
Utilisation de Python et des sitemaps pour auditer les stratégies de contenu
Publié: 2020-10-08L'intérêt pour ce qui peut être fait pour le compte du SEO avec Python Libraries n'est plus un secret. Cependant, la plupart des personnes ayant peu d'expérience en programmation ont des difficultés à importer et à utiliser un grand nombre de bibliothèques ou à pousser, les résultats au-delà de ce que tout robot d'exploration ou outil de référencement ordinaire peut faire.
C'est pourquoi une bibliothèque Python créée spécifiquement pour le référencement, le SEM, le SMO, la vérification SERP et l'analyse de contenu est utile pour tout le monde.
Dans cet article, nous allons jeter un œil à quelques-unes des choses qui peuvent être faites avec la bibliothèque Python Advertools pour le référencement, créée et développée par Elias Dabbas, et pour laquelle je vois un gros potentiel dans les capacités de référencement, de PPC et de codage. en très peu de temps. De plus, nous utiliserons des scripts Python personnalisés avec d'autres bibliothèques Python de manière éducative et adaptative.
Nous allons examiner ce que l'on peut apprendre pour le référencement d'un sitemap grâce à la fonction sitemap_to_df d'Elias Dabbas qui aide au téléchargement et à l'analyse des sitemaps XML (Un sitemap est un document au format XML utilisé pour signaler les URL explorables et indexables aux moteurs de recherche.)
Cet article vous montrera comment vous pouvez écrire des codes Python personnalisés pour analyser différents sites Web en fonction de leur structure différente, comment interpréter les données en termes de référencement et comment penser comme un moteur de recherche en ce qui concerne les profils de contenu, les URL et les structures de site. .
Analyser l'échelle de contenu et la stratégie d'un site Web en fonction de son plan de site
Un sitemap est un composant d'un site Web qui peut capturer de nombreux types de données différents, tels que la fréquence à laquelle un site Web publie du contenu, les catégories de contenu, les dates de publication, les informations sur l'auteur, le sujet du contenu…
Dans des conditions normales, vous pouvez gratter un sitemap avec scrapy, le convertir en DataFrame avec Pandas et l'interpréter avec de nombreuses bibliothèques auxiliaires différentes si vous le souhaitez.
Mais dans cet article, nous n'utiliserons que Advertools et certaines méthodes et attributs de la bibliothèque Pandas. Certaines bibliothèques seront activées pour visualiser les données que nous avons acquises.
Plongeons-nous directement et sélectionnons un site Web pour utiliser son plan de site afin de conclure quelques informations SEO importantes.
Extraction et création de cadres de données à partir de plans de site avec Advertools
Dans Advertools, vous pouvez découvrir, parcourir et combiner tous les sitemaps d'un site Web avec une seule ligne de code.
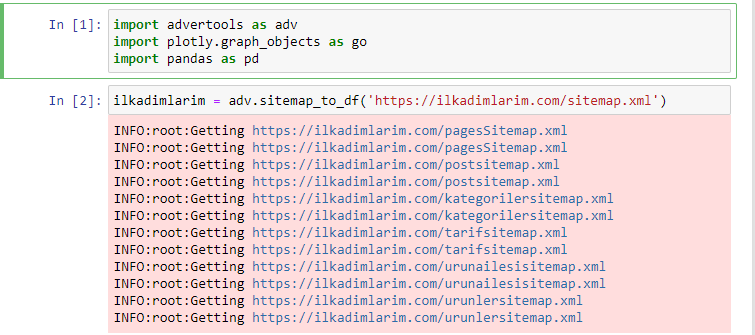
J'adore utiliser Jupyter Notebook au lieu d'un éditeur de code ou d'un IDE classique.
Dans la première cellule, nous avons importé Pandas et Advertools pour la collecte et l'organisation des données et Plotly.graph_objects pour la visualisation des données.
La commande adv.sitemap_to_df('sitemap address') collecte simplement tous les sitemaps et les unifie en tant que DataFrame.
Si vous faites la même chose en utilisant Pandas et Advertools, vous pouvez découvrir quelle URL est disponible dans quel sitemap.
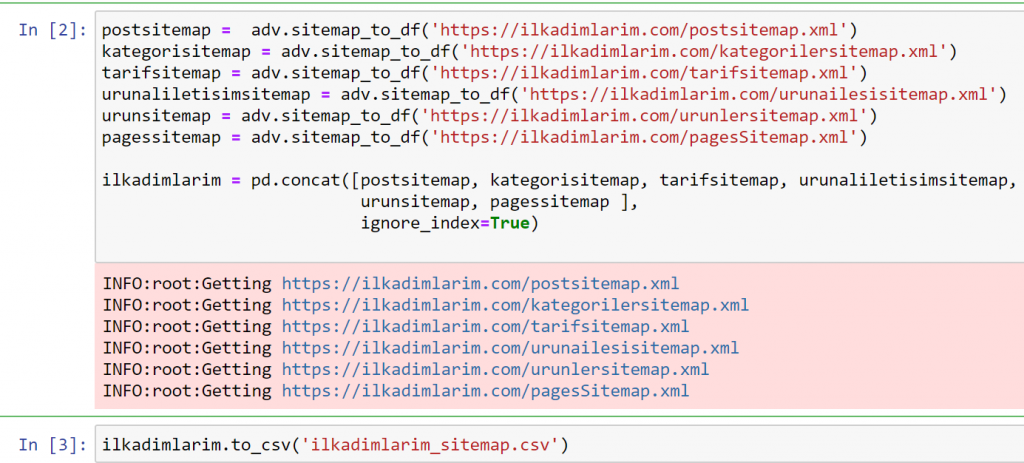
Dans l'exemple ci-dessus, nous avons extrait les mêmes sitemaps séparément, puis les avons combinés avec la commande pd.concat et avons transféré le résultat au format CSV. L'exemple précédent utilisait le fichier d'index du sitemap, auquel cas la fonction va récupérer tous les autres sitemaps. Vous avez donc la possibilité de sélectionner des sitemaps spécifiques comme nous l'avons fait ici si vous êtes intéressé par une section particulière du site Web.
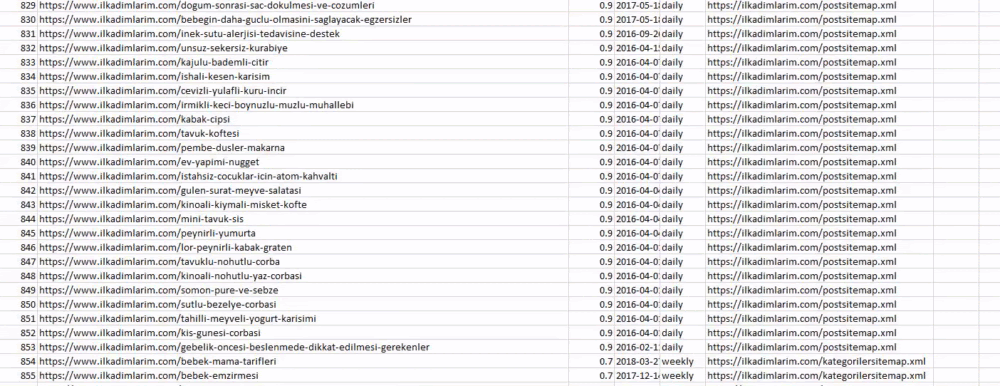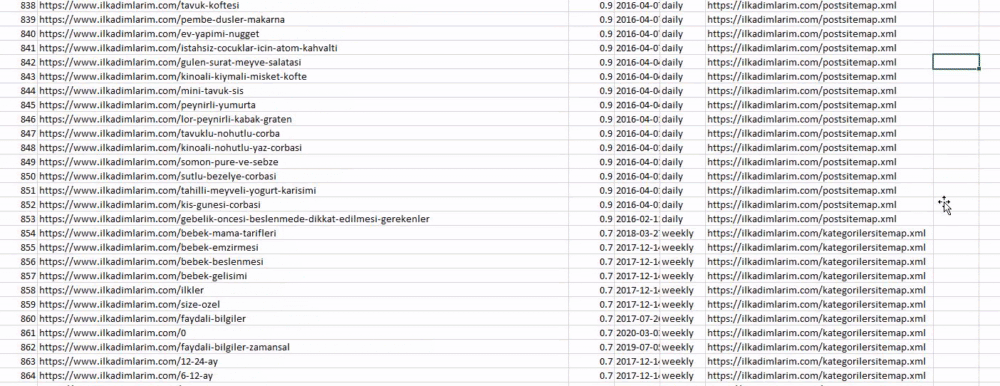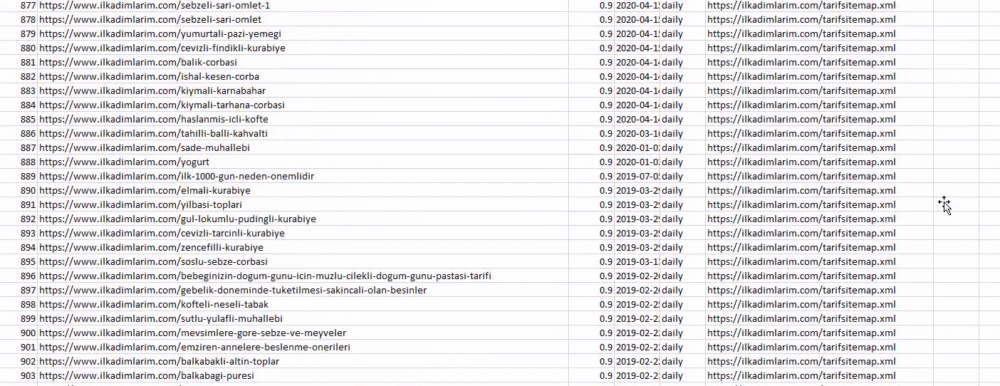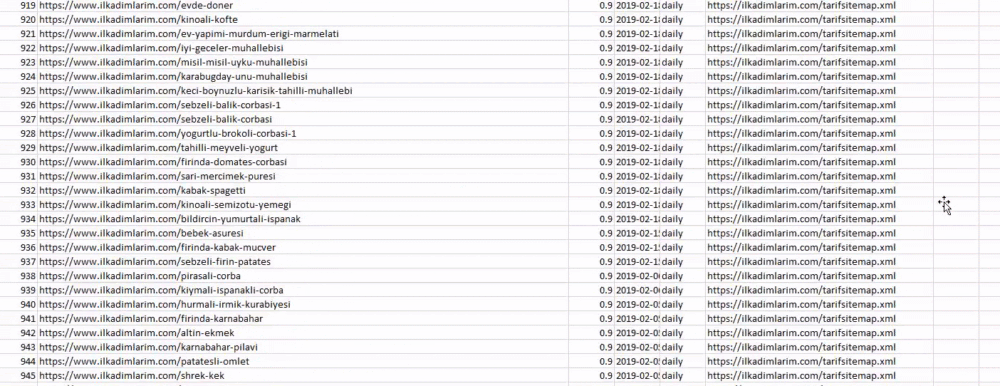
Vous pouvez voir une colonne avec différents noms de sitemap ci-dessus. ignore_index=True section est pour l'ordre ordonné des numéros d'index de différents DataFrames, si vous en avez fusionné plusieurs ensemble.
Oncrawl Data³
 Apprendre encore plus
Apprendre encore plusNettoyage et préparation du cadre de données Sitemap pour l'analyse de contenu avec Python
Pour comprendre le profil de contenu d'un site Web via un sitemap, nous devons le préparer afin d'examiner le DataFrame que nous avons obtenu avec Advertools.
Nous utiliserons quelques commandes de base de la bibliothèque Pandas pour façonner nos données :
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(columns = 'Sans nom : 0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
"Ilkadimlarim" signifie "mes premiers pas" en turc, et comme vous pouvez l'imaginer, c'est un site pour les bébés, la grossesse et la maternité.
Nous avons effectué trois opérations avec ces lignes.
- Sans nom : Nous avons supprimé une colonne vide nommée 0 du DataFrame. De plus, si vous utilisez 'index = False " avec la fonction pd.to_csv() , vous ne verrez pas cette colonne 'Unnamed 0' au début.
- Nous avons converti les données de la colonne Dernière modification en date et heure.
- Nous avons amené la colonne "lastmod" à la position d'index.
Ci-dessous, vous pouvez voir la version finale du DataFrame.
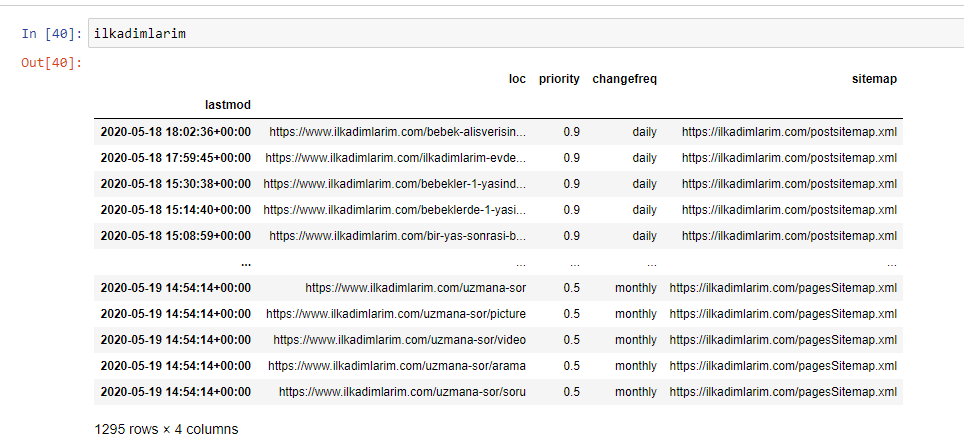
Nous savons que Google n'utilise pas les informations de priorité et de fréquence de modification des sitemaps. Ils l'appellent "un sac de bruit". Mais si vous accordez de l'importance aux performances de votre site Web pour les autres moteurs de recherche, vous trouverez peut-être utile de les examiner également. Personnellement, je ne me soucie pas beaucoup de ces données, mais je n'ai toujours pas besoin de les supprimer du DataFrame.
