
Bagaimana menjawab pertanyaan data yang kompleks dengan data Oncrawl, di luar Oncrawl
Diterbitkan: 2022-01-04Salah satu keuntungan Oncrawl untuk SEO perusahaan adalah memiliki akses penuh ke data mentah Anda. Baik Anda menghubungkan data SEO Anda ke BI atau alur kerja ilmu data, melakukan analisis Anda sendiri, atau bekerja dalam pedoman keamanan data untuk organisasi Anda, SEO mentah dan data audit situs web dapat melayani banyak tujuan.
Hari ini kita akan melihat bagaimana menggunakan data Oncrawl untuk menjawab pertanyaan data yang kompleks.
Apa itu pertanyaan data yang kompleks?
Pertanyaan data kompleks adalah pertanyaan yang tidak dapat dijawab oleh pencarian database sederhana, tetapi memerlukan pemrosesan data untuk mendapatkan jawabannya.
Berikut adalah beberapa contoh umum dari pertanyaan data "kompleks" yang sering dimiliki SEO:
- Membuat daftar semua tautan yang mengarah ke halaman yang mengarahkan ke halaman lain dengan status 404
- Membuat daftar semua tautan dan teks jangkarnya yang mengarah ke halaman dalam segmentasi berdasarkan metrik non-URL
Bagaimana menjawab pertanyaan data yang kompleks di Oncrawl
Struktur data Oncrawl dibuat untuk memungkinkan hampir semua situs mencari data hampir secara real time. Ini melibatkan penyimpanan berbagai jenis data dalam kumpulan data yang berbeda untuk memastikan bahwa waktu pencarian dijaga agar tetap minimum di antarmuka. Misalnya, kami menyimpan semua data yang terkait dengan URL dalam satu kumpulan data: kode respons, jumlah tautan keluar, jenis data terstruktur yang ada, jumlah kata, jumlah kunjungan organik… Dan kami menyimpan semua data yang terkait dengan tautan dalam kumpulan data terpisah: target tautan, asal tautan, teks jangkar…
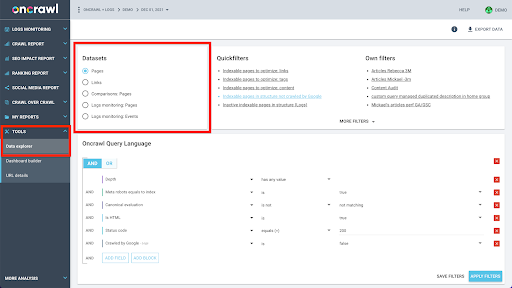
Bergabung dengan kumpulan data ini secara komputasi rumit, dan tidak selalu didukung di antarmuka aplikasi Oncrawl. Jika Anda tertarik untuk mencari sesuatu yang memerlukan pemfilteran satu kumpulan data untuk mencari sesuatu di kumpulan data lain, kami sarankan untuk memanipulasi data mentah Anda sendiri.
Karena semua data Oncrawl tersedia untuk Anda, ada banyak cara untuk menggabungkan kumpulan data dan mengekspresikan kueri kompleks.
Dalam artikel ini, kita akan melihat salah satunya, menggunakan Google Cloud dan BigQuery, yang sesuai untuk kumpulan data yang sangat besar seperti yang ditemui banyak klien kami saat memeriksa data untuk situs dengan halaman bervolume tinggi.
Apa yang Anda butuhkan?
Untuk mengikuti metode yang akan kita bahas di artikel ini, Anda memerlukan akses ke alat berikut:
- Merangkak
- API Oncrawl dengan Ekspor Big Data
- Penyimpanan Google Cloud
- BigQuery
- Skrip Python untuk mentransfer data dari Oncrawl ke BigQuery (Kami akan membuatnya selama artikel ini.)
Sebelum memulai, Anda harus memiliki akses ke laporan perayapan lengkap di Oncrawl.
Cara memanfaatkan data Oncrawl di Google BigQuery
Rencana untuk artikel hari ini adalah sebagai berikut:
- Pertama, kami akan memastikan bahwa Google Cloud Storage diatur untuk menerima data dari Oncrawl.
- Selanjutnya, kita akan menggunakan skrip Python untuk menjalankan ekspor Big Data Oncrawl untuk mengekspor data dari perayapan tertentu ke keranjang Google Cloud Storage. Kami akan mengekspor dua kumpulan data: halaman dan tautan.
- Setelah selesai, kami akan membuat kumpulan data di Google BigQuery. Kami kemudian akan membuat tabel dari masing-masing dua ekspor dalam set data BigQuery.
- Terakhir, kita akan bereksperimen dengan mengkueri kumpulan data individual, dan kemudian kedua kumpulan data bersama-sama untuk menemukan jawaban atas pertanyaan kompleks.
Menyiapkan dalam Google Cloud untuk menerima data Oncrawl
Untuk menjalankan panduan ini di lingkungan sandbox khusus, kami menyarankan Anda untuk membuat proyek Google Cloud baru untuk mengisolasinya dari proyek Anda yang sedang berjalan.
Mari kita mulai di beranda Google Cloud.
Dari beranda Google Cloud, Anda memiliki akses ke banyak hal selain Cloud Storage. Kami tertarik dengan bucket Cloud Storage, yang tersedia dalam tingkat penyimpanan cloud Google Cloud Platform: 
Anda juga dapat mengakses browser Cloud Storage langsung di https://console.cloud.google.com/storage/browser.
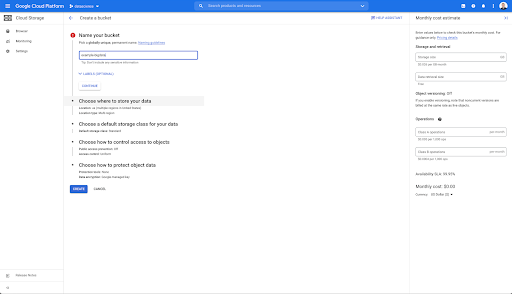
Anda kemudian perlu membuat keranjang Cloud Storage, dan memberikan izin yang benar sehingga Akun Layanan Oncrawl diizinkan untuk menulis ke dalamnya, di bawah awalan pilihan Anda.
