
Signifikansi Statistik Pengujian A/B: Bagaimana dan Kapan Mengakhiri Pengujian
Diterbitkan: 2020-05-22
Dalam analisis terbaru kami terhadap 28.304 eksperimen yang dijalankan oleh pelanggan Convert, kami menemukan bahwa hanya 20% eksperimen yang mencapai tingkat signifikansi statistik 95%. Econsultancy menemukan tren serupa dalam laporan pengoptimalannya tahun 2018. Dua pertiga respondennya melihat “pemenang yang jelas dan signifikan secara statistik” hanya dalam 30% atau kurang dari eksperimen mereka.
Jadi sebagian besar eksperimen (70-80%) tidak dapat disimpulkan atau dihentikan lebih awal.
Dari jumlah tersebut, yang dihentikan lebih awal membuat kasus yang aneh karena pengoptimal mengambil panggilan untuk mengakhiri eksperimen saat mereka anggap cocok. Mereka melakukannya ketika mereka dapat "melihat" pemenang (atau pecundang) yang jelas atau ujian yang jelas tidak signifikan. Biasanya, mereka juga memiliki beberapa data untuk membenarkannya.
Ini mungkin tidak terlalu mengejutkan, mengingat 50% pengoptimal tidak memiliki "titik perhentian" standar untuk eksperimen mereka. Bagi sebagian besar, melakukannya adalah suatu keharusan, berkat tekanan karena harus mempertahankan kecepatan pengujian tertentu (tes XXX/bulan) dan perlombaan untuk mendominasi kompetisi mereka.
Lalu ada juga kemungkinan eksperimen negatif yang merugikan pendapatan. Penelitian kami sendiri telah menunjukkan bahwa eksperimen yang tidak menang, rata-rata, dapat menyebabkan penurunan rasio konversi sebesar 26% !
Semua mengatakan, mengakhiri eksperimen lebih awal masih berisiko …
… karena meninggalkan kemungkinan eksperimen berjalan sesuai keinginannya, didukung oleh ukuran sampel yang tepat, hasilnya bisa saja berbeda.
Jadi, bagaimana tim yang mengakhiri eksperimen lebih awal tahu kapan waktunya untuk mengakhirinya? Bagi sebagian besar, jawabannya terletak pada pembuatan aturan penghentian yang mempercepat pengambilan keputusan, tanpa mengurangi kualitasnya.
Beranjak dari aturan berhenti tradisional
Untuk percobaan web, nilai p 0,05 berfungsi sebagai standar. Toleransi kesalahan 5 persen atau tingkat signifikansi statistik 95% ini membantu pengoptimal menjaga integritas pengujian mereka. Mereka dapat memastikan hasilnya adalah hasil aktual dan bukan kebetulan.
Dalam model statistik tradisional untuk pengujian cakrawala tetap — di mana data pengujian dievaluasi hanya sekali pada waktu yang tetap atau pada sejumlah pengguna yang terlibat — Anda akan menerima hasil yang signifikan bila Anda memiliki nilai-p lebih rendah dari 0,05. Pada titik ini, Anda dapat menolak hipotesis nol bahwa kontrol dan perawatan Anda sama dan bahwa hasil yang diamati tidak kebetulan.
Tidak seperti model statistik yang memberi Anda ketentuan untuk mengevaluasi data saat dikumpulkan, model pengujian semacam itu melarang Anda melihat data eksperimen saat sedang berjalan. Praktik ini — juga dikenal sebagai mengintip — tidak disarankan dalam model seperti itu karena nilai p berfluktuasi hampir setiap hari. Anda akan melihat bahwa suatu eksperimen akan menjadi signifikan suatu hari dan hari berikutnya, nilai p-nya akan naik ke titik yang tidak signifikan lagi.
