
Cara memperkirakan pendapatan lalu lintas organik non-merek berdasarkan posisi URL dengan Python
Diterbitkan: 2022-05-24Apa itu perkiraan SEO?
Perkiraan SEO, atau estimasi lalu lintas organik, adalah proses menggunakan data situs Anda sendiri atau data pihak ketiga untuk memperkirakan lalu lintas organik situs Anda di masa mendatang, pendapatan SEO, dan ROI SEO. Estimasi ini dapat dihitung menggunakan banyak metode berbeda berdasarkan data kami.
Dalam tutorial ini, kami ingin memprediksi pendapatan organik tanpa merek dan lalu lintas organik tanpa merek berdasarkan posisi URL kami dan pendapatan mereka saat ini. Ini dapat membantu kami sebagai SEO untuk mendapatkan lebih banyak dukungan dari pemangku kepentingan lain: dari peningkatan anggaran bulanan, triwulanan, atau tahunan hingga lebih banyak jam kerja dari tim produk dan pengembang.
Ingatlah bahwa tutorial ini tidak hanya berlaku untuk lalu lintas organik non-merek; dengan membuat beberapa perubahan dan mengetahui Python, Anda dapat menggunakannya untuk memperkirakan lalu lintas halaman target Anda.
Hasilnya, kita bisa menghasilkan Google Sheet seperti gambar di bawah ini.
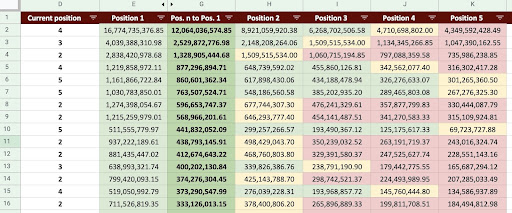
Gambar Google Spreadsheet
Prakiraan lalu lintas SEO non-merek
Pertanyaan pertama yang mungkin Anda tanyakan setelah membaca pendahuluan adalah, “Mengapa menghitung lalu lintas organik non-merek?”.
Mari kita pertimbangkan perusahaan seperti Amazon. Saat Anda ingin membeli buku atau topeng, Anda cukup mencari, “beli topeng amazon.”
Merek sering kali menjadi top of mind dan ketika Anda ingin membeli sesuatu, preferensi Anda adalah membeli barang yang Anda butuhkan dari perusahaan tersebut. Di setiap industri, ada perusahaan bermerek yang memengaruhi perilaku pengguna dalam pencarian Google.
Jika kami memeriksa data Google Search Console (GSC) Amazon, kami mungkin akan menemukan bahwa itu menerima banyak lalu lintas dari kueri bermerek, dan sebagian besar waktu, hasil pertama dari kueri bermerek adalah situs merek itu.
Sebagai seorang SEO, seperti saya, Anda mungkin sering mendengar bahwa, “Hanya merek kami yang membantu SEO kami!” Bagaimana kita bisa mengatakan, "Tidak, bukan itu masalahnya," dan menunjukkan lalu lintas dan pendapatan kueri non-merek?
Lebih rumit lagi untuk membuktikannya karena kita tahu bahwa algoritme Google sangat kompleks dan sulit untuk memisahkan dengan jelas penelusuran bermerek dan non-merek. Tapi inilah yang membuat apa yang kita lakukan sebagai SEO menjadi lebih penting.
Dalam tutorial ini, saya akan menunjukkan kepada Anda bagaimana membedakan keduanya – bermerek dan tidak bermerek – dan menunjukkan betapa hebatnya SEO.
Meskipun perusahaan Anda tidak bermerek, Anda masih dapat memperoleh banyak manfaat dari artikel ini: Anda dapat mempelajari cara memperkirakan data organik situs Anda.
ROI SEO berdasarkan estimasi lalu lintas
Di mana pun Anda berada atau apa yang Anda lakukan, ada batasan sumber daya; baik itu anggaran atau hanya jumlah jam dalam hari kerja. Mengetahui cara terbaik untuk mengalokasikan sumber daya Anda memainkan peran utama dalam keseluruhan dan laba atas investasi (ROI) SEO.
