
Mengontrol Perayapan & Pengindeksan: Panduan SEO untuk Robots.txt & Tag
Diterbitkan: 2019-02-19Mengoptimalkan anggaran perayapan dan memblokir bot dari halaman pengindeksan adalah konsep yang dikenal banyak SEO. Tetapi iblis ada dalam detailnya. Terutama karena praktik terbaik telah berubah secara signifikan selama beberapa tahun terakhir.
Satu perubahan kecil pada file robots.txt atau tag robots dapat memiliki dampak dramatis pada situs web Anda. Untuk memastikan dampaknya selalu positif bagi situs Anda, hari ini kita akan mempelajari:
Mengoptimalkan Anggaran Perayapan
Apa itu File Robots.txt
Apa itu Meta Robots Tags
Apa itu X-Robots-Tag
Arahan Robot & SEO
Daftar Periksa Robot Praktik Terbaik
Mengoptimalkan Anggaran Perayapan
Laba-laba mesin pencari memiliki "uang saku" untuk berapa banyak halaman yang dapat dan ingin dirayapi di situs Anda. Ini dikenal sebagai "anggaran perayapan".
Temukan anggaran perayapan situs Anda di laporan “Statistik Perayapan” Google Search Console (GSC). Perhatikan bahwa GSC adalah agregat dari 12 bot yang tidak semuanya didedikasikan untuk SEO. Itu juga mengumpulkan bot AdWords atau AdSense yang merupakan bot SEA. Dengan demikian, alat ini memberi Anda gambaran tentang anggaran perayapan global Anda tetapi bukan partisi ulang yang tepat.
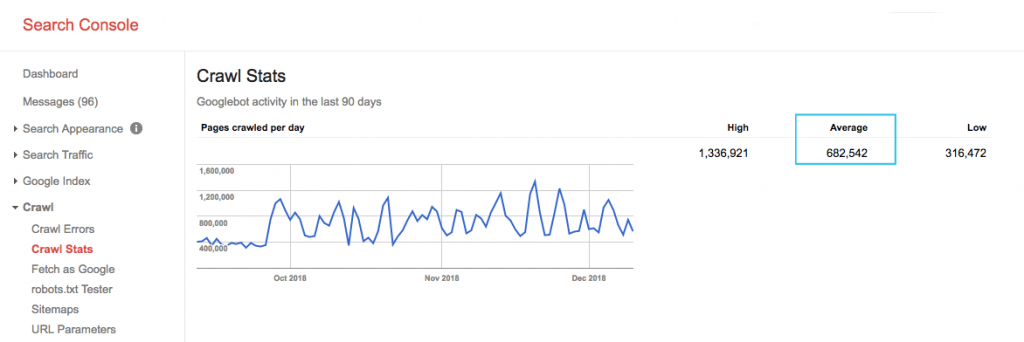
Untuk membuat angka tersebut lebih dapat ditindaklanjuti, bagi rata-rata halaman yang dirayapi per hari dengan total halaman yang dapat dirayapi di situs Anda – Anda dapat meminta nomor tersebut kepada pengembang atau menjalankan perayap situs tanpa batas. Ini akan memberi Anda rasio perayapan yang diharapkan untuk mulai dioptimalkan.
Ingin masuk lebih dalam? Dapatkan perincian lebih rinci tentang aktivitas Googlebot, seperti halaman mana yang sedang dikunjungi, serta statistik untuk perayap lain, dengan menganalisis file log server situs Anda.
Ada banyak cara untuk mengoptimalkan anggaran perayapan, tetapi tempat yang mudah untuk memulai adalah memeriksa laporan "Cakupan" GSC untuk memahami perilaku perayapan dan pengindeksan Google saat ini.
