
Hacker The Topic Graph avec Wikipedia et l'API Google Language
Publié: 2019-08-27L'un de mes jeux de diapositives préférés des dix dernières années a été réalisé par Mark Johnstone en 2014, alors qu'il était encore chez Distilled. Le jeu s'appelait Comment produire de meilleures idées de contenu et je l'ai utilisé comme ma bible pendant quelques années tout en constituant des équipes pour faire le travail acharné de la promotion du contenu.
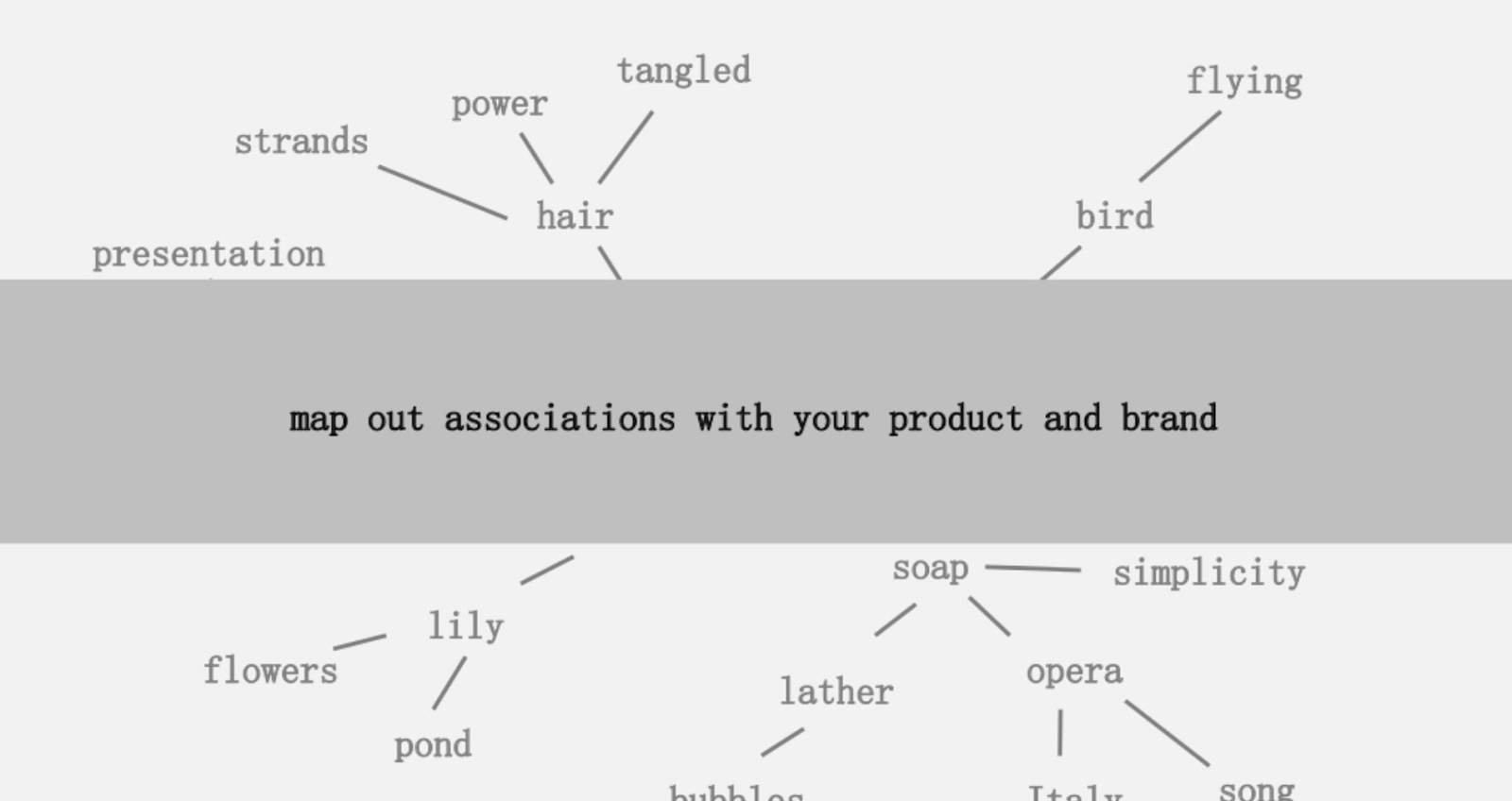
L'une des idées proposées était de créer une cartographie visuelle de la connexité des mots associés à votre produit ou à votre marque afin que vous puissiez prendre du recul et chercher des moyens de combiner les associations en quelque chose d'intéressant. L'objectif étant la production d'idées, qu'il définit comme " une nouvelle combinaison d'éléments auparavant non connectés d'une manière qui ajoute de la valeur".
