
10 Masalah Umum Teknis SEO – dan cara menemukannya
Diterbitkan: 2019-06-04Setelah melakukan layanan SEO di berbagai industri, terkadang Anda dapat memahami masalah umum terutama saat mengerjakan CMS umum seperti WordPress, Shopify, atau SquareSpace.
Di sini saya telah menguraikan 10 masalah SEO teknis yang cukup umum yang mungkin Anda temui saat mengoptimalkan situs web.
Saya tidak mengatakan bahwa masalah ini pasti akan menjadi masalah bagi Anda atau klien Anda – seringkali konteks masih sangat penting. Tidak selalu ada satu ukuran yang cocok untuk semua solusi tetapi mungkin masih baik untuk berhati-hati dengan skenario yang diuraikan di bawah ini.
1 – File robots.txt memblokir akses ke Googlebot
Ini bukan hal baru bagi sebagian besar SEO teknis, tetapi masih sangat mudah untuk mengabaikan pemeriksaan file robots – dan tidak hanya pada saat menjalankan audit teknis, tetapi sebagai pemeriksaan berulang.
Anda dapat menggunakan alat seperti Search Console (versi lama) untuk meninjau apakah Google memiliki masalah akses, atau Anda dapat mencoba merayapi situs Anda sebagai Googlebot dengan alat seperti OnCrawl (cukup pilih Agen Pengguna mereka). OnCrawl akan mematuhi robots.txt kecuali jika Anda mengatakan sebaliknya.
Ekspor hasil perayapan dan bandingkan dengan daftar halaman yang diketahui di situs Anda dan periksa tidak ada titik buta perayap.
Untuk menunjukkan bahwa ini masih sering terjadi, dan untuk beberapa situs yang cukup besar, beberapa minggu yang lalu saya melihat alat Tes Kecepatan Pingdom diblokir di dalam Google.
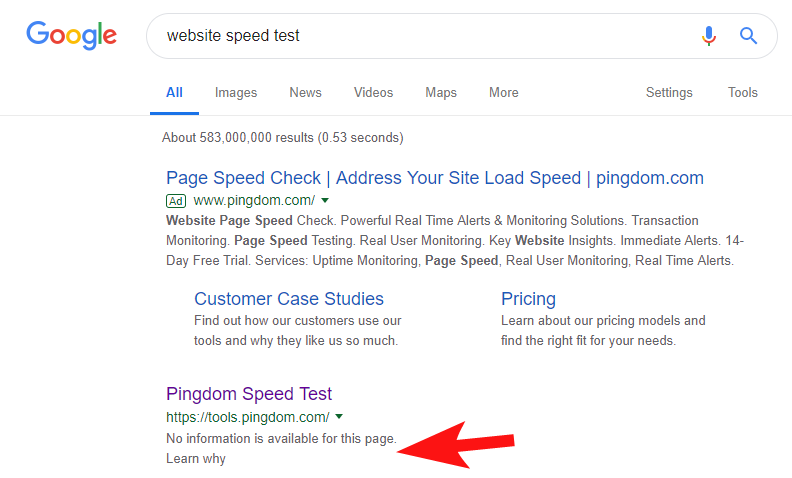
Melihat file robots mereka (dan kemudian mencoba merayapi halaman mereka dari OnCrawl sebagai Googlebot) mengkonfirmasi kecurigaan saya bahwa mereka memblokir akses ke situs mereka.
File robots.txt yang bersalah ditunjukkan di bawah ini:

Saya menghubungi mereka dengan "FYI" tetapi tidak ada tanggapan, tetapi kemudian beberapa hari kemudian melihat bahwa semuanya kembali normal. Fiuh – saya bisa tidur dengan mudah lagi!
Dalam kasus mereka, tampaknya setiap kali Anda memindai situs Anda sebagai bagian dari audit kecepatan mereka, itu membuat URL termasuk karakter hash yang disorot dalam file robot di atas.
Mungkin ini dirayapi dan bahkan diindeks entah bagaimana, dan mereka ingin mengendalikannya (yang akan sangat bisa dimengerti). Dalam hal ini mereka mungkin tidak sepenuhnya menguji potensi dampak – yang kemungkinan kecil pada akhirnya.
Inilah robot mereka saat ini untuk siapa saja yang tertarik.

Perlu dicatat bahwa dalam beberapa kasus Anda dapat mengakses perubahan file robots.txt bersejarah menggunakan Internet Wayback Machine. Dari pengalaman saya, ini berfungsi paling baik di situs yang lebih besar seperti yang dapat Anda bayangkan – mereka jauh lebih sering dirayapi oleh pengarsip Wayback Machine.
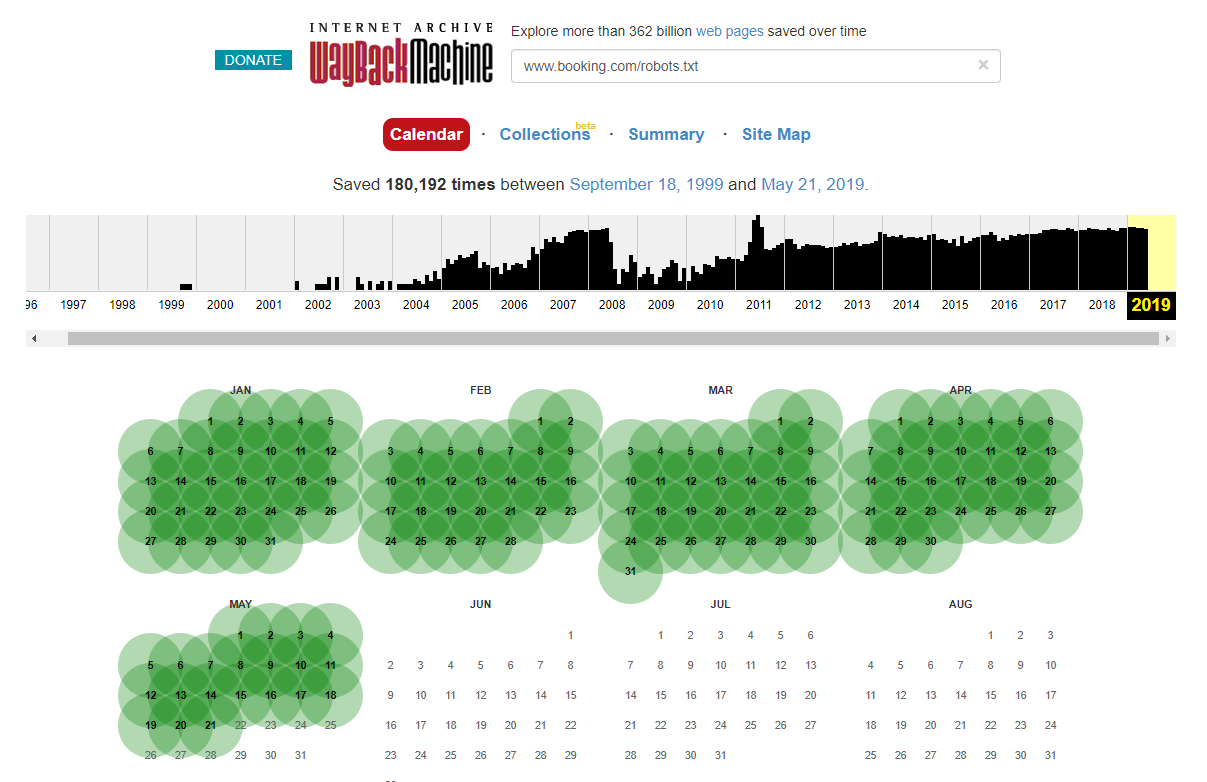
Ini bukan pertama kalinya saya melihat robots.txt hidup di alam liar menyebabkan sedikit kekacauan di SERP. Dan itu pasti tidak akan menjadi yang terakhir – itu adalah hal yang sederhana untuk diabaikan (ini benar-benar satu file) tetapi memeriksanya harus menjadi bagian dari jadwal kerja setiap SEO yang sedang berlangsung.
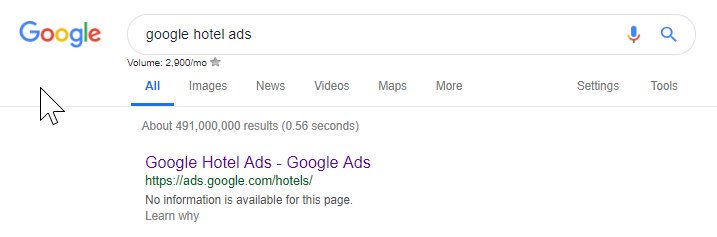
Dari atas Anda dapat melihat bahwa bahkan Google terkadang mengacaukan file robot mereka, memblokir diri mereka sendiri untuk mengakses konten mereka. Ini bisa saja disengaja tetapi melihat bahasa file robot mereka di bawah ini entah bagaimana saya meragukannya.