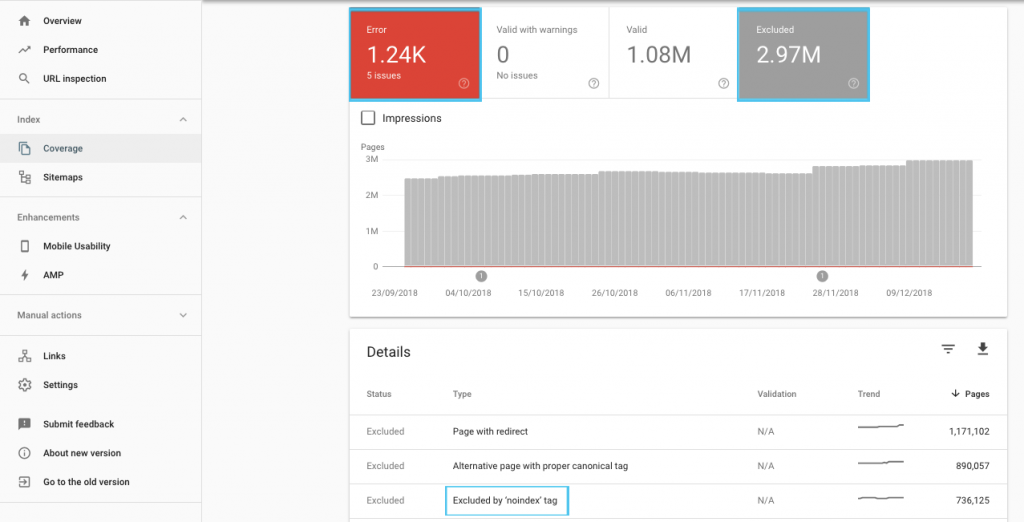
Jika Anda melihat kesalahan seperti “URL yang dikirimkan bertanda 'noindex'” atau “URL yang dikirim diblokir oleh robots.txt”, bekerja samalah dengan pengembang Anda untuk memperbaikinya. Untuk pengecualian robot apa pun, selidiki mereka untuk memahami apakah mereka strategis dari perspektif SEO.
Secara umum, SEO harus bertujuan untuk meminimalkan pembatasan perayapan pada robot. Meningkatkan arsitektur situs web Anda untuk membuat URL berguna dan dapat diakses oleh mesin telusur adalah strategi terbaik.
Google sendiri mencatat bahwa "arsitektur informasi yang solid kemungkinan akan menjadi penggunaan sumber daya yang jauh lebih produktif daripada berfokus pada prioritas perayapan".
Meskipun demikian, sangat bermanfaat untuk memahami apa yang dapat dilakukan dengan file robots.txt dan tag robots untuk memandu perayapan, pengindeksan, dan penerusan ekuitas tautan. Dan yang lebih penting, kapan dan bagaimana memanfaatkannya untuk SEO modern.
[Studi Kasus] Mengelola perayapan bot Google
 Baca studi kasus
Baca studi kasusApa itu File Robots.txt
Sebelum mesin pencari menelusuri halaman mana pun, ia akan memeriksa robots.txt. File ini memberi tahu bot jalur URL mana yang izinnya mereka kunjungi. Tapi entri ini hanya arahan, bukan mandat.
Robots.txt tidak dapat diandalkan untuk mencegah perayapan seperti firewall atau perlindungan kata sandi. Ini padanan digital dari tanda "tolong, jangan masuk" di pintu yang tidak terkunci.
Perayap yang sopan, seperti mesin pencari utama, biasanya akan mematuhi instruksi. Perayap yang bermusuhan, seperti pengikis email, robot spam, malware, dan laba-laba yang memindai kerentanan situs, sering kali tidak memperhatikan.
Terlebih lagi, ini adalah file yang tersedia untuk umum . Siapa pun dapat melihat arahan Anda.
Jangan gunakan file robots.txt Anda untuk:
- Untuk menyembunyikan informasi sensitif. Gunakan perlindungan kata sandi.
- Untuk memblokir akses ke situs pementasan dan/atau pengembangan Anda. Gunakan otentikasi sisi server.
- Untuk secara eksplisit memblokir perayap yang bermusuhan. Gunakan pemblokiran IP atau pemblokiran agen pengguna (alias menghalangi akses perayap tertentu dengan aturan di file .htaccess Anda atau alat seperti CloudFlare).
Setiap situs web harus memiliki file robots.txt yang valid dengan setidaknya satu pengelompokan direktif. Tanpa satu, semua bot diberikan akses penuh secara default – sehingga setiap halaman diperlakukan sebagai dapat dirayapi. Meskipun ini yang Anda inginkan, lebih baik jelaskan hal ini kepada semua pemangku kepentingan dengan file robots.txt. Plus, tanpanya, log server Anda akan dipenuhi dengan permintaan yang gagal untuk robots.txt.
Struktur file robots.txt
Agar diakui oleh perayap, robots.txt Anda harus:
- Jadilah file teks bernama "robots.txt". Nama file peka huruf besar/kecil. "Robots.TXT" atau variasi lainnya tidak akan berfungsi.
- Berada di direktori tingkat atas domain kanonik Anda dan, jika relevan, subdomain. Misalnya, untuk mengontrol perayapan pada semua URL di bawah https://www.example.com, file robots.txt harus berada di https://www.example.com/robots.txt dan untuk subdomain.example.com di subdomain.example.com/robots.txt.
- Kembalikan status HTTP 200 OK.