Dans cet article, nous adoptons une approche beaucoup plus gauche, en utilisant Python, l'API Language de Google, ainsi que Wikipedia, pour explorer les associations d'entités qui existent à partir d'un sujet de départ. L'objectif étant une vue de haut niveau des relations entre les entités le long du graphique thématique. Cet article n'est pas pour le lecteur moyen. Les lecteurs qui connaissent Python et qui ont au moins un niveau de base de capacité de codage le trouveront beaucoup plus instructif.
L'idée
Suite à l'idée de cartographie de Mark Johnstone, j'ai pensé qu'il serait intéressant de laisser Google et Wikipédia définir une structure de sujet à partir d'un sujet de départ ou d'une page Web. L'objectif est de construire visuellement la cartographie des relations avec le sujet principal, dans un graphique en forme d'arbre qui peut être examiné pour rechercher des connexions et éventuellement générer des idées de contenu. L'image suivante représente l'idée de conception initiale.
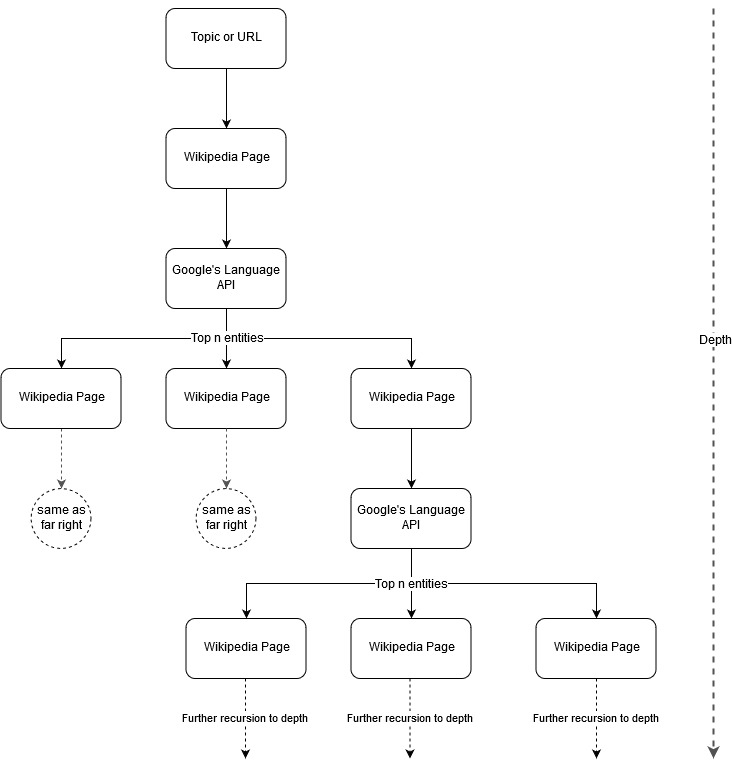
Essentiellement, nous donnons à l'outil un sujet ou une URL, et laissons l'API Language de Google sélectionner les n premières entités (3 dans nos exemples) (qui incluent les URL de Wikipédia) pour chaque page d'entité et nous continuons à construire de manière récursive un graphique de réseau pour chaque entité trouvée jusqu'à une profondeur maximale.