Bucket Google Cloud Storage akan berfungsi sebagai penyimpanan sementara untuk menahan ekspor Big Data dari Oncrawl sebelum memuatnya ke Google BigQuery.
Di ember ini, saya juga membuat dua folder: "tautan" dan "halaman": 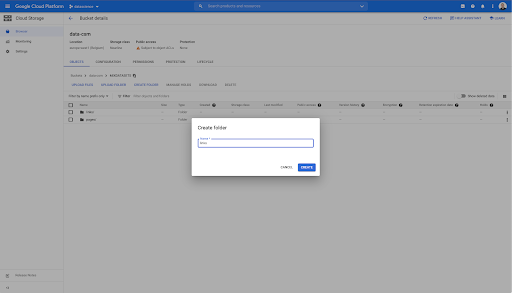
Mengekspor Kumpulan Data dari Oncrawl
Sekarang kita telah menyiapkan ruang di mana kita ingin menyimpan data, kita perlu mengekspornya dari Oncrawl. Mengekspor ke bucket Google Cloud Storage dengan Oncrawl sangat mudah, karena kami dapat mengekspor data dalam format yang tepat, dan menyimpannya langsung ke bucket. Ini menghilangkan langkah-langkah tambahan.
Membuat kunci API
Mengekspor data dari Oncrawl dalam format Parket untuk BigQuery akan memerlukan penggunaan kunci API untuk bertindak di API secara terprogram, atas nama pemilik akun Oncrawl. Aplikasi Oncrawl memungkinkan pengguna untuk membuat kunci API bernama sehingga akun Anda selalu terorganisir dengan baik dan bersih. Kunci API juga dikaitkan dengan izin (cakupan) yang berbeda sehingga Anda dapat mengelola kunci dan tujuannya.
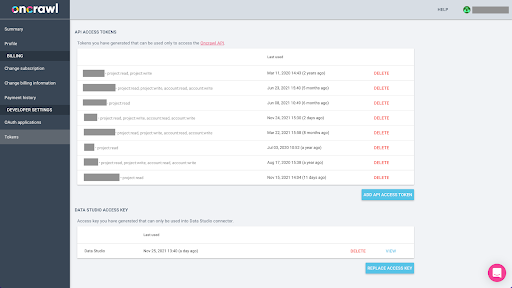
Mari beri nama kunci baru kita 'Kunci sesi Pengetahuan'. Fitur ekspor Big Data memerlukan izin menulis di akun, karena kami membuat ekspor data. Untuk melakukan ini, kita perlu memiliki akses baca di proyek dan akses baca dan tulis di akun.
Sekarang kita memiliki kunci API baru, yang akan saya salin ke clipboard saya.
Perhatikan bahwa, untuk alasan keamanan, Anda hanya dapat menyalin kunci satu kali . Jika Anda lupa menyalin kunci, Anda harus menghapus kunci dan membuat yang baru.
Membuat skrip Python Anda
Saya membuat buku catatan Google Colab untuk ini, tetapi saya akan membagikan kode di bawah ini sehingga Anda dapat membuat alat sendiri atau buku catatan Anda sendiri.
1. Simpan kunci API Anda dalam variabel global
Pertama, kami mem-bootstrap lingkungan dan mendeklarasikan kunci API dalam variabel global bernama "Token Oncrawl". Kemudian, kami mempersiapkan sisa percobaan:
#@title Mengakses API Oncrawl
#@markdown Berikan token API Anda di bawah ini untuk mengizinkan notebook ini mengakses data Oncrawl Anda:
# TOKEN ANDA UNTUK API ONCRAWL
ONCRAWL_TOKEN = "" #@param {ketik:"string"}
!pip install penjara
dari IPython.display impor clear_output
hapus_keluaran()
print('Semua dimuat.') 
2. Buat daftar tarik-turun untuk memilih proyek Oncrawl yang ingin Anda kerjakan
Kemudian, dengan menggunakan kunci itu, kami ingin dapat memilih proyek yang ingin kami mainkan dengan mendapatkan daftar proyek dan membuat widget drop-down dari daftar itu. Dengan menjalankan blok kode kedua, lakukan langkah-langkah berikut:
- Kami akan memanggil API Oncrawl untuk mendapatkan daftar proyek di akun menggunakan kunci API yang baru saja dikirimkan.
- Setelah kami memiliki daftar proyek dari respons API, kami memformatnya sebagai daftar menggunakan nama proyek serta URL awal proyek.
- Kami menyimpan ID proyek yang diberikan dalam respons.
- Kami membangun menu tarik-turun dan menunjukkannya di bawah blok kode.
#@title Pilih situs web yang akan dianalisis dengan memilih proyek Oncrawl yang sesuai
permintaan impor
penjara impor
impor ipywidgets sebagai widget
impor json
# Dapatkan daftar proyek
response = request.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
batas = 1000,
sort='nama:asc'
),
headers={ 'Otorisasi': 'Pembawa '+ONCRAWL_TOKEN }
)
json_res = respon.json()
#siapkan dropdown untuk memungkinkan pengguna memilih proyek
proyek = []
untuk item di json_res['projects']:
project.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
keluaran = widget. Keluaran()
dropdown_purpose = widgets.Dropdown(opsi = proyek, deskripsi="Proyek: ")
def dropdown_project_eventhandler(ubah):
keluaran.clear_output()
dengan keluaran:
tampilan (proyek)
dropdown_purpose.observe(dropdown_project_eventhandler, names='value')
tampilan (dropdown_purpose) Dari menu tarik-turun yang dibuat, Anda dapat melihat daftar lengkap proyek yang dapat diakses oleh kunci API. 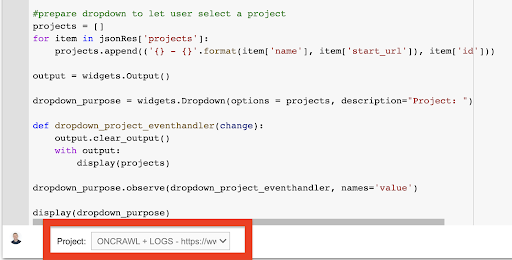
Untuk tujuan demonstrasi hari ini, kami menggunakan proyek demo berdasarkan situs web Oncrawl.
