
Comprendre l'IA : comment nous avons enseigné le langage naturel aux ordinateurs
Publié: 2023-11-28L’expression « intelligence artificielle » est utilisée en relation avec les ordinateurs depuis les années 1950, mais jusqu’à l’année dernière, la plupart des gens pensaient probablement que l’IA était encore plus une science-fiction qu’une réalité technologique.
L'arrivée de ChatGPT d'OpenAI en novembre 2022 a soudainement changé la perception des gens sur ce dont l'apprentissage automatique était capable – mais qu'est-ce qui a exactement fait que ChatGPT ait incité le monde à s'asseoir et à réaliser que l'intelligence artificielle était là à grande échelle ?
En un mot, le langage – la raison pour laquelle ChatGPT a semblé être un bond en avant si remarquable était dû à la façon dont il semblait parler couramment le langage naturel comme aucun chatbot ne l’a jamais été auparavant.
Il s’agit d’une nouvelle étape remarquable dans le « traitement du langage naturel » (NLP), la capacité des ordinateurs à interpréter le langage naturel et à produire des réponses convaincantes. ChatGPT est construit sur un « grand modèle de langage » (LLM), qui est un type de réseau neuronal utilisant l'apprentissage profond formé sur des ensembles de données massifs capables de traiter et de générer du contenu.
« Comment un programme informatique a-t-il atteint une telle maîtrise linguistique ? »
Mais comment en sommes-nous arrivés là ? Comment un programme informatique a-t-il atteint une telle maîtrise linguistique ? Comment cela semble-t-il si infailliblement humain ?
ChatGPT n’a pas été créé en vase clos : il s’appuie sur une myriade d’innovations et de découvertes différentes au cours des dernières décennies. La série d’avancées qui ont conduit à ChatGPT ont toutes constitué des jalons dans l’informatique, mais il est possible de les considérer comme imitant les étapes par lesquelles les humains acquièrent le langage.
Comment apprend-on la langue ?
Pour comprendre comment l'IA a atteint ce stade, il convient de considérer la nature même de l'apprentissage des langues : nous commençons par des mots simples, puis commençons à les combiner en séquences plus longues jusqu'à ce que nous puissions communiquer des concepts, des idées et des instructions complexes.
Par exemple, certaines étapes courantes de l’acquisition du langage chez les enfants sont :
- Stade holophrastique : entre 9 et 18 mois, les enfants apprennent à utiliser des mots simples qui décrivent leurs besoins ou désirs fondamentaux. Communiquer avec un seul mot signifie que l’accent est mis sur la clarté plutôt que sur l’exhaustivité conceptuelle. Si un enfant a faim, il ne dira pas « Je veux de la nourriture » ou « J'ai faim », mais il dira simplement « de la nourriture » ou « du lait ».
- Étape de deux mots : entre 18 et 24 mois, les enfants commencent à utiliser des regroupements simples de deux mots pour améliorer leurs compétences en communication. Ils peuvent désormais communiquer leurs sentiments et leurs besoins avec des expressions telles que « plus de nourriture » ou « lire un livre ».
- Stade télégraphique : entre 24 et 30 mois, les enfants commencent à enchaîner plusieurs mots pour former des expressions et des phrases plus complexes. Le nombre de mots utilisés est encore faible, mais un ordre correct des mots et une plus grande complexité commencent à apparaître. Les enfants commencent à apprendre la construction de phrases de base, telles que « je veux le montrer à maman ».
- Étape multi-mots : Après 30 mois, les enfants commencent à passer à l’étape multi-mots. À ce stade, les enfants commencent à utiliser des phrases plus grammaticalement correctes, plus complexes et comportant plusieurs clauses. Il s’agit de la dernière étape de l’acquisition du langage et les enfants finissent par communiquer avec des phrases complexes telles que « S’il pleut, je veux rester à l’intérieur et jouer à des jeux ».
L’une des premières étapes clés de l’acquisition d’une langue est la capacité à commencer à utiliser des mots isolés de manière très simple. Le premier obstacle que les chercheurs en IA devaient donc surmonter était de savoir comment entraîner des modèles à apprendre des associations de mots simples.
Modèle 1 – Apprendre des mots simples avec Word2Vec (épreuve 1 et épreuve 2)
L'un des premiers modèles de réseaux neuronaux ayant tenté d'apprendre les associations de mots de cette manière était Word2Vec, développé par Tomaš Mikolov et un groupe de chercheurs de Google. Il a été publié dans deux articles en 2013 (ce qui montre à quelle vitesse les choses se sont développées dans ce domaine.)
Ces modèles ont été formés en apprenant à associer des mots couramment utilisés ensemble. Cette approche s'appuie sur l'intuition des premiers pionniers de la linguistique tels que John R. Firth, qui a noté que le sens pouvait être dérivé de l'association de mots : « Vous connaîtrez un mot par la compagnie qu'il tient. »
L’idée est que les mots qui partagent une signification sémantique similaire ont tendance à apparaître plus fréquemment ensemble. Les mots « chats » et « chiens » apparaissent généralement plus fréquemment ensemble qu'avec des mots comme « pommes » ou « ordinateurs ». En d’autres termes, le mot « chat » devrait ressembler davantage au mot « chien » que « chat » ne le serait à « pomme » ou « ordinateur ».