Nous avons besoin d'une ligne de code supplémentaire pour catégoriser les sitemaps dans une autre colonne.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
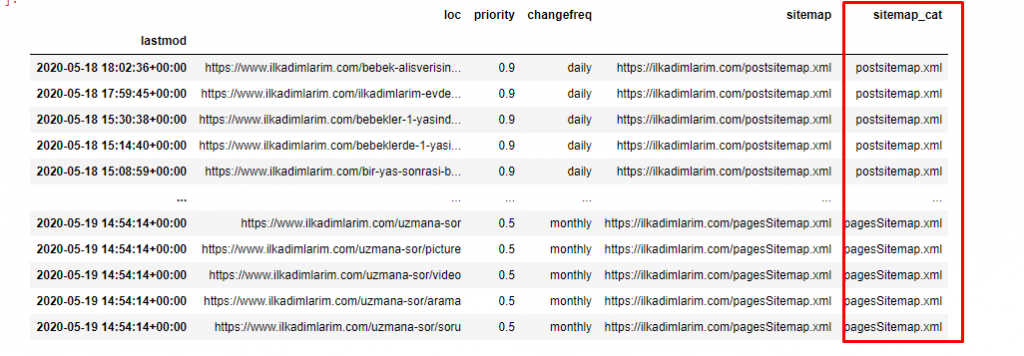
Dans Pandas, vous pouvez ajouter de nouvelles colonnes ou lignes à un DataFrame ou vous pouvez les mettre à jour facilement. Nous avons créé une nouvelle colonne avec l'extrait de code DataFrame['new_columns'] . DataFrame['column_name'].str nous permet d'effectuer différentes opérations en modifiant le type de données dans une colonne. Nous divisons les données de chaîne dans la colonne liée à .split ('/') par le caractère / et les plaçons dans une liste. Avec .str [number] , nous créons le contenu de la nouvelle colonne en sélectionnant un élément particulier dans cette liste.
Analyse du profil de contenu en fonction du nombre et des types de sitemaps
Après avoir placé les sitemaps dans une colonne différente en fonction de leurs types, nous pouvons vérifier quel % du contenu se trouve dans chaque sitemap. Ainsi, nous pouvons également déduire quelle partie du site Web est la plus importante.
ilkadimlarim['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['column_name'] sélectionne la colonne que nous voulons faire un processus.
- value_counts() compte la fréquence des valeurs dans la colonne.
- normalize=True prend le rapport des valeurs en décimal.
- Nous facilitons la lecture en agrandissant les nombres décimaux avec *100.
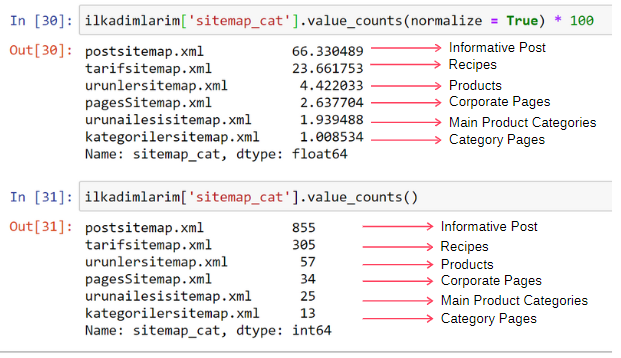
Nous constatons que 65 % du contenu se trouve dans le Post Sitemap et 23 % dans le Recipe Sitemap. Le plan du site du produit n'a que 2 % du contenu.
Cela montre que nous avons un site Web qui doit créer du contenu informatif pour un large public afin de commercialiser ses propres produits. Vérifions si notre thèse est correcte.
Avant de continuer, nous devons changer le nom de la colonne ilkadimlarim['sitemap_cat'] en 'URL_Count' avec le code ci-dessous :
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- La fonction rename() est utile pour modifier le nom de vos colonnes ou index pour connecter les données et leur signification à un niveau plus profond.
- Nous avons changé le nom de la colonne pour qu'il soit permanent grâce à l' attribut 'inplace=True' .
- Vous pouvez également modifier les styles de lettres de vos colonnes et index avec ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) . Ceci n'écrit que les premières lettres en majuscules de chaque colonne d'Ilkadimlarim.

Maintenant, nous pouvons continuer.
Pour voir ces informations dans un seul cadre, vous pouvez utiliser le code ci-dessous :
(ilkadimlarim['sitemap_cat']
.value_counts()
.encadrer()
.assign(percentage=lambda df : df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', pourcentage='{:.1%}')))
- to_frame() est utilisé pour encadrer les valeurs mesurées par value_counts() dans la colonne sélectionnée.
- assign() est utilisé pour ajouter certaines valeurs au cadre.
- lambda fait référence à des fonctions anonymes en Python.
- Ici, la fonction Lambda et les types de plan de site sont divisés par le nombre total de plan de site par la méthode Pandas div() .
- style() détermine comment les valeurs finales spécifiées sont écrites.
- Ici, nous définissons le nombre de chiffres écrits après le point avec la méthode format() .
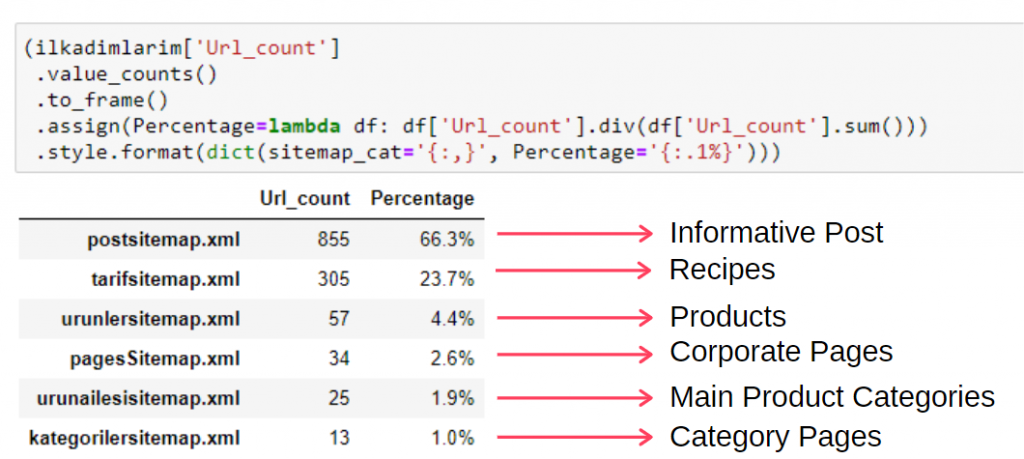
Ainsi, nous voyons l'importance du marketing de contenu pour ce site Web. Nous pouvons également vérifier leurs tendances de publication d'articles par année avec deux lignes de code simples pour examiner leur situation plus en profondeur.
Examen et visualisation des tendances de publication de contenu par année via Sitemaps et Python
Nous avons fait correspondre le contenu et l'intention du site Web examiné en fonction des catégories du sitemap, mais nous n'avons pas encore effectué de classification temporelle. Nous utiliserons la méthode resample() pour accomplir cela.
post_par_mois = ilkadimlarim.resample('A')['loc'].count()
post_per_month.to_frame()
Resample est une méthode de la bibliothèque Pandas. resample('A') vérifie la série de données pour un DataFrame annuel. Pendant des semaines, vous pouvez utiliser 'W', pendant des mois, vous pouvez utiliser 'M'.
Loc symbolise ici l'index ; count signifie que vous voulez compter la somme des exemples de données.
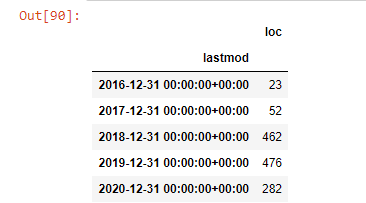
Nous voyons qu'ils ont commencé à publier des articles en 2016, mais leur principale tendance de publication a augmenté après 2017. Nous pouvons également mettre cela dans un graphique à l'aide de Plotly Graph Objects.
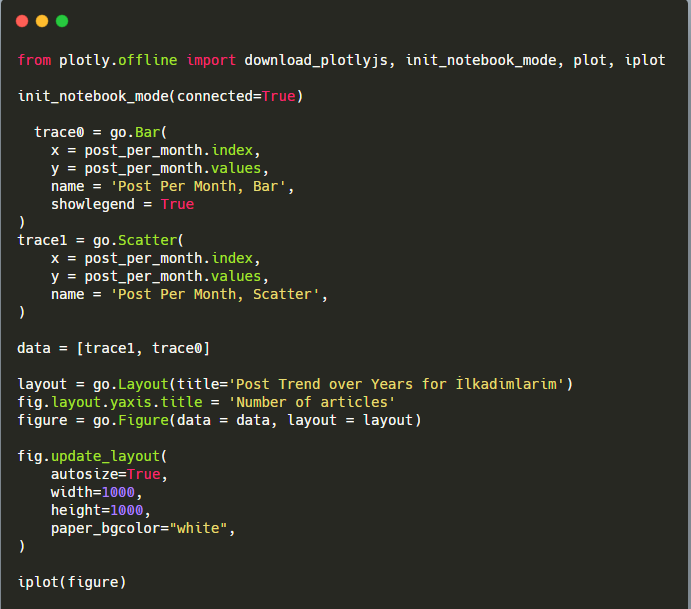
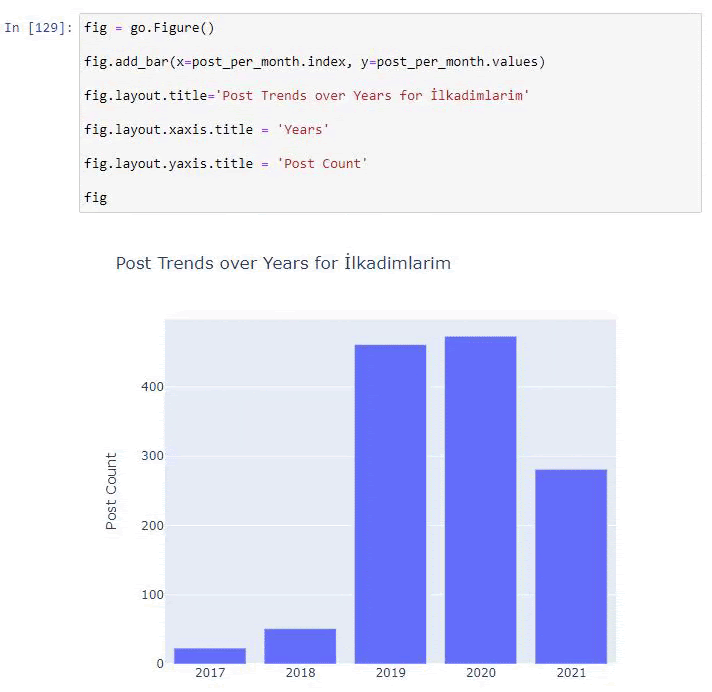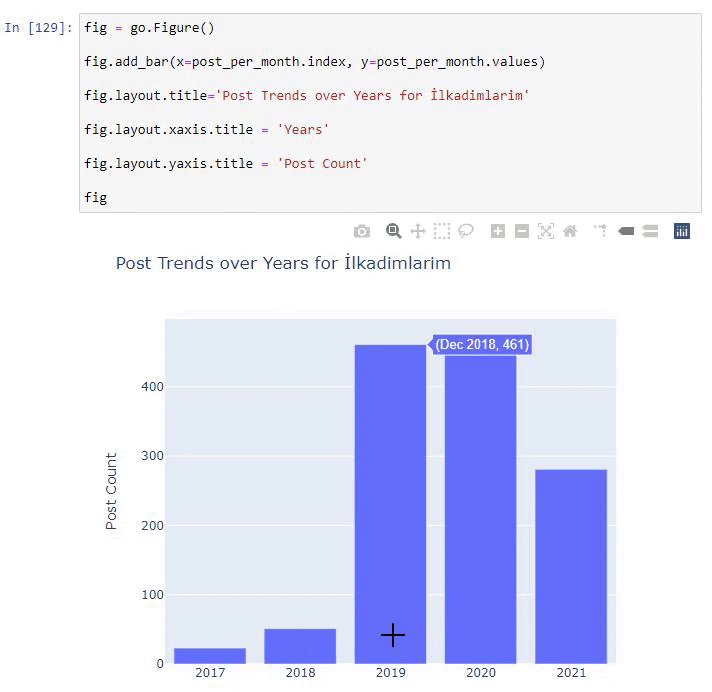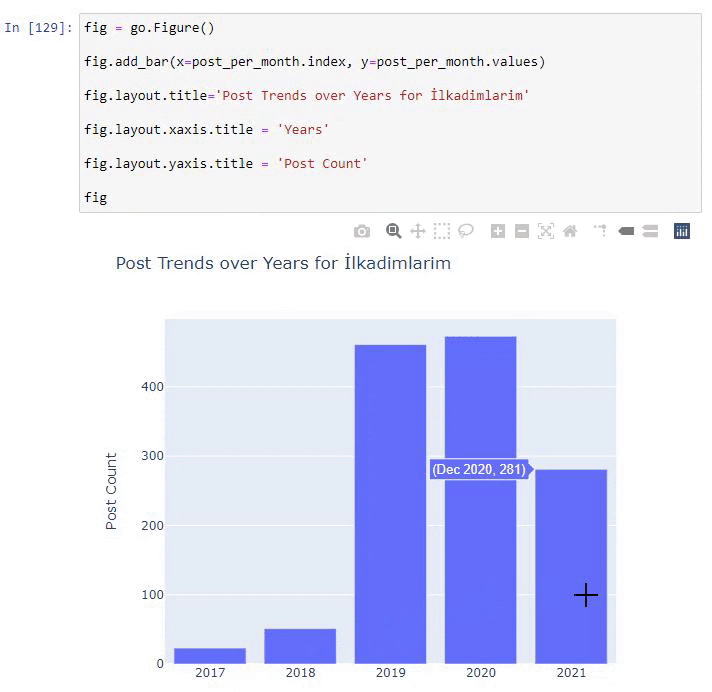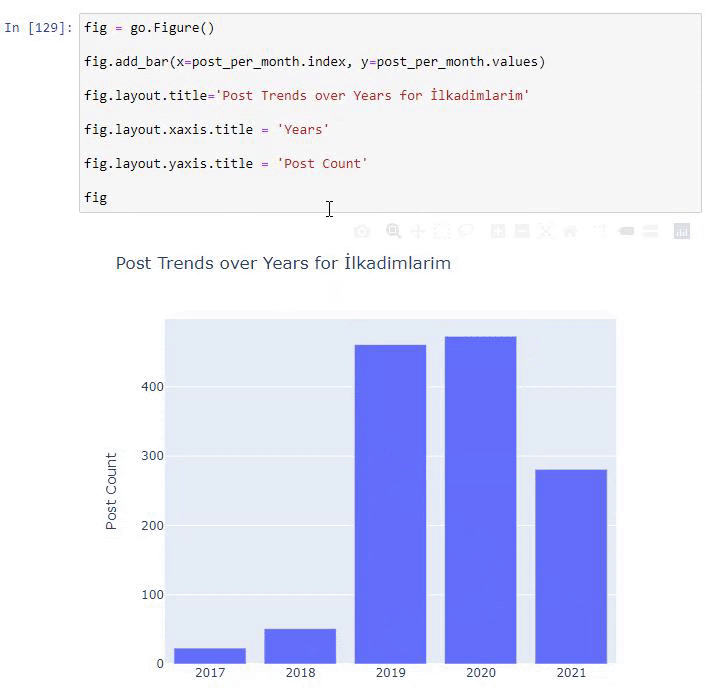
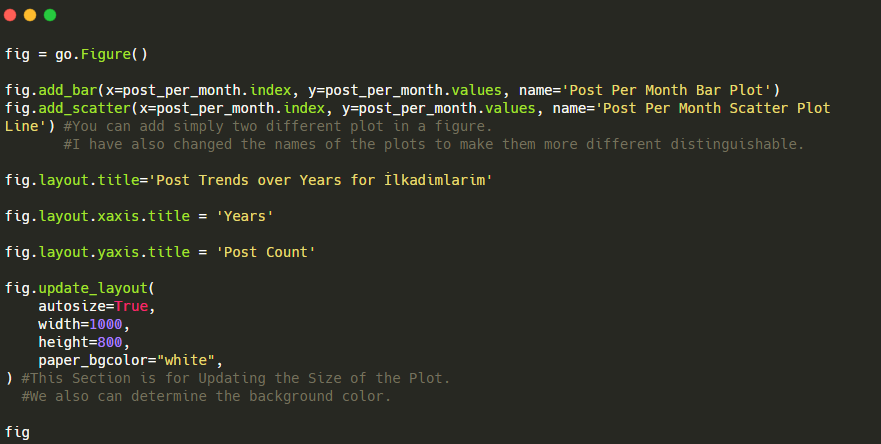
Explication de cet extrait de code Plotly Bar Plot :
- fig = go.Figure() sert à créer une figure.