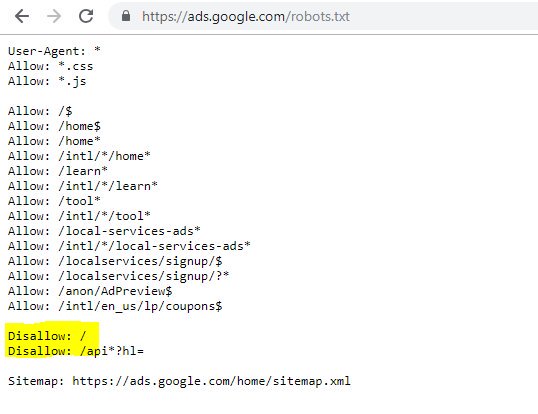
Disallow yang disorot: / dalam hal ini mencegah akses ke jalur URL apa pun; akan lebih aman untuk membuat daftar bagian tertentu dari situs yang seharusnya tidak dirayapi.
2 – Masalah Konfigurasi Domain di Tingkat DNS
Ini adalah salah satu yang sangat umum tetapi biasanya ini adalah perbaikan cepat. Ini adalah salah satu dari perubahan SEO berbiaya rendah, *berpotensi* berdampak tinggi yang disukai oleh SEO teknis.
Seringkali dengan implementasi SSL saya gagal melihat versi domain non-WWW dikonfigurasi dengan benar, seperti 302 mengarahkan ulang ke URL berikutnya dan membentuk rantai, atau skenario terburuk tidak memuat sama sekali.
Contoh yang bagus di sini adalah situs web Hotel Football.
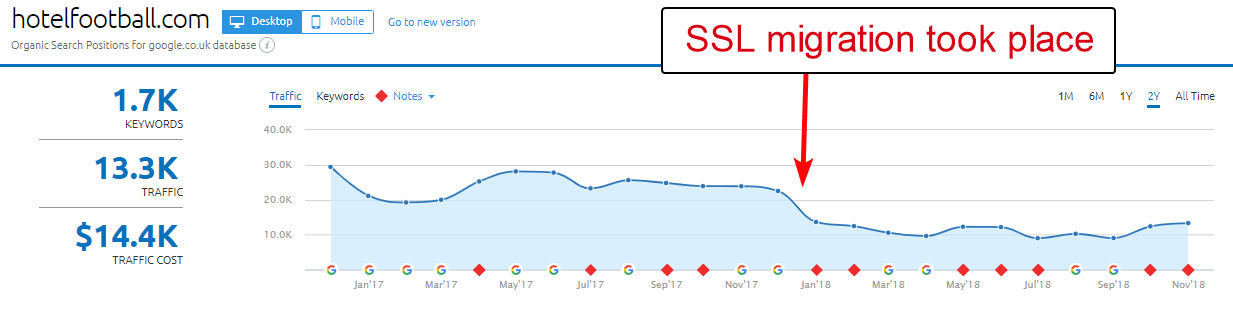
Mereka menjalani migrasi SSL awal tahun lalu, yang tidak berjalan dengan baik bagi mereka dilihat dari laporan ikhtisar domain SEMRush di atas.
Saya telah memperhatikan yang satu ini beberapa waktu lalu karena saya telah banyak bekerja dalam industri perjalanan dan perhotelan – dan dengan kecintaan yang besar pada sepak bola, saya tertarik untuk melihat seperti apa situs web mereka (ditambah bagaimana kinerjanya secara organik tentu saja! ).
Ini sebenarnya sangat mudah untuk didiagnosis – situs tersebut memiliki banyak sekali backlink yang sangat bagus, semuanya mengarah ke domain WWW non-SSL di http://www.hotelfootball.com/
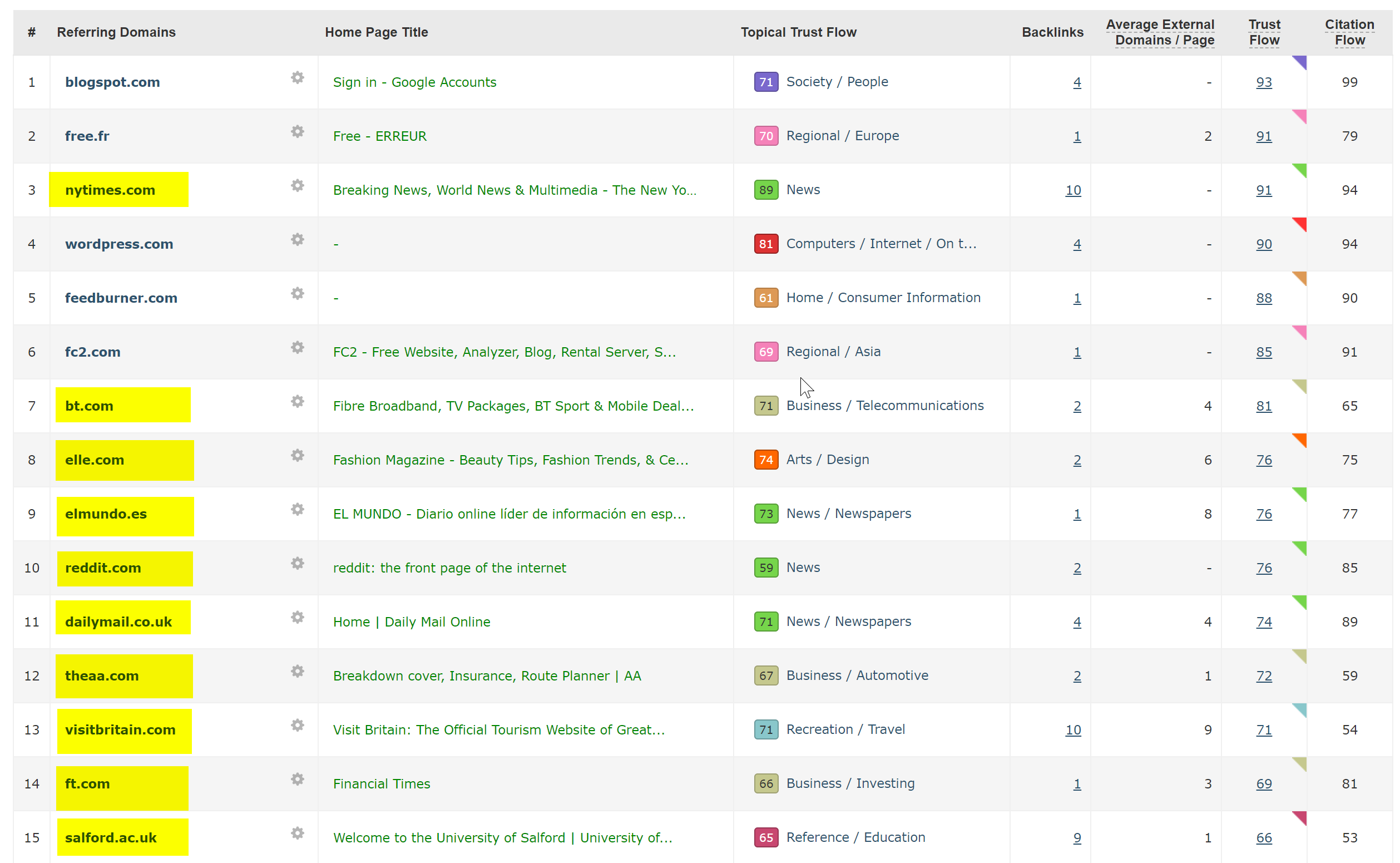
Jika Anda mencoba mengakses URL di atas, itu tidak dimuat. Ups. Dan sudah seperti ini selama sekitar 18 bulan sekarang, setidaknya. Saya menghubungi agensi yang mengelola situs melalui Twitter untuk memberi tahu mereka tentang hal itu tetapi tidak ada tanggapan.
Dengan yang satu ini yang perlu mereka lakukan adalah memastikan pengaturan zona DNS sudah benar, dengan catatan "A" untuk versi domain "WWW", yang menunjuk ke alamat IP yang benar (CNAME juga akan berfungsi). Ini akan mencegah domain dari tidak menyelesaikan.
Satu-satunya downside, atau alasan yang satu ini membutuhkan waktu lama untuk diselesaikan, adalah sulitnya mendapatkan akses ke panel manajemen domain situs, atau bahkan kata sandi telah hilang, atau tidak dianggap sebagai prioritas tinggi.
Mengirim instruksi untuk diperbaiki ke orang non-teknisi yang memegang kunci nama domain juga tidak selalu merupakan ide yang bagus.
Saya akan sangat tertarik untuk melihat dampak organik jika/ketika mereka dapat melakukan penyesuaian di atas – terutama mengingat semua backlink yang telah dibangun oleh domain non WWW sejak hotel ini diluncurkan oleh mantan pemain sepak bola Manchester United Gary Neville, Ryan Giggs dan perusahaan.
Meskipun mereka menempati peringkat #1 di Google untuk nama hotel mereka (seperti yang Anda bayangkan), mereka tampaknya tidak memiliki peringkat yang kuat sama sekali untuk istilah pencarian non-merek yang lebih kompetitif (saat ini mereka berada di posisi 10 di Google untuk "hotel dekat Old Trafford").
Mereka mencetak sedikit gol bunuh diri dengan hal di atas – tetapi memperbaiki masalah ini setidaknya bisa menyelesaikannya.
Perayap SEO Oncrawl
 Belajarlah lagi
Belajarlah lagi3 – Halaman Rogue dalam Peta Situs XML
Sekali lagi ini adalah salah satu yang cukup mendasar tetapi anehnya umum – setelah meninjau peta situs XML situs (yang hampir selalu di domain.com/sitemap.xml atau domain.com/sitemap_index.xml, mungkin ada halaman yang terdaftar di sini yang benar-benar tidak 'tidak perlu diindeks.