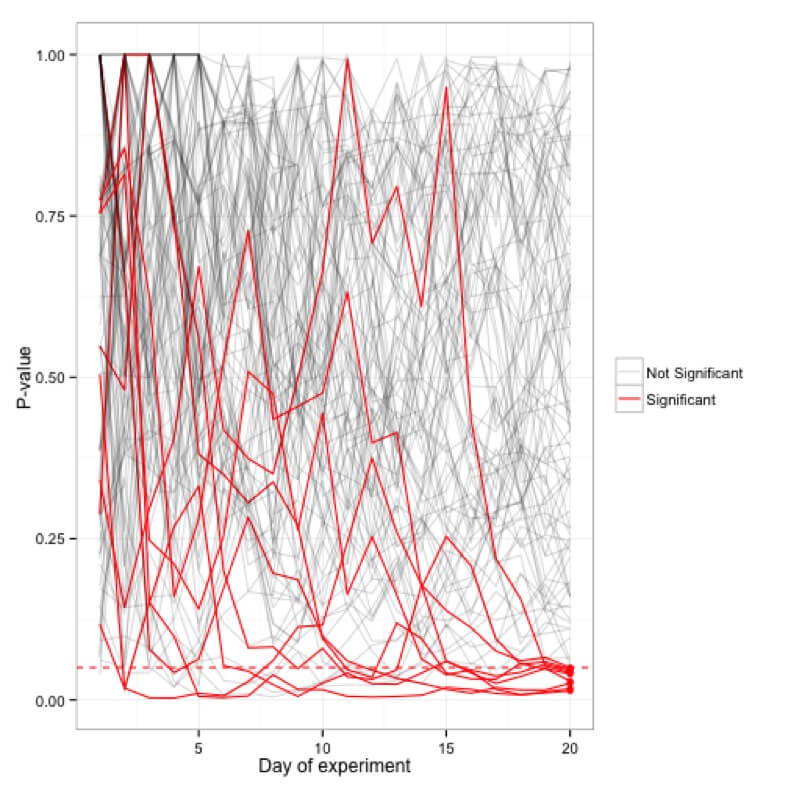
Simulasi nilai-p yang diplot selama seratus (20 hari) percobaan; hanya 5 percobaan yang benar-benar menjadi signifikan pada tanda 20 hari sementara banyak yang kadang-kadang mencapai batas <0,05 untuk sementara.
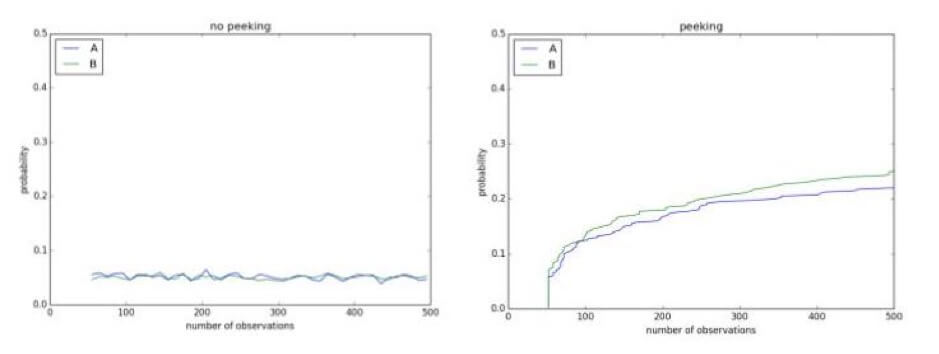
Mengintip eksperimen Anda untuk sementara dapat menunjukkan hasil yang tidak ada. Misalnya, di bawah ini Anda memiliki tes A/A menggunakan tingkat signifikansi 0,1. Karena ini adalah tes A/A, tidak ada perbedaan antara kontrol dan perlakuan. Namun, setelah 500 pengamatan selama percobaan yang sedang berlangsung, ada lebih dari 50% kemungkinan untuk menyimpulkan bahwa mereka berbeda dan bahwa hipotesis nol dapat ditolak:
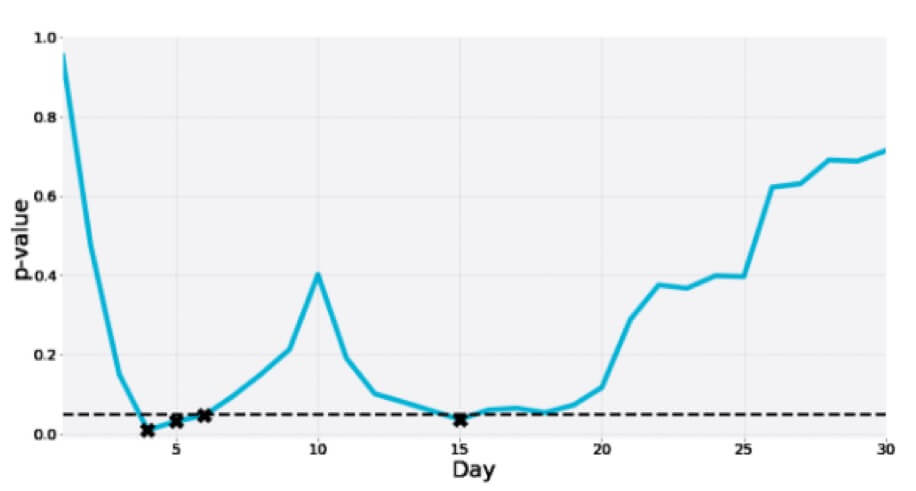
Inilah salah satu dari tes A/A selama 30 hari di mana nilai-p turun ke zona signifikansi beberapa kali untuk sementara hanya untuk akhirnya menjadi jauh lebih dari batas:
Melaporkan nilai p dengan benar dari eksperimen cakrawala tetap berarti Anda harus melakukan pra-komit ke ukuran sampel tetap atau durasi pengujian. Beberapa tim juga menambahkan sejumlah konversi ke kriteria penghentian eksperimen ini dan durasi yang diinginkan.
Namun, masalahnya di sini adalah bahwa memiliki lalu lintas uji yang cukup untuk mendorong setiap percobaan untuk penghentian optimal menggunakan praktik standar ini sulit dilakukan untuk sebagian besar situs web.
Di sinilah menggunakan metode pengujian berurutan yang mendukung aturan penghentian opsional membantu.
Bergerak menuju aturan penghentian fleksibel yang memungkinkan keputusan lebih cepat
