
Secara otomatis mengekstrak konsep dan kata kunci dari teks (Bagian I : Metode tradisional)
Diterbitkan: 2022-02-22Di departemen Litbang Oncrawl, kami semakin berupaya meningkatkan konten semantik halaman Web Anda. Menggunakan model Machine Learning untuk pemrosesan bahasa alami (NLP), kami dapat membandingkan konten halaman Anda secara mendetail, membuat ringkasan otomatis, melengkapi atau memperbaiki tag artikel Anda, mengoptimalkan konten sesuai dengan data Google Search Console Anda, dll.
Dalam artikel sebelumnya, kami berbicara tentang mengekstrak konten teks dari halaman HTML. Kali ini, kami ingin berbicara tentang ekstraksi otomatis kata kunci dari sebuah teks. Topik ini akan dibagi menjadi dua posting:
- yang pertama akan membahas konteks dan apa yang disebut metode "tradisional" dengan beberapa contoh nyata
- yang kedua akan segera hadir akan membahas lebih banyak pendekatan semantik berdasarkan transformator dan metode evaluasi untuk membandingkan metode yang berbeda ini
Konteks
Selain judul atau abstrak, cara apa yang lebih baik untuk mengidentifikasi konten teks, makalah ilmiah, atau halaman web selain dengan beberapa kata kunci. Ini adalah cara yang sederhana dan sangat efektif untuk mengidentifikasi topik dan konsep dari teks yang lebih panjang. Ini juga bisa menjadi cara yang baik untuk mengkategorikan serangkaian teks: mengidentifikasinya dan mengelompokkannya berdasarkan kata kunci. Situs yang menawarkan artikel ilmiah seperti PubMed atau arxiv.org dapat menawarkan kategori dan rekomendasi berdasarkan kata kunci tersebut.
Kata kunci juga sangat berguna untuk mengindeks dokumen yang sangat besar dan untuk pencarian informasi, bidang keahlian yang dikenal oleh mesin pencari
Kurangnya kata kunci adalah masalah berulang dalam kategorisasi otomatis artikel ilmiah [1]: banyak artikel tidak memiliki kata kunci yang ditetapkan. Oleh karena itu, metode harus ditemukan untuk mengekstrak konsep dan kata kunci secara otomatis dari sebuah teks. Untuk mengevaluasi relevansi kumpulan kata kunci yang diekstraksi secara otomatis, kumpulan data sering membandingkan kata kunci yang diekstraksi oleh suatu algoritme dengan kata kunci yang diekstraksi oleh beberapa orang.
Seperti yang dapat Anda bayangkan, ini adalah masalah yang dibagikan oleh mesin pencari saat mengkategorikan halaman web. Pemahaman yang lebih baik tentang proses otomatis ekstraksi kata kunci memungkinkan untuk lebih memahami mengapa halaman web diposisikan untuk kata kunci ini atau itu. Itu juga dapat mengungkapkan kesenjangan semantik yang mencegahnya dari peringkat yang baik untuk kata kunci yang Anda targetkan.
Jelas ada beberapa cara untuk mengekstrak kata kunci dari teks atau paragraf. Dalam posting pertama ini, kami akan menjelaskan apa yang disebut pendekatan "klasik".
[Ebook] Data SEO: Petualangan Besar Berikutnya
 Baca ebooknya
Baca ebooknyaPengekangan
Namun demikian, kami memiliki beberapa keterbatasan dan prasyarat dalam pemilihan algoritme:
- Metode harus dapat mengekstrak kata kunci dari satu dokumen. Beberapa metode memerlukan corpus yang lengkap, yaitu beberapa ratus atau bahkan ribuan dokumen. Meskipun metode ini dapat digunakan oleh mesin pencari, mereka tidak akan berguna untuk satu dokumen.
- Kami berada dalam kasus Machine Learning tanpa pengawasan. Kami tidak memiliki kumpulan data dalam bahasa Prancis, Inggris, atau bahasa lain dengan data beranotasi. Dengan kata lain, kami tidak memiliki ribuan dokumen dengan kata kunci yang sudah diekstraksi.
- Metode harus independen dari domain / bidang leksikal dokumen. Kami ingin dapat mengekstrak kata kunci dari semua jenis dokumen: artikel berita, halaman web, dll. Perhatikan bahwa beberapa kumpulan data yang sudah memiliki kata kunci yang diekstraksi untuk setiap dokumen sering kali adalah obat khusus domain, ilmu komputer, dll.
