
Ekstrak data dari Google Search Console API untuk analisis data dengan Python
Diterbitkan: 2022-03-01Google Search Console (GSC) jelas merupakan salah satu alat yang paling berguna untuk Pakar SEO, karena memungkinkan Anda mendapatkan informasi tentang cakupan indeks dan terutama kueri yang saat ini Anda rangking. Mengetahui hal ini, banyak orang menganalisis data GSC menggunakan spreadsheet dan itu baik-baik saja, selama Anda memahami bahwa ada lebih banyak ruang untuk perbaikan dengan alat seperti bahasa pemrograman.
Sayangnya, antarmuka GSC cukup terbatas baik dari segi baris yang ditampilkan (hanya 5.000) dan jangka waktu yang tersedia, hanya 16 bulan. Jelas bahwa ini dapat sangat membatasi kemampuan Anda untuk mendapatkan wawasan dan tidak cocok untuk situs web yang lebih besar.
Python memungkinkan Anda mendapatkan data GSC dengan mudah dan mengotomatiskan perhitungan yang lebih kompleks yang akan membutuhkan lebih banyak upaya dalam perangkat lunak spreadsheet tradisional.
Ini adalah solusi untuk salah satu masalah terbesar di Excel, yaitu batas baris dan kecepatan. Saat ini, Anda memiliki lebih banyak alternatif untuk menganalisis data daripada sebelumnya dan di situlah Python berperan.
Anda tidak memerlukan pengetahuan coding tingkat lanjut untuk mengikuti tutorial ini, cukup memahami beberapa konsep dasar dan beberapa latihan dengan Google Colab.
Memulai dengan Google Search Console API
Sebelum kita mulai, penting untuk menyiapkan Google Search Console API. Prosesnya cukup sederhana, yang Anda butuhkan hanyalah akun Google. Langkah-langkahnya adalah sebagai berikut:
- Buat proyek baru di Google Cloud Platform. Anda harus memiliki akun Google dan saya yakin Anda memilikinya. Buka konsol dan Anda akan menemukan opsi di bagian atas untuk membuat proyek baru.
- Klik pada menu di sebelah kiri dan pilih "API dan layanan", Anda akan sampai ke layar lain.
- Dari bilah pencarian di bagian atas, cari "Google Search Console API" dan aktifkan.
- Kemudian lanjutkan ke tab "Kredensial", Anda memerlukan semacam izin untuk menggunakan API.
- Konfigurasikan layar "persetujuan", karena ini wajib. Tidak masalah untuk penggunaan yang akan kita buat apakah itu publik atau tidak.
- Anda dapat memilih "Aplikasi Desktop" untuk jenis aplikasi
- Kami akan menggunakan OAuth 2.0 untuk tutorial ini, Anda harus mengunduh file json dan sekarang Anda selesai.
Ini sebenarnya bagian tersulit bagi kebanyakan orang, terutama yang tidak terbiasa dengan Google API. Jangan khawatir, langkah selanjutnya akan jauh lebih mudah dan tidak terlalu bermasalah.
Mendapatkan data dari Google Search Console API dengan Python
Rekomendasi saya adalah Anda menggunakan notebook seperti Jupyter Notebook atau Google Colab. Yang terakhir lebih baik karena Anda tidak perlu khawatir tentang persyaratan. Oleh karena itu, yang akan saya jelaskan adalah berbasis Google Colab.
Sebelum kita mulai, perbarui file json Anda ke Google Colab dengan kode berikut:
dari file impor google.colab file.upload()
Kemudian, mari kita instal semua perpustakaan yang kita perlukan untuk analisis kita dan mari kita buat visualisasi tabel yang lebih baik dengan cuplikan kode ini:
%%menangkap #muat apa yang dibutuhkan !pip install git+https://github.com/joshcarty/google-searchconsole impor panda sebagai pd impor numpy sebagai np impor matplotlib.pyplot sebagai plt dari google.colab impor data_table !git clone https://github.com/jroakes/querycat.git !pip install -r querycat/requirements_colab.txt !pip install umap-belajar data_table.enable_dataframe_formatter() #untuk visualisasi tabel yang lebih baik
Terakhir, Anda dapat memuat perpustakaan searchconsole, yang menawarkan cara termudah untuk melakukannya tanpa bergantung pada fungsi yang panjang. Jalankan kode berikut dengan argumen yang saya gunakan dan pastikan client_config memiliki nama yang sama dengan file json yang diunggah.
impor konsol pencarian akun = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
Anda akan diarahkan ke halaman Google untuk mengotorisasi aplikasi, pilih akun Google Anda, lalu salin dan tempel kode yang akan Anda dapatkan ke bilah Google Colab.
