
Pembelajaran Mendalam vs. Pembelajaran Mesin – bagaimana membedakannya?
Diterbitkan: 2020-03-10Dalam beberapa tahun terakhir, Machine Learning, Deep Learning, dan Artificial Intelligence telah menjadi kata-kata buzz. Akibatnya, Anda dapat menemukannya di mana-mana dalam materi pemasaran dan iklan dari semakin banyak perusahaan.
Tapi apa itu Machine Learning dan Deep Learning? Juga, apa perbedaan di antara mereka? Pada artikel ini, saya akan mencoba menjawab pertanyaan-pertanyaan ini, dan menunjukkan kepada Anda beberapa kasus aplikasi Deep dan Machine Learning.
Apa itu Pembelajaran Mesin?
Machine Learning adalah bagian dari Ilmu Komputer yang berhubungan dengan merepresentasikan peristiwa atau objek dunia nyata dengan model matematika, berdasarkan data. Model-model ini dibangun dengan algoritma khusus yang mengadaptasi struktur umum model sehingga cocok dengan data pelatihan. Bergantung pada jenis masalah yang dipecahkan, kami mendefinisikan algoritma Machine Learning dan Machine Learning yang diawasi dan tidak.
Machine Learning yang diawasi vs. tidak diawasi
Pembelajaran Mesin yang Dibimbing berfokus pada pembuatan model yang dapat mentransfer pengetahuan yang sudah kita miliki tentang data yang ada ke data baru. Data baru tidak terlihat oleh algoritma pembuatan model (pelatihan) selama fase pelatihan. Kami menyediakan algoritme dengan data fitur bersama dengan nilai terkait yang harus dipelajari algoritme untuk menyimpulkannya (disebut variabel target).
Dalam Pembelajaran Mesin tanpa pengawasan, kami hanya menyediakan algoritme dengan fitur. Itu memungkinkannya untuk mengetahui struktur dan/atau dependensinya sendiri. Tidak ada variabel target yang jelas ditentukan. Gagasan pembelajaran tanpa pengawasan mungkin sulit dipahami pada awalnya, tetapi melihat contoh yang diberikan pada empat grafik di bawah ini akan memperjelas gagasan ini.
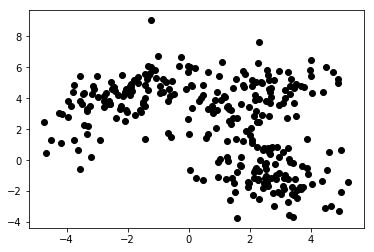
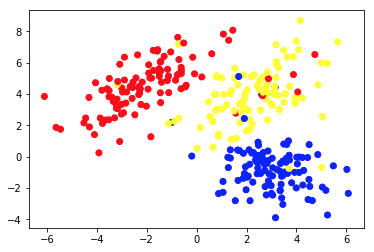

Bagan 1a menyajikan beberapa data yang dijelaskan dengan 2 fitur pada sumbu x dan y . Yang ditandai sebagai 1b menunjukkan data yang sama berwarna. Kami menggunakan algoritme pengelompokan K- means untuk mengelompokkan titik-titik ini menjadi 3 klaster, dan mewarnainya sesuai dengan itu. Ini adalah contoh dari algoritma Machine Learning tanpa pengawasan . Algoritme hanya diberikan fitur, dan label (nomor cluster) harus diketahui.
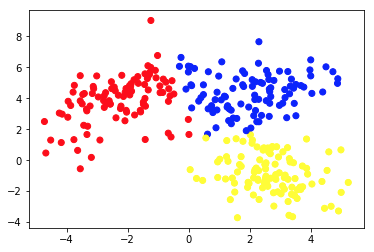
Gambar kedua menunjukkan Bagan 2a, yang menyajikan sekumpulan data berlabel (dan diwarnai sesuai dengan itu). Kita tahu kelompok masing-masing titik data milik apriori . Kami menggunakan algoritme SVM untuk menemukan 2 garis lurus yang akan menunjukkan kepada kami cara membagi titik data agar sesuai dengan grup ini. Pemisahan ini tidak sempurna, tetapi ini adalah yang terbaik yang dapat dilakukan dengan garis lurus. Jika kita ingin menetapkan grup ke titik data baru yang tidak berlabel, kita hanya perlu memeriksa di mana letaknya pada bidang. Ini adalah contoh aplikasi Machine Learning yang diawasi .