Contexte des outils utilisés
API de langue Google
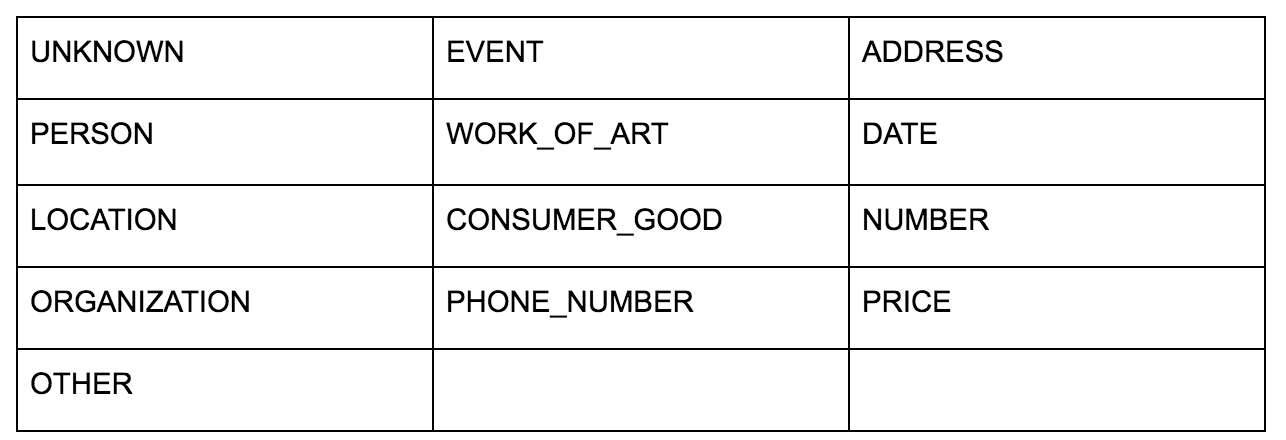
L'API Language de Google vous permet de lui transmettre du texte brut ou du HTML et renvoie comme par magie toutes les différentes entités associées au contenu. L'API fait plus que cela, mais pour cette analyse, nous nous concentrerons uniquement sur cette partie. Voici une liste des types d'entités renvoyées :
L'identification d'entité est depuis longtemps un élément fondamental du traitement du langage naturel (TAL) et la terminologie correcte pour cette tâche est la reconnaissance d'entité nommée (NER). Le NER est une tâche difficile car de nombreux mots ont des significations différentes en fonction du contexte utilisé. Les outils de TAL ou les API doivent donc comprendre le contexte complet entourant les termes pour pouvoir les identifier correctement en tant qu'entité particulière.
J'ai donné un aperçu assez détaillé de cette API, et des entités en particulier, dans un article sur opensource.com si vous souhaitez rattraper un peu le contexte avant de terminer cet article.
Une caractéristique intéressante de l'API Language de Google est qu'en plus de trouver des entités pertinentes, elle marque également leur lien avec le document global (saillance) et, pour certains, fournit un article Wikipédia (graphique de connaissances) associé représentant l'entité.
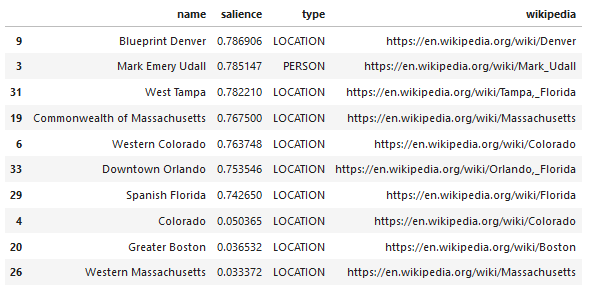
Voici un exemple de sortie de ce que l'API renvoie (trié par importance) :
Développeur Oncrawl
 Apprendre encore plus
Apprendre encore plusPython
Python est un langage logiciel qui est devenu populaire dans l'espace de la science des données en raison d'un ensemble important et croissant de bibliothèques qui facilitent l'ingestion, le nettoyage, la manipulation et l'analyse de grands ensembles de données. Il bénéficie également d'un environnement collaboratif appelé cahiers Jupyter qui permettent aux utilisateurs de tester et d'annoter facilement leur code sans effort.
Pour cet examen, nous utiliserons quelques bibliothèques clés qui nous permettront de faire des choses intéressantes avec les données NLP de Google.
- Pandas : pensez à pouvoir créer des scripts Microsoft Excel pour lire, enregistrer, analyser ou réorganiser des feuilles de calcul et vous aurez une idée de ce que fait Pandas. Les pandas sont incroyables. (lien)
- Networkx : Networkx est un outil pour construire des graphes de nœuds et d'arêtes qui définissent les relations entre les nœuds. Il a également un support intégré pour tracer les graphiques afin qu'ils soient faciles à visualiser. (lien)
- Pywikibot : Pywikibot est une bibliothèque qui vous permet d'interagir avec Wikipédia pour rechercher, éditer, trouver des relations, etc., avec tout le contenu de chaque site Wikipédia. (lien)
Le processus
Nous partageons ici un bloc-notes Google Colab qui peut être utilisé pour suivre. (Remerciements particuliers à Tyler Reardon pour la vérification de l'intégrité de l'article et de ce carnet.)