Kami belum selesai, Anda harus memilih properti yang akan Anda perlukan datanya. Anda dapat dengan mudah memeriksa properti Anda melalui account.webproperties untuk melihat apa yang harus Anda pilih.
property_name = input('Masukkan nama website Anda seperti yang tercantum di GSC: ')
webproperty=akun[str(nama_properti)]
Setelah selesai, Anda akan menjalankan fungsi kustom untuk membuat objek yang berisi data kami.
def extract_gsc_data(properti web, mulai, hentikan, *args):
jika properti web bukan Tidak Ada:
print(f'Mengekstrak data untuk {webproperty}')
gsc_data = webproperty.query.range(mulai, hentikan).dimension(*args).get()
kembalikan gsc_data
kalau tidak:
print('Properti web tidak ditemukan, pilih yang benar')
kembali Tidak ada
Ide dari fungsi ini adalah untuk mengambil properti yang Anda tetapkan sebelumnya dan kerangka waktu, dalam bentuk tanggal mulai dan berakhir, bersama dengan dimensi.
Pilihan untuk dapat memilih dimensi sangat penting bagi Pakar SEO karena memungkinkan Anda memahami apakah Anda memerlukan tingkat perincian tertentu. Misalnya, Anda mungkin tidak tertarik untuk mendapatkan dimensi tanggal, dalam beberapa kasus.
Saran saya adalah untuk selalu memilih kueri dan halaman, karena antarmuka Google Search Console dapat mengekspornya secara terpisah dan sangat menjengkelkan untuk menggabungkannya setiap saat. Ini adalah manfaat lain dari Search Console API.
Dalam kasus kami, kami juga bisa langsung mendapatkan dimensi tanggal, untuk menunjukkan beberapa skenario menarik di mana Anda perlu memperhitungkan waktu.
ex = extract_gsc_data(properti web, '2021-09-01', '2021-12-31', 'kueri', 'halaman', 'tanggal')
Pilih kerangka waktu yang tepat, mengingat untuk properti yang lebih besar Anda perlu menunggu banyak waktu. Untuk contoh ini, saya hanya mempertimbangkan rentang waktu 3 bulan yang cukup untuk mendapatkan wawasan berharga dari sebagian besar kumpulan data, rata-rata.
Anda dapat memilih bahkan satu minggu jika Anda berurusan dengan sejumlah besar data, yang kami pedulikan adalah prosesnya.
Apa yang akan saya tunjukkan di sini didasarkan pada data sintetis atau data nyata yang dimodifikasi agar cocok untuk contoh. Akibatnya, apa yang Anda lihat di sini benar-benar realistis dan dapat mencerminkan skenario dunia nyata.
Pembersihan data
Bagi mereka yang tidak tahu, kami tidak dapat menggunakan data kami apa adanya, ada beberapa langkah tambahan untuk memastikan kami bekerja dengan benar. Pertama-tama, kita harus mengonversi objek kita menjadi kerangka data Pandas, struktur data yang harus Anda ketahui karena merupakan dasar analisis data dengan Python.
df = pd.DataFrame(data=ex) df.head()
Metode kepala dapat menampilkan 5 baris pertama dari kumpulan data Anda, sangat berguna untuk melihat sekilas seperti apa tampilan data Anda. Kita dapat menghitung berapa banyak halaman yang kita miliki dengan menggunakan fungsi sederhana.
Cara yang baik untuk menghapus duplikat adalah dengan mengonversi objek menjadi kumpulan, karena kumpulan tidak dapat berisi elemen duplikat.
Beberapa cuplikan kode terinspirasi oleh buku catatan Hamlet Batista dan satu lagi dari Masaki Okazawa.
Menghapus istilah bermerek
Hal pertama yang harus dilakukan adalah menghapus kata kunci bermerek, kami mencari kueri yang tidak mengandung istilah bermerek kami. Ini cukup mudah dilakukan dengan fungsi khusus dan Anda biasanya akan memiliki serangkaian istilah bermerek.