La chose intéressante à propos de Word2Vec est la façon dont il a été formé pour apprendre ces associations de mots :
- Devinez le mot cible : le modèle reçoit un nombre fixe de mots en entrée, le mot cible étant manquant et il doit deviner le mot cible manquant. Ceci est connu sous le nom de sac de mots continu (CBOW).
- Devinez les mots environnants : le modèle reçoit un seul mot, puis est chargé de deviner les mots environnants. Ceci est connu sous le nom de Skip-Gram et constitue l’approche opposée du CBOW dans la mesure où nous prédisons les mots environnants.
L’un des avantages de ces approches est que vous n’avez pas besoin de données étiquetées pour entraîner le modèle : étiqueter des données, par exemple décrire un texte comme « positif » ou « négatif » pour enseigner l’analyse des sentiments, est un travail lent et laborieux, après tout.
L'une des choses les plus surprenantes de Word2Vec était les relations sémantiques complexes qu'il capturait avec une approche de formation relativement simple. Word2Vec génère des vecteurs qui représentent le mot d'entrée. En effectuant des opérations mathématiques sur ces vecteurs, les auteurs ont pu montrer que les vecteurs de mots capturaient non seulement des éléments syntaxiquement similaires, mais également des relations sémantiques complexes.
Ces relations sont liées à la manière dont les mots sont utilisés. L'exemple cité par les auteurs était la relation entre des mots comme « Roi » et « Reine » et « Homme » et « Femme ».
Mais même s’il s’agissait d’un pas en avant, Word2Vec avait des limites. Il n’y avait qu’une seule définition par mot – par exemple, nous savons tous que « banque » peut signifier différentes choses selon que vous envisagez d’en retenir une ou de pêcher à partir d’une. Word2Vec s'en fichait, il n'avait qu'une seule définition du mot « banque » et l'utiliserait dans tous les contextes.
Surtout, Word2Vec ne pouvait pas traiter les instructions ni même les phrases. Il ne pouvait prendre qu'un mot comme entrée et produire une « incorporation de mots », ou représentation vectorielle, qu'il avait apprise pour ce mot. Pour s’appuyer sur cette base de mots uniques, les chercheurs devaient trouver un moyen d’enchaîner deux mots ou plus dans une séquence. Nous pouvons imaginer que cela soit similaire à l’étape de l’acquisition du langage à deux mots.
Modèle 2 – Apprentissage de séquences de mots avec des RNN et des séquences de texte
Une fois que les enfants ont commencé à maîtriser l’utilisation d’un seul mot, ils tentent de rassembler des mots pour exprimer des pensées et des sentiments plus complexes. De même, l’étape suivante dans le développement de la PNL consistait à développer la capacité à traiter des séquences de mots. Le problème du traitement des séquences de texte est qu’elles n’ont pas de longueur fixe. La longueur d’une phrase peut varier de quelques mots à un long paragraphe. La totalité de la séquence ne sera pas importante pour la signification et le contexte généraux. Mais nous devons être capables de traiter l’intégralité de la séquence pour savoir quelles parties sont les plus pertinentes.
C'est là qu'apparaissent les réseaux de neurones récurrents (RNN).
Développé dans les années 1990, un RNN fonctionne en traitant son entrée dans une boucle où la sortie des étapes précédentes est acheminée à travers le réseau au fur et à mesure qu'elle parcourt chaque étape de la séquence.