CMO, VP pemasaran, atau pemasar kinerja semuanya memiliki KPI yang berbeda dan memerlukan sumber daya yang berbeda untuk memenuhi tujuan mereka. Cara terbaik untuk memastikan Anda mendapatkan apa yang Anda butuhkan adalah membuktikan kebutuhannya dengan menunjukkan hasil yang akan diperoleh perusahaan. ROI SEO tidak berbeda. Ketika waktu alokasi anggaran tahun datang dan tim Anda ingin meminta anggaran yang lebih besar, memperkirakan ROI SEO Anda dapat memberi Anda keunggulan dalam bernegosiasi. Setelah Anda menghitung estimasi lalu lintas non-merek, Anda dapat mengevaluasi anggaran yang dibutuhkan dengan lebih baik untuk mencapai hasil yang diinginkan.
Pengaruh prediksi SEO pada strategi SEO
Seperti yang kita ketahui, setiap 3 atau 6 bulan sekali kami meninjau strategi SEO kami dan menyesuaikannya untuk mendapatkan hasil terbaik yang kami bisa. Namun apa jadinya bila Anda tidak tahu di mana keuntungan terbesar bagi perusahaan Anda? Anda dapat membuat keputusan, tetapi keputusan tersebut tidak akan seefektif keputusan yang dibuat saat Anda memiliki pandangan yang lebih komprehensif tentang lalu lintas situs.
Estimasi pendapatan lalu lintas organik non-merek dapat digabungkan dengan halaman arahan dan segmentasi kueri Anda untuk memberikan gambaran besar yang akan membantu Anda mengembangkan strategi yang lebih baik sebagai manajer SEO atau ahli strategi SEO.
Berbagai cara untuk memperkirakan lalu lintas organik
Ada banyak metode dan skrip publik yang berbeda di komunitas SEO untuk memprediksi lalu lintas organik di masa depan.
Beberapa metode tersebut antara lain:
- Prakiraan lalu lintas organik di seluruh situs
- Prakiraan lalu lintas organik pada halaman tertentu (blog, produk, kategori, dll) atau satu halaman
- Perkiraan lalu lintas organik pada kueri tertentu (kueri berisi "beli", "cara", dll.) atau kueri
- Prakiraan lalu lintas organik untuk periode tertentu (terutama untuk acara musiman)
Metode saya adalah untuk halaman tertentu dan jangka waktu untuk satu bulan.
[Studi Kasus] Mendorong pertumbuhan di pasar baru dengan SEO pada halaman
 Baca studi kasus
Baca studi kasusBagaimana menghitung pendapatan lalu lintas organik
Cara yang akurat didasarkan pada data Google Analytics (GA) Anda. Jika situs Anda baru, Anda harus menggunakan alat pihak ketiga. Saya lebih suka menghindari penggunaan alat seperti itu ketika Anda memiliki data sendiri.
Ingat, Anda harus menguji data pihak ketiga yang Anda gunakan terhadap beberapa data halaman asli Anda untuk menemukan kemungkinan kesalahan dalam data mereka.
Cara menghitung pendapatan lalu lintas SEO non-merek dengan Python
Sejauh ini, kita telah membahas banyak konsep teoretis yang harus kita ketahui untuk lebih memahami berbagai aspek lalu lintas organik dan prediksi pendapatan kita. Sekarang, kita akan menyelami bagian praktis dari artikel ini.
Pertama, kita akan mulai dengan menghitung kurva CTR kita. Dalam artikel kurva CTR saya di Oncrawl, saya menjelaskan dua metode berbeda dan juga metode lain yang dapat Anda gunakan dengan membuat beberapa perubahan pada kode saya. Saya sarankan Anda membaca artikel kurva klik terlebih dahulu; itu memberi Anda wawasan tentang artikel ini.