Untuk tujuan demonstratif, Anda tidak perlu memfilter semuanya, tetapi lakukan untuk analisis nyata. Ini adalah salah satu langkah pembersihan data terpenting dalam SEO, jika tidak, Anda berisiko memberikan hasil yang menyesatkan.
domain_name = str(input('Sisipkan istilah merek dipisahkan dengan koma: ')).replace(',', '|')
impor ulang
domain_name = re.sub(r"\s+", "", nama_domain)
print('Hapus semua spasi menggunakan RegEx:\n')
df['Merek/Tidak Bermerek'] = np.where(
df['query'].str.contains(nama_domain), 'Merek', 'Tidak bermerek'
)
Kami akan menambahkan kolom baru ke dataset kami untuk mengenali perbedaan antara dua kelas. Kita dapat memvisualisasikan melalui tabel atau barplot seberapa banyak mereka memperhitungkan jumlah total kueri.
Saya tidak akan menunjukkan barplot karena sangat sederhana dan saya pikir tabel lebih baik untuk kasus ini.
brand_count_df = df['Brand/Non-branded'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Persentase'] = brand_count_df['counts']/sum(brand_count_df['counts'])
pd.options.display.float_format = '{:.2%}'.format
merek_jumlah_df
Anda dapat dengan cepat melihat rasio antara kata kunci bermerek dan tidak bermerek untuk mendapatkan gambaran tentang berapa banyak yang akan Anda hapus dari kumpulan data Anda. Tidak ada rasio ideal di sini, meskipun Anda pasti ingin memiliki persentase kata kunci tidak bermerek yang lebih tinggi.
Kemudian, kita bisa membuang semua baris yang ditandai sebagai bermerek dan melanjutkan dengan langkah lain.
#hanya pilih kata kunci yang tidak bermerek df = df.loc[df['Merek/Tidak bermerek'] == 'Tidak bermerek']
Mengisi nilai yang hilang dan langkah lainnya
Jika kumpulan data Anda menampilkan nilai yang hilang (atau NA dalam jargon), Anda memiliki beberapa opsi. Yang paling umum adalah menghapus semuanya atau mengisinya dengan nilai placeholder seperti 0 atau rata-rata kolom itu.
Tidak ada jawaban yang benar dan kedua pendekatan memiliki pro dan kontra, serta risiko. Untuk data Google Search Console, saran terbaik saya adalah menempatkan nilai placeholder seperti 0, untuk meremehkan efek beberapa metrik.
df.fillna(0, inplace = True)
Sebelum kita beralih ke analisis data aktual, kita perlu menyesuaikan fitur kita, yaitu kolom dataset kita. Posisi ini sangat menarik, karena kami ingin menggunakannya untuk beberapa tabel pivot yang keren.
Kita dapat membulatkan posisi menjadi bilangan bulat, yang sesuai dengan tujuan kita.
df['posisi'] = df['posisi'].round(0).astype('int64')
Anda harus mengikuti semua langkah pembersihan lainnya yang dijelaskan di atas dan kemudian menyesuaikan kolom tanggal.
Kami mengekstraksi bulan dan tahun dengan bantuan panda. Anda tidak perlu sespesifik ini jika bekerja dengan kerangka waktu yang lebih pendek, ini adalah contoh yang memperhitungkan setengah tahun.
#konversi tanggal ke format yang tepat df['tanggal'] = pd.to_datetime(df['tanggal']) #ekstrak bulan df['bulan'] = df['tanggal'].dt.bulan #ekstrak tahun df['tahun'] = df['tanggal'].dt.tahun
[Ebook] Data SEO: Petualangan Besar Berikutnya
 Baca ebooknya
Baca ebooknyaAnalisis Data Eksplorasi
Keuntungan utama tentang Python adalah Anda dapat melakukan hal yang sama seperti yang Anda lakukan di Excel tetapi dengan lebih banyak opsi dan lebih mudah. Mari kita mulai dengan sesuatu yang sangat diketahui oleh setiap analis: tabel pivot.
Menganalisis RKT rata-rata per grup posisi
Menganalisis Rata-rata RKT per grup posisi adalah salah satu aktivitas yang paling berwawasan karena memungkinkan Anda memahami situasi umum situs web. Terapkan pivot dan kemudian mari kita plot.
pd.options.display.float_format = '{:.2%}'.format
query_analysis = df.pivot_table(index=['position'], values=['ctr'], aggfunc=['mean'])
query_analysis.sort_values(by=['position'], ascending=True).head(10)
ax = query_analysis.head(10).plot(kind='bar')
ax.set_xlabel('Posisi Rata-Rata')
ax.set_ylabel('RKT')
ax.set_title('RKT menurut posisi rata-rata')
ax.grid('pada')
ax.get_legend().hapus()
plt.xticks(rotasi=0)
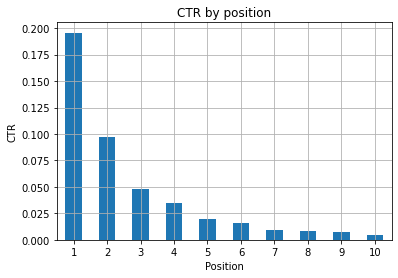
Gambar 1: Mewakili RKT berdasarkan posisi untuk menemukan anomali.