3. Buat daftar tarik-turun untuk memilih profil perayapan dalam proyek yang ingin Anda kerjakan
Selanjutnya, kami akan memutuskan profil perayapan mana yang akan digunakan. Kami ingin memilih profil perayapan dalam proyek ini. Proyek demo memiliki banyak konfigurasi perayapan yang berbeda: 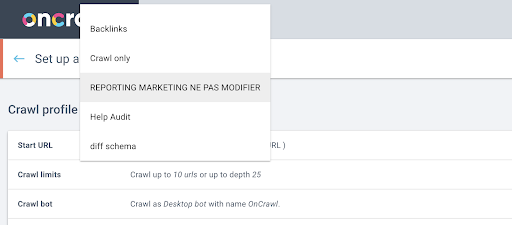
Dalam hal ini, kami sedang melihat proyek yang sering digunakan oleh tim Oncrawl untuk eksperimen, jadi saya akan memilih profil perayapan yang digunakan oleh tim pemasaran untuk memantau kinerja situs web Oncrawl. Karena ini seharusnya menjadi profil perayapan paling stabil, ini adalah pilihan yang baik untuk eksperimen hari ini.
Untuk mendapatkan profil perayapan, kami akan menggunakan API Oncrawl, untuk meminta perayapan terakhir dalam setiap profil perayapan dalam proyek:
- Kami bersiap untuk menanyakan API Oncrawl untuk proyek yang diberikan.
- Kami akan meminta semua perayapan dikembalikan dengan urutan menurun menurut tanggal "dibuat pada".
permintaan impor
impor json
impor ipywidgets sebagai widget
project_id = dropdown_purpose.value
# Dapatkan detail proyek (termasuk semua perayapan dalam proyek)
proyek = request.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=Benar, sort="created_at:desc"),
headers={ 'Otorisasi': 'Pembawa '+ONCRAWL_TOKEN }).json()
# Perayapan grup berdasarkan profil perayapan (nama perayapan)
crawls_by_config = {}
mencoba:
untuk perayapan dalam proyek['perayapan']:
jika crawl['status'] di ["selesai"]:
jika crawl['crawl_config']['name'] tidak ada di crawls_by_config.keys():
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
if len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
jika crawl['status'] == "diarsipkan":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = Benar
kecuali Pengecualian sebagai e:
menaikkan Pengecualian("kesalahan {} , {}".format(e, proyek))
# Buat daftar untuk dropdown pilih
list = [("{} ({})".format(k, len(v['crawl_ids'])), k) untuk k, v di crawls_by_config.items()]
dropdown_crawl_configs = widgets.Dropdown(opsi = daftar, deskripsi="Konfigurasi perayapan: ")
def dropdown_cc_eventhandler(ubah):
keluaran.clear_output()
dengan keluaran:
tampilan (crawls_by_config)
if len(crawls_by_config.values()) == 0:
print('Tidak ditemukan perayapan langsung dalam proyek ini')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, nama='nilai')
tampilan (dropdown_crawl_configs)Saat kode ini dijalankan, API Oncrawl akan merespons kami dengan daftar perayapan dengan menurunkan properti "dibuat di".
Kemudian, karena kami hanya ingin fokus pada perayapan yang sudah selesai, kami akan menelusuri daftar perayapan. Untuk setiap crawl dengan status “selesai”, kami akan menyimpan nama profil crawl dan kami akan menyimpan ID crawl.
Kami akan menyimpan paling banyak satu perayapan profil perayapan sehingga kami tidak ingin mengekspos terlalu banyak perayapan.
Hasilnya adalah menu tarik-turun baru ini dibuat dari daftar profil perayapan dalam proyek. Kami akan memilih yang kami inginkan. Ini akan mengambil perayapan terakhir yang dijalankan oleh tim pemasaran: 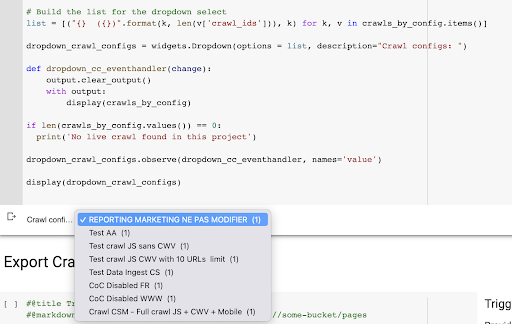
4. Identifikasi perayapan terakhir dengan profil yang ingin kita gunakan
Kami sudah memiliki ID perayapan yang terkait dengan perayapan terakhir di profil yang dipilih. Itu tersembunyi di kamus objek "crawl_by_config". 
Anda dapat memeriksanya dengan mudah di antarmuka: Temukan perayapan terakhir yang diselesaikan dalam analisis profil ini. 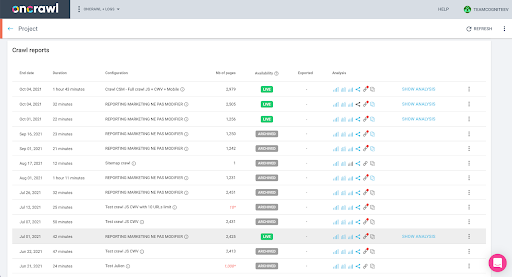
Jika kita klik untuk melihat analisisnya, kita akan melihat bahwa crawl ID diakhiri dengan E617. 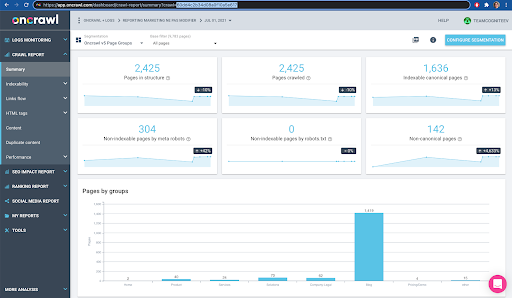
Mari kita perhatikan ID perayapan untuk tujuan demonstrasi hari ini.
