
Memprediksi lalu lintas SEO dengan Prophet dan Python
Diterbitkan: 2021-03-16Menetapkan target dan mengevaluasi pencapaian dari waktu ke waktu adalah latihan yang sangat menarik untuk memahami apa yang dapat kita capai dan apakah strategi yang kita gunakan efektif atau tidak. Namun, biasanya tidak mudah untuk menetapkan target ini karena pertama-tama kita harus membuat perkiraan.
Membuat perkiraan bukanlah hal yang mudah, tetapi berkat beberapa prosedur perkiraan yang tersedia, CPU kami, dan beberapa keterampilan pemrograman, kami dapat mengurangi kerumitannya cukup banyak. Dalam posting ini, saya akan menunjukkan kepada Anda bagaimana kami dapat membuat prediksi yang akurat dan bagaimana Anda dapat menerapkannya pada SEO dengan menggunakan Python dan library Prophet dan tanpa harus memiliki kekuatan super peramal.
Jika Anda belum pernah mendengar tentang Nabi Anda mungkin bertanya-tanya apa itu. Singkatnya, Prophet adalah prosedur untuk peramalan yang dirilis oleh tim Core Data Science Facebook yang tersedia dalam Python dan R dan yang menangani outlier dan efek musiman dengan sangat baik untuk
memberikan prediksi yang akurat dan cepat.
Ketika kita berbicara tentang peramalan, kita perlu mempertimbangkan dua hal:
- Semakin banyak data historis yang kita miliki, semakin akurat model kita dan oleh karena itu prediksi kita nantinya.
- Model prediksi hanya akan valid jika faktor internal tetap sama dan tidak ada faktor eksternal yang mempengaruhinya. Ini berarti bahwa jika misalnya, kami telah menerbitkan satu posting per minggu dan kami mulai menerbitkan dua posting per minggu, model ini mungkin tidak valid untuk memprediksi apa hasil dari perubahan strategi ini. Di sisi lain, jika ada pembaruan algoritma, modelnya mungkin juga tidak valid. Perlu diingat bahwa model dibangun berdasarkan data historis.
Untuk menerapkan ini ke SEO, apa yang akan kita lakukan adalah memprediksi sesi SEO untuk bulan mendatang dengan mengikuti langkah-langkah berikut:
- Mendapatkan data dari Google Analytics tentang sesi organik untuk jangka waktu tertentu.
- Melatih model kami.
- Memprediksi lalu lintas SEO untuk bulan mendatang.
- Mengevaluasi seberapa baik model kami dengan kesalahan absolut rata-rata.
Apakah Anda ingin mengetahui lebih lanjut tentang cara kerja prosedur peramalan ini? Mari kita mulai!
Mendapatkan data dari Google Analytics
Kita dapat mendekati ekstraksi data dari Google Analytics dengan dua cara: mengekspor file Excel dari antarmuka normal atau menggunakan API untuk mengambil data ini.
Mengimpor data dari file Excel
Cara termudah untuk mendapatkan data ini dari Google Analytics adalah pergi ke bagian Saluran di bilah samping, mengklik Organik dan mengekspor data dengan tombol yang ada di atas halaman. Pastikan Anda memilih pada menu tarik-turun di atas grafik variabel yang ingin Anda analisis, dalam hal ini Sesi.
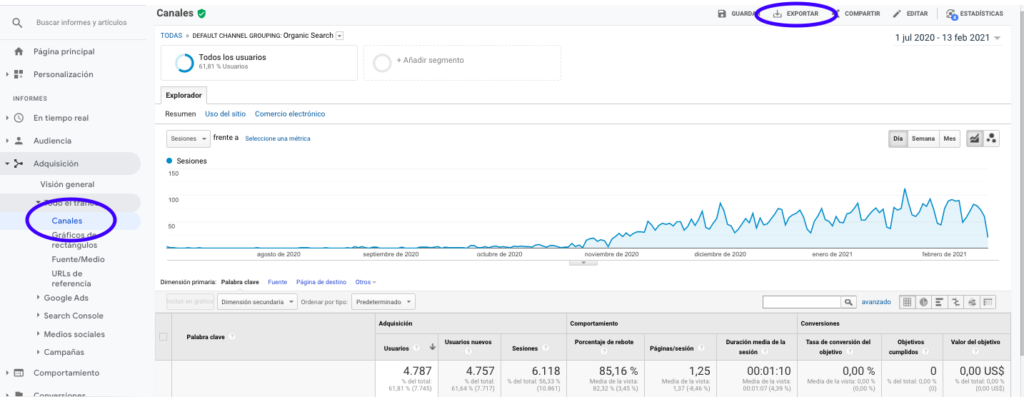
Setelah mengekspor data sebagai file Excel, kita dapat mengimpornya ke dalam buku catatan kita dengan Pandas. Perhatikan bahwa file Excel dengan data tersebut akan berisi tab yang berbeda, sehingga tab dengan lalu lintas bulanan perlu ditentukan sebagai argumen di bagian kode di bawah ini. Kami juga menghapus baris terakhir karena berisi jumlah total sesi, yang akan mendistorsi model kami.