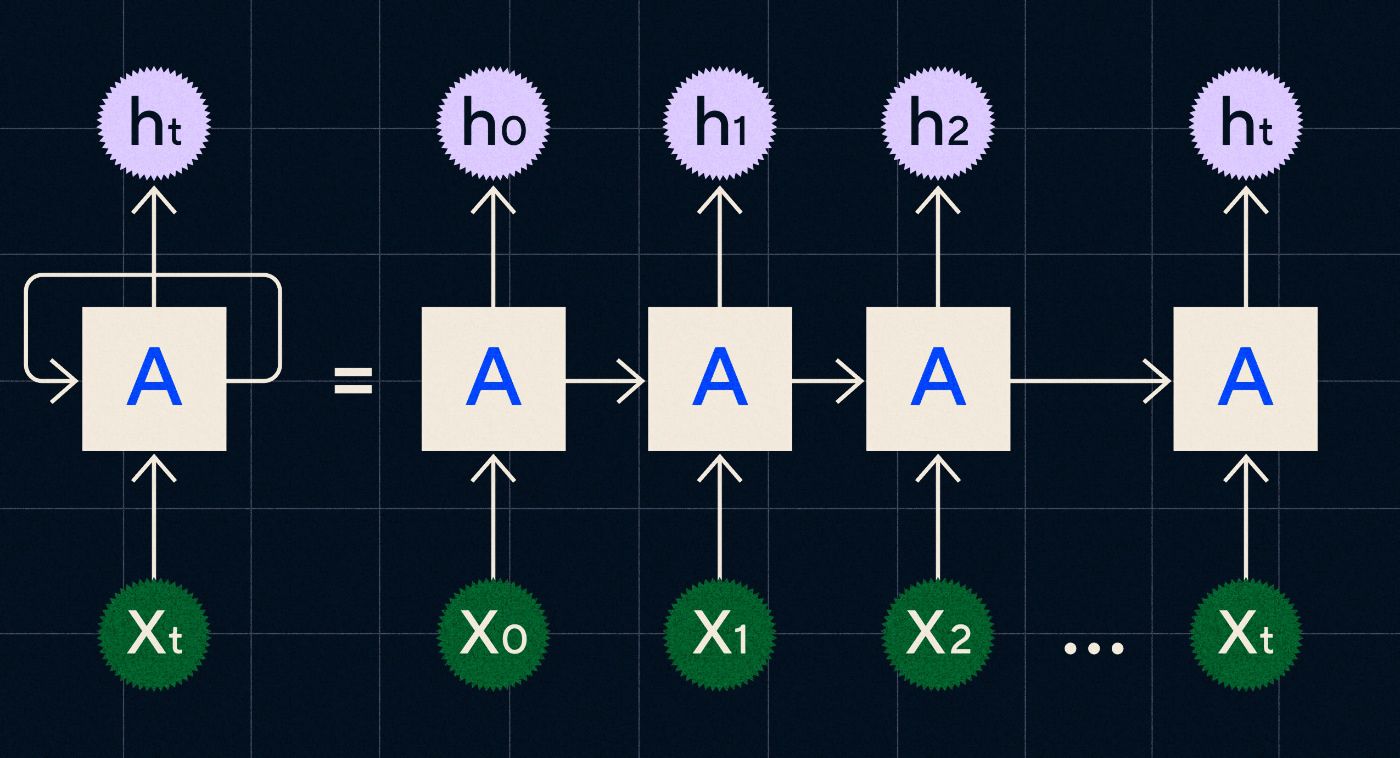
Source : article de blog de Christopher Olah sur les RNN
Le diagramme ci-dessus montre comment imaginer un RNN comme une série de réseaux de neurones (A) où la sortie de l'étape précédente (h0, h1, h2… ht) est transmise à l'étape suivante. A chaque étape une nouvelle entrée (X0, X1, X2… Xt) est également traitée par le réseau.
Les RNN (et plus particulièrement les réseaux de mémoire à long terme ou LSTM, un type spécial de RNN introduit par Sepp Hochreiter et Jurgen Schmidhuber en 1997) nous ont permis de créer des architectures de réseaux neuronaux capables d'effectuer des tâches plus complexes telles que la traduction.
En 2014, un article a été publié par Ilya Sutskever (co-fondateur d'OpenAI), Oriol Vinyals et Quoc V Le chez Google, qui décrivait les modèles Sequence to Sequence (Seq2Seq). Cet article a montré comment entraîner un réseau de neurones à prendre un texte saisi et à renvoyer une traduction de ce texte. Vous pouvez considérer cela comme un premier exemple de réseau neuronal génératif, dans lequel vous lui donnez une invite et il renvoie une réponse. Cependant, la tâche était fixe, donc s'il était formé à la traduction, vous ne pouviez pas le « inciter » à faire autre chose.
N'oubliez pas que le modèle précédent, Word2Vec, ne pouvait traiter que des mots simples. Donc, si vous lui transmettez une phrase comme « le dentiste m'a arraché une dent », cela générerait simplement un vecteur pour chaque mot comme s'ils n'avaient aucun rapport.
Cependant, l’ordre et le contexte sont importants pour des tâches telles que la traduction. Vous ne pouvez pas simplement traduire des mots individuels, vous devez analyser des séquences de mots, puis afficher le résultat. C'est là que les RNN ont permis aux modèles Seq2Seq de traiter les mots de cette manière.
