yang Akan Ditulis dan Diterbitkan
Jumlah konten bukan merupakan faktor peringkat. Sebenarnya, menceritakan lebih banyak hal dengan lebih sedikit konten dengan artikel yang lebih komprehensif dan berwibawa lebih baik untuk banyak aspek seperti anggaran perayapan, distribusi PageRank, pengenceran backlink, atau masalah kanibalisasi.
Namun, jumlah konten penting untuk merencanakan prosesnya. Karena, Anda perlu mengetahui berapa banyak penulis yang Anda perlukan, atau berapa banyak artikel yang akan Anda terbitkan per hari atau per minggu. Saya tidak memasukkan banyak istilah SEO dalam ringkasan eksekutif ini seperti publikasi konten dan frekuensi pembaruan konten… Tapi, bahkan jika Anda menentukan topik, konten, konteks, entitas, Anda masih tidak tahu berapa banyak konten yang Anda perlukan. Terkadang Google lebih memilih situs yang menampilkan konteks berbeda untuk suatu topik di halaman yang sama, namun dalam kasus lain Google lebih suka melihat konteks berbeda di halaman berbeda.


Rata-rata Heading Count per level heading pada halaman web berada di atas. Jumlah judul per jenis judul dapat mengungkapkan detail konten, panjang, dan tingkat perincian untuk SEO.
Untuk mengetahui jumlah pasti konten/artikel, memeriksa jenis SERP Google, bentuk jaringan konten pesaing adalah penting. Ini juga penting untuk anggaran proyek . Jika Anda memberi tahu pelanggan Anda bahwa Anda hanya membutuhkan 120 konten tetapi kemudian, Anda menyadari bahwa Anda sebenarnya membutuhkan 180 konten, itu adalah masalah kepercayaan yang serius.
Dan, untuk setiap kisah sukses SEO, komunikasi yang jelas adalah suatu keharusan.
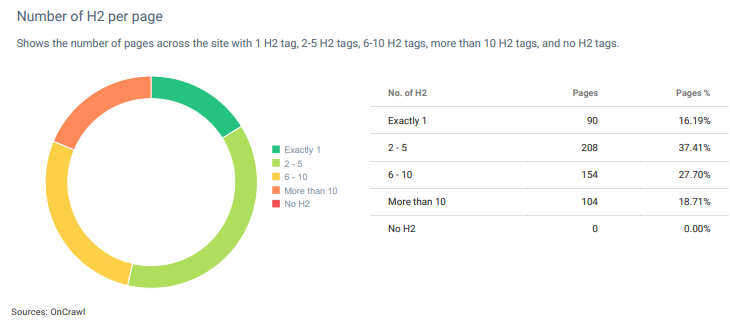
Dari jumlah H2, Anda dapat memahami tingkat detail pada halaman web jika sumbernya tidak menggunakan "kalimat omong kosong" untuk struktur kontennya.
6- Tentukan Kategori dan Hirarki URL
Kategori URL tidak digunakan dalam studi kasus SEO mana pun di sini. Namun, ini tidak berarti bahwa kategori URL dan remah roti yang sesuai tidak bermanfaat untuk SEO semantik. Menyimpan konten serupa di folder yang sama di jalur URL Anda memudahkan mesin telusur untuk memahami situs web. Ini juga memberikan tip bagi pengguna dan memfasilitasi navigasi di dalam situs.
Jika itu masalahnya, mengapa saya tidak menggunakannya? Untuk dua alasan yang sama saya tidak menggunakan SEO teknis: karena keterbatasan waktu dan karena saya ingin menjalankan eksperimen SEO di masa mendatang.
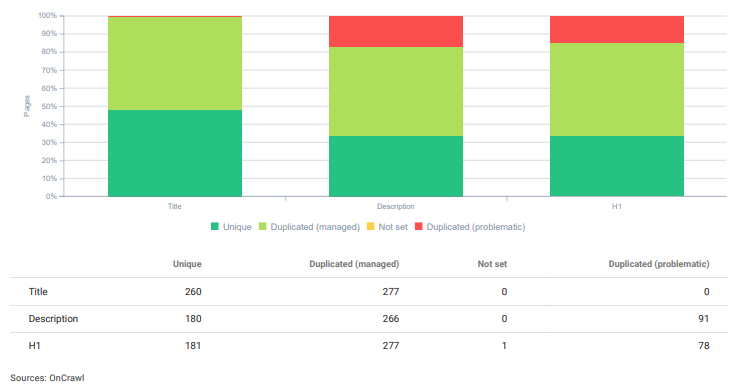
Duplikasi Bermasalah dan Terkelola ada di seluruh situs untuk Proyek SEO ini.
