
Que sont les vecteurs de mots et comment le balisage structuré les suralimente
Publié: 2021-07-28Comment définissez-vous les vecteurs de mots ? Dans cet article, je vais vous présenter le concept de vecteurs de mots. Nous passerons en revue différents types d'incorporations de mots et, plus important encore, le fonctionnement des vecteurs de mots. Nous pourrons alors voir l'impact des vecteurs de mots sur le référencement, ce qui nous amènera à comprendre comment le balisage Schema.org pour les données structurées peut vous aider à tirer parti des vecteurs de mots dans le référencement.
Continuez à lire cet article si vous souhaitez en savoir plus sur ces sujets.
Plongeons dedans.
Que sont les vecteurs de mots ?
Les vecteurs de mots (également appelés incorporations de mots) sont un type de représentation de mots qui permet à des mots ayant des significations similaires d'avoir une représentation égale.
En termes simples : un vecteur de mot est une représentation vectorielle d'un mot particulier.
Selon Wikipédia :
Il s'agit d'une technique utilisée dans le traitement du langage naturel (TLN) pour représenter des mots pour l'analyse de texte, généralement sous la forme d'un vecteur à valeur réelle qui encode la signification du mot afin que les mots proches dans l'espace vectoriel aient probablement des significations similaires.
L'exemple suivant nous aidera à mieux comprendre cela :
Regardez ces phrases similaires :
Passez une bonne journée . et bonne journée.
Ils ont à peine une signification différente. Si nous construisons un vocabulaire exhaustif (appelons-le V), il aurait V = {Have, a, good, great, day} combinant tous les mots. Nous pourrions coder le mot comme suit.
La représentation vectorielle d'un mot peut être un vecteur codé à chaud où 1 représente la position où le mot existe et 0 représente le reste
Avoir = [1,0,0,0,0]
un=[0,1,0,0,0]
bon=[0,0,1,0,0]
grand=[0,0,0,1,0]
jour=[0,0,0,0,1]
Supposons que notre vocabulaire ne comporte que cinq mots : roi, reine, homme, femme et enfant. Nous pourrions coder les mots comme suit :
Roi = [1,0,0,0,0]
Reine = [0,1,0,0,0]
Homme = [0,0,1,00]
Femme = [0,0,0,1,0]
Enfant = [0,0,0,0,1]
Types d'incorporation de mots (vecteurs de mots)
L'incorporation de mots est l'une de ces techniques dans laquelle les vecteurs représentent du texte. Voici quelques-uns des types d'incorporation de mots les plus populaires :
- Intégration basée sur la fréquence
- Intégration basée sur la prédiction
Nous n'approfondirons pas ici l'intégration basée sur la fréquence et l'intégration basée sur la prédiction, mais vous trouverez peut-être les guides suivants utiles pour comprendre les deux :
Une compréhension intuitive des incorporations de mots et une introduction rapide au sac de mots (BOW) et au TF-IDF pour créer des fonctionnalités à partir de texte
Une brève introduction à WORD2Vec
Alors que l'intégration basée sur la fréquence a gagné en popularité, il y a encore un vide dans la compréhension du contexte des mots et limité dans leurs représentations de mots.
L'intégration basée sur la prédiction (WORD2Vec) a été créée, brevetée et introduite dans la communauté NLP en 2013 par une équipe de chercheurs dirigée par Tomas Mikolov chez Google.
Selon Wikipedia, l'algorithme word2vec utilise un modèle de réseau de neurones pour apprendre les associations de mots à partir d'un grand corpus de texte (ensemble de textes large et structuré).
Une fois formé, un tel modèle peut détecter des mots synonymes ou suggérer des mots supplémentaires pour une phrase partielle. Par exemple, avec Word2Vec, vous pouvez facilement créer de tels résultats : Roi - homme + femme = Reine, ce qui était considéré comme un résultat presque magique.