Skenario yang ideal di sini adalah memiliki RKT yang lebih baik di sisi kiri grafik, karena biasanya hasil di Posisi 1 akan menampilkan RKT yang jauh lebih tinggi. Namun berhati-hatilah, Anda mungkin melihat beberapa kasus di mana 3 tempat pertama memiliki RKT lebih rendah dari yang diharapkan, dan Anda harus menyelidikinya.
Tolong, pertimbangkan juga kasus tepi, misalnya di mana posisi 11 lebih baik daripada yang pertama. Seperti yang dijelaskan dalam dokumentasi Google untuk Search Console, metrik ini tidak mengikuti urutan yang mungkin Anda pikirkan pada awalnya.
Selain itu, ia menambahkan bahwa metrik ini adalah rata-rata, karena posisi tautan berubah setiap saat dan tidak mungkin memiliki akurasi 100%.
Terkadang peringkat halaman Anda tinggi tetapi tidak cukup meyakinkan, jadi Anda bisa mencoba memperbaiki judulnya. Karena ini adalah ikhtisar tingkat tinggi, Anda tidak akan melihat perbedaan terperinci, jadi harap bertindak cepat jika masalah ini berskala besar.
Perhatikan juga saat sekelompok halaman di posisi yang lebih rendah memiliki RKT rata-rata yang lebih tinggi daripada yang berada di tempat yang lebih baik.
Untuk alasan ini, Anda mungkin ingin memperluas analisis Anda hingga posisi 15 atau lebih, untuk menemukan pola yang aneh.
Hitungan kueri per posisi dan pengukuran upaya SEO
Peningkatan kueri yang Anda rangking selalu merupakan sinyal yang baik, namun itu tidak berarti peringkat yang lebih baik di masa mendatang. Hitungan kueri adalah proses menghitung jumlah kueri yang Anda rangking dan merupakan salah satu tugas terpenting yang dapat Anda lakukan dengan data GSC.
Tabel pivot sangat membantu sekali lagi, dan kami dapat memplot hasilnya.
ranking_queries = df.pivot_table(index=['position'], values=['query'], aggfunc=['count']) ranking_queries.sort_values(by=['position']).head(10)
Apa yang Anda inginkan sebagai Pakar SEO adalah memiliki jumlah kueri yang lebih tinggi di sisi paling kiri, posisi teratas. Alasannya cukup alami, posisi tinggi rata-rata mendapatkan RKPT yang lebih baik, yang dapat diterjemahkan ke lebih banyak orang yang mengklik halaman Anda.
kapak = ranking_queries.head(10).plot(kind='bar')
ax.set_ylabel('Jumlah kueri')
ax.set_xlabel('Posisi')
ax.set_title('Distribusi peringkat')
ax.grid('pada')
ax.get_legend().hapus()
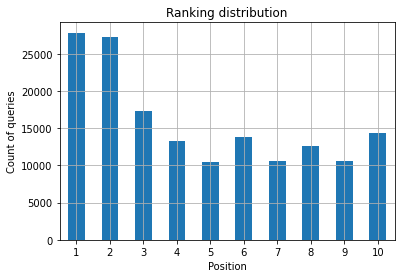
Gambar 2: Berapa banyak kueri yang saya miliki berdasarkan posisi?
Yang Anda pedulikan adalah meningkatkan jumlah kueri di posisi teratas seiring berjalannya waktu.
Bermain dengan dimensi tanggal
Mari kita lihat bagaimana klik bervariasi dalam interval waktu yang dipertimbangkan, mari kita dapatkan jumlah kliknya terlebih dahulu:
clicks_sum = df.groupby('date')['clicks'].sum()
Kami mengelompokkan data berdasarkan dimensi tanggal dan mendapatkan jumlah klik untuk masing-masingnya, ini adalah jenis ringkasan.