- Beberapa metode didasarkan pada model penandaan POS, yaitu kemampuan model NLP untuk mengidentifikasi kata-kata dalam kalimat berdasarkan jenis tata bahasanya: kata kerja, kata benda, penentu. Menentukan pentingnya kata kunci yang merupakan kata benda daripada penentu jelas relevan. Namun, tergantung pada bahasanya, model penandaan POS terkadang memiliki kualitas yang sangat tidak merata.
Tentang metode tradisional
Kami membedakan antara apa yang disebut metode "tradisional" dan yang lebih baru yang menggunakan NLP – Natural Language Processing – teknik seperti penyisipan kata dan penyematan kontekstual. Topik ini akan dibahas dalam posting mendatang. Tapi pertama-tama, mari kita kembali ke pendekatan klasik, kita membedakan dua di antaranya:
- pendekatan statistik
- pendekatan grafik
Pendekatan statistik terutama akan bergantung pada frekuensi kata dan kemunculannya bersama. Kita mulai dengan hipotesis sederhana untuk membangun heuristik dan mengekstrak kata-kata penting: kata yang sangat sering, serangkaian kata berurutan yang muncul beberapa kali, dll. Metode berbasis grafik akan membangun grafik di mana setiap simpul dapat berkorespondensi dengan kata, kelompok kata atau kalimat. Kemudian setiap busur dapat mewakili probabilitas (atau frekuensi) mengamati kata-kata ini bersama-sama.
Berikut adalah beberapa metode:
- Berbasis statistik
- TF-IDF
- MENYAPU
- YAK
- Berbasis grafik
- Peringkat Teks
- Peringkat Topik
- Peringkat Tunggal
Semua contoh yang diberikan menggunakan teks yang diambil dari halaman web ini: Jazz au Tresor : John Coltrane – Impressions Graz 1962.
Pendekatan statistik
Kami akan memperkenalkan Anda pada dua metode Rake dan Yake. Dalam konteks SEO, Anda mungkin pernah mendengar tentang metode TF-IDF. Tetapi karena memerlukan kumpulan dokumen, kami tidak akan membahasnya di sini.
MENYAPU
RAKE adalah singkatan dari Ekstraksi Kata Kunci Otomatis Cepat. Ada beberapa implementasi metode ini dalam Python, termasuk rake-nltk. Skor setiap kata kunci, yang juga disebut frasa kunci karena mengandung beberapa kata, didasarkan pada dua elemen: frekuensi kata dan jumlah kemunculannya bersama. Konstitusi setiap frasa kunci sangat sederhana, terdiri dari:
- memotong teks menjadi kalimat
- potong setiap kalimat menjadi frasa kunci
Dalam kalimat berikut, kita akan mengambil semua kelompok kata yang dipisahkan oleh elemen tanda baca atau stopwords:
Tepat sebelumnya, Coltrane memimpin kuintet, dengan Eric Dolphy di sisinya dan Reggie Workman pada double bass.
Ini dapat menghasilkan frasa kunci berikut:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
Perhatikan bahwa stopwords adalah serangkaian kata-kata yang sangat sering seperti " the " in ", "dan" or " it ". Karena metode klasik sering didasarkan pada perhitungan frekuensi kemunculan kata, penting untuk memilih stopword Anda dengan hati-hati. Sebagian besar waktu, kami tidak ingin memiliki kata-kata seperti >"to" , "the" or "of" dalam proposal frasa kunci kami. Memang, stopwords ini tidak terkait dengan bidang leksikal tertentu dan karena itu kurang relevan dibandingkan dengan kata-kata " jazz " atau " saxophone " misalnya.

Setelah kami mengisolasi beberapa kandidat frasa kunci, kami memberi mereka skor sesuai dengan frekuensi kata dan kemunculannya. Semakin tinggi skor, semakin relevan frasa kunci yang seharusnya.
Mari kita coba cepat dengan teks dari artikel tentang John Coltrane.