Tentu saja, jika Anda sudah tahu apa yang Anda lakukan, Anda dapat melewati langkah-langkah yang baru saja kita bahas untuk memanggil API Oncrawl untuk mendapatkan daftar proyek dan daftar perayapan berdasarkan profil perayapan: Anda sudah memiliki ID perayapan dari antarmuka, dan ID ini adalah semua yang Anda butuhkan untuk menjalankan ekspor.
Langkah-langkah yang telah kami lakukan sejauh ini hanyalah untuk memudahkan proses mendapatkan perayapan terakhir dari profil perayapan yang diberikan dari proyek yang diberikan, mengingat apa yang dapat diakses oleh kunci API. Ini dapat berguna jika Anda memberikan solusi ini kepada pengguna lain, atau jika Anda ingin mengotomatiskannya.
5. Ekspor hasil perayapan
Sekarang, kita akan melihat perintah ekspor:
#@title Memicu ekspor bigdata
#@markdown Berikan Bucket GCS Anda dan awalan gs://some-bucket/pages
# BUKET GCS ANDA
gcs_bucket = #@param {ketik:"string"}
gcs_prefix = #@param {ketik:"string"}
# Dapatkan ID perayapan terakhir dari proyek / profil perayapan yang diberikan
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = daftar_crawl_id[0]
# Muatan template untuk kueri ekspor data
muatan = {
"ekspor_data": {
"data_type": 'halaman',
"resource_id": last_crawl_id,
"output_format": 'parket',
"target": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
# Pemicu ekspor
export = request.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json()
# Tampilkan respons API
tampilan (ekspor)
# Simpan ID ekspor untuk penggunaan di masa mendatang
export_id = ekspor['data_ekspor']['id']Kami ingin mengekspor ke bucket Cloud Storage yang kami siapkan sebelumnya.
Di dalamnya kita akan mengekspor halaman untuk ID perayapan terakhir:
- ID perayapan terakhir diperoleh dari daftar ID perayapan, yang disimpan di suatu tempat di kamus “crawls_by_config”, yang dibuat pada langkah 3.
- Kami ingin memilih yang sesuai dengan menu drop down pada langkah 4, jadi kami menggunakan atribut value dari menu drop down.
- Kemudian, kami mengekstrak atribut crawl_ID. Ini adalah daftar. Kami akan menyimpan 50 item teratas dalam daftar. Kami perlu melakukan ini karena pada langkah 2, seperti yang akan Anda ingat, ketika kami membuat kamus crawls_by_config, kami hanya menyimpan satu ID perayapan per nama konfigurasi.
Saya menyiapkan bidang masukan untuk memudahkan penyediaan keranjang dan awalan Google Cloud Storage, atau folder, tempat kami ingin mengirim ekspor. 
Untuk tujuan demonstrasi, hari ini, kami akan menulis ke folder "dataset campuran", di salah satu folder yang sudah saya siapkan. Saat kami menyiapkan ember kami di Google Cloud Storage, Anda akan ingat bahwa saya menyiapkan folder untuk ekspor "tautan" dan untuk ekspor "halaman".
Untuk ekspor pertama, kami ingin mengekspor halaman ke folder "halaman" untuk ID perayapan terakhir menggunakan format file Parket. 
Pada hasil di bawah, Anda akan melihat payload yang akan dikirim ke titik akhir ekspor data, yang merupakan titik akhir untuk meminta ekspor Big Data menggunakan kunci API:
# Muatan template untuk kueri ekspor data
muatan = {
"ekspor_data": {
"data_type": 'halaman',
"resource_id": last_crawl_id,
"output_format": 'parket',
"target": 'gcs',
"target_parameters": {
"gcs_bucket": gcs_bucket,
"gcs_prefix": gcs_prefix
}
}
}
Ini berisi beberapa elemen, termasuk tipe kumpulan data yang ingin Anda ekspor. Anda dapat mengekspor kumpulan data halaman, kumpulan data link, kumpulan data cluster, atau kumpulan data terstruktur. Jika Anda tidak tahu apa yang dapat dilakukan, Anda dapat memasukkan kesalahan di sini, dan ketika Anda memanggil API, Anda akan mendapatkan pesan yang menyatakan bahwa pilihan untuk tipe data harus berupa halaman atau tautan atau klaster atau data terstruktur. Pesannya terlihat seperti ini:

{'fields': [{'message': 'Bukan pilihan yang valid. Harus salah satu dari "halaman", "tautan", "cluster", "data_terstruktur".',
'nama': 'tipe_data',
'type': 'invalid_choice'}],
'type': 'invalid_request_parameters'}
Untuk tujuan percobaan hari ini, kami akan mengekspor kumpulan data halaman dan kumpulan data tautan dalam ekspor terpisah.
Mari kita mulai dengan kumpulan data halaman. Ketika saya menjalankan blok kode ini, saya telah mencetak output dari panggilan API, yang terlihat seperti ini:
{'data_export': {'data_type': 'halaman',
'export_failure_reason': Tidak ada,
'id': 'XXXXXXXXXXXXXXX',
'output_format': 'parket',
'output_format_parameters': Tidak ada,
'output_row_count': Tidak ada,
'output_size_in_bytes: 1634460016000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'status': 'DIMINTA',
'target': 'gcs',
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/pages/'}}}
Ini memungkinkan saya untuk melihat bahwa ekspor diminta.
