
Keaslian, Dalle-2 & Midjourney Dan Ketertarikan Kami pada Gambar & Seni yang Dihasilkan AI
Diterbitkan: 2022-08-04Artikel ini adalah tentang teknologi di balik platform seperti Dalle-2 dan Midjourney, dan mengapa pembuat Open AI berpotensi membayar Anda uang – bukan membebankan biaya …
Semakin banyak orang di internet yang menyebut Dalle-2 dan Open AI sebagai penipuan. Alasannya adalah Dalle-2 sekarang tiba-tiba berubah menjadi layanan yang dimonetisasi, di mana Anda perlu membeli kredit, jika Anda menggunakan platform di luar batas beta.
DALLE 2 hanyalah salah satu dari banyak platform baru yang menawarkan Anda akses ke konten yang dihasilkan AI, dan mengklaim bahwa Anda dapat menggunakannya untuk tujuan komersial. Platform lainnya termasuk Midjourney, Jasper Art, Nightcafe, Starry AI dan Craiyon. Kami akan fokus pada Dalle 2 dalam posting blog ini, tetapi mereka hampir identik, dalam hal tantangan dan masalah hukum.
Scam adalah pernyataan yang cukup keras menurut kami, tetapi ada masalah yang jelas dalam menggunakan data yang telah dibuat orang lain (foto, video, anotasi, orang pada gambar, dll.) dan kemudian mulai menjualnya kembali ke orang yang sama.
Masalah ini mungkin diabaikan oleh banyak dari kita, karena kita hanya terpesona oleh teknologi baru. Sesuatu yang sangat bisa dimengerti.
Namun, meskipun DALL-E 2 pada akhirnya hanyalah mesin pengenalan pola tingkat lanjut, outputnya tidak netral, dan polanya tidak berasal dari udara segar.
Mereka didasarkan pada banyak data, di mana ada beberapa pertanyaan hukum yang harus diajukan. Pertanyaan yang penting bagi Anda sebagai calon pengguna gambar yang Anda hasilkan.
 Gambar dibuat oleh DALLE-2
Gambar dibuat oleh DALLE-2
Model AI tidak bisa dibandingkan dengan manusia
Anda harus mulai dengan membaca artikel brilian ini di Engadget, sebelum Anda mulai mempertimbangkan untuk menggunakan gambar DALL-E 2 untuk tujuan komersial.
Dalam artikel Engadget mereka menunjukkan hal lain yang sangat penting. Yaitu fakta bahwa DALL-E 2 dan OpenAI TIDAK melepaskan hak mereka sendiri untuk mengkomersialkan gambar yang dibuat pengguna menggunakan DALL-E. Pada dasarnya berarti Anda dapat menghasilkan gambar yang kemudian akan mereka jual secara komersial kepada orang lain.
Ini menunjukkan bahwa niatnya sangat berbeda dari analogi yang kadang-kadang digunakan, di mana promotor DALLE-2 akan membandingkannya dengan seorang siswa yang membaca karya seorang penulis mapan. Dalam contoh ini siswa dapat mempelajari gaya dan pola penulis dan kemudian menemukan ini berlaku dalam konteks lain dan menggunakannya kembali di sana.
Namun, ini bukan tentang otak manusia yang menggunakan memori kreatif untuk menciptakan karya kreatif baru. Ini adalah tentang penggunaan kembali mesin pengenalan pola dan dalam beberapa kasus mereproduksi data pelatihan dalam gambar yang kemudian digunakan atau bahkan dijual secara komersial. Ini hanyalah dua dunia yang berbeda – baik secara metaforis maupun secara harfiah.
 Foto asli dari dunia nyata
Foto asli dari dunia nyata
Janji Keaslian JumpStory
Artikel ini ditujukan untuk orang-orang yang ingin memahami lebih dalam, bagaimana teknologi pembuatan gambar AI yang baru ini bekerja. Namun sebelum kita mulai, cukup jelaskan beberapa alasan mengapa JumpStory saat ini tidak membuat mesin serupa.
Tentu saja, kami telah ditanyai pertanyaan itu berkali-kali. Paling tidak mengingat bahwa kami sudah menggunakan AI di perusahaan kami, dan karena kami memiliki akses ke jutaan gambar asli.
Namun, ini bukan diskusi teknologi bagi kami, tetapi diskusi etis. Sebuah diskusi yang menghasilkan Janji Keaslian kami.