- fig.add_bar() sert à ajouter un barplot dans la figure. Nous déterminons également quels axes X et Y seront entre parenthèses.
- Fig.layout sert à créer un titre général pour la figure et les axes.
- À la dernière ligne, nous appelons le tracé que nous avons créé avec la commande fig qui est égale à go.Figure ()
Ci-dessous, vous retrouverez les mêmes données par mois, avec scatterplot et barplot :
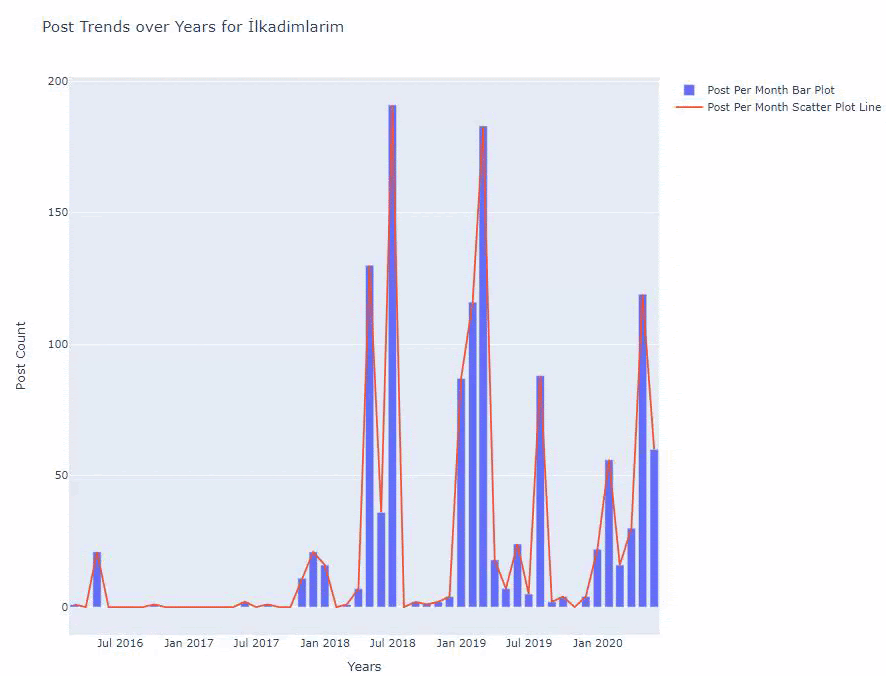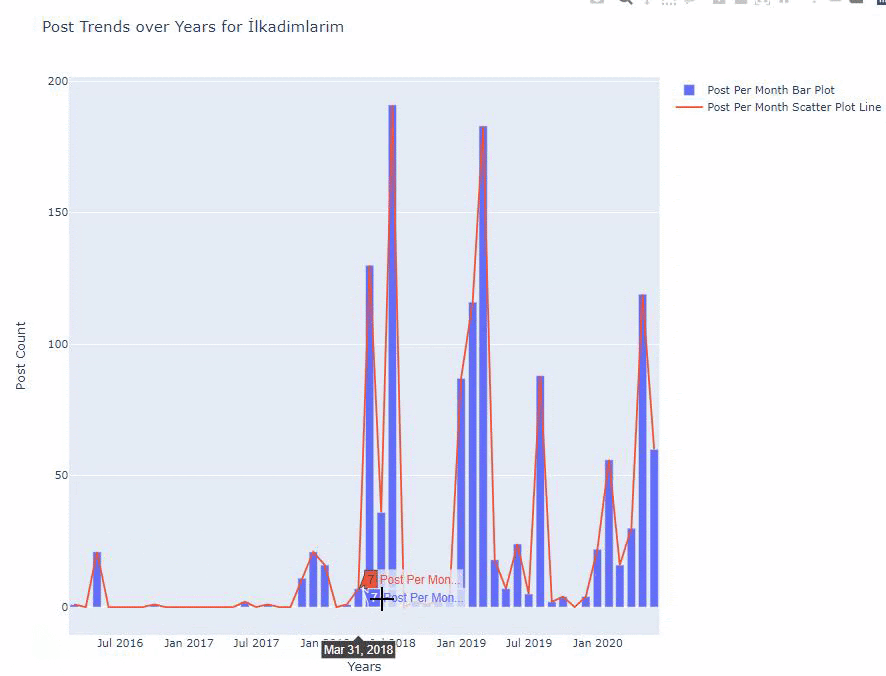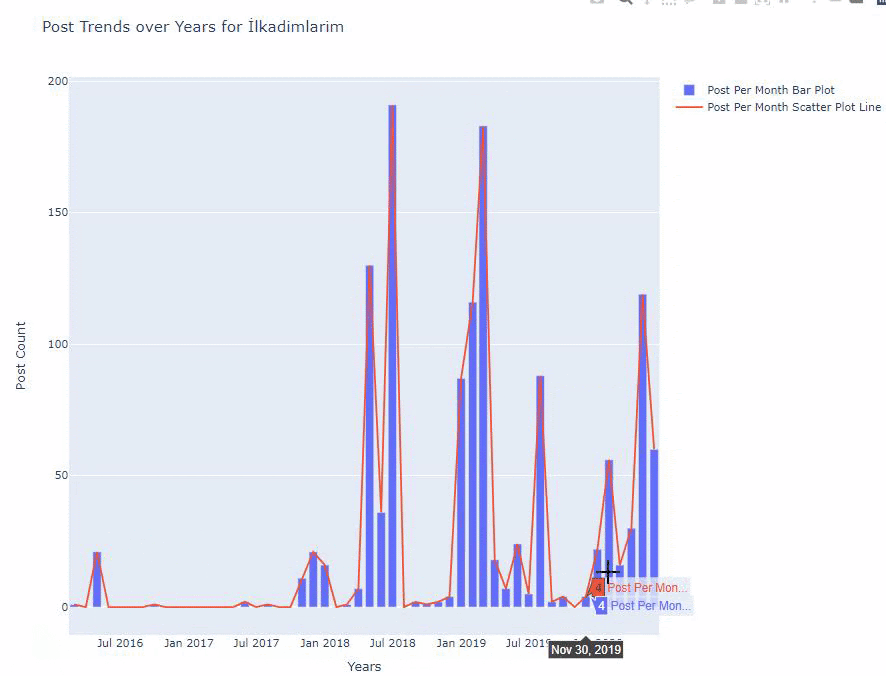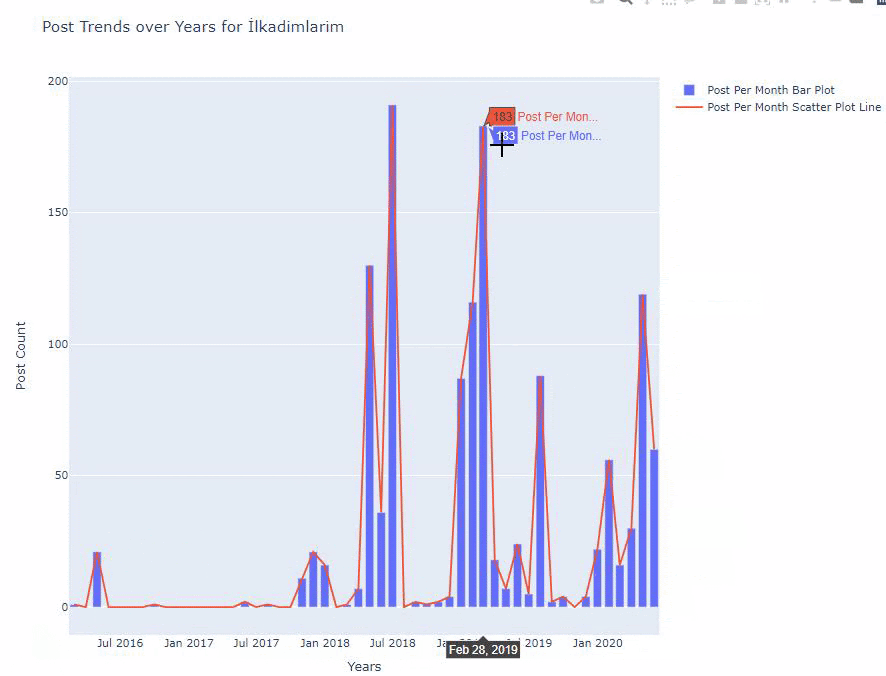
Voici les codes pour créer cette figure :
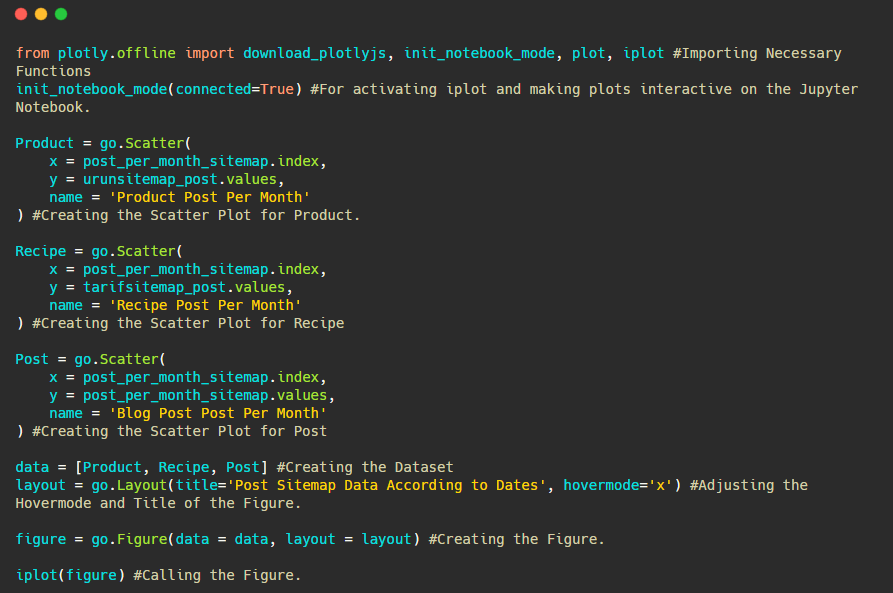
Nous avons ajouté un deuxième tracé avec fig.add_scatter() , et nous avons également changé les noms en utilisant l'attribut name. fig.update_layout() sert à changer la taille et la couleur d'arrière-plan du tracé.
Vous pouvez également modifier le mode de survol, la distance entre les barres, etc. Je pense qu'il suffit de ne partager que les codes, car expliquer chaque code ici séparément peut nous faire nous éloigner du sujet principal.