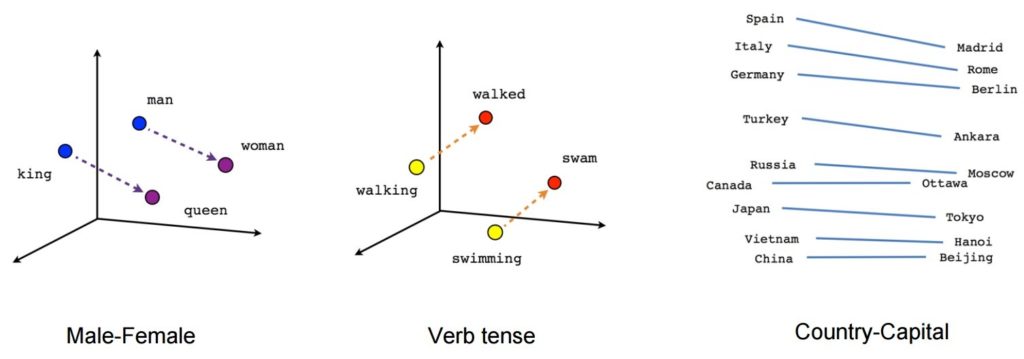 Source de l'image : Tensorflow
Source de l'image : Tensorflow
- [roi] - [homme] + [femme] ~= [reine] (une autre façon de penser à cela est que [roi] - [reine] encode uniquement la partie genrée de [monarque])
- [marcher] – [nager] + [nager] ~= [marcher] (ou [nager] – [nager] encode simplement le « passé » du verbe)
- [madrid] – [espagne] + [france] ~= [paris] (ou [madrid] – [espagne] ~= [paris] – [france] qui est vraisemblablement à peu près « capitale »)
Source : Brainslab numérique
Je sais que c'est un peu technique, mais Stitch Fix a rédigé un article fantastique sur les relations sémantiques et les vecteurs de mots.
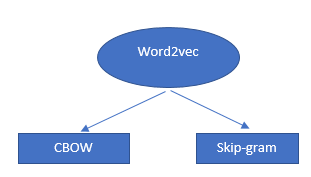
L'algorithme Word2Vec n'est pas un algorithme unique mais une combinaison de deux techniques qui utilise quelques méthodes d'IA pour faire le pont entre la compréhension humaine et la compréhension de la machine. Cette technique est essentielle pour résoudre de nombreux PNL problèmes.
Ces deux techniques sont :
- – CBOW (Continuous bag of words) ou modèle CBOW
- – Modèle de saut de gramme.
Les deux sont des réseaux de neurones peu profonds qui fournissent des probabilités pour les mots et se sont avérés utiles dans des tâches telles que la comparaison de mots et l'analogie de mots.
Comment fonctionnent les vecteurs de mots et word2vecs
Word Vector est un modèle d'IA développé par Google, et il nous aide à résoudre des tâches NLP très complexes.
"Les modèles Word Vector ont un objectif central que vous devez connaître :
C'est un algorithme qui aide Google à détecter les relations sémantiques entre les mots.
Chaque mot est encodé dans un vecteur (sous la forme d'un nombre représenté en plusieurs dimensions) pour correspondre aux vecteurs de mots qui apparaissent dans un contexte similaire. Par conséquent, un vecteur dense est formé pour le texte.
Ces modèles vectoriels mappent des phrases sémantiquement similaires à des points proches en fonction de l'équivalence, des similitudes ou de la parenté des idées et du langage
[Étude de cas] Stimuler la croissance sur de nouveaux marchés avec le référencement sur la page
 Lire l'étude de cas
Lire l'étude de casWord2Vec - Comment ça marche ?