Aplikasi model Pembelajaran Mesin
Algoritma Machine Learning standar dibuat untuk menangani data dalam bentuk tabel. Ini berarti bahwa untuk menggunakannya kita memerlukan semacam tabel. Dalam baris tabel seperti itu dapat dianggap sebagai contoh objek yang dimodelkan (misalnya, pinjaman). Pada saat yang sama, kolom harus dilihat sebagai fitur (karakteristik) dari contoh khusus ini (misalnya, pembayaran bulanan pinjaman, pendapatan bulanan peminjam).

Penasaran dengan pengembangan Machine Learning?
Belajarlah lagiTabel 1. adalah contoh yang sangat singkat dari data tersebut. Tentu saja, ini tidak berarti bahwa data murni itu sendiri harus berbentuk tabel dan terstruktur. Tetapi jika kita ingin menerapkan algoritma Machine Learning standar pada beberapa dataset, kita biasanya harus membersihkan, mencampur, dan mengubahnya menjadi sebuah tabel. Dalam supervised learning juga terdapat satu kolom khusus yang berisi nilai target (misalnya informasi jika pinjaman telah wanprestasi).
Algoritme pelatihan mencoba menyesuaikan struktur umum model ke dalam data ini. Algoritma tersebut melakukannya dengan mengubah parameter model. Itu menghasilkan model yang menggambarkan hubungan antara data yang diberikan dan variabel target seakurat mungkin.
Adalah penting bahwa model tidak hanya cocok dengan data pelatihan yang diberikan dengan baik tetapi juga mampu menggeneralisasi. Generalisasi berarti bahwa kita dapat menggunakan model untuk menyimpulkan target untuk instance yang tidak digunakan selama pelatihan. Ini juga merupakan fitur penting dari model yang berguna. Membangun model generalisasi yang baik bukanlah tugas yang mudah. Seringkali membutuhkan teknik validasi yang canggih dan pengujian model yang menyeluruh.
| pinjaman_id | peminjam_usia | pendapatan_bulanan | jumlah pinjaman | pembayaran bulanan | bawaan |
| 1 | 34 | 10.000 | 100.000 | 1.200 | 0 |
| 2 | 43 | 5.700 | 25.000 | 800 | 0 |
| 3 | 25 | 2.500 | 24,000 | 400 | 0 |
| 4 | 67 | 4.600 | 40.000 | 2.000 | 1 |
| 5 | 38 | 35.000 | 2.500.000 | 10.000 | 0 |
Tabel 1. Data pinjaman dalam bentuk tabel
Orang-orang menggunakan algoritma Machine Learning dalam berbagai aplikasi. Tabel 2. menyajikan beberapa kasus penggunaan bisnis yang memungkinkan algoritma dan model Machine Learning yang tidak mendalam. Ada juga deskripsi singkat tentang data potensial, variabel target, dan algoritme terpilih yang berlaku.
| Kasus penggunaan | Contoh data | Nilai target (dimodelkan) | Algoritma/model yang digunakan |
| Rekomendasi artikel di situs blog | ID artikel yang dibaca oleh pengguna, waktu yang dihabiskan untuk masing-masingnya | Preferensi pengguna terhadap artikel | Penyaringan Kolaboratif dengan Alternating Least Squares |
| Penilaian kredit hipotek | Riwayat transaksi dan kredit, data pendapatan calon peminjam | Nilai biner yang menunjukkan apakah pinjaman akan dilunasi secara penuh atau akan default | CahayaGBM |
| Memprediksi churn pengguna premium game seluler | Waktu yang dihabiskan untuk bermain setiap hari, waktu sejak peluncuran pertama, kemajuan dalam game | Nilai biner yang menunjukkan apakah pengguna akan membatalkan langganan bulan depan | XGBoost |
| Deteksi penipuan kartu kredit | Data transaksi kartu kredit historis – jumlah, tempat, tanggal dan waktu | Nilai biner yang menunjukkan jika transaksi kartu kredit adalah penipuan | Hutan acak |
| Segmentasi pelanggan toko internet | Riwayat pembelian anggota program loyalitas | Nomor segmen ditetapkan untuk setiap pelanggan | K-berarti |
| Pemeliharaan prediktif taman mesin | Data dari kinerja, suhu, kelembaban, dll. sensor | Salah satu kelas berikut – 'baik', 'untuk mengamati', 'memerlukan pemeliharaan' | Pohon keputusan |
Tabel 2. Contoh kasus penggunaan Machine Learning
Pembelajaran Mendalam dan Jaringan Saraf Dalam
Deep Learning adalah bagian dari Machine Learning di mana kami menggunakan model jenis tertentu, yang disebut jaringan saraf tiruan dalam (JST). Sejak diperkenalkan, jaringan saraf tiruan telah melalui proses evolusi yang ekstensif. Itu menyebabkan sejumlah subtipe, beberapa di antaranya sangat rumit. Tetapi untuk memperkenalkannya, yang terbaik adalah menjelaskan salah satu bentuk dasarnya – multilayer perceptron (MPL).