- Gunakan sintaks robots.txt yang valid – Periksa menggunakan alat pengujian robots.txt Google Search Console.
File robots.txt terdiri dari pengelompokan arahan. Entri sebagian besar terdiri dari:
- 1. User-agent: Mengatasi berbagai crawler. Anda dapat memiliki satu grup untuk semua robot atau menggunakan grup untuk menamai mesin telusur tertentu.
- 2. Disallow: Menentukan file atau direktori yang akan dikecualikan agar tidak dirayapi oleh agen pengguna di atas. Anda dapat memiliki satu atau lebih dari baris ini per blok.
Untuk daftar lengkap nama agen pengguna dan contoh arahan lainnya, periksa panduan robots.txt di Yoast.
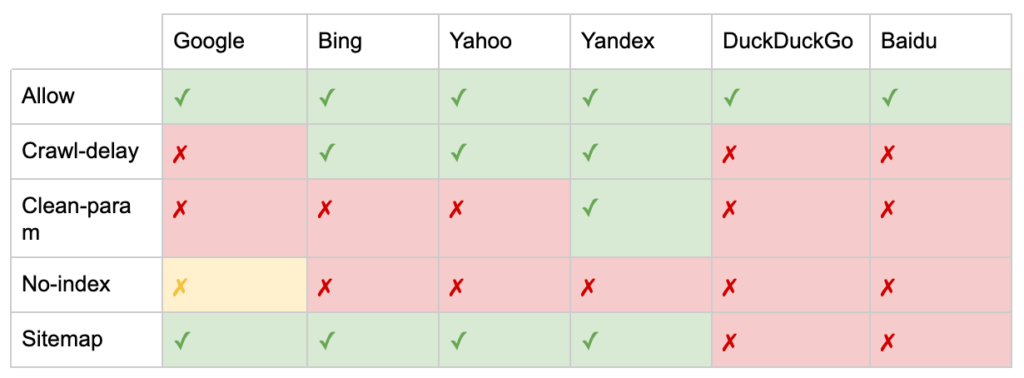
Selain arahan “User-agent” dan “Disallow”, ada beberapa arahan non-standar:
- Allow: Tentukan pengecualian untuk direktif disallow untuk direktori induk.
- Crawl-delay: Kurangi crawler berat dengan memberi tahu bot berapa detik untuk menunggu sebelum mengunjungi halaman. Jika Anda mendapatkan beberapa sesi organik, penundaan perayapan dapat menghemat bandwidth server. Tetapi saya akan menginvestasikan upaya hanya jika perayap secara aktif menyebabkan masalah pemuatan server. Google tidak mengakui perintah ini, menawarkan opsi untuk membatasi kecepatan perayapan di Google Search Console.
- Clean-param: Hindari meng-crawl ulang konten duplikat yang dihasilkan oleh parameter dinamis.
- Tanpa indeks: Dirancang untuk mengontrol pengindeksan tanpa menggunakan anggaran perayapan apa pun. Ini tidak lagi didukung secara resmi oleh Google. Meskipun ada bukti bahwa itu mungkin masih berdampak, itu tidak dapat diandalkan dan tidak direkomendasikan oleh para ahli seperti John Mueller.
@maxxeight @google @DeepCrawl Saya benar-benar akan menghindari penggunaan noindex di sana.
— ???? Yohanes ???? (@JohnMu) 1 September 2015
- Peta Situs: Cara optimal untuk mengirimkan peta situs XML Anda adalah melalui Google Search Console dan Alat Webmaster mesin telusur lainnya. Namun, menambahkan arahan peta situs di dasar file robots.txt akan membantu perayap lain yang mungkin tidak menawarkan opsi pengiriman.
Batasan robots.txt untuk SEO
Kita sudah tahu robots.txt tidak dapat mencegah perayapan untuk semua bot. Sama halnya, melarang perayap dari suatu halaman tidak mencegahnya disertakan dalam halaman hasil mesin pencari (SERP).
Jika halaman yang diblokir memiliki sinyal peringkat kuat lainnya, Google mungkin menganggapnya relevan untuk ditampilkan di hasil pencarian. Meskipun tidak merayapi halaman.
Karena konten dari URL tersebut tidak diketahui oleh Google, maka hasil pencariannya akan terlihat seperti ini:

Untuk memblokir halaman agar tidak muncul di SERP, Anda perlu menggunakan tag meta robot “noindex” atau header HTTP X-Robots-Tag.
Dalam hal ini, jangan larang halaman di robots.txt , karena halaman harus di-crawl agar tag “noindex” dapat dilihat dan dipatuhi. Jika URL diblokir, semua tag robot tidak akan efektif.