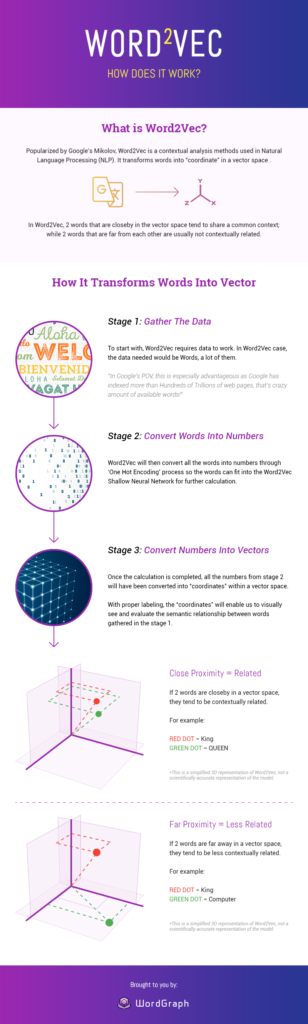
Source de l'image : Seopressor
Avantages et inconvénients de Word2Vec
Nous avons vu que Word2vec est une technique très efficace pour générer une similarité distributionnelle. J'ai énuméré certains de ses autres avantages ici:
- Il n'y a aucune difficulté à comprendre les concepts de Word2vec. Word2Vec n'est pas si complexe que vous ne soyez pas conscient de ce qui se passe dans les coulisses.
- L'architecture de Word2Vec est très puissante et facile à utiliser. Comparé à d'autres techniques, il est rapide à former.
- La formation est presque entièrement automatisée ici, de sorte que les données étiquetées par l'homme ne sont plus nécessaires.
- Cette technique fonctionne à la fois pour les petits et les grands ensembles de données. En conséquence, c'est un modèle facile à mettre à l'échelle.
- Si vous connaissez les concepts, vous pouvez facilement reproduire l'intégralité du concept et de l'algorithme.
- Il capture exceptionnellement bien la similarité sémantique.
- Précis et efficace en termes de calcul
- Comme cette approche n'est pas supervisée, elle est très économique en termes d'efforts.
Défis de Word2Vec
Le concept Word2vec est très efficace, mais vous pouvez trouver quelques points un peu difficiles. Voici quelques-uns des défis les plus courants.
- Lors du développement d'un modèle word2vec pour votre ensemble de données, le débogage peut être un défi majeur, car le modèle word2vec est facile à développer mais difficile à déboguer.
- Il ne traite pas des ambiguïtés. Ainsi, dans le cas de mots à sens multiples, Embedding reflétera la moyenne de ces sens dans l'espace vectoriel.
- Impossible de gérer les mots inconnus ou OOV : Le plus gros problème avec word2vec est l'incapacité de gérer les mots inconnus ou hors vocabulaire (OOV).
Vecteurs de mots : un changement de jeu dans l'optimisation des moteurs de recherche ?
De nombreux experts en référencement pensent que Word Vector affecte le classement d'un site Web dans les résultats des moteurs de recherche.
Au cours des cinq dernières années, Google a introduit deux mises à jour d'algorithmes qui mettent clairement l'accent sur la qualité du contenu et l'exhaustivité de la langue.
Prenons un peu de recul et parlons des mises à jour :
Colibri
En 2013, Hummingbird a donné aux moteurs de recherche la capacité d'analyse sémantique. En utilisant et en incorporant la théorie de la sémantique dans leurs algorithmes, ils ont ouvert une nouvelle voie vers le monde de la recherche.
Google Hummingbird a été le plus grand changement apporté au moteur de recherche depuis Caffeine en 2010. Il tire son nom du fait qu'il est "précis et rapide".
Selon Search Engine Land, Hummingbird accorde plus d'attention à chaque mot d'une requête, garantissant que l'intégralité de la requête est prise en compte, plutôt que des mots particuliers.

L'objectif principal de Hummingbird était de fournir de meilleurs résultats en comprenant le contexte de la requête plutôt qu'en renvoyant des résultats pour des mots clés spécifiques.
"Google Hummingbird est sorti en septembre 2013."
RankBrain
En 2015, Google a annoncé RankBrain, une stratégie intégrant l'intelligence artificielle (IA).
RankBrain est un algorithme qui aide Google à décomposer les requêtes de recherche complexes en requêtes plus simples. RankBrain convertit les requêtes de recherche du langage "humain" en un langage que Google peut facilement comprendre.