Mise en place
Les premières cellules du bloc-notes traitent de l'installation de certaines bibliothèques, de la mise à disposition de ces bibliothèques pour Python et de la fourniture d'informations d'identification et d'un fichier de configuration pour l'API Language de Google et Pywikibot, respectivement. Voici toutes les bibliothèques que nous devons installer pour nous assurer que l'outil peut fonctionner :
- pandas
- demandes
- httplib2
- google-cloud-language
- pywikibot
- réseaux
- validateurs
- Bs4
Remarque : La partie la plus difficile pour pouvoir exécuter ce bloc-notes est d'obtenir des informations d'identification de Google pour accéder à leurs API. Pour ceux qui n'ont pas d'expérience avec cela, cela prendra environ une heure à comprendre. Nous avons lié les instructions pour obtenir les informations d'identification du compte de service en haut du bloc-notes pour vous aider. Vous trouverez ci-dessous un exemple de la façon dont nous avons inclus le nôtre.
Fonctions pour la victoire
Dans la cellule indiquée par "Définir certaines fonctions pour Google NLP", nous développons huit fonctions qui gèrent des éléments tels que l'interrogation de l'API Language, l'interaction avec Wikipedia, l'extraction de texte de page Web et la création et le traçage de graphiques. Les fonctions sont essentiellement de petites unités de code qui prennent certaines données de paramètres, effectuent un travail et produisent quelque chose. Toutes les fonctions sont commentées pour indiquer les variables qu'elles prennent et ce qu'elles produisent.

Tester l'API
Les deux cellules suivantes prennent une URL, extraient le texte de l'URL et extraient les entités de l'API Language de Google. L'un extrait uniquement les entités qui ont des URL Wikipédia et l'autre extrait toutes les entités de cette page.
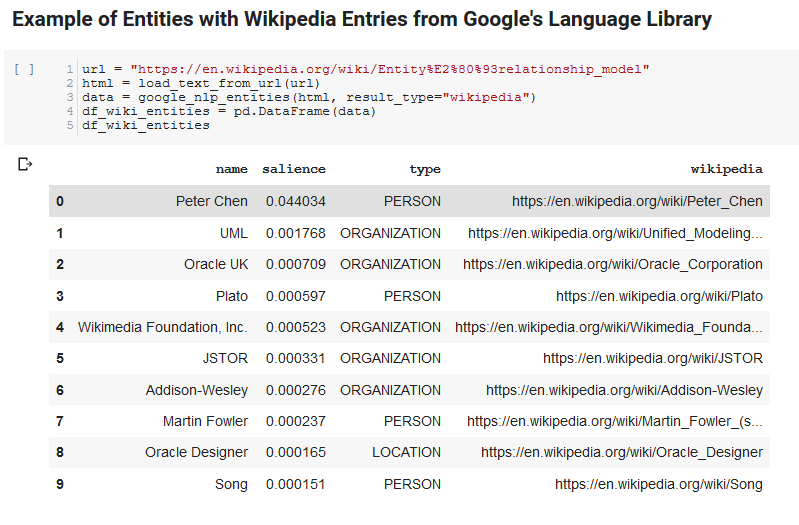
C'était une première étape importante juste pour obtenir la partie d'extraction de contenu correcte et comprendre comment l'API Language fonctionnait et renvoyait des données.
Réseaux
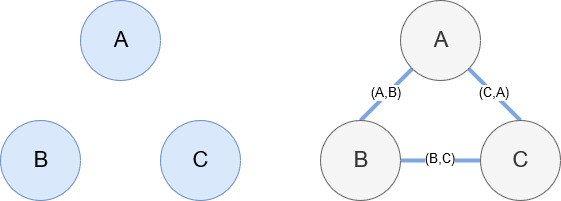
Networkx, comme mentionné précédemment, est une merveilleuse bibliothèque avec laquelle il est assez intuitif de jouer. Essentiellement, vous devez lui dire quels sont vos nœuds et comment les nœuds sont connectés. Par exemple, dans l'image ci-dessous, nous donnons à Networkx trois nœuds (A, B, C). Nous disons ensuite à Networkx qu'ils sont connectés par des arêtes (A,B), (B,C), (C,A) définissant les relations entre les nœuds. Pour notre usage, les entités avec des URL Wikipédia seront les nœuds et les bords sont définis par de nouvelles entités trouvées sur une page d'entité actuelle. Donc, si nous examinons la page Wikipedia pour l'entité A, et que sur cette page, l'entité B est découverte, alors c'est un bord entre l'entité A et l'entité B.