Nous pouvons également comparer les tendances de publication de contenu des concurrents selon les catégories comme ci-dessous :
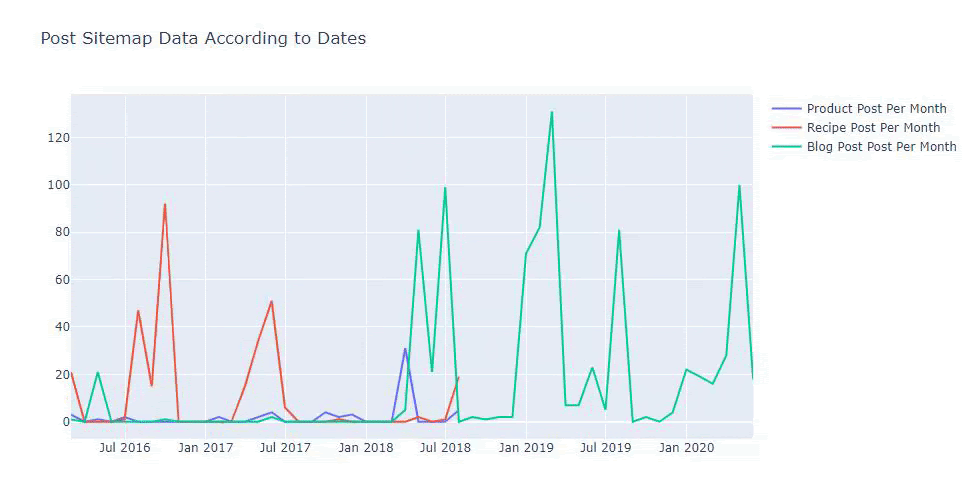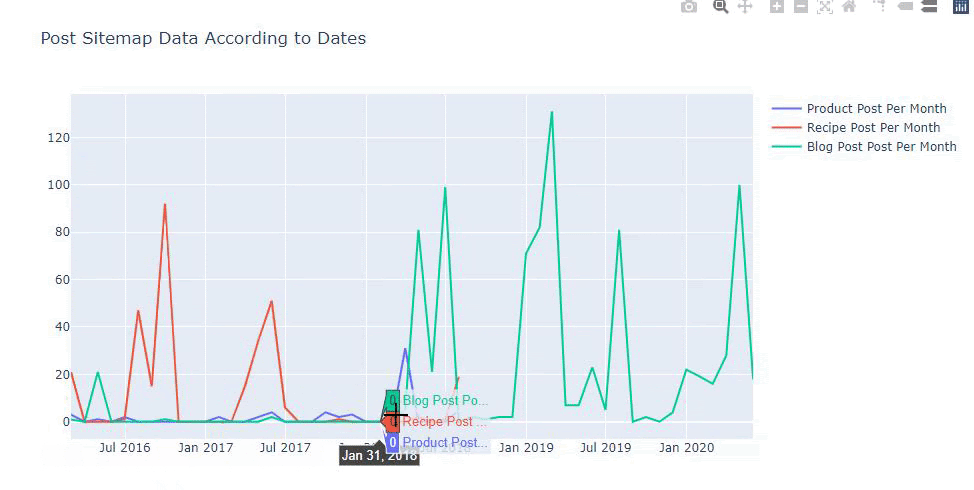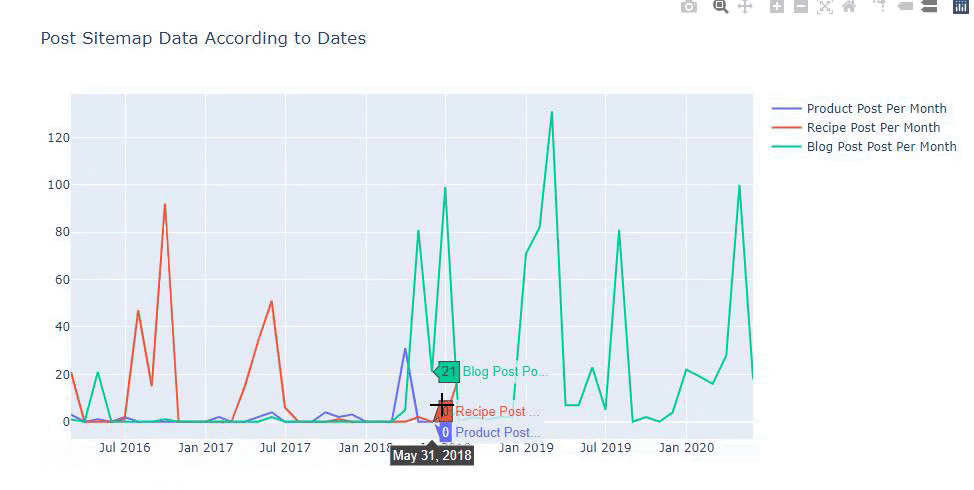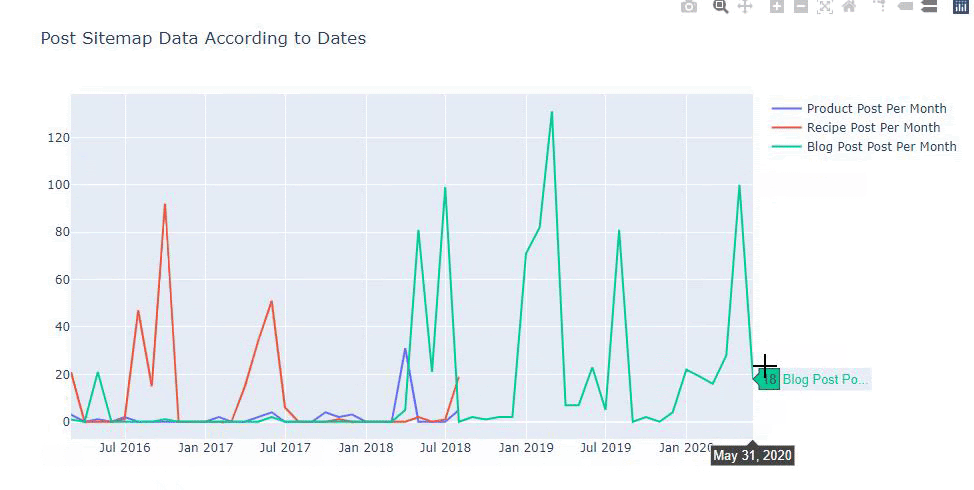
Ce graphique a été créé avec la deuxième méthode, comme vous pouvez le constater, il n'y a pas de différence, mais l'une d'entre elles est assez simple.
Afin de tracer la fréquence et la tendance de la publication de contenu à partir de trois plans de site distincts, nous devons placer le plan de site, qui a l'intervalle le plus long, sur l'axe X. Ainsi, nous pouvons comparer la fréquence à laquelle le site Web que nous examinons publie chaque type de contenu différent pour différentes intentions de recherche.
Lorsque vous examinez les codes pertinents ci-dessous, vous verrez qu'il n'est pas très différent de ce qui précède.
Pour créer un nuage de points avec plusieurs axes Y, vous pouvez utiliser le code ci-dessous.
Il existe d'autres méthodes telles que l'unification de différents sitemaps et l'utilisation d'une boucle for pour que les colonnes utilisent plusieurs axes Y dans le nuage de points, mais pour un si petit site, nous n'en avons pas besoin. Pour la plupart, il serait plus logique d'utiliser cette méthode sur des sites Web avec des centaines de sitemaps.
De plus, parce que le site Web est petit, le graphique peut sembler superficiel, mais comme vous le verrez plus tard dans l'article sur un site Web avec des millions d'URL, ces graphiques sont un excellent moyen de comparer différents sites ainsi que de comparer différentes catégories du même site internet.
Examiner et visualiser les catégories de contenu, l'intention et les tendances de publication avec Sitemaps et Python
Dans cette section, nous vérifierons qu'ils ont écrit un grand nombre de contenus dans un domaine de connaissance spécifique pour commercialiser un petit nombre de produits, ce que nous disions au début de l'article. Grâce à cela, nous pouvons voir s'ils ont ou non un partenariat de contenu avec d'autres marques.
Pour montrer ce que l'on peut trouver d'autre sur les sitemaps, nous allons continuer à creuser un peu plus. Nous pouvons également obtenir des informations de la partie 'loc' du sitemap comme d'autres.
Il n'y a pas de répartition par catégorie dans les URL d'Ilkadimlarim. Si un site Web a une répartition par catégorie dans ses URL, nous pouvons en apprendre beaucoup plus sur la distribution de contenu. Sinon, nous pouvons accéder aux mêmes données en écrivant du code supplémentaire, mais seulement avec moins de certitude.
À ce stade, vous pouvez imaginer à quel point les pannes d'URL sont beaucoup moins coûteuses pour les moteurs de recherche qui explorent des milliards de sites pour comprendre votre site Web.
a = ilkadimlarim['loc'].str.contains(“bebek|hamile|haftalik”)
Bebek : bébé
Hamil : enceinte
Haftalik : hebdomadaire ou « semaines de grossesse »
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
La méthode str() nous permet ici encore de définir la colonne dans laquelle nous sélectionnons certaines opérations.
Avec la méthode contains() , nous déterminons les données pour vérifier si elles sont incluses dans les données converties en chaîne.
Ici, "|" entre les termes signifie « ou » .
Ensuite, nous attribuons les données que nous avons filtrées à une variable et utilisons la méthode resample() que nous avons utilisée précédemment.
La méthode de comptage , quant à elle, mesure quelles données sont utilisées et combien de fois.
Le résultat obtenu avec count() est à nouveau joint au to_frame() .
De plus, str.contains() prend les valeurs Regex par défaut, ce qui signifie que vous pouvez créer des conditions de filtrage plus compliquées avec moins de code.
En d'autres termes, à ce stade, nous attribuons les URL contenant les mots "bébé", "hebdomadaire", "enceinte" à une variable dans ilkadimlarim , puis nous mettons la date de publication des URL dans les conditions appropriées pour ce filtre que nous créé dans un cadre.
Ensuite, nous faisons de même pour les URL contenant le mot 'aptamil'. Aptamil est le nom d'un produit de nutrition infantile introduit par Ilkadimlarim. Dès lors, on peut également prêter attention à la densité de diffusion des contenus informatifs et commerciaux.
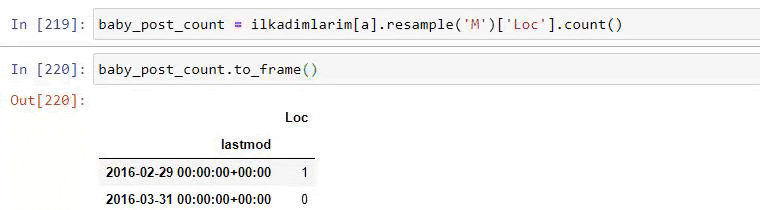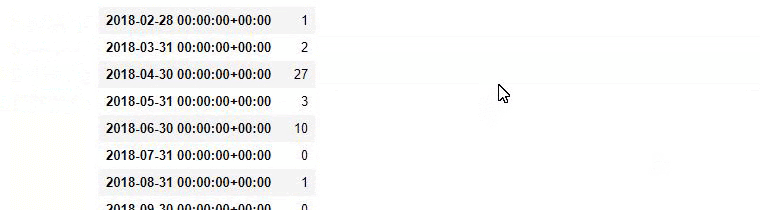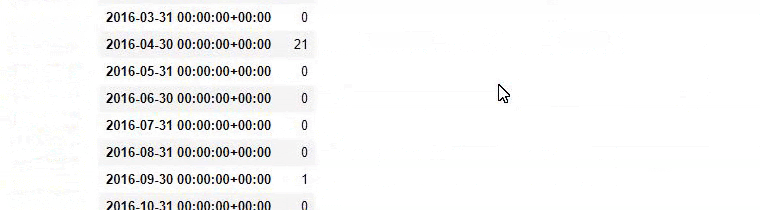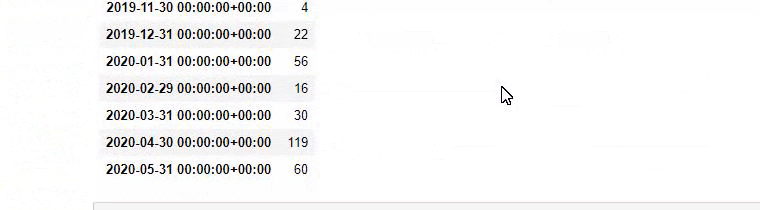
Et vous pouvez voir les deux groupes de contenu différents publier des calendriers au fil des ans pour différentes intentions de recherche avec plus de certitude et des informations précises à partir des URL.
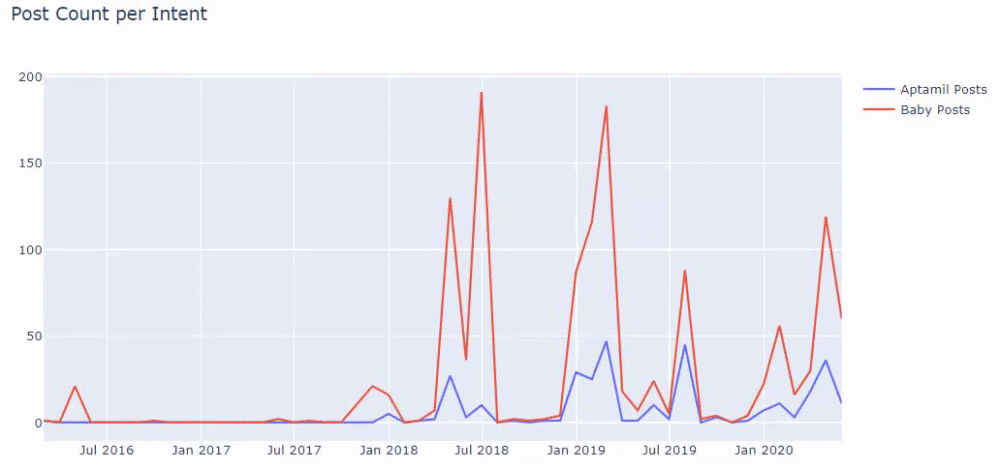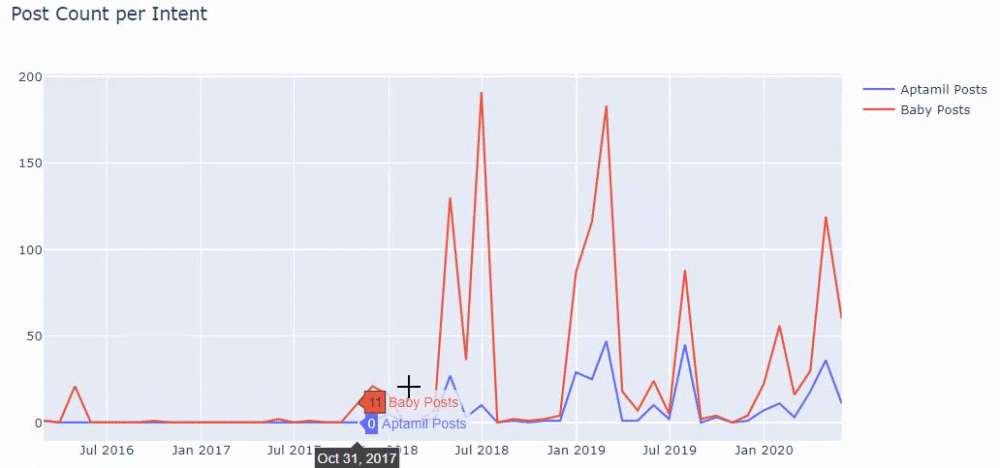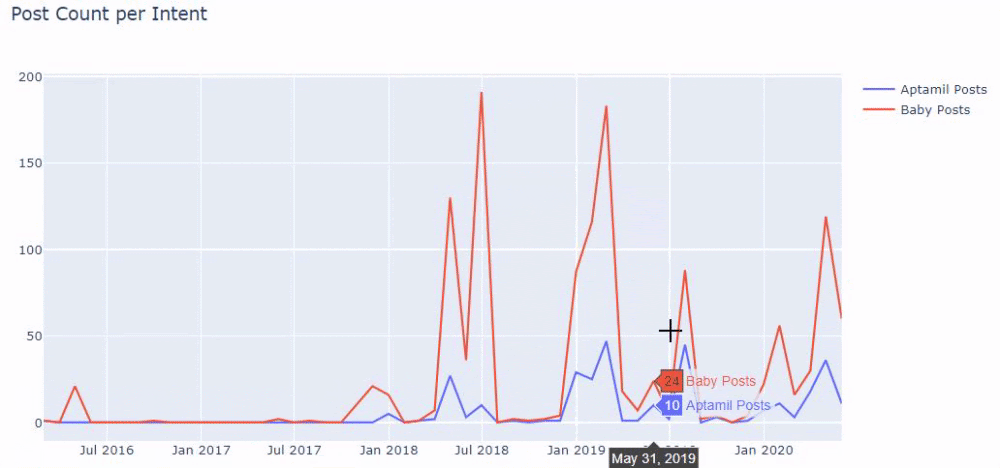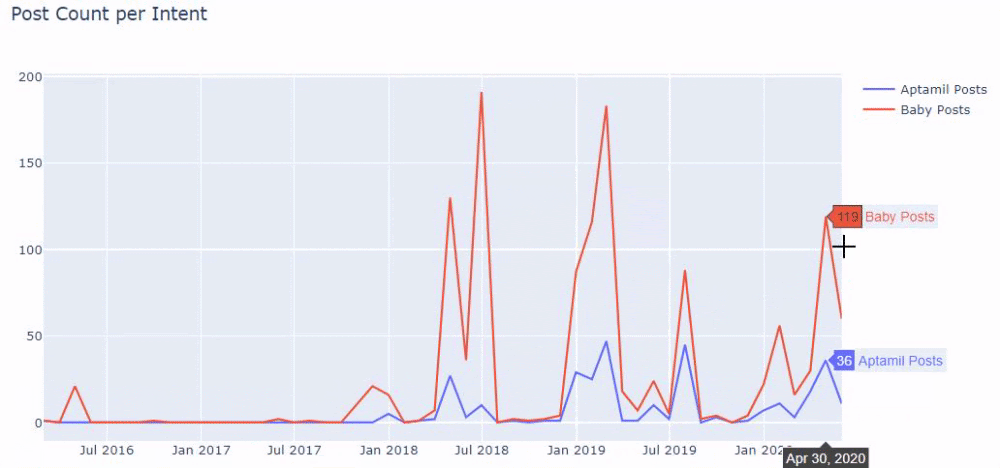
Le code pour produire ce graphique n'a pas été partagé car il est le même que celui utilisé pour le graphique précédent
Avec l'aide des opérateurs de recherche sur Google, j'obtiens 38 résultats lorsque je veux les pages où le mot Aptamil est utilisé dans le texte d'ancrage sur Ilkadimlarim.com. Un nombre important de ces pages sont informatives et renvoient à des contenus commerciaux.
