
Saluran Business Intelligence berdasarkan layanan AWS – studi kasus
Diterbitkan: 2019-05-16Dalam beberapa tahun terakhir, kami telah melihat peningkatan minat dalam analisis data besar. Eksekutif, manajer, dan pemangku kepentingan bisnis lainnya menggunakan Business Intelligence (BI) untuk membuat keputusan berdasarkan informasi. Hal ini memungkinkan mereka untuk menganalisis informasi penting dengan segera, dan membuat keputusan berdasarkan tidak hanya pada intuisi mereka tetapi juga pada apa yang dapat mereka pelajari dari perilaku nyata pelanggan mereka.
Saat Anda memutuskan untuk membuat solusi BI yang efektif dan informatif, salah satu langkah pertama yang perlu dilakukan tim pengembangan Anda adalah merencanakan arsitektur jalur data. Ada beberapa alat berbasis cloud yang dapat diterapkan untuk membangun saluran seperti itu, dan tidak ada satu solusi yang akan menjadi yang terbaik untuk semua bisnis. Sebelum Anda memutuskan opsi tertentu, Anda harus mempertimbangkan tumpukan teknologi Anda saat ini, harga alat, dan keahlian pengembang Anda. Pada artikel ini, saya akan menunjukkan arsitektur yang dibangun dengan alat AWS yang telah berhasil digunakan sebagai bagian dari aplikasi Timesheets.
Ikhtisar Arsitektur
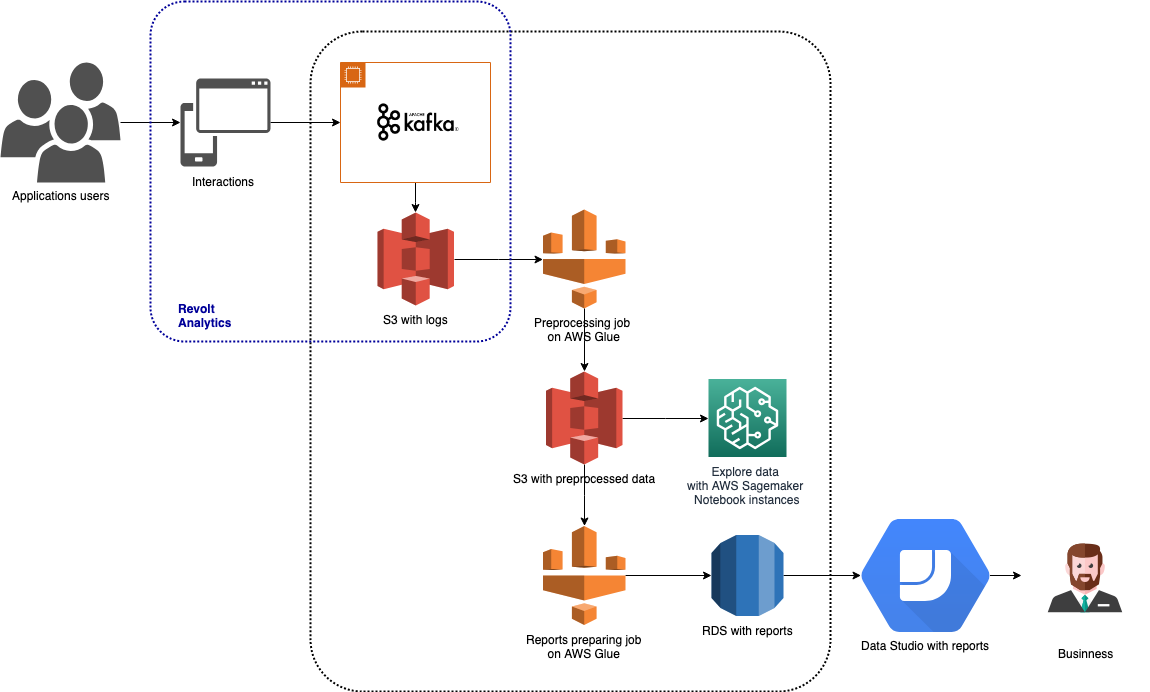
Timesheets adalah alat untuk melacak dan melaporkan waktu karyawan. Itu dapat digunakan melalui web, iOS, Android dan aplikasi desktop, chatbot terintegrasi dengan Hangouts dan Slack, dan aksi di Google Assistant. Karena ada banyak jenis aplikasi yang tersedia, ada juga banyak data yang beragam untuk dilacak. Data dikumpulkan melalui Revolt Analytics, disimpan di Amazon S3, dan diproses dengan AWS Glue dan Amazon SageMaker. Hasil analisis disimpan di Amazon RDS dan digunakan untuk membuat laporan visual di Google Data Studio. Arsitektur ini disajikan dalam grafik di atas.