La clé des modèles Seq2Seq était la conception du réseau neuronal, qui utilisait deux RNN dos à dos. L'un était un encodeur qui transformait l'entrée du texte en une intégration, et l'autre était un décodeur qui prenait comme entrée les intégrations émises par l'encodeur :
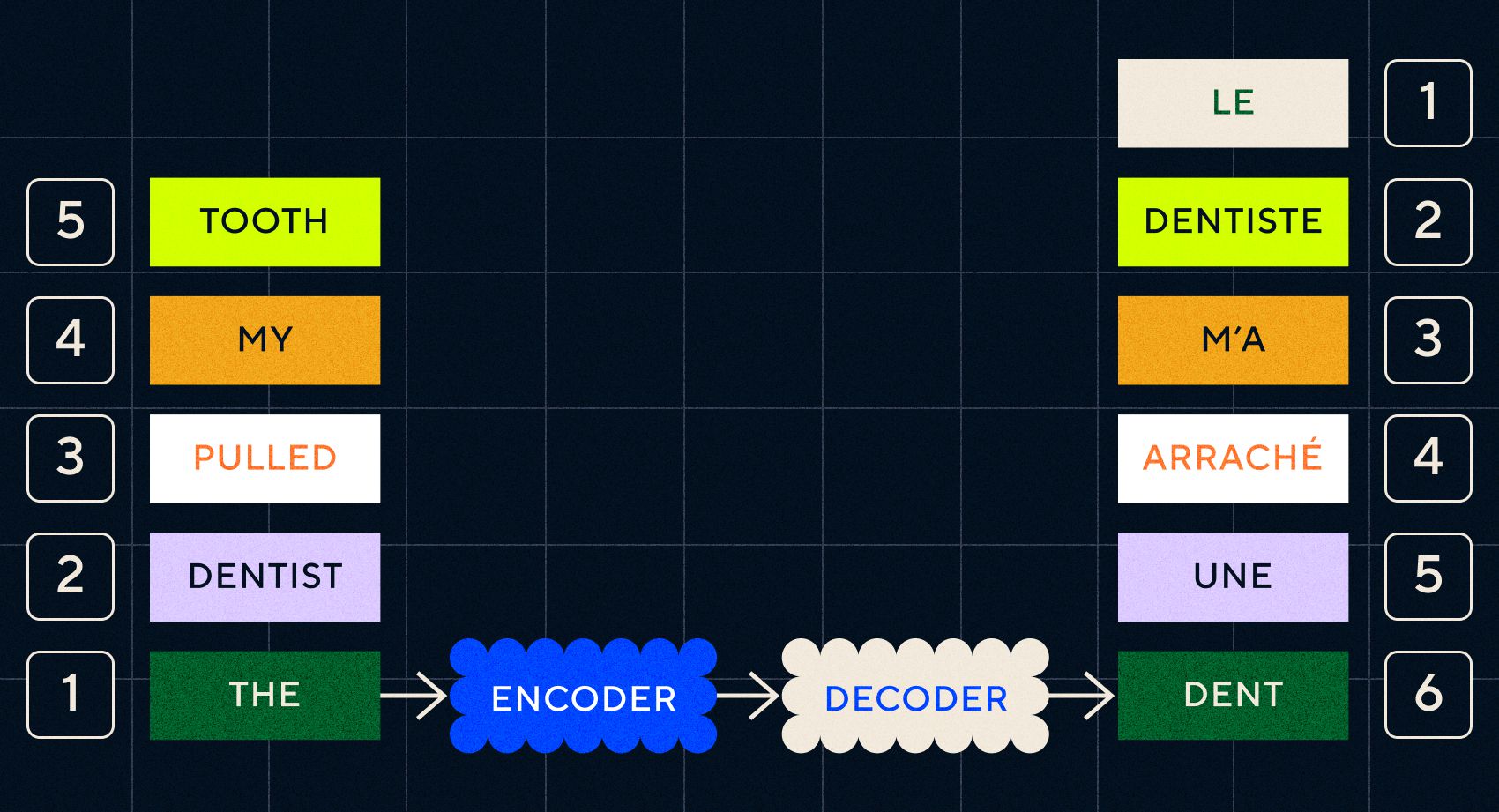
Une fois que l'encodeur a traité les entrées à chaque étape, il commence alors à transmettre la sortie au décodeur qui transforme les intégrations en un texte traduit.
Nous pouvons voir avec l’évolution de ces modèles qu’ils commencent à ressembler, sous une forme simple, à ce que nous voyons aujourd’hui avec ChatGPT. Cependant, nous pouvons également constater à quel point ces modèles étaient limités en comparaison. Comme pour notre propre développement du langage, pour vraiment améliorer nos capacités linguistiques, nous devons savoir exactement à quoi prêter attention afin de créer des expressions et des phrases plus complexes.
Modèle 3 – Apprentissage par attention et mise à l’échelle avec Transformers
Nous avons noté plus tôt que les étapes télégraphiques étaient celles où les enfants commençaient à créer des phrases courtes de deux mots ou plus. Un aspect clé de cette étape de l’acquisition du langage est que les enfants commencent à apprendre à construire des phrases appropriées.
Les modèles RNN et Seq2Seq aidaient les modèles de langage à traiter plusieurs séquences de mots, mais ils étaient toujours limités dans la longueur des phrases qu'ils pouvaient traiter. À mesure que la longueur de la phrase augmente, nous devons prêter attention à la plupart des éléments de la phrase.
Par exemple, prenons la phrase suivante « Il y avait tellement de tension dans la pièce qu’on pourrait la couper avec un couteau ». Il se passe beaucoup de choses là-bas. Pour savoir que nous ne coupons pas littéralement quelque chose avec un couteau, nous devons lier « couper » à « tension » plus tôt dans la phrase.