Pada artikel ini, saya mengubah beberapa bagian dari kode saya untuk mendapatkan hasil spesifik yang kami inginkan dalam estimasi lalu lintas. Kemudian, kami akan mendapatkan data dari GA dan menggunakan dimensi pendapatan GA untuk memperkirakan pendapatan kami.
Memperkirakan pendapatan lalu lintas organik non-merek dengan Python: Memulai
Anda dapat menjalankan kode ini sendiri, tanpa mengetahui Python. Namun, saya lebih suka Anda tahu sedikit tentang sintaks Python dan pengetahuan dasar tentang perpustakaan Python yang akan saya gunakan dalam kode peramalan ini. Ini akan membantu Anda untuk lebih memahami kode saya dan menyesuaikannya dengan cara yang berguna bagi Anda.
Untuk menjalankan kode ini, saya akan menggunakan Visual Studio Code dengan ekstensi Python dari Microsoft, yang menyertakan ekstensi "Jupyter". Tapi, Anda bisa menggunakan notebook Jupyter itu sendiri.
Untuk keseluruhan proses, kita perlu menggunakan pustaka Python ini:
- numpy
- panda
- plotly
Juga, kami akan mengimpor beberapa pustaka standar Python:
- JSON
- cetak
# Mengimpor perpustakaan yang kami butuhkan untuk proses kami impor json dari pprint impor pprint impor numpy sebagai np impor panda sebagai pd impor plotly.express sebagai px
Langkah 1: Menghitung kurva RKT relatif (Kurva klik relatif)
Pada langkah pertama, kami ingin menghitung kurva RKPT relatif kami. Tapi, apa itu kurva RKPT relatif?
Apa itu kurva RKPT relatif?
Mari kita mulai pertama dengan berbicara tentang 'kurva RKPT absolut'. Ketika kita menghitung kurva RKPT absolut, kita mengatakan RKT median (atau RKT rata-rata) dari posisi pertama adalah 36% dan posisi kedua adalah 20%, dan seterusnya.
Dalam kurva RKT relatif, instan persentase, kita membagi setiap median posisi dengan RKT posisi pertama. Misalnya, kurva RKT relatif posisi pertama adalah 0,36 / 0,36 = 1, yang kedua adalah 0,20 / 0,36 = 0,55, dan seterusnya.
Mungkin Anda bertanya-tanya mengapa menghitung ini berguna? Pikirkan tentang halaman peringkat di posisi satu, yang memiliki RKPT 44%. Jika halaman ini masuk ke posisi dua, kurva CTR tidak turun menjadi 20%, kemungkinan besar CTR akan turun menjadi 44% * 0,55 = 24,2%.
1. Mendapatkan data lalu lintas organik bermerek dan tidak bermerek dari GSC
Untuk proses perhitungan kami, kami perlu mendapatkan data kami dari GSC. Pertama kali, semua data akan didasarkan pada kueri bermerek dan saat berikutnya, semua data akan didasarkan pada kueri tidak bermerek.
Untuk mendapatkan data ini, Anda dapat menggunakan metode yang berbeda: dari skrip Python atau dari add-on Google Sheets “Search Analytics for Sheets”. Saya akan menggunakan penjelajah API GSC.
Output dari data ini adalah dua file JSON yang menunjukkan kinerja setiap halaman. Satu file JSON yang menampilkan performa halaman landing berdasarkan kueri bermerek dan file lainnya menunjukkan performa halaman landing berdasarkan kueri tidak bermerek.
Untuk mendapatkan data dari GSC API explorer, ikuti langkah-langkah berikut:
- Buka https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Maksimalkan API explorer yang ada di pojok kanan atas halaman.
