
Bagaimana cara mengekstrak konten teks yang relevan dari halaman HTML?
Diterbitkan: 2021-10-13Konteks
Di departemen Litbang Oncrawl, kami semakin berupaya untuk menambah nilai pada konten semantik halaman web Anda. Menggunakan model pembelajaran mesin untuk pemrosesan bahasa alami (NLP), dimungkinkan untuk melakukan tugas dengan nilai tambah nyata untuk SEO.
Tugas-tugas tersebut meliputi kegiatan-kegiatan seperti:
- Menyesuaikan konten halaman Anda
- Membuat ringkasan otomatis
- Menambahkan tag baru ke artikel Anda atau mengoreksi yang sudah ada
- Mengoptimalkan konten sesuai dengan data Google Search Console Anda
- dll.
Langkah pertama dalam petualangan ini adalah mengekstrak konten teks halaman web yang akan digunakan oleh model pembelajaran mesin ini. Ketika kita berbicara tentang halaman web, ini termasuk HTML, JavaScript, menu, media, header, footer, ... Mengekstrak konten secara otomatis dan benar tidaklah mudah. Melalui artikel ini, saya mengusulkan untuk mengeksplorasi masalah dan mendiskusikan beberapa alat dan rekomendasi untuk mencapai tugas ini.
Masalah
Mengekstrak konten teks dari halaman web mungkin tampak sederhana. Dengan beberapa baris Python, misalnya, beberapa ekspresi reguler (regexp), perpustakaan penguraian seperti BeautifulSoup4, dan selesai.
Jika Anda mengabaikan selama beberapa menit fakta bahwa semakin banyak situs menggunakan mesin rendering JavaScript seperti Vue.js atau React, penguraian HTML tidak terlalu rumit. Jika Anda ingin mengatasi masalah ini dengan memanfaatkan perayap JS kami dalam perayapan Anda, saya sarankan Anda membaca "Bagaimana cara merayapi situs dalam JavaScript?".
Namun, kami ingin mengekstrak teks yang masuk akal, seinformatif mungkin. Ketika Anda membaca artikel tentang album anumerta terakhir John Coltrane, misalnya, Anda mengabaikan menu, footer, ... dan jelas, Anda tidak melihat seluruh konten HTML. Elemen HTML yang muncul di hampir semua halaman Anda ini disebut boilerplate. Kami ingin menyingkirkannya dan hanya menyimpan sebagian: teks yang membawa informasi yang relevan.
Oleh karena itu, hanya teks inilah yang ingin kami sampaikan ke model pembelajaran mesin untuk diproses. Itulah mengapa ekstraksi harus sekualitatif mungkin.
Solusi
Secara keseluruhan, kami ingin menyingkirkan segala sesuatu yang "menggantung" teks utama: menu dan bilah sisi lainnya, elemen kontak, tautan footer, dll. Ada beberapa metode untuk melakukan ini. Kami sebagian besar tertarik pada proyek Sumber Terbuka dengan Python atau JavaScript.
jusTeks
jusText adalah implementasi yang diusulkan dengan Python dari tesis PhD: "Menghapus Boilerplate dan Konten Duplikat dari Web Corpora". Metode ini memungkinkan blok teks dari HTML untuk dikategorikan sebagai "baik", "buruk", "terlalu pendek" menurut heuristik yang berbeda. Heuristik ini sebagian besar didasarkan pada jumlah kata, rasio teks/kode, ada atau tidaknya tautan, dll. Anda dapat membaca lebih lanjut tentang algoritme dalam dokumentasi.
trafilatura
trafilatura, juga dibuat dengan Python, menawarkan heuristik pada tipe elemen HTML dan kontennya, misalnya panjang teks, posisi/kedalaman elemen dalam HTML, atau jumlah kata. trafilatura juga menggunakan jusText untuk melakukan beberapa pemrosesan.
keterbacaan
Pernahkah Anda memperhatikan tombol di bilah URL Firefox? Ini adalah Tampilan Pembaca: memungkinkan Anda untuk menghapus boilerplate dari halaman HTML untuk menyimpan hanya konten teks utama. Cukup praktis digunakan untuk situs berita. Kode di balik fitur ini ditulis dalam JavaScript dan disebut readability oleh Mozilla. Ini didasarkan pada pekerjaan yang diprakarsai oleh lab Arc90.
Berikut adalah contoh cara merender fitur ini untuk artikel dari situs web France Musice. 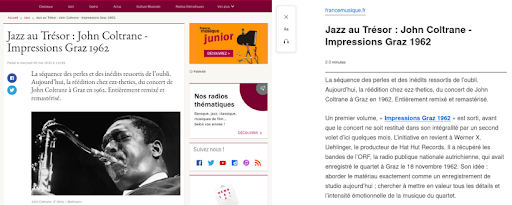
Di sebelah kiri, ini adalah ekstrak dari artikel asli. Di sebelah kanan, ini adalah rendering fitur Tampilan Pembaca di Firefox.
Yang lain
Penelitian kami tentang alat ekstraksi konten HTML juga membuat kami mempertimbangkan alat lain:
- koran: perpustakaan ekstraksi konten yang didedikasikan untuk situs berita (Python). Pustaka ini digunakan untuk mengekstrak konten dari korpus OpenWebText2.
- boilerpy3 adalah port Python dari perpustakaan boilerpipe.
- library dragnet Python juga terinspirasi oleh boilerpipe.