Perceptron berlapis-lapis
Sederhananya, MLP memiliki bentuk grafik (jaringan) dari simpul (juga disebut neuron) dan tepi (diwakili oleh angka yang disebut bobot). Neuron-neuron tersebut tersusun berlapis-lapis, dan neuron-neuron dalam lapisan-lapisan yang berurutan dihubungkan satu sama lain. Data mengalir melalui jaringan dari input ke output layer. Data kemudian ditransformasikan pada neuron dan tepi di antara mereka. Setelah titik data melewati seluruh jaringan, lapisan output berisi nilai prediksi di neuronnya.
Setiap kali sepotong data pelatihan melewati jaringan, kami membandingkan prediksi dengan nilai sebenarnya yang sesuai. Itu memungkinkan kami menyesuaikan parameter (bobot) model untuk membuat prediksi lebih baik. Kita bisa melakukannya dengan algoritma yang disebut backpropagation. Setelah beberapa iterasi, jika struktur model dirancang dengan baik secara khusus untuk mengatasi masalah Machine Learning yang dihadapi.
Mendapatkan model akurasi tinggi
Setelah data yang cukup melewati jaringan beberapa kali, kami memperoleh model akurasi tinggi. Dalam praktiknya, ada banyak transformasi yang dapat diterapkan pada neuron. Itu membuat JST sangat fleksibel dan kuat. Namun, kekuatan ANN ada harganya. Biasanya, semakin rumit struktur model, semakin banyak data dan waktu yang dibutuhkan untuk melatihnya dengan akurasi tinggi.
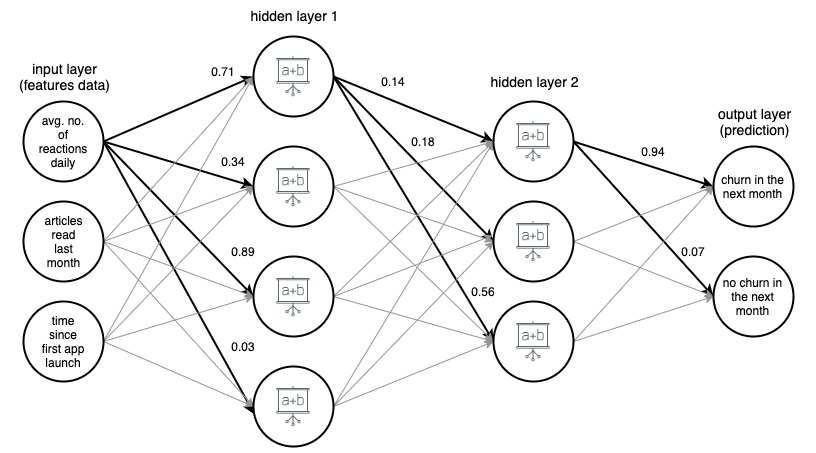
Gambar 1. (draw.io) Struktur jaringan saraf tiruan 4 lapis, memprediksi apakah pengguna aplikasi berita akan melakukan churn bulan depan, berdasarkan tiga fitur sederhana.