Kami sekarang siap untuk merencanakan apa yang kami dapatkan, kodenya akan cukup panjang hanya untuk meningkatkan visualisasi, jangan takut dengan itu.

# Jumlah klik di seluruh periode
%config InlineBackend.figure_format = 'retina'
dari angka impor matplotlib.pyplot
angka(ukuran gambar=(8, 6), dpi=80)
kapak = jumlah_klik.plot(warna='merah')
ax.grid('pada')
ax.set_ylabel('Jumlah klik')
ax.set_xlabel('Bulan')
ax.set_title('Bagaimana klik bervariasi setiap bulan')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('miring')
xlab.set_size(10)
ylab.set_style('miring')
ylab.set_size(10)
ttl = ax.title
ttl.set_weight('tebal')
ax.spines['kanan'].set_color((.8,.8,.8))
ax.spines['top'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='kuning')
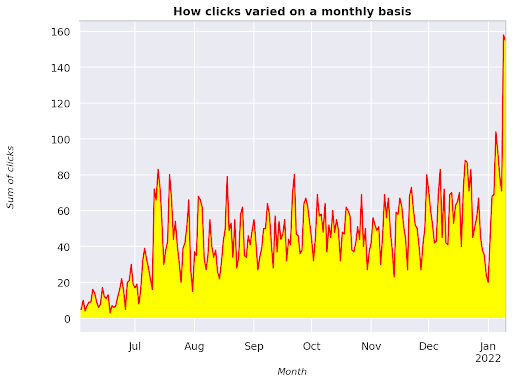
Gambar 3: Memplot jumlah klik dalam kaitannya dengan variabel bulan
Ini adalah contoh mulai dari Juni 2021 dan langsung ke setengah Januari 2022. Semua baris yang Anda lihat di atas memiliki peran untuk membuat visualisasi ini lebih cantik, Anda dapat mencoba bermain dengannya untuk melihat apa yang terjadi.
Jumlah kueri per posisi, snapshot bulanan
Visualisasi keren lainnya yang dapat kita plot dengan Python adalah peta panas, yang bahkan lebih visual daripada barplot sederhana. Saya akan menunjukkan kepada Anda bagaimana menampilkan jumlah kueri dari waktu ke waktu dan menurut posisinya.
impor seaborn sebagai sns sns.set_theme() df_new = df.loc[(df['position'] <= 10) & (df['year'] != 2022),:] # Muat contoh dataset penerbangan dan konversikan ke bentuk panjang df_heat = df_new.pivot_table(indeks = "posisi", kolom = "bulan", nilai = "kueri", aggfunc='hitung') # Gambar peta panas dengan nilai numerik di setiap sel f, ax = plt.subplots(figsize=(20, 12)) x_axis_labels = ["September", "Oktober", "November", "Desember"] sns.heatmap(df_heat, annot=True, linewidths=.5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Bulan', ylabel='Posisi', title = 'Bagaimana jumlah kueri per posisi berubah seiring waktu') #rotate Label posisi agar lebih mudah dibaca plt.yticks(rotasi=0)
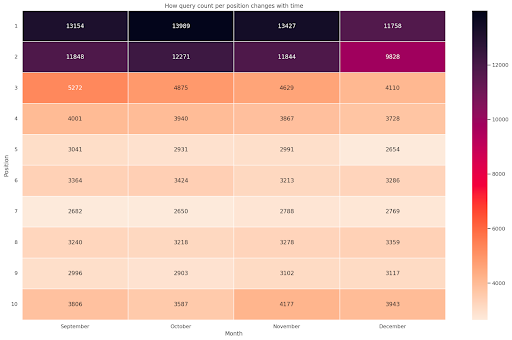
Gambar 4: Peta panas yang menunjukkan progres penghitungan kueri menurut posisi dan bulan.
Ini adalah salah satu favorit saya, peta panas bisa sangat efektif untuk menampilkan tabel pivot, seperti dalam contoh ini. Periode ini berlangsung selama 4 bulan dan jika Anda membacanya secara horizontal, Anda dapat melihat bagaimana jumlah kueri berubah seiring berjalannya waktu. Untuk posisi 10 mengalami sedikit kenaikan dari bulan September sampai Desember, tetapi untuk posisi 2 mengalami penurunan yang mencolok, seperti yang ditunjukkan oleh warna ungu.
Dalam skenario berikut, Anda memiliki sebagian besar kueri di posisi teratas yang bisa sangat tidak biasa. Jika itu terjadi, Anda mungkin ingin kembali dan menganalisis kerangka data, mencari kemungkinan istilah bermerek, jika ada.