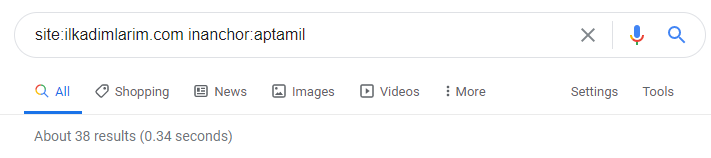
Notre thèse a fait ses preuves.
"Mes premiers pas" utilise des centaines de contenus informatifs sur la maternité, les soins du bébé et la grossesse pour atteindre son public cible. « Ilkadimlarim » relie les pages contenant les produits Aptamil à partir de ce contenu et y dirige les utilisateurs.
Profilage de contenu comparatif et analyse de la stratégie de contenu via des sitemaps avec Python
Maintenant, si vous le souhaitez, faisons la même chose pour une entreprise du même secteur et faisons une comparaison pour comprendre l'aspect général de ce secteur et les différences de stratégie entre ces deux marques.

Comme deuxième exemple, j'ai choisi Prima.com.tr, qui est Pampers, mais utilise le nom de marque Prima en Turquie. Étant donné que Prima a un seul sitemap, nous ne pourrons pas classer par sitemaps, mais au moins ils ont des ruptures différentes dans leurs URL. Nous avons donc beaucoup de chance : nous devrons écrire moins de code.
Imaginez à quel point les algorithmes que Google doit exécuter pour vous sont beaucoup plus coûteux lorsque vous créez un site difficile à comprendre ! Cela peut aider à rendre le calcul des coûts de crawl plus tangible dans votre esprit, ne serait-ce qu'en ce qui concerne la structure de l'URL.
Afin de ne pas augmenter davantage le volume de l'article, nous ne plaçons pas les codes des processus similaires à ceux que nous avons déjà effectués.
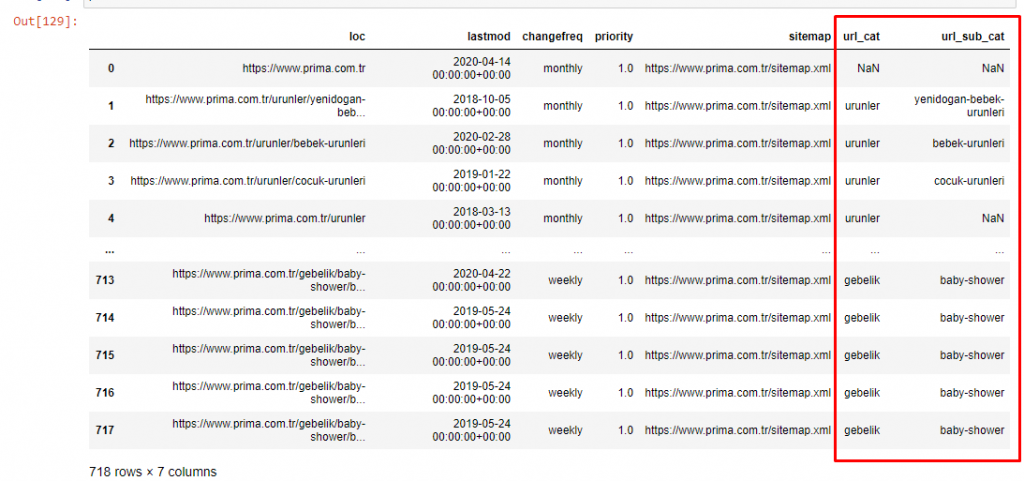
Maintenant, nous pouvons examiner la distribution de leur catégorie de contenu par catégories d'URL et sous-catégories d'URL. Nous constatons qu'ils ont une quantité excessive de pages Web d'entreprise. Ces pages Web d'entreprise sont placées dans la section "prima-hakkinda" ("À propos de Prima"). Mais quand je les vérifie avec Python, je vois qu'ils ont unifié leurs produits et leurs pages Web d'entreprise dans une seule catégorie. Vous pouvez voir leur distribution de contenu ci-dessous :

Nous pouvons faire de même pour les sous-catégories suivantes.
Il est intéressant de noter que Prima utilise "gebelik" (grossesse en turc) qui est une variante de "hamilelik" (grossesse en arabe), et les deux signifient la période de grossesse.

Maintenant, nous voyons une catégorisation plus profonde sur leur contenu. 9,2% du contenu concerne une grossesse en santé, 7,3% concerne le processus de croissance des bébés, 8,3% du contenu concerne les activités pouvant être réalisées avec les bébés, 0,7% concerne l'ordre de sommeil des bébés. Il y a même des sujets comme la dentition avec 3,9 %, la sécurité du bébé avec 1,9 % et le fait de révéler une grossesse à la famille avec 1,4 %. Comme vous pouvez le voir, vous pouvez apprendre à connaître une industrie avec seulement des URL et leur pourcentage de distribution.
Ce n'est pas la catégorisation parfaite, mais au moins nous pouvons voir l'état d'esprit et les tendances du marketing de contenu de nos concurrents, ainsi que le contenu de leur site Web en fonction des catégories. Vérifions maintenant la fréquence de publication du contenu par mois.
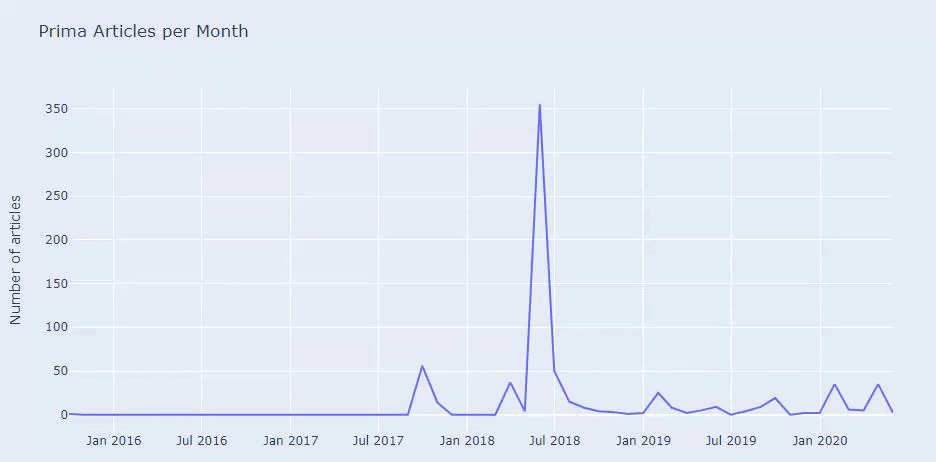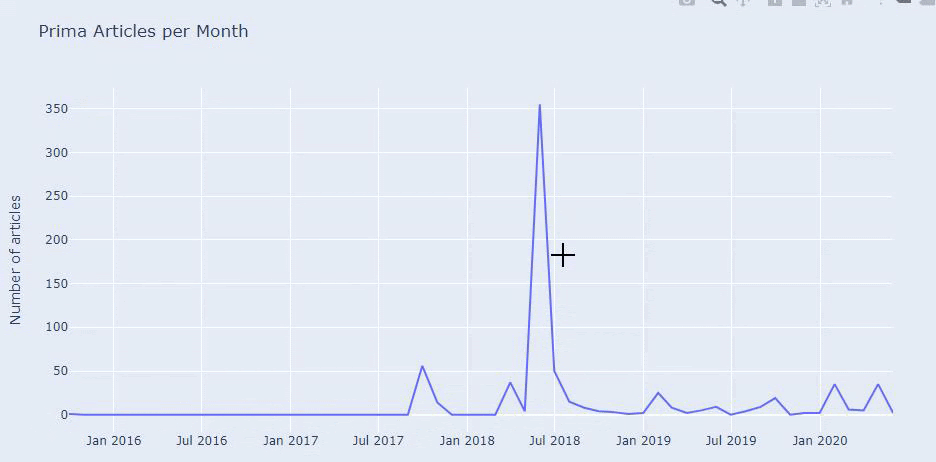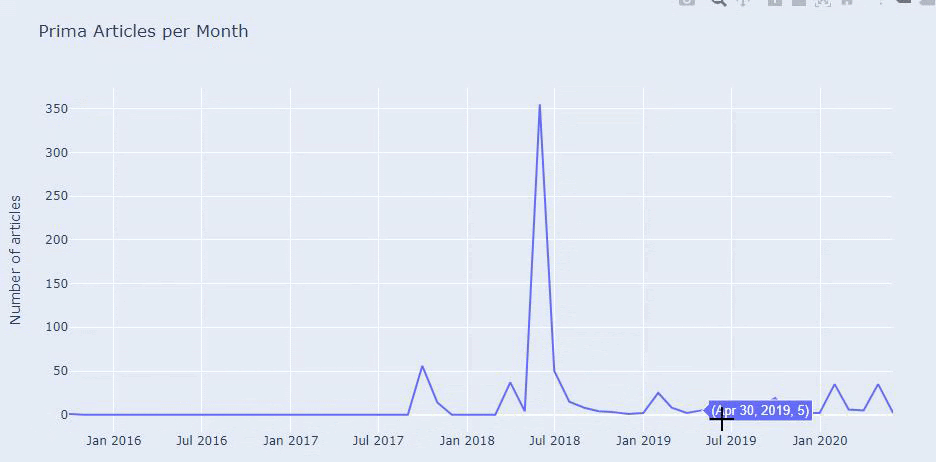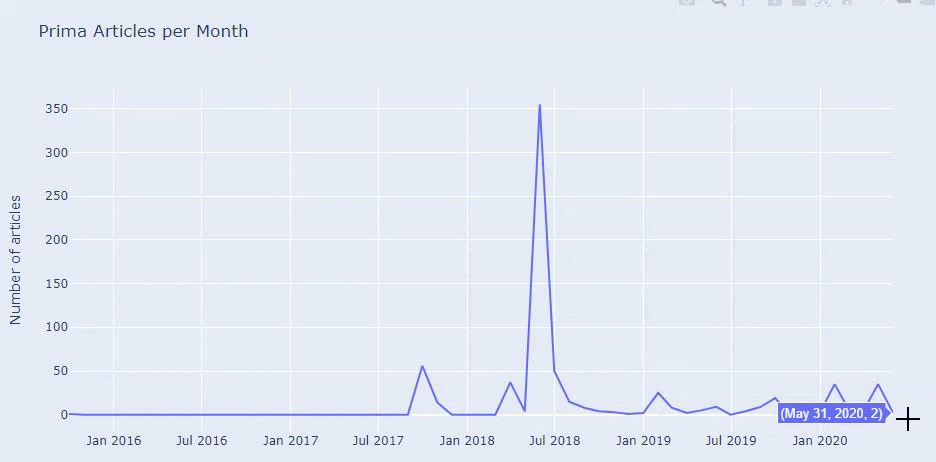
On voit qu'ils ont publié 355 articles en juillet 2018 et selon Sitemap, leur contenu n'est pas rafraîchi depuis. Nous pouvons également comparer leurs tendances de publication de contenu selon les catégories au fil des ans. Comme vous pouvez le constater, leur contenu se situe principalement dans quatre catégories différentes et la plupart d'entre eux sont publiés le même mois.
Avant de continuer, je dois dire que les données du sitemap ne sont pas toujours correctes. Par exemple, les données Lastmod peuvent avoir été mises à jour pour toutes les URL car elles ont renouvelé tous les sitemaps à cette date. Pour contourner cela, nous pouvons également vérifier qu'ils n'ont pas changé leur contenu depuis lors en utilisant la Wayback Machine.
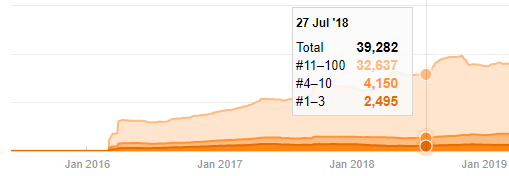
Même si cela semble suspect, ces données peuvent être réelles. De nombreuses entreprises en Turquie ont tendance à donner un nombre élevé de commandes et à publier du contenu un instant avant. Lorsque je vérifie leur nombre de mots clés, je vois un bond sur cette période. Ainsi, si vous effectuez un profil de contenu comparatif et une analyse de stratégie, vous devez également réfléchir à ces questions.