Jika kita ingin mengecek status ekspor, caranya sangat mudah. Menggunakan ID ekspor yang kami simpan di akhir blok kode ini, kami dapat meminta status ekspor kapan saja dengan panggilan API berikut:
# STATUS EKSPOR
export_status = request.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json ()
tampilan (status_ekspor)
Ini akan menunjukkan status sebagai bagian dari objek JSON yang dikembalikan:
{'data_export': {'data_type': 'halaman',
'export_failure_reason': Tidak ada,
'id': 'XXXXXXXXXXXXXXX',
'output_format': 'parket',
'output_format_parameters': Tidak ada,
'output_row_count': Tidak ada,
'output_size_in_bytes': Tidak ada,
'diminta_at': 1638350549000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'status': 'EKSPOR',
'target': 'gcs',
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASETS/pages/'}}} Ketika ekspor selesai ( 'status': 'DONE' ), kita dapat kembali ke Google Cloud Storage.
Jika kita melihat ke ember kita, dan kita masuk ke folder "link", belum ada apa-apa di sini karena kita mengekspor halaman. 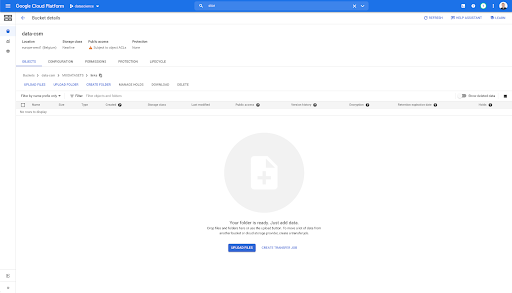
Namun, ketika kita melihat di folder “pages”, kita dapat melihat bahwa ekspor telah berhasil. Kami memiliki file Parket: 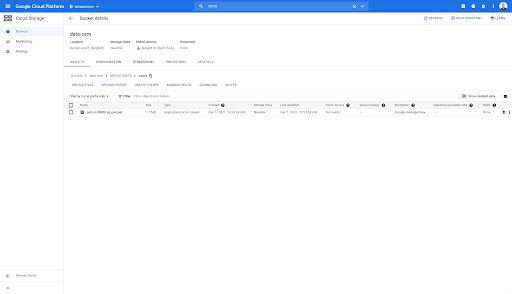
Pada tahap ini, set data halaman siap untuk diimpor di BigQuery, tetapi pertama-tama kita akan mengulangi langkah-langkah di atas untuk mendapatkan file Parket untuk link:
- Pastikan untuk mengatur awalan tautan.
- Pilih tipe data "tautan".
- Jalankan blok kode ini lagi untuk meminta ekspor kedua.

Ini akan menghasilkan file Parket di folder "tautan".
Membuat set data BigQuery
Saat ekspor sedang berjalan, kita dapat melanjutkan dan mulai membuat set data di BigQuery dan mengimpor file Parket ke dalam tabel terpisah. Kemudian kita akan menggabungkan tabel bersama.
Yang ingin kami lakukan sekarang adalah bermain dengan Google Big Query, yang merupakan sesuatu yang tersedia sebagai bagian dari Google Cloud Platform. Anda dapat menggunakan bilah pencarian di bagian atas layar, atau langsung membuka https://console.cloud.google.com/bigquery.
Membuat kumpulan data untuk pekerjaan Anda
Kita harus membuat set data dalam Google BigQuery: 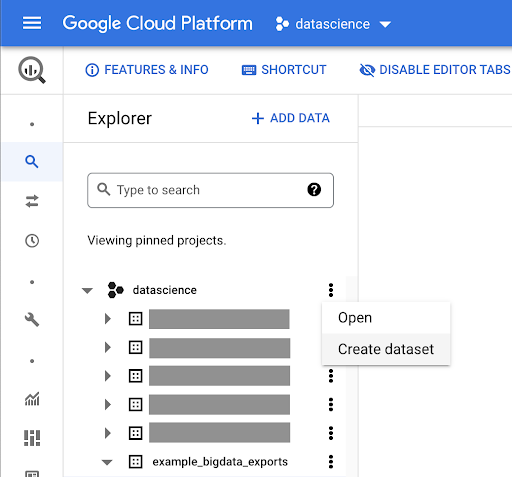
Anda harus memberikan dataset dengan nama, dan memilih lokasi di mana data akan disimpan. Hal ini penting karena akan mengkondisikan dimana data diproses, dan tidak dapat diubah. Hal ini dapat berdampak jika data Anda menyertakan informasi yang dicakup oleh GDPR atau undang-undang privasi lainnya. 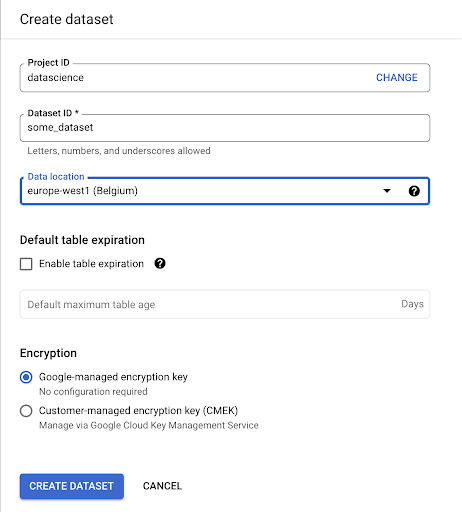
Dataset ini awalnya kosong. Saat Anda membukanya, Anda akan dapat membuat tabel, membagikan kumpulan data, menyalin, menghapus, dan sebagainya.
Membuat tabel untuk data Anda
Kami akan membuat tabel di dataset ini. 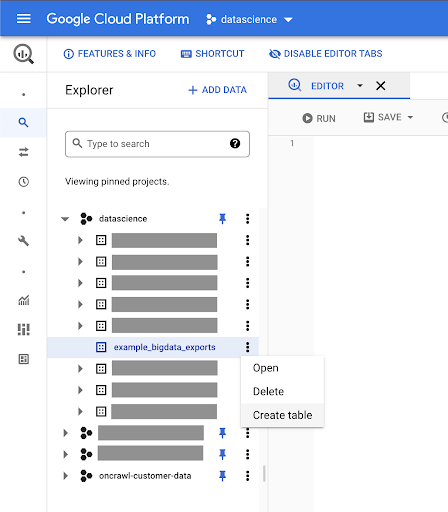
Anda bisa membuat tabel kosong dan kemudian memberikan skema. Skema adalah definisi kolom dalam tabel. Anda dapat menentukan sendiri, atau Anda dapat menelusuri Google Cloud Storage untuk memilih skema dari file.