- Di bidang “
siteUrl”, masukkan nama domain Anda. Misalnya “https://www.example.com” atau “http://your-domain.com”. - Di badan permintaan, pertama-tama kita perlu mendefinisikan parameter “
startDate” dan “endDate”. Preferensi saya adalah 30 hari terakhir. - Kemudian kita tambahkan "
dimensions" dan pilih "page" untuk daftar ini. - Sekarang kita menambahkan “
dimensionFilterGroups” untuk memfilter kueri kita. Sekali untuk yang bermerek dan yang kedua untuk kueri yang tidak bermerek. - Pada akhirnya, kami menetapkan "
rowLimit" kami menjadi 25.000. Jika halaman situs Anda yang mendapatkan lalu lintas organik setiap bulan lebih dari 25 ribu, Anda harus mengubah badan permintaan Anda. - Setelah membuat setiap permintaan, simpan respons JSON. Untuk kinerja bermerek, simpan file JSON sebagai “
branded_data.json” dan untuk kinerja non-merek, simpan file JSON sebagai “non_branded_data.json”.
Setelah kami memahami parameter di badan permintaan kami, satu-satunya hal yang perlu Anda lakukan adalah menyalin, dan menempel di bawah badan permintaan. Pertimbangkan untuk mengganti nama merek Anda dengan “ brand variation names ”.
Anda harus memisahkan nama merek dengan pipeline atau “ | ”. Misalnya “ amazon|amazon.com|amazn ”.
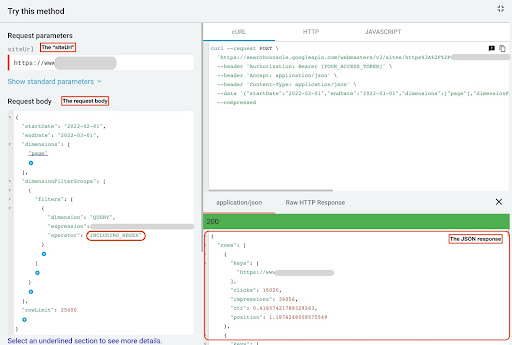
Penjelajah API GSC
Badan permintaan bermerek:
{
"tanggal mulai": "02-02-01",
"endDate": "2020-03-01",
"dimensi": [
"halaman"
],
"dimensionFilterGroups": [
{
"filter": [
{
"dimensi": "QUERY",
"expression": "nama variasi merek",
"operator": "TERMASUK_REGEX"
}
]
}
],
"rowLimit": 25000
}
Badan permintaan tanpa merek:
{
"tanggal mulai": "02-02-01",
"endDate": "2020-03-01",
"dimensi": [
"halaman"
],
"dimensionFilterGroups": [
{
"filter": [
{
"dimensi": "QUERY",
"expression": "nama variasi merek",
"operator": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
2. Mengimpor data ke notebook Jupyter kami dan mengekstrak direktori situs
Sekarang, kita perlu memuat data kita ke dalam notebook Jupyter kita untuk dapat memodifikasinya dan mengekstrak apa yang kita inginkan darinya. Mari kita lanjutkan di mana kita tinggalkan di atas.
Untuk memuat data bermerek, Anda perlu menjalankan blok kode ini:
# Membuat DataFrame untuk kinerja URL situs web pada merek, dan kueri bermerek
dengan open("./branded_data.json") sebagai json_file:
branded_data = json.loads(json_file.read())["baris"]
branded_df = pd.DataFrame(branded_data)
# Mengganti nama kolom 'kunci' menjadi kolom 'halaman arahan', dan mengonversi daftar 'halaman arahan' menjadi URL
branded_df.rename(columns={"keys": "halaman arahan"}, inplace=True)
branded_df["halaman arahan"] = branded_df["halaman arahan"].apply(lambda x: x[0])
Untuk kinerja halaman arahan yang tidak bermerek, Anda harus menjalankan blok kode ini:
# Membuat DataFrame untuk kinerja URL situs web pada kueri non-merek
dengan open("./non_branded_data.json") sebagai json_file:
non_branded_data = json.loads(json_file.read())["baris"]
non_branded_df = pd.DataFrame(non_branded_data)
# Mengganti nama kolom 'kunci' menjadi kolom 'halaman arahan', dan mengonversi daftar 'halaman arahan' menjadi URL
non_branded_df.rename(columns={"keys": "halaman arahan"}, inplace=True)
non_branded_df["halaman arahan"] = non_branded_df["halaman arahan"].apply(lambda x: x[0])
Kami memuat data kami, maka kami perlu menentukan nama situs kami untuk mengekstrak direktorinya.