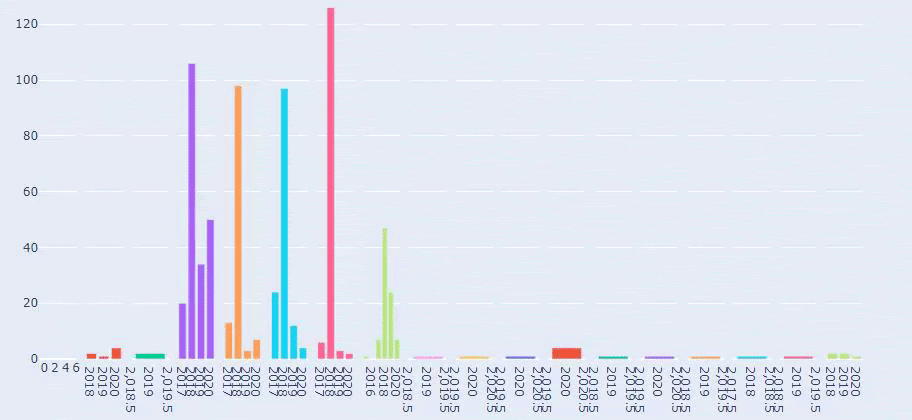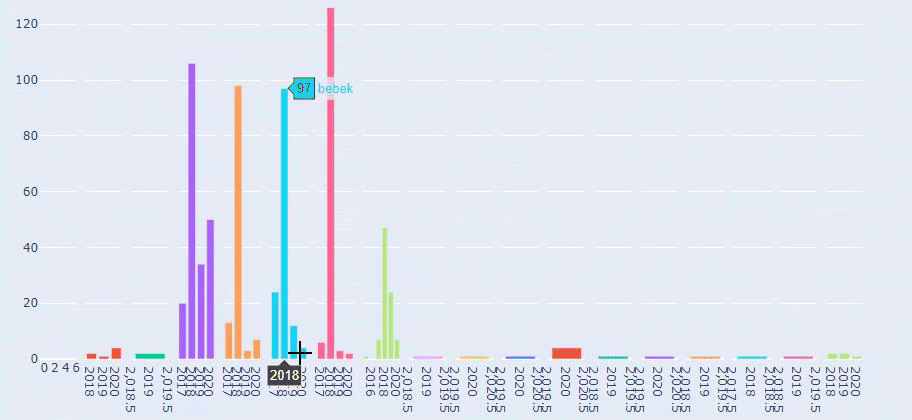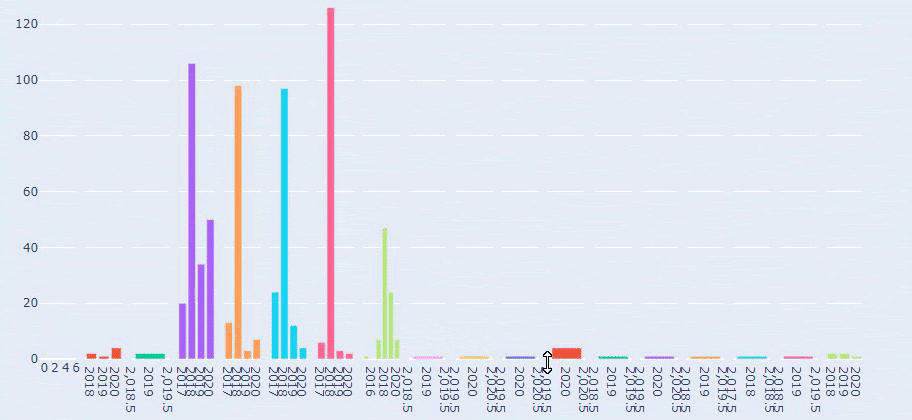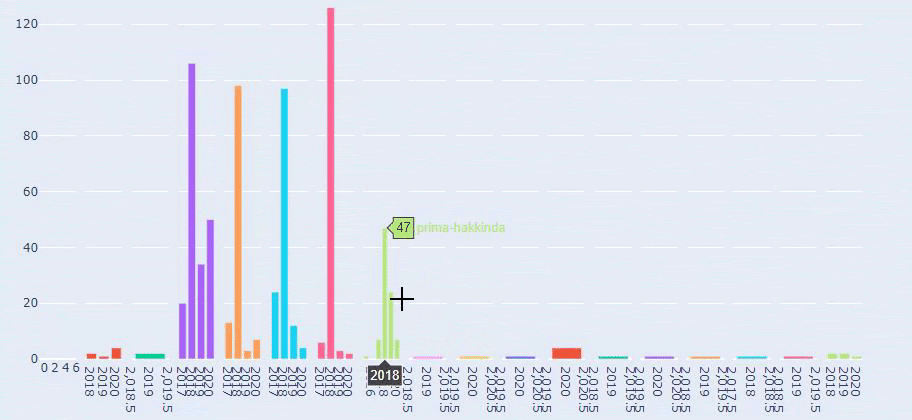
Il s'agit d'une comparaison entre la tendance de publication de contenu de chaque catégorie au fil des ans pour Prima.com.tr
Maintenant, nous pouvons comparer les catégories de contenu des deux sites Web différents et leurs tendances de publication.
Lorsque nous examinons la fréquence à laquelle Prima publie des articles sur la croissance du bébé, la grossesse et la maternité, nous constatons une similitude avec Ilkadimlarim :
- La plupart des articles ont été publiés à une certaine époque.
- Ils n'avaient pas été mis à jour depuis longtemps.
- Le nombre de produits et de pages était très faible par rapport au nombre de pages de contenu informatif.
- Récemment, ils viennent d'ajouter de nouveaux produits à leurs sites.
Nous pouvons considérer ces quatre caractéristiques comme l'état d'esprit par défaut de l'industrie et nous pouvons utiliser ces faiblesses en faveur de notre campagne. Après tout, la qualité exige de la fraîcheur (comme l'a déclaré Amit Singhal, Google Fellow).
À ce stade, nous voyons également que l'industrie n'est pas familière avec le comportement de Googlebot. Au lieu de télécharger 250 éléments de contenu en une journée et de n'apporter aucune modification pendant un an, il est préférable d'ajouter périodiquement du nouveau contenu et de mettre à jour régulièrement l'ancien contenu. Ainsi, vous pouvez maintenir la qualité du contenu, Googlebot peut comprendre votre site plus facilement et vos valeurs de fréquence de demande de crawl seront plus élevées que celles de vos concurrents.
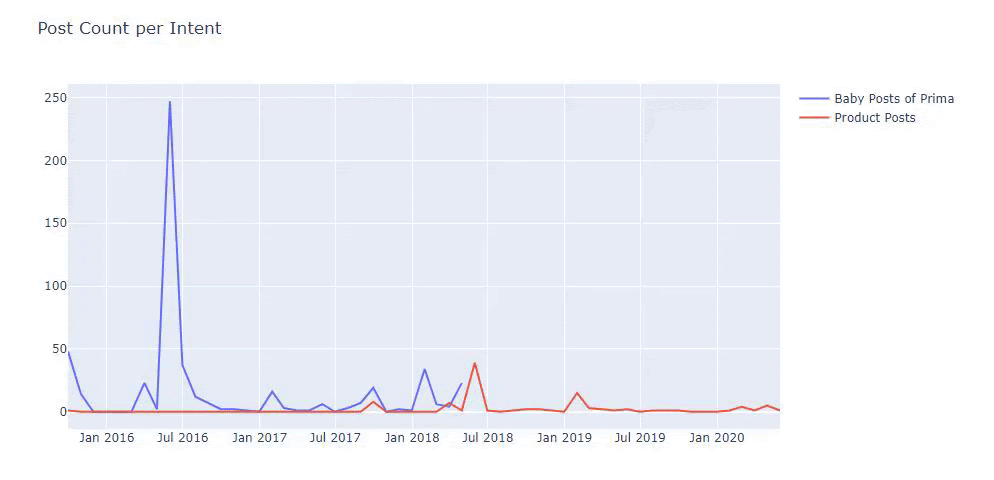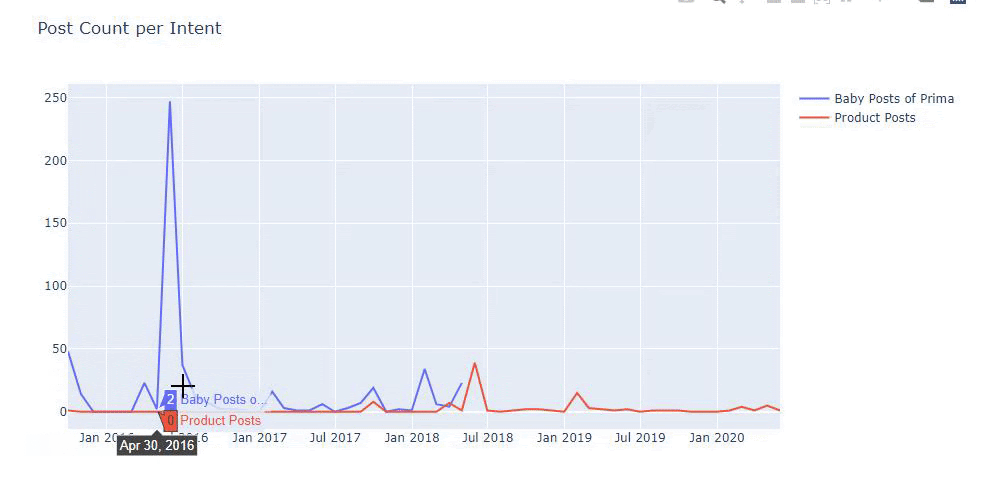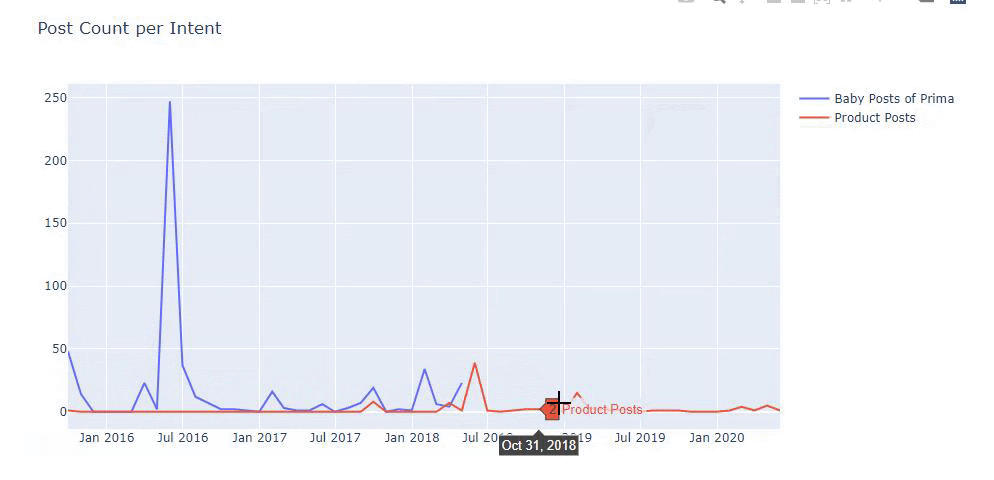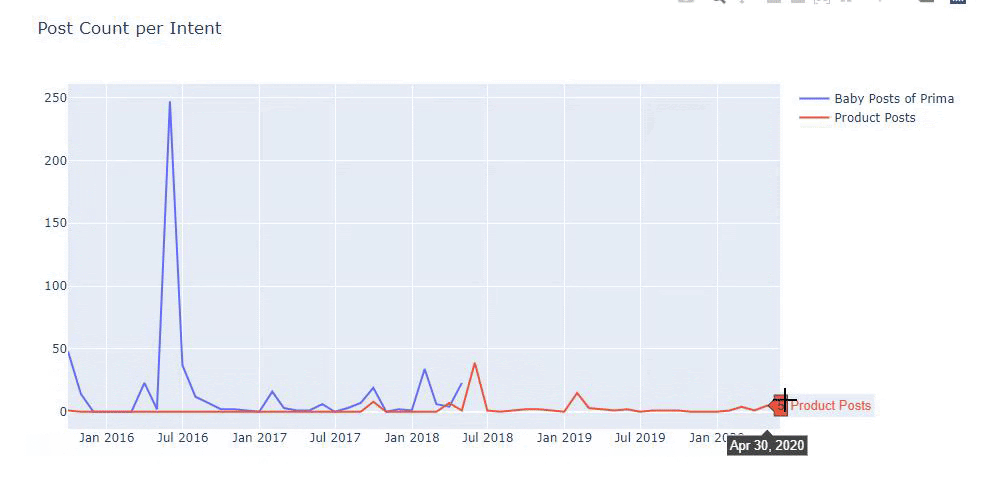
J'ai utilisé les méthodes précédentes pour faire la distinction entre les pages de produit et de contenu informatif et j'ai profilé les mots les plus utilisés dans les URL. Baby Posts ici signifie qu'il s'agit d'un contenu informatif.
Comme vous pouvez le voir, ils ont ajouté 247 contenus en une journée. De plus, ils n'ont pas publié ni actualisé de contenu informatif depuis plus d'un an, et ils ajoutent occasionnellement de nouvelles pages de produits.
Comparons maintenant leurs tendances de publication dans un seul chiffre mais avec deux tracés différents. J'ai utilisé les codes ci-dessous pour créer cette figure:
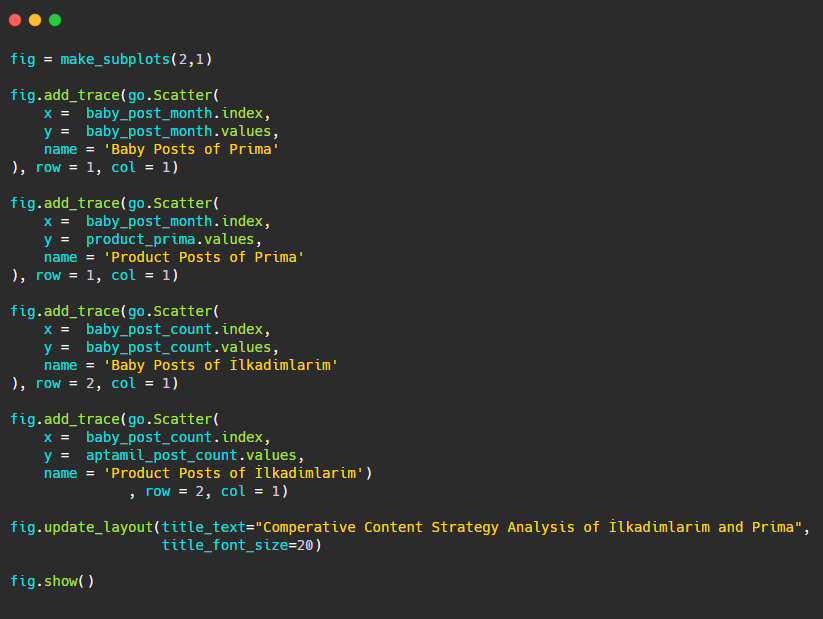
Comme ce graphique est différent des précédents, je voulais vous montrer le code. Ici, deux parcelles distinctes sont placées dans la même figure. Pour cela, la méthode make_subplots a été appelée avec la commande from plotly.subplots import make_subplots.
Il a été créé sous la forme d'une figure à deux lignes et une colonne avec make_subplots (2,1) .
Par conséquent, col et row sont écrits à la fin des traces et leurs positions sont spécifiées. C'est un système que toute personne familiarisée avec le système de grille en CSS peut facilement reconnaître.