Penyebab umum termasuk halaman terima kasih yang tersembunyi (terima kasih telah mengirimkan formulir kontak), halaman arahan PPC yang mungkin menyebabkan masalah konten duplikat, atau bentuk halaman/postingan/taksonomi lain yang telah Anda noindex di tempat lain.
Memasukkannya lagi ke dalam peta situs XML dapat mengirimkan sinyal yang bertentangan ke mesin telusur – Anda seharusnya hanya mencantumkan halaman yang Anda ingin mereka temukan dan indeks, yang terutama merupakan inti dari peta situs.
Sekarang Anda dapat menggunakan laporan praktis dalam Search Console untuk mengetahui apakah halaman telah atau belum disertakan dalam peta situs XML situs melalui opsi Periksa URL.
Jika Anda memiliki situs yang cukup kecil, Anda mungkin dapat meninjau peta situs XML secara manual di dalam browser Anda – jika tidak, unduh dan bandingkan dengan perayapan penuh dari URL Anda yang dapat diindeks.
Seringkali Anda dapat menangkap konten berkualitas rendah dan tak ternilai semacam ini dengan melakukan pencarian site:domain.com di Google untuk mengembalikan semua yang telah diindeks.
Perlu dicatat di sini bahwa ini dapat berisi konten lama dan tidak boleh diandalkan 100% up-to-date, tetapi ini adalah pemeriksaan yang mudah untuk memastikan tidak ada muatan kapal yang membebani upaya SEO Anda dan menghabiskan anggaran perayapan.
4 – Masalah dengan Googlebot Rendering Konten Anda
Yang ini layak untuk seluruh artikel yang didedikasikan untuk itu, dan saya pribadi merasa seperti saya telah menghabiskan seumur hidup bermain dengan alat ambil dan render Google.
Banyak yang telah dikatakan tentang ini (dan tentang JavaScript) oleh beberapa SEO yang sangat cakap, jadi saya tidak akan menyelidiki ini terlalu dalam, tetapi memeriksa bagaimana Googlebot merender situs Anda akan selalu sepadan dengan waktu Anda.
Menjalankan beberapa pemeriksaan melalui alat online dapat membantu mengungkap blindspot Googlebot (area di situs yang tidak dapat mereka akses), masalah dengan lingkungan hosting Anda, sumber daya yang terbakar JavaScript yang bermasalah, dan bahkan masalah penskalaan layar.
Biasanya alat pihak ketiga ini cukup membantu dalam mendiagnosis masalah (Google bahkan memberi tahu Anda ketika sumber daya diblokir karena file robot Anda misalnya) tetapi terkadang Anda mungkin menemukan diri Anda berputar-putar.
Untuk menunjukkan contoh langsung dari situs bermasalah, saya akan menembak diri saya sendiri dan merujuk ke situs web pribadi saya – dan tema WordPress yang saya gunakan membuat frustrasi.
Terkadang saat menjalankan Inspeksi URL dari Search Console, saya mendapatkan peringatan “Halaman tidak ramah seluler” (lihat di bawah).
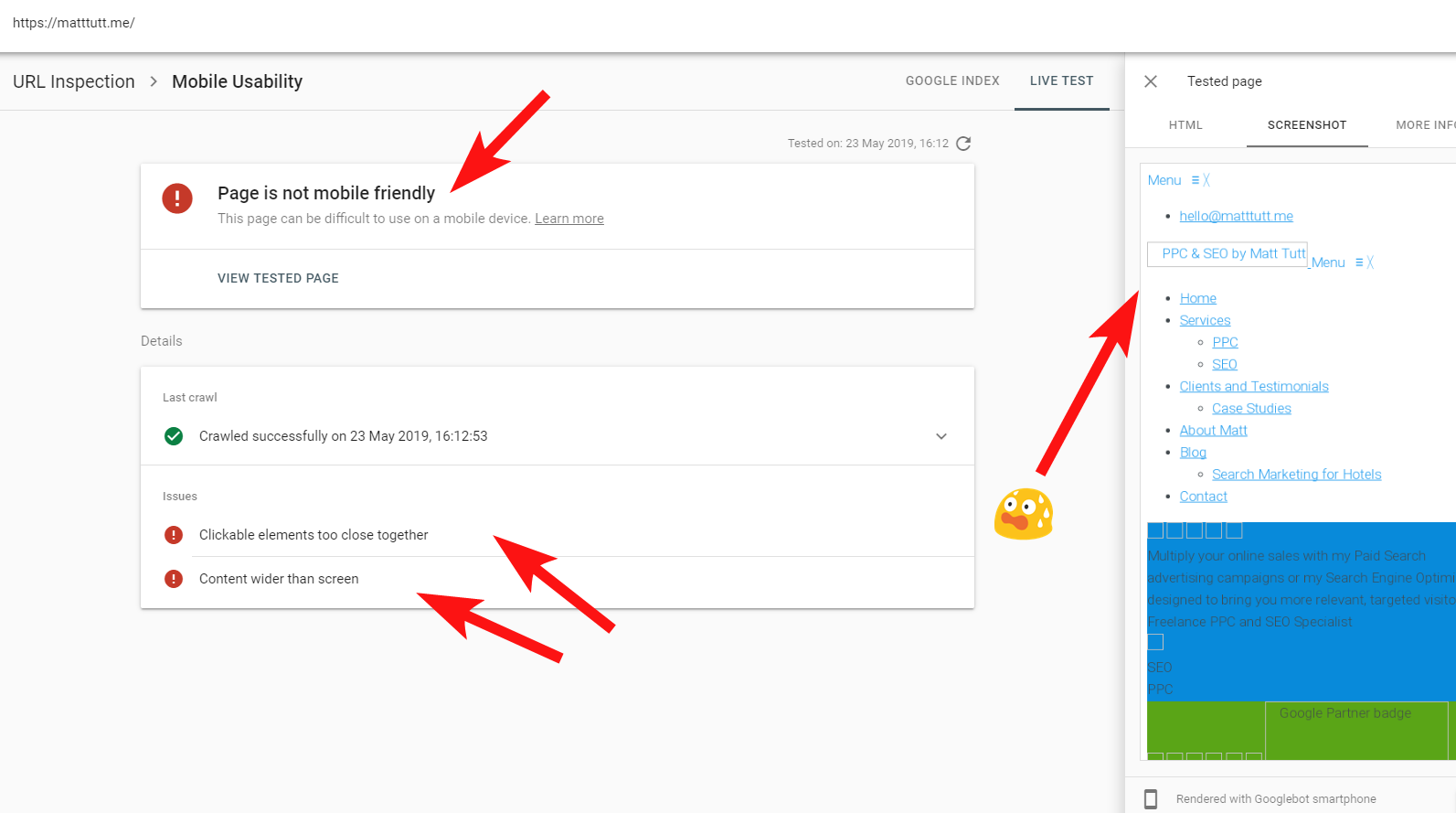
Dari mengklik tab More Info (kanan atas) memberikan daftar sumber daya yang tidak dapat diakses kemudian oleh Googlebot yang terutama CSS dan file gambar.
Ini kemungkinan karena Googlebot tidak selalu dapat memberikan "energi" penuhnya untuk merender halaman – terkadang karena Google waspada terhadap kerusakan situs saya (yang semacam itu), dan di lain waktu saya mungkin dibatasi karena mereka telah menggunakan banyak sumber daya untuk mengambil dan merender situs saya.
Terkadang karena hal di atas, ada baiknya menjalankan tes ini beberapa kali pada interval yang tersebar untuk mendapatkan cerita yang lebih benar. Saya juga merekomendasikan untuk memeriksa log server jika Anda bisa, untuk memeriksa bagaimana Googlebot mengakses (atau tidak mengakses) konten situs Anda.
404 atau status buruk lainnya untuk sumber daya ini jelas akan menjadi pertanda buruk, terutama jika konsisten.
Dalam kasus saya, Google memanggil situs tersebut karena tidak ramah seluler yang terutama disebabkan oleh file gaya CSS tertentu yang gagal selama render, yang dapat membunyikan lonceng alarm dengan benar.
Untuk membuat masalah lebih membingungkan, saat menjalankan Tes Ramah Seluler oleh Google, atau saat menggunakan alat pihak ketiga lainnya, tidak ada masalah yang terdeteksi: situs ini ramah seluler.