# Menentukan nama situs Anda di antara tanda kutip. Misalnya, 'https://www.example.com/' atau 'http://domainsaya.com/' SITE_NAME = "https://www.domain_anda.com/"
Kami hanya perlu mengekstrak direktori dari kinerja non-merek.
# Mendapatkan setiap direktori halaman arahan (URL)
non_branded_df["direktori"] = non_branded_df["halaman arahan"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
Kemudian kami mencetak direktori untuk memilih mana yang penting untuk proses ini. Anda mungkin ingin memilih semua direktori untuk mendapatkan wawasan yang lebih baik tentang situs Anda.

# Untuk mendapatkan semua direktori dalam output, kita perlu memanipulasi opsi Pandas
pd.set_option("display.max_rows", Tidak ada)
# Direktori situs web
non_branded_df["direktori"].value_counts()
Di sini, Anda dapat memasukkan direktori mana saja yang penting bagi Anda.
""" Pilih direktori mana yang penting untuk mendapatkan kurva RKT mereka.
Masukkan direktori ke dalam variabel 'important_directories'.
Misalnya, 'produk, tag, kategori produk, majalah'. Pisahkan nilai direktori dengan koma.
"""
IMPORTANT_DIRECTORIES = "direktori_penting_anda"
IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split(",")
3. Memberi label halaman berdasarkan posisinya dan menghitung kurva RKT relatif
Sekarang kita perlu memberi label pada halaman arahan kita berdasarkan posisinya. Kami melakukan ini, karena kami perlu menghitung kurva RKT relatif untuk setiap direktori berdasarkan posisi halaman arahannya.
# Memberi label pada posisi yang tidak bermerek
untuk saya dalam rentang (1, 11):
non_branded_df.loc[
(non_branded_df["posisi"] >= i) & (non_branded_df["posisi"] < i + 1),
"label posisi",
] = saya
Kemudian, kami mengelompokkan halaman arahan berdasarkan direktori mereka.
# Mengelompokkan halaman arahan berdasarkan nilai 'direktori' mereka non_brand_grouped_df = non_branded_df.groupby(["directory"])
Mari kita definisikan fungsi untuk menghitung kurva RKPT relatif.
def each_dir_relative_ctr_curve(dir_df, kunci):
"""Fungsi ini menghitung setiap kurva RKT relatif IMPORTANT_DIRECTORIES.
"""
# Mengelompokkan "non_brand_grouped_df" berdasarkan nilai 'label posisi' mereka
dir_grouped_df = dir_df.groupby(["label posisi"])
# Daftar untuk menyimpan setiap posisi CTR median
median_ctr_list = []
# Menyimpan setiap direktori sebagai kunci, dan "median_ctr_list" sebagai nilai
direktori_median_ctr = {}
# Ulangi setiap grup "dir_grouped_df"
untuk saya dalam rentang (1, 11):
# Sebuah percobaan-kecuali untuk menangani situasi-situasi yang direktori misalnya tidak memiliki data untuk posisi 4
mencoba:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
kecuali:
median_ctr_list.append(0)
# Menghitung kurva RKPT relatif
direktori_median_ctr[kunci] = np.array(daftar_median_ctr) / np.array(
[daftar_ctr_median[0]] * 10
)
kembali direktori_median_ctr
Setelah kami mendefinisikan fungsi, kami menjalankannya.
# Mengulangi direktori dan menjalankan fungsi 'each_dir_relative_ctr_curve'
direktori_median_ctr_dict = dict()
untuk kunci, item di non_brand_grouped_df:
jika memasukkan IMPORTANT_DIRECTORIES:
direktori_median_ctr_dict.update(each_dir_relative_ctr_curve(item, kunci))
pprint(direktori_median_ctr_dict)
Sekarang, kami akan memuat halaman arahan kami, bermerek dan tidak bermerek, kinerja dan menghitung kurva RKT relatif untuk data non-merek kami. Mengapa kami melakukan ini hanya untuk data non-merek? Karena kami ingin memprediksi lalu lintas dan pendapatan organik non-merek.