Seperti yang Anda lihat dari kodenya, tidak sulit untuk membuat plot yang rumit, selama Anda mendapatkan logikanya.
Jumlah kueri akan meningkat seiring waktu jika Anda melakukan hal yang "benar" dan kami dapat memplot perbedaannya di dua kerangka waktu yang berbeda. Dalam contoh yang saya berikan jelas tidak demikian, karena, terutama untuk posisi teratas, di mana Anda seharusnya memiliki RKPT yang lebih tinggi.
Memperkenalkan beberapa konsep dasar NLP
Natural Language Processing (NLP) adalah anugerah untuk SEO dan Anda tidak perlu menjadi ahli untuk menerapkan algoritme dasar. N-gram adalah salah satu ide paling kuat namun sederhana yang dapat memberi Anda wawasan dengan data GSC.
N-gram adalah urutan huruf, suku kata, atau kata yang berdekatan. Untuk kata-kata analisis kami akan menjadi unit ukuran. Sebuah n-gram disebut bigram jika elemen-elemen yang berdekatan adalah dua (sepasang) dan trigram jika mereka tiga, dan seterusnya. Saya menyarankan Anda untuk menguji dengan kombinasi yang berbeda dan paling banyak hingga 5 gram.
Dengan cara ini, Anda dapat menemukan kalimat yang paling umum di halaman pesaing Anda atau untuk menilai kalimat Anda sendiri. Karena Google mungkin mengandalkan pengindeksan berbasis frasa, lebih baik untuk mengoptimalkan kalimat daripada kata kunci individual, seperti yang ditunjukkan oleh paten Google yang melibatkan topik ini.
Sebagaimana dinyatakan di halaman di atas oleh Bill Slawski sendiri, nilai pemahaman istilah terkait sangat berharga untuk pengoptimalan dan untuk pengguna Anda.
Pustaka nltk sangat terkenal dengan aplikasi NLP dan memberi kita kemungkinan untuk menghapus kata berhenti dalam bahasa tertentu, seperti bahasa Inggris. Anggap mereka sebagai kebisingan yang ingin Anda hapus, pada kenyataannya, artikel dan kata-kata yang sangat sering tidak menambah nilai dalam memahami teks.
impor nltk
nltk.download('stopwords')
dari nltk.corpus mengimpor stopwords
stoplist = stopwords.words('bahasa Inggris')
dari sklearn.feature_extraction.text impor CountVectorizer
c_vec = CountVectorizer(stop_words=stoplist, ngram_range=(2,3))
# matriks ngram
ngram = c_vec.fit_transform(df['query'])
# hitung frekuensi ngram
count_values = ngrams.toarray().sum(axis=0)
# daftar ngram
vocab = c_vec.vocabulary_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) for k,i in vocab.items()], reverse=True)
).rename(columns={0: 'frequency', 1:'bigram/trigram'})
df_ngram.head(20).style.background_gradient()
Kami mengambil kolom kueri dan menghitung frekuensi bi-gram untuk membuat kerangka data yang menyimpan bi-gram dan jumlah kemunculannya.
Langkah ini sebenarnya sangat penting untuk menganalisa website kompetitor juga. Anda cukup mengikis teks mereka dan memeriksa n-gram apa yang paling umum, dengan menyetel n setiap kali untuk melihat apakah Anda menemukan pola yang berbeda di halaman berperingkat tinggi.
Jika Anda memikirkannya sejenak, itu jauh lebih masuk akal, karena kata kunci individual tidak memberi tahu Anda apa pun tentang konteksnya.
Buah gantung rendah
Salah satu hal yang paling menyenangkan untuk dilakukan adalah memeriksa buah-buahan yang menggantung rendah, halaman-halaman yang dapat Anda tingkatkan dengan mudah untuk melihat hasil yang baik sedini mungkin. Ini sangat penting dalam langkah pertama setiap proyek SEO untuk meyakinkan pemangku kepentingan Anda. Oleh karena itu, jika ada kesempatan untuk memanfaatkan halaman seperti itu, lakukan saja!
Kriteria kami untuk mempertimbangkan halaman seperti itu adalah kuantil untuk tayangan dan RKT. Dengan kata lain, kami memfilter baris yang berada di 80% tayangan teratas tetapi berada di 20% yang menerima RKT terendah. Baris ini akan memiliki RKPT lebih buruk dari 80% dari yang lain.
top_impressions = df[df['impressions'] >= df['impressions'].quantile(0.8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0.2)].sort_values('impressions', ascending = False))
Sekarang Anda memiliki daftar dengan semua peluang yang diurutkan berdasarkan Tayangan, dalam urutan menurun.