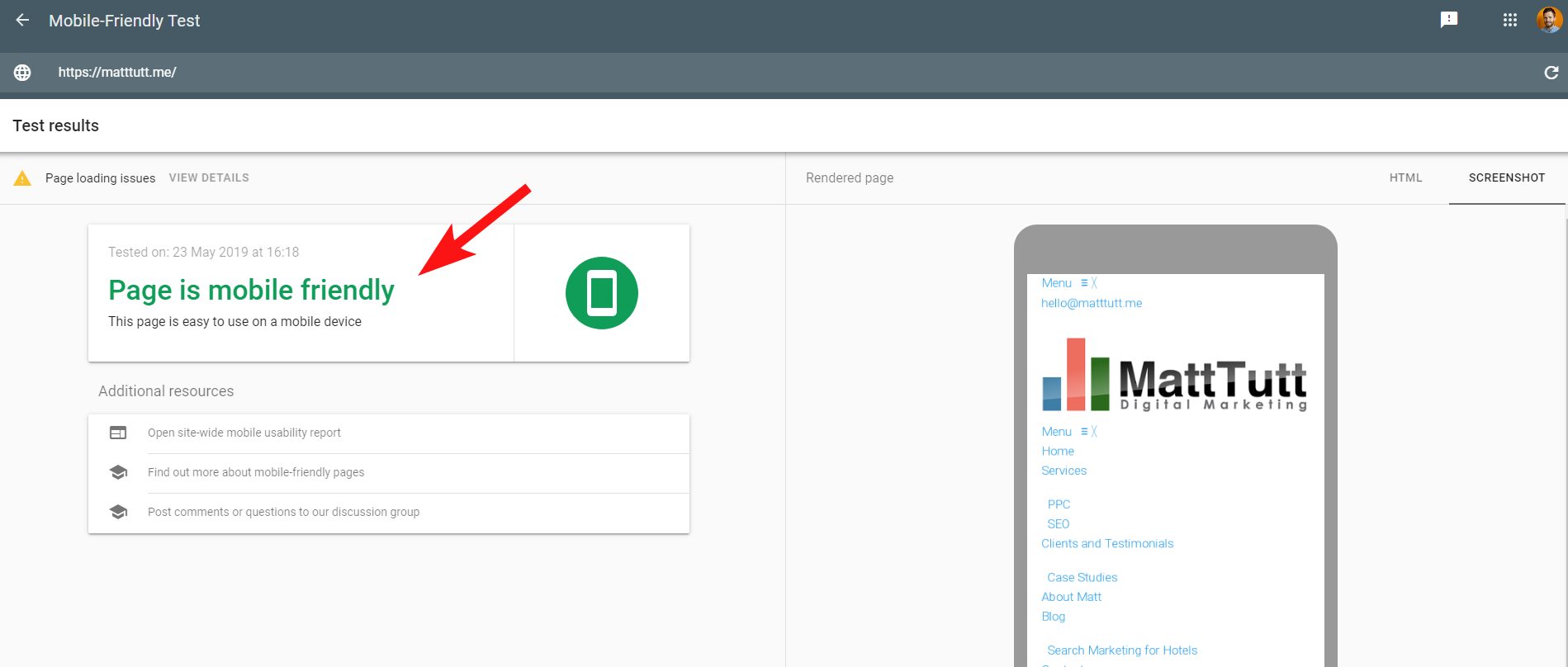
Pesan-pesan yang saling bertentangan ini dari Google dapat menjadi rumit bagi SEO dan pengembang web untuk memecahkan kode. Untuk memahami lebih jauh, saya menghubungi John Mueller yang menyarankan agar saya memeriksa host web saya (tidak ada masalah) dan bahwa file CSS memang dapat di-cache oleh Google.
Search Console menggunakan Layanan Rendering Web (WRS) yang lebih lama dibandingkan dengan Alat Ramah Seluler, jadi saat ini saya cenderung memberi bobot lebih pada yang terakhir.
Dengan Google mengumumkan Googlebot yang lebih baru dengan kemampuan rendering terbaru, ini semua dapat diatur untuk berubah, jadi ada baiknya terus mengikuti perkembangan alat mana yang terbaik untuk digunakan untuk pemeriksaan rendering.
Kiat lain di sini – jika Anda ingin melihat render halaman yang dapat digulir penuh, Anda dapat beralih ke tab HTML dari alat pengujian seluler Google, tekan CTRL+A untuk menyorot semua kode HTML yang dirender, lalu salin dan tempel ke editor teks dan simpan sebagai file HTML.
Membukanya di browser Anda (semoga saja, terkadang tergantung pada CMS yang digunakan!) akan memberi Anda render yang dapat digulir. Dan keuntungannya adalah Anda dapat memeriksa bagaimana setiap situs dirender – Anda tidak memerlukan akses Search Console.
5 – Situs yang Diretas dan Tautan Balik Spam
Ini cukup menyenangkan untuk ditangkap dan seringkali dapat menyelinap di situs yang berjalan pada versi WordPress yang lebih lama atau platform CMS lain yang memerlukan pembaruan keamanan rutin.
Dengan klien ini (spa kecantikan), saya melihat beberapa istilah pencarian aneh muncul di Search Console.
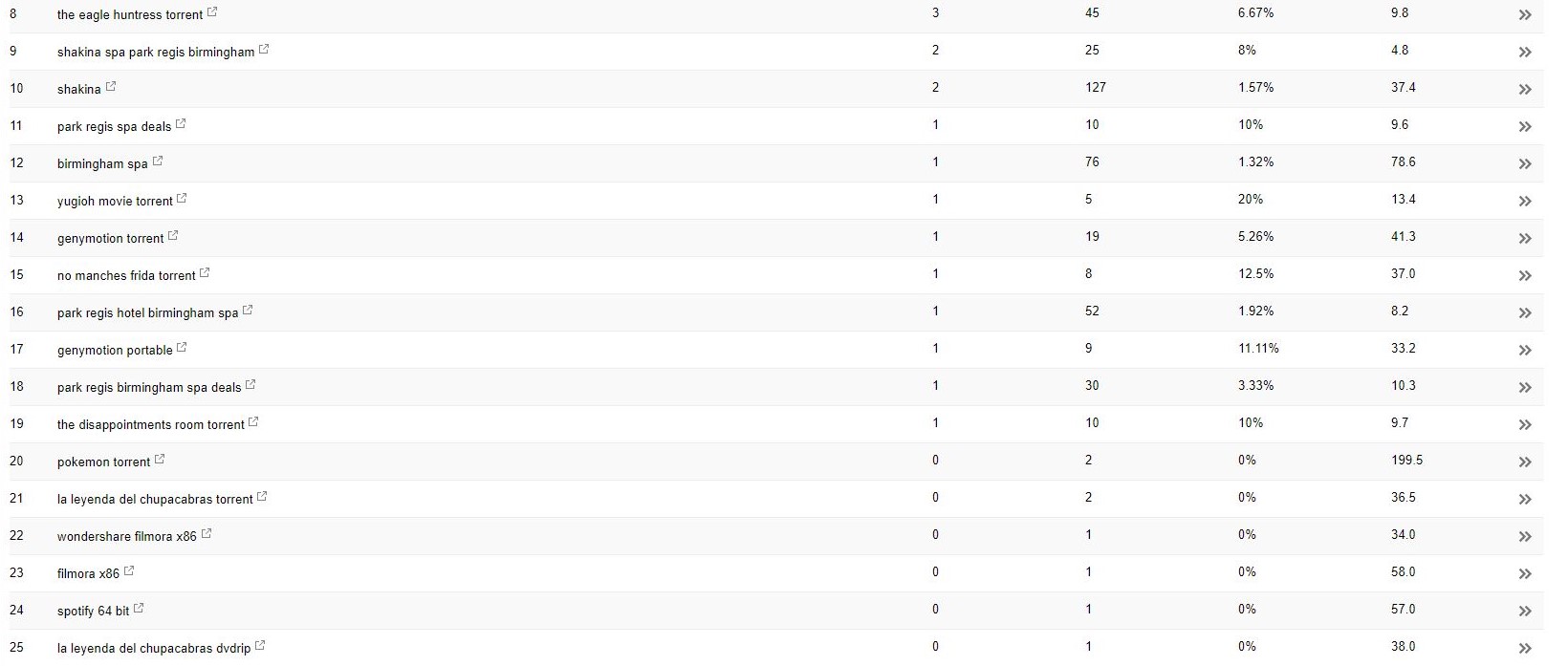
Anehnya, mereka tidak hanya memiliki tayangan di Search Console tetapi juga Klik – artinya pasti ada sesuatu yang diindeks di domain tersebut.
Dilihat dari pertanyaannya, itu jelas sangat berisi spam, dan bukan sesuatu yang diinginkan klien untuk dikaitkan dengan bisnis mereka.
Melakukan pencarian sederhana “site:domain.com” di Google menemukan ratusan halaman torrent yang seharusnya dihosting oleh klien di situs mereka.