Kami akan menggunakan opsi terakhir ini. Kami akan menavigasi ke ember kami, lalu ke folder "halaman". Mari kita pilih file halaman. Hanya ada satu file, jadi kami hanya dapat memilih satu, tetapi jika ekspor telah menghasilkan beberapa file, kami dapat memilih semuanya. 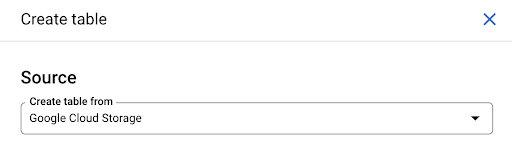
Ketika kami memilih file, secara otomatis mendeteksi bahwa itu dalam format file Parket. Kami ingin membuat tabel bernama "halaman", dan skema akan ditentukan oleh file sumber. 
Saat kami memuat file Parket, itu menyematkan skema. Dengan kata lain, definisi kolom tabel yang kita buat akan disimpulkan dari skema yang sudah ada di dalam file Parket. Di sinilah sebenarnya bagian dari keajaiban terjadi.
Mari kita lanjutkan dan buat tabel dari file Parket. 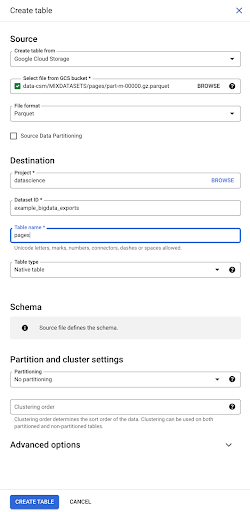
Di bilah sisi kiri, sekarang kita dapat melihat bahwa sebuah tabel muncul di dalam kumpulan data kita, yang persis seperti yang kita inginkan:
Jadi, kami sekarang memiliki skema tabel halaman dengan semua bidang yang telah disimpulkan secara otomatis dari file Parket. Kami memiliki Inrank, kedalaman halaman, jika halaman tersebut adalah redirect dan seterusnya dan seterusnya: 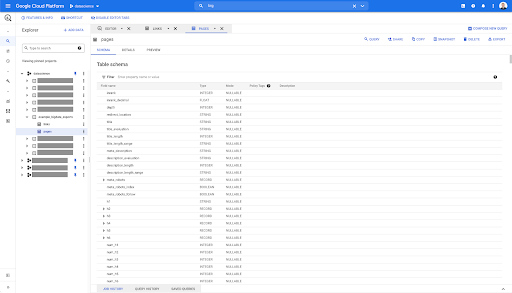
Sebagian besar kolom ini sama dengan yang tersedia dalam Data Studio melalui konektor Oncrawl Data Studio, dan sama dengan yang Anda lihat di Data Explorer di antarmuka Oncrawl. 
Namun, ada beberapa perbedaan. Saat kami bermain dengan ekspor data besar mentah, Anda memiliki semua data mentah.
- Di Data Studio, beberapa bidang diganti namanya, beberapa bidang disembunyikan, dan beberapa bidang ditambahkan, seperti status.
- Di Data Explorer, beberapa bidang adalah apa yang kami sebut "bidang virtual", yang berarti bahwa bidang tersebut mungkin semacam pintasan ke bidang yang mendasarinya. Bidang virtual yang tersedia di Data Explorer ini tidak akan dicantumkan dalam skema, tetapi dapat dibuat ulang berdasarkan apa yang tersedia di file Parket.
Sekarang mari kita tutup tabel ini dan lakukan lagi untuk tautannya.
Untuk tabel tautan, skemanya sedikit lebih kecil. 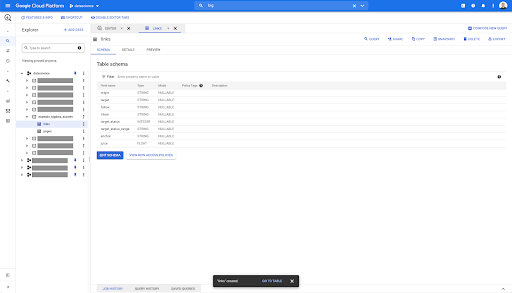
Ini hanya berisi bidang-bidang berikut:
- Asal tautan,
- Sasaran tautan,
- Properti berikut,
- Properti internal,
- status sasaran,
- Rentang status target,
- Teks jangkar, dan
- Jus atau ekuitas dibeli oleh tautan.
Di tabel mana pun di BigQuery, saat Anda mengklik tab pratinjau, Anda memiliki pratinjau tabel tanpa membuat kueri ke database: 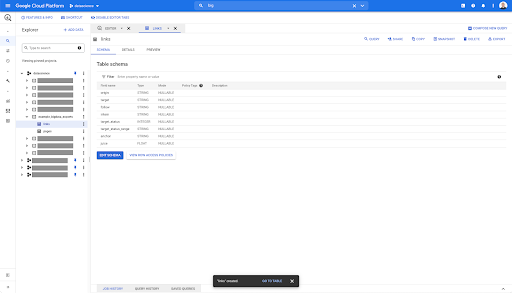
Ini memberi Anda gambaran singkat tentang apa yang tersedia di dalamnya. Dalam pratinjau untuk tabel tautan di atas, Anda memiliki pratinjau untuk setiap baris dan semua kolom.