Langkah 2: Memprediksi pendapatan lalu lintas organik non-merek
Pada langkah kedua ini, kita akan membahas cara mengambil data pendapatan dan memprediksi pendapatan kita.
1. Menggabungkan data organik bermerek dan tidak bermerek
Sekarang, kami akan menggabungkan data bermerek dan tidak bermerek kami. Ini akan membantu kami menghitung persentase lalu lintas organik tanpa merek di setiap laman landas dibandingkan dengan semua lalu lintas.
# 'main_df' adalah kombinasi dari 'seluruh data situs' dan 'data non-merek' DataFrames.
# Menggunakan DataFrame ini, Anda dapat mengetahui di mana sebagian besar klik dan tayangan kami
# berasal dari Kueri yang tidak bermerek.
main_df = non_branded_df.merge(
branded_df, on="halaman arahan", suffixes=("_non_brand", "_branded")
)
Kemudian kami memodifikasi kolom untuk menghapus yang tidak berguna.
# Memodifikasi kolom 'main_df' menjadi yang kita butuhkan
main_df = main_df[
[
"halaman arahan",
"klik_non_merek",
"ctr_non_brand",
"direktori",
"label posisi",
"clicks_branded",
]
]
Sekarang, mari kita hitung persentase klik tidak bermerek terhadap total klik laman landas.
# Menghitung persentase klik kueri non-merek berdasarkan halaman arahan ke seluruh klik halaman arahan
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_branded"]),
sumbu=1,
)
[Ebook] Mengotomatiskan SEO dengan Oncrawl
 Baca ebooknya
Baca ebooknya2. Memuat pendapatan lalu lintas organik
Sama seperti mengambil data GSC, kami memiliki sejumlah cara untuk mendapatkan data GA: kami dapat menggunakan “add-on Google Analytics Sheets” atau GA API. Dalam tutorial ini, saya lebih suka menggunakan Google Data Studio (GDS) karena kesederhanaannya.
Untuk mendapatkan data GA dari GDS, ikuti langkah-langkah berikut:
- Di GDS, buat laporan atau penjelajah baru dan tabel.
- Untuk dimensi tambahkan "halaman arahan" dan untuk metrik, kita harus menambahkan "Pendapatan".
- Kemudian, Anda harus membuat segmen khusus di GA berdasarkan sumber dan media. Filter lalu lintas "Google/organik". Setelah pembuatan segmen, tambahkan ke bagian segmen di GDS.
- Pada langkah terakhir, ekspor tabel dan simpan sebagai “
landing_pages_revenue.csv”.
Ekspor csv pendapatan halaman arahan
Mari kita memuat data kita.
organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
Sekarang, kita perlu menambahkan nama situs kita ke URL halaman arahan GA.
Saat kami mengekspor data kami dari GA, halaman arahan berada dalam bentuk relatif, tetapi data GSC kami dalam bentuk absolut.
Jangan lupa untuk memeriksa data halaman arahan GA Anda. Dalam kumpulan data yang saya gunakan, saya menemukan bahwa data GA membutuhkan sedikit pembersihan setiap saat.
# Menggabungkan URL laman landas GA dengan SITE_NAME.
# Juga, mengganti nama kolom
organic_revenue_df.loc[:, "Halaman Landas"] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
organic_revenue_df.rename(columns={"Halaman Landas": "halaman arahan", "Pendapatan": "pendapatan"}, inplace=Benar)
Sekarang, mari kita gabungkan data GSC kita dengan data GA.
# Pada langkah ini, saya menggabungkan 'main_df' dengan 'dk_organic_revenue_df' DataFrame yang berisi persentase data kueri non-merek main_df = main_df.merge(organic_revenue_df, on="halaman arahan", bagaimana="kiri")
Di akhir bagian ini, kami melakukan sedikit pembersihan pada kolom DataFrame kami.