7- Buat Hirarki Topikal dengan Vektor Kontekstual dengan Menyesuaikannya dengan Hirarki URL
Sub-topik telah dikonfirmasi untuk digunakan oleh Google selama Januari 2020 tetapi sebenarnya, Google telah menyebut mereka sebagai "Jaringan Neural" atau "Jaringan Saraf" sebelumnya. Di saluran YouTube Pengembang Google, mereka juga menunjukkan ringkasan yang bagus tentang bagaimana topik terhubung satu sama lain dalam hierarki dan logika. Itu sebabnya sekali lagi, taksonomi dan ontologi adalah kunci untuk SEO semantik.
Tapi, apa yang dimaksud dengan “membuat Hirarki Topikal dengan Vektor Kontekstual”? Ini berarti bahwa setiap topik harus telah diproses dengan setiap kemungkinan konteks dan entitas terkait dengan dikelompokkan dengan struktur URL logis.
Ini akan mengarahkan mesin pencari untuk memberikan sumber otoritas dan keahlian topikal yang lebih baik berkat arsitektur informasi yang lebih terperinci dan terperinci.
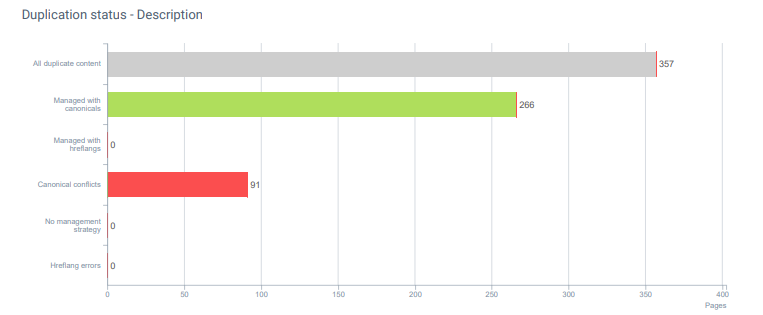
Kami juga memiliki "konflik kanonik".
8- Sesuaikan Vektor Pos
Heading Vectors… Istilah lain yang masih asing di telinga banyak orang. Vektor heading sebenarnya adalah urutan heading sebagai sinyal untuk menentukan sudut utama dan topik konten. Menurut Pedoman Penilai Kualitas Google, konten dipandang memiliki tiga bagian berbeda: “Konten Utama”, “Iklan”, dan “Konten Tambahan”.
Kita semua tahu bahwa Google memberi bobot lebih pada konten di paro atas atau di “bagian atas” artikel. Itu sebabnya kueri di bagian atas konten selalu memiliki peringkat yang lebih baik daripada kueri di bagian bawah. Bagi Google, bagian bawah sebenarnya mewakili “konten tambahan.”
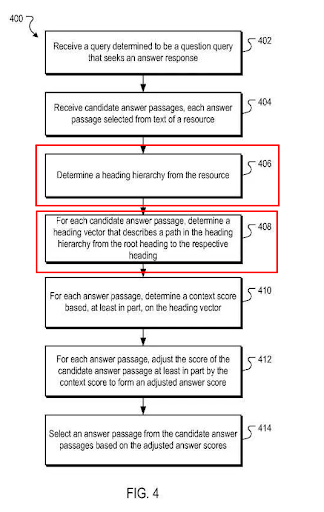
Representasi metodologi Google untuk Penghitungan Skor Passage Jawaban Kontekstual melalui Vektor Heading.
Itulah mengapa menggunakan relevansi kontekstual dan logika dalam hierarki heading itu penting. Sederhananya, berikut adalah beberapa panduan dasar untuk menuju vektor dalam perspektif saya tentang SEO semantik:
- Apa pun yang dikatakan mesin pencari, gunakan tag HTML semantik, termasuk tag heading.