Untuk kejelasan, bobot telah ditandai hanya untuk tepi yang dipilih (tebal), tetapi setiap tepi memiliki bobotnya sendiri. Data mengalir dari lapisan input ke lapisan output, melewati 2 lapisan tersembunyi di tengah. Pada setiap sisi, nilai input dikalikan dengan bobot sisi, dan produk yang dihasilkan menuju ke simpul di mana tepi berakhir. Kemudian, di setiap node di lapisan tersembunyi, sinyal yang masuk dari tepi dijumlahkan dan kemudian ditransformasikan dengan beberapa fungsi. Hasil dari transformasi ini kemudian diperlakukan sebagai input ke lapisan berikutnya.
Di lapisan keluaran, data yang masuk dijumlahkan lagi dan diubah, menghasilkan hasil dalam bentuk dua angka – probabilitas bahwa pengguna akan keluar dari aplikasi di bulan berikutnya, dan kemungkinan tidak.
Jenis jaringan saraf lanjutan
Dalam jaringan saraf jenis yang lebih maju, lapisan memiliki struktur yang jauh lebih kompleks. Mereka tidak hanya terdiri dari lapisan padat sederhana dengan neuron satu operasi yang diketahui dari MLP, tetapi juga lapisan multi-operasi yang jauh lebih rumit seperti lapisan konvolusi, dan lapisan berulang.
Lapisan konvolusi dan berulang
lapisan convolutional sebagian besar digunakan dalam aplikasi visi komputer . Mereka terdiri dari array kecil angka yang meluncur di atas representasi piksel gambar. Nilai piksel dikalikan dengan angka-angka ini dan kemudian digabungkan, menghasilkan representasi gambar yang baru dan padat.
Lapisan berulang digunakan untuk memodelkan data sekuensial yang dipesan seperti deret waktu atau teks . Mereka menerapkan banyak transformasi multi-argumen yang rumit ke data yang masuk, mencoba mencari tahu ketergantungan antara item urutan. Namun demikian, tidak peduli jenis dan struktur jaringan, selalu ada beberapa (satu atau lebih) lapisan input dan output, dan jalur dan arah yang ditentukan secara ketat di mana data mengalir melalui jaringan.
Secara umum, Deep Neural Networks adalah JST dengan banyak lapisan. Gambar 1, 2, dan 3 di bawah ini menunjukkan arsitektur jaringan saraf tiruan dalam yang dipilih. Semuanya dikembangkan dan dilatih di Google, dan tersedia untuk umum. Mereka memberikan gambaran tentang betapa kompleksnya jaringan buatan dalam akurasi tinggi yang digunakan saat ini.
Jaringan ini memiliki ukuran yang sangat besar. Misalnya, sebagian ditampilkan pada Gambar 3 InceptionResNetV2 memiliki 572 lapisan, dan total lebih dari 55 juta parameter! Mereka semua telah dikembangkan sebagai model klasifikasi gambar (mereka menetapkan label, misalnya 'mobil' ke gambar tertentu), dan telah dilatih pada gambar dari set ImageNet, yang terdiri dari lebih dari 14 juta gambar berlabel.

Gambar 2. Struktur NASNetMobile (paket keras)

Gambar 3. Struktur XCeption (paket keras)

Gambar 4. Struktur bagian (sekitar 25%) dari InceptionResNetV2 (paket keras)
Dalam beberapa tahun terakhir kami telah mengamati perkembangan besar dalam Deep Learning dan aplikasinya. Banyak fitur 'pintar' dari smartphone dan aplikasi kita adalah buah dari kemajuan ini. Meskipun ide JST bukanlah hal baru, booming baru-baru ini adalah hasil dari memenuhi beberapa kondisi. Pertama-tama, kami telah menemukan potensi komputasi GPU. Arsitektur unit pemrosesan grafis sangat bagus untuk komputasi paralel, sangat membantu dalam Pembelajaran Mendalam yang efisien.
Selain itu, munculnya layanan komputasi awan telah membuat akses ke perangkat keras berefisiensi tinggi menjadi lebih mudah, lebih murah, dan memungkinkan dalam skala yang jauh lebih besar. Terakhir, kekuatan komputasi perangkat seluler terbaru cukup besar untuk menerapkan model Deep Learning, menciptakan pasar besar pengguna potensial fitur berbasis DNN.