Metode pengujian berurutan memungkinkan Anda memanfaatkan data eksperimen saat muncul dan menggunakan model signifikansi statistik Anda sendiri untuk menemukan pemenang lebih cepat, dengan aturan penghentian yang fleksibel.
Tim pengoptimalan pada tingkat kematangan CRO tertinggi sering merancang metodologi statistik mereka sendiri untuk mendukung pengujian tersebut. Beberapa alat pengujian A/B juga memasukkan ini ke dalamnya dan dapat menyarankan jika suatu versi tampaknya menang. Dan beberapa memberi Anda kendali penuh atas bagaimana Anda ingin signifikansi statistik Anda dihitung, dengan nilai khusus Anda dan banyak lagi. Jadi, Anda dapat mengintip dan melihat pemenang bahkan dalam eksperimen yang sedang berlangsung.

Ahli statistik, penulis, dan instruktur kursus CXL populer tentang statistik pengujian A/B, Georgi Georgiev cocok untuk metode pengujian berurutan yang memungkinkan fleksibilitas dalam jumlah dan waktu analisis sementara:
“ Pengujian berurutan memungkinkan Anda memaksimalkan keuntungan dengan penerapan awal varian pemenang, serta menghentikan pengujian yang memiliki kemungkinan kecil untuk menghasilkan pemenang sedini mungkin. Yang terakhir meminimalkan kerugian karena varian yang lebih rendah dan mempercepat pengujian ketika varian tidak mungkin mengungguli kontrol. Kekakuan statistik dipertahankan dalam semua kasus. ”
Georgiev bahkan telah mengerjakan kalkulator yang membantu tim membuang model pengujian sampel tetap untuk model yang dapat mendeteksi pemenang saat eksperimen masih berjalan. Modelnya memperhitungkan banyak statistik dan membantu Anda melakukan tes sekitar 20-80% lebih cepat daripada perhitungan signifikansi statistik standar, tanpa mengorbankan kualitas.