Mettre tous ensemble
La section suivante du bloc-notes s'appelle Wikipedia Topic Branching by URL. C'est là que la magie opère. Nous avions précédemment défini une fonction spéciale (recurse_entities) qui parcourt les pages de Wikipédia en suivant les nouvelles entités définies par l'API de langage de Google. Nous avons également ajouté une fonction très difficile à comprendre (hierarchy_pos) que nous avons extraite de Stack Overflow qui fait un bon travail en présentant un graphique en forme d'arbre avec de nombreux nœuds. Dans la cellule ci-dessous, nous définissons l' entrée comme "Search Engine Optimization" et spécifions une profondeur de 3 (c'est le nombre de pages qu'il suit de manière récursive) et une limite de 3 (c'est le nombre d'entités qu'il extrait par page).
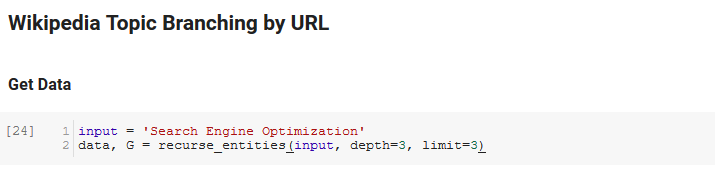
En l'exécutant pour le terme "Search Engine Optimization", nous pouvons voir le chemin suivi par l'outil, en commençant par la page Search Engine Optimization de Wikipedia (niveau 0) et en suivant, de manière récursive, les pages jusqu'à la profondeur maximale spécifiée (3).

Nous prenons ensuite toutes les entités trouvées et les ajoutons à un Pandas DataFrame, ce qui facilite grandement l'enregistrement au format CSV. Nous trions ces données par saillance (c'est-à-dire l'importance de l'entité par rapport à la page sur laquelle elle a été trouvée), mais ce score est un peu trompeur dans ce contexte car il ne vous dit pas à quel point l'entité est liée à votre terme d'origine (" Optimisation du moteur de recherche"). Nous laisserons ce travail ultérieur au lecteur.