Google a confirmé l'utilisation de RankBrain le 26 octobre 2015 dans un article publié par Bloomberg.
BERT
Le 21 octobre 2019, BERT a commencé à se déployer dans le système de recherche de Google
BERT signifie Représentations d'encodeurs bidirectionnels à partir de transformateurs, une technique basée sur un réseau de neurones utilisée par Google pour la pré-formation en traitement du langage naturel (NLP).
En bref, BERT aide les ordinateurs à comprendre le langage plus comme les humains, et c'est le plus grand changement dans la recherche depuis que Google a introduit RankBrain.
Il ne remplace pas RankBrain, mais plutôt une méthode supplémentaire pour comprendre le contenu et les requêtes.
Google utilise BERT dans son système de classement en complément. L'algorithme RankBrain existe toujours pour certaines requêtes et continuera d'exister. Mais lorsque Google estime que BERT peut mieux comprendre une requête, il l'utilise.
Pour plus d'informations sur BERT, consultez cet article de Barry Schwartz, ainsi que la plongée en profondeur de Dawn Anderson.
Classez votre site avec Word Vectors
Je suppose que vous avez déjà créé et publié un contenu unique, et même après l'avoir peaufiné encore et encore, cela n'améliore pas votre classement ou votre trafic.
Vous vous demandez pourquoi cela vous arrive ?
C'est peut-être parce que vous n'avez pas inclus Word Vector : le modèle d'IA de Google.
- La première étape consiste à identifier les vecteurs de mots des 10 meilleurs classements SERP pour votre créneau.
- Sachez quels mots clés vos concurrents utilisent et ce que vous pourriez ignorer.
En appliquant Word2Vec, qui tire parti des techniques avancées de traitement du langage naturel et du cadre d'apprentissage automatique, vous pourrez tout voir en détail.
Mais ceux-ci sont possibles si vous connaissez les techniques d'apprentissage automatique et de PNL, mais nous pouvons appliquer des vecteurs de mots dans le contenu à l'aide de l'outil suivant :
WordGraph, le premier outil vectoriel de mots au monde
Cet outil d'intelligence artificielle est créé avec des réseaux de neurones pour le traitement du langage naturel et formé avec l'apprentissage automatique.
Basé sur l'Intelligence Artificielle, WordGraph analyse votre contenu et vous aide à améliorer sa pertinence par rapport au Top 10 des sites de classement.
Il suggère des mots-clés mathématiquement et contextuellement liés à votre mot-clé principal.
Personnellement, je l'associe à BIQ, un puissant outil de référencement qui fonctionne bien avec WordGraph.
Ajoutez votre contenu à l'outil d'intelligence de contenu intégré à Biq. Il vous montrera toute une liste de conseils SEO sur la page que vous pouvez ajouter si vous souhaitez vous classer en première position.
Vous pouvez voir comment fonctionne l'intelligence de contenu dans cet exemple. Les listes vous aideront à maîtriser le référencement sur la page et à vous classer en utilisant des méthodes exploitables !
Comment optimiser les vecteurs de mots : utiliser le balisage de données structurées
Le balisage de schéma, ou données structurées, est un type de code (écrit en JSON, Java-Script Object Notation) créé à l'aide du vocabulaire schema.org qui aide les moteurs de recherche à explorer, organiser et afficher votre contenu.
Comment ajouter des données structurées
Les données structurées peuvent être facilement ajoutées à votre site Web en ajoutant un script en ligne dans votre html
Un exemple ci-dessous montre comment définir les données structurées de votre organisation dans le format le plus simple possible.
Pour générer le Schema Markup, j'utilise ce Schema Markup Generator (JSON-LD).
Voici l'exemple en direct de balisage de schéma pour https://www.telecloudvoip.com/. Vérifiez le code source et recherchez JSON.