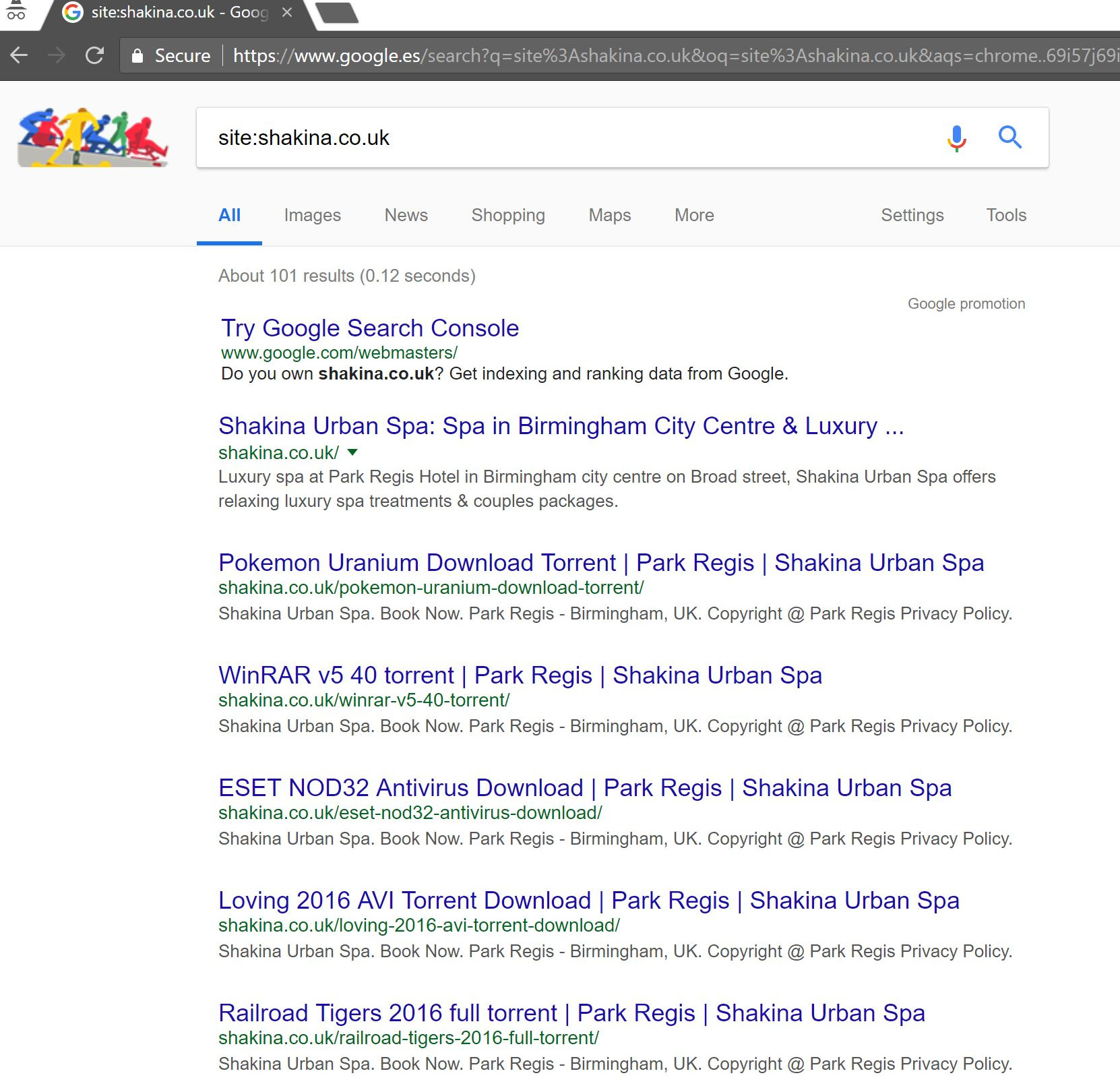
Mengunjungi salah satu dari URL tersebut sebenarnya menghasilkan 404 – namun mereka masih diindeks (Saya juga memeriksa berbagai Agen Pengguna dan semuanya mendapatkan kesalahan 404) yang sama).
Selanjutnya saya menjalankan domain melalui pemeriksa backlink Majestic dan itu memberikan daftar panjang tautan balik berkualitas sangat rendah yang menunjuk ke halaman-halaman ini di situs klien – yang kemungkinan membantu membuat mereka diindeks.
Melihat Majestic's Anchor Cloud dari backlink benar-benar menunjukkan sejauh mana masalahnya.


Satu-satunya perbaikan di sini adalah menolak semua tautan balik itu berdasarkan domain, dan kemudian menjalankan instalasi WordPress dengan harapan membersihkan injeksi kode apa pun, atau menginstal salinan WordPress baru.
Jika Anda benar-benar khawatir tentang konten yang diindeks dalam kasus seperti di atas, Anda juga dapat menyajikan kode status 410 untuk benar-benar memperjelas berbagai hal dengan perayap pencarian.
Hal di atas akan sesuai dengan situs yang telah diberikan peringatan hukum karena klaim hak cipta dari produser film – yang terkadang dapat terjadi dalam situasi seperti ini jika masalah tidak diselesaikan dengan cepat.
6 – Pengaturan SEO Internasional yang Buruk
Berbasis di Spanyol tetapi menjelajahi internet dalam bahasa Inggris asli saya, saya sering mendapati diri saya dialihkan secara otomatis ke situs web versi Spanyol.
Sementara saya memahami logikanya (saya berbasis di Spanyol oleh karena itu saya ingin menelusuri situs dalam bahasa Spanyol), itu cukup mengganggu dari perspektif pengalaman pengguna, dan jika tidak dilakukan dengan benar juga dapat menyebabkan sedikit kekacauan dengan SEO internasional Anda.
Situs seperti Google Ads membawa ini ke tingkat lain – memanfaatkan JavaScript Angular untuk menghasilkan konten secara dinamis berdasarkan lokasi saya, bahkan tidak melewati pengalihan halaman apa pun dan memuat konten langsung di DOM.
Metode pilihan pilihan saya ketika beberapa bahasa tersedia adalah dengan mengalihkan 302 pengguna ke bahasa berdasarkan pengaturan browser Internet mereka.
Oleh karena itu, jika seseorang menggunakan bahasa Jerman sebagai bahasa default di Google Chrome, mereka kemungkinan besar akan nyaman membaca situs dalam bahasa Jerman terlepas dari lokasi fisiknya.
Ini juga membantu mengatasi kesulitan ketika seseorang tinggal di wilayah di mana berbagai bahasa digunakan seperti di Swiss yang menggunakan bahasa Prancis, Italia, Jerman, dan Romansh.
Ini juga merupakan kunci untuk tujuan kegunaan untuk memastikan ada opsi untuk beralih bahasa berdasarkan preferensi Anda – untuk berjaga-jaga jika mereka ingin beralih.
Dalam satu kasus saya bekerja dengan sebuah hotel yang berbasis di Barcelona, di mana skrip pengalihan bahasa JavaScript ditambahkan ke situs tanpa mempertimbangkan dampak SEO.
Skrip ini mengarahkan pengguna berdasarkan pengaturan bahasa browser mereka (yang sebenarnya tidak terlalu buruk) melalui pengalihan JavaScript sisi klien.
Sayangnya dalam kasus ini skrip tidak diatur dengan benar karena konfigurasi aneh dari tautan permanen situs, dan ketika digabungkan dengan fakta bahwa tag lang HTML hilang dari semua halaman di situs, Googlebot menjadi sedikit gila…
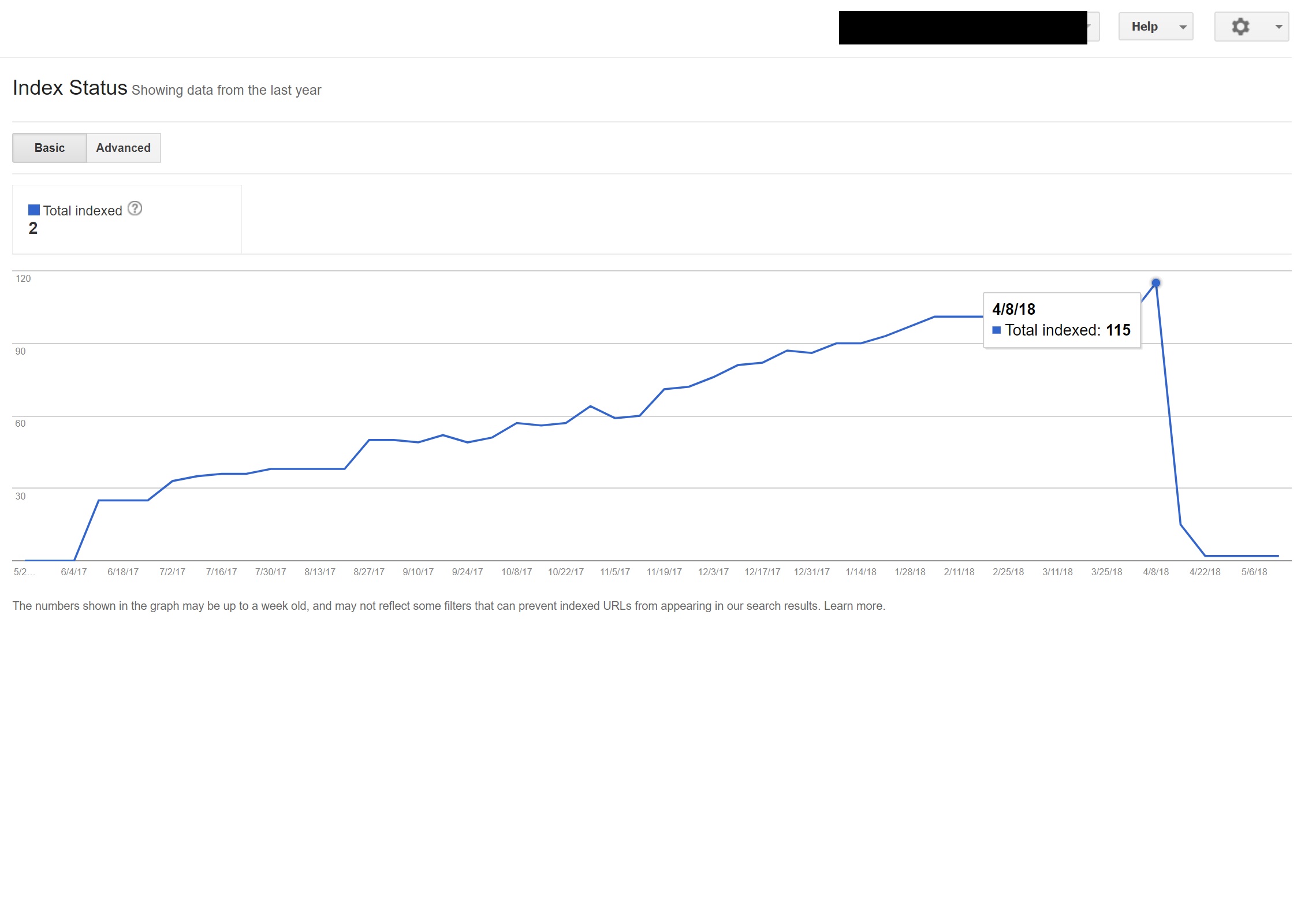
Dalam contoh ini, hampir semua konten non-bahasa Inggris di situs telah dideindeks oleh Google, karena dialihkan ke halaman yang tidak ada, sehingga menyajikan beberapa kesalahan 404.