- Vektor heading dimulai dari tag judul, sehingga heading dan tag judul harus saling melengkapi.
- Setiap judul harus fokus pada informasi yang berbeda dan paragraf apa pun setelah judul tersebut tidak boleh mengulangi informasi yang diberikan sebelumnya.
- Judul yang berfokus pada ide yang sama harus dikelompokkan bersama.
- Judul apa pun yang harus menyertakan entitas lain juga harus ditautkan ke sana.
- Setiap konten heading harus memiliki format yang tepat dengan daftar, tabel, definisi deskriptif…
Seperti yang Anda lihat, segala sesuatu tentang bagian ini sebenarnya memiliki logika dasar. Tidak ada yang baru. Namun, izinkan saya menunjukkan salah satu paten Google, “Penyesuaian penilaian konteks untuk bagian jawaban” di bawah ini.

Sumber: Penyesuaian penilaian konteks untuk bagian jawaban
Menggunakan vektor heading, Google mencoba memilih bagian mana yang memiliki vektor kontekstual terbaik untuk kueri tertentu. Jadi itulah mengapa saya menyarankan Anda membuat struktur logis yang jelas di antara judul-judul ini.
Jika mau, Anda juga dapat membaca paten ini dari sudut pandang analitis Bill Slawski: Menyesuaikan Jawaban Cuplikan Unggulan berdasarkan Konteks.
Mulai uji coba gratis selama 14 hari
 Mulai uji coba Anda
Mulai uji coba Anda9- Hubungkan Entitas Terkait untuk Topik dalam Konteks
Menghubungkan entitas dan asosiasi entitas adalah istilah yang dekat satu sama lain. Asosiasi entitas dapat dilakukan oleh mesin telusur berdasarkan atribut entitas dan juga melalui cara kueri diutarakan untuk kemungkinan maksud penelusuran.
Menghubungkan entitas dan menghubungkan entitas satu sama lain dalam suatu konteks adalah aplikasi praktis ontologi. Misalnya, dalam konteks industri proyek SEO ini yaitu “Pembelajaran Bahasa Inggris”, untuk topik “Kata Kerja Phrasal”, Anda juga dapat menggunakan “Kata Kerja Tidak Beraturan”, “Kata Kerja yang Paling Banyak Digunakan”, “Kata Kerja Berguna untuk Pengacara ”, “Etimologi kata kerja asal latin”, “Kata kerja yang kurang dikenal” yang dapat dihubungkan satu sama lain.
Tag HTML terkait SEO harus dioptimalkan dalam hal panjang dan istilah di dalamnya. Dalam proyek-proyek ini, saya tidak mengimplementasikannya, seperti yang mungkin Anda lihat.
Semua konteks itu sebenarnya berfokus pada “kata kerja dalam bahasa Inggris”. Semuanya terkait dengan “Aturan Tata Bahasa”, “Contoh Kalimat”, “Pengucapan”, dan “Beda Tenses”. Anda dapat merinci, menyusun, mengkategorikan, dan menghubungkan semua konteks dan entitas ini satu sama lain.
Setelah Anda pada dasarnya mencakup setiap konteks yang mungkin untuk suatu topik dan semua entitas terkait, mesin pencari semantik tidak memiliki kesempatan lain selain memilih Anda sebagai sumber tepercaya untuk kemungkinan maksud pencarian untuk ini.
10- Hasilkan Pertanyaan dan Jawaban untuk Kemungkinan Maksud Pencarian
“Menghasilkan Pertanyaan dari Jawaban”… Paten Google lainnya. Tapi, karena artikel ini sudah cukup panjang, saya tidak akan membahasnya secara detail. Pada dasarnya, mesin pencari menghasilkan pertanyaan dari konten di web dan mencocokkan pertanyaan ini dengan kueri dengan penulisan ulang kueri. Dan menggunakan pertanyaan ini untuk menutup kemungkinan kesenjangan konten untuk kemungkinan maksud pencarian di web.