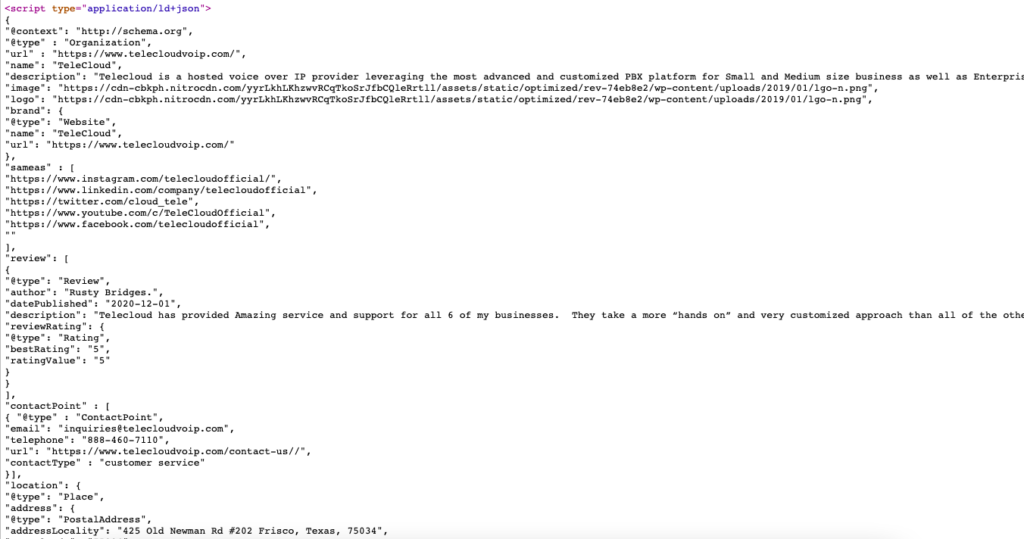
Une fois le code de balisage de schéma créé, utilisez le test de résultats enrichis de Google pour voir si la page prend en charge les résultats enrichis.
Vous pouvez également utiliser l'outil d'audit de site Semrush pour explorer les éléments de données structurées pour chaque URL et identifier les pages éligibles pour figurer dans les résultats enrichis. 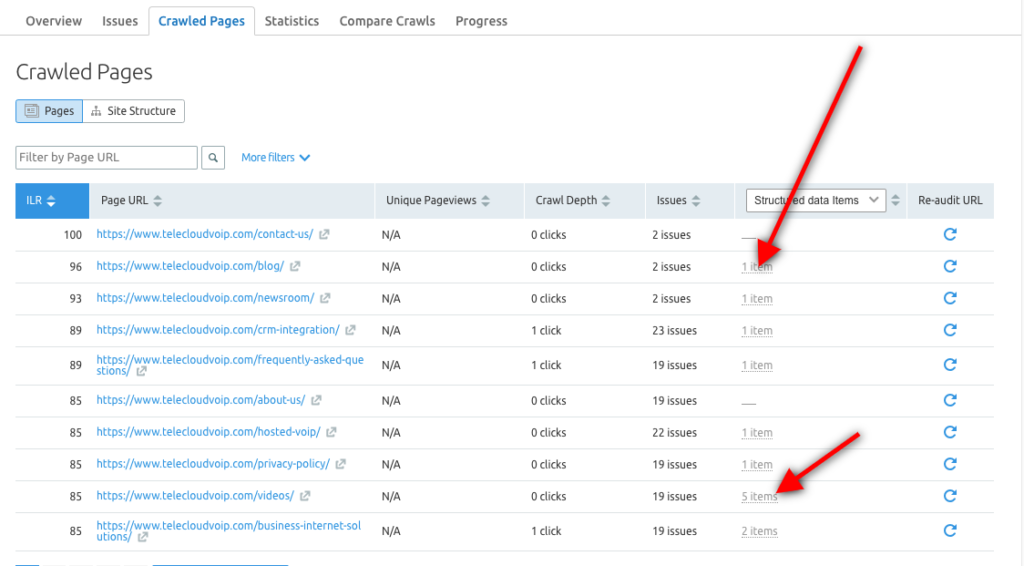
Pourquoi les données structurées sont-elles importantes pour le référencement ?