Di beberapa set data Oncrawl, Anda mungkin melihat beberapa baris yang merentang beberapa baris. Saya tidak punya contoh untuk Anda, tetapi jika ini masalahnya, itu karena beberapa bidang berisi daftar nilai. Misalnya, dalam daftar judul h2 pada halaman, satu baris akan menjangkau beberapa baris di Big Query. Kita akan melihatnya nanti jika kita melihat contohnya.
Membuat kueri Anda
Jika Anda belum pernah membuat kueri di BigQuery, sekaranglah waktunya untuk bermain-main dengan kueri tersebut untuk memahami cara kerjanya. BigQuery menggunakan SQL untuk mencari data.
Cara kerja kueri
Sebagai contoh, mari kita lihat semua URL dan peringkatnya…
PILIH url, peringkat ...
dari kumpulan data halaman…
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` ...
di mana kode status halaman adalah 200…
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 ...
dan hanya menyimpan 10 hasil pertama:
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
Saat kami menjalankan kueri ini, kami akan mendapatkan 10 baris pertama dari daftar halaman dengan kode status 200.
Semua properti ini dapat dimodifikasi. f Saya ingin 1000 baris, bukan 10, saya dapat mengatur 1000 baris:
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
Jika saya ingin mengurutkan, saya dapat melakukannya dengan "urutkan berdasarkan": ini akan memberi saya semua baris yang diurutkan berdasarkan urutan Inrank.
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
Ini adalah pertanyaan pertama saya. Saya dapat menyimpannya jika saya mau, yang akan memberi saya kemampuan untuk menggunakan kembali kueri ini nanti jika saya mau: 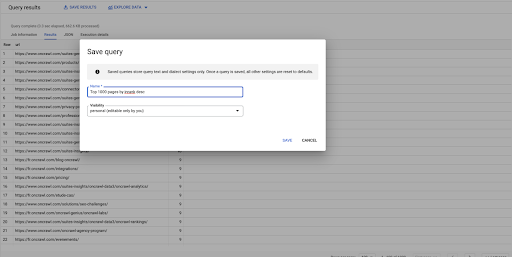
Menggunakan kueri untuk menjawab pertanyaan sederhana: Mencantumkan semua tautan internal ke halaman dengan status 301
Sekarang setelah kita tahu cara membuat kueri, mari kembali ke masalah awal.
Kami ingin menjawab pertanyaan data, baik yang sederhana maupun yang kompleks. Mari kita mulai dengan pertanyaan sederhana, seperti “apa saja tautan internal yang mengarah ke halaman dengan status 301 (dialihkan), dan di mana saya dapat menemukannya?”
Membuat kueri baru
Kita akan mulai dengan menjelajahi cara kerjanya.
Saya akan menginginkan kolom untuk elemen berikut dari database "tautan":
- Asal
- Target
- Kode status sasaran
PILIH asal, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links`
Saya ingin membatasi ini hanya untuk tautan internal, tetapi bayangkan saya tidak ingat nama kolom atau nilai yang menunjukkan apakah tautan itu internal atau eksternal. Saya dapat membuka skema untuk mencarinya, dan menggunakan pratinjau untuk melihat nilainya: 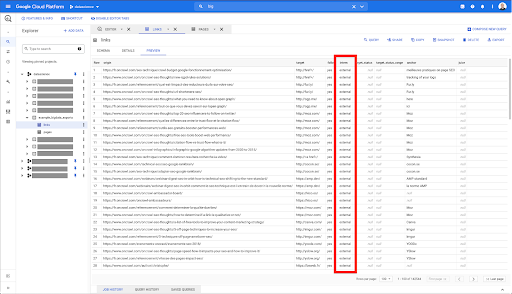
Ini memberi tahu saya bahwa kolom tersebut bernama "intern", dan rentang nilai yang mungkin adalah "eksternal" atau "internal".
Dalam kueri saya, saya ingin menentukan "di mana magang internal", dan membatasi hasil ke 100 pertama untuk saat ini:
PILIH asal, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' LIMIT 100
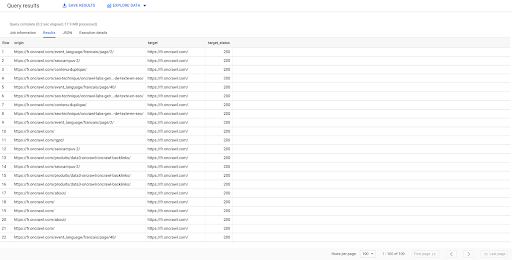
Hasil di atas menunjukkan daftar tautan dengan status targetnya. Kami hanya memiliki tautan internal, dan kami memiliki 100 tautan, sebagaimana ditentukan dalam kueri.
Jika kita hanya ingin memiliki tautan internal ke titik itu ke halaman yang dialihkan, kita dapat mengatakan 'di mana magang seperti internal dan status target sama dengan 301':
PILIH asal, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' AND target_status = 301
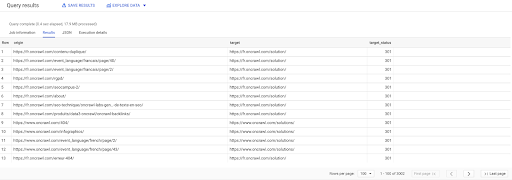
Jika kami tidak tahu berapa banyak dari mereka yang ada, kami dapat menjalankan kueri baru ini dan kami akan melihat bahwa ada 3002 tautan internal dengan status target 301.
Bergabung dengan tabel: menemukan kode status akhir dari tautan yang mengarah ke halaman yang dialihkan
Di situs web, Anda sering kali memiliki tautan ke halaman yang dialihkan. Kami ingin mengetahui kode status halaman tempat mereka diarahkan (atau URL target akhir).
Dalam satu kumpulan data, Anda memiliki informasi tentang tautan: laman asal, laman target, dan kode statusnya (seperti 301), tetapi bukan URL yang dituju oleh laman yang dialihkan. Dan di sisi lain, Anda memiliki informasi tentang pengalihan dan target akhir mereka, tetapi bukan halaman asli tempat tautan ke sana ditemukan.