Itu sebabnya saya memberitahu Anda untuk memproses setiap entitas dengan setiap konteks sambil menghubungkan mereka satu sama lain. Namun, Anda juga harus tahu apa itu ekstraksi informasi. Ekstraksi informasi adalah menarik fakta-fakta penting dan koneksi definitif tentang konsep dari sebuah dokumen. Berkat ekstraksi informasi, Mesin Pencari dapat memahami pertanyaan mana yang dapat dijawab dari dokumen atau fakta mana yang dapat dipahami. Ekstraksi informasi bahkan dapat digunakan untuk membuat grafik pengetahuan antara entitas dan atributnya, dan digunakan untuk menghasilkan pertanyaan terkait.

Menghasilkan Pertanyaan Terkait untuk Kueri Penelusuran
Anda seharusnya tidak hanya fokus pada VOLUME PENCARIAN! Bahkan mungkin belum ada yang menanyakan pertanyaan ini sebelumnya. Dan bahkan mesin pencari mungkin tidak tahu jawaban atas pertanyaan ini. Tetapi jika informasi unik ini berguna untuk mendefinisikan atribut entitas dalam topik, buat dan jawab pertanyaan ini, dan jadilah sumber informasi unik untuk web dan untuk mesin telusur di niche Anda.
11- Temukan Kesenjangan Informasi Alih-alih Kesenjangan Kata Kunci
Pertama, baca kutipan di bawah ini.
“Skor perolehan informasi untuk dokumen tertentu menunjukkan informasi tambahan yang disertakan dalam dokumen di luar informasi yang terkandung dalam dokumen yang sebelumnya dilihat oleh pengguna.”

Sumber: Paten “Estimasi Kontekstual Perolehan Informasi Tautan”
Kita semua tahu bahwa bahkan baru-baru ini pada tahun 2020, “15% kueri setiap hari adalah baru dan Google menggunakan RankBrain untuk mencocokkan kueri ini dengan kemungkinan maksud pencarian dan dokumen baru”. Google juga selalu mencari informasi dan jawaban unik untuk kemungkinan pertanyaan di masa mendatang dari penggunanya. Berikan informasi unik, dan cobalah untuk memuat "istilah, informasi terkait, pertanyaan, studi, orang, tempat, acara, dan saran" yang kurang dikenal.
Jadi, "konten yang lebih panjang" atau "kata kunci" bukanlah kunci untuk studi kasus SEO ini. "Informasi lebih lanjut" dan "pertanyaan unik" dan "koneksi unik" adalah kuncinya. Setiap konten untuk proyek ini memiliki judul unik yang bahkan tidak terkait dengan volume pencarian dan bahkan pengguna mungkin tidak menyadarinya.
Di bawah ini, Anda akan melihat Google Patent lain untuk menunjukkan relevansi kontekstual untuk kueri tambahan dan kemungkinan aktivitas pencarian terkait.
Kueri Pencarian Tertambah Menggunakan Informasi Grafik Pengetahuan
“Memasukkan setiap entitas terkait dengan koneksi kontekstualnya sambil menjelaskan intinya” dapat dilihat juga di sini dengan kepentingannya.
12- Berhenti Peduli Tentang Volume atau Kesulitan Kata Kunci
Saya sudah membagikan pendapat saya tentang volume kata kunci. Selama empat proyek ini, saya melihat diri saya sebagian besar sebagai seorang yang menciptakan “buku pendidikan” yang berkualitas dan dapat dipahami.
- Pada awal proyek, pesaing otoritatif dengan banyak backlink tidak mengintimidasi saya.
- Saya tidak peduli dengan metrik pihak ketiga seperti kesulitan kata kunci.
- Data historis dan kekuatan merek pesaing tidak membuat saya takut.
- Dan akhirnya, saya menghindari menggunakan "Saya baru saja menggunakan Google Search Console untuk menunjukkan kepada klien saya situasi proyek terbaru". Kecuali untuk meninjau reaksi Google, saya tidak masuk ke GSC.
Saat menulis artikel, jika subtopik diperlukan dalam struktur semantik topik, itu harus ditulis. Itu harus ditulis bahkan jika volume pencarian adalah "0". Itu harus ditulis bahkan jika kesulitan kata kunci adalah 100.
Ada poin penting lainnya di sini.
Jika Anda ingin peringkat pertama di SERP untuk "frasa", Anda harus memasukkan semua frasa yang relevan, dan setiap detail di semua grafik topikal yang relevan. Dengan kata lain, tidak mungkin dengan SEO semantik untuk melihat peningkatan peringkat dalam kueri yang terkait dengan topik itu tanpa sepenuhnya memproses setiap topik terkait.