Aplikasi model Deep Learning
Model Deep Learning biasanya diterapkan pada masalah yang berhubungan dengan data yang tidak memiliki struktur baris-kolom sederhana, seperti klasifikasi gambar atau terjemahan bahasa, karena mereka hebat dalam mengoperasikan data yang tidak terstruktur dan struktur kompleks yang ditangani oleh tugas-tugas ini – gambar, teks , dan suara. Ada masalah dengan penanganan data jenis dan ukuran ini dengan algoritma Pembelajaran Mesin klasik, dan membuat dan menerapkan beberapa jaringan saraf dalam untuk masalah ini telah menyebabkan perkembangan luar biasa di bidang pengenalan gambar, pengenalan ucapan, klasifikasi teks, dan terjemahan bahasa di beberapa tahun terakhir.
Penerapan Deep Learning untuk masalah ini dimungkinkan karena fakta bahwa DNN menerima tabel angka multi-dimensi, yang disebut tensor, baik sebagai input maupun output, dan dapat melacak hubungan spasial dan temporal antara elemen-elemennya. Misalnya, kita dapat menampilkan gambar sebagai tensor 3 dimensi, di mana dimensi satu dan dua mewakili resolusi gambar digital (begitu juga ukuran lebar dan tinggi gambar), dan dimensi ketiga mewakili warna RGB. pengkodean masing-masing piksel (jadi dimensi ketiga adalah ukuran 3).
Hal ini memungkinkan kita untuk tidak hanya mewakili semua informasi tentang gambar dalam tensor tetapi juga menjaga hubungan spasial antara piksel, yang ternyata sangat penting dalam penerapan apa yang disebut lapisan konvolusi, penting dalam klasifikasi gambar yang sukses dan jaringan pengenalan.
Fleksibilitas jaringan saraf dalam struktur input dan output juga membantu dalam tugas-tugas lain, seperti terjemahan bahasa . Saat berurusan dengan data teks, kami memberi makan jaringan saraf dalam dengan representasi angka dari kata-kata, yang diurutkan sesuai dengan penampilannya dalam teks. Setiap kata diwakili oleh vektor seratus atau beberapa ratus angka, dihitung (biasanya menggunakan jaringan saraf yang berbeda) sehingga hubungan antara vektor yang sesuai dengan kata yang berbeda meniru hubungan kata-kata itu sendiri. Representasi bahasa vektor ini, yang disebut embeddings, setelah dilatih, dapat digunakan kembali di banyak arsitektur, dan merupakan blok bangunan pusat dari model bahasa jaringan saraf.
Contoh penggunaan model Deep Learning
Tabel 3. berisi contoh penerapan model Deep Learning untuk masalah kehidupan nyata. Seperti yang Anda lihat, masalah yang ditangani dan diselesaikan oleh algoritma Deep Learning jauh lebih kompleks daripada tugas yang diselesaikan dengan teknik Machine Learning standar, seperti yang disajikan pada Tabel 1.
Namun demikian, penting untuk diingat bahwa banyak kasus penggunaan Machine Learning yang dapat membantu bisnis saat ini tidak memerlukan metode canggih seperti itu, dan dapat diselesaikan dengan lebih efisien (dan dengan akurasi lebih tinggi) dengan model standar. Tabel 3. juga memberikan gambaran tentang berapa banyak jenis lapisan jaringan saraf tiruan yang ada, dan berapa banyak arsitektur berguna yang berbeda yang dapat dibangun dengannya.