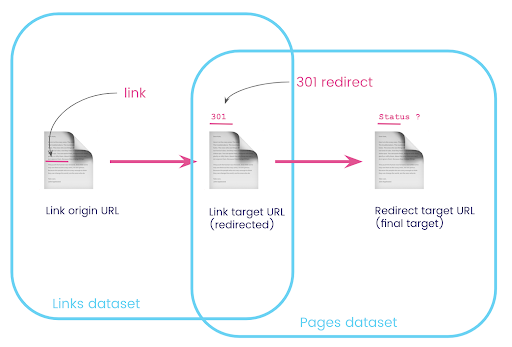
Mari kita uraikan ini:
Pertama, kami ingin tautan ke pengalihan. Mari kita tulis ini. Kami ingin:
- asal.
- Sasaran, tujuan. Target harus memiliki kode status 301.
- Target akhir dari pengalihan.
Dengan kata lain, dalam kumpulan data tautan, kami ingin:
- Asal linknya
- Sasaran tautan
Di kumpulan data halaman, kami ingin:
- Semua target yang dialihkan
- Target akhir dari pengalihan
Ini akan memberi kita pertanyaan seperti:
SELECT url, final_redirect_location, final_redirect_status FROM `datascience-oncrawl.example_bigdata_exports.pages` SEBAGAI halaman WHERE status_code = 301 OR status_code = 302
Ini akan memberi saya bagian pertama dari persamaan.
Sekarang saya membutuhkan semua tautan yang tertaut ke halaman yang merupakan hasil dari kueri yang baru saja saya buat, menggunakan alias untuk kumpulan data saya, dan menggabungkannya pada URL target tautan dan URL halaman. Ini sesuai dengan area yang tumpang tindih dari dua kumpulan data dalam diagram di awal bagian ini.
PILIH link.asal, halaman.url, halaman.final_redirect_location, halaman.final_redirect_status DARI `halaman AS `datascience-oncrawl.example_bigdata_exports.pages` IKUTI Tautan AS `datascience-oncrawl.example_bigdata_exports.links` PADA link.target = halaman.url DI MANA halaman.status_code = 301 ATAU halaman.status_code = 302 DIPESAN OLEH asal ASC
Dalam hasil Kueri, saya dapat mengganti nama kolom untuk memperjelas, tetapi saya sudah dapat melihat bahwa saya memiliki tautan dari halaman di kolom pertama, yang menuju ke halaman di kolom kedua, yang pada gilirannya dialihkan ke halaman di kolom ketiga. Di kolom keempat, saya memiliki kode status target akhir: 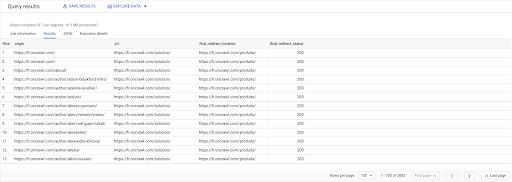
Sekarang saya dapat mengetahui tautan mana yang mengarah ke halaman yang dialihkan yang tidak mencapai 200 halaman. Mungkin mereka 404, misalnya, yang memberi saya daftar prioritas tautan untuk diperbaiki.
Kami melihat sebelumnya cara menyimpan kueri. Kami juga dapat menyimpan hasil, hingga 16000 baris hasil: 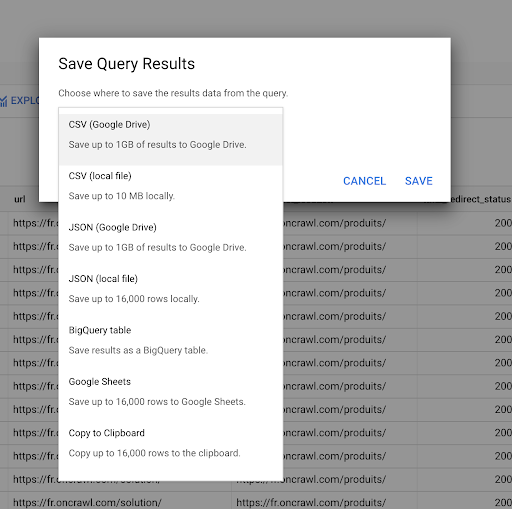
Kami kemudian dapat menggunakan hasil ini dalam berbagai cara. Berikut adalah beberapa contoh:
- Kami dapat menyimpan ini sebagai file CSV atau JSON secara lokal.
- Kami dapat menyimpannya sebagai spreadsheet Google Spreadsheet dan membagikannya dengan anggota tim lainnya.
- Kami juga dapat mengekspornya langsung ke Data Studio.
Data sebagai keunggulan strategis
Dengan semua kemungkinan ini, menggunakan jawaban atas pertanyaan kompleks Anda secara strategis itu mudah. Anda mungkin sudah memiliki pengalaman menghubungkan hasil BigQuery ke Data Studio atau platform visualisasi data lainnya, atau Anda mungkin sudah memiliki proses yang mendorong informasi ke tim engineering atau bahkan ke intelijen bisnis atau alur kerja analisis data.
Jika Anda telah menyertakan langkah-langkah dalam artikel ini sebagai bagian dari proses, ingatlah bahwa Anda dapat mengotomatiskan semua langkah di BigQuery: semua tindakan yang kami lakukan dalam artikel ini juga dapat diakses melalui BigQuery API. Ini berarti bahwa mereka dapat dijalankan secara terprogram sebagai bagian dari skrip atau alat khusus.
Apa pun langkah Anda selanjutnya, langkah pertama selalu akses ke SEO mentah dan data situs web. Kami percaya bahwa akses ke data ini adalah salah satu bagian terpenting dari analisis teknis: dengan Oncrawl, Anda akan selalu memiliki akses penuh ke data mentah Anda.
Akses ke data juga berarti bahwa Anda dapat melampaui apa yang mungkin dilakukan di antarmuka Oncrawl, dan menjelajahi semua hubungan antara data Anda, tidak peduli seberapa rumit pertanyaan yang Anda ajukan.