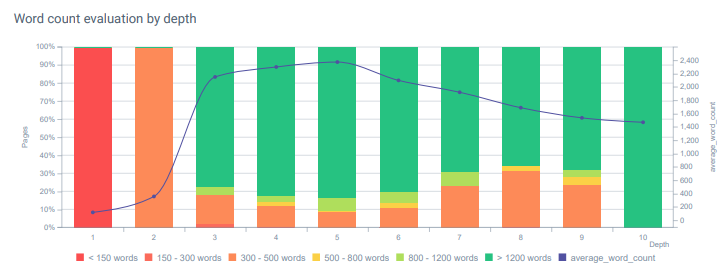
Evaluasi Jumlah Kata berdasarkan kedalaman halaman. Semakin tua konten, kedalaman klik halaman meningkat pada contoh ini karena kami tidak menggunakan navigasi internal standar. Tetapi bahkan di kedalaman 10, kami memiliki konten yang lebih kuat daripada pesaing kami. Hal ini mendorong Google untuk melihat lebih jauh dan lebih dalam.
13- Fokus pada Cakupan Topik dan Otoritas dengan Data Historis
Grafik topikal adalah grafik yang menunjukkan topik mana yang saling berhubungan dalam hubungan mana. Cakupan topikal berarti seberapa baik Anda menutupi grafik ini. Data historis mengacu pada berapa lama Anda telah meliput grafik topikal ini pada tingkat tertentu.
Otoritas Topik = Cakupan Topik * Data Historis
Itulah mengapa di setiap grafik yang saya tunjukkan, Anda melihat "pertumbuhan pesat" setelah jangka waktu tertentu. Dan karena saya menggunakan pemrosesan dan pemahaman bahasa alami, sebagian besar pertumbuhan lalu lintas organik awal yang cepat dengan bentuk gelombang ini berasal dari cuplikan unggulan.
Jika Anda dapat mengambil cuplikan unggulan untuk suatu topik, itu berarti Anda telah mulai menjadi sumber yang otoritatif dengan struktur konten yang mudah dipahami untuk mesin telusur.
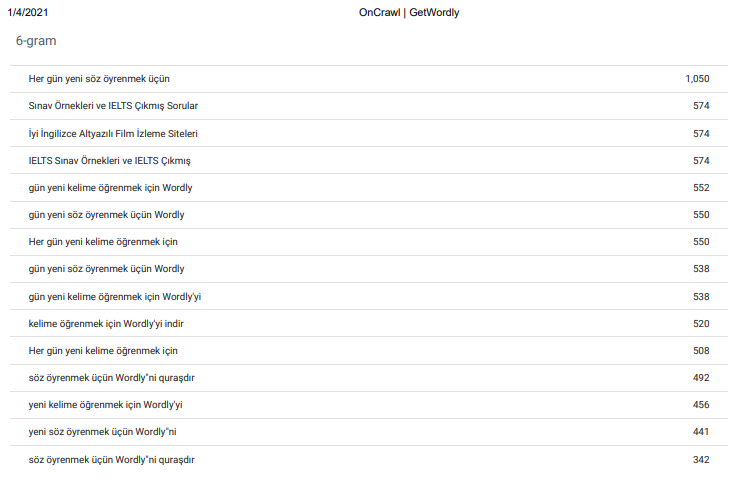
Analisis N-Gram adalah salah satu fitur terbaik OnCrawl bagi saya. Dan itu adalah fitur unik untuk SEO Crawler. Anda dapat melihat “Analisis 6 gram sebagai seluruh situs” di atas. “Belajar dan mengajar bahasa Inggris” (Ingilizce Ogrenmek ve Ogretmek) adalah tema utama dari entitas ini seperti yang terlihat.
14- Gunakan Ketentuan Pemrosesan Bahasa Alami dengan Penulis Anda untuk Menentukan Struktur Kalimat dan Format Konten Terbaik
Didik penulis Anda.