Enfin, nous traçons le graphique construit par l'outil pour montrer la connexité de toutes les entités. Dans la cellule ci-dessous, les paramètres que vous pouvez passer à la fonction sont : ( G : le Graph construit préalablement par la fonction recurse_entities, w : la largeur du tracé, h : la hauteur du tracé, c : le pourcentage circulaire du tracé et nom de fichier : le fichier PNG qui est enregistré dans le dossier images.)

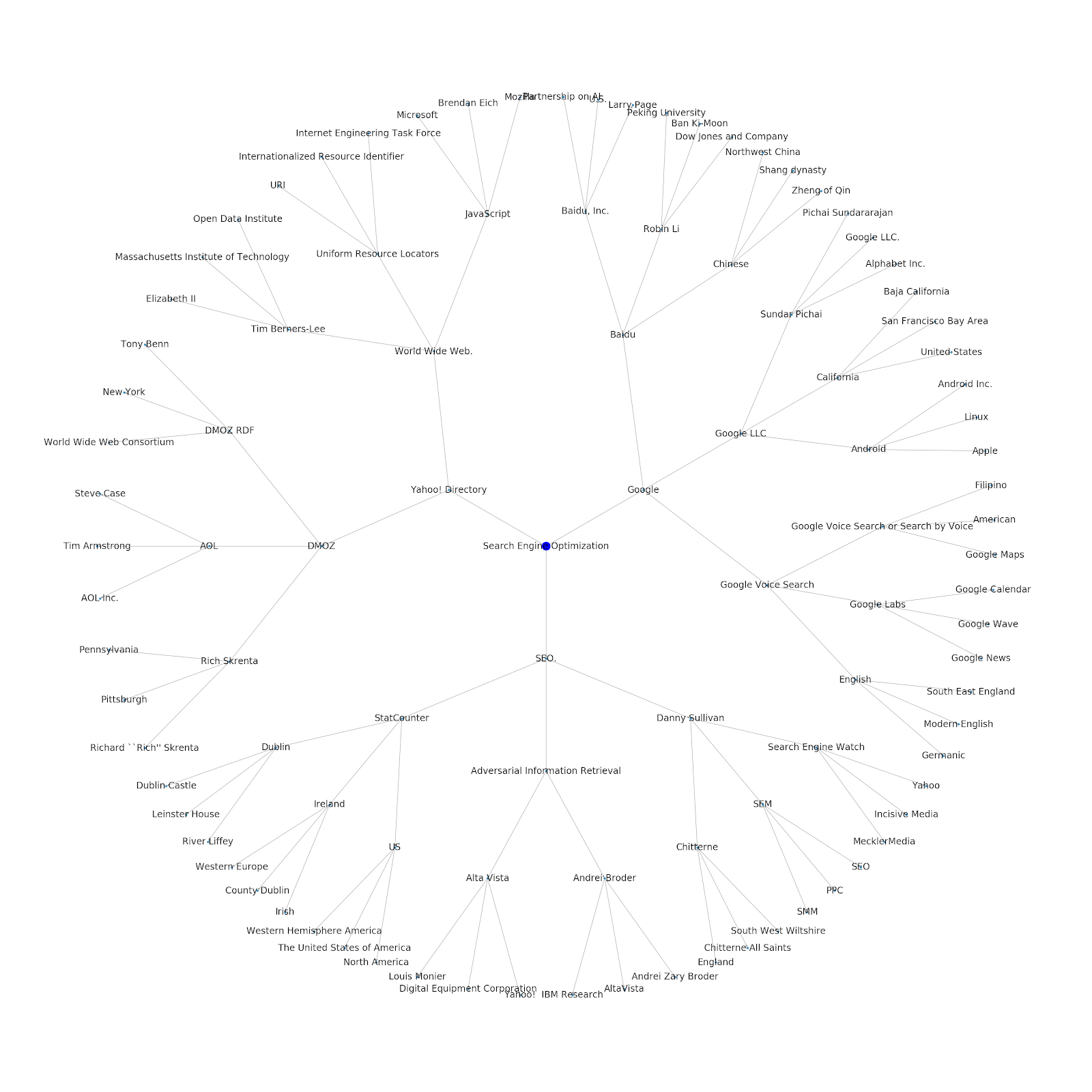
Nous avons ajouté la possibilité de lui donner un sujet de départ ou une URL de départ. Dans ce cas, nous examinons les entités associées à l'article Google's Indexing Issues Continue But This One Is Different
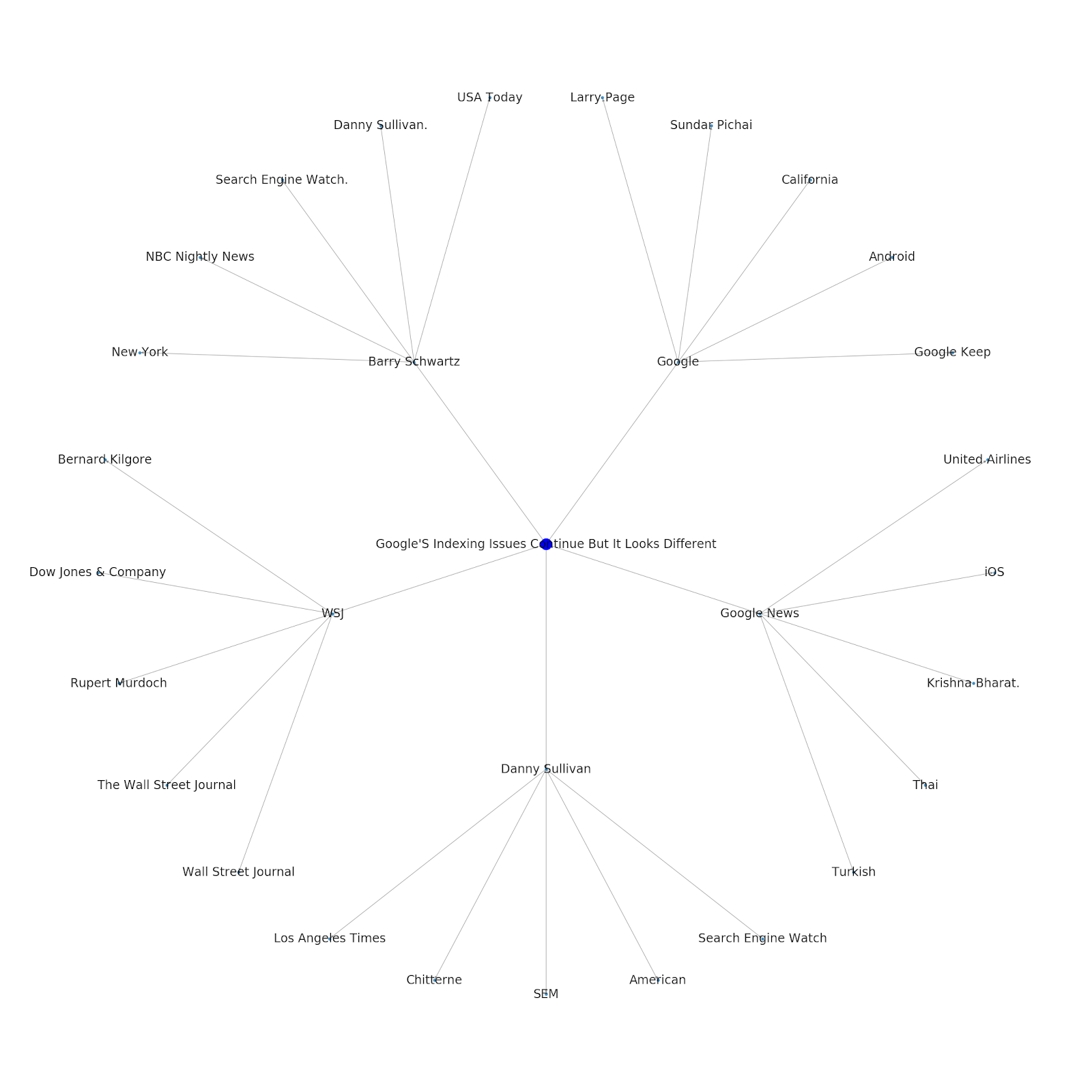
Voici le graphique d'entité Google/Wikipedia pour Python.
Qu'est-ce que cela signifie
Comprendre la couche thématique d'Internet est intéressant du point de vue du référencement, car cela vous oblige à penser en termes de connexion et pas uniquement à des requêtes individuelles. Étant donné que Google utilise cette couche pour faire correspondre les affinités des utilisateurs individuels aux sujets, comme mentionné dans leur réintroduction de Google Discover, cela peut devenir un flux de travail plus important pour les SEO axés sur les données. Dans le graphique "Python" ci-dessus, on peut en déduire que la familiarité d'un utilisateur avec les sujets liés à un sujet de départ peut être un indicateur raisonnable de son niveau d'expertise avec le sujet de départ.