# cuplikan python untuk rake dari rake_nltk impor Rake # misalkan Anda sudah memiliki artikel di variabel 'teks' rake = Rake(stopwords=FRENCH_STOPWORDS, max_length=4) rake.extract_keywords_from_text(teks) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
Berikut adalah 5 frasa kunci pertama:
"radio publik nasional Austria", "puncak lirik yang lebih surgawi", "graz memiliki dua kekhasan", "john coltrane tenor saxophone", "hanya versi rekaman"
Ada beberapa kelemahan metode ini. Yang pertama adalah pentingnya pemilihan stopwords karena digunakan untuk memecah kalimat menjadi kandidat frase kunci. Yang kedua adalah bahwa ketika frase kunci terlalu panjang, mereka akan sering memiliki skor yang lebih tinggi karena kemunculan kata-kata yang ada. Untuk membatasi panjang frasa kunci, kami telah menetapkan metode dengan max_length=4 .
YAK
YAKE adalah singkatan dari Yet Another Keyword Extractor. Cara ini berdasarkan artikel berikut YAKE! Ekstraksi kata kunci dari dokumen tunggal menggunakan beberapa fitur lokal yang berasal dari tahun 2020. Ini adalah metode yang lebih baru daripada RAKE yang penulisnya telah mengusulkan implementasi Python yang tersedia di Github.
Kami akan, seperti untuk RAKE, mengandalkan frekuensi kata dan kemunculan bersama. Penulis juga akan menambahkan beberapa heuristik yang menarik:
- kita akan membedakan antara kata-kata dalam huruf kecil dan kata-kata dalam huruf besar (baik huruf pertama atau seluruh kata). Kami akan berasumsi di sini bahwa kata-kata yang dimulai dengan huruf kapital (kecuali di awal kalimat) lebih relevan daripada yang lain: nama orang, kota, negara, merek. Ini adalah prinsip yang sama untuk semua kata dengan huruf kapital.
- skor setiap frasa kunci kandidat akan tergantung pada posisinya dalam teks. Jika frasa kunci kandidat muncul di awal teks, mereka akan memiliki skor lebih tinggi daripada jika muncul di akhir. Misalnya, artikel berita sering menyebutkan konsep penting di awal artikel.
# cuplikan python untuk yake dari yake impor KeywordExtractor sebagai Yake yake = Yake(lan="fr", stopwords=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(teks)
Seperti RAKE, berikut adalah 5 hasil teratas:
“Treasure Jazz”, “John Coltrane”, “Impressions Graz”, “Graz”, “Coltrane”
Meskipun ada duplikasi kata-kata tertentu dalam beberapa frasa kunci, metode ini tampaknya cukup menarik.
Pendekatan grafik
Jenis pendekatan ini tidak terlalu jauh dari pendekatan statistik dalam arti kita juga akan menghitung kemunculan kata bersama. Sufiks Peringkat yang terkait dengan beberapa nama metode seperti TextRank didasarkan pada prinsip algo PageRank untuk menghitung popularitas setiap halaman berdasarkan tautan masuk dan keluarnya.
[Ebook] Mengotomatiskan SEO dengan Oncrawl
 Baca ebooknya
Baca ebooknyaPeringkat Teks
Algoritma ini berasal dari makalah TextRank: Bringing Order into Texts dari tahun 2004 dan didasarkan pada prinsip yang sama dengan algoritma PageRank . Namun, alih-alih membuat grafik dengan halaman dan tautan, kami akan membuat grafik dengan kata-kata. Setiap kata akan dihubungkan dengan kata lain sesuai dengan kemunculannya.
Ada beberapa implementasi di Python. Pada artikel ini, saya akan memperkenalkan pytextrank. Kami akan mematahkan salah satu kendala kami tentang penandaan POS. Memang, saat membangun grafik, kami tidak akan memasukkan semua kata sebagai node. Hanya kata kerja dan kata benda yang akan diperhitungkan. Seperti metode sebelumnya yang menggunakan stopword untuk menyaring kandidat yang tidak relevan, algo TextRank menggunakan jenis kata gramatikal.