À mesure que la longueur des phrases augmente, il devient plus difficile de savoir à quels mots font référence et d’en déduire le sens propre. C’est là que les RNN ont commencé à rencontrer des limites et nous avions besoin d’un nouveau modèle pour passer à l’étape suivante de l’acquisition du langage.
« Pensez à essayer de résumer une conversation au fur et à mesure qu'elle devient de plus en plus longue avec une limite fixe de mots. À chaque étape, vous commencez à perdre de plus en plus d’informations. »
En 2017, un groupe de chercheurs de Google a publié un article proposant une technique permettant de mieux permettre aux modèles de prêter attention au contexte important d'un morceau de texte.
Ce qu'ils ont développé était un moyen pour les modèles de langage de rechercher plus facilement le contexte dont ils avaient besoin lors du traitement d'une séquence de texte d'entrée. Ils ont appelé cette approche « architecture de transformation » et elle représentait le plus grand progrès dans le traitement du langage naturel à ce jour.
Ce mécanisme de recherche permet au modèle d'identifier plus facilement lequel des mots précédents a fourni plus de contexte au mot en cours de traitement. Les RNN tentent de fournir du contexte en transmettant un état agrégé de tous les mots déjà traités à chaque étape. Pensez à essayer de résumer une conversation au fur et à mesure qu'elle devient de plus en plus longue avec une limite fixe de mots. À chaque étape, vous commencez à perdre de plus en plus d’informations. Au lieu de cela, les transformateurs ont pondéré les mots (ou les jetons, qui ne sont pas des mots entiers mais des parties de mots) en fonction de leur importance pour le mot actuel en termes de contexte. Cela a facilité le traitement de séquences de mots de plus en plus longues sans le goulot d'étranglement observé dans les RNN. Ce nouveau mécanisme d'attention a également permis au texte d'être traité en parallèle plutôt que séquentiellement comme un RNN.
Imaginez donc une phrase comme « L'animal n'a pas traversé la rue parce qu'il était trop fatigué ». Pour un RNN, il faudrait représenter tous les mots précédents à chaque étape. À mesure que le nombre de mots entre « ça » et « animal » augmente, il devient plus difficile pour le RNN d'identifier le contexte approprié.

Avec l'architecture du transformateur, le modèle a désormais la capacité de rechercher le mot le plus susceptible de faire référence à « cela ». Le diagramme ci-dessous montre comment les modèles de transformateurs sont capables de se concentrer sur la partie « l'animal » du texte lorsqu'ils tentent de traiter une phrase.
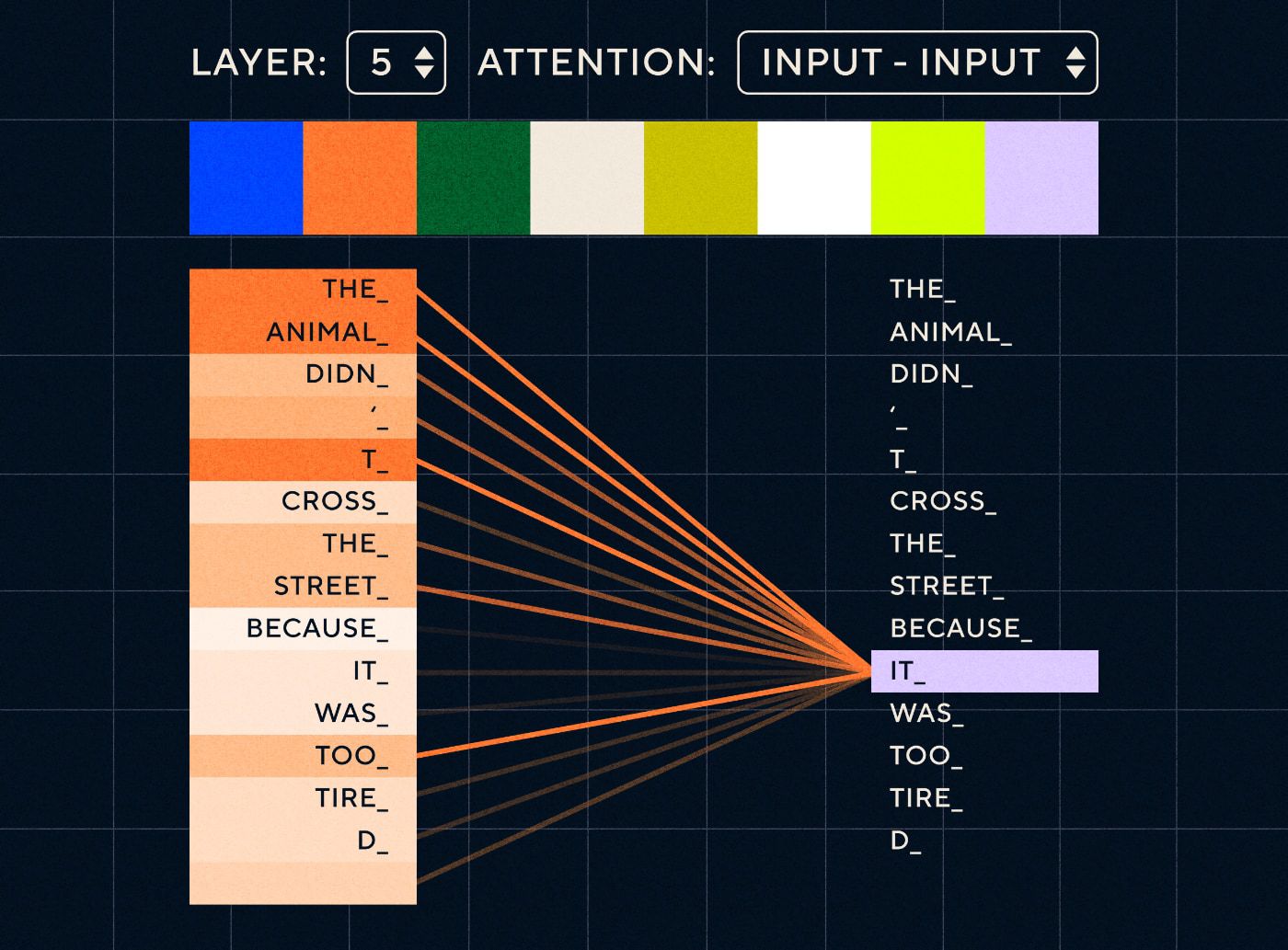
Source : Le transformateur illustré
Le diagramme ci-dessus montre l'attention au niveau de la couche 5 du réseau. À chaque niveau, le modèle développe sa compréhension de la phrase et « prête attention » à une partie particulière de l'entrée qu'il considère comme plus pertinente pour l'étape qu'il traite à ce moment-là, c'est-à-dire qu'il accorde plus d'attention à « l'étape de traitement ». animal » pour le « ça » dans cette couche. Source : Le Transformer illustré
Considérez-le comme une base de données dans laquelle il peut récupérer le mot avec le score le plus élevé et qui est le plus probablement lié à « cela ».