Anda dapat memikirkan kriteria lain untuk menentukan apa itu buah gantung rendah, sesuai dengan kebutuhan situs web Anda dan ukurannya.
Untuk situs web yang lebih kecil, Anda dapat mempertimbangkan untuk mencari persentase yang lebih tinggi, sedangkan di situs web besar Anda seharusnya sudah mendapatkan banyak informasi dengan kriteria yang saya gunakan.
[Ebook] Teknis SEO untuk pemikir non-teknis
 Baca ebooknya
Baca ebooknyaMemperkenalkan querycat: klasifikasi dan asosiasi
Querycat adalah pustaka sederhana namun kuat yang menampilkan penambangan aturan asosiasi untuk mengelompokkan kata kunci dan banyak lagi. Saya hanya akan menunjukkan kepada Anda asosiasi karena mereka lebih berharga dalam jenis analisis ini.
Anda dapat mempelajari lebih lanjut tentang perpustakaan yang luar biasa ini dengan melihat repositori GitHub querycat.
Intro singkat tentang pembelajaran aturan asosiasi
Pembelajaran aturan asosiasi adalah metode untuk menemukan aturan yang mendefinisikan asosiasi dan kejadian bersama di seluruh set item. Ini sedikit berbeda dari metode pembelajaran mesin tanpa pengawasan lainnya, yang disebut pengelompokan.
Tujuan akhirnya sama, mendapatkan kelompok kata kunci untuk memahami bagaimana kinerja situs web kami untuk beberapa topik.
Querycat memberi Anda kemungkinan untuk memilih di antara dua algoritme: Apriori dan FP-Growth. Kami akan memilih yang terakhir untuk kinerja yang lebih baik, sehingga Anda dapat mengabaikan yang pertama.
FP-Growth adalah versi Apriori yang ditingkatkan untuk menemukan pola yang sering muncul dalam kumpulan data. Pembelajaran aturan asosiasi juga sangat berguna untuk transaksi e-niaga, Anda mungkin tertarik untuk memahami apa yang orang beli bersama, misalnya.
Dalam hal ini, fokus kami adalah semua pada kueri, tetapi aplikasi lain yang saya sebutkan dapat menjadi ide lain yang berguna untuk data Google Analytics.
Menjelaskan algoritma ini dari perspektif struktur data cukup menantang dan menurut saya tidak perlu untuk tugas SEO Anda. Saya hanya akan menjelaskan beberapa konsep dasar untuk memahami apa yang dimaksud dengan parameter.
3 elemen utama dari 2 algoritma adalah:
- Dukungan – Ini mengungkapkan popularitas item atau itemset. Dengan kata teknis, ini adalah jumlah transaksi di mana kueri X dan kueri Y muncul bersama dibagi dengan jumlah total transaksi.
Selain itu, dapat digunakan sebagai ambang batas untuk menghapus item yang jarang. Sangat berguna untuk meningkatkan signifikansi dan kinerja statistik. Menetapkan dukungan minimum yang baik sangat baik. - Keyakinan - Anda dapat menganggapnya sebagai probabilitas kemunculan bersama untuk istilah.
- Lift – Rasio antara dukungan untuk (istilah 1 dan istilah 2) dan dukungan dari istilah 1. Kita dapat melihat nilainya untuk mendapatkan wawasan tentang hubungan antar istilah. Jika lebih besar dari 1 istilah berkorelasi; jika kurang dari 1 istilah tidak mungkin memiliki asosiasi: jika lift tepat 1 (atau dekat) tidak ada hubungan yang signifikan.
Rincian lebih lanjut disediakan dalam artikel ini tentang querycat yang ditulis oleh penulis perpustakaan.
Sekarang kita siap untuk beralih ke bagian praktis.
impor querycat
query_cat = querycat.Categorize(df, 'query', min_support=10, alg='fpgrowth')
dfgrouped = df.groupby('category').agg(sumclicks = ('clicks', 'sum')).sort_values('sumclicks', ascending=False)
#buat grup untuk memfilter kategori dengan kurang dari 15 klik (nomor arbitrer)
filtergroup = dfgrouped[dfgrouped['sumclicks'] > 15]
grup filter
#terapkan filter
df = df.merge(filtergroup, on=['category','category'], how='inner')
Kami telah memfilter kategori yang lebih jarang dalam prosesnya, saya memilih 15 sebagai tolok ukur dalam kasus saya. Itu hanya angka arbitrer, tidak ada kriteria di baliknya.