# Sedikit membersihkan DataFrame 'main_df'
main_df = main_df[
[
"halaman arahan",
"klik_non_merek",
"ctr_non_brand",
"direktori",
"label posisi",
"klik_non_merek_persentase",
"pendapatan",
]
]
3. Menghitung pendapatan non-branded
Di bagian ini, kami akan memproses data untuk mengekstrak informasi yang kami cari.
Tapi sebelumnya, mari kita filter halaman arahan kita berdasarkan “ IMPORTANT_DIRECTORIES ”:
# Menghapus halaman arahan direktori lain, tidak termasuk dalam "IMPORTANT_DIRECTORIES"
main_df = (
main_df[main_df["direktori"].isin(IMPORTANT_DIRECTORIES)]
.dropna(subset=["pendapatan"])
.reset_index(drop=True)
)
Sekarang, mari kita hitung lalu lintas pendapatan organik tanpa merek.
Saya mendefinisikan metrik yang tidak dapat kami hitung dengan mudah dan ini lebih merupakan intuisi daripada apa pun yang mengarahkan kami untuk menetapkan nomor padanya.
Metrik “ brand_influence ” menunjukkan kekuatan merek Anda. Jika Anda yakin penelusuran non_merek mendorong lebih sedikit penjualan ke bisnis Anda, buat angka ini lebih rendah; sesuatu seperti 0.8 misalnya.
# Jika merek Anda begitu kuat sehingga kueri tanpa merek Anda dapat menjual sebanyak kueri dengan merek Anda, maka 1 bagus untuk Anda.
# Pikirkan tentang mencari buku tanpa nama merek yang disertakan dalam kueri Anda. Ketika Anda melihat Amazon, apakah Anda membeli dari pasar atau toko lain?
pengaruh_merek = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x: x["pendapatan"] * x["clicks_non_brand_percentage"] * brand_influence, axis=1
)
Mari kita buat diagram lingkaran untuk mendapatkan beberapa wawasan tentang pendapatan non-merek berdasarkan direktori penting.
# Di sel ini saya ingin mendapatkan semua pendapatan halaman arahan non-merek berdasarkan direktori mereka
non_branded_directory_dist_revenue_df = pd.pivot_table(
main_df,
indeks="direktori",
nilai=["non_brand_revenue"],
aggfunc={"non_brand_revenue": "jumlah"},
)
pie_fig = px.pie(
non_branded_directory_dist_revenue_df,
nilai="non_brand_revenue",
nama=non_branded_directory_dist_revenue_df.index,
title="Pendapatan tanpa merek berdasarkan direktori situs web",
)
pie_fig.update_traces(textposition="di dalam", textinfo="persen+label")
pie_fig.show()
Plot ini menunjukkan distribusi kueri tidak bermerek di IMPORTANT_DIRECTORIES Anda.
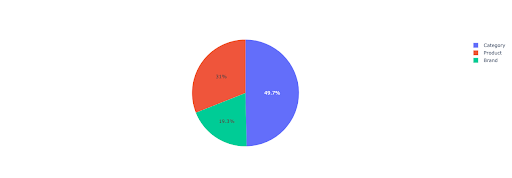
Distribusi kueri tidak bermerek
Berdasarkan data kurva RKT saya, saya melihat bahwa saya tidak dapat mengandalkan RKT untuk posisi yang lebih tinggi dari 5. Karena itu, saya memfilter data saya berdasarkan posisi.
Anda dapat memodifikasi blok kode di bawah ini berdasarkan data Anda.
# Karena akurasi CTR di kurva CTR kami, saya pikir kami dapat melewati pendaratan dengan posisi lebih dari 5. Karena itu, saya memfilter halaman arahan lain main_df = main_df[main_df["label posisi"] < 6].reset_index(drop=True)
4. Menghitung “Pendapatan per klik” (RPC)
Di sini, saya membuat metrik khusus dan menyebutnya “Pendapatan per Klik” atau RPC. Ini menunjukkan kepada kita pendapatan yang dihasilkan setiap klik tidak bermerek.