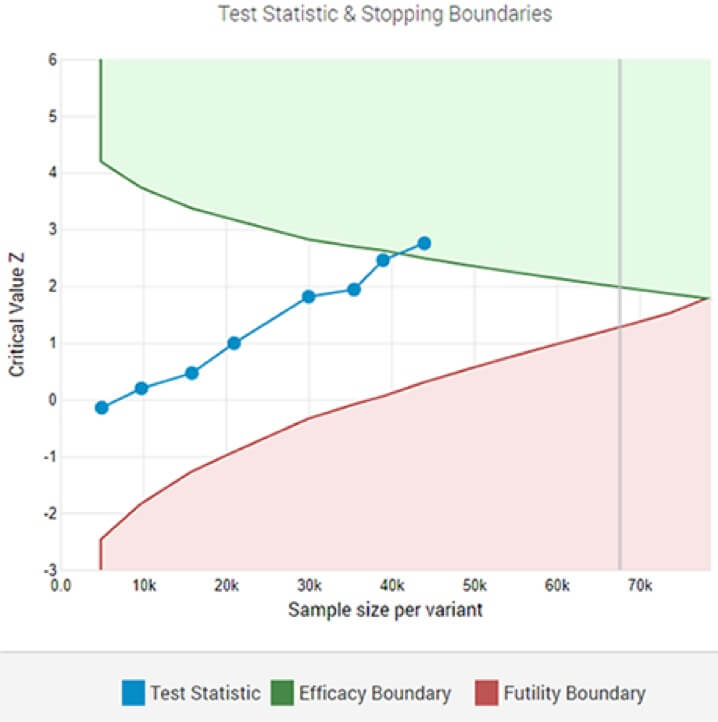
Uji A/B adaptif yang menunjukkan pemenang yang signifikan secara statistik pada ambang signifikansi yang ditentukan setelah analisis sementara ke-8.
Meskipun pengujian semacam itu dapat mempercepat proses pengambilan keputusan Anda, ada satu aspek penting yang perlu ditangani: dampak eksperimen yang sebenarnya . Mengakhiri eksperimen untuk sementara dapat membuat Anda melebih-lebihkannya.
Melihat perkiraan yang tidak disesuaikan untuk ukuran efek bisa berbahaya, Georgiev memperingatkan. Untuk menghindari hal ini, modelnya menggunakan metode untuk menerapkan penyesuaian yang memperhitungkan bias yang timbul akibat pemantauan sementara. Dia menjelaskan bagaimana analisis tangkas mereka menyesuaikan perkiraan “bergantung pada tahap penghentian dan nilai statistik yang diamati (overshoot, jika ada).” Di bawah ini, Anda dapat melihat analisis untuk pengujian di atas: (Perhatikan bagaimana perkiraan kenaikan lebih rendah dari yang diamati dan interval tidak terpusat di sekitarnya.)