Mari kita periksa kategori kita dengan cuplikan berikut:
df['kategori'].nilai_jumlah()
Bagaimana dengan 10 kategori yang paling banyak diklik? Mari kita periksa berapa banyak kueri yang kita miliki untuk masing-masingnya.
df.groupby('category').sum()['clicks'].sort_values(ascending=False).head(10)
Nomor yang dipilih bersifat arbitrer, pastikan untuk memilih salah satu yang menyaring persentase grup yang baik. Salah satu ide potensial adalah mendapatkan median tayangan dan menurunkan 50% terendah, asalkan Anda ingin mengecualikan grup kecil.
Mendapatkan cluster dan apa yang harus dilakukan dengan output
Rekomendasi saya adalah mengekspor kerangka data baru Anda untuk menghindari menjalankan FP-Growth lagi, silakan lakukan untuk menghemat waktu yang berguna.
Segera setelah Anda memiliki kluster, Anda ingin mengetahui klik dan tayangan untuk masing-masing cluster untuk menilai area mana yang paling membutuhkan peningkatan.
grouped_df = df.groupby('category')[['clicks', 'impressions']].agg('sum')
Dengan beberapa manipulasi data, kami dapat meningkatkan hasil asosiasi kami dan memiliki klik dan tayangan untuk setiap cluster.
group_ex = df.groupby(['category'])['query'].apply(' | '.join).reset_index()
#hapus kueri duplikat lalu urutkan menurut abjad
group_ex['query'] = group_ex['query'].apply(lambda x: ' | '.join(sorted(list(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['category', 'category'], how='inner')
df_final.head()
Anda sekarang memiliki file CSV dengan semua kluster kata kunci Anda bersama dengan klik dan tayangan.
#save file csv dan unduh ke komputer lokal Anda. Jika Anda menggunakan Safari, pertimbangkan untuk beralih ke Chrome untuk mengunduh file ini karena mungkin tidak berfungsi.
df_final.to_csv('cluster_queries.csv')
file.download('cluster_queries.csv')
Sebenarnya, ada metode yang lebih baik untuk pengelompokan, ini hanyalah contoh bagaimana Anda dapat menggunakan querycat untuk melakukan banyak tugas untuk penggunaan langsung. Tujuan utama di sini adalah untuk mendapatkan wawasan sebanyak mungkin, terutama untuk situs web baru di mana Anda tidak memiliki banyak pengetahuan.
Saat ini pendekatan terbaik melibatkan semantik, jadi jika Anda ingin fokus pada pengelompokan, saya sarankan Anda mempertimbangkan untuk mempelajari grafik atau embeddings.
Namun, ini adalah topik lanjutan jika Anda seorang pemula dan Anda dapat mencoba beberapa aplikasi Streamlit bawaan yang tersedia secara online.
Data Perayapan³
 Belajarlah lagi
Belajarlah lagiKesimpulan dan apa selanjutnya
Python dapat menawarkan bantuan besar dalam menganalisis situs web Anda dan dapat membantu Anda menggabungkan pembersihan data, visualisasi, dan analisis di satu tempat. Mengekstrak data dari GSC API jelas diperlukan untuk tugas yang lebih lanjut dan merupakan pengenalan yang "lembut" untuk otomatisasi data.
Meskipun Anda dapat melakukan banyak perhitungan lanjutan dengan Python, rekomendasi saya adalah memeriksa apa yang masuk akal dalam hal nilai SEO.
Misalnya, Jumlah Kueri jauh lebih penting secara keseluruhan dalam jangka panjang, karena Anda ingin situs web Anda dipertimbangkan untuk lebih banyak kueri.
Menggunakan notebook merupakan bantuan besar untuk mengemas kode dengan komentar dan inilah alasan utama mengapa saya menyarankan Anda untuk membiasakan diri dengan Google Colab.
Ini hanyalah permulaan dari apa yang dapat ditawarkan oleh analisis data kepada Anda, karena ide-ide terbaik datang dari penggabungan kumpulan data yang berbeda.
Google Search Console sendiri merupakan alat yang ampuh dan benar-benar gratis, jumlah informasi praktis yang dapat Anda peroleh darinya hampir tidak terbatas di tangan yang tepat.