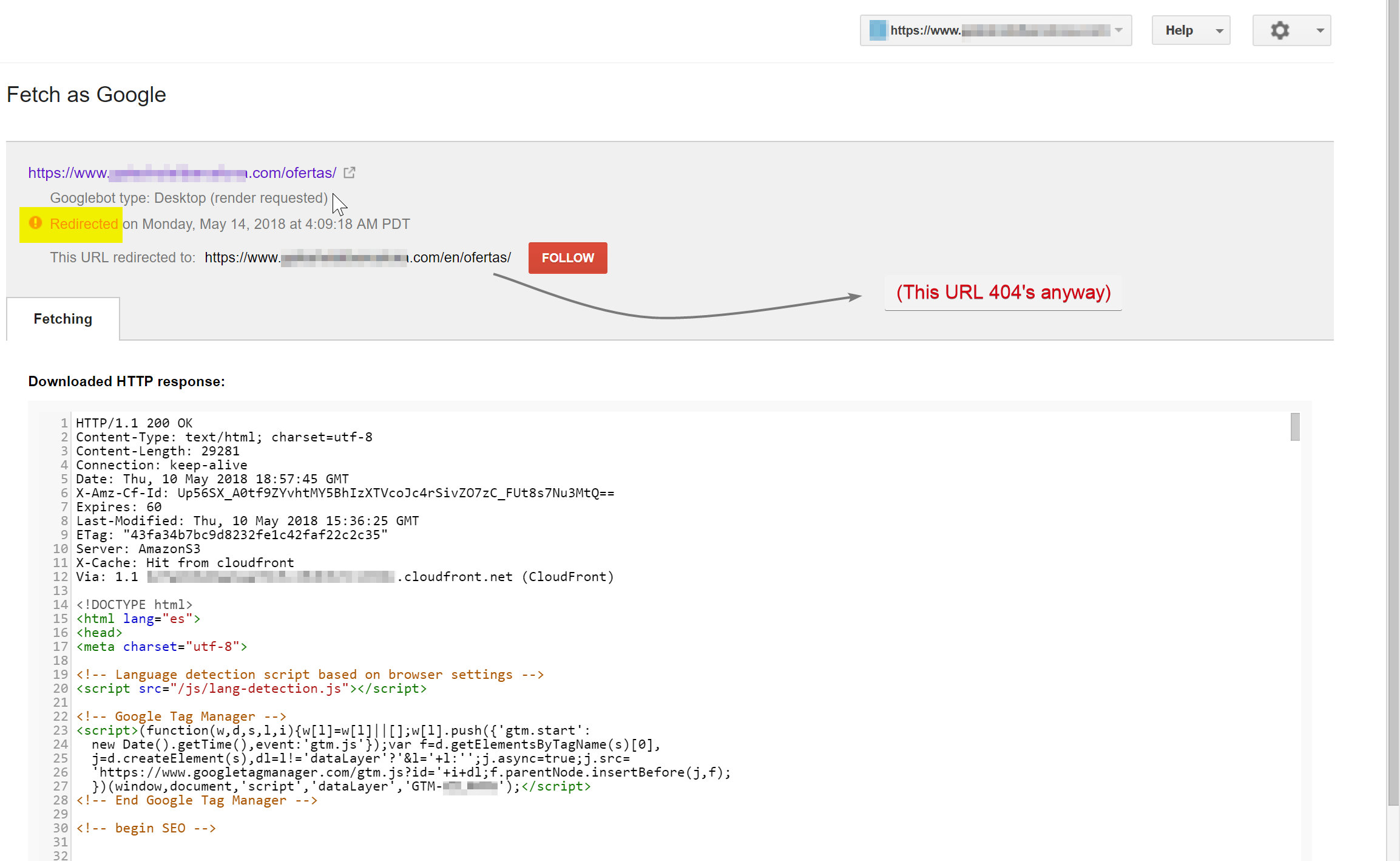
Googlebot mencoba merayapi konten berbahasa Spanyol (yang ada di hotelname.com/ofertas) dan dialihkan ke hotelname.com/en/ofertas – URL yang tidak ada.
Anehnya dalam kasus ini Googlebot mengikuti semua pengalihan JavaScript ini, dan karena tidak dapat menemukan URL ini, ia terpaksa menghapusnya dari indeksnya.
Dalam kasus di atas saya dapat mengkonfirmasi ini dengan mengakses log server situs, memfilter ke Googlebot dan memeriksa di mana itu dilayani 404.
Menghapus skrip pengalihan JavaScript yang salah menyelesaikan masalah, dan untungnya halaman yang diterjemahkan tidak diindeks dalam waktu lama.
Itu selalu merupakan ide yang baik untuk menguji semuanya sepenuhnya – berinvestasi dalam VPN dapat membantu mendiagnosis jenis skenario ini, atau bahkan mengubah lokasi dan/atau bahasa Anda di dalam browser Chrome.
[Studi Kasus] Menangani beberapa audit situs
 Baca studi kasus
Baca studi kasus7 – Konten Duplikat
Konten duplikat adalah masalah yang cukup umum dan didiskusikan dengan baik, dan ada banyak cara Anda dapat memeriksa duplikat konten di situs Anda – Richard Baxter baru-baru ini menulis artikel yang bagus tentang topik tersebut.
Dalam kasus saya, masalahnya mungkin sedikit lebih sederhana. Saya sering melihat situs menerbitkan konten hebat, sering kali sebagai posting blog, tetapi kemudian hampir seketika membagikan beberapa konten itu di situs web pihak ketiga seperti Medium.com.
Medium adalah situs yang bagus untuk menggunakan kembali konten yang ada untuk menjangkau khalayak yang lebih luas, tetapi harus berhati-hati dengan pendekatannya.
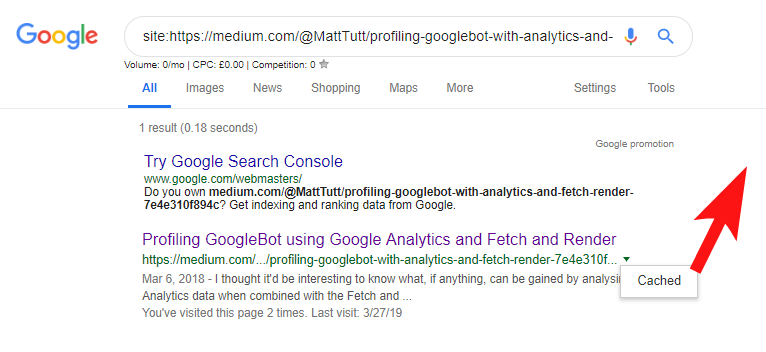
Saat mengimpor konten dari WordPress ke Medium, selama proses ini Medium akan menggunakan URL situs web Anda sebagai tag kanoniknya. Jadi secara teori, hal itu akan membantu untuk memberikan situs web Anda kredit untuk konten, sebagai sumber aslinya.