Berikut adalah contoh bagian dari grafik yang akan dibangun oleh algo : 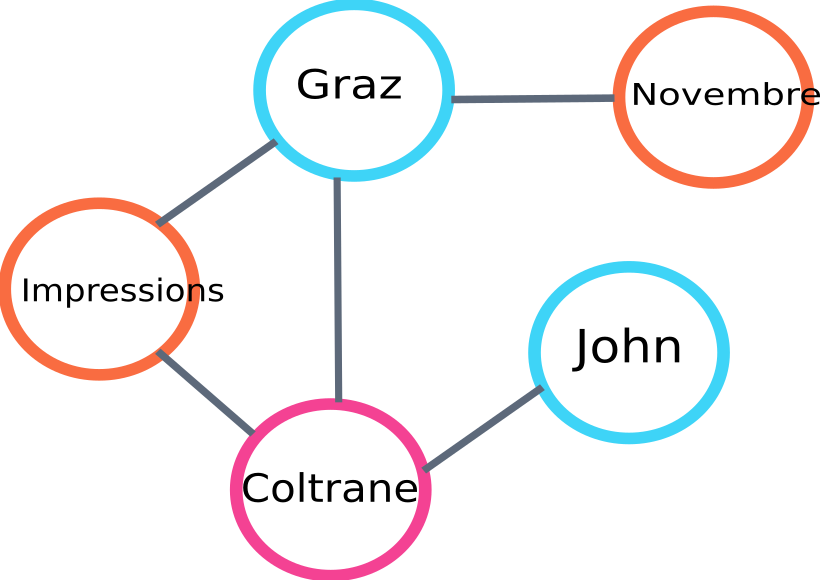
contoh grafik peringkat teks
Berikut adalah contoh penggunaan dalam Python. Perhatikan bahwa implementasi ini menggunakan mekanisme pipeline library spaCy. Library inilah yang mampu melakukan POS-tagging.
# cuplikan python untuk pytextrank
impor spasi
impor pytextrank
# memuat model Prancis
nlp = spacy.load("fr_core_news_sm")
# tambahkan pytextrank ke pipa
nlp.add_pipe("peringkat teks")
doc = nlp(teks)
textrank_keyphrases = doc._.phrases
Berikut adalah 5 hasil teratas:
"Kopenhague", "novembre", "Tayangan Graz", "Graz", "John Coltrane"
Selain mengekstrak frasa kunci, TextRank juga mengekstraksi kalimat. Ini bisa sangat berguna untuk membuat apa yang disebut "ringkasan ekstraktif" – aspek ini tidak akan dibahas dalam artikel ini.
Kesimpulan
Di antara tiga metode yang diuji di sini, dua yang terakhir bagi kita tampaknya cukup relevan dengan subjek teks. Untuk membandingkan pendekatan-pendekatan ini dengan lebih baik, kita jelas harus mengevaluasi model-model yang berbeda ini pada lebih banyak contoh. Memang ada metrik untuk mengukur relevansi model ekstraksi kata kunci ini.
Daftar kata kunci yang dihasilkan oleh apa yang disebut model tradisional ini memberikan dasar yang sangat baik untuk memeriksa apakah halaman Anda ditargetkan dengan baik. Selain itu, mereka memberikan perkiraan pertama tentang bagaimana mesin pencari dapat memahami dan mengklasifikasikan konten.
Di sisi lain, metode lain menggunakan model NLP pra-terlatih seperti BERT juga dapat digunakan untuk mengekstrak konsep dari dokumen. Bertentangan dengan apa yang disebut pendekatan klasik, metode ini biasanya memungkinkan penangkapan semantik yang lebih baik.
Metode evaluasi yang berbeda, penyematan kontekstual dan transformator akan disajikan dalam artikel kedua yang akan datang tentang masalah ini!
Berikut adalah daftar kata kunci yang diambil dari artikel ini dengan salah satu dari tiga metode yang disebutkan:
“metode”, “kata kunci”, “frasa kunci”, “teks”, “kata kunci yang diekstraksi”, “Pemrosesan Bahasa Alami”
Referensi bibliografi
- [1] Peningkatan Ekstraksi Kata Kunci Otomatis Mengingat Lebih Banyak Pengetahuan Linguistik, Anette Hulth, 2003
- [2] Ekstraksi Kata Kunci Otomatis dari Dokumen Individual, Stuart Rose et. al, 2010
- [3] YA! Ekstraksi kata kunci dari dokumen tunggal menggunakan beberapa fitur lokal, Ricardo Campos et. al, 2020
- [4] TextRank: Membawa Ketertiban ke dalam Teks, Rada Mihalcea et. al, 2004
Mulai uji coba gratis selama 14 hari
 Mulai uji coba Anda
Mulai uji coba Anda