| Kasus penggunaan | Data | Target/hasil model | Algoritma/model yang digunakan |
| Klasifikasi gambar | Gambar-gambar | Label ditetapkan ke gambar | Jaringan Saraf Konvolusi (CNN) |
| Deteksi gambar dengan mobil self-driving | Gambar-gambar | Label dan kotak pembatas di sekitar objek yang diidentifikasi pada gambar | R-CNN cepat |
| Sentimen analisis dari komentar di toko online | Teks komentar online | Label sentimen (misalnya, positif, netral, negatif) ditetapkan untuk setiap komentar | Jaringan Memori Jangka Pendek Dua Arah (LSTM) |
| Harmonisasi melodi | File MIDI dengan melodi | File MIDI dengan melodi ini diselaraskan | Jaringan Permusuhan Generatif |
| Prediksi kata berikutnya dalam sebuah on line surel editor | Potongan teks yang sangat besar (misalnya, dump dari semua artikel Wikipedia dalam bahasa Inggris) | Sebuah kata yang cocok dengan teks berikutnya yang ditulis sejauh ini | Jaringan Neural Berulang (RNN) dengan lapisan Embedding |
| Terjemahan teks ke bahasa lain | Teks dalam bahasa Polandia | Teks yang sama diterjemahkan ke dalam bahasa Inggris | Encoder – Jaringan Decoder yang dibangun dengan lapisan jaringan saraf berulang (RNN) |
| Transfer gaya Monet ke gambar apa pun | Kumpulan gambar lukisan Monet, dan kumpulan gambar lainnya | Gambar dimodifikasi agar terlihat seperti dilukis oleh Monet | Jaringan Permusuhan Generatif |
Tabel 3. Contoh kasus penggunaan Deep Learning
Keuntungan model Deep Learning
Jaringan Permusuhan Generatif
Salah satu aplikasi Deep Neural Networks yang paling mengesankan datang dengan munculnya Generative Adversarial Networks (GANs). Mereka diperkenalkan pada tahun 2014 oleh Ian Goodfellow, dan sejak saat itu idenya telah dimasukkan ke dalam banyak alat, beberapa dengan hasil yang menakjubkan.
GAN bertanggung jawab atas keberadaan aplikasi yang membuat kita terlihat lebih tua di foto, mengubah gambar agar terlihat seolah-olah dilukis oleh van Gogh, atau bahkan menyelaraskan melodi untuk beberapa band instrumen. Selama pelatihan GAN, dua jaringan saraf bersaing. Jaringan generator menghasilkan output dari input acak, sementara diskriminator mencoba memberi tahu instance yang dihasilkan dari yang nyata. Selama pelatihan, generator belajar bagaimana berhasil 'menipu' diskriminator, dan akhirnya mampu membuat output yang terlihat seperti nyata.
Jaringan saraf dalam yang kuat di aplikasi seluler
Penting untuk dicatat bahwa meskipun melatih jaringan saraf dalam adalah tugas yang sangat mahal secara komputasi dan dapat memakan waktu lama, menerapkan jaringan yang terlatih untuk melakukan tugas tertentu tidak harus, terutama jika diterapkan pada satu atau beberapa kasus sekaligus. Sebenarnya, hari ini kami dapat menjalankan jaringan saraf dalam yang kuat di aplikasi seluler di ponsel cerdas kami.
Bahkan ada beberapa arsitektur jaringan yang dirancang khusus agar efisien saat diterapkan pada perangkat seluler (misalnya, NASNetMobile yang disajikan pada Gambar 1). Meskipun ukurannya jauh lebih kecil dibandingkan dengan jaringan canggih, mereka masih dapat memperoleh kinerja prediksi akurasi tinggi.
Pindah belajar
Fitur lain yang sangat kuat dari jaringan saraf tiruan, memungkinkan penggunaan model Deep Learning secara luas, adalah transfer learning . Setelah kita memiliki model yang dilatih pada beberapa data (baik yang dibuat sendiri, atau diunduh dari repositori publik), kita dapat membangun semua atau sebagian darinya untuk mendapatkan model yang memecahkan kasus penggunaan khusus kita. Misalnya, kita dapat menggunakan model NASNetLarge yang telah dilatih sebelumnya, dilatih pada dataset ImageNet yang besar, yang memberikan label pada gambar, membuat beberapa modifikasi kecil di bagian atas strukturnya, melatihnya lebih lanjut dengan kumpulan gambar berlabel baru, dan gunakan untuk memberi label pada beberapa jenis objek tertentu (misalnya spesies pohon berdasarkan gambar daunnya).
Keuntungan dari transfer belajar
Pembelajaran transfer sangat berguna, karena biasanya melatih jaringan saraf dalam yang akan melakukan beberapa tugas praktis dan berguna membutuhkan data dalam jumlah besar dan daya komputasi yang besar. Ini sering dapat berarti jutaan instans data berlabel, dan ratusan unit pemrosesan grafis (GPU) berjalan selama berminggu-minggu.
