
Apa itu kurva RKT dan bagaimana cara menghitungnya dengan Python?
Diterbitkan: 2022-03-22Kurva CTR, atau dengan kata lain rasio klik-tayang organik berdasarkan posisi, adalah data yang menunjukkan kepada Anda berapa banyak tautan biru pada Halaman Hasil Mesin Pencari (SERP) yang memperoleh RKT berdasarkan posisinya. Misalnya, sebagian besar waktu, tautan biru pertama di SERP mendapatkan RKT paling banyak.
Di akhir tutorial ini, Anda akan dapat menghitung kurva RKT situs Anda berdasarkan direktorinya atau menghitung RKT organik berdasarkan kueri RKT. Output dari kode Python saya adalah plot kotak dan batang yang menggambarkan kurva RKT situs.
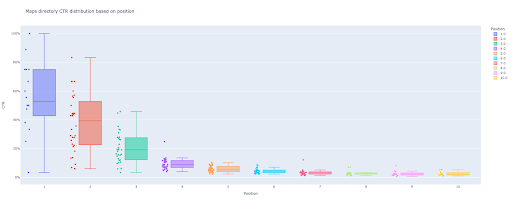
Jika Anda seorang pemula dan belum mengetahui definisi CTR, saya akan menjelaskannya lebih lanjut di bagian selanjutnya.
Apa itu CTR Organik atau Rasio Klik Tayang Organik?
RKT berasal dari membagi klik organik menjadi tayangan. Misalnya, jika 100 orang mencari "apel" dan 30 orang mengklik hasil pertama, RKT dari hasil pertama adalah 30/100 * 100 = 30%.
Ini berarti bahwa dari setiap 100 pencarian, Anda mendapatkan 30% dari mereka. Penting untuk diingat bahwa tayangan di Google Search Console (GSC) tidak didasarkan pada tampilan tautan situs web Anda di viewport pencari. Jika hasilnya muncul di SERP pencari, Anda mendapatkan satu tayangan untuk setiap pencarian.
Apa kegunaan kurva CTR?
Salah satu topik penting dalam SEO adalah prediksi traffic organik. Untuk meningkatkan peringkat di beberapa kumpulan kata kunci, kita perlu mengalokasikan ribuan dan ribuan dolar untuk mendapatkan lebih banyak saham. Tetapi pertanyaan di tingkat pemasaran perusahaan sering kali, “Apakah biaya yang efisien bagi kami untuk mengalokasikan anggaran ini?”.
Selain itu, selain topik alokasi anggaran untuk proyek SEO, kita perlu mendapatkan perkiraan kenaikan atau penurunan lalu lintas organik kita di masa mendatang. Misalnya, jika kita melihat salah satu pesaing kita berusaha keras untuk menggantikan kita di posisi peringkat SERP kita, berapa biayanya untuk kita?
Dalam situasi ini atau banyak skenario lainnya, kami membutuhkan kurva RKT situs kami.
Mengapa kita tidak menggunakan studi kurva CTR dan menggunakan data kita?
Cukup dijawab, tidak ada situs web lain yang memiliki karakteristik situs Anda di SERP.
Ada banyak penelitian untuk kurva RKT di industri yang berbeda dan fitur SERP yang berbeda, tetapi ketika Anda memiliki data, mengapa situs Anda tidak menghitung RKT daripada mengandalkan sumber pihak ketiga?
Mari kita mulai melakukan ini.
Menghitung kurva RKT dengan Python: Memulai
Sebelum kita masuk ke proses perhitungan rasio klik-tayang Google berdasarkan posisi, Anda perlu mengetahui sintaks dasar Python dan memiliki pemahaman dasar tentang pustaka Python umum, seperti Pandas. Ini akan membantu Anda untuk lebih memahami kode dan menyesuaikannya dengan cara Anda.
Selain itu, untuk proses ini, saya lebih suka menggunakan notebook Jupyter.
Untuk menghitung CTR organik berdasarkan posisi, kita perlu menggunakan library Python ini:
- panda
- plotly
- kaleido
Selain itu, kami akan menggunakan pustaka standar Python ini:
- os
- json
Seperti yang saya katakan, kita akan mengeksplorasi dua cara berbeda untuk menghitung kurva RKT. Beberapa langkah sama di kedua metode: mengimpor paket Python, membuat folder keluaran gambar plot, dan mengatur ukuran plot keluaran.
# Mengimpor perpustakaan yang diperlukan untuk proses kami impor os impor json impor panda sebagai pd impor plotly.express sebagai px impor plotly.io sebagai pio impor kaleido
Di sini kita membuat folder output untuk menyimpan gambar plot kita.
# Membuat folder keluaran gambar plot
jika tidak os.path.exists('./output plot images'):
os.mkdir('./output gambar plot')
Anda dapat mengubah tinggi dan lebar gambar plot keluaran di bawah ini.
# Mengatur lebar dan tinggi gambar plot keluaran pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
Mari kita mulai dengan metode pertama yang didasarkan pada CTR query.
Metode pertama: Hitung kurva RKT untuk seluruh situs web atau properti URL tertentu berdasarkan RKT kueri
Pertama-tama, kita perlu mendapatkan semua kueri kita dengan RKT, posisi rata-rata, dan tayangannya. Saya lebih suka menggunakan satu bulan data lengkap dari bulan lalu.
Untuk melakukan ini, saya mendapatkan data kueri dari sumber data tayangan situs GSC di Google Data Studio. Atau, Anda dapat memperoleh data ini dengan cara apa pun yang Anda inginkan, seperti GSC API atau add-on Google Sheets “Search Analytics for Sheets” misalnya. Dengan cara ini, jika blog atau halaman produk Anda memiliki properti URL khusus, Anda dapat menggunakannya sebagai sumber data di GDS.
1. Mendapatkan data kueri dari Google Data Studio (GDS)
Untuk melakukan ini:
- Buat laporan dan tambahkan bagan tabel ke dalamnya
- Tambahkan sumber data "Tayangan situs" situs Anda ke laporan
- Pilih "kueri" untuk dimensi serta "ctr", "posisi rata-rata" dan "'tayangan" untuk metrik
- Saring kueri yang berisi nama merek dengan membuat filter (Kueri yang berisi merek akan memiliki rasio klik-tayang yang lebih tinggi, yang akan menurunkan keakuratan data kami)
- Klik kanan pada tabel dan klik Ekspor
- Simpan output sebagai CSV
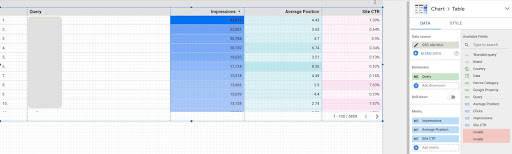
2. Memuat data kami dan melabeli kueri berdasarkan posisinya
Untuk memanipulasi CSV yang diunduh, kami akan menggunakan Pandas.
Praktik terbaik untuk struktur folder proyek kami adalah memiliki folder 'data' tempat kami menyimpan semua data kami.
Di sini, demi kelancaran dalam tutorial, saya tidak melakukan ini.
query_df = pd.read_csv('./downloaded_data.csv')
Kemudian kami memberi label kueri kami berdasarkan posisi mereka. Saya membuat loop 'untuk' untuk memberi label posisi 1 hingga 10.
Misalnya, jika posisi rata-rata kueri adalah 2,2 atau 2,9, kueri akan diberi label “2”. Dengan memanipulasi rentang posisi rata-rata, Anda dapat mencapai akurasi yang Anda inginkan.
untuk saya dalam rentang (1, 11):
query_df.loc[(query_df['Posisi Rata-Rata'] >= i) & (
query_df['Posisi Rata-Rata'] < i + 1), 'label posisi'] = i
Sekarang, kita akan mengelompokkan query berdasarkan posisinya. Ini membantu kami untuk memanipulasi setiap data kueri posisi dengan cara yang lebih baik di langkah selanjutnya.
query_grouped_df = query_df.groupby(['label posisi'])
3. Memfilter kueri berdasarkan datanya untuk penghitungan kurva RKT
Cara termudah untuk menghitung kurva RKT adalah dengan menggunakan semua data kueri dan membuat perhitungan. Namun; jangan lupa untuk memikirkan kueri tersebut dengan satu tayangan di posisi dua dalam data Anda.
Pertanyaan-pertanyaan ini, berdasarkan pengalaman saya, membuat banyak perbedaan dalam hasil akhir. Tapi cara terbaik adalah mencobanya sendiri. Berdasarkan dataset, ini dapat berubah.
Sebelum kita memulai langkah ini, kita perlu membuat daftar untuk output bar plot dan DataFrame untuk menyimpan kueri yang dimanipulasi.
# Membuat DataFrame untuk menyimpan data yang dimanipulasi 'query_df' modifikasi_df = pd.DataFrame() # Daftar untuk menyimpan rata-rata setiap posisi untuk grafik batang kami mean_ctr_list = []
Kemudian, kami mengulang grup query_grouped_df dan menambahkan 20% kueri teratas berdasarkan tayangan ke modified_df DataFrame.
Jika menghitung RKT hanya berdasarkan 20% kueri teratas yang memiliki tayangan terbanyak bukanlah yang terbaik untuk Anda, Anda dapat mengubahnya.
Untuk melakukannya, Anda dapat menambah atau menguranginya dengan memanipulasi .quantile(q=your_optimal_number, interpolation='lower')] dan your_optimal_number harus antara 0 hingga 1.
Misalnya, jika Anda ingin mendapatkan 30% kueri teratas, your_optimal_num adalah selisih antara 1 dan 0.3 (0,7).
untuk saya dalam rentang (1, 11):
# Percobaan-kecuali untuk menangani situasi di mana direktori tidak memiliki data untuk beberapa posisi
mencoba:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['impressions'] >= query_grouped_df.get_group(i)['impressions']
.quantile(q=0.8, interpolasi='lebih rendah')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modifikasi_df = modifikasi_df.append(tmp_df, abaikan_index=Benar)
kecuali KeyError:
mean_ctr_list.append(0)
# Menghapus DataFrame 'tmp_df' untuk mengurangi penggunaan memori
del [tmp_df]
4. Menggambar plot kotak
Langkah inilah yang kami tunggu-tunggu. Untuk menggambar plot, kita bisa menggunakan Matplotlib, seaborn sebagai pembungkus Matplotlib, atau Plotly.
Secara pribadi, saya pikir menggunakan Plotly adalah salah satu yang paling cocok untuk pemasar yang suka menjelajahi data.
Dibandingkan dengan Mathplotlib, Plotly sangat mudah digunakan dan hanya dengan beberapa baris kode, Anda dapat menggambar plot yang indah.
# 1. Plot kotak
box_fig = px.box(modified_df, x='position label', y='Site RKT', title='Distribusi RKT kueri berdasarkan posisi',
points='all', color='position label', labels={'position label': 'Position', 'Site CTR': 'CTR'})
# Menampilkan semua sepuluh sumbu x kutu
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Mengubah format centang sumbu y menjadi persentase
box_fig.update_yaxes(tickformat=".0%")
# Menyimpan plot ke direktori 'output plot images'
box_fig.write_image('./output plot images/Queries box plot CTR curve.png')
Dengan hanya empat baris ini, Anda bisa mendapatkan plot kotak yang indah dan mulai menjelajahi data Anda.
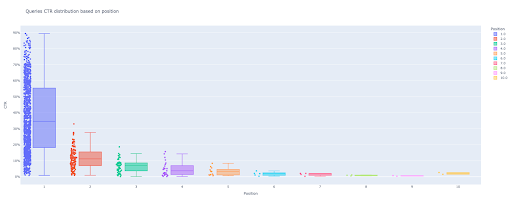
Jika Anda ingin berinteraksi dengan kolom ini, di sel baru jalankan:
box_fig.show()
Sekarang, Anda memiliki plot kotak yang menarik dalam output yang interaktif.
Saat Anda mengarahkan kursor ke plot interaktif di sel keluaran, nomor penting yang Anda minati adalah "pria" dari setiap posisi.
Ini menunjukkan RKT rata-rata untuk setiap posisi. Karena pentingnya mean, seperti yang Anda ingat, kami membuat daftar yang berisi mean setiap posisi. Selanjutnya, kita akan melanjutkan ke langkah berikutnya untuk menggambar plot batang berdasarkan rata-rata setiap posisi.
5. Menggambar plot batang
Seperti plot kotak, menggambar plot batang sangat mudah. Anda dapat mengubah title bagan dengan memodifikasi argumen title dari px.bar() .
# 2. Plot bar
bar_fig = px.bar(x=[pos untuk pos dalam rentang(1, 11)], y=mean_ctr_list, title='Kueri rata-rata distribusi RKT berdasarkan posisi',
labels={'x': 'Posisi', 'y': 'CTR'}, text_auto=True)
# Menampilkan semua sepuluh sumbu x kutu
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Mengubah format centang sumbu y menjadi persentase
bar_fig.update_yaxes(tickformat='.0%')
# Menyimpan plot ke direktori 'output plot images'
bar_fig.write_image('./output plot images/Queries bar plot CTR curve.png')
Pada output, kami mendapatkan plot ini:
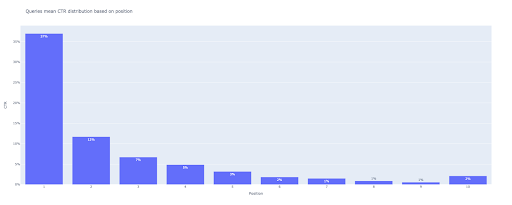
Seperti plot kotak, Anda dapat berinteraksi dengan plot ini dengan menjalankan bar_fig.show() .
Itu dia! Dengan beberapa baris kode, kami mendapatkan rasio klik-tayang organik berdasarkan posisi dengan data kueri kami.
Jika Anda memiliki properti URL untuk setiap subdomain atau direktori, Anda bisa mendapatkan kueri properti URL ini dan menghitung kurva RKT untuknya.
[Studi Kasus] Meningkatkan peringkat, kunjungan organik, dan penjualan dengan analisis file log
 Baca studi kasus
Baca studi kasusMetode kedua: Menghitung kurva RKT berdasarkan URL laman landas untuk setiap direktori
Pada metode pertama, kami menghitung RKT organik kami berdasarkan RKT kueri, tetapi dengan pendekatan ini, kami memperoleh semua data laman landas dan kemudian menghitung kurva RKT untuk direktori pilihan kami.

Saya suka cara ini. Seperti yang Anda ketahui, RKPT untuk halaman produk kami sangat berbeda dari posting blog kami atau halaman lainnya. Setiap direktori memiliki CTR sendiri berdasarkan posisi.
Dengan cara yang lebih maju, Anda dapat mengategorikan setiap halaman direktori dan mendapatkan rasio klik-tayang organik Google berdasarkan posisi untuk sekumpulan halaman.
1. Mendapatkan data halaman arahan
Sama seperti cara pertama, ada beberapa cara untuk mendapatkan data Google Search Console (GSC). Dalam metode ini, saya lebih suka mendapatkan data halaman arahan dari GSC API explorer di: https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
Untuk apa yang dibutuhkan dalam pendekatan ini, GDS tidak menyediakan data halaman arahan yang solid. Anda juga dapat menggunakan add-on Google Sheets “Search Analytics for Sheets”.
Perhatikan bahwa Google API Explorer sangat cocok untuk situs-situs dengan data kurang dari 25 ribu halaman. Untuk situs yang lebih besar, Anda bisa mendapatkan sebagian data halaman arahan dan menggabungkannya bersama-sama, menulis skrip Python dengan loop 'untuk' untuk mengeluarkan semua data Anda dari GSC, atau menggunakan alat pihak ketiga.
Untuk mendapatkan data dari Google API Explorer:
- Buka halaman dokumentasi API GSC “Search Analytics: query”: https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- Gunakan API Explorer yang ada di sisi kanan halaman
- Di bidang “siteUrl”, masukkan alamat properti URL Anda, seperti
https://www.example.com. Juga, Anda dapat memasukkan properti domain Anda sebagai berikutsc-domain:example.com - Di bidang "badan permintaan" tambahkan
startDatedanendDate. Saya lebih suka mendapatkan data bulan lalu. Format nilai ini adalahYYYY-MM-DD - Tambahkan
dimensiondan atur nilainya kepage - Buat "dimensionFilterGroups" dan filter kueri dengan nama variasi merek (ganti
brand_variation_namesmerek dengan nama merek Anda RegExp) - Tambahkan
rawLimitdan atur ke 25000 - Pada akhirnya tekan tombol 'EXECUTE'
Anda juga dapat menyalin dan menempelkan badan permintaan di bawah ini:
{
"tanggal mulai": "01-01-2022",
"tanggal akhir": "02-02-01",
"dimensi": [
"halaman"
],
"dimensionFilterGroups": [
{
"filter": [
{
"dimensi": "QUERY",
"expression": "brand_variation_names",
"operator": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
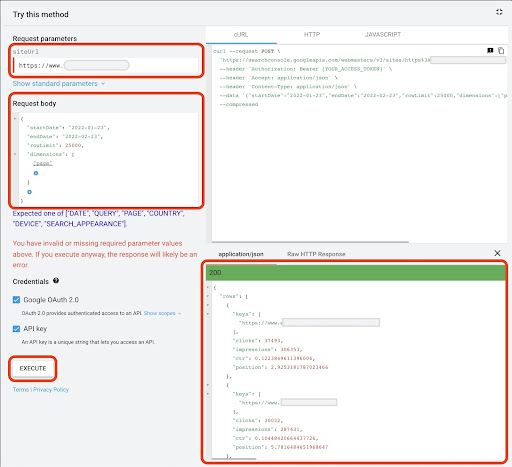
Setelah permintaan dieksekusi, kita perlu menyimpannya. Karena format respons, kita perlu membuat file JSON, menyalin semua respons JSON, dan menyimpannya dengan nama file downloaded_data.json .
Jika situs Anda kecil, seperti situs perusahaan SASS, dan data halaman arahan Anda di bawah 1000 halaman, Anda dapat dengan mudah mengatur tanggal Anda di GSC dan mengekspor data halaman arahan untuk tab "HALAMAN" sebagai file CSV.
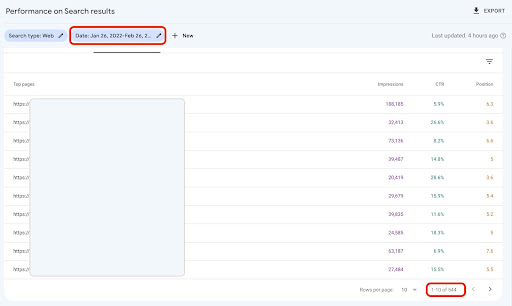
2. Memuat data halaman arahan
Demi tutorial ini, saya akan menganggap Anda mendapatkan data dari Google API Explorer dan menyimpannya dalam file JSON. Untuk memuat data ini kita harus menjalankan kode di bawah ini:
# Membuat DataFrame untuk data yang diunduh
dengan open('./downloaded_data.json') sebagai json_file:
landings_data = json.loads(json_file.read())['baris']
landing_df = pd.DataFrame(data_landingan)
Selain itu, kita perlu mengubah nama kolom agar lebih bermakna dan menerapkan fungsi untuk mendapatkan URL halaman arahan langsung di kolom “halaman arahan”.
# Mengganti nama kolom 'kunci' menjadi kolom 'halaman arahan' dan mengonversi daftar 'halaman arahan' menjadi URL
landings_df.rename(columns={'keys': 'halaman arahan'}, inplace=True)
landings_df['landing page'] = landings_df['landing page'].apply(lambda x: x[0])
3. Mendapatkan semua direktori root halaman arahan
Pertama-tama, kita perlu menentukan nama situs kita.
# Menentukan nama situs Anda di antara tanda kutip. Misalnya, 'https://www.example.com/' atau 'http://domainsaya.com/' nama_situs = ''
Kemudian kami menjalankan fungsi pada URL halaman arahan untuk mendapatkan direktori root mereka dan melihatnya di output untuk memilihnya.
# Mendapatkan setiap direktori halaman arahan (URL)
landings_df['directory'] = landings_df['landing page'].str.extract(pat=f'((?<={site_name})[^/]+)')
# Untuk mendapatkan semua direktori dalam output, kita perlu memanipulasi opsi Pandas
pd.set_option("display.max_rows", Tidak ada)
# Direktori situs web
landings_df['directory'].value_counts()
Kemudian, kami memilih direktori mana yang kami butuhkan untuk mendapatkan kurva CTR-nya.
Masukkan direktori ke dalam variabel important_directories .
Misalnya, product,tag,product-category,mag . Pisahkan nilai direktori dengan koma.
penting_direktori = ''
penting_direktori = penting_direktori.split(',')
4. Memberi label dan mengelompokkan halaman arahan
Seperti kueri, kami juga melabeli laman landas berdasarkan posisi rata-ratanya.
# Memberi label pada posisi halaman arahan
untuk saya dalam rentang (1, 11):
landings_df.loc[(landings_df['position'] >= i) & (
landings_df['posisi'] < i + 1), 'label posisi'] = i
Kemudian, kami mengelompokkan halaman arahan berdasarkan "direktori" mereka.
# Mengelompokkan halaman arahan berdasarkan nilai 'direktori' mereka landings_grouped_df = landings_df.groupby(['directory'])
5. Membuat plot kotak dan batang untuk direktori kami
Dalam metode sebelumnya, kami tidak menggunakan fungsi untuk menghasilkan plot. Namun; untuk menghitung kurva RKT untuk halaman arahan yang berbeda secara otomatis, kita perlu mendefinisikan sebuah fungsi.
# Fungsi untuk membuat dan menyimpan setiap bagan direktori
def each_dir_plot(dir_df, kunci):
# Mengelompokkan halaman arahan direktori berdasarkan nilai 'label posisi' mereka
dir_grouped_df = dir_df.groupby(['label posisi'])
# Membuat DataFrame untuk menyimpan data yang dimanipulasi 'dir_grouped_df'
modifikasi_df = pd.DataFrame()
# Daftar untuk menyimpan rata-rata setiap posisi untuk grafik batang kami
mean_ctr_list = []
'''
Mengulangi grup 'query_grouped_df' dan menambahkan 20% kueri teratas berdasarkan tayangan ke DataFrame 'modified_df'.
Jika menghitung RKT hanya berdasarkan 20% kueri teratas yang memiliki tayangan terbanyak bukanlah yang terbaik untuk Anda, Anda dapat mengubahnya.
Untuk mengubahnya, Anda dapat menambah atau menguranginya dengan memanipulasi '.quantile(q=your_optimal_number, interpolation='lower')]'.
'you_optimal_number' harus antara 0 hingga 1.
Misalnya, jika Anda ingin mendapatkan 30% teratas dari kueri Anda, 'jumlah_optimal_Anda' adalah selisih antara 1 dan 0,3 (0,7).
'''
untuk saya dalam rentang (1, 11):
# Percobaan-kecuali untuk menangani situasi di mana direktori tidak memiliki data untuk beberapa posisi
mencoba:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['impressions'] >= dir_grouped_df.get_group(i)['impressions']
.quantile(q=0.8, interpolasi='lebih rendah')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modifikasi_df = modifikasi_df.append(tmp_df, abaikan_index=Benar)
kecuali KeyError:
mean_ctr_list.append(0)
# 1. Plot kotak
box_fig = px.box(modified_df, x='position label', y='ctr', title=f'{key} direktori distribusi RKT berdasarkan posisi',
points='all', color='position label', labels={'position label': 'Position', 'ctr': 'CTR'})
# Menampilkan semua sepuluh sumbu x kutu
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Mengubah format centang sumbu y menjadi persentase
box_fig.update_yaxes(tickformat=".0%")
# Menyimpan plot ke direktori 'output plot images'
box_fig.write_image(f'./output plot images/{key} directory-Box plot CTR curve.png')
# 2. Plot bar
bar_fig = px.bar(x=[pos untuk pos dalam range(1, 11)], y=mean_ctr_list, title=f'{key} direktori berarti distribusi RKT berdasarkan posisi',
labels={'x': 'Posisi', 'y': 'CTR'}, text_auto=True)
# Menampilkan semua sepuluh sumbu x kutu
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Mengubah format centang sumbu y menjadi persentase
bar_fig.update_yaxes(tickformat='.0%')
# Menyimpan plot ke direktori 'output plot images'
bar_fig.write_image(f'./output plot images/{key} directory-Bar plot CTR curve.png')
Setelah mendefinisikan fungsi di atas, kita membutuhkan loop 'untuk' untuk mengulang data direktori yang ingin kita dapatkan kurva CTR-nya.
# Mengulangi direktori dan menjalankan fungsi 'each_dir_plot'
untuk kunci, item di landings_grouped_df:
jika memasukkan important_directory:
setiap_dir_plot(item, kunci)
Dalam output, kami mendapatkan plot kami di folder output plot images .
Tip tingkat lanjut!
Anda juga dapat menghitung kurva RKT direktori yang berbeda dengan menggunakan halaman arahan kueri. Dengan beberapa perubahan fungsi, Anda dapat mengelompokkan kueri berdasarkan direktori halaman arahannya.
Anda dapat menggunakan badan permintaan di bawah ini untuk membuat permintaan API di API Explorer (jangan lupa batasan 25000 baris):
{
"tanggal mulai": "01-01-2022",
"tanggal akhir": "02-02-01",
"dimensi": [
"pertanyaan",
"halaman"
],
"dimensionFilterGroups": [
{
"filter": [
{
"dimensi": "QUERY",
"expression": "brand_variation_names",
"operator": "EXCLUDING_REGEX"
}
]
}
],
"rowLimit": 25000
}
Kiat untuk menyesuaikan penghitungan kurva RKT dengan Python
Untuk mendapatkan data yang lebih akurat untuk menghitung kurva CTR, kita perlu menggunakan alat pihak ketiga.
Misalnya, selain mengetahui kueri mana yang memiliki cuplikan unggulan, Anda dapat menjelajahi lebih banyak fitur SERP. Juga, jika Anda menggunakan alat pihak ketiga, Anda bisa mendapatkan pasangan kueri dengan peringkat halaman arahan untuk kueri itu, berdasarkan fitur SERP.
Kemudian, memberi label halaman arahan dengan direktori root (induk), mengelompokkan kueri berdasarkan nilai direktori, mempertimbangkan fitur SERP, dan terakhir mengelompokkan kueri berdasarkan posisi. Untuk data RKT, Anda dapat menggabungkan nilai RKT dari GSC ke kueri rekan mereka.