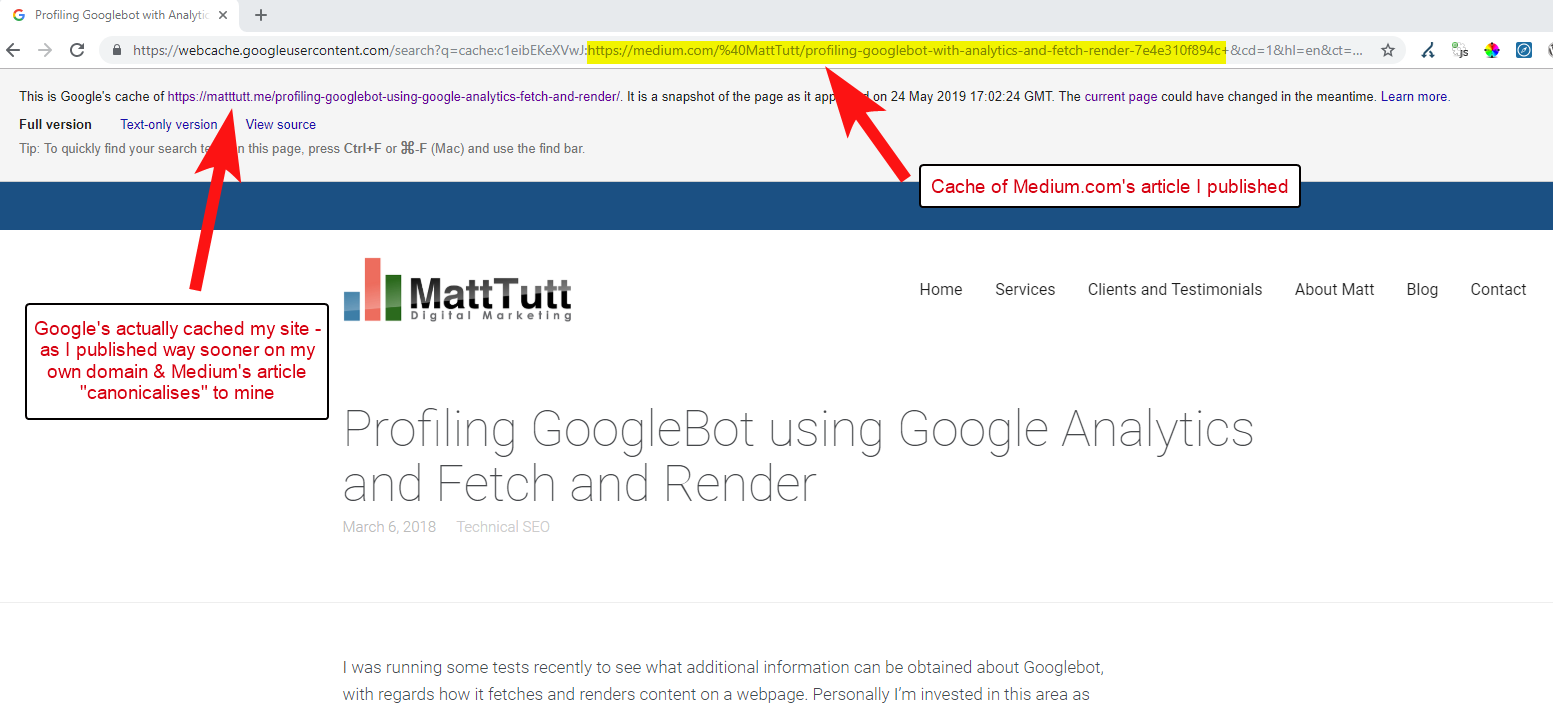
Dari beberapa analisis saya meskipun tidak selalu bekerja seperti ini.
Saya percaya hal ini terjadi karena ketika sebuah artikel diterbitkan di Medium tanpa terlebih dahulu memberi waktu kepada Google untuk merayapi dan mengindeks artikel di domain Anda, jika artikel tersebut berjalan dengan baik di Medium (yang sedikit hit atau miss) konten Anda mendapat diindeks dan dikaitkan dengan situs Medium meskipun kanoniknya menunjuk ke situs Anda.
Setelah konten ditambahkan ke Medium (dan terutama jika itu populer), Anda dapat menjamin bahwa konten tersebut akan dihapus dan diterbitkan ulang di web di tempat lain hampir seketika – jadi sekali lagi konten Anda diduplikasi di tempat lain.
Sementara ini semua terjadi, kemungkinan bahwa jika domain Anda cukup kecil dalam hal otoritas, Google bahkan mungkin tidak memiliki kesempatan untuk merayapi dan mengindeks konten yang Anda terbitkan – dan bahkan bisa jadi elemen rendering dari perayapan/pengindeksan belum selesai, atau ada JavaScript berat yang menyebabkan jeda waktu yang besar antara perayapan, rendering, dan pengindeksan konten tersebut.
Saya telah melihat situasi di mana sebuah perusahaan besar menerbitkan artikel yang bagus, tetapi kemudian hari berikutnya mereka menerbitkannya sebagai bagian pemikiran di blog berita industri besar. Selain itu, situs mereka memiliki masalah di mana konten diduplikasi (dan diindeks) di https://domain.com dan https://www.domain.com.
Beberapa hari setelah penerbitan, ketika mencari frasa yang tepat dari artikel dalam tanda kutip di Google, situs web perusahaan tidak terlihat. Sebaliknya, blog industri otoritatif berada di tempat pertama, dan penerbit ulang lainnya mengambil posisi berikutnya.
Dalam hal ini, konten telah dikaitkan dengan blog industri dan tautan apa pun yang diperoleh akan menguntungkan situs web itu – bukan penerbit asli.
Jika Anda akan menggunakan kembali konten di mana saja di web, kemungkinan besar akan diindeks, Anda harus benar-benar menunggu sampai Anda benar-benar yakin bahwa konten tersebut telah diindeks oleh Google di domain Anda sendiri.
Anda mungkin bekerja keras untuk membuat dan menyusun konten Anda – jangan membuang semuanya dengan terlalu tertarik untuk mempublikasikan ulang di tempat lain!
8 – Konfigurasi AMP Buruk (deklarasi URL AMP tidak ada)
Hanya segelintir klien yang saya bantu telah memilih untuk mencoba AMP, mungkin berdasarkan beberapa dari banyak studi kasus yang didanai Google seputar penggunaannya.
Terkadang saya bahkan tidak menyadari bahwa klien memiliki versi AMP situs mereka sama sekali – ada beberapa lalu lintas aneh yang muncul dalam laporan rujukan Analytics – di mana versi AMP situs ditautkan kembali ke versi situs non-AMP.
Dalam hal ini, versi halaman AMP tidak dikonfigurasi dengan benar karena tidak ada referensi URL dari kepala halaman non-AMP.

Tanpa memberi tahu mesin telusur bahwa halaman AMP ada di URL tertentu, tidak ada gunanya menyiapkan AMP sama sekali – intinya adalah halaman itu diindeks dan dikembalikan di SERPS untuk pengguna seluler.
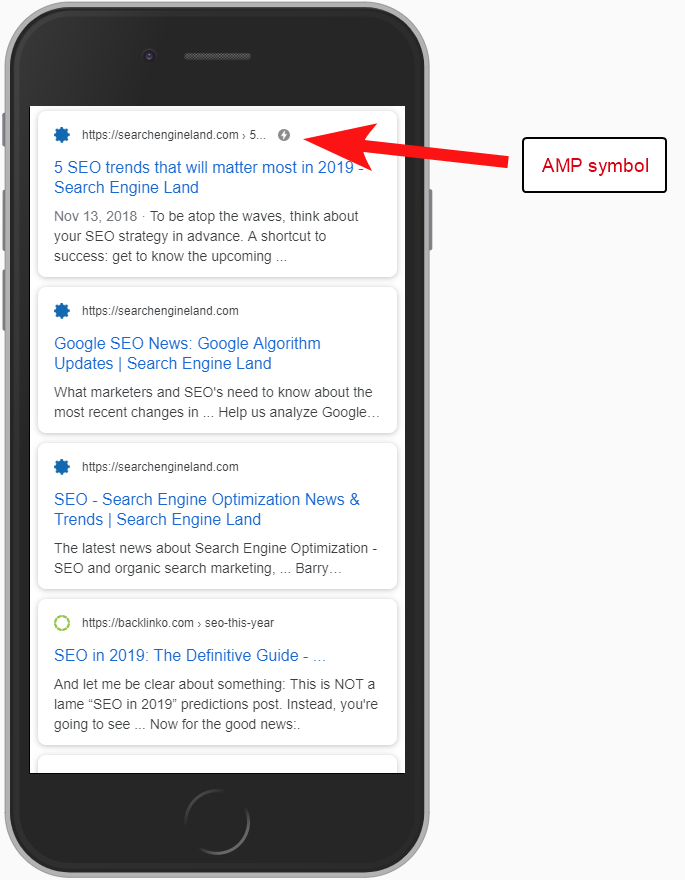
Menambahkan referensi ke halaman non-AMP Anda adalah cara penting untuk memberi tahu Google tentang halaman AMP, dan penting untuk diingat bahwa tag kanonik pada halaman AMP tidak boleh merujuk sendiri: tag tersebut menautkan kembali ke halaman non-AMP.
Dan meskipun bukan pertimbangan SEO teknis, perlu diperhatikan bahwa Anda masih perlu menyertakan kode pelacakan di halaman AMP jika Anda ingin dapat melaporkan informasi lalu lintas dan perilaku pengguna.
Biasanya sebagai bagian dari audit SEO saya, saya juga suka menjalankan beberapa pemeriksaan dasar dari implementasi analitik – jika tidak, data yang Anda berikan mungkin tidak terlalu membantu, terutama jika ada pengaturan analitik berbodged.
9 – Domain Legacy yang 302 redirect atau membentuk rantai redirect
Saat bekerja dengan merek hotel independen besar di AS, yang telah mengalami beberapa perubahan merek selama beberapa tahun terakhir (cukup umum di industri perhotelan), penting untuk memantau perilaku permintaan nama domain sebelumnya.
Ini mudah dilupakan, tetapi ini bisa menjadi pemeriksaan semi-reguler sederhana untuk mencoba merayapi situs lama mereka menggunakan alat seperti OnCrawl, atau bahkan situs pihak ketiga yang memeriksa kode status dan pengalihan.