Terlebih lagi, jika sebuah halaman telah mengumpulkan banyak tautan masuk, tetapi Google diblokir dari merayapi halaman-halaman itu oleh robots.txt, sementara tautannya diketahui oleh Google, ekuitas tautan akan hilang.
Apa itu Meta Robots Tags
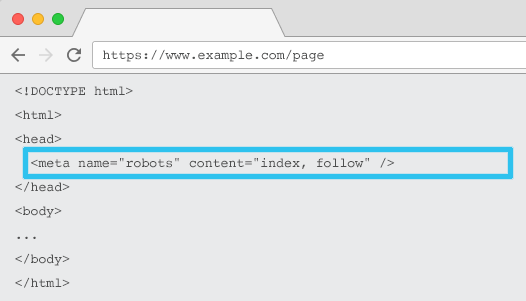
Ditempatkan di HTML setiap URL, meta name="robots" memberi tahu perayap jika dan bagaimana "mengindeks" konten dan apakah akan "mengikuti" (yaitu, merayapi) semua tautan di halaman, meneruskan ekuitas tautan.
Menggunakan meta name=“robots” umum, arahan berlaku untuk semua crawler. Anda juga dapat menentukan agen pengguna tertentu. Misalnya, nama meta="googlebot". Tapi jarang perlu menggunakan beberapa tag meta robot untuk mengatur instruksi untuk laba-laba tertentu.
Ada dua pertimbangan penting saat menggunakan tag meta robot:
- Mirip dengan robots.txt, tag meta adalah arahan, bukan mandat, jadi mungkin diabaikan oleh beberapa bot.
- Arahan robots nofollow hanya berlaku untuk tautan di halaman itu. Ada kemungkinan perayap mengikuti tautan dari halaman atau situs web lain tanpa nofollow. Jadi bot mungkin masih tiba dan mengindeks halaman yang tidak Anda inginkan.
Berikut daftar semua arahan meta robots tag:
- index: Memberitahu mesin pencari untuk menampilkan halaman ini di hasil pencarian. Ini adalah status default jika tidak ada arahan yang ditentukan.
- noindex: Memberitahu mesin pencari untuk tidak menampilkan halaman ini di hasil pencarian.
- follow: Memberi tahu mesin telusur untuk mengikuti semua tautan di halaman ini dan memberikan ekuitas, bahkan jika halaman tersebut tidak diindeks. Ini adalah status default jika tidak ada arahan yang ditentukan.
- nofollow: Memberitahu mesin pencari untuk tidak mengikuti tautan apa pun di halaman ini atau memberikan ekuitas.
- semua: Setara dengan "indeks, ikuti".
- none: Setara dengan "noindex, nofollow".
- noimageindex: Memberi tahu mesin pencari untuk tidak mengindeks gambar apa pun di halaman ini.
- noarchive: Memberi tahu mesin telusur untuk tidak menampilkan tautan yang di-cache ke halaman ini di hasil penelusuran.
- nocache: Sama seperti noarchive, tetapi hanya digunakan oleh Internet Explorer dan Firefox.
- nosnippet: Memberi tahu mesin telusur untuk tidak menampilkan deskripsi meta atau pratinjau video untuk laman ini di hasil penelusuran.
- notranslate: Memberi tahu mesin pencari untuk tidak menawarkan terjemahan halaman ini dalam hasil pencarian.
- unavailable_after: Memberi tahu mesin telusur untuk tidak lagi mengindeks halaman ini setelah tanggal yang ditentukan.
- noodp: Sekarang tidak digunakan lagi, pernah mencegah mesin pencari menggunakan deskripsi halaman dari DMOZ di hasil pencarian.
- noydir: Sekarang tidak digunakan lagi, pernah mencegah Yahoo menggunakan deskripsi halaman dari direktori Yahoo di hasil pencarian.
- noyaca: Mencegah Yandex menggunakan deskripsi halaman dari direktori Yandex di hasil pencarian.
Seperti yang didokumentasikan oleh Yoast, tidak semua mesin pencari mendukung semua tag meta robot, atau bahkan jelas apa yang mereka lakukan dan tidak dukung.