Les données structurées sont importantes pour le référencement, car elles aident Google à comprendre de quoi parlent votre site Web et vos pages, ce qui permet un classement plus précis de votre contenu.
Les données structurées améliorent à la fois l'expérience du robot de recherche et l'expérience de l'utilisateur en améliorant les SERP (pages de résultats des moteurs de recherche) avec plus d'informations et de précision.
Pour voir l'impact dans la recherche Google, accédez à la Search Console et sous Performances > Résultat de la recherche > Apparence de la recherche, vous pouvez afficher une répartition de tous les types de résultats enrichis comme les « vidéos » et les « FAQ » et voir les impressions et les clics organiques qu'ils ont générés. pour votre contenu.
Voici quelques avantages des données structurées :
- Les données structurées prennent en charge la recherche sémantique
- Il prend également en charge votre E‑AT (expertise, autorité et confiance)
- Le fait de disposer de données structurées peut également augmenter les taux de conversion, car davantage de personnes verront vos annonces, ce qui augmente la probabilité qu'elles achètent chez vous.
- En utilisant des données structurées, les moteurs de recherche sont mieux à même de comprendre votre marque, votre site Web et votre contenu.
- Il sera plus facile pour les moteurs de recherche de distinguer les pages de contact, les descriptions de produits, les pages de recettes, les pages d'événements et les avis des clients.
- À l'aide de données structurées, Google crée un graphe de connaissances et un panel de connaissances plus précis et plus précis sur votre marque.
- Ces améliorations peuvent entraîner davantage d'impressions et de clics organiques.
Les données structurées sont actuellement utilisées par Google pour améliorer les résultats de recherche. Lorsque les internautes recherchent vos pages Web à l'aide de mots clés, les données structurées peuvent vous aider à obtenir de meilleurs résultats. Les moteurs de recherche remarqueront davantage votre contenu si nous ajoutons le balisage Schema.
Vous pouvez implémenter le balisage de schéma sur un certain nombre d'éléments différents. Voici quelques domaines où le schéma peut être appliqué :
- Des articles
- Billets de blog
- articles de presse
- Événements
- Des produits
- Vidéos
- Prestations de service
- Commentaires
- Notes globales
- Restaurants
- Entreprises locales
Voici une liste complète des éléments que vous pouvez baliser avec un schéma.
Données structurées avec incorporation d'entités
Le terme « entité » fait référence à une représentation de tout type d'objet, de concept ou de sujet. Une entité peut être une personne, un film, un livre, une idée, un lieu, une entreprise ou un événement.
Alors que les machines ne peuvent pas vraiment comprendre les mots, avec les incorporations d'entités, elles sont capables de comprendre facilement la relation entre roi - reine = mari - femme
Les intégrations d'entités fonctionnent mieux que les encodages à chaud
L'algorithme de vecteur de mots est utilisé par Google pour découvrir les relations sémantiques entre les mots, et lorsqu'il est combiné avec des données structurées, nous nous retrouvons avec un web sémantiquement amélioré.
En utilisant des données structurées, vous contribuez à un web plus sémantique. Il s'agit d'un site Web amélioré où nous décrivons les données dans un format lisible par machine.
Les données sémantiques structurées sur votre site Web aident les moteurs de recherche à faire correspondre votre contenu avec le bon public. L'utilisation de la PNL, de l'apprentissage automatique et de l'apprentissage en profondeur aide à réduire l'écart entre ce que les gens recherchent et les titres disponibles.
Dernières pensées
Comme vous comprenez maintenant le concept de vecteurs de mots et son importance, vous pouvez rendre votre stratégie de recherche organique plus efficace et plus efficiente en utilisant des vecteurs de mots, des incorporations d'entités et des données sémantiques structurées.
Afin d'obtenir le classement, le trafic et les conversions les plus élevés, vous devez utiliser des vecteurs de mots, des intégrations d'entités et des données sémantiques structurées pour démontrer à Google que le contenu de votre page Web est exact, précis et digne de confiance.