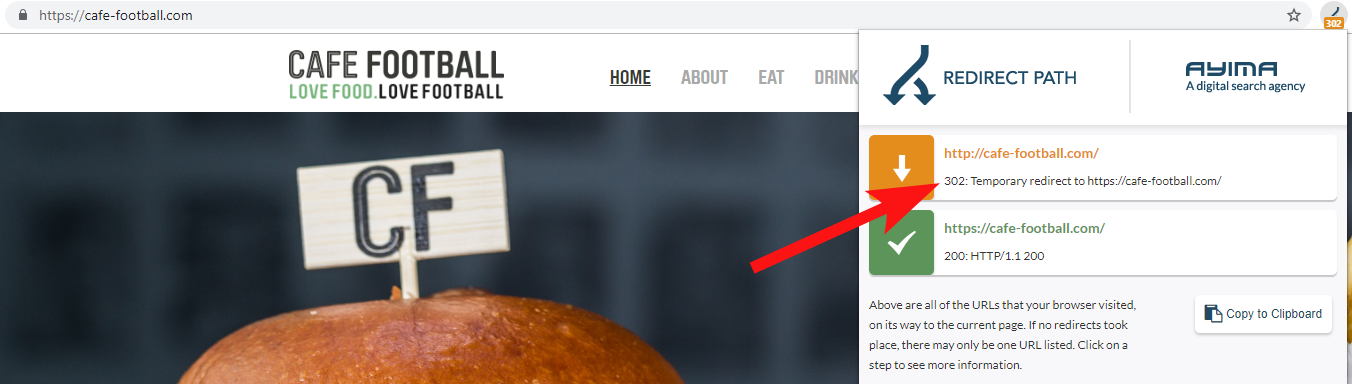
Lebih sering daripada tidak, Anda akan menemukan domain 302 dialihkan ke tujuan akhir (301 selalu merupakan taruhan terbaik di sini) atau 302 ke versi URL non-WWW sebelum melompati beberapa pengalihan lagi sebelum mencapai URL final.
John Mueller dari Google telah menyatakan sebelumnya bahwa mereka hanya mengikuti 5 pengalihan sebelum menyerah, sementara itu juga diketahui bahwa untuk setiap pengalihan yang dilewati beberapa nilai tautan hilang. Untuk alasan itu saya lebih memilih untuk tetap menggunakan pengalihan 301 yang sebersih mungkin.
Redirect Path oleh Ayima adalah ekstensi browser Chrome hebat yang akan menunjukkan kepada Anda status pengalihan saat Anda menjelajahi web.
Cara lain saya mendeteksi nama domain lama milik klien adalah dengan mencari di Google untuk nomor telepon mereka, menggunakan tanda kutip yang sama persis, atau bagian dari alamat mereka.
Bisnis seperti hotel tidak sering mengubah alamat (setidaknya sebagian saja) dan Anda mungkin menemukan direktori/profil bisnis lama yang tertaut ke domain lama.
Menggunakan alat backlink seperti Majestic atau Ahrefs mungkin juga menampilkan beberapa tautan lama dari domain sebelumnya, jadi ini juga merupakan port of call yang bagus – terutama jika Anda tidak berhubungan langsung dengan klien.
10 – Berurusan dengan Konten Pencarian Internal dengan Buruk
Ini sebenarnya adalah topik yang pernah saya tulis sebelumnya di sini di OnCrawl – tetapi saya memasukkannya lagi karena saya masih sering melihat konten internal bermasalah yang terjadi "di alam liar".
Saya mulai bagian ini berbicara tentang masalah arahan robots.txt Pingdom yang dari luar saya tampak sebagai perbaikan untuk mencegah konten yang mereka hasilkan agar tidak dirayapi dan diindeks.
Setiap situs yang menyajikan hasil pencarian internal ke Google sebagai konten, atau yang menghasilkan banyak konten buatan pengguna, harus sangat berhati-hati dengan cara mereka melakukannya.
Jika sebuah situs menyajikan hasil pencarian internal ke Google dengan cara yang sangat langsung, maka ini dapat menyebabkan semacam hukuman manual. Google kemungkinan akan melihat itu sebagai pengalaman pengguna yang buruk – mereka mencari X, lalu mendarat di situs di mana mereka harus memfilter secara manual untuk apa yang mereka inginkan.
Dalam beberapa kasus saya percaya tidak apa-apa untuk menyajikan konten internal, itu hanya tergantung pada konteks dan keadaan. Sebuah situs pekerjaan misalnya mungkin ingin menyajikan hasil pekerjaan terbaru yang diperbarui hampir setiap hari – sehingga mereka hampir harus berurusan dengan ini.
Memang adalah contoh terkenal dari situs pekerjaan yang mungkin mengambil ini terlalu jauh, menghasilkan semua jenis konten berdasarkan permintaan pencarian populer (lihat di bawah untuk apa yang bisa terjadi jika Anda menggunakan taktik ini).
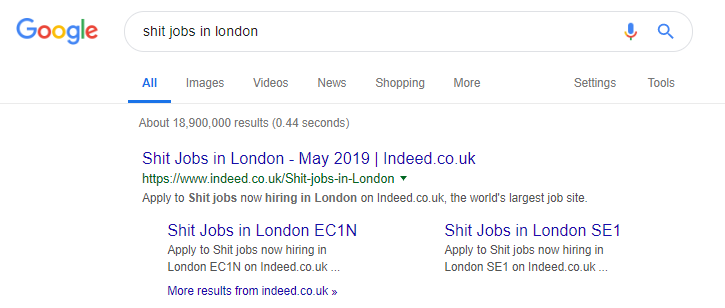
Meskipun demikian, menurut data SEMRush, lalu lintas organik mereka baik-baik saja – tetapi ini adalah garis halus, dan berperilaku seperti ini membuat Anda berisiko tinggi terkena penalti Google.
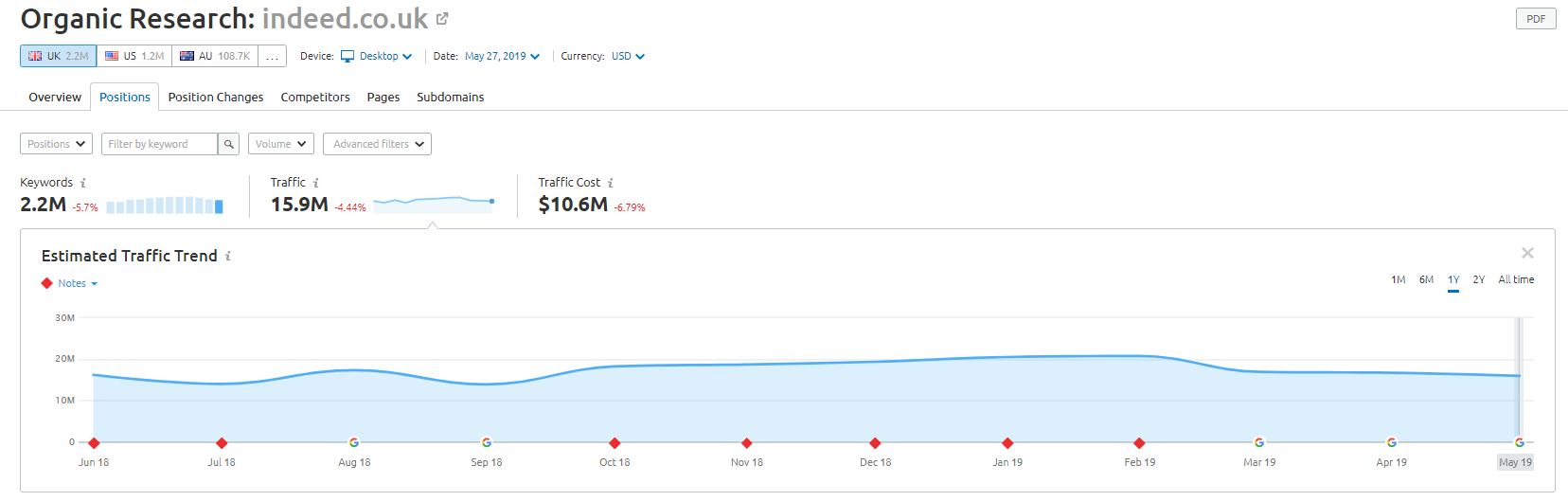
Pengecer online Wayfair.com adalah merek lain yang suka berlayar mendekati angin. Dengan jutaan URL yang diindeks (dan banyak URL kata kunci yang dibuat secara otomatis), mereka melakukan yang terbaik dalam hal lalu lintas organik – tetapi mereka berisiko tinggi terkena sanksi karena menyajikan konten dengan cara ini ke mesin telusur.
Dengan menerapkan struktur situs yang tepat yang melibatkan pengkategorian semua konten, membangun hierarki induk/anak yang berbeda, bahkan menggunakan tag atau taksonomi khusus lainnya, Anda dapat membantu membantu navigasi perayap pelanggan dan penelusuran.
Menggunakan trik seperti di atas mungkin menang dalam jangka pendek tetapi tidak mungkin berbuat banyak untuk Anda dalam jangka panjang. Ini menjadikannya kunci untuk mendapatkan struktur situs sejak awal, atau setidaknya merencanakannya dengan baik sebelumnya.
Membungkus
10 kesalahan yang dibahas dalam artikel ini adalah beberapa masalah teknis paling umum yang saya temui selama audit situs.
Memperbaiki kesalahan ini di situs Anda adalah langkah pertama untuk memastikan situs Anda sehat secara teknis. Setelah masalah ini diperbaiki, audit teknis dapat berkonsentrasi pada masalah yang khusus untuk situs Anda.