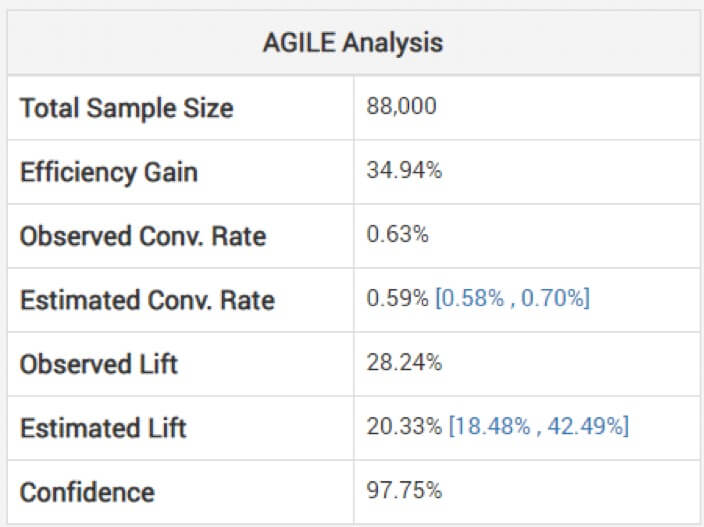
Jadi, kemenangan mungkin tidak sebesar yang terlihat berdasarkan eksperimen Anda yang lebih singkat dari yang direncanakan.
Kerugiannya juga perlu diperhitungkan, karena Anda mungkin masih salah menyebut pemenang terlalu cepat. Tetapi risiko ini ada bahkan dalam pengujian cakrawala tetap. Validitas eksternal, bagaimanapun, mungkin menjadi perhatian yang lebih besar saat memanggil eksperimen lebih awal dibandingkan dengan tes cakrawala tetap yang berjalan lebih lama. Tapi ini, seperti yang dijelaskan Georgiev, “ konsekuensi sederhana dari ukuran sampel yang lebih kecil dan dengan demikian durasi pengujian. “
Pada akhirnya… Ini bukan tentang pemenang atau pecundang…
… tetapi tentang keputusan bisnis yang lebih baik, seperti yang dikatakan Chris Stucchio.
Atau seperti yang dinyatakan oleh Tom Redman (penulis Data Driven: Profiting from Your Most Important Business Asset) bahwa dalam bisnis: “ seringkali ada kriteria yang lebih penting daripada signifikansi statistik. Pertanyaan pentingnya adalah, “ Apakah hasilnya bertahan di pasar, jika hanya untuk waktu yang singkat? ”'
Dan kemungkinan besar akan, dan bukan hanya untuk periode singkat, catat Georgiev, “ jika secara statistik signifikan dan pertimbangan validitas eksternal ditangani dengan cara yang memuaskan pada tahap desain.”
Inti dari eksperimen adalah memberdayakan tim untuk membuat keputusan yang lebih tepat. Jadi, jika Anda dapat menyampaikan hasil — yang ditunjukkan oleh data eksperimen Anda — lebih cepat, mengapa tidak?
Ini mungkin eksperimen UI kecil yang secara praktis tidak bisa Anda dapatkan dengan ukuran sampel yang "cukup". Ini mungkin juga merupakan eksperimen di mana penantang Anda menghancurkan yang asli dan Anda bisa mengambil taruhan itu!
Seperti yang ditulis Jeff Bezos dalam suratnya kepada para pemegang saham Amazon, eksperimen besar membutuhkan banyak waktu:
“ Diberi kesempatan sepuluh persen dari hasil 100 kali, Anda harus mengambil taruhan itu setiap saat. Tapi Anda masih akan salah sembilan kali dari sepuluh. Kita semua tahu bahwa jika Anda mengayun ke pagar, Anda akan banyak menyerang, tetapi Anda juga akan memukul beberapa home run. Perbedaan antara bisbol dan bisnis, bagaimanapun, adalah bahwa bisbol memiliki distribusi hasil yang terpotong. Saat Anda mengayun, tidak peduli seberapa baik Anda terhubung dengan bola, lari paling banyak yang bisa Anda dapatkan adalah empat. Dalam bisnis, sesekali, ketika Anda melangkah ke atas, Anda bisa mencetak 1.000 run. Distribusi pengembalian berekor panjang inilah mengapa penting untuk berani. Pemenang besar membayar begitu banyak eksperimen. “
Menyebutkan eksperimen lebih awal, hingga tingkat yang luar biasa, seperti mengintip hasil setiap hari dan berhenti pada titik yang menjamin taruhan yang bagus.