Anda dapat menggunakan metrik ini dengan cara yang berbeda. Saya menemukan halaman dengan RPC tinggi, tetapi klik rendah. Ketika saya memeriksa halaman tersebut, saya menemukan bahwa halaman tersebut diindeks kurang dari satu minggu yang lalu dan kami dapat menggunakan metode yang berbeda untuk mengoptimalkan halaman tersebut.
# Menghitung pendapatan yang dihasilkan dengan setiap klik (RPC: Pendapatan Per Klik)
main_df["rpc"] = main_df.apply(
lambda x: x["non_brand_revenue"] / x["clicks_non_brand"], axis=1
)
5. Memprediksi pendapatan!
Kami mencapai akhir, kami menunggu sampai sekarang untuk memprediksi pendapatan organik non-merek kami.
Mari kita jalankan blok kode terakhir.
# Fungsi utama untuk menghitung pendapatan berdasarkan posisi yang berbeda
untuk indeks, row_values di main_df.iterrows():
# Beralih di antara daftar CTR direktori
ctr_curve = direktori_median_ctr_dict[row_values["direktori"]]
# Ulangi posisi 1 hingga 5 dan hitung pendapatan berdasarkan kenaikan atau penurunan RKT
untuk saya dalam rentang (1, 6):
jika saya == row_values["label posisi"]:
main_df.loc[index, i] = row_values["non_brand_revenue"]
kalau tidak:
# main_df.loc[indeks, i + 1] ==
main_df.loc[indeks, i] = (
row_values["non_brand_revenue"]
* (ctr_curve[i - 1])
/ ctr_curve[int(row_values["label posisi"] - 1)]
)
# Menghitung metrik "N hingga 1". Ini menunjukkan peningkatan pendapatan ketika peringkat Anda naik dari "N" menjadi "1"
main_df.loc[indeks, "N ke 1"] = main_df.loc[indeks, 1] - main_df.loc[indeks, row_values["label posisi"]]
Melihat hasil akhir, kami memiliki kolom baru. Nama-nama kolom ini adalah “1”, “2”, “3”, “4”, “5”.
Apa arti nama-nama ini? Misalnya, kami memiliki halaman di posisi 3 dan kami ingin memprediksi pendapatannya jika meningkatkan posisinya, atau kami ingin tahu berapa banyak kami akan kehilangan jika kami turun peringkat.
Kolom “1” dan “2” menunjukkan pendapatan halaman saat posisi rata-rata halaman ini meningkat dan kolom “4” dan “5” menunjukkan pendapatan halaman ini saat kita turun peringkat.
Kolom “3” dalam contoh ini menunjukkan pendapatan halaman saat ini.
Juga, saya membuat metrik yang disebut "N ke 1". Ini menunjukkan kepada Anda jika posisi rata-rata halaman ini bergerak dari “3” (atau N) ke “1” dan seberapa besar pergerakan tersebut dapat memengaruhi pendapatan.
Membungkus
Saya membahas banyak hal dalam artikel ini dan sekarang giliran Anda untuk mengotori tangan Anda dan memprediksi pendapatan lalu lintas organik non-merek Anda.
Ini adalah cara paling sederhana yang bisa kita gunakan untuk prediksi ini. Kami dapat membuat algoritme ini lebih kompleks dan menggabungkannya dengan beberapa model ML, tetapi itu akan membuat artikel menjadi lebih rumit.
Saya lebih suka menyimpan data ini dalam CSV dan mengunggahnya ke Google Sheet. Atau, jika saya berencana untuk membagikannya dengan anggota tim atau organisasi saya yang lain, saya akan membukanya dengan excel dan memformat kolom menggunakan warna agar lebih mudah dibaca.
Berdasarkan data ini, Anda dapat memprediksi ROI lalu lintas organik non-merek dan menggunakannya dalam proses negosiasi Anda.