Avec ce développement, les modèles de langage ne se limitent plus à analyser de courtes séquences textuelles. Au lieu de cela, vous pouvez utiliser des séquences de texte plus longues comme entrées. Nous savons qu’exposer les enfants à davantage de mots via une « conversation engagée » contribue à améliorer leur développement linguistique.
De même, avec le nouveau mécanisme d’attention, les modèles de langage ont pu analyser des types plus nombreux et variés de données d’entraînement textuelles. Cela incluait les articles Wikipédia, les forums en ligne, Twitter et toute autre donnée textuelle que vous pouviez analyser. Comme pour le développement de l’enfant, l’exposition à tous ces mots et à leur utilisation dans différents contextes a aidé les modèles linguistiques à développer des capacités linguistiques nouvelles et plus complexes.
C’est au cours de cette phase que nous avons commencé à assister à une course à la mise à l’échelle où les gens jetaient de plus en plus de données sur ces modèles pour voir ce qu’ils pouvaient en apprendre. Ces données n’avaient pas besoin d’être étiquetées par des humains : les chercheurs pouvaient simplement parcourir Internet et les transmettre au modèle et voir ce qu’il avait appris.
« Des modèles comme BERT ont battu tous les records de traitement du langage naturel disponibles. En fait, les ensembles de données de test utilisés pour ces tâches étaient beaucoup trop simples pour ces modèles de transformateurs. »
Le modèle BERT (Bidirectionnel Encoder Representations from Transformers) mérite une mention spéciale pour plusieurs raisons. Ce fut l’un des premiers modèles à utiliser la fonction d’attention qui est au cœur de l’architecture Transformer. Premièrement, BERT était bidirectionnel dans le sens où il pouvait examiner le texte à gauche et à droite de l'entrée actuelle. C'était différent des RNN qui ne pouvaient traiter le texte que de manière séquentielle de gauche à droite. Deuxièmement, BERT a également utilisé une nouvelle technique de formation appelée « masquage » qui, d'une certaine manière, obligeait le modèle à apprendre la signification des différentes entrées en « cachant » ou en « masquant » des jetons aléatoires pour garantir que le modèle ne puisse pas « tricher » et concentrez-vous sur un seul jeton à chaque itération. Et enfin, BERT pourrait être affiné pour effectuer différentes tâches de PNL. Il n’était pas nécessaire de le former de toutes pièces pour ces tâches.
Les résultats ont été étonnants. Des modèles comme BERT ont battu tous les records disponibles en matière de traitement du langage naturel. En fait, les ensembles de données de test utilisés pour ces tâches étaient beaucoup trop simples pour ces modèles de transformateur.
Nous avions désormais la possibilité de former de grands modèles de langage qui servaient de modèles de base pour de nouvelles tâches de traitement du langage naturel. Auparavant, les gens entraînaient principalement leurs modèles à partir de zéro. Mais désormais, les modèles pré-entraînés comme BERT et les premiers modèles GPT étaient si bons qu'il ne servait à rien de le faire vous-même. En fait, ces modèles étaient si efficaces que les gens ont découvert qu'ils pouvaient effectuer de nouvelles tâches avec relativement peu d'exemples – ils ont été décrits comme des « apprenants en quelques étapes », de la même manière que la plupart des gens n'ont pas besoin de trop d'exemples pour appréhender de nouveaux concepts.