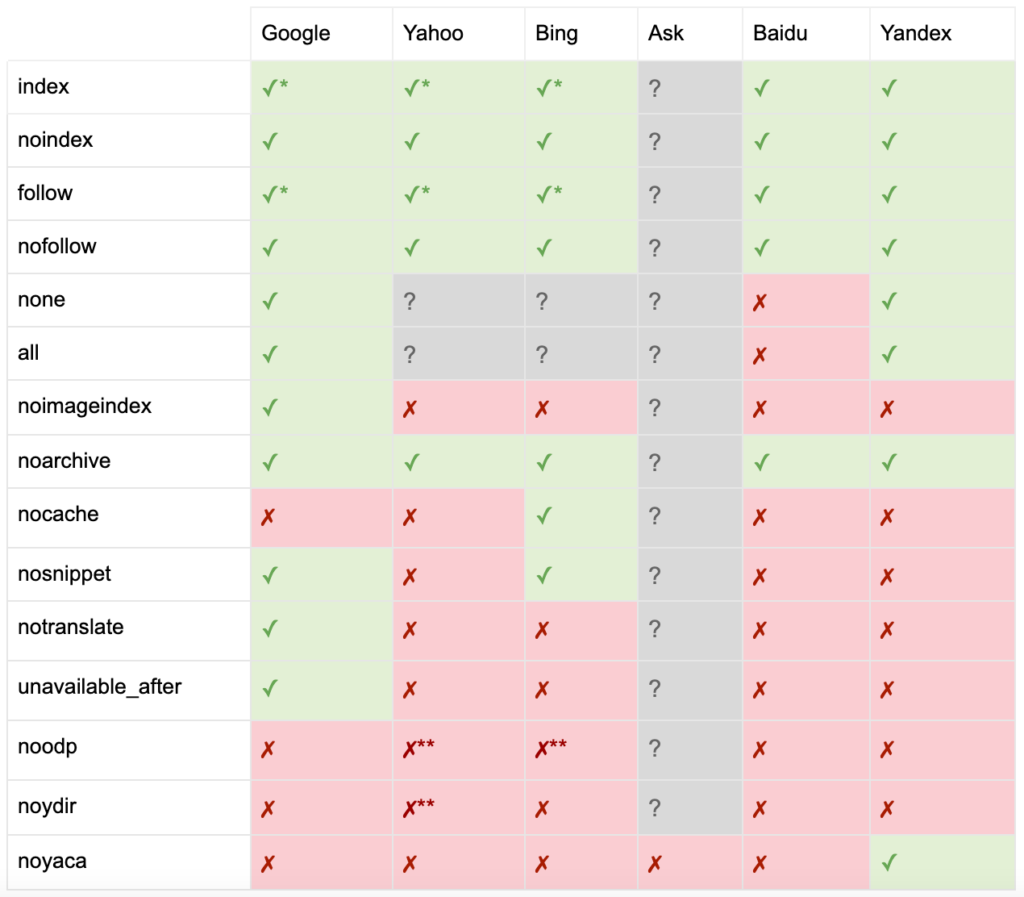
* Sebagian besar mesin pencari tidak memiliki dokumentasi khusus untuk ini, tetapi diasumsikan bahwa dukungan untuk mengecualikan parameter (misalnya, nofollow) menyiratkan dukungan untuk persamaan positif (misalnya, ikuti).
** Sementara atribut noodp dan noydir mungkin masih 'didukung', direktori tidak ada lagi, dan kemungkinan nilai-nilai ini tidak melakukan apa-apa.

Biasanya, tag robot akan disetel ke "indeks, ikuti". Beberapa SEO menganggap menambahkan tag ini dalam HTML sebagai hal yang berlebihan karena merupakan default. Argumen tandingannya adalah bahwa spesifikasi arahan yang jelas dapat membantu menghindari kebingungan manusia.
Perhatikan: URL dengan tag “noindex” akan lebih jarang dirayapi dan, jika ada untuk waktu yang lama, pada akhirnya akan mengarahkan Google untuk tidak mengikuti tautan halaman tersebut.
Jarang ditemukan kasus penggunaan untuk "nofollow" semua tautan di halaman dengan tag meta robots. Lebih umum melihat "nofollow" ditambahkan pada tautan individual menggunakan atribut tautan rel="nofollow". Misalnya, Anda mungkin ingin mempertimbangkan untuk menambahkan atribut rel="nofollow" ke komentar yang dibuat pengguna atau tautan berbayar.
Bahkan lebih jarang memiliki kasus penggunaan SEO untuk arahan tag robot yang tidak membahas pengindeksan dasar dan mengikuti perilaku, seperti caching, pengindeksan gambar dan penanganan cuplikan, dll.
Tantangan dengan tag meta robot adalah bahwa mereka tidak dapat digunakan untuk file non-HTML seperti gambar, video, atau dokumen PDF. Di sinilah Anda dapat beralih ke X-Robots-Tags.