Tunjukkan pada mereka bagaimana Google menggunakan NLP dan NLU. Ajari mereka apa itu "Tag Bagian dari Ucapan" atau apa itu "Pengenalan Entitas Bernama" dan "Tautan Entitas Bernama". Gunakan N-Grams, Skip-Grams, Word2Vec dengan hasil dan praktik nyata untuk membuat mereka memahami analisis teks yang dijalankan mesin. Tunjukkan kepada mereka cara kerja Grafik Pengetahuan Google.
Ajari mereka apa itu Neural Matching atau Entity Type Matching. Tunjukkan kesalahan mereka atas Google Documents saat merevisi konten mereka, lalu tunjukkan kepada mereka pertumbuhan lalu lintas organik dengan cuplikan unggulan.
Saya terkadang menyebutnya “Pemasaran Konten Berorientasi Cuplikan Unggulan” . Kita semua tahu bahwa Google hanya menggunakan model NLP untuk memahami konten dan jujur, mengalahkan bahkan pesaing paling otoritatif lebih mudah daripada di tahun 2011, berkat algoritma berbasis NLP Google.
Dan, seperti yang saya katakan di awal Manifesto SEO Semantik ini, saya kehilangan semua cuplikan fitur dalam satu hari. Ini terjadi ketika Google melakukan pembaruan kecil yang menurunkan persentase cuplikan unggulan sebesar 4% dalam satu hari. Pada saat yang sama, server kami sedang down karena lalu lintas yang berlebihan. Selain itu, untuk membuat "permintaan reranking", saya telah memperbarui banyak konten sambil terus menerbitkan konten baru.
Cara Google mencoba memahami apakah suatu konten berbasis opini atau fakta. Nama paten: Pembelajaran mesin untuk mengidentifikasi opini dalam dokumen.
Di bawah ini, Anda dapat menemukan beberapa aturan saya untuk penulis saya:
- Jangan pernah memberikan pendapat Anda dalam sebuah artikel.
- Jangan pernah menggunakan "bahasa sehari-hari" dalam artikel.
- Jangan menggunakan analogi.
- Jangan menggunakan kata-kata yang tidak perlu.
- Konten harus sesingkat mungkin dan selama diperlukan.
- Selalu gunakan kalimat pendek daripada kalimat panjang.
- Selalu memberikan jawaban secara langsung dan tepat.
- Selalu gunakan “sumber” sebagai otoritas sebelum memberikan pernyataan.
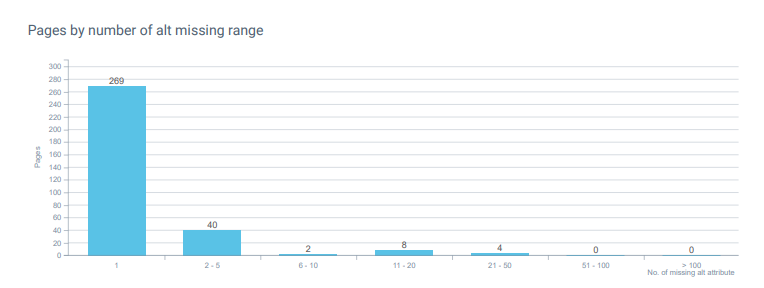
Dan, sebagai kejutan besar, saya tidak menggunakan "alt tag" untuk gambar. Tapi, karena ini juga merupakan masalah aksesibilitas, bahkan jika itu untuk eksperimen SEO, meninggalkan situs dalam situasi yang tidak dapat diakses rasanya tidak benar. Imagine that for an experiment, you remove the wheelchair entrance to a store. The same principle applies to websites.
Sometimes it is difficult to get your authors to follow these rules, and I am not saying that you must follow them.

I am saying that I (mostly) followed these rules during these SEO projects.
15- Educate Your Customer instead of Keeping them in the Dark
I see that most of the SEO agencies do not explain SEO's subtle sides to their customers. The main reason for this lies the basic side of their business model. SEO is a business model based on the subscription economy model. It means that customers should continue to buy the service.
But you can also use the “IKEA Effect” for your business. The IKEA Effect is when you make customers contribute to the work, and it makes them love you more. As an owner of a “one-man-one-desk” company, I use my customers' team for our SEO projects. In other words, I don't need an SEO team for myself because I already have multiple teams that I educate.