Kami pada dasarnya menentang masa depan, di mana gambar yang dihasilkan AI menjadi norma dan bukan pengecualian. Sebut kami kuno, tapi kami percaya bahwa dunia NYATA itu indah.
Kami bangga bahwa foto & video kami menggambarkan manusia nyata dalam berbagai bentuk dan ukuran. Kami tidak menentang penggunaan AI, tetapi kami tidak berpikir itu harus digunakan untuk menghasilkan orang atau kenyataan palsu.
Teknologi seperti media sintetis dan DALL-E 2 mungkin menarik di permukaan, tetapi mereka juga menimbulkan risiko nyata. Mereka berisiko mengaburkan batas antara nyata dan palsu, yang akan menjadi ancaman mendasar bagi kepercayaan antara manusia.
Inilah mengapa JumpStory tidak menggunakan kecerdasan buatan untuk menghasilkan gambar palsu, melainkan menggunakan AI untuk mengidentifikasi gambar mana yang asli, asli, dan – tentu saja – legal untuk digunakan untuk tujuan komersial.

Ini adalah gambar yang Anda temukan menggunakan layanan kami, dan kami menamai pendekatan kami 'Kecerdasan Asli'.
Memahami bagaimana gambar AI dihasilkan
Cukup tentang JumpStory dan masalah hukum dengan DALL-E 2 untuk saat ini. Mari kita lihat bagaimana gambar AI dihasilkan pada platform seperti DALLE-2, Imagen, Crayion (sebelumnya Dall-E Mini), Midjourney, dll. … Menggunakan DALLE-2 sebagai contoh paling populer saat ini.
Untuk memulai dengan DALLE-2 dapat melakukan berbagai jenis tugas, tetapi kami akan fokus pada tugas pembuatan gambar di posting blog ini.
Cara kerjanya adalah bahwa prompt teks dimasukkan ke dalam encoder teks. Encoder ini dilatih untuk memetakan prompt ke ruang representasi. Setelah itu, model sebelumnya yang disebut memetakan teks yang dikodekan ke pengkodean gambar yang sesuai yang menangkap informasi semantik dari prompt pengkodean teks.
(Jika ini sudah menjadi sedikit culun, saya sangat menyesal, tetapi ini akan menjadi lebih buruk)
Langkah terakhir untuk encoder gambar adalah menghasilkan gambar yang memvisualisasikan informasi semantik yang diterima encoder. Ini adalah dasar-dasar mesin seperti Open AI.
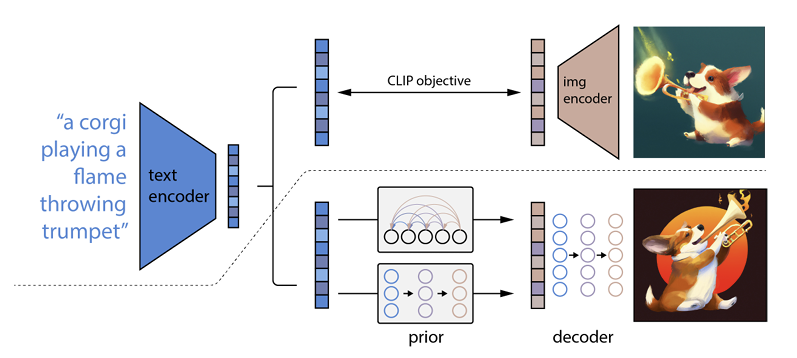
Hubungan antara teks dan visual
DALL-E 2 dan teknologi serupa sering disebut sebagai generator teks-ke-gambar. Alasannya adalah kemampuan mereka untuk menerima input teks dan mengirimkan output gambar.
Sebagai contoh, ini adalah “Seorang astronot menunggang kuda dengan gaya Andy Warhol:

sumber: DALLE-2
Apa yang terjadi di sini didasarkan pada model Open AI bernama CLIP. CLIP adalah kependekan dari “Contrastive Language-Image Pre-training” dan merupakan model yang sangat kompleks yang dilatih pada jutaan gambar dan keterangan.
Apa CLIP sangat baik dalam memahami seberapa banyak teks tertentu berhubungan dengan gambar tertentu. Kuncinya di sini bukanlah caption, tetapi seberapa terkait caption tertentu dengan gambar tertentu.