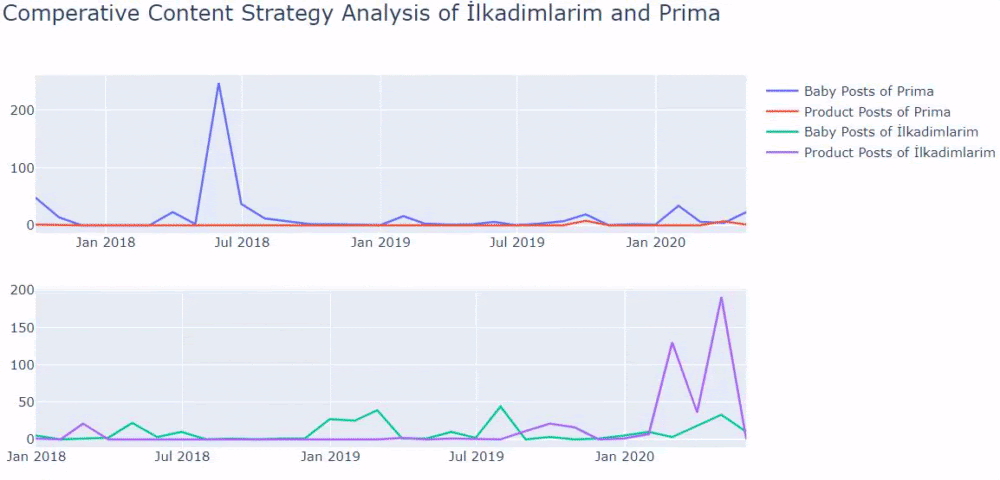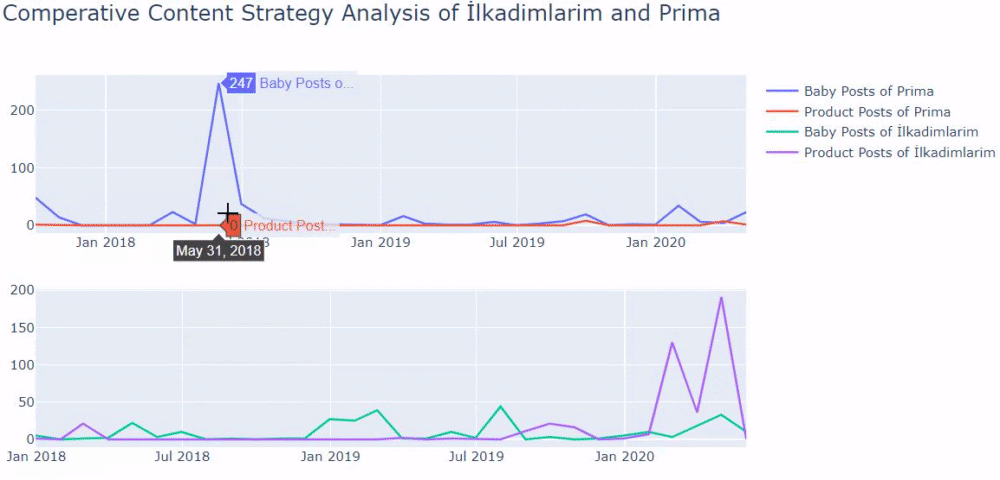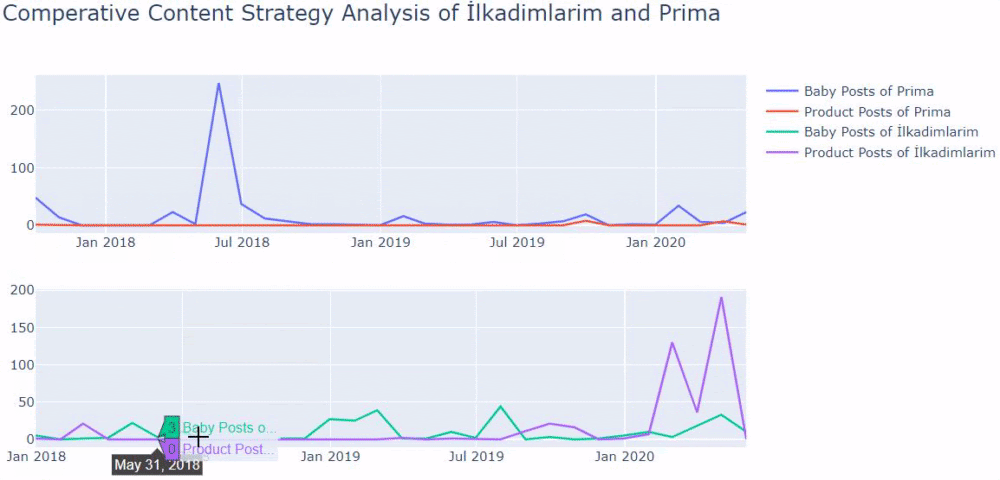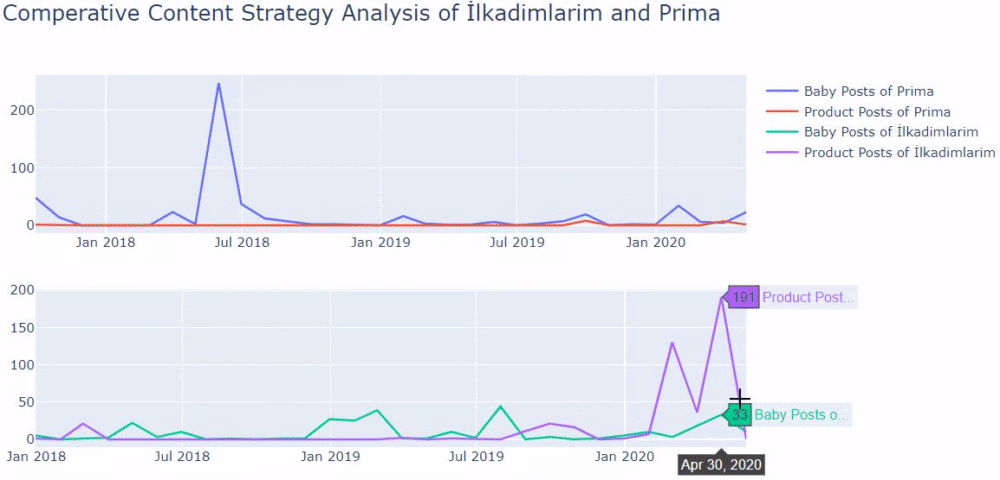
Si vous avez un client dans le même secteur, vous pouvez utiliser ces données pour créer une stratégie de contenu, pour voir les faiblesses de vos concurrents et leur réseau de requêtes/pages de destination sur SERP. En outre, vous pouvez comprendre la quantité de contenu que vous devez publier dans le même domaine de connaissances ou pour la même intention d'utilisateur.
Avant de conclure avec ce que nous pouvons apprendre des sitemaps dans le cadre d'une analyse de stratégie de contenu, nous pouvons examiner un dernier site Web avec un nombre d'URL beaucoup plus élevé d'un autre secteur.
Analyse de la stratégie de contenu des entités Web d'actualités sur les devises avec Python et Sitemaps
Dans cette section, nous utiliserons le tracé de la carte thermique de Seaborn ainsi que des méthodes de cadrage et d'extraction de données plus sophistiquées.

Elias Dabbas a une archive Kaggle intéressante et vraiment utile en termes de Data Science et de SEO. Ce mois-ci, il a ouvert une nouvelle section Kaggle Dataset pour les sites d'actualités turcs pour que j'écrive les codes nécessaires et effectue une analyse de stratégie de contenu avec Advertools via des sitemaps.
Avant de commencer à utiliser ces techniques sur Kaggle, j'aimerais montrer quelques exemples de ce qui se passerait si nous utilisions les mêmes techniques sur de plus grandes entités Web dans cet article.
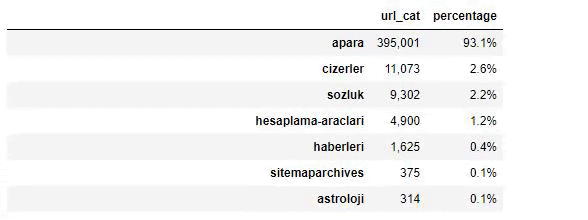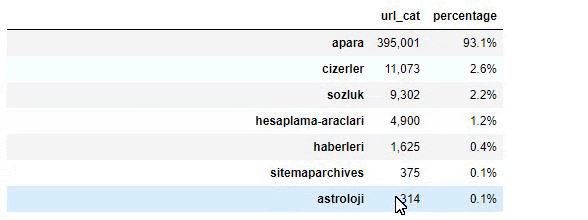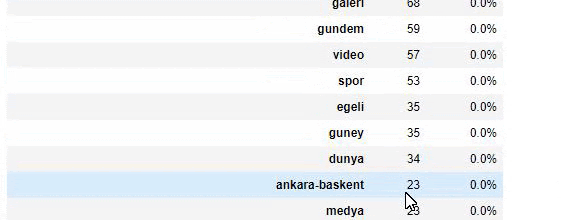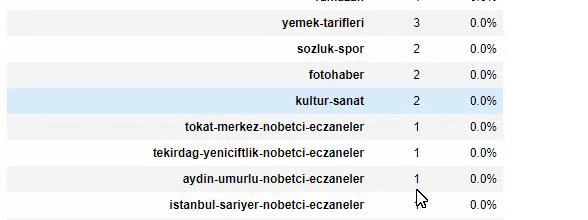
Lorsque nous analysons le contenu du journal Sabah, nous constatons qu'une partie importante de son contenu (81%) se trouve dans une catégorie appelée "apara". En outre, ils ont de grandes catégories pour l'astrologie, le calcul, le dictionnaire, la météo et les nouvelles du monde. (Para signifie l'argent en turc)
Pour Sabah Newspaper, nous pouvons également analyser le contenu avec des sitemaps que nous avons collectés uniquement avec Advertools, mais comme le journal en question est très grand, je ne l'ai pas préféré à cause du nombre élevé de sitemaps et du contenu de différents sitemaps contenant la même URL Catégorie.
Ci-dessous, vous pouvez également voir l'excès de sitemaps avec Advertools.
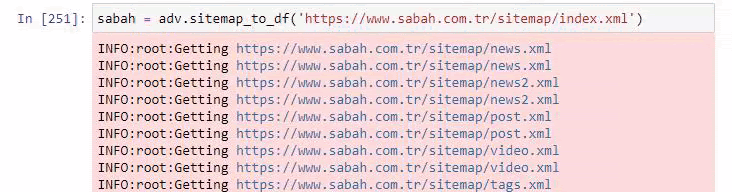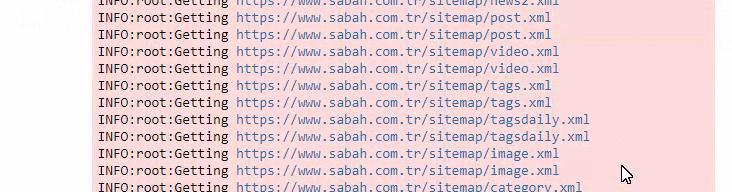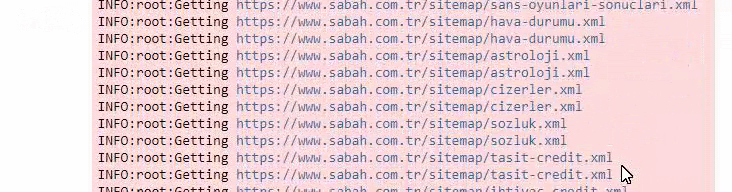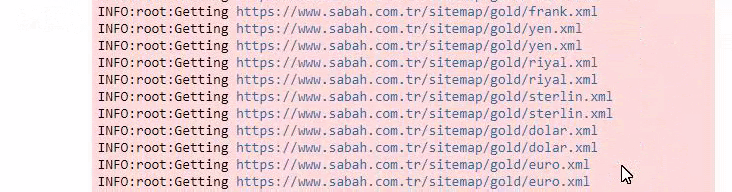
Nous pouvons voir qu'ils ont des plans de site différents pour les mêmes catégories d'URL telles que l'or, le crédit, les devises, les balises, les heures de prière et les heures de travail de la pharmacie, etc.
En bref, nous pouvons obtenir ces détails en nous concentrant sur des sous-catégories d'URL. Au lieu d'unifier différents sitemaps via des variables. J'ai donc unifié tous les sitemaps avec la méthode sitemap_to_df() d'Advertools comme au début de l'article.
Nous pouvons également utiliser un autre ensemble de fonctions créé par Elias Dabbas pour créer de meilleures trames de données. Si vous vérifiez les fonctions dataset_utililites, vous pouvez voir quelques exemples. Le code ci-dessous donne le total et le pourcentage d'une expression régulière d'URL spécifiée ainsi que la somme cumulée par stylisation.
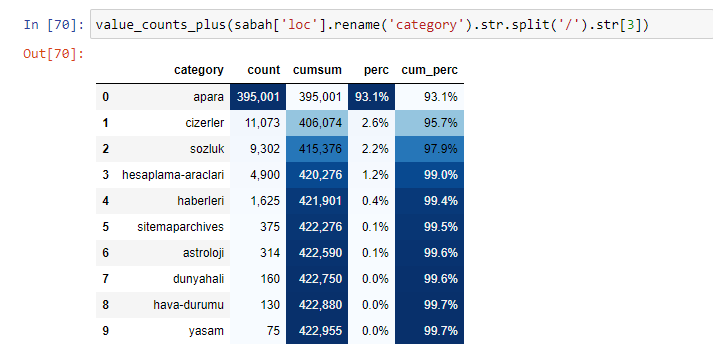
Si nous faisons la même chose avec une ventilation sous-URL du journal Sabah, nous obtiendrons le résultat suivant.