Ce fut un point d’inflexion majeur dans le développement de ces modèles et de leurs capacités linguistiques. Il ne nous restait plus qu'à améliorer les instructions de fabrication.
Modèle 4 – Instructions d’apprentissage avec InstructGPT
L’une des choses que les enfants apprennent au cours de la dernière étape de l’acquisition du langage, l’étape multi-mots, est la capacité d’utiliser des mots fonctionnels pour relier les éléments porteurs d’informations dans une phrase. Les mots fonctionnels nous renseignent sur la relation entre les différents mots dans une phrase. Si nous voulons créer des instructions, les modèles de langage devront être capables de créer des phrases avec des mots de contenu et des mots de fonction qui capturent des relations complexes. Par exemple, dans l'instruction suivante, les mots de fonction sont mis en évidence en gras :
- « Je veux que tu écrives une lettre…»
- "Dites -moi ce que vous pensez du texte ci-dessus "
Mais avant de pouvoir essayer de former des modèles de langage à suivre des instructions, nous devions comprendre exactement ce qu'ils savaient déjà sur les instructions.
Le GPT-3 d'OpenAI est sorti en 2020. C'était un aperçu de ce dont ces modèles étaient capables, mais nous devions encore comprendre comment débloquer les capacités sous-jacentes de ces modèles. Comment pourrions-nous interagir avec ces modèles pour les amener à effectuer différentes tâches ?
Par exemple, GPT-3 a montré que l’augmentation de la taille du modèle et des données de formation permettait ce que les auteurs appelaient le « méta-apprentissage » : c’est là que le modèle linguistique développe un large éventail de capacités linguistiques, dont beaucoup étaient inattendues, et peut les utiliser. compétences pour comprendre une tâche donnée.
« Le modèle serait-il capable de comprendre l'intention de l'instruction et d'exécuter la tâche plutôt que de simplement prédire le mot suivant ?
N'oubliez pas que GPT-3 et les modèles de langage antérieurs n'ont pas été conçus pour développer ces compétences : ils ont principalement été formés pour simplement prédire le mot suivant dans une séquence de texte. Mais grâce aux progrès des RNN, Seq2Seq et des réseaux d’attention, ces modèles ont pu traiter davantage de texte, dans des séquences plus longues et mieux se concentrer sur le contexte pertinent.
Vous pouvez considérer GPT-3 comme un test pour voir jusqu’où nous pourrions aller. Quelle taille pourrions-nous faire aux modèles et quelle quantité de texte pourrions-nous leur alimenter ? Ensuite, après cela, au lieu de simplement fournir au modèle du texte d'entrée à compléter, nous pourrions utiliser le texte d'entrée comme instruction. Le modèle serait-il capable de comprendre l’intention de l’instruction et d’exécuter la tâche plutôt que de simplement prédire le mot suivant ? D’une certaine manière, c’était comme essayer de comprendre à quel stade d’acquisition du langage ces modèles étaient parvenus.
Nous décrivons maintenant cela comme une « incitation », mais en 2020, au moment de la parution du document, il s’agissait d’un concept très nouveau.
Hallucinations et alignement
Le problème avec GPT-3, comme nous le savons maintenant, était qu'il n'était pas très efficace pour s'en tenir strictement aux instructions contenues dans le texte saisi. GPT-3 peut suivre des instructions mais il perd facilement son attention, ne peut comprendre que des instructions simples et a tendance à inventer des choses. En d’autres termes, les modèles ne sont pas « alignés » sur nos intentions. Le problème n’est donc plus tant d’améliorer les compétences linguistiques des modèles que leur capacité à suivre des instructions.
Il convient de noter que GPT-3 n’a jamais été vraiment formé sur instructions. On ne lui disait pas ce qu'était une instruction, ni en quoi elle différait des autres textes, ni comment elle était censée suivre les instructions. D'une certaine manière, il a été « trompé » pour qu'il suive des instructions en lui faisant « compléter » une invite comme les autres séquences de texte. En conséquence, OpenAI devait former un modèle plus capable de suivre des instructions comme un humain. Et ils l’ont fait dans un article intitulé à juste titre Former des modèles de langage pour suivre les instructions avec des commentaires humains, publié début 2022. InstructGPT se révélerait être un précurseur de ChatGPT plus tard dans la même année.