Apa itu X-Robots-Tag
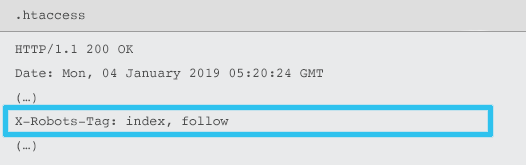
X-Robots-Tag dikirim oleh server sebagai elemen dari header respons HTTP untuk URL yang diberikan menggunakan file .htaccess dan httpd.conf.
Setiap arahan meta tag robot juga dapat ditetapkan sebagai X-Robots-Tag. Namun, X-Robots-Tag menawarkan beberapa fleksibilitas dan fungsionalitas tambahan di atas.
Anda akan menggunakan X-Robots-Tag di atas tag meta robots jika Anda ingin:
- Kontrol perilaku robot untuk file non-HTML, bukan file HTML saja.
- Kontrol pengindeksan elemen halaman tertentu, bukan halaman secara keseluruhan.
- Tambahkan aturan apakah halaman harus diindeks atau tidak. Misalnya, jika seorang penulis memiliki lebih dari 5 artikel yang diterbitkan, indeks halaman profil mereka.
- Terapkan indeks & ikuti arahan di tingkat seluruh situs, bukan khusus halaman.
- Gunakan ekspresi reguler.
Hindari menggunakan kedua robot meta dan tag x-robots pada halaman yang sama – hal itu akan sia-sia.
Untuk melihat X-Robots-Tags, Anda dapat menggunakan fitur “Fetch as Google” di Google Search Console.
Arahan Robot & SEO
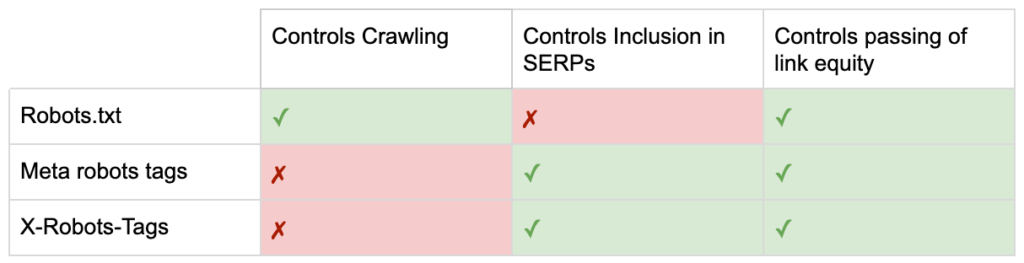
Jadi sekarang Anda tahu perbedaan antara ketiga arahan robot.
robots.txt berfokus pada penghematan anggaran perayapan, tetapi tidak akan mencegah halaman ditampilkan di hasil penelusuran. Ini bertindak sebagai penjaga gerbang pertama situs web Anda, mengarahkan bot untuk tidak mengakses sebelum halaman diminta.
Kedua jenis tag robot ini berfokus pada pengendalian pengindeksan dan penerusan ekuitas tautan. Tag meta robot hanya efektif setelah halaman dimuat . Sementara header X-Robots-Tag menawarkan kontrol yang lebih terperinci dan efektif setelah server merespons permintaan halaman.
Dengan pemahaman ini, SEO dapat mengembangkan cara kami menggunakan arahan robot untuk memecahkan tantangan perayapan dan pengindeksan.
Memblokir Bot untuk Menghemat Bandwidth Server
Masalah: Menganalisis file log Anda, Anda akan melihat banyak agen pengguna mengambil bandwidth tetapi memberikan sedikit nilai kembali.
- Perayap SEO, seperti MJ12bot (dari Majestic) atau Ahrefsbot (dari Ahrefs).
- Alat yang menyimpan konten digital secara offline, seperti Webcopier atau Teleport.
- Mesin pencari yang tidak relevan di pasar Anda, seperti Baiduspider atau Yandex.
Solusi sub-optimal: Memblokir laba-laba ini dengan robots.txt karena tidak dijamin akan dihormati dan merupakan pernyataan publik, yang dapat memberikan wawasan kompetitif kepada pihak yang berkepentingan.
Pendekatan praktik terbaik: Arahan pemblokiran agen pengguna yang lebih halus. Ini dapat dilakukan dengan berbagai cara, tetapi biasanya dilakukan dengan mengedit file .htaccess Anda untuk mengarahkan permintaan spider yang tidak diinginkan ke halaman 403 – Terlarang.
Halaman Pencarian Situs Internal Menggunakan Anggaran Perayapan
Masalah: Di banyak situs web, halaman hasil pencarian situs internal dibuat secara dinamis pada URL statis, yang kemudian menghabiskan anggaran perayapan dan dapat menyebabkan konten tipis atau masalah duplikat konten jika diindeks.