impor panda sebagai pd
df = pd.read_excel ('.xlsx', sheet_name= "")
df = df.drop(len(df) - 1)
Kita dapat menggambar dengan Matplotlib bagaimana data terlihat seperti:
dari matplotlib impor pyplot
df["Sesi"].plot(judul = "Sesi")
gambar.tampilkan() 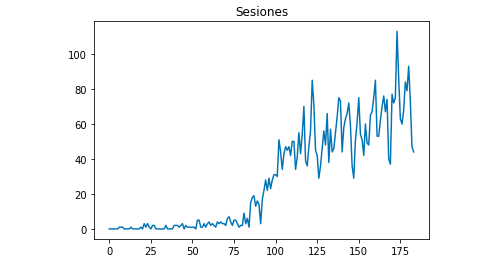
Menggunakan Google Analytics API
Pertama-tama, untuk menggunakan Google Analytics API, kita perlu membuat proyek di konsol pengembang Google, mengaktifkan layanan Pelaporan Google Analytics, dan mendapatkan kredensial. Jean-Christophe Chouinard menjelaskan dengan sangat baik dalam artikel ini cara mengaturnya.
Setelah kredensial didapat, maka kita perlu mengautentikasi sebelum membuat permintaan. Otentikasi perlu dilakukan dengan file kredensial yang diperoleh awalnya dari konsol pengembang Google. Kami juga perlu menuliskan dalam kode kami ID Tampilan GA dari properti yang ingin kami gunakan.
dari apiclient.discovery import build
dari oauth2client.service_account impor ServiceAccountCredentials
LINGKUP = ['https://www.googleapis.com/auth/analytics.readonly']
KUNCI_FILE_LOKASI = ''
MELIHAT_
kredensial = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, CAKUPAN)
analytics = build('analyticsreporting', 'v4', kredensial=kredensial)Setelah mengautentikasi, kita hanya perlu membuat permintaan. Salah satu yang perlu kita gunakan untuk mendapatkan data tentang sesi organik untuk setiap hari adalah:
tanggapan = analytics.reports().batchGet(body={
'permintaan laporan': [{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
'metrik': [
{"expression": "ga:sessions"}
], "dimensi": [
{"nama": "ga:tanggal"}
],
"filtersExpression":"ga:channelGrouping=~Organik",
"includeEmptyRows": "benar"
}]}).menjalankan()Perhatikan bahwa kami memilih rentang waktu di dateRanges. Dalam kasus saya, saya akan mengambil data dari 1 September hingga 31 Januari: [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
Setelah ini, kita hanya perlu mengambil file respons untuk menambahkan daftar hari dengan sesi organiknya:
daftar_nilai = [] untuk x sebagai tanggapan["laporan"][0]["data"]["baris"]: list_values.append([x["dimensions"][0],x["metrics"][0]["values"][0]])
Seperti yang Anda lihat, menggunakan Google Analytics API cukup sederhana dan dapat digunakan untuk banyak tujuan. Dalam artikel ini, saya menjelaskan bagaimana Anda dapat menggunakan Google Analytics API untuk membuat peringatan untuk mendeteksi halaman yang berkinerja buruk.

Menyesuaikan daftar ke Dataframe
Untuk menggunakan Prophet kita perlu memasukkan Dataframe dengan dua kolom yang perlu diberi nama: “ds” dan “y”. Jika Anda telah mengimpor data dari file Excel, kami sudah memilikinya sebagai Dataframe sehingga Anda hanya perlu memberi nama kolom “ds” dan “y”:
df.columns = ['ds', 'y']
Jika Anda menggunakan API untuk mengambil data, maka kita perlu mengubah daftar menjadi kerangka data dan memberi nama kolom sesuai kebutuhan:
dari panda impor DataFrame df_sessions = DataFrame(list_values,columns=['ds','y'])
Melatih model
Setelah kami memiliki Dataframe dengan format yang diperlukan, kami dapat menentukan dan melatih model kami dengan sangat mudah dengan:
impor fbprophet dari fbprophet import Prophet model = Nabi() model.fit(df_sessions)
Membuat prediksi kami
Akhirnya setelah melatih model kami, kami dapat mulai memperkirakan! Untuk melanjutkan prediksi, pertama-tama kita perlu membuat daftar dengan rentang waktu yang ingin kita prediksi dan menyesuaikan format waktu-waktu:
dari panda impor ke_datetime perkiraan_hari = [] untuk x dalam rentang (1, 28): tanggal = "2021-02-" + str(x) forecast_days.append([tanggal]) forecast_days = DataFrame(forecast_days) forecast_days.columns = ['ds'] forecast_days['ds']= to_datetime(forecast_days['ds'])
Dalam contoh ini saya menggunakan loop yang akan membuat kerangka data yang akan berisi semua hari dari Februari. Dan sekarang tinggal menggunakan model yang sudah dilatih sebelumnya:
ramalan = model.predict(forecast_days)
Kita dapat menggambar plot yang menyoroti periode waktu yang diperkirakan:
dari matplotlib impor pyplot model.plot(perkiraan) gambar.tampilkan()
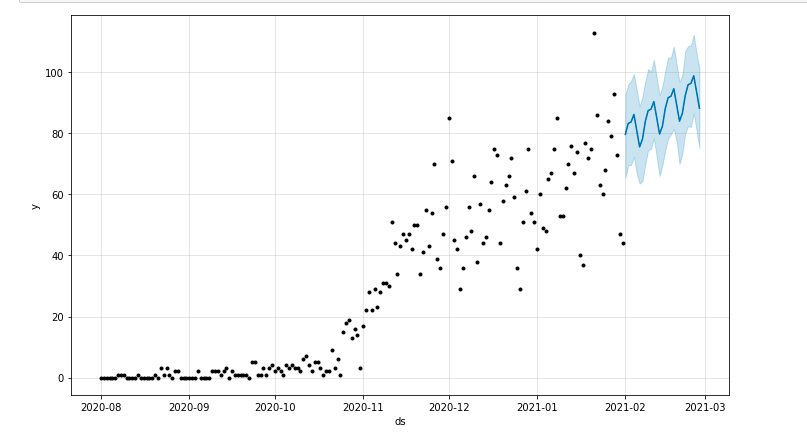
Mengevaluasi model
Akhirnya, kami dapat mengevaluasi seberapa akurat model kami dengan menghilangkan beberapa hari dari data yang digunakan untuk melatih model, memperkirakan sesi untuk hari-hari itu dan menghitung kesalahan absolut rata-rata.