Dalam paragraf berikut, saya akan menjelaskan secara singkat masing-masing alat Big Data yang digunakan dalam arsitektur ini.
Analisis Pemberontakan
Revolt Analytics adalah alat yang dikembangkan oleh Miquido untuk melacak dan menganalisis data dari semua jenis aplikasi. Untuk menyederhanakan implementasi Revolt di sistem klien, iOS, Android, JavaScript, Go, Python, dan Java SDK telah dibangun. Salah satu fitur utama Revolt adalah kinerjanya: semua acara diantrekan, disimpan, dan dikirim dalam paket, yang memastikan mereka dikirimkan dengan cepat dan efisien. Revolt memberi pemilik aplikasi kemampuan untuk mengidentifikasi pengguna dan melacak perilaku mereka di aplikasi. Hal ini memungkinkan kami untuk membangun model Pembelajaran Mesin yang membawa nilai, seperti Sistem Rekomendasi dan model Prediksi Churn yang sepenuhnya dipersonalisasi, dan untuk Pembuatan Profil Pelanggan berdasarkan perilaku pengguna. Revolt juga menyediakan fitur sessionization. Pengetahuan tentang jalur dan perilaku pengguna dalam aplikasi dapat membantu Anda memahami tujuan dan kebutuhan pelanggan Anda.
Pemberontakan dapat diinstal pada infrastruktur apa pun yang Anda pilih. Pendekatan ini memberi Anda kendali penuh atas biaya dan peristiwa yang dilacak. Dalam kasus Timesheets yang disajikan dalam artikel ini, itu dibangun di atas infrastruktur AWS. Berkat akses penuh ke penyimpanan data, pemilik produk dapat dengan mudah mendapatkan wawasan tentang aplikasi mereka dan menggunakan data itu di sistem lain.
SDK Revolt ditambahkan ke setiap komponen sistem Timesheets, yang terdiri dari:
- Aplikasi Android & iOS (dibangun dengan Flutter)
- Aplikasi desktop (dibangun dengan Electron)
- Aplikasi web (ditulis dalam React)
- Backend (ditulis dalam bahasa Golang)
- Hangouts dan obrolan online Slack
- Tindakan di Asisten Google
Revolt memberikan pengetahuan kepada administrator Timesheets tentang perangkat (misalnya merek perangkat, model) dan sistem (misalnya versi OS, bahasa, zona waktu) yang digunakan oleh pelanggan aplikasi. Selain itu, ia mengirimkan berbagai acara khusus yang terkait dengan aktivitas pengguna di aplikasi. Akibatnya, administrator dapat menganalisis perilaku pengguna, dan lebih memahami tujuan dan harapan mereka. Mereka juga dapat memverifikasi kegunaan fitur yang diterapkan, dan menilai apakah fitur ini memenuhi asumsi Pemilik Produk tentang bagaimana fitur tersebut akan digunakan.

Lem AWS
AWS Glue adalah layanan ETL (extract, transform, and load) yang membantu menyiapkan data untuk tugas analitis. Ini menjalankan pekerjaan ETL di lingkungan tanpa server Apache Spark. Biasanya, itu terdiri dari tiga elemen berikut:
- Definisi perayap – Perayap digunakan untuk memindai data di semua jenis repositori dan sumber, mengklasifikasikannya, mengekstrak informasi skema darinya, dan menyimpan metadata tentangnya di Katalog Data. Ini dapat, misalnya, memindai log yang disimpan dalam file JSON di Amazon S3, dan menyimpan informasi skemanya di Katalog Data.