Solusi sub-optimal: Larang direktori dengan robots.txt. Meskipun ini dapat mencegah jebakan perayap, ini membatasi kemampuan Anda untuk menentukan peringkat untuk pencarian pelanggan utama dan untuk halaman tersebut untuk melewati ekuitas tautan.
Pendekatan praktik terbaik: Memetakan kueri volume tinggi yang relevan ke URL ramah mesin telusur yang ada. Misalnya, jika saya mencari "ponsel samsung", daripada membuat halaman baru untuk /search/samsung-phone, alihkan ke /phones/samsung.
Jika tidak memungkinkan, buat URL berbasis parameter. Anda kemudian dapat dengan mudah menentukan apakah Anda ingin parameter dirayapi atau tidak di dalam Google Search Console.
Jika Anda mengizinkan perayapan, analisis apakah halaman tersebut memiliki kualitas yang cukup tinggi untuk diberi peringkat. Jika tidak, tambahkan arahan “noindex, follow” sebagai solusi jangka pendek saat Anda menyusun strategi bagaimana meningkatkan kualitas hasil untuk membantu SEO dan pengalaman pengguna.
Memblokir Parameter dengan Robot
Masalah: Parameter string kueri, seperti yang dihasilkan oleh navigasi atau pelacakan segi, terkenal menghabiskan anggaran perayapan, membuat URL konten duplikat, dan memisahkan sinyal peringkat.
Solusi suboptimal: Larang perayapan parameter dengan robots.txt atau dengan tag meta robot “noindex”, karena keduanya (yang pertama segera, kemudian dalam jangka waktu yang lebih lama) akan mencegah aliran ekuitas tautan.
Pendekatan praktik terbaik: Pastikan setiap parameter memiliki alasan yang jelas untuk ada dan menerapkan aturan pemesanan, yang menggunakan kunci hanya sekali dan mencegah nilai kosong. Tambahkan atribut tautan rel=canonical ke halaman parameter yang sesuai untuk menggabungkan kemampuan peringkat. Kemudian konfigurasikan semua parameter di Google Search Console, di mana terdapat opsi yang lebih terperinci untuk mengomunikasikan preferensi perayapan. Untuk detail selengkapnya, lihat panduan penanganan parameter Jurnal Mesin Pencari.
Memblokir Admin atau Area Akun
Masalah: Mencegah mesin telusur merayapi dan mengindeks konten pribadi apa pun.
Solusi sub-optimal: Menggunakan robots.txt untuk memblokir direktori karena ini tidak dijamin untuk menjaga halaman pribadi keluar dari SERP.
Pendekatan praktik terbaik: Gunakan perlindungan kata sandi untuk mencegah perayap mengakses halaman dan mundur dari arahan "noindex" di header HTTP.
Memblokir Halaman Arahan Pemasaran & Halaman Terima Kasih
Masalah: Seringkali Anda perlu mengecualikan URL yang tidak dimaksudkan untuk pencarian organik, seperti email khusus atau halaman arahan kampanye BPK. Sama halnya, Anda tidak ingin orang yang belum berkonversi mengunjungi halaman terima kasih Anda melalui SERP.
Solusi sub-optimal: Larang file dengan robots.txt karena ini tidak akan mencegah tautan disertakan dalam hasil pencarian.
Pendekatan praktik terbaik: Gunakan tag meta “noindex”.
Kelola Konten Duplikat Di Tempat
Masalah: Beberapa situs web memerlukan salinan konten tertentu untuk alasan pengalaman pengguna, seperti versi halaman yang ramah printer, tetapi ingin memastikan halaman kanonik, bukan halaman duplikat, dikenali oleh mesin telusur. Di situs web lain, konten duplikat disebabkan oleh praktik pengembangan yang buruk, seperti merender item yang sama untuk dijual di beberapa URL kategori.
Solusi suboptimal: Melarang URL dengan robots.txt akan mencegah halaman duplikat meneruskan sinyal peringkat apa pun. Noindexing untuk robot, pada akhirnya akan menyebabkan Google memperlakukan tautan sebagai "nofollow" juga, akan mencegah halaman duplikat melewati ekuitas tautan apa pun.
Pendekatan praktik terbaik: Jika konten duplikat tidak memiliki alasan untuk ada, hapus sumber dan 301 redirect ke URL ramah mesin pencari. Jika ada alasan untuk ada, tambahkan atribut tautan rel=canonical untuk mengkonsolidasikan sinyal peringkat.
Konten Tipis dari Halaman Terkait Akun yang Dapat Diakses
Masalah: Halaman terkait akun seperti login, daftar, keranjang belanja, checkout, atau formulir kontak, seringkali kontennya ringan dan menawarkan sedikit nilai bagi mesin telusur, tetapi penting bagi pengguna.