Sebagai contoh, apa yang akan saya lakukan adalah menghilangkan dari kerangka data asli 12 hari terakhir dari Januari, memperkirakan sesi untuk setiap hari dan membandingkan lalu lintas aktual dengan yang diperkirakan.
Pertama kami menghilangkan dari dataframe asli 12 hari terakhir dengan pop dan kami membuat dataframe baru yang hanya akan menyertakan 12 hari yang akan digunakan untuk perkiraan:
kereta = df_sessions.drop(df_sessions.index[-12:]) masa depan = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
Sekarang kita melatih modelnya, membuat ramalannya dan kita menghitung kesalahan absolut rata-rata. Pada akhirnya, kita dapat menggambar plot yang akan menunjukkan perbedaan antara nilai perkiraan yang sebenarnya dan yang sebenarnya. Ini adalah sesuatu yang saya pelajari dari artikel yang ditulis oleh Jason Brownlee ini.
dari sklearn.metrics impor mean_absolute_error
impor numpy sebagai np
dari array impor numpy
#Kami melatih modelnya
model = Nabi()
model.fit(kereta api)
#Sesuaikan kerangka data yang digunakan untuk hari prakiraan ke format yang diminta Nabi.
masa depan = daftar (masa depan)
masa depan = DataFrame(masa depan)
masa depan = masa depan.rename(columns={0: 'ds'})
# Kami membuat ramalan
ramalan = model.prediksi(masa depan)
# Kami menghitung MAE antara nilai aktual dan nilai prediksi
y_true = df_sessions['y'][-12:].values
y_pred = perkiraan['yhat'].nilai
mae = mean_absolute_error(y_true, y_pred)
# Kami memplot hasil akhir untuk pemahaman visual
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, label='Aktual')
pyplot.plot(y_pred, label='Diprediksi')
pyplot.legenda()
gambar.tampilkan()
cetak (mae) 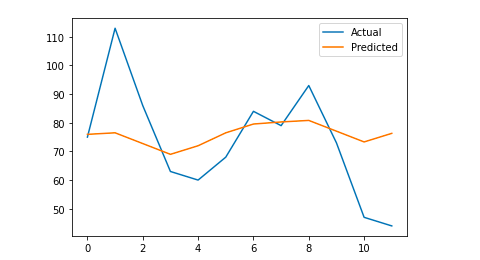
Rata-rata kesalahan absolut saya adalah 13, yang berarti bahwa model perkiraan saya menetapkan 13 sesi lebih banyak setiap hari daripada yang sebenarnya, yang tampaknya merupakan kesalahan yang dapat diterima.
Itu saja! Saya harap Anda menemukan artikel ini menarik dan Anda dapat mulai membuat prediksi SEO Anda untuk menetapkan target.
Melangkah lebih jauh: Lab OnCrawl
Jika Anda senang memperkirakan lalu lintas dengan metode ini, Anda juga akan tertarik dengan OnCrawl Labs, lab ilmu data dan pembelajaran mesin OnCrawl yang menawarkan proyek pra-kode untuk alur kerja SEO Anda.
Dalam peramalan SEO, OnCrawl Labs akan membantu Anda menyempurnakan proyeksi SEO Anda:
- Dapatkan pemahaman yang lebih baik tentang teori dan proses di balik algoritma Facebook Prophet
- Analisis segmen lalu lintas, seperti lalu lintas pada kata kunci ekor panjang saja, atau hanya kata kunci bermerek…
- Ikuti proses langkah-demi-langkah untuk mengatur peristiwa sejarah, menyesuaikan pengaruhnya dan kemungkinan terulangnya peristiwa tersebut.