L'exemple ci-dessous montre deux utilisateurs avec les surbrillances vertes indiquant leur intérêt historique ou leur affinité avec des sujets connexes. L'utilisateur de gauche, comprenant ce qu'est un IDE et comprenant ce que signifient PyPy et CPython, serait un utilisateur beaucoup plus expérimenté avec Python, que quelqu'un qui sait que c'est un langage, mais pas grand-chose d'autre. Cela serait facile à transformer en scores numériques pour chaque sujet, pour chaque utilisateur.

Conclusion
Mon objectif aujourd'hui était de partager ce qui est un processus assez standard que je traverse pour tester et examiner l'efficacité de divers outils ou API à l'aide de Jupyter Notebooks. Explorer le graphique thématique est incroyablement intéressant et nous espérons que vous trouverez que les outils partagés vous donnent l'avance dont vous avez besoin pour commencer à explorer par vous-même. Avec ces outils, vous pouvez créer des graphiques thématiques qui explorent de nombreux niveaux de relation, limités uniquement à l'étendue du quota de l'API Language de Google (qui est de 800 000 par jour). (Mise à jour : le prix est basé sur des unités de 1 000 caractères Unicode envoyés à l'API et est gratuit jusqu'à 5 000 unités. Étant donné que les articles de Wikipédia peuvent devenir longs, vous souhaitez surveiller vos dépenses. Un conseil à John Murch pour l'avoir signalé.) Si vous améliorez le cahier ou trouvez des cas intéressants, j'espère que vous me le ferez savoir. Vous pouvez me trouver sur @jroakes sur Twitter.