Solusi sub-optimal: Larang file dengan robots.txt karena ini tidak akan mencegah tautan disertakan dalam hasil pencarian.
Pendekatan praktik terbaik: Untuk sebagian besar situs web, jumlah halaman ini seharusnya sangat sedikit dan Anda mungkin tidak melihat dampak KPI dari penerapan penanganan robot. Jika Anda merasa perlu, sebaiknya gunakan arahan "noindex", kecuali jika ada permintaan pencarian untuk halaman tersebut.
Tag Halaman Menggunakan Anggaran Perayapan
Masalah: Pemberian tag yang tidak terkontrol menghabiskan anggaran perayapan dan sering kali menyebabkan masalah konten yang tipis.
Solusi sub-optimal: Melarang dengan robots.txt atau menambahkan tag “noindex”, karena keduanya akan menghalangi tag yang relevan dengan SEO dari peringkat dan (segera atau akhirnya) mencegah berlalunya ekuitas tautan.
Pendekatan praktik terbaik: Nilai nilai setiap tag Anda saat ini. Jika data menunjukkan halaman menambahkan sedikit nilai ke mesin pencari atau pengguna, 301 redirect mereka. Untuk halaman yang selamat dari pemusnahan, bekerjalah untuk meningkatkan elemen di halaman sehingga menjadi berharga bagi pengguna dan bot.
Perayapan JavaScript & CSS
Masalah: Sebelumnya, bot tidak dapat merayapi JavaScript dan konten media kaya lainnya. Itu berubah dan sekarang sangat disarankan untuk mengizinkan mesin pencari mengakses file JS dan CSS untuk merender halaman secara opsional.
Solusi kurang optimal: Melarang file JavaScript dan CSS dengan robots.txt untuk menghemat anggaran perayapan dapat mengakibatkan pengindeksan yang buruk dan berdampak negatif pada peringkat. Misalnya, memblokir akses mesin telusur ke JavaScript yang menayangkan interstisial iklan atau mengalihkan pengguna dapat dianggap sebagai penyelubungan.
Pendekatan praktik terbaik: Periksa masalah rendering apa pun dengan alat "Ambil sebagai Google" atau dapatkan ikhtisar singkat tentang sumber daya apa yang diblokir dengan laporan "Sumber Daya yang Diblokir", keduanya tersedia di Google Search Console. Jika ada sumber daya yang diblokir yang dapat mencegah mesin telusur merender halaman dengan benar, hapus larangan robots.txt.
Perayap SEO Oncrawl
 Belajarlah lagi
Belajarlah lagiDaftar Periksa Robot Praktik Terbaik
Sangat umum bagi sebuah situs web untuk secara tidak sengaja dihapus dari Google oleh kesalahan pengontrolan robot.
Namun demikian, penanganan robot dapat menjadi tambahan yang kuat untuk gudang SEO Anda ketika Anda tahu cara menggunakannya. Pastikan untuk melanjutkan dengan bijak dan hati-hati.
Untuk membantu, berikut adalah daftar periksa singkat:
- Amankan informasi pribadi dengan menggunakan proteksi kata sandi
- Blokir akses ke situs pengembangan dengan menggunakan otentikasi sisi server
- Batasi perayap yang menggunakan bandwidth tetapi menawarkan sedikit nilai kembali dengan pemblokiran agen pengguna
- Pastikan domain utama dan subdomain apa pun memiliki file teks bernama "robots.txt" di direktori tingkat atas yang mengembalikan kode 200
- Pastikan file robots.txt memiliki setidaknya satu blok dengan baris agen pengguna dan baris larangan
- Pastikan file robots.txt memiliki setidaknya satu baris peta situs, dimasukkan sebagai baris terakhir
- Validasi file robots.txt di penguji robots.txt GSC
- Pastikan setiap halaman yang dapat diindeks menentukan arahan tag robotnya
- Pastikan tidak ada arahan yang kontradiktif atau berlebihan antara robots.txt, tag meta robot, X-Robots-Tags, file .htaccess, dan penanganan parameter GSC
- Perbaiki kesalahan "URL yang dikirim bertanda 'noindex'" atau "URL yang dikirim diblokir oleh robots.txt" dalam laporan cakupan GSC
- Pahami alasan pengecualian terkait robot apa pun dalam laporan cakupan GSC
- Pastikan hanya halaman yang relevan yang ditampilkan dalam laporan "Sumber Daya yang Diblokir" GSC
Periksa penanganan robot Anda dan pastikan Anda melakukannya dengan benar.