Les étapes décrites dans ce document ont également été utilisées pour former ChatGPT. La formation pédagogique a suivi 3 étapes principales :
- Étape 1 – Affiner GPT-3 : Étant donné que GPT-3 semblait si bien fonctionner avec un apprentissage en quelques étapes, l’idée était qu’il serait préférable qu’il soit affiné sur des exemples d’instructions de haute qualité. L'objectif était de faciliter l'alignement de l'intention de l'instruction avec la réponse générée. Pour ce faire, OpenAI a demandé à des étiqueteurs humains de créer des réponses à certaines invites soumises par des personnes utilisant GPT-3. En utilisant des instructions réelles, les auteurs espéraient capturer une « répartition » réaliste des tâches que les utilisateurs essayaient de faire exécuter par GPT-3. Celles-ci ont été utilisées pour affiner GPT-3 afin de l’aider à améliorer sa capacité de réponse rapide.
- Étape 2 – Amener les humains à classer le nouveau GPT-3 amélioré : pour évaluer la nouvelle instruction GPT-3 affinée, les étiqueteurs ont désormais évalué les performances des modèles sur différentes invites sans réponse prédéfinie. Le classement était lié à des facteurs d’alignement importants, tels que le fait d’être utile, véridique et non toxique, biaisé ou nuisible. Donnez donc une tâche au modèle et évaluez ses performances en fonction de ces mesures. Le résultat de cet exercice de classement a ensuite été utilisé pour former un modèle distinct afin de prédire quels résultats les étiqueteurs préféreraient probablement. Ce modèle est connu sous le nom de modèle de récompense (RM).
- Étape 3 – Utilisez le RM pour vous entraîner sur davantage d'exemples : Enfin, le RM a été utilisé pour entraîner le nouveau modèle d'instruction afin de mieux générer des réponses alignées sur les préférences humaines.
Il est difficile de comprendre pleinement ce qui se passe ici avec l'apprentissage par renforcement à partir du feedback humain (RLHF), les modèles de récompense, les mises à jour des politiques, etc.
Une façon simple d’y penser est qu’il s’agit simplement d’un moyen de permettre aux humains de générer de meilleurs exemples sur la façon de suivre les instructions. Par exemple, pensez à la façon dont vous essaieriez d’apprendre à un enfant à dire merci :
- Parent : « Quand quelqu’un te donne X, tu dis merci ». Il s'agit de l'étape 1, un exemple d'ensemble de données d'invites et de réponses appropriées.
- Parent : « Maintenant, qu'est-ce que tu dis à Y ici ? ». Il s'agit de l'étape 2 où nous demandons à l'enfant de générer une réponse, puis le parent l'évaluera. "Oui c'est bon."
- Enfin, lors de rencontres ultérieures, le parent récompensera l'enfant en fonction de bons ou de mauvais exemples de réponses dans des scénarios similaires à l'avenir. Il s’agit de l’étape 3, où se déroule le comportement de renforcement.
Pour sa part, OpenAI affirme que tout ce qu'il fait est simplement de débloquer des capacités qui étaient déjà présentes dans des modèles comme GPT-3, « mais qui étaient difficiles à obtenir par la seule ingénierie rapide », comme le dit le document.
En d’autres termes, ChatGPT n’apprend pas vraiment de « nouvelles » fonctionnalités, mais simplement une meilleure « interface » linguistique pour les utiliser.
La magie du langage
ChatGPT ressemble à un bond en avant magique, mais il est en réalité le résultat de progrès technologiques minutieux au fil des décennies.
En examinant certains des développements majeurs dans le domaine de l’IA et de la PNL au cours de la dernière décennie, nous pouvons voir à quel point ChatGPT « se tient sur les épaules de géants ». Les modèles antérieurs ont d’abord appris à identifier le sens des mots. Ensuite, les modèles suivants ont rassemblé ces mots et nous avons pu les entraîner à effectuer des tâches telles que la traduction. Une fois qu'ils ont pu traiter des phrases, nous avons développé des techniques qui ont permis à ces modèles de langage de traiter de plus en plus de texte et de développer la capacité d'appliquer ces apprentissages à des tâches nouvelles et imprévues. Et puis, avec ChatGPT nous avons enfin développé la possibilité de mieux interagir avec ces modèles en spécifiant nos instructions dans un format en langage naturel.
« Puisque le langage est le véhicule de nos pensées, l’enseignement aux ordinateurs de toute la puissance du langage mènera-t-il à une intelligence artificielle indépendante ?
Cependant, l'évolution de la PNL révèle une magie plus profonde à laquelle nous sommes généralement aveugles : la magie du langage lui-même et la manière dont nous, en tant qu'humains, l'acquérons.
Il existe encore de nombreuses questions et controverses ouvertes sur la manière dont les enfants apprennent la langue. On se demande également s’il existe une structure sous-jacente commune à toutes les langues. Les humains ont-ils évolué pour utiliser le langage ou est-ce l’inverse ?
Ce qui est curieux, c'est que, à mesure que ChatGPT et ses descendants améliorent leur développement linguistique, ces modèles peuvent aider à répondre à certaines de ces questions importantes.
Enfin, puisque le langage est le véhicule de nos pensées, l’enseignement aux ordinateurs de toute la puissance du langage mènera-t-il à une intelligence artificielle indépendante ? Comme toujours dans la vie, il reste tellement de choses à apprendre.