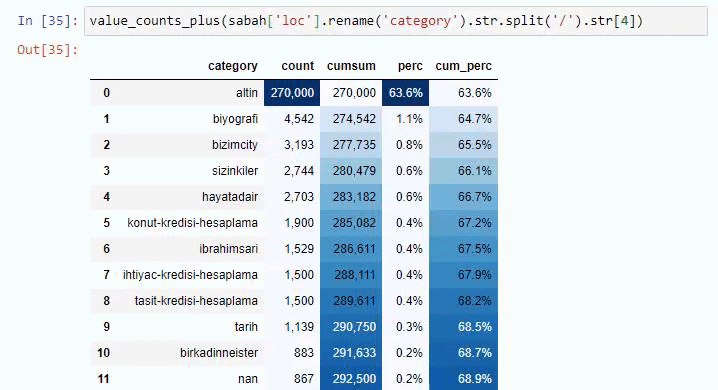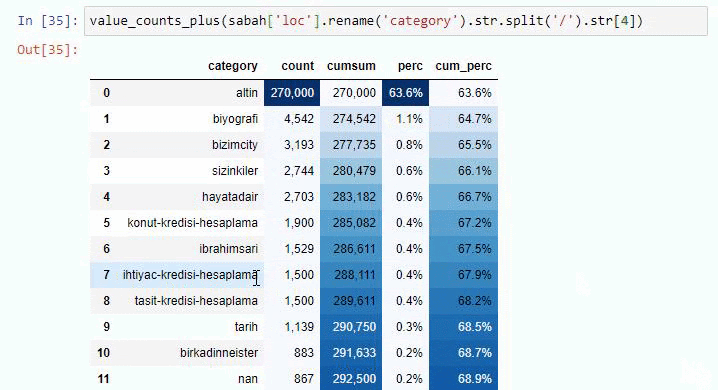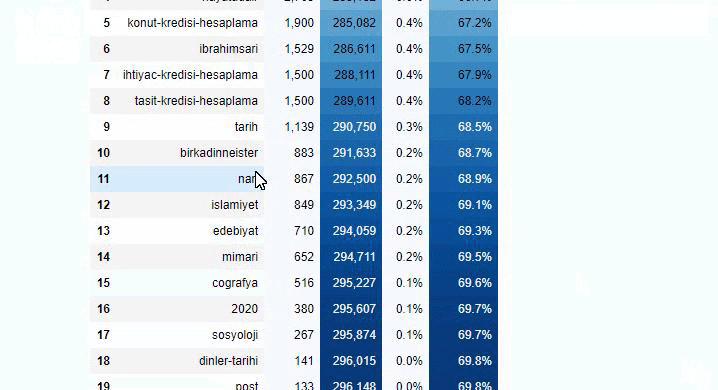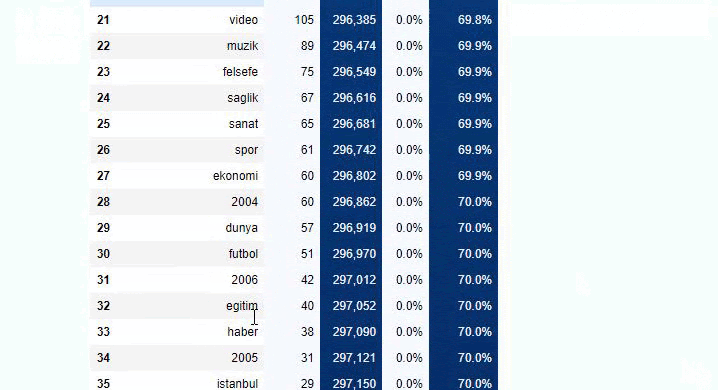
Vous pouvez augmenter le nombre de lignes que la fonction en question affichera en modifiant la ligne ci-dessous. De plus, si vous examinez le contenu de la fonction, vous verrez qu'elle est similaire à celles que nous avons utilisées auparavant.
Dans les sous-découpages, nous voyons différentes ventilations telles que « Histoire de la religion », « Biographie », « Noms de villes », « Football », « Bizimcity (Caricature) », « Crédit hypothécaire ». La répartition la plus importante se situe dans la catégorie "Or".
Alors, comment un journal peut-il avoir 295 000 URL pour les prix de l'or ?
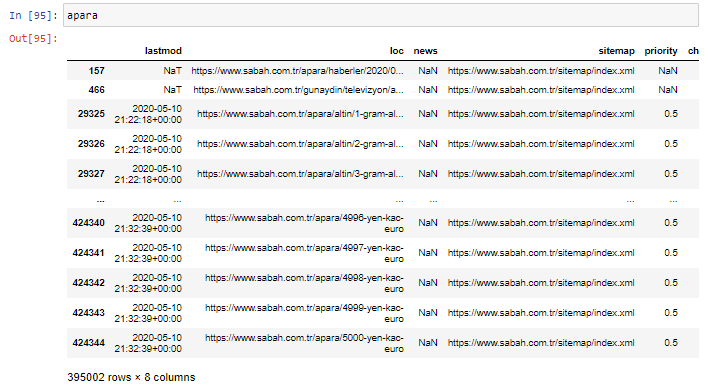
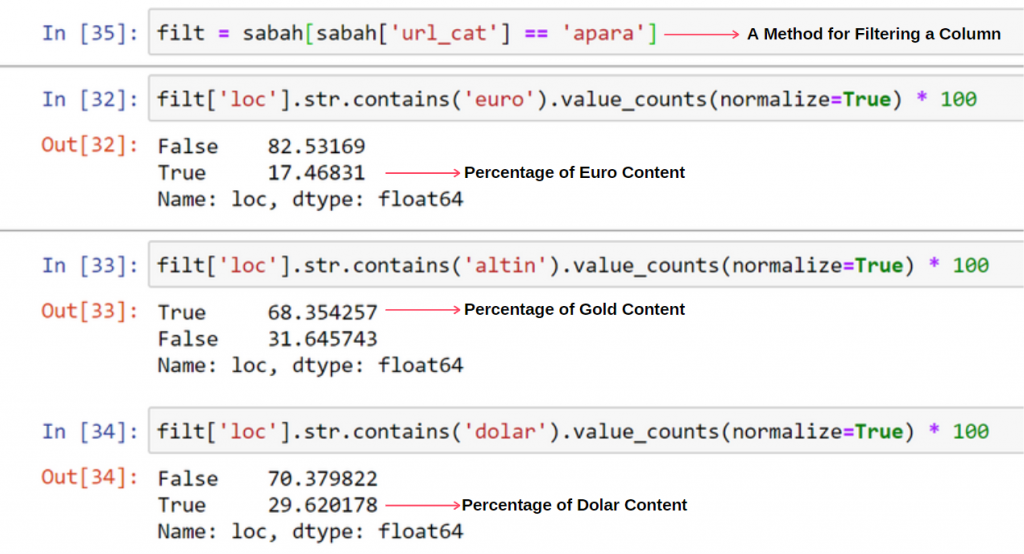
Tout d'abord, je jette toutes les URL qui contiennent le "apara" dans la première ventilation d'URL du journal Sabah dans une variable.
apara = sabah[sabah['loc'].str.contains('apara')]
Voici le résultat :
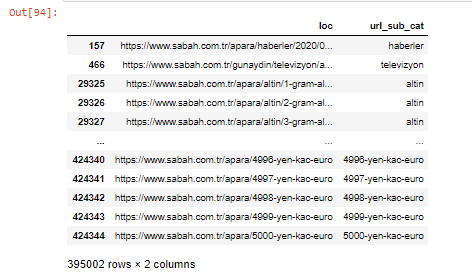
Nous pouvons également filtrer les colonnes avec la méthode .filter() :
Maintenant, nous pouvons voir au bas du DataFrame pourquoi le journal Sabah a une quantité excessive d'URL Apara parce qu'ils ont ouvert différentes pages Web pour chaque montant de calcul de devise tel que 5000 euros, 4999 euros, 4998 euros et plus…
Mais, avant toute conclusion, il faut être sûr car plus de 250 000 de ces URL appartiennent à la catégorie « altin (or) ».
apara.filter(['loc', 'url_sub_cat' ]).tail(60) nous montrera les 60 dernières lignes de ce Data Frame :

Nous pouvons faire de même pour la répartition des URL or au sein du groupe Apara.
or = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
À ce stade, nous voyons que le journal Sabah a ouvert 5000 pages différentes pour convertir chaque devise en dollar, euro, or et TL (lire turque). Il existe une page de calcul distincte pour chaque unité monétaire entre 1 et 5000. Vous pouvez voir l'exemple des 85 premières et 85 dernières lignes du groupe or ci-dessous. Une page distincte a été ouverte pour chaque gramme de prix de l'or.


Nous ne doutons pas que ces pages sont inutiles, avec beaucoup de contenu en double et excessivement volumineuses, mais Sabah Newspaper est un site Web si fort que Google continue de le montrer dans presque toutes les requêtes, en tête du classement.
À ce stade, nous pouvons également voir que la tolérance aux coûts de crawl est élevée pour un ancien site d'actualités à haute autorité.
Cependant, cela n'explique pas pourquoi la catégorie or a plus d'URL que les autres.
Je ne vois rien d'étrange à ce que des valeurs qui se chevauchent totalisent plus de 100 %.
A moins que j'ai raté quelque chose ?
Comme vous le remarquerez, lorsque nous additionnons toutes les valeurs vraies, nous obtenons le résultat de 115,16 %. La raison en est ci-dessous.
Même le groupe principal a une intersection les uns avec les autres comme ça. On pourrait aussi analyser ces intersections, mais cela pourrait faire l'objet d'un autre article.
Nous constatons que 68 % du contenu du groupe d'URL Apara sont liés à GOLD.
Pour mieux comprendre cette situation, la première chose que nous devons faire est de scanner les URL dans la réfraction d'or.
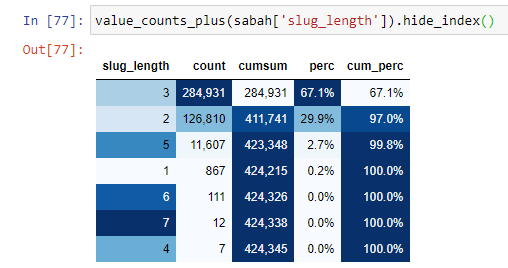
Lorsque l'on classe les URL selon le nombre de '/' qu'elles ont depuis la section racine, on constate que le nombre d'URL avec un maximum de 3 sauts est élevé. Lorsque nous analysons ces URL, nous constatons que 270 000 des 3 URL slug_length sont dans la catégorie Gold.
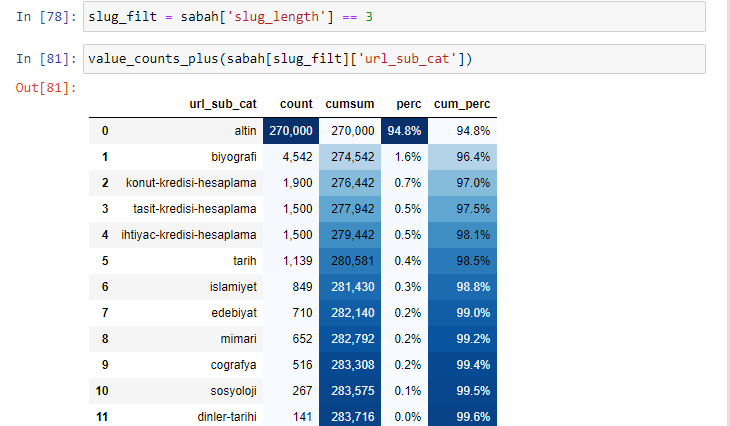
morning_filt = morning ['slug_length'] == 3 Cela signifie que vous n'obtenez que ceux qui sont égaux à 3 du groupe de données de type de données int dans une certaine colonne d'une certaine trame de données. Ensuite, sur la base de ces informations, nous encadrons les URL qui conviennent à la condition avec le nombre, les sommes et les taux d'agrégation avec la somme cumulée.
Lorsque nous extrayons les mots les plus couramment utilisés dans les URL dorées, nous rencontrons des mots qui représentent "plein", "république", "quart", "gramme", "moitié", "ancêtre". Les types d'or Ata et Republic sont uniques pour la Turquie. L'un d'eux représente la souveraineté turque et l'autre est le fondateur de la République, Kemal Atatürk. C'est pourquoi leurs volumes de recherche de requêtes sont élevés.
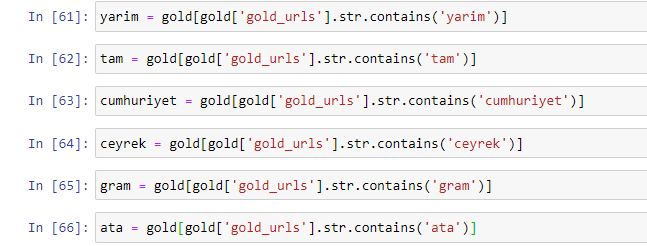
Tout d'abord, nous avons supprimé les mots communs trouvés dans les URL et les avons affectés à des variables distinctes. Ensuite, nous utiliserons ces variables dans le Gold DataFrame pour créer des colonnes spécifiques à leurs types.
Après avoir créé de nouvelles colonnes via des variables, nous devons les filtrer avec des valeurs booléennes.
Comme vous pouvez le voir, nous avons pu catégoriser toutes les URL or avec 270 000 lignes et 6 colonnes. La principale raison du nombre élevé de pages spécifiques à l'or est que le dollar ou l'euro n'ont pas de types distincts, tandis que l'or a des types distincts. Dans le même temps, la diversité des pages de croisement entre l'or et les différentes devises est plus élevée que les autres devises en raison de leur confiance traditionnelle dans le peuple turc.
À mon avis, tous les types de pages d'or devraient être équitablement répartis, n'est-ce pas ?
Nous pouvons facilement tester cela avec la fonction Heatmap de Seaborn.
importer seaborn en tant que sns
importer matplotlib.pyplot en tant que plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.show()
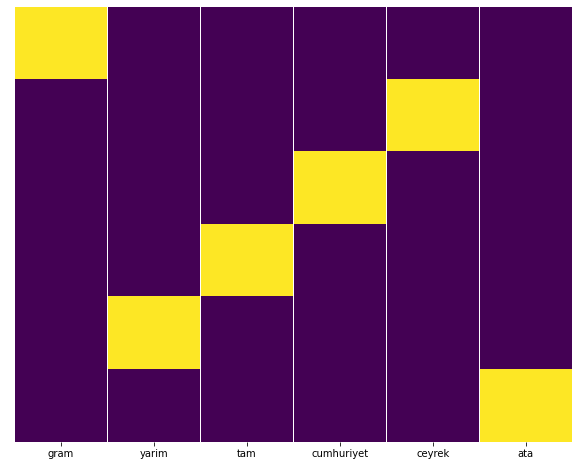
Ici, sur la carte thermique, les vrais dans chaque colonne sont simplement marqués. Comme on peut le voir, la taille de chacun est symétrique l'une de l'autre et est soigneusement disposée sur la carte.
Ainsi, nous avons adopté une large perspective sur la politique de contenu du journal Sabah.com.tr sur les devises et le calcul des devises.
À l'avenir, j'écrirai des sites Web d'actualités turcs et leurs stratégies de contenu basées sur Sitemaps Kaggle, qui a été lancé par Elias Dabbas, mais dans cet article, nous avons suffisamment parlé de ce qui peut être découvert sur les grands et les petits sites Web avec des sitemaps. .
Conclusion et plats à emporter
Je pense que nous avons vu à quel point il est facile de comprendre un site Web, grâce à une structure d'URL fluide et sémantique. Nous devons également nous rappeler à quel point une structure d'URL appropriée peut être précieuse pour Google.
Dans le futur, nous verrons de plus en plus de référenceurs se familiariser avec la science des données, la visualisation de données, la programmation frontale, etc. Je vois ce processus comme le début d'un changement inévitable : le fossé entre les référenceurs et les développeurs sera complètement comblé. dans quelques années.
Avec Python, vous pouvez pousser ce type d'analyse encore plus loin : il est possible d'obtenir des données en comprenant les opinions politiques d'un site d'information, sur qui écrit sur quoi, à quelle fréquence et avec quels sentiments. Je préfère ne pas m'y attarder ici car ces processus relèvent plus de la pure data science que du SEO (et cet article est déjà assez long).
Mais si cela vous intéresse, il existe de nombreux autres types d'audits qui peuvent être effectués via Sitemaps et Python, comme la vérification des codes d'état des URL dans un sitemap.
J'ai hâte d'expérimenter et de partager d'autres tâches de référencement que vous pouvez effectuer avec Python et Advertools.