Tidak semua orang mampu atau memiliki akses ke aset tersebut, yang dapat membuat sangat sulit untuk membangun solusi kustom akurasi tinggi dari awal, katakanlah, klasifikasi gambar. Untungnya, beberapa model pra-pelatihan (terutama jaringan untuk klasifikasi gambar dan matriks penyematan pra-pelatihan untuk model bahasa) telah bersumber terbuka dan tersedia secara gratis dalam bentuk yang mudah diterapkan (misalnya sebagai contoh Model di Keras, jaringan saraf jaringan API).
Bagaimana memilih dan membangun model Machine Learning yang tepat untuk aplikasi Anda
Saat Anda ingin menerapkan Machine Learning untuk menyelesaikan masalah bisnis, Anda mungkin tidak perlu langsung memutuskan jenis modelnya. Biasanya ada beberapa pendekatan yang dapat diuji. Seringkali tergoda untuk memulai dengan model yang paling rumit pada awalnya, tetapi ada baiknya memulai yang sederhana, dan secara bertahap meningkatkan kompleksitas model yang diterapkan. Model yang lebih sederhana biasanya lebih murah dalam hal pengaturan, waktu komputasi, dan sumber daya. Selain itu, hasil mereka adalah tolok ukur yang bagus untuk mengevaluasi pendekatan yang lebih maju.
Memiliki tolok ukur semacam itu dapat membantu ilmuwan data untuk menilai apakah arah pengembangan model mereka adalah arah yang benar. Keuntungan lain adalah kemungkinan penggunaan kembali beberapa model yang dibuat sebelumnya, dan menggabungkannya dengan yang lebih baru, menciptakan apa yang disebut model ensemble. Pencampuran model dari jenis yang berbeda sering menghasilkan metrik kinerja yang lebih tinggi daripada masing-masing model gabungan saja. Juga, periksa apakah ada beberapa model pra-pelatihan yang dapat digunakan dan disesuaikan dengan kasus bisnis Anda melalui pembelajaran transfer.
Tips lebih praktis
Pertama dan terpenting, model apa pun yang Anda gunakan, pastikan bahwa data ditangani dengan benar. Ingatlah aturan 'sampah masuk, sampah keluar'. Jika data pelatihan yang diberikan kepada model berkualitas rendah atau belum diberi label dan dibersihkan dengan benar, kemungkinan besar model yang dihasilkan juga akan berkinerja buruk. Juga pastikan bahwa model – apa pun kompleksitasnya – telah divalidasi secara ekstensif selama fase pemodelan, dan pada akhirnya diuji jika dapat digeneralisasikan dengan baik ke data yang tidak terlihat.
Pada catatan yang lebih praktis, pastikan bahwa solusi yang dibuat dapat diimplementasikan dalam produksi pada infrastruktur yang tersedia. Dan jika bisnis Anda dapat mengumpulkan lebih banyak data yang dapat digunakan untuk meningkatkan model Anda di masa mendatang, jalur pelatihan ulang harus disiapkan untuk memastikan pembaruannya yang mudah. Pipa semacam itu bahkan dapat diatur untuk melatih ulang model secara otomatis dengan frekuensi waktu yang telah ditentukan.
Pikiran terakhir
Jangan lupa untuk melacak kinerja dan kegunaan model setelah penerapannya ke produksi, karena lingkungan bisnis sangat dinamis. Beberapa hubungan dalam data Anda dapat berubah seiring waktu, dan fenomena baru dapat muncul. Oleh karena itu, mereka dapat mengubah efisiensi model Anda, dan harus diperlakukan dengan benar. Selain itu, jenis model baru yang kuat dapat ditemukan. Di satu sisi, mereka dapat membuat solusi Anda relatif lemah, tetapi di sisi lain, memberi Anda kesempatan untuk lebih meningkatkan bisnis Anda dan memanfaatkan teknologi terbaru.
Terlebih lagi, model Machine dan Deep Learning dapat membantu Anda membangun alat canggih untuk bisnis dan aplikasi Anda serta memberikan pengalaman yang luar biasa kepada pelanggan Anda . Meskipun membuat fitur 'pintar' ini membutuhkan usaha yang besar, namun potensi keuntungannya sepadan. Pastikan Anda dan tim Ilmu Data Anda mencoba model yang sesuai dan mengikuti praktik yang baik, dan Anda akan berada di jalur yang benar untuk memberdayakan bisnis dan aplikasi Anda dengan solusi Machine Learning yang mutakhir.
Sumber:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf