
Pentingnya Jaringan Semantik untuk SEO: Membuat Jaringan Konten Semantik dengan Query dan Template Dokumen – Studi Kasus
Diterbitkan: 2022-01-11Sebuah Jaringan Semantik terhubung dengan konsep basis pengetahuan yang dapat mewakili informasi dunia nyata untuk hal-hal yang memiliki koneksi relasional. Basis pengetahuan dapat memiliki ribuan jenis relasi dengan miliaran entitas, dan triliunan fakta. Jaringan semantik dapat dibuat dari keberadaan dunia nyata apa pun dengan fitur timbal balik seperti berat, ukuran, jenis, bau, atau warna. Hubungan antara Jaringan Semantik dan Web Semantik dibuat oleh mesin pencari semantik dan pengoptimalan.
Jaringan Semantik digunakan dalam Parsing Semantik, Disambiguasi Word-sense, Pembuatan WordNet, Teori Grafik, Pemrosesan Bahasa Alami, Pemahaman, dan Generasi. Perspektif Jaringan Semantik dapat digunakan dalam Pengoptimalan Mesin Pencari Semantik dengan menyediakan jaringan konten semantik.
Dalam Studi Kasus SEO ini, dua situs web berbeda dengan dua metode berbeda dengan perspektif yang sama akan dijelaskan berdasarkan Query, Document, Intent template dan pasangan entitas-atribut di belakangnya.
Menggunakan pemahaman tentang bagaimana mesin pencari mewakili pengetahuan dan bagaimana mereka memperluas representasi pengetahuan mereka, saya dapat memanfaatkannya untuk menghasilkan hasil peringkat yang luar biasa. Setelah Anda memahami konsep dasarnya, saya akan menjelaskan bagaimana saya menerapkannya ke dua situs web yang berbeda, dan kemudian saya akan menjelaskan metode yang saya gunakan.
Bagaimana Jaringan Semantik dapat membantu Peringkat Situs Web Anda?
Di bawah ini, Anda akan menemukan hasil mentah keseluruhan untuk Proyek I.
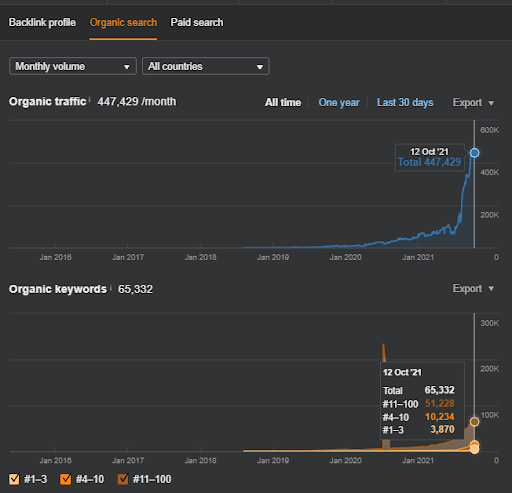
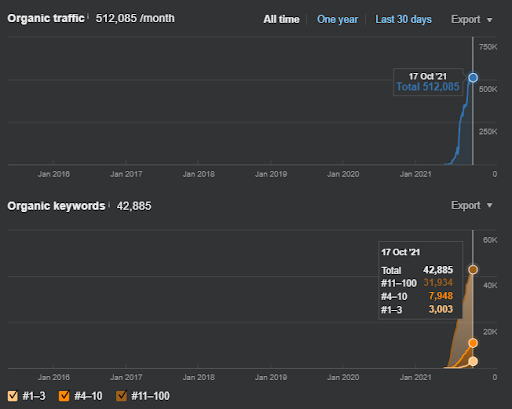
Hasil untuk Proyek Satu yaitu IstanbulBogaziciEnstitu.com. Untuk membuktikan bahwa "Jaringan Semantik" dapat digunakan untuk SEO dengan templat kueri dan dokumen, saya akan mendemonstrasikan dua jaringan konten yang berbeda dari Project One. Project One akan mendapatkan hasil yang jauh lebih baik dalam waktu dekat berkat Semantic Content Network Two. Klien akan bertanggung jawab atas peluncuran jaringan kedua ini, tetapi saya akan menjelaskan logikanya juga.
17 hari kemudian, berikut adalah kemajuan yang dibuat pada Proyek I: 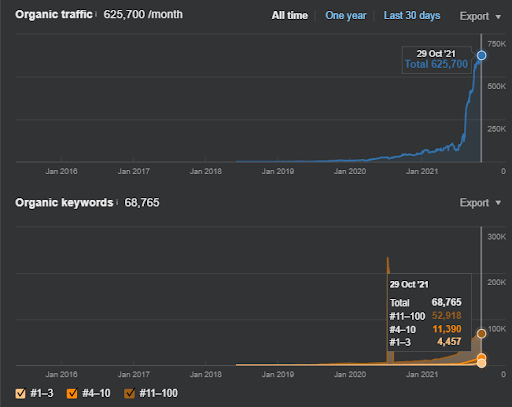
17 hari kemudian, proses re-ranking Semantic Content Network lebih jelas.
Konsep Jaringan Konten Semantik membantu kita memahami nilai kueri, maksud pencarian, perilaku, dan templat dokumen untuk entitas dari tipe yang sama. Dalam Studi Kasus SEO yang berfokus pada Jaringan Semantik ini, Otoritas Topikal dan Studi Kasus SEO Semantik sebelumnya akan diperdalam melalui dua situs web baru yang menggunakan jaringan konten yang dibuat secara semantik di sekitar jenis entitas yang sama.
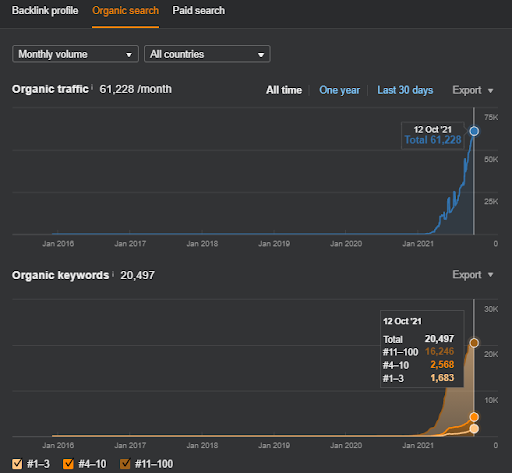
Ini adalah grafik SEMRush dari Proyek Pertama. Saya juga harus menyebutkan bahwa situs web ini telah kehilangan Pembaruan Algoritma Broad Core Juni, jika tidak kehilangan "Peringkat"-nya, hasilnya akan lebih baik. Untuk Pembaruan Algoritma Inti Luas berikutnya, dengan otoritas topikal, cakupan, dan data historis yang lebih baik, dapat memulihkan "Peringkat" dengan mudah.
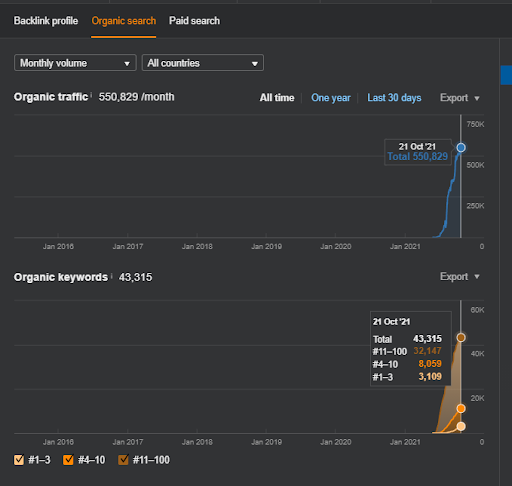
Nama Proyek Kedua adalah Vizem.net. Tidak seperti Project One, Anda dapat melihat bahwa Vizem.net memiliki peningkatan yang lebih lambat namun stabil. Itu karena mereka menggunakan Jaringan Konten Semantik dengan perspektif yang sedikit berbeda. Di bawah ini, Anda dapat melihat hasil Ahrefs dari Proyek Kedua.
Hasil Proyek Kedua merupakan “Proses Re-ranking Lambat” dengan meningkatkan Cakupan Topik dan Otoritas secara bertahap. Istilah "Peringkat Ulang" dan "Peringkat Awal" akan dijelaskan setelah konsep yang terkait dengan Jaringan Konten Semantik. Jika Anda menyadari "stabilitas" dalam grafik, itu karena saya telah berhenti menerbitkan konten baru di sumbernya. Dan, itu mempengaruhi Proses Pemeringkatan Ulang seperti yang Anda sadari dari hitungan 3 Hitungan Kueri Teratas. Hubungan "Momentum", dan "Peringkat ulang" dapat ditemukan setelah penjelasan konsep dasar.
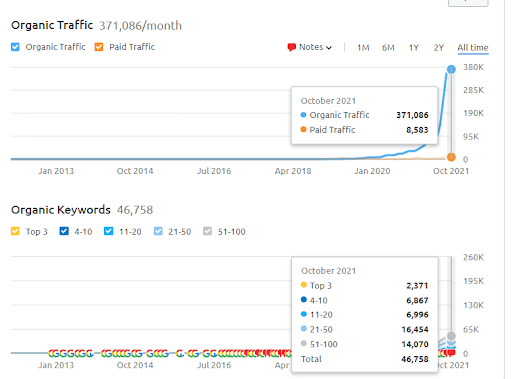
Di bawah ini, Anda dapat menemukan hasil SEMRush Vizem.net.
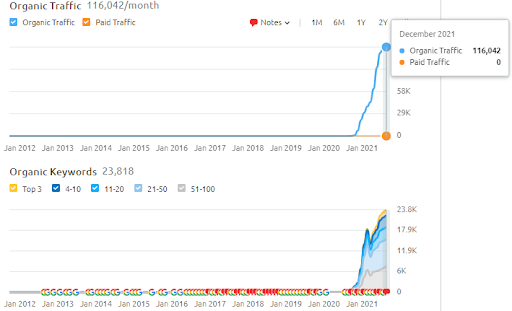
Lalu lintas sebenarnya dari situs web ini adalah 3x lebih banyak dari jumlah yang tercantum dalam SEMRush. Anda dapat mewujudkan "stabilitas" yang sama, dan konsep "momentum" dalam grafik ini juga.
Saat menulis Studi Kasus SEO Otoritas Topikal, saya berterima kasih kepada Bill Slawski karena telah mendidik perspektif saya. Saya ulangi untuk Studi Kasus SEO Jaringan Konten Semantik juga. Untuk memahami konsep "Peringkat Ulang" dan "Peringkat Awal", "Cara Mesin Pencari Dapat Merangking Ulang Hasil Pencarian" harus dibaca.
Pada 18 Maret 2021, Oncrawl, RankSense dan Holistic SEO & Digital menerbitkan Python SEO dan Data Science Webinar. Di webinar, SERP telah direkam untuk menghidupkan perbedaan hasil. Dapat dilihat bahwa mesin pencari mengubah peringkat sumber tertentu dengan sumber lain dengan frekuensi yang sama.
Sebelum saya melanjutkan lebih jauh, saya tahu bahwa ini adalah artikel yang panjang. Tapi, sebenarnya ini adalah penjelasan singkat tentang metodologi SEO yang sangat kompleks. Jaringan Konten Semantik membutuhkan terlalu banyak pemikiran saat merancangnya, dan pendidikan berbulan-bulan untuk klien, penulis, dan bersama dengan orientasi. Jadi, dalam artikel ini, saya ingin fokus pada definisi konsep dengan saran singkat yang dapat dieksekusi terbaik dan Google yang penting, dan paten mesin pencari lainnya, makalah penelitian bersama dengan konsep mereka sendiri. Dalam versi panjang (pada dasarnya, sebuah buku), saya telah fokus pada "peringkat awal" dan "peringkat ulang" jaringan konten semantik.
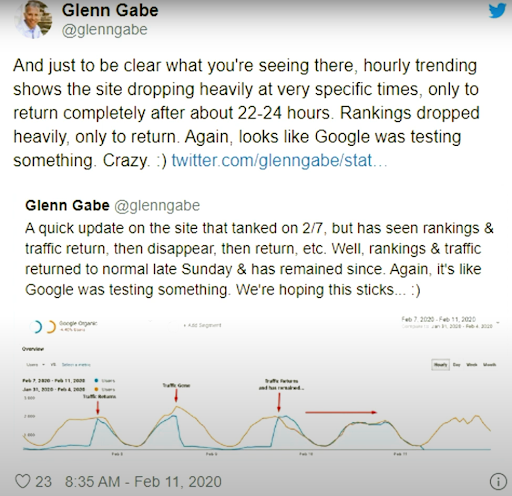
Mulai 11 Februari 2020, Glenn Gabe memiliki contoh bagus untuk metodologi Re-ranking dan pengujian Mesin Pencari secara visual.
Jika Anda ingin mempelajari lebih lanjut, baca "Pentingnya Peringkat Awal dan Peringkat Ulang untuk SEO".
Untuk menyelam jauh ke dalam data dunia nyata untuk Studi Kasus SEO, konsep untuk memahami Jaringan Konten Semantik harus diproses dengan perspektif Pemahaman-Komunikasi Mesin Pencari.
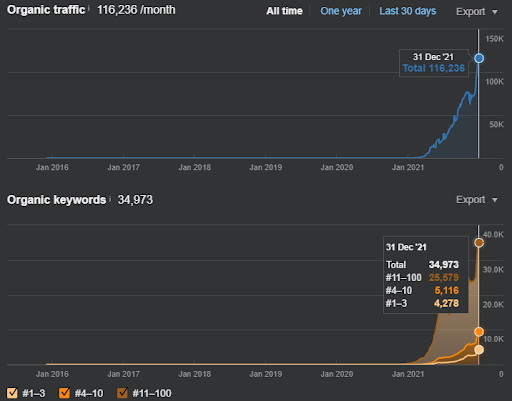
Sebagai contoh peringkat ulang dari Vizem.net, situasi yang diperbarui dapat dilihat di atas. Di bagian Studi Kasus SEO yang akan datang, akan ada penjelasan lebih lanjut untuk Algoritma Pemeringkatan Ulang Google untuk SEO.
Apa itu Jaringan Semantik?
Jaringan semantik dapat digunakan untuk menghubungkan dan menganalisis internet of things. Ini dapat bermanfaat untuk mengenali pembeli potensial di pasar teknologi, atau hanya analisis kata bersama untuk pembuatan dan pengelompokan jaringan kata kunci. Jaringan semantik dapat digunakan untuk mendukung navigasi dan mengungkapkan struktur hubungan, atau kepentingan relatif dari suatu hal ke hal lain. Jaringan Semantik memiliki komponen-komponen di bawah ini:
- Semantik Leksikal: Memahami kata dan konsep mana yang terkait dengan yang lain, dengan perbedaan apa.
- Komponen Struktural: Memahami simpul mana yang terhubung ke tepi mana dengan informasi apa.
- Komponen Semantik: Definisi fakta.
- Bagian Prosedural: Membantu menciptakan koneksi lebih lanjut antar komponen.
Karena jaringan semantik bersifat multiguna, algoritme NLP juga dapat digunakan untuk tujuan yang sangat beragam, seperti membantu mengidentifikasi masalah kesehatan yang rumit. Struktur jaringan semantik yang sama dapat diimplementasikan di beberapa area lain selama area lain tersebut memiliki hubungan semantik antara satu sama lain.
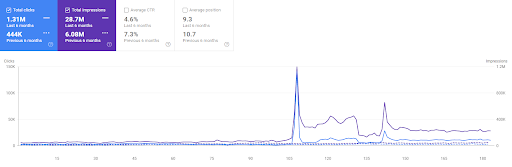
Perbandingan 6 bulan terakhir dari Proyek Pertama.
Apa itu basis pengetahuan?
Basis pengetahuan adalah perpustakaan informasi dengan klasifikasi dalam bentuk yang dapat dibaca mesin. Basis pengetahuan dapat digunakan sebagai ensiklopedia yang dapat dipersempit dan diperdalam berdasarkan kueri. Basis pengetahuan dapat dibentuk berdasarkan proposisi, ekstraksi fakta, dan ekstraksi informasi. Hubungan antara jaringan semantik dan basis pengetahuan adalah bahwa segala sesuatu yang ada di jaringan semantik akan ditempatkan ke dalam basis pengetahuan sambil mengekstraksi fakta.
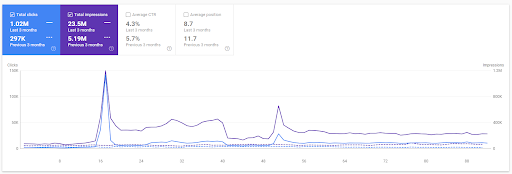
Perbandingan 3 bulan terakhir dari Proyek Pertama
Apa itu Jaringan Konten Semantik?
Jaringan Konten Semantik merupakan jaringan konten yang telah disusun berdasarkan komponen dan pemahaman jaringan semantik. Jaringan konten semantik dapat menyertakan beberapa atribut dari entitas atau entitas dari grup yang sama untuk menyediakan basis pengetahuan dengan lebih detail.
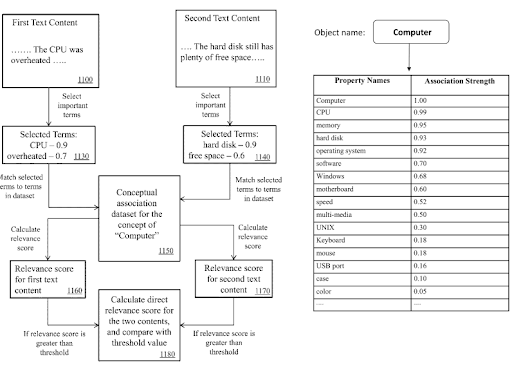
Dalam Jaringan Konten Semantik, Persyaratan Domain Pengetahuan, dan Tiga Kali Lipat dapat digunakan untuk menandakan tujuan utama dokumen, dan kemungkinan potongan konten lingkungan.
Mesin pencari dapat membandingkan basis pengetahuannya sendiri dengan basis pengetahuan yang dapat dihasilkan dari konten situs web. Jika situs web memiliki tingkat akurasi dan kelengkapan yang tinggi untuk lapisan kontekstual yang berbeda, mesin pencari dapat meningkatkan basis pengetahuannya sendiri dari konten situs web. Jika mesin pencari meningkatkan dan memperluas basis pengetahuannya sendiri dari sumber lain di web terbuka, itu adalah sinyal Kepercayaan berbasis Pengetahuan tingkat tinggi.
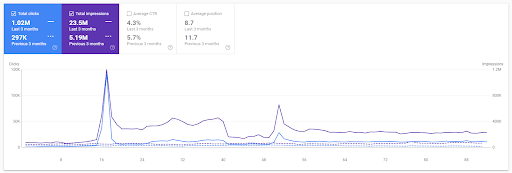
Perbandingan Tahun ke Tahun selama 3 Bulan Terakhir berdasarkan Proyek Pertama.
Apa itu Kepercayaan Berbasis Pengetahuan?
Kepercayaan berbasis pengetahuan berfokus pada open web berbasis pada "akurasi informasi", bukan "PageRank". Ini adalah algoritma yang mirip dengan RankMerge. Kepercayaan berbasis pengetahuan melibatkan kembar tiga, ekstraksi fakta, pemeriksaan akurasi, dan pemahaman teks dengan menghilangkan ambiguitas teks. Kepercayaan berbasis pengetahuan dapat diperoleh dengan menyediakan jaringan konten semantik yang memiliki komponen yang sangat terhubung dalam artikel, berdasarkan lapisan kontekstual yang berbeda namun relevan.
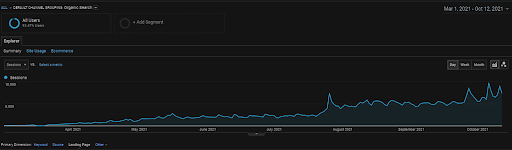
Sesi Organik Vizem.net dari GA selama 6 Bulan Terakhir.
Di bawah ini, Anda akan melihat contoh presentasi Kepercayaan Berbasis Pengetahuan dari Luna Dong. Ini menunjukkan bagaimana mesin pencari dapat fokus pada "faktor peringkat internal" daripada faktor peringkat eksogen. Ini menjelaskan bahwa PageRank tinggi tidak dapat mewakili kualitas dan akurasi tinggi untuk konten itu sendiri. Jadi, memiliki KBT (Knowledge Based Trust) itu penting.
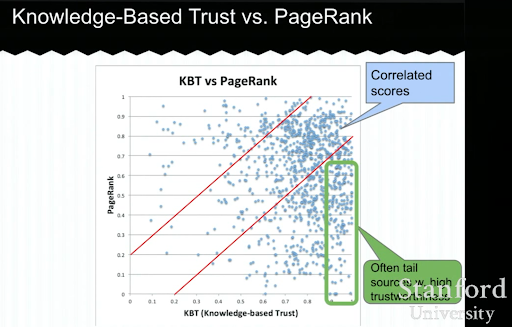
Banyak terima kasih kepada Arnout Hellemans yang berbagi kuliah pendidikan ini dengan saya selama obrolan SEO pribadi. Jika Anda ingin mempelajari lebih lanjut tentang Kepercayaan Berbasis Pengetahuan: Seminar Stanford – Gudang Pengetahuan dan Kepercayaan Berbasis Pengetahuan
Apa itu Cakupan Kontekstual?
Cakupan Kontekstual dan Cakupan Topik tidak sama dengan Domain Pengetahuan dan Domain Kontekstual tidak sama. Cakupan kontekstual mewakili sudut pemrosesan suatu konsep. Suatu konsep dapat diproses berdasarkan titik-titik timbal baliknya dengan hal-hal lain. Seperti jika entitas tersebut adalah sebuah negara, sikapnya terhadap krisis lingkungan dapat diproses. Jika negara lain diproses dari sudut yang sama, berarti kita sedang meliput domain kontekstual.

Google Search Engine membuat makalah penelitian dan patennya dari waktu ke waktu. Kutipan kanan dari bagian di atas adalah atribut untuk "vektor konteks" sedangkan bagian kiri adalah atribut untuk "taksonomi frasa". Yang menarik, bahkan contohnya sama, yaitu “kamera digital”.
Rincian mendalam dan sub-bagian dari kombinasi ini mewakili lapisan kontekstual dalam domain kontekstual. Setiap entitas apakah itu bernama, atau tidak, memiliki banyak domain kontekstual. Dengan demikian, Google mengekstrak lebih banyak domain kontekstual dan pengguna mencari kueri yang lebih panjang setiap tahun. Ketika Pemrosesan Bahasa Alami dan Pemahaman Bahasa Alami dikembangkan, kueri dan dokumen berkembang bersama dalam hal detail, dan konteks.
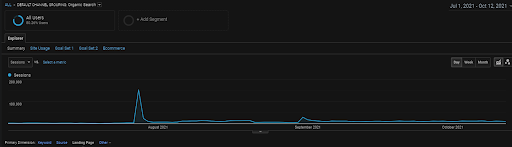
Grafik Sesi Organik GA selama 4 bulan terakhir dari Proyek BogaziciEnstitu. Karena "Tahap Pengumpulan Data Historis" proyek, detail yang meningkat tidak jelas untuk dilihat sebagai linier.
Cakupan kontekstual dapat dipahami dengan “kualifikasi konteks”. Kualifikasi konteks dapat berupa kata sifat, kata keterangan, atau kata depan lainnya seperti frasa yang dimulai dengan “untuk, di, di, selama, sementara”. Pertanyaan terkait entitas di bawah ini tidak sama dalam hal domain kontekstual:
- Apa buah yang paling bermanfaat untuk anak penderita insomnia?
- Apa buah yang paling bermanfaat untuk anak dengan kecemasan?
Pertanyaan terkait entitas di bawah ini tidak sama dalam hal lapisan kontekstual:
- Apa buah yang paling berguna untuk anak-anak dengan insomnia parah di atas 6 tahun?
- Apa buah yang paling bermanfaat untuk anak dengan kecemasan tingkat rendah di bawah 6 tahun?
Pertanyaan terkait entitas di bawah ini tidak sama dalam hal domain pengetahuan:
- Apa buku yang paling berguna untuk anak-anak dengan insomnia parah di atas 6 tahun?
- Apa permainan yang paling berguna untuk anak-anak dengan kecemasan tingkat rendah di bawah 6 tahun?
Tetapi semua pertanyaan ini dapat berada di Jaringan Konten Semantik yang sama karena semuanya memiliki "konsep" dan "area minat" yang sama dengan aktivitas penelusuran serupa, dan aktivitas dunia nyata terkait penelusuran.
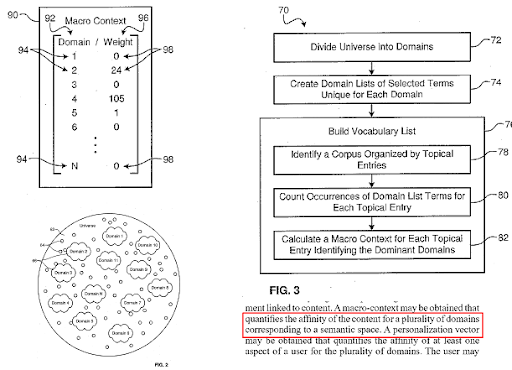
Mesin pencari membagi web menjadi domain pengetahuan yang berbeda, dan menghitung skor konteks makro dan mikro untuk sumber, halaman web, dan bagian halaman web pada saat yang bersamaan.
Saya tahu bahwa saya memiliki banyak konsep baru untuk Anda, dan karena ini adalah versi singkat dari artikel ini, saya tidak akan dapat membicarakan semuanya di sini, tetapi di Kursus SEO Semantik mendatang, saya akan memproses hal-hal ini seperti perbedaan antara "aktivitas pencarian", dan "aktivitas dunia nyata terkait pencarian".
Mari kita lanjutkan sedikit ke hal-hal yang lebih konkret.
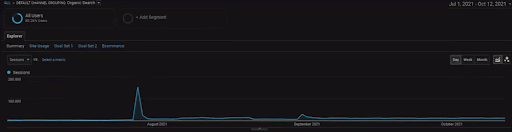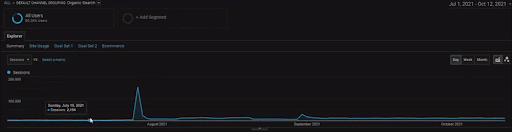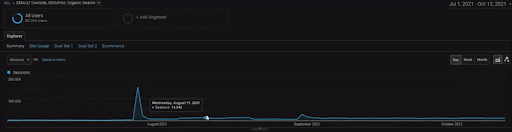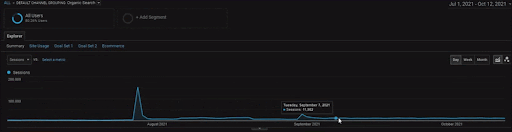
Untuk menampilkan detail Proyek BogaziciEnstitu, Anda dapat memeriksa versi gambar interaktif. Proses pengujian dan pemeringkatan ulang mesin telusur menjadi lebih jelas pada proyek ini setelah peristiwa sumber data historis.
Bagaimana MuM Terkait dengan Jaringan Konten Semantik?
Pembelajaran Multitugas dengan Transformator Terpadu atau Model Terpadu Multitugas melatih model bahasa untuk mengevaluasi input visual, serta teks. Hal ini mampu menghasilkan teks bersama dengan pemahaman. Selain itu, MuM adalah agnostik bahasa, dengan kata lain, SEO semantik bergantung pada keterampilan bahasa, tetapi tidak terbatas pada bahasa. Karena entitas tidak memiliki bahasa dan makna bersifat universal, MuM memanfaatkan informasi dari berbagai bahasa dan berbagai konteks ke dalam satu basis pengetahuan.
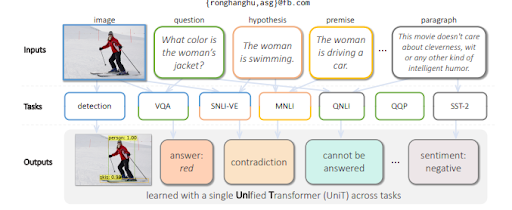
Untuk menjawab pertanyaan dari visual, MuM menghasilkan pertanyaan berdasarkan objek yang terdeteksi dalam gambar. Dalam waktu dekat, pertanyaan terkait audio dan video akan dapat dihasilkan juga.
MuM menggunakan domain yang berbeda untuk deteksi objek dan pemahaman bahasa alami dengan struktur encoder-decoder transformator. Setiap input berasal dari area berbeda dari web terbuka sementara semuanya dievaluasi dari satu dekoder bersama. Di bawah ini, Anda akan dapat melihat contoh lebih lanjut dari makalah penelitian.
Sebagai catatan, MuM bisa 1000 kali lebih kuat dari BERT, tetapi BERT masih digunakan di dalam Text Encoder MuM. Keunggulan utama MuM adalah dapat digunakan untuk visual, dan audio secara langsung, sehingga dapat disebut sebagai model “multitask”. Keuntungan kedua adalah menghilangkan semua hambatan bahasa secara langsung. Keunggulan ketiga adalah dapat menghubungkan segala sesuatu dengan hal lain tanpa perlu perantara tambahan. Keuntungan keempat adalah bahwa MuM dapat menghasilkan teks juga, tidak seperti BERT.
Hubungan antara MuM, Basis Pengetahuan, Jaringan Semantik, dan Cakupan Kontekstual adalah bahwa mesin pencari dapat menemukan lebih banyak domain kontekstual melalui kualifikasi konteks dan kombinasinya dengan kemungkinan domain pengetahuan. Dengan demikian, Jaringan Konten Semantik yang terstruktur dengan baik yang dibentuk dengan Peta Topik dan Konteks Sumber yang tepat dapat meningkatkan Kepercayaan basis Pengetahuan, bersama dengan Otoritas Topik.
Apa Konteks Sumbernya?
Konteks Sumber mewakili dua hal. Pusat pencarian internet dari sumber, dan pusat aktivitas pencarian yang dapat dilakukan dengan aktivitas pencarian terkait. Untuk situs web e-niaga, konteks sumbernya adalah membeli produk tertentu atau jenis produk tertentu. Jika itu adalah situs web perjalanan, konteks sumbernya pergi ke suatu tempat dari tempat lain untuk berbagai jenis makanan, pemandangan alam, atau hanya bisnis. Berdasarkan Konteks Sumber, desain Jaringan Konten Semantik, dan Peta Topikal perlu dikonfigurasi lebih lanjut. Ini membutuhkan pemilihan bagian tengah dalam peta topikal, dan bagian tambahan dalam peta topikal.
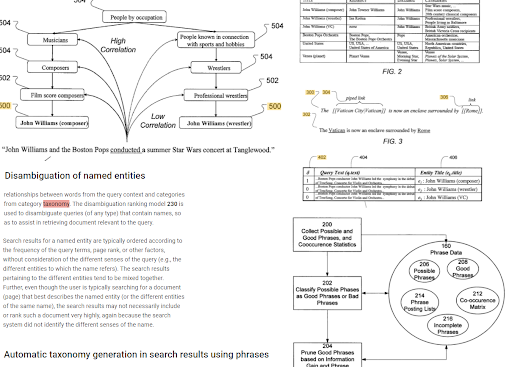
Pengindeksan berbasis frase, dan pemahaman pencarian berorientasi entitas terhubung satu sama lain berdasarkan semantik. Di atas, "Disambiguasi Entitas Bernama" dan "Pembuatan taksonomi otomatis dalam hasil pencarian menggunakan frasa" dapat dilihat bersama untuk menentukan "konteks". Frase yang baik, dan informasi unik namun berkorelasi untuk suatu topik akan membantu untuk awal dan peringkat ulang yang lebih baik.
Sekali lagi, beberapa konsep ini, "konfigurasi peta topikal", "desain jaringan konten semantik" belum ditentukan, dan ini bukan tempat yang tepat untuk itu. Namun, aktivitas pencarian terkait telah dijelaskan bersama dengan maksud pencarian kanonik, dan frasa representatif untuk maksud pencarian kanonik ini.
Latar Belakang Studi Kasus SEO Berfokus Jaringan Semantik
Berdasarkan konsep di atas, saya menggunakan Jaringan Semantik untuk membuat Studi Kasus SEO. Kita akan melihat dua proyek situs web yang saya sebutkan di awal artikel ini dan memeriksa hasilnya, dan bagaimana saya menerapkan Jaringan Semantik untuk menghasilkannya.
Untuk memberi Anda gambaran tentang seberapa kuat jaringan ini, hasil terkait SEO untuk Studi Kasus SEO yang berfokus pada Jaringan Semantik tercantum di bawah ini.
- Pemahaman Jaringan Semantik adalah suatu keharusan untuk membuat Peta Topikal yang tepat.
- Untuk kedua proyek, SEO Teknis tidak digunakan untuk mengisolasi efek SEO semantik.
- Pengoptimalan Kecepatan Halaman tidak digunakan, untuk alasan yang sama.
- Pengoptimalan Desain dan WUX (Pengalaman Pengguna Situs Web) tidak digunakan.
- Tautan Balik (Referensi Eksternal dan aliran PageRank) tidak digunakan.
- Kedua merek tidak memiliki data historis. Vizem.net benar-benar baru, BogaziciEnstitusu memiliki sejarah yang lebih tua tetapi lebih rendah dari perusahaan yang sebenarnya.
- SEO OnPage atau vertikal SEO lainnya tidak digunakan.
- Kedua merek tersebut memiliki server yang lebih baik daripada contoh Studi Kasus Otoritas Topikal sebelumnya.
Studi Kasus SEO yang berfokus pada Jaringan Semantik ini akan membantu orang-orang yang ingin meningkatkan perspektif SEO Semantik mereka dengan dua metodologi dan konsep berbeda yang berfokus pada dua situs web berbeda.
Proyek Dua: Vizem.net berfokus pada Proses Aplikasi Visa. Sebelum menulis, menerbitkan, atau bahkan meluncurkan proyek-proyek ini, saya telah menunjukkan kedua situs web ini berkali-kali kepada klien atau mitra saya yang lain. Dan, Vizem.net telah memulai perjalanan "Otoritas Topikal" baru-baru ini.
SEO berdasarkan Studi Kasus Jaringan Semantik telah ditulis dalam dua versi yang berbeda. Jika Anda ingin membaca semua paten terkait, makalah penelitian, dan pemeriksaan yang sangat rinci, interpretasi dari sudut pandang mesin pencari sambil memahami pohon keputusan mesin pencari lebih lanjut, Anda dapat membaca Pentingnya SEO peringkat awal dan peringkat ulang Artikel Studi Kasus yang lebih dari 30.000 kata. Jika Anda tidak memiliki pengetahuan teoretis yang cukup untuk SEO dan latar belakang sejarah, Anda dapat melanjutkan membaca ringkasan eksekutif.
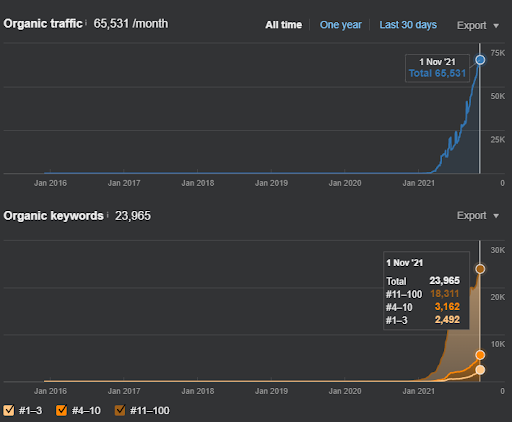
Di bawah ini, Anda dapat melihat grafik Proyek Kedua (Vizem.net) dari SEMRush.
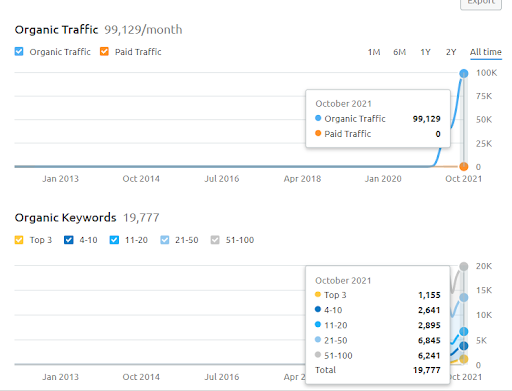
Grafik SEMRush dari Situs Kedua. Vizem.net adalah sumber yang sama sekali baru yang menargetkan industri dengan tingkat pesaing yang tinggi seperti “Aplikasi Visa”. Terutama, karena peristiwa terbaru di Turki, tingkat persaingan industri meningkat. Jadi, menggunakan perspektif Jaringan Semantik untuk membuat Jaringan Konten berguna.
Proyek Pertama: Istanbul Bogazici Enstitusu: Peningkatan Klik Organik 600% dalam 3 Bulan – Memanfaatkan data Historis dan Peringkat Awal
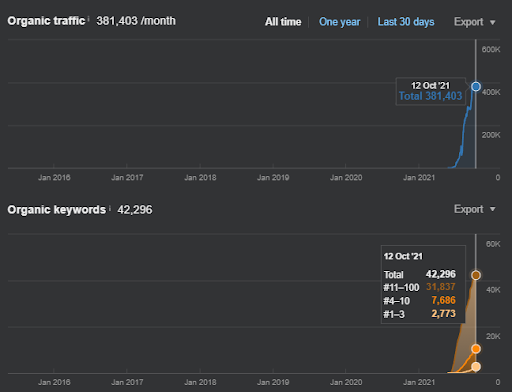
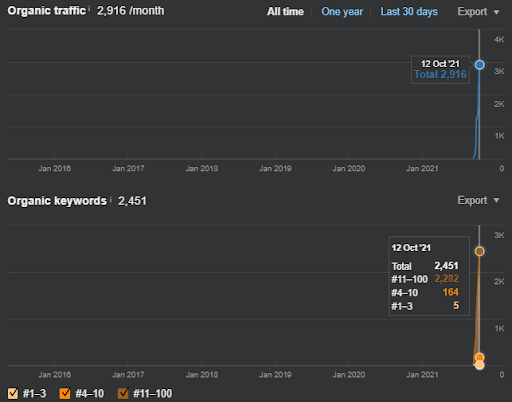
IstanbulBogazici Enstitusu adalah salah satu Studi Kasus SEO tersulit yang pernah saya lakukan, bukan karena Mesin Pencari, tetapi karena orang-orang dan masalah kesehatan saya. Jadi, saya telah meninggalkan proyek dan tidak menerbitkan jaringan konten semantik ketiga yang dirancang untuk menyelesaikan hubungan semantik berdasarkan konteks sumbernya. Bahkan jika tidak memiliki istilah domain pengetahuan, dan frasa kontekstual diterapkan dengan benar, itu dikonfigurasi dengan tingkat koneksi semantik dan akurasi yang cukup, untuk memungkinkan kinerja pencarian organik keseluruhan lebih dari tiga juta sesi per bulan jika jaringan konten ketiga adalah diterbitkan di masa depan, memperhitungkan peningkatan efek dari jaringan konten semantik kedua juga.
Di bawah ini, Anda akan melihat grafik perubahan IstanbulBogazici Enstitusu di GSC selama 12 bulan terakhir. Proyek ini diluncurkan pada Mei 2021 dengan cara yang benar dan berakhir pada September 2021 dengan menerbitkan dua Jaringan Konten Semantik.
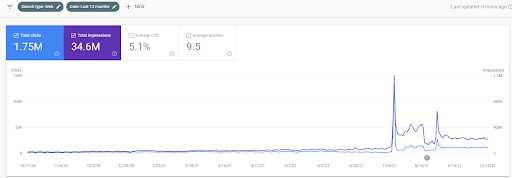
Di bawah ini Anda dapat melihat versi yang lebih rinci. Dari 1400 klik harian hingga 140000 klik, dan kemudian 10.000+ klik reguler per hari dapat dilihat dalam kinerja Penelusuran Organik
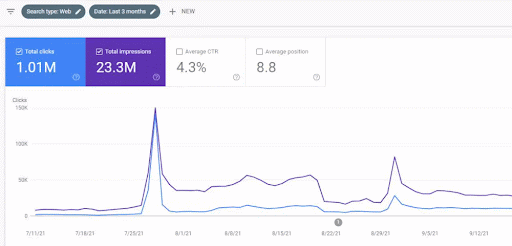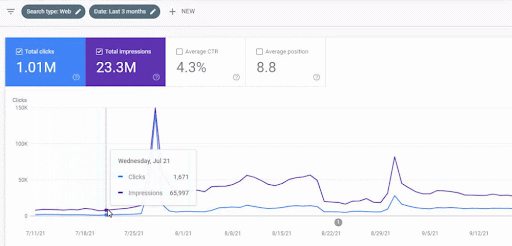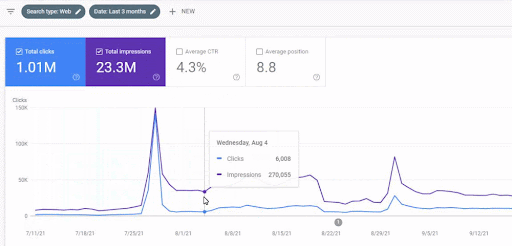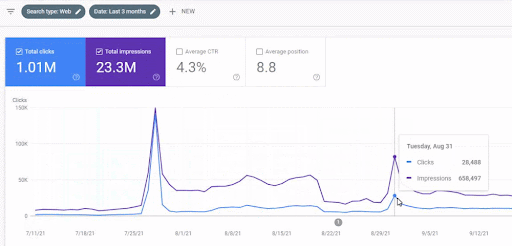
Peningkatan trafik jaringan konten pertama setelah peluncuran dapat dilihat di bawah ini.
Tangkapan layar ini menunjukkan bulan ke-4 Jaringan Konten Semantik Pertama.
Seperti yang Anda lihat dari grafik, keseluruhan lalu lintas situs web telah didominasi dan dipengaruhi oleh Jaringan Konten Semantik Pertama yang berfokus pada "cabang pendidikan". Jaringan konten kedua yang saya luncurkan dengan situs web ini dapat dilihat di bawah dari Google Search Console. Tangkapan layar di bawah ini berasal dari hari ke-16 jaringan konten semantik kedua.
Pemeringkatan awal dan pemeringkatan ulang telah digunakan dalam artikel karena mereka menentukan fase algoritme peringkat bersama dengan jenis dan tujuannya sebelum menguji sumber, dan halaman web dari sumber dalam SERP untuk kueri yang lebih penting yang memiliki popularitas .
Apa Jaringan Konten Semantik Pertama dari Proyek Pertama yang Difokuskan?
"Jaringan Konten Semantik" menggunakan jaringan semantik dari basis pengetahuan untuk menjelaskan hubungan utama, sekunder, dan tersier antara hal-hal dalam basis pengetahuan. Dengan demikian, membuat Jaringan Konten Semantik memerlukan perancangan jaringan konten semantik berikutnya berdasarkan konteks sumber yang merupakan fungsi utama situs web. Dalam konteks ini, jaringan konten semantik pertama berfokus pada "departemen universitas, cabang pendidikan, dan kebutuhan untuk pendidikan universitas dalam organisasi dan cabang tertentu."
Di bawah, Anda akan menemukan Grafik Ahrefs Jaringan Konten Semantik Pertama.
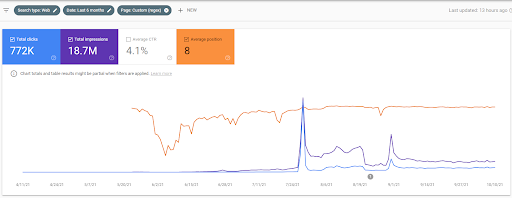
Ini lima hari kemudian dari tangkapan layar sebelumnya.
“Root: istanbulbogazicienstitu.com/bolum”, setelah tahap initial-ranking pertama, proses re-ranking lebih efisien dan produktif.
Anda dapat melihat versi empat hari kemudian seperti di bawah ini untuk mendukung sifat "peringkat ulang".
Apa Fokus Jaringan Konten Semantik Kedua dari Proyek Pertama?
Jaringan konten semantik kedua telah berfokus pada pekerjaan, pekerjaan, keterampilan, dan pendidikan yang diperlukan untuk keterampilan ini, atau rutinitas. Berdasarkan jaringan konten semantik pertama, jaringan konten semantik kedua telah didukung. Dan, menurut "template maksud templat kueri", dua jaringan sub-konten semantik yang berbeda dibuat dan ditempatkan dengan "koneksi relasional" saat terhubung ke tingkat hierarki atas yang serupa.
Saya tahu bahwa bagian ini rumit bagi Anda karena Anda belum melihat definisi untuk hal-hal di bawah ini.
- Jaringan Konten Semantik
- Konteks Sumber
- Jaringan Sub-konten Semantik
- Dasar pengetahuan
- Koneksi Relasional
- Peringkat Awal
- Peringkat ulang
- Liputan Kontekstual
- Peringkat Perbandingan
- Ekstraksi Fakta
Setelah menjelaskan website kedua, akan lebih mudah untuk memahami konsep dan kalimat tersebut.
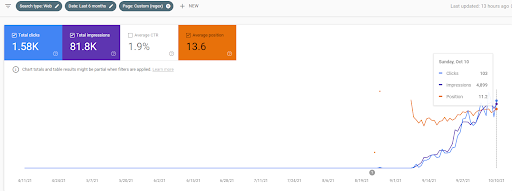
Vizem.net: Dari 0 hingga 9.000+ Klik Harian Per Hari dalam 6 Bulan – Peringkat Perbandingan yang Dimanfaatkan dengan Cakupan Kontekstual
Anda dapat melihat grafik Vizem.net selama 12 bulan terakhir. Untuk proyek ini, karena Covid-19, kami mengalami banyak masalah ekonomi karena investornya dari industri gym. Jadi, saya dapat mengatakan bahwa masalah ekonomi memperlambat proyek, dan itu menyebabkan beberapa latensi untuk "proses peringkat ulang".
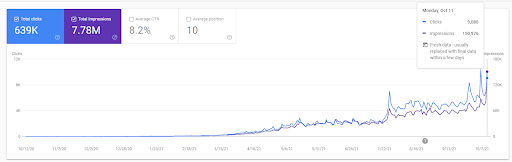
Untuk memahami peringkat awal, dan peringkat ulang sedikit lebih jauh, Anda dapat menggunakan grafik di bawah ini.
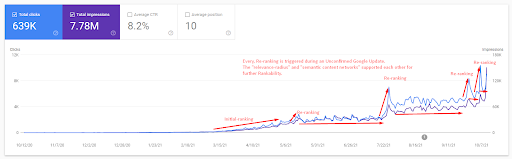
Beberapa definisi yang terkait dengan Peringkat Awal dan Peringkat Ulang dari grafik di atas dapat ditemukan di bawah ini.
- Lompatan peringkat besar terjadi selama Pembaruan Google yang Belum Dikonfirmasi. Beberapa tes memberikan beberapa Cuplikan Unggulan, dan Orang Juga Mengajukan Pertanyaan.
- Beberapa tes dari Google menghapus pendapatan FS dan PAA.
- Setiap kali, garis waktu antara dua proses peringkat ulang lebih pendek.
- Proses pemeringkatan ulang meningkatkan Rankability sumber setiap saat.
- Sumber selalu meningkatkan radius relevansinya sambil memperluas kluster kueri.
Sekedar catatan, saya bisa meninggalkan kalimat di bawah ini.
Jika Mesin Pencari mengindeks halaman web Anda, itu tidak berarti bahwa mesin pencari memahami halaman web tersebut. Pengindeksan terjadi lebih cepat daripada pemahaman, dan sebagian besar waktu, mesin pencari memberi peringkat halaman web dengan prediksi, "awalnya". Setelah pemahaman, "peringkat ulang" terjadi. 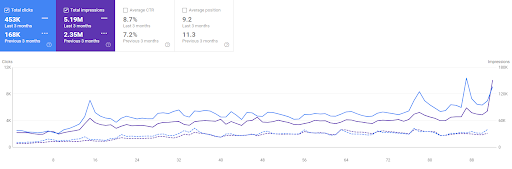
Perbandingan 3 bulan terakhir dari Vizem.net
Bagaimana Jaringan Konten Semantik Vizem.net?
Saya ingat bahwa untuk banyak klien, teman, atau Grup SEO rahasia saya, selama pertemuan, saya telah mendemonstrasikan kedua situs web ini dengan mengatakan, "mereka akan meledak". Dan, saat menulis artikel ini, saya memberi tahu Anda ini:
Tonton Jaringan Konten Semantik “istanbulbogazicienstitu.com/meslek”, karena akan meledak. Dan, Anda dapat menemukan video yang telah saya terbitkan sebelum menulis artikel ini sambil mendemonstrasikan “Data Historis” dari peristiwa musiman dan pengaruhnya terhadap proses Awal, dan Pemeringkatan Ulang. Anda dapat melihatnya di bawah ini.
Berdasarkan ini, Jaringan Konten Semantik Vizem.net tidak mirip dengan IstanbulBogazici Enstitusu, jadi, saya tidak menggunakan "tingkat Cakupan Topik dan peningkatan Data Historis yang intens", saya perlu membuat otoritas terkait dengan jenis entitas, atributnya, dan kemungkinan tindakan di balik kueri untuk pasangan atribut-entitas ini. Vizem.net tidak hanya memiliki "cabang universitas pendidikan", atau "pekerjaan, dan kursus online" di dalamnya. Ini memiliki "negara untuk aplikasi visa". Dengan demikian, menciptakan tingkat Otoritas Topik yang cukup membutuhkan konsistensi dari waktu ke waktu dengan setidaknya 190 jaringan konten semantik yang berbeda.
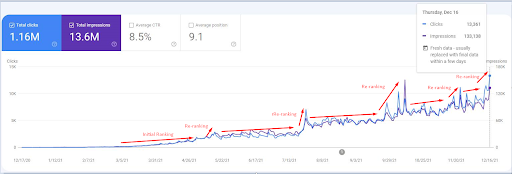
Tangkapan layar dari 18 Desember 2021. Anda dapat melihat peringkat ulang terus menerus dan peningkatan tayangan dan klik. Ini adalah 4 minggu kemudian dari tangkapan layar sebelumnya.
Untuk melihat peristiwa pemeringkatan ulang, Anda dapat membandingkan versi telanjang dari grafik kinerja pencarian organik yang menunjukkan efek SEO Semantik. 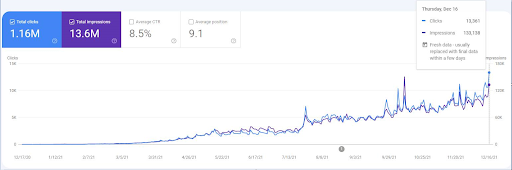
190 jaringan konten semantik yang berbeda ini dibentuk berdasarkan "negara" itu sendiri, dan negara-negara tersebut ditempatkan di tengah peta topikal dengan setiap lapisan kontekstual yang memungkinkan untuk meningkatkan cakupan aktivitas pencarian.
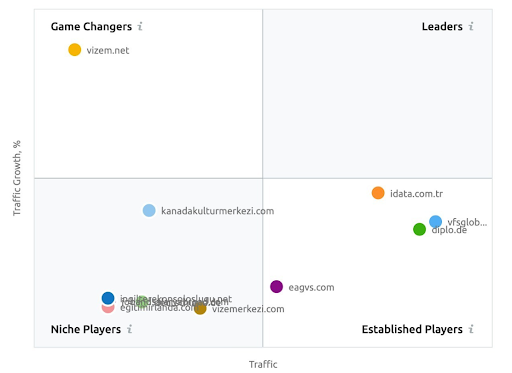
Tangkapan layar dari SEMRush menunjukkan persepsi mereka terhadap Vizem.net tidak seperti pemain industri lainnya.
Saya juga telah menerbitkan video lain, hanya untuk Vizem.net. Dalam video ini, situasi terakhir dari situs web tidak ada, jadi, saya percaya, ini juga memberikan perbandingan yang bagus antara hari ini dan hari itu.
Terakhir, menerbitkan hal-hal yang tidak relevan dalam artikel, segmen situs web, atau sumber yang tidak relevan dapat mengurangi relevansi keseluruhan entitas web dengan domain pengetahuan tertentu. Vizem.net akan menunjukkan nilai sebenarnya, dan Rankability di masa depan akan jauh lebih baik.
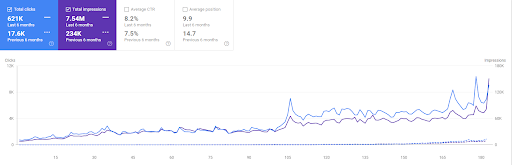
Perbandingan Vizem.net 6 bulan terakhir.
Sebelum saya melanjutkan lebih jauh, saya tahu bahwa ini adalah artikel yang panjang. Tapi, sebenarnya ini adalah penjelasan singkat tentang metodologi SEO yang sangat kompleks. Jaringan Konten Semantik membutuhkan terlalu banyak pemikiran saat merancangnya, dan pendidikan berbulan-bulan untuk klien, penulis, dan bersama dengan orientasi. Jadi, dalam artikel ini, saya ingin fokus pada definisi konsep dengan saran singkat yang dapat dieksekusi terbaik dan Google yang penting, dan paten mesin pencari lainnya, makalah penelitian bersama dengan konsep mereka sendiri. Dalam versi panjang (pada dasarnya, sebuah buku), saya telah fokus pada "peringkat awal" dan "peringkat ulang" jaringan konten semantik.
Jika Anda ingin mempelajari lebih lanjut, baca "Pentingnya Peringkat Awal dan Peringkat Ulang untuk SEO".
Sampai saat ini, kami telah memproses hal-hal di bawah ini.
- Jaringan Semantik
- Dasar pengetahuan
- Jaringan Konten Semantik
- Pengetahuan Berbasis-Kepercayaan
- Liputan Kontekstual
- Domain dan Lapisan Kontekstual
- Relevansi MuM dengan Jaringan Konten Semantik
- Konteks Sumber
Konsep-konsep ini untuk memahami bagaimana fungsi Jaringan Konten Semantik, dan bagaimana mereka dapat digunakan dengan peta topikal. Bagian selanjutnya adalah tentang bagaimana mesin pencari memberi peringkat pada Jaringan Konten Semantik Awalnya dan kemudian, Memodifikasi. Dalam konteks ini, hal-hal di bawah ini akan diproses.
- Peringkat Awal
- Peringkat ulang
- Templat Kueri
- Templat Dokumen
- Templat Maksud Pencarian
- Apa yang harus Anda lakukan untuk memanfaatkan Jaringan Konten Semantik
Apa itu Peringkat Awal untuk SEO?
Ini adalah istilah dan konsep baru untuk SEO, tetapi yang lama untuk Search Engine. Versi panjang dari "Studi Kasus SEO yang berfokus pada jaringan semantik" berfokus pada Algoritma Peringkat berdasarkan pada algoritma yang bergantung pada kueri, bergantung pada dokumen, bergantung pada sumber, dan beberapa paten. Predictive Information Retrieval atau algoritma peringkat prediktif mencoba mengurangi biaya komputasi. Dan, bahkan jika pengindeksan terjadi dalam satu hari, memahami dokumen bisa memakan waktu berbulan-bulan atau bahkan bertahun-tahun. Oleh karena itu, menghitung peringkat awal adalah cara untuk meningkatkan Kualitas SERP sambil mengurangi biaya. Beberapa tugas terkait Mesin Pencari memiliki prioritas lebih tinggi daripada yang lain untuk menjaga indeks tetap hidup, segar, dan berkualitas cukup tinggi.

Istilah peringkat awal muncul dalam puluhan ribu Paten Google dan makalah penelitian yang berbeda karena merupakan perspektif klasik di antara pembuat mesin pencari. Jadi, di atas, Anda dapat melihat dokumen paten yang berbeda dengan kelanjutan dari paragraf yang sama, dan persyaratan dengan sedikit perubahan di sekitar peringkat awal istilah.
Peringkat awal mewakili peringkat dokumen di SERP segera setelah diindeks. Peringkat awal dokumen mewakili keseluruhan otoritas, dan relevansi sumber dengan topik tertentu, template kueri, dan maksud pencarian. Konten yang sama dapat diberi peringkat berbeda dalam hal peringkat awal antara sumber yang berbeda. Peringkat awal penting saat menggunakan Jaringan Konten Semantik untuk melihat peningkatan kualitas dan otoritas sumber secara keseluruhan. Setiap dokumen baru meningkatkan peringkat awalnya sambil mengurangi penundaan pengindeksan jika desain jaringan konten semantik terstruktur dengan benar.
Pemeringkatan awal mendukung proses pemeringkatan ulang dan efisiensinya untuk sumber. Dan, "Peringkat peringkat sumber" harus diproses dengan dua istilah ini, peringkat awal dan peringkat ulang.
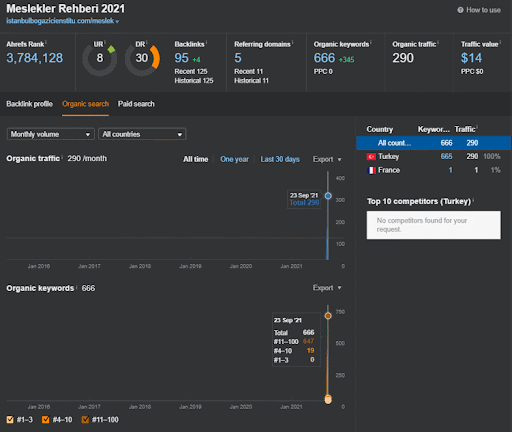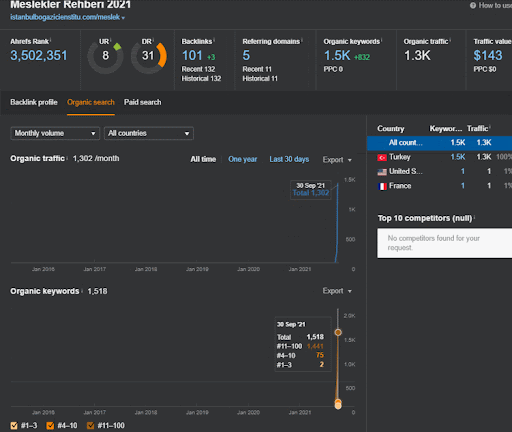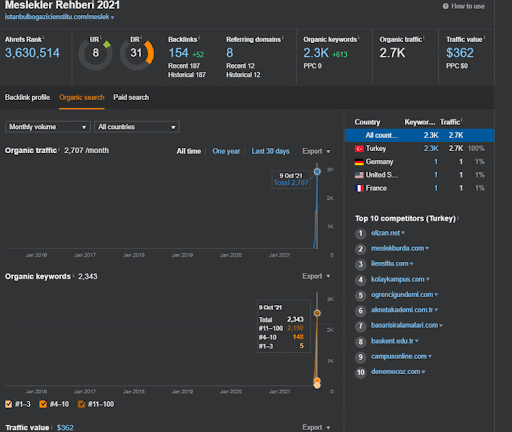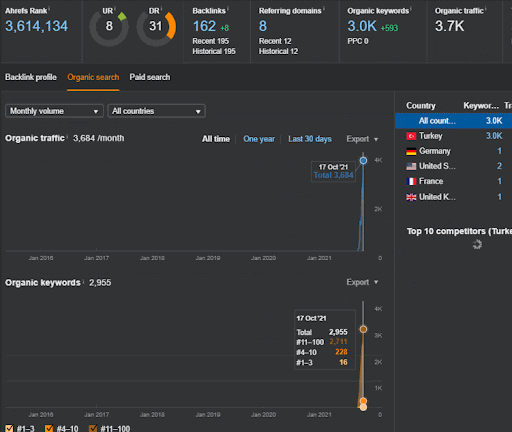
Anda dapat menonton 20 hari pertama perubahan kinerja organik Jaringan Konten Kedua dari Proyek I.
Dalam konteks ini, setiap kali Vizem.net menerbitkan dokumen baru, atau setiap kali IstanbulBogazici Enstitu menerbitkan jaringan konten semantik baru, peringkat awal lebih baik dari sebelumnya sementara konten diindeks lebih cepat.
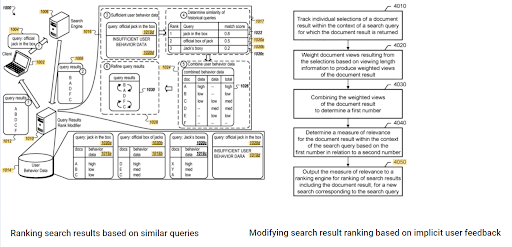
Keunggulan peringkat awal dan data historis dapat dilihat di antara dua paten Google yang saling melengkapi ini. Salah satunya adalah untuk dokumen awal dan peringkat ulang berdasarkan umpan balik pengguna implisit. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 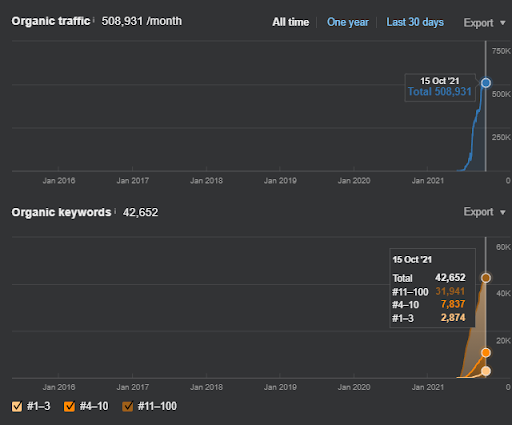
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 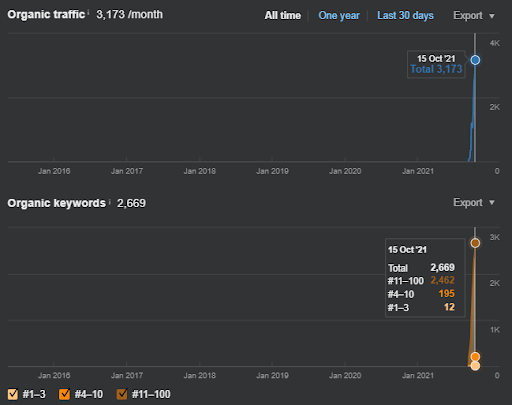
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 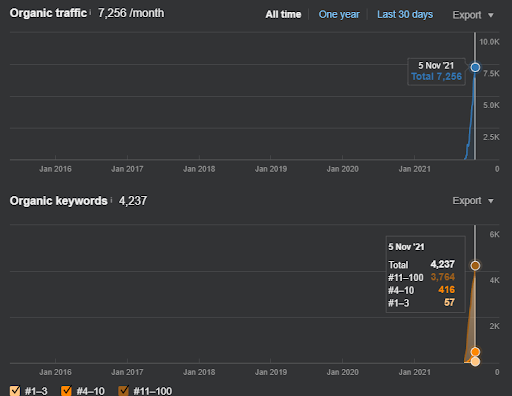
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 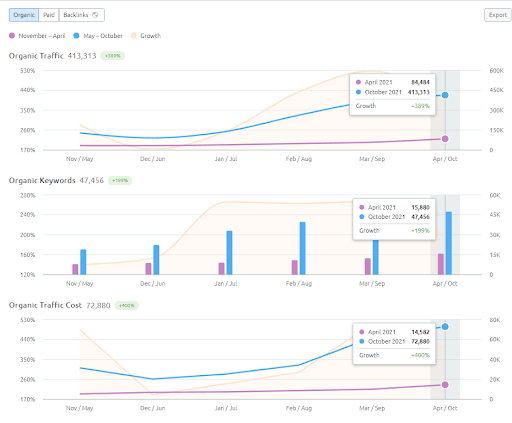
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.

The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
Data Perayapan³
 Belajarlah lagi
Belajarlah lagiWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 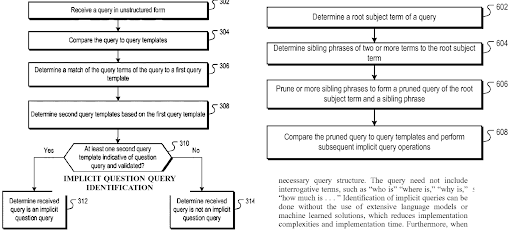
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
Iya itu mereka. Peringkat Probabilistik, dan Peringkat Relevansi yang Terdegradasi adalah kolom utama dari mesin pencari semantik untuk memahami pengguna, dan menciptakan SERP kualitas tertinggi terbaik yang disiapkan untuk keadaan kemungkinan. 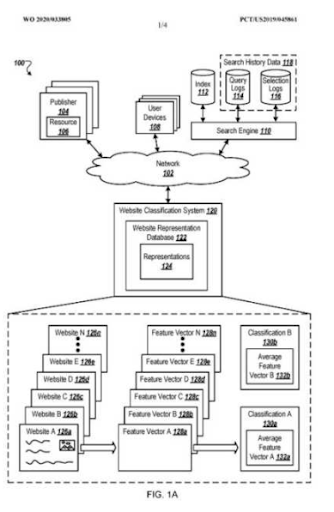
Sebelumnya, untuk membuat argumen “desain situs web, dan tampilan, atau nada suara” untuk pembelajaran representasi untuk situs web, Bill Slawski telah menulis “Vektor Representasi Situs Web”.
Apa yang dimaksud dengan template maksud pencarian?
Templat maksud pencarian dapat diwakili oleh kebutuhan di balik templat kueri. Templat kueri-dokumen bisa disatukan berdasarkan templat maksud. Memiliki template maksud pencarian dengan kemungkinan pemahaman “Peringkat Relevansi yang Terdegradasi”, dan “Peringkat Probabilistik” akan membantu menciptakan aktivitas pencarian terbaik dan cakupan maksud pencarian dengan urutan yang benar. Saat membuat Jaringan Konten Semantik, hal terpenting adalah menyesuaikan template maksud kueri dokumen berdasarkan konteks sumber untuk menyelesaikan jaringan semantik berdasarkan domain pengetahuan dengan meningkatkan cakupan kontekstual untuk meningkatkan kepercayaan berbasis pengetahuan dan otoritas topikal . 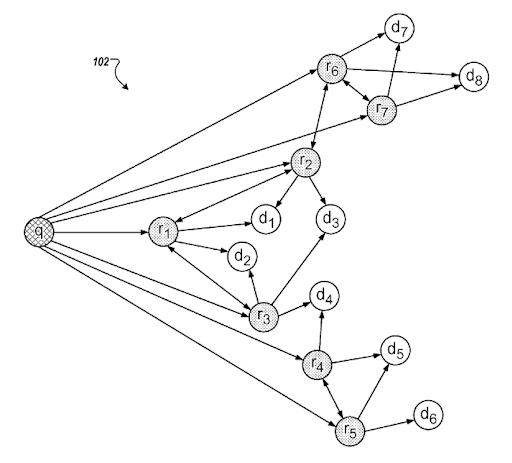
Bagian dari "Penyempurnaan Kueri berdasarkan Inferred Intent" Google. Ini bekerja melalui cluster kueri dan template maksud dengan koneksi semantik. Anda dapat mengalaminya pada tingkat taksonomi frasa yang berbeda.
Sebelum beralih ke beberapa contoh konkret, dan saran untuk membantu Anda membuat jaringan konten semantik yang lebih baik, saya harus memberi tahu Anda bahwa bahkan versi sederhana dari Studi Kasus SEO ini memerlukan pemahaman mesin pencari dan keterampilan komunikasi tingkat tinggi. Jadi, meskipun saya merasa telah memberikan informasi tingkat tinggi, saya tahu bahwa kursus SEO Semantik yang akan saya buat akan menunjukkan kepada Anda beberapa contoh konkret yang lebih banyak dan lebih baik. 
Paten yang sama menjelaskan hubungan yang tepat antara "jalur kueri" dan "pergeseran konteks" yang berbeda.
Apa yang harus Anda ketahui tentang memanfaatkan Jaringan Konten Semantik?
Untuk membuat Jaringan Konten Semantik, terkadang bahkan ringkasan dan desain konten semantik sederhana dapat memakan waktu satu jam, jika Anda meletakkan semua detail yang relevan berdasarkan semantik leksikal, atau jenis hubungan antara entitas, dan frasa. Menggunakan beberapa sudut pada saat yang sama seperti pengindeksan berbasis frase, dan vektor kata, atau vektor konteks untuk menghitung relevansi kontekstual dari keseluruhan konten ke domain kontekstual, atau relevansinya berdasarkan jenis sub-konten individu, itu membutuhkan pemahaman mesin pencari semantik tingkat tinggi.
Dengan demikian, menggunakan metodologi generatif akan mempermudah segalanya dengan konsep yang telah saya jelaskan kepada Anda di atas, karena meskipun Anda mempersiapkan setiap bagian jaringan konten semantik dengan sempurna, penulis dan penulis tidak akan dapat menulisnya, atau pengelola konten tidak akan bisa mengikuti visi Anda. Jadi, itu mungkin melelahkan Anda tanpa alasan, dan membuat Anda meninggalkan proyek seperti yang saya lakukan untuk beberapa Proyek Studi Kasus SEO ini setelah saya membuktikan konsepnya dengan cara yang cukup, hidup, dan dapat diaudit.
Saran di bawah ini hanya untuk langkah-langkah yang mudah dieksekusi dan singkat yang akan membantu Anda.
1. Jangan gunakan Tautan Bilah Sisi Tetap dari Setiap Jaringan Jaringan Konten Semantik
Setiap link harus memiliki deskripsi koneksi antara dua dokumen hypertext seperti setiap kata dalam halaman web. Penggunaan HTML Semantik dapat membantu menentukan posisi dan fungsi dokumen pada halaman web sambil membantu mesin telusur untuk menimbang bagian secara berbeda dalam konteks konteks.
Pada contoh Vizem.net, saya tidak menggunakan desain sidebar yang sama. Bilah sisi tidak menampilkan posting terbaru, atau yang paling penting. Bilah sisi hanya menampilkan atribut entitas pusat, dan tidak tetap, mereka dinamis. Dengan kata lain, berdasarkan hierarki dalam peta topikal, jaring jaringan konten semantik berubah meskipun berada di bilah sisi. 
Memikirkan Model Peselancar yang Wajar dan Peselancar yang Berhati-hati dapat membantu SEO untuk menciptakan relevansi yang lebih baik antara dokumen hypertext yang berbeda.
Selain itu, tautan mengalir dalam hal keunggulan, dan popularitas harus mengikuti konteks sumber dari koneksi terbaik. Di bawah ini, Anda dapat melihat bagian bilah sisi dengan kode HTML Semantik yang disesuaikan. 
Menurut hierarki artikel yang aktif pada sesi pengguna, tab, urutan tab, tautan di dalam tab akan berubah. Contoh di atas adalah dari hierarki remah roti di bawah ini. ![]()
2. Dukung Jaringan Konten Semantik dengan PageRank
Bahkan jika PageRank eksternal tidak wajib dari sumber eksternal, jika Anda dapat menggunakannya, Anda akan menyadari bahwa peringkat awal dan peringkat ulang akan lebih baik. Untuk kedua proyek ini, saya tidak menggunakannya, tetapi kali ini bukan itu tujuannya. Untuk Vizem.net, ada masalah ekonomi, dan saya tidak ingin menghabiskan anggaran untuk PR dan penjangkauan digital. Untuk Istanbul BogaziciEnstitusu, saya mengatur beberapa "sumber yang saling terhubung secara lokal" untuk mendukung keaslian sumber untuk topik tertentu, tetapi sekali lagi, perusahaan tidak dapat menerapkan ini karena masalah anggaran dan disiplin organisasi. 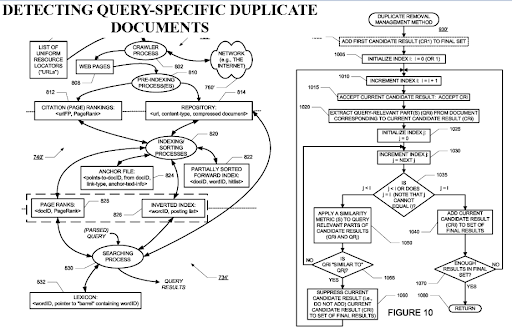
Mendeteksi Dokumen Duplikat Query-spesifik adalah perspektif penting dari Search Engine, karena PageRank dapat membantu dokumen untuk disaring sebagai berharga bahkan jika digandakan. Karena, jaringan konten semantik yang sangat terorganisir dapat serupa satu sama lain, aliran PageRank, dan data historis berguna.
Saat memilih titik aliran PageRank eksternal untuk jenis jaringan konten semantik ini, gunakan sumber dengan data historis. Dalam kasus saya, saya telah mengatur titik akhir PageRank ini sebelumnya, sebelum saya meluncurkan dan menerbitkan jaringan konten semantik pertama. Dengan cara ini, saya dapat mengambil referensi eksternal dari pesaing langsung, tetapi ketika saya menerbitkan jaringan konten semantik, pesaing menyerah untuk menautkan sumbernya karena mereka telah melihat peningkatan massa sumber sebagai pesaing.
Situasi ini membawa kita ke saran ketiga. Jika kita dapat menggunakan aliran PageRank dari referensi eksternal, proses re-ranking akan lebih cepat, dan ranking awal akan lebih tinggi.
3. Gunakan Teks Jangkar Berbeda dari Footer, Header, dan Konten Utama untuk Bagian Jaringan Konten Semantik yang Menonjol
Teks jangkar atau "teks tautan" dari sudut pandang mesin pencari menandakan relevansi dokumen hiperteks dengan yang lain. Menurut dokumen asli PageRank, jumlah tautan sebanding dengan aliran PageRank. Namun, belakangan Google mengubahnya untuk mencegah “link stuffing” dan membatasi tautan yang benar-benar dapat melewati PageRank. Berdasarkan hal ini, TrustRank, Cautious Surfer, Hilltop Algorithm, atau Reasonable Surfer Models dikembangkan. 
Ini adalah dua tautan ke dua jaringan konten semantik yang berbeda untuk BogaziciEnstitusu, tetapi karena saya tidak menerapkan SEO teknis, atau peningkatan UX, Anda dapat menyadari "murahnya" desain tombol.
Menurut Google, tautan yang sama tidak dapat melewati PageRank untuk kedua kalinya ke halaman web lain, sedangkan PageRank hanya akan diteruskan dari tautan pertama. Dan, dalam bentuk asli dari algoritma PageRank, dokumen hypertext dapat menautkan dirinya sendiri untuk meningkatkan PageRank-nya, atau pengalihan 301 dapat digunakan untuk mengambil PageRank dari dokumen target tautan. Kedua situasi ini menciptakan Teknik Black Hat lama seperti mengarahkan ulang halaman web ke halaman lain untuk sementara hanya karena mengambil PageRank-nya. Ini adalah dari hari-hari ketika SEO dapat melihat PageRank halaman web dari Google Search Console atau SERP. Kemudian, Google mulai meredam PageRank dengan setiap pengalihan sementara Danny Sullivan menjelaskan bahwa pengalihan 301 akan melewati PageRank sepenuhnya. Selain semua perubahan ini, yang penting di sini adalah bahwa bahkan jika tautan kedua tidak lulus PageRank, tetap melewati relevansi teks tautan. 
Bagian terkemuka dari Jaringan Konten Semantik telah ditautkan dari HomePage berdasarkan "perbaikan kueri tengah" yang mencakup "kata kerja, predikat", atau "aktivitas pencari".
Dengan demikian, bagian yang menonjol dari Jaringan Konten Semantik harus ditautkan dari menu header dan footer dengan bagian taksonomi yang lebih tinggi, dan teks tautan harus berbeda satu sama lain. Dalam contoh ini, saya telah menggunakan tautan tajuk dengan teks tautan yang menonjol tetapi pendek sementara saya menyimpan contoh footer lebih lama. 
Bagian dari "Pengindeksan Tag Jangkar dalam sistem perayap web", ini merangkum pentingnya teks jangkar, dan teks anotasi untuk memposisikan halaman web di dalam kluster kueri, dan kluster halaman web.
Jika bagian Jaringan Konten Semantik terlalu menonjol, untuk melewati PageRank dan prioritas perayapan dengan benar, saya telah menautkan bagian yang paling penting dengan teks tautan yang tepat, dan paragraf penjelasan yang menyertakan atribut yang menonjol dengan berbagai variasi N-Gram yang relevan. 
Ini adalah area tertaut kedua dari beranda Vizem.net, berada di belakang akordeon, dan berfokus pada negara-negara dalam kueri, dan menghubungkan bagian tengah jaringan konten semantik.
Catatan: Di sekitar Anchor Texts, selalu, "teks penjelasan" yang direncanakan telah digunakan untuk meningkatkan ketepatan tujuan tautan.
4. Batasi Batasan Jumlah Tautan dan Pencocokan Tautan Desktop dan Seluler dan Konten Utama
Kedua proyek dibatasi untuk memiliki kurang dari 150 tautan internal per halaman web. Dengan bantuan HTML Semantik, tempat tautan, dan fungsi tautan menjadi jelas bagi perayap. IstanbulBogazici Enstitusu memiliki lebih dari 450 tautan per halaman web, dan beberapa di antaranya adalah tautan sendiri (tautan dari halaman yang sama ke halaman yang sama). Bagian terburuknya adalah setengah dari tautan ini tidak ada dalam konten versi seluler. 
Skor Penyimpanan URL, Skor Perayapan, dan jenis skor lainnya dapat digunakan untuk menentukan keunggulan tautan dalam Peta URL internal, dan tag identifikasi dokumen dalam berbagai tingkatan dapat digunakan untuk mengurutkan indeks berdasarkan skor relevansi yang tidak bergantung pada kueri.
Karena Google menggunakan pengindeksan khusus seluler, jika konten tidak ada dalam versi seluler, konten tersebut akan diabaikan, dan tidak digunakan untuk tujuan evaluasi relevansi dan peringkat. Dengan demikian, konten seluler dan desktop telah dikonfigurasi untuk dicocokkan satu sama lain. Bahkan jika Google mentolerir ketidakcocokan konten antara versi desktop dan seluler, itu masih membuat pemahaman dan peringkat halaman web lebih sulit untuk mesin pencari. 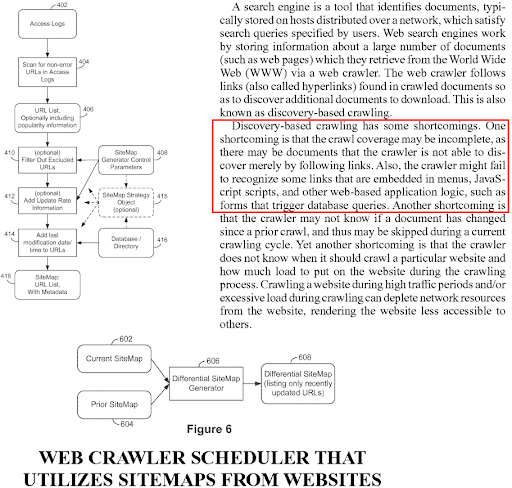
Mesin pencari dapat menghasilkan peta situs untuk situs web, dan peta situs ini dapat dibuat ulang dalam satu lingkaran, jika tautan, dan metadata URL tidak cocok antara agen pengguna, atau garis waktu. Jadi, menjaga agar jalur perayapan tetap pendek, antrian perayapan singkat, dan tautan internal konsisten adalah penting.
Seiring dengan tautan antara halaman web yang berbeda, juga tautan untuk subbagian halaman web digunakan dengan "tabel konten", dan "Fragmen URL". Fragmen URL ini menargetkan sub-bagian tertentu dari halaman web sambil menamainya dengan benar, dan bagian tertentu telah dimasukkan ke dalam tag bagian dengan h2. Dengan bantuan Fragmen URL dengan “tautan navigasi dalam halaman”, mengarahkan pengguna dari SERP ke bagian tertentu dari halaman web menjadi lebih mudah, sementara bagian bawah konten telah dibuat lebih menonjol untuk memenuhi kebutuhan di balik pertanyaan.
5. Miliki Disiplin Tingkat Militer untuk Proyek SEO Anda
Ini sepenuhnya topik lain dan artikel lain dapat ditulis untuk mendefinisikan apa arti disiplin tingkat militer, atau mengapa ini berguna untuk Proyek SEO. Tapi, saya harus memberitahu Anda bahwa selama 2 bulan terakhir ini, saya telah melatih banyak CEO, dan SEO dari agensi lain bersama dengan tim mereka untuk melihat apakah desain kursus saya akan bekerja dengan baik atau tidak.
Setiap kali saya melihat kesuksesan, dan tingkat keterikatan yang tinggi untuk sesi pendidikan yang saya lakukan, ada kemauan dan ketekunan yang kuat. Masalah utama adalah bahwa SEO Semantik jauh lebih sulit daripada SEO Vertikal lainnya. SEO teknis bersifat universal, dan bahkan memiliki panduan tertulis untuk setiap langkah. SEO OnPage, atau WUX dan Desain Tata Letak dapat dilacak dengan pengukuran numerik. Ketika berbicara tentang Semantik, itu adalah praktik menyatukan perspektif mesin yang bekerja berdasarkan sistem adaptif yang kompleks dengan homo-sapiens yang tidak memahami cara kerja mesin.
Perbedaan ini membutuhkan landasan beton yang harus diletakkan sejak hari pertama proyek. Sebagian besar waktu, saya menggunakan aturan di bawah ini.
- Desain konten dan jaringan konten semantik tidak harus logis bagi seorang penulis, atau penulis.
- Tugas pengelola konten adalah mengaudit kompatibilitas konten dengan desain konten.
- Tugas penulis adalah menulis konten dengan informasi terkait yang mencakup tingkat akurasi dan detail yang tinggi.
- Tautan, definisi, bukti, perbandingan, proposisi, referensi harus dibuat dengan contoh konkret, bukan dengan basa-basi.
- Setiap kata yang tidak perlu adalah pengenceran untuk konteks dan konsep.
Ketika Anda membaca, mungkin terdengar mudah untuk diterapkan, tetapi tidak semudah itu. Jadi, saya dapat mengatakan bahwa saya bahkan akan memecat beberapa karyawan saya sendiri. Saya senang saya tidak melakukannya, setidaknya untuk saat ini. Dalam kondisi normal, akan banyak pertanyaan yang akan Anda tanyakan, jika pemilik pertanyaan bukan SEO atau pemilik perusahaan, jangan dijawab. Simpan energi Anda ke penyimpanan data mesin pencari yang akan menyimpan umpan balik positif Anda, bukan umpan balik yang berlebihan dan tidak relevan dengan peringkat.
6. Perluas Sumber dengan Relevansi Kontekstual
Bagian ini sepenuhnya tentang memahami kebutuhan Google untuk membuat MuM. Saat Anda mendesain Peta Topik, itu akan mencakup banyak Jaringan Konten Semantik yang akan memberikan Basis Pengetahuan tingkat situs yang lebih baik. Jadi, saat menerbitkan sub-bagian ini, mereka harus dapat terhubung ke konteks sumber, atau itu dapat mengubah cara mesin pencari melihat sumbernya, dan tema situs web dapat beralih ke domain pengetahuan lain. Misalnya, menghubungkan hal-hal di sekitar konsep dan area minat dengan tindakan yang mungkin memerlukan pemahaman koneksi makna yang rumit satu sama lain. Membuat koneksi ini jelas bagi pengguna, penulis, dan juga mesin pada saat yang sama adalah proses pembuatan Jaringan Konten Semantik. 
Untuk mencapai ini, setiap bagian baru untuk situs web harus dapat dihubungkan ke bagian tengah dari peta topikal. Jembatan kontekstual ini dapat dilihat dari desain dan penjelasan LaMDA Google sendiri.
Saya menemukan banyak pertanyaan seperti “apakah saya harus menulis tentang topik lain”, “jika saya memiliki dua niche yang berbeda, apakah akan merugikan?”. Jika Anda menghubungkan semua sub-bagian ini, segmen situs web sebagai komponen yang sangat terhubung, jaringan konten semantik ini akan saling mendukung untuk peringkat yang lebih baik daripada membagi identitas merek, dan otoritas topikal untuk dua topik yang berbeda dan tidak relevan.
7. Buat Lalu Lintas Aktual dan audit dengan Segmentasi Kustom Google Analytics
Lalu Lintas Aktual terhubung ke RankMerge dengan cara yang sama seperti Kepercayaan Berbasis Pengetahuan terhubung ke PageRank. Segera, saya berpikir untuk menulis artikel lain dengan judul “Ketika PageRank Berbohong…” untuk menjelaskan mengapa mesin pencari mencoba mempengaruhi PageRank dengan sinyal samping. Faktanya, PageRank bukanlah sinyal definitif yang menunjukkan otoritas, keahlian, dan kepercayaan seorang sumber. Ini bisa menjadi sinyal untuk peringkat, dan faktor, tetapi tidak bisa dipercaya sendirian. RankMerge adalah proses menyatukan lalu lintas situs web dan PageRank sedemikian rupa sehingga situs web dapat masuk akal bagi mesin pencari. PageRank tinggi dan lalu lintas rendah dapat menandakan "lalu lintas tidak populer", atau "manipulasi PageRank".
Jadi, untuk meningkatkan data historis sumber, saya telah menggunakan Acara SEO musiman, dan saya telah meningkatkan kueri "merek + istilah umum". Lalu lintas langsung, dan halaman web yang di-bookmark meningkat dengan lalu lintas yang sebenarnya dan otentik.
Jenis data ini membantu mesin pencari untuk memercayainya untuk memberi peringkat lebih tinggi dan lebih tinggi di SERP.
Untuk dapat mengaudit lalu lintas aktual yang berasal dari Jaringan Konten Semantik ini, SEO dapat membuat segmen khusus dari Google Analytics untuk melihat bagaimana mereka datang sebagai lalu lintas langsung. Juga, Sasaran khusus dapat dibuat seperti membuat kemungkinan perjalanan pencarian dari Jaringan Konten Semantik pertama ke Jaringan Konten Kedua. Ini adalah bukti konsep bahwa jaringan semantik dibangun di sekitar minat, konsep, dan kemungkinan tindakan terkait pencarian.
Di bawah ini, Anda hanya akan menemukan satu contoh untuk salah satu halaman web yang ditempatkan dalam Jaringan Konten Semantik pertama untuk menunjukkan lalu lintas langsung yang diperoleh melalui lalu lintas organik. 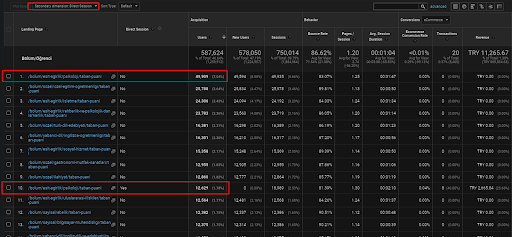
Dalam 3 bulan terakhir, hanya satu halaman web dari jaringan konten semantik pertama yang telah digunakan oleh 49.000 pengguna organik. Dan, 12.900 pengguna tambahan datang sebagai lalu lintas langsung yang diperoleh oleh pencarian organik untuk pertama kalinya. Dan, metrik sesi/halaman dan durasi sesi rata-rata lebih tinggi untuk segmen pengguna ini.
Seperti yang dikatakan sebelumnya, mesin pencari dapat mengelompokkan kueri, dokumen, maksud, konsep, minat, tindakan, tetapi juga dapat mengelompokkan pengguna. Jika grup pengguna meninggalkan umpan balik positif sambil menciptakan nilai merek dengan menambahkan halaman web ini ke bookmark, mengetik bilah alamat secara langsung, dan mencari istilah umum bersama dengan nama merek, itu menunjukkan bahwa sumber meningkatkan otoritasnya, dan mesin pencari mampu mengenali semuanya dari SERP, Chrome, dan alamat DNS-nya sendiri. 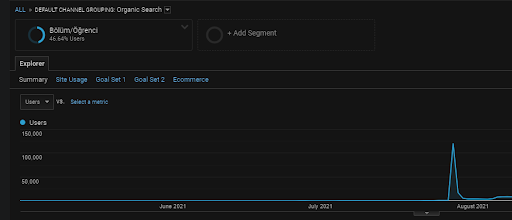
Di atas, Anda dapat melihat segmen pengguna Jaringan Konten Pertama. Anda dapat membuat segmen pengguna untuk setiap Jaringan Konten Semantik dengan sasaran khusus, dan Anda juga dapat menambahkan segmen sub-pengguna untuk jaringan sub-konten Semantik.
8. Mendukung Jaringan Konten Semantik dengan Sub-bagian berdasarkan Aktivitas Pencarian
Bagian ini juga tentang resolusi atribut entitas, dan analisis yang merupakan topik lain. Tapi, sederhananya, beberapa atribut entitas ini berdasarkan domain kontekstual harus diletakkan di hierarki yang lebih rendah, bukan ke hierarki yang lebih tinggi. Dalam hal ini, “Vizem.net” dapat memberikan contoh yang lebih baik, sedangkan untuk Bogazici Enstitusu dapat ditunjukkan dengan “Gaji Pekerjaan”, dan “Poin Ujian Universitas”. Dua atribut yang menonjol ini telah ditempatkan berdasarkan kueri dan templat dokumen ke jaringan sub-konten semantik. 
Identifikasi Unit Semantik dari dalam kueri penelusuran adalah paten Google lain yang membagi frasa ke dalam kategori semantik yang berbeda, dan menggabungkan relevansi dokumen berdasarkan kedekatannya dengan semua variasi kueri.
Dalam Studi Kasus SEO sebelumnya, saya tidak mengikuti jenis struktur ini, saya membuat jalur perayapan berdasarkan "kronologi" dan tautan internal yang sangat terbatas. Dalam artikel ini jumlah tautan internal yang ditempatkan konten utama lebih tinggi dari yang sebelumnya.
9. Gunakan Kata Tematik dalam URL
Jika Google menemukan dua URL berbeda dengan konten yang sama tanpa sinyal kanonikalisasi, Google akan memilih yang pendek sebagai yang kanonik. Karena, URL pendek lebih mudah untuk diurai, diselesaikan, dan diminta. Ketika Anda memiliki triliunan halaman web yang Anda refresh miliaran kali setiap hari, bahkan huruf di URL dapat menunjukkan “keseimbangan biaya/kualitas” dari sebuah situs web. Seperti yang saya katakan sebelumnya, "biaya pengambilan" harus lebih rendah daripada "biaya tidak mengambil". Jika Anda ingin dipahami oleh mesin telusur, Anda harus meletakkan "sinyal konteks yang berurutan dan saling melengkapi" di setiap level, termasuk URL. 
Bagian dari peringkat "berbasis bukti" melalui agregasi bukti. Ini menjelaskan bagaimana jawaban dapat dicocokkan dengan pertanyaan.
Dalam konteks ini, sebagian besar waktu, saya menggunakan satu kata di dalam URL. Ini dapat mencerminkan hierarki dan struktur jaringan konten semantik. Beberapa masih berpikir bahwa "jumlah lapisan" dalam URL memengaruhi frekuensi perayapan, sebelum 2019, itu benar. Tapi, selama konten masuk akal, dan memuaskan pengguna dari topik populer atau menonjol, itu tidak akan terpengaruh oleh situasi seperti itu.
Untuk mendemonstrasikannya, Anda bisa mengikuti contoh di bawah ini.
- Root-domain/semantic-content-network-1/type-1/sub-content-network-part-for-type-1
- Root-domain/semantic-content-network-2/type-2/sub-content-network-part-for-type-2
Kedua jaringan konten semantik ini dapat menghubungkan satu sama lain dari hierarki yang sama, dan mereka dapat menghubungkan diri mereka sendiri berdasarkan relevansinya juga. Ada lebih banyak hal di sini yang bisa kita bicarakan seperti "Isi Kerapu Entitas - Konten Tipe Hub", tetapi topik hari lain.
Catatan: Jaringan Konten Semantik Ketiga yang direncanakan dapat diproses sebagai "Jaringan Konten Kerapu Konseptual" juga. Dan, jika diterbitkan, dengan efek Jaringan Konten Semantik Kedua, Traffic Organik keseluruhan bisa lebih dari 3 juta sesi per bulan.
10. Pahami Perbedaan antara Bersarang dan Menghubungkan
Sebagai perbedaan metodologis praktis, menghubungkan adalah menghubungkan hal-hal serupa satu sama lain berdasarkan domain kontekstual, sedangkan bersarang adalah mengelompokkan konten serupa dengan tujuan yang sama bersama. Pengelompokan ini akan membantu mesin pencari untuk menemukan konten serupa satu sama lain lebih cepat dan membuat skor kualitas sumber untuk grup ini, atau konten bersarang ini berdasarkan jaringan semantik akan lebih mudah. 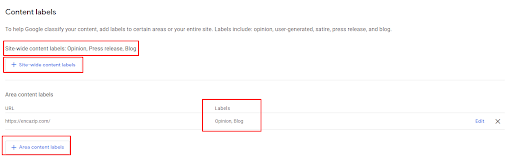
Bayangkan ada dua jalur perayapan yang berbeda seperti di bawah ini.
- Jalur Perayapan 1: Menemukan URL secara acak, tanpa template, kesamaan, dan relevansi kontekstual.
- Jalur Perayapan 2: Menemukan URL yang masuk akal bahkan dari URL itu sendiri, dengan template, tingkat kemiripan dan relevansi yang tinggi berdasarkan konteks.
Jika bahkan dari jalur perayapan, konten masuk akal, "peringkat awal" dan "peringkat ulang" akan lebih baik berkat "pemicu peringkat ulang berdasarkan pemahaman cakupan mesin pencari".
Catatan: Menggunakan tautan internal dengan taksonomi frase dengan cara yang benar adalah penting untuk membuat sarang dan menghubungkan.
Ini membawa kita ke dua metodologi praktis terakhir berbagi secara singkat. Dan, bagian ini lagi-lagi terkait dengan tingkat kedisiplinan dan kecukupan organisasi yang tinggi. 
Paten dari Trystan Upstill dan Steven D. Baker karena mengenali istilah yang muncul bersamaan dalam Daftar HTML. Keunggulan paten ini adalah menunjukkan nilai dari Daftar HTML tunggal untuk menentukan daftar istilah yang muncul bersama untuk suatu topik, atau bagian dari taksonomi frasa.
11. Pahami Kapan Memublikasikan Jaringan Konten Semantik dengan Frekuensi yang Disesuaikan
Ini telah dijelaskan sebelumnya, tetapi dalam salah satu Proyek Studi Kasus SEO ini, saya telah menerbitkan hampir 400 konten dalam satu hari. Ketika datang ke yang lain, saya sudah mulai menerbitkan hanya 10-15 konten secara tiba-tiba, kemudian saya meningkatkan kecepatan dari waktu ke waktu dengan kemantapan sampai masalah Ekonomi terkait Covid dimulai.
Jika sumber baru membuat Jaringan Konten Semantik baru, menerbitkannya pada hari pertama mungkin sedikit lebih sulit dari yang Anda kira, memeriksa semua tautan internal, tata bahasa, dan informasi di halaman web tidaklah mudah. Tetapi, jika semua konten hanya dari satu topik, dan templat kueri, dan jika sumber tidak memiliki riwayat apa pun tentang topik itu, menerbitkan sebagian besar jaringan konten semantik memiliki keuntungan seperti pengindeksan yang lebih cepat, pemahaman dan peringkat ulang.
Dalam situasi saya, ada juga peristiwa sejarah dengan musim. Jadi, tujuan saya adalah memiliki tingkat posisi rata-rata yang cukup sampai saya dapat diuji oleh mesin pencari untuk entitas tertentu dan aktivitas pencarian terhadap sumber yang lebih lama. Jadi, saya telah menerbitkan Jaringan Konten Semantik pertama dengan persiapan tingkat tinggi sebelum 45 hari dari acara musiman.
Kemudian, Anda dapat melihat bagaimana Search Engine menguji sumber berulang kali seperti di bawah ini. 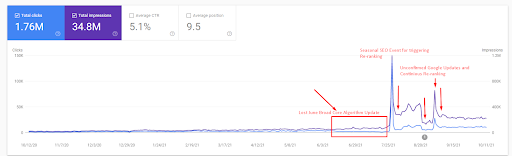
Penjelasan lebih rinci dapat ditemukan di bawah ini. 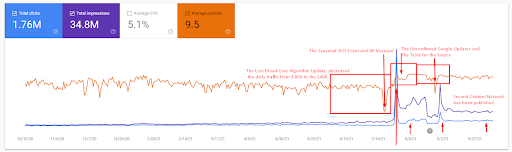
Cek fakta cepat dapat ditemukan di bawah untuk penjelasan tangkapan layar di atas.
- Pembaruan Algoritma Inti Luas telah menurunkan lalu lintas situs web lebih dari 200%.
- Situs web ini juga kehilangan lebih dari 15.000 kueri.
- Ini mempengaruhi pengindeksan keseluruhan sumber untuk jaringan konten semantik baru seperti dalam artikel Studi Kasus SEO terperinci telah dijelaskan dengan lebih baik.
- Berkat Acara SEO Musiman, peringkat ulang terjadi lebih awal, dan setelah Acara SEO musiman, mesin pencari menormalkan peringkat sumber berdasarkan lalu lintas aktual selama pembaruan yang belum dikonfirmasi.
- Kueri, dan peringkat yang diperoleh berkat Jaringan Konten Semantik Pertama dan Acara Musiman telah dilindungi, dan ditingkatkan lebih lanjut.
- Jaringan Konten Semantik pertama juga mendukung Jaringan Konten Semantik baru dan kedua.
Kehilangan kueri dan rata-rata kehilangan peringkat juga dapat dilihat dari Ahrefs seperti di bawah ini. Anda dapat memeriksa efek Google Broad Core Algorithm Update (GBCAU) Juni 2021 bersama dengan efek pembaruan yang belum dikonfirmasi. 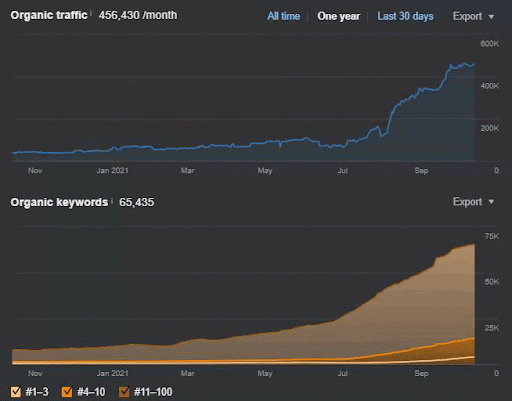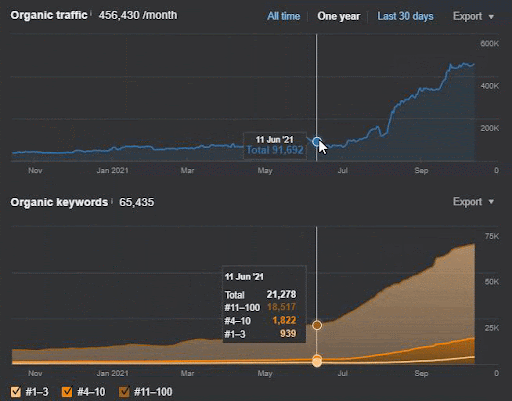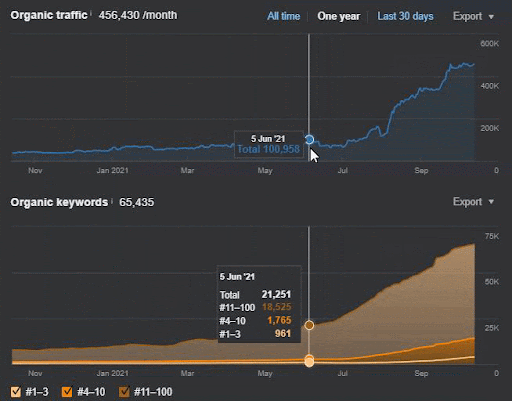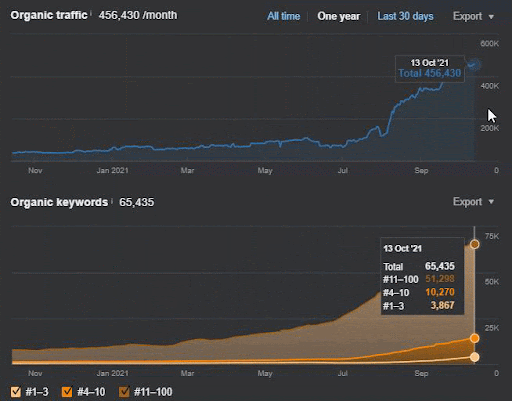
Jadi, menggunakan Jaringan Konten Semantik dengan beberapa kemungkinan strategi adalah suatu keharusan. Sekalipun GCBAU hilang, tetap saja, berkat faktor lain yang terkait dengan natura mesin pencari dapat membantu SEO. Jadi, Anda mungkin membayangkan mengapa menjelaskan hal-hal ini kepada seorang penulis, atau klien lebih sulit daripada SEO Teknis. SEO semantik tidak menggunakan nilai numerik, ia menggunakan Pengetahuan Teoritis yang berasal dari Pemahaman Mesin Pencari melalui paten, makalah penelitian, pengalaman, dan pengumuman historis.
12. Gunakan Pengoptimalan Kalimat Dalam Halaman untuk Struktur Faktual yang Lebih Baik
Sejujurnya, bahkan daftar ke-10 adalah topik yang sama sekali baru dan bahkan mungkin perlu menulis 20.000 kata di sini. Tapi, saya akan mulai dengan contoh sederhana.
- X adalah Y
- Y adalah X.
Untuk contoh kalimat di atas, Anda dapat memahami hal-hal di bawah ini.
- Kalimat di atas bukan merupakan duplikat konten.
- Proposisi di atas adalah duplikat.
- Penjelasan relasional antara dua kalimat adalah sama.
- Label Peran Semantik 100% berbeda.
- Output Pengenalan Entitas Bernama adalah 100% sama.
Pengoptimalan Kalimat Dalam Halaman terkait dengan Algoritma Pembuatan Pertanyaan dan teknologi pasangan Pertanyaan-jawaban. Format pertanyaan membutuhkan jenis kalimat tertentu. Dan jenis pertanyaan tertentu harus dijawab dengan jenis kalimat tertentu. Format konten, NER dan Ekstraksi Fakta akan terpengaruh dari optimasi struktur kalimat. 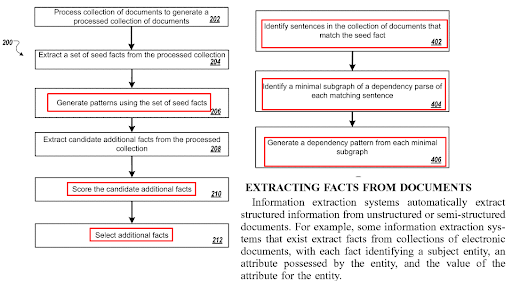
Kembar tiga (satu objek, dua subjek) dapat diekstraksi dan diperiksa akurasinya lebih cepat. Dua kalimat yang mirip tidak berarti mereka rangkap, itu berarti mereka dekat satu sama lain dalam hal struktur kalimat. Selama proposisi berbeda, menggunakan kalimat serupa antara templat dokumen serupa untuk pasangan maksud kueri yang berbeda adalah kebutuhan untuk pembuatan jaringan konten semantik. 
Struktur kalimat yang jelas dengan pola yang tepat berguna untuk membuat potongan teks lebih relevan satu sama lain sambil membantu mesin pencari mengenali entitas bernama, dan subjek, atribut, bersama dengan nilainya satu sama lain.
Ini juga akan membantu untuk melihat bagian artikel mana yang dapat dibuat lebih baik, dan di Jaring Topik, di mana peringkat konten Anda lebih baik untuk jenis pasangan kata, vektor kata, dan maksud apa. Karena, jika jenis struktur kalimat tertentu untuk jenis pertanyaan tertentu dapat diamati di beberapa halaman web, ini akan membantu untuk Pengujian A/B SEO Tingkat Lanjut dengan jumlah sampel data yang tidak terbatas, dan sampel pengujian. Anda dapat membuat beberapa desain kalimat dalam halaman untuk memeriksa bagaimana mesin pencari mengekstrak fakta untuk membandingkannya. 
Dalam hal memberikan fakta, “Knowledge Vault”, dan Luna Dong harus diingat.
13. Berikan Informasi Dunia Nyata dengan Presisi dan Konsistensi bukan Opini dengan Fluff
Ketepatan di sini berarti dapat dibandingkan dengan nilai numerik, atau hubungan konkrit konseptual. Konsistensi berarti bahwa Anda melindungi pendirian Anda untuk proposisi tertentu. Misalnya, jangan katakan bahwa “produk X terbaik untuk Y” untuk setiap ulasan produk yang terkait dengan Y. Jangan memberikan proposisi yang bertentangan di seluruh situs. Dan, jika produknya terbaik, apa buktinya? Bahan, ukuran, atau warna dan baunya? Fluff dalam teks berarti Anda menggunakan kata penghubung yang tidak perlu, atau tidak mengatakan hal-hal yang tidak mungkin untuk dibuktikan, atau bertentangan dengan kebenaran.
Dalam konteks instruksi non-definisi ini yang didukung oleh beberapa contoh, Anda dapat memeriksa salah satu Model Bahasa Google yaitu KeALM.
Ini untuk menghasilkan teks dari database dengan model data-ke-teks, dan untuk memeriksa keakuratan konten. 
KELM adalah contoh Audit Akurasi untuk proposisi dengan metode text-to-data.
Ini juga sedikit tentang definisi "Triplet", dan "Ekstraksi Informasi Terbuka untuk Entitas Tidak Dikenal", tetapi seperti yang Anda tahu, ini adalah versi singkatnya, dan saya rasa, saya sudah cukup memberi tahu. Pada dasarnya, ketika Anda memberikan informasi yang salah di situs web Anda, pastikan bahwa Google dapat memahaminya untuk mengurangi Kepercayaan Berbasis Pengetahuan dari sumbernya. Di sini, Anda mungkin juga perlu mengetahui bahwa, karena Anda dapat memperluas Basis Pengetahuan, mesin pencari dapat mengubah basis pengetahuannya sendiri berdasarkan informasi Anda, jika Anda memiliki Sumber Berkorelasi dengan PageRank, dan Kepercayaan Basis Pengetahuan dengan akurasi tinggi, dan kembar tiga yang unik.
14. Memahami Pohon Ketergantungan Semantik untuk Entitas
Pohon Ketergantungan Semantik berarti bahwa atribut yang menandakan hubungan dengan entitas lain memiliki ketergantungan hierarkis di antara mereka. Pohon Ketergantungan Semantik dapat diamati dengan memeriksa beberapa profil entitas dan sudut seperti negara dapat menjadi anggota organisasi, dan sebagai entitas lain, organisasi ini dapat memiliki beberapa atribut lain yang dapat dikaitkan dengan negara terhubung dengan hubungan yang disimpulkan.
Di bawah ini, Anda akan dapat melihat contoh sederhana dari Search Engine, secara langsung. 
REALM adalah metode yang menggunakan Pohon Ketergantungan Semantik untuk mengekstrak informasi dari teks yang ambigu.
Di web terbuka, ekstraksi informasi terbuka dapat mengenali entitas bernama baru, dan mengekstrak entitas yang sama seperti yang terjadi bersama entitas lain. Kejadian bersama dan atribut bersama ini dalam artikel dapat menetapkan konteks dan tipe relasi kandidat antar entitas. Berdasarkan koneksi, dan tipe entitas, pohon ketergantungan semantik dapat dibuat. Logika yang sama juga berlaku untuk Lexical Semantics. Kata "anak laki-laki" memiliki beberapa kemungkinan arti dan beberapa arti lain yang tepat. Misalnya, anak laki-laki adalah laki-laki, dan mungkin remaja yang belum menikah. Hal ini dapat digunakan dekat dengan siswa juga. Kata "Ratu" di sisi lain mencakup sisi lain dan makna yang tepat seperti "perempuan", dan "menjadi gubernur". Jadi, memiliki sesuatu untuk diatur adalah hierarki pohon ketergantungan semantik alami yang dapat memberi sinyal pada beberapa jenis templat kueri tertentu seperti "Ratu ...", atau "Untuk Quen". These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 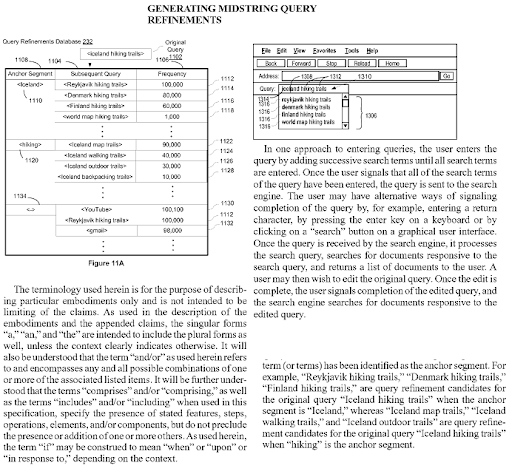
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.