- Skrip pekerjaan – Pekerjaan AWS Glue mengubah data ke dalam format yang diinginkan. AWS Glue dapat secara otomatis membuat skrip untuk memuat, membersihkan, dan mengubah data Anda. Anda juga dapat menyediakan skrip Apache Spark Anda sendiri yang ditulis dengan Python atau Scala yang akan menjalankan transformasi yang diinginkan. Mereka dapat mencakup tugas-tugas seperti menangani nilai nol, sesi, agregasi, dll.
- Pemicu – Perayap dan pekerjaan dapat dijalankan sesuai permintaan, atau dapat diatur untuk memulai saat pemicu tertentu terjadi. Pemicu dapat berupa jadwal berbasis waktu atau peristiwa (misalnya, keberhasilan pelaksanaan pekerjaan tertentu). Opsi ini memberi Anda kemampuan untuk mengelola keaktualan data dalam laporan Anda dengan mudah.
Dalam arsitektur Timesheets kami, bagian dari pipeline ini disajikan sebagai berikut:
- Pemicu berbasis waktu memulai pekerjaan prapemrosesan, yang mengeksekusi pembersihan data, menetapkan log peristiwa yang sesuai dengan sesi, dan menghitung agregasi awal. Data yang dihasilkan dari pekerjaan ini disimpan di AWS S3.
- Pemicu kedua diatur untuk dijalankan setelah eksekusi pekerjaan prapemrosesan yang lengkap dan berhasil. Pemicu ini memulai pekerjaan yang menyiapkan data yang langsung digunakan dalam laporan yang dianalisis oleh Pemilik Produk.
- Hasil pekerjaan kedua disimpan dalam database AWS RDS. Ini membuatnya mudah diakses dan digunakan di alat Business Intelligence seperti Google Data Studio, PowerBI, atau Tableau.
AWS SageMaker
Amazon SageMaker menyediakan modul untuk membangun, melatih, dan menerapkan model pembelajaran mesin.
Ini memungkinkan pelatihan dan penyetelan model pada skala apa pun dan memungkinkan penggunaan algoritme kinerja tinggi yang disediakan oleh AWS. Meskipun demikian, Anda juga dapat menggunakan algoritme khusus setelah Anda memberikan gambar buruh pelabuhan yang tepat. AWS SageMaker juga menyederhanakan penyetelan hyperparameter dengan pekerjaan yang dapat dikonfigurasi yang membandingkan metrik untuk kumpulan parameter model yang berbeda.
Di Timesheets, Instans Notebook SageMaker membantu kami menjelajahi data, menguji skrip ETL, dan menyiapkan prototipe bagan visualisasi untuk digunakan dalam alat BI untuk pembuatan laporan. Solusi ini mendukung dan meningkatkan kolaborasi ilmuwan data karena memastikan mereka bekerja di lingkungan pengembangan yang sama. Selain itu, ini membantu memastikan bahwa tidak ada data sensitif (yang dapat menjadi bagian dari output sel notebook) yang disimpan di luar infrastruktur AWS karena notebook hanya disimpan di bucket AWS S3, dan tidak diperlukan repositori git untuk berbagi pekerjaan antar rekan kerja. .
Bungkus
Memutuskan alat Big Data dan Machine Learning mana yang akan digunakan sangat penting dalam merancang arsitektur pipeline untuk solusi Business Intelligence. Pilihan ini dapat berdampak besar pada kemampuan sistem, biaya, dan kemudahan penambahan fitur baru di masa mendatang. Alat AWS tentu saja patut dipertimbangkan, tetapi Anda harus memilih teknologi yang sesuai dengan tumpukan teknologi Anda saat ini dan keterampilan tim pengembangan Anda.
Manfaatkan pengalaman kami dalam membangun solusi berorientasi masa depan dan hubungi kami!