Data Perayapan³
 Belajarlah lagi
Belajarlah lagiEvaluasi dan rekomendasi
Sebelum mengevaluasi dan membandingkan alat yang berbeda, kami ingin mengetahui apakah komunitas NLP menggunakan beberapa alat ini untuk menyiapkan korpus (kumpulan dokumen yang besar). Misalnya, kumpulan data bernama The Pile yang digunakan untuk melatih GPT-Neo memiliki +800 GB teks bahasa Inggris dari Wikipedia, Openwebtext2, Github, CommonCrawl, dll. Seperti BERT, GPT-Neo adalah model bahasa yang menggunakan transformator tipe. Ini menawarkan implementasi open-source yang mirip dengan arsitektur GPT-3.

Artikel “The Pile: An 800GB Dataset of Diverse Text for Language Modeling” menyebutkan penggunaan jusText untuk sebagian besar corpus mereka dari CommonCrawl. Kelompok peneliti ini juga telah merencanakan untuk melakukan benchmark terhadap alat ekstraksi yang berbeda. Sayangnya, mereka tidak dapat melakukan pekerjaan yang direncanakan karena kurangnya sumber daya. Dalam kesimpulan mereka, perlu dicatat bahwa:
- jusText terkadang menghapus terlalu banyak konten tetapi tetap memberikan kualitas yang baik. Mengingat jumlah data yang mereka miliki, ini bukan masalah bagi mereka.
- trafilatura lebih baik dalam mempertahankan struktur halaman HTML tetapi menyimpan terlalu banyak boilerplate.
Untuk metode evaluasi kami, kami mengambil sekitar tiga puluh halaman web. Kami mengekstrak konten utama "secara manual". Kami kemudian membandingkan ekstraksi teks dari alat yang berbeda dengan apa yang disebut konten "referensi". Kami menggunakan skor ROUGE, yang terutama digunakan untuk mengevaluasi ringkasan teks otomatis, sebagai metrik.
Kami juga membandingkan alat ini dengan alat "buatan sendiri" berdasarkan aturan penguraian HTML. Ternyata trafilatura, jusText, dan alat buatan kami lebih baik daripada kebanyakan alat lain untuk metrik ini.
Berikut adalah tabel rata-rata dan standar deviasi skor ROUGE:
| Peralatan | Berarti | Std |
|---|---|---|
| trafilatura | 0,783 | 0,28 |
| Merangkak | 0,779 | 0,28 |
| jusTeks | 0,735 | 0.33 |
| boilerpy3 | 0,698 | 0.36 |
| keterbacaan | 0,681 | 0.34 |
| jaring | 0,672 | 0.37 |
Mengingat nilai deviasi standar, perhatikan bahwa kualitas ekstraksi dapat sangat bervariasi. Cara implementasi HTML, konsistensi tag, dan penggunaan bahasa yang tepat dapat menyebabkan banyak variasi dalam hasil ekstraksi.
Tiga alat yang berkinerja terbaik adalah trafilatura, alat internal kami bernama "oncrawl" untuk acara tersebut dan jusText. Karena jusText digunakan sebagai fallback oleh trafilatura, kami memutuskan untuk menggunakan trafilatura sebagai pilihan pertama kami. Namun, ketika yang terakhir gagal dan mengekstrak nol kata, kami menggunakan aturan kami sendiri.
Perhatikan bahwa kode trafilatura juga menawarkan patokan pada beberapa ratus halaman. Ini menghitung skor presisi, skor f1, dan akurasi berdasarkan ada atau tidaknya elemen tertentu dalam konten yang diekstraksi. Dua alat menonjol: trafilatura dan goose3. Anda mungkin juga ingin membaca:
- Memilih alat yang tepat untuk mengekstrak konten dari Web (2020)
- repositori Github: tolok ukur ekstraksi artikel: perpustakaan sumber terbuka dan layanan komersial
Kesimpulan
Kualitas kode HTML dan heterogenitas jenis halaman membuat sulit untuk mengekstrak konten berkualitas. Seperti yang ditemukan oleh peneliti EleutherAI – yang berada di balik The Pile dan GPT-Neo –, tidak ada alat yang sempurna. Ada trade-off antara konten yang terkadang terpotong dan kebisingan sisa dalam teks ketika tidak semua boilerplate telah dihapus.
Keuntungan dari alat ini adalah bebas konteks. Artinya, mereka tidak memerlukan data apa pun selain HTML halaman untuk mengekstrak konten. Dengan menggunakan hasil Oncrawl, kita dapat membayangkan metode hybrid menggunakan frekuensi kemunculan blok HTML tertentu di semua halaman situs untuk mengklasifikasikannya sebagai boilerplate.
Adapun kumpulan data yang digunakan dalam tolok ukur yang kami temukan di Web, mereka sering kali memiliki jenis halaman yang sama: artikel berita atau posting blog. Mereka tidak harus menyertakan situs asuransi, agen perjalanan, e-commerce, dll. di mana konten teks terkadang lebih rumit untuk diekstraksi.
Sehubungan dengan tolok ukur kami dan karena kurangnya sumber daya, kami menyadari bahwa tiga puluh halaman atau lebih tidak cukup untuk mendapatkan tampilan skor yang lebih detail. Idealnya, kami ingin memiliki lebih banyak halaman web berbeda untuk menyempurnakan nilai tolok ukur kami. Dan kami juga ingin menyertakan alat lain seperti goose3, html_text atau inscriptis.