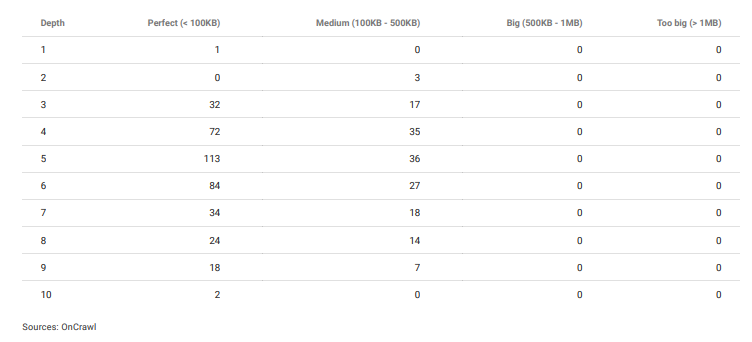
OnCrawl's response size report according to the click depth. Having a “bad design” can also be useful if you want to have “smaller response sizes”. It is not an intentional situation but it is a natural outcome.
And when the customer starts to understand, to learn from you and to work hands-on on their own project, they start to love SEO and they feel the IKEA Effect. They give more value to the SEO project through self-association and effort justification.
Thus, they will listen to you easier, and sharing the “real know-how” won't jeopardize your business. Instead, it will make things easier. I even educate interns or sometimes enter job interviews for my customers' job applicants, because their future team member is also my team member.
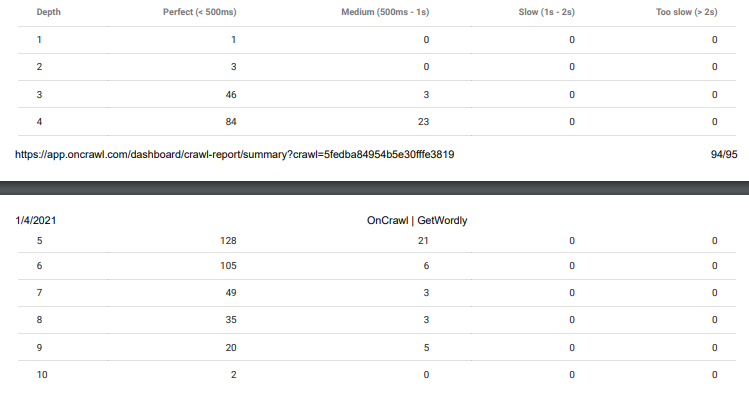
OnCrawl's response time report. After a server crash due to the organic traffic increase, we have bought a new server. That's why this crawl report shows better response timing. The other side of reality can be seen below.
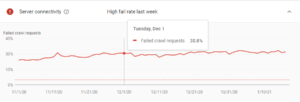
During the SEO case study and experiment, even the most important thing was not enough: the server. A screenshot from Interingilizce.com's Server Connectivity report from Google Search Console's Crawl Stats Report.
As an entrepreneur, this is my own model that is born from my own conditions. I hope this also fits for you as in other articles. Semantic SEO relies on patience, costly authors, highly theoric SEO terms, and content engineering with algorithmic knowledge. Without educating the customer, it might not be possible to convince the customer to follow you on this road.
And when you do convince them, they are happier to work with you, even when you propose theories that sound new or different to them:
“Koray likes to apply new things to our projects in a very short time. We got huge spikes in our web sites with his strategy. We like his enthusiasm. If you don't work with him, you haven't seen an advanced SEO theory glossary.”
Savas Ates
Owner of the KonusarakOgren
Last Thoughts on Semantic SEO
While writing this guide for this SEO case study with four different SEO projects, I have tried to keep things simple as much as possible. And I have told everything with complete honesty. If you can endure long theoric articles with a deep analytical analysis for SEO, I recommend you read the article that I recommended in the beginning that explains more than 40 different lesser-known SEO terms to understand everything behind this methodology.
As you have seen, in order to focus on an initial, rapid gain in traffic, I neglected a lot of SEO improvements for these sites. Working on these different technical SEO elements that you have seen in screenshots throughout the article will also improve traffic even more, but I wanted to be able to clearly show you the effects of semantic SEO alone.
Thanks to deep learning and machine learning, semantic SEO will soon become a more popular strategy. And I believe that technical SEO and branding will give more power to the SEOs who give value to the theoretical side of SEO and who try to protect their holistic approach.
See you in the future SEO case studies and experiments.