Teknologi semacam ini dinamakan 'kontrastif', dan yang dapat dilakukan CLIP adalah mempelajari semantik dari bahasa alami. Cara CLIP mempelajari ini adalah melalui suatu proses, di mana tujuannya adalah untuk (sekarang mengutip dokumentasi teknologi): “secara bersamaan memaksimalkan kesamaan kosinus antara N pasangan gambar/teks yang dikodekan dengan benar dan meminimalkan kesamaan kosinus antara N 2 – N gambar yang dikodekan salah /pasangan keterangan.”
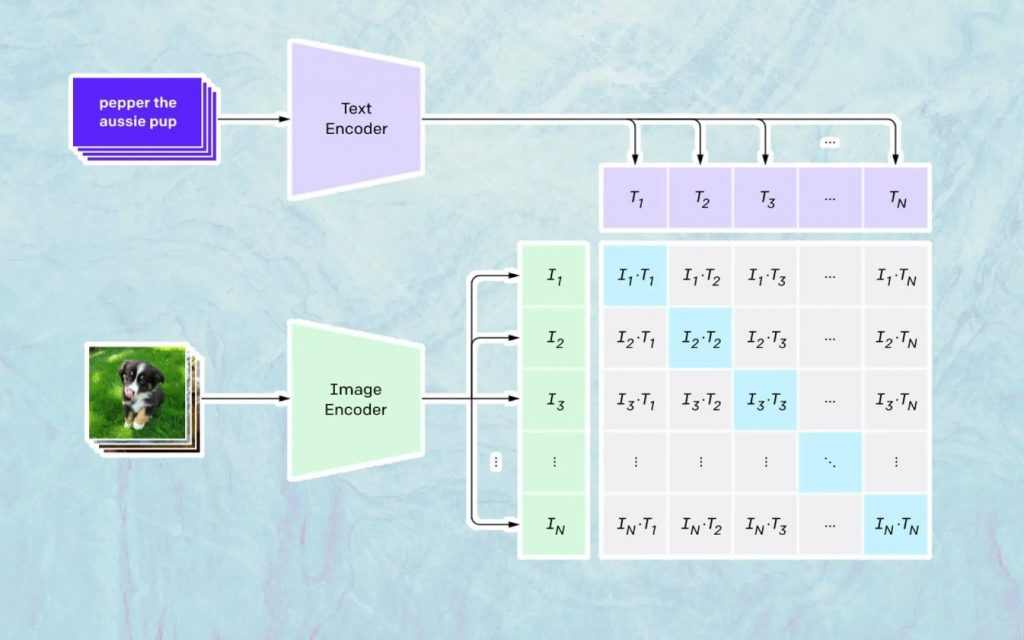
Menghasilkan gambar
Seperti dijelaskan di atas, model CLIP mempelajari ruang representasi di mana ia dapat menentukan, bagaimana pengkodean gambar dan teks terkait.
Tugas selanjutnya adalah menggunakan ruang ini untuk menghasilkan gambar. Untuk tujuan ini Open AI telah mengembangkan model lain bernama GLIDE, yang dapat menggunakan input dari CLIP dan – menggunakan model difusi – melakukan pembuatan gambar.
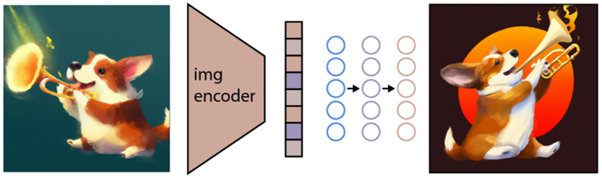
Untuk menjelaskan secara singkat apa itu model difusi, pada dasarnya ini adalah model yang belajar menghasilkan data dengan membalikkan proses noise bertahap. Maaf untuk ini sekarang menjadi sangat teknis, jadi mengutip deskripsi yang ditemukan di dokumentasi Open AI:
“Proses noise dipandang sebagai rantai Markov berparameter yang secara bertahap menambahkan noise ke gambar untuk merusaknya, akhirnya (secara asimtotik) menghasilkan noise Gaussian murni. Model Difusi belajar untuk menavigasi mundur di sepanjang rantai ini, secara bertahap menghilangkan kebisingan melalui serangkaian langkah waktu untuk membalikkan proses ini.”

Jika Anda ingin masuk lebih jauh ke dalam teknologi, kami sarankan untuk membaca artikel luar biasa dari Ryan O'Connor ini.