
Comment façonner un extrait à l'ère de Google en tant qu'éditeur
Publié: 2019-10-22Google se considère depuis longtemps comme un éditeur de contenu, même si la tendance est devenue difficile à ignorer ces dernières années. Cela a été en partie facilité par les progrès de l'apprentissage automatique et par les nouvelles fonctionnalités de la page de résultats des moteurs de recherche (SERP).
"Google en tant qu'éditeur de contenu" est un problème potentiel pour de nombreux propriétaires de sites Web, car il présente un choix difficile. Devrais-tu:
- Protéger votre contenu et risquer d'être exclu des résultats de Google ?
- Fournir des sources de contenu gratuites à Google, sachant que Google pourrait ne pas envoyer de visiteurs sur votre site ?
Les nouvelles balises de gestion des extraits qui entrent en vigueur fin octobre 2019 peuvent être considérées comme une déclaration d'intention de Google. Ils constituent également un pas dans la bonne direction en donnant aux propriétaires de sites Web un moyen de protéger leur contenu et de contrôler la manière dont leurs pages apparaissent dans les SERP.
Pourquoi se soucier d'un contenu de qualité ?
Les propriétés de Google fournissent encore environ 60 % du trafic vers les sites Web, en fonction de la verticale. Par conséquent, ne pas jouer au jeu de Google a un effet négatif potentiellement énorme sur la visibilité et le trafic d'un site Web. Mais en même temps, à travers EAT et les Quality Rater Guidelines, Google a clairement établi que les internautes recherchent un contenu de qualité et que les sites Web doivent investir dans sa production pour survivre.
Cet investissement dans un contenu unique et de haute qualité est quelque chose qu'un propriétaire de site Web devrait naturellement vouloir protéger. En offrant du contenu, les sites Web permettent à d'autres fournisseurs (dans ce cas : les moteurs de recherche) de profiter de leur temps, de leur argent et de leur expertise.
Comment Google utilise-t-il le contenu ?
Google utilise, remixe et réécrit le contenu pour fournir des réponses aux questions posées par les utilisateurs des moteurs de recherche. Ces réponses sont affichées sous de nombreuses formes sur les SERP.
Listes de résultats de recherche ou "extraits"
Google compose un extrait pour une page Web donnée dans les résultats de recherche en utilisant différents éléments tirés à l'origine de la page Web elle-même :
- balise <titre>
- Balise <meta description=”Snippet text”>
- Balisage Schema.org pour les données structurées prises en charge
- URL
- Favicon (dans les résultats mobiles dans certaines régions)
Aujourd'hui, peu d'entre eux sont utilisés tels quels. Google se réserve le droit de remplacer le favicon. Google déclare explicitement que leur « génération de titres de page et de descriptions est entièrement automatisée et… [Google utilise] un certain nombre de sources différentes pour ces informations, y compris des informations descriptives dans le titre et les balises méta de chaque page ». Enfin, Google a commencé à supprimer les URL dans les SERP comme on l'a vu lors de tests récents.
Google supprimant les URL dans le SERP peut légèrement aider les "mauvais" TLD.
Si vous ne pouvez pas dire s'il s'agit d'un .io, .org, .net, .ie, etc., vous ne pouvez pas les contredire et cliquer sur ce .com qui semble plus légitime. Peut-être pas un impact énorme, mais pourrait être un impact subtil qui s'agrandit avec le temps. pic.twitter.com/CcQ2E0lVtZ
– Ross Hudgens (@RossHudgens) 21 octobre 2019
Extraits en vedette
Google crée des extraits de code, qui apparaissent avant les listes de résultats de recherche, en extrayant le contenu d'une page Web qui semble répondre à la question du chercheur. Il y a eu divers épisodes d'extraits de code apparaissant sans attribution (ou sans attribution visible ou facilement accessible) en février et juin 2019. Dans chaque cas, Google a dénoncé l'intention de contourner les droits de l'éditeur et a affirmé que l'absence d'attribution était une erreur.
Définitions, météo et nourriture
La recherche de définitions de dictionnaire ou de météo dans un lieu spécifique donne une réponse dans la zone de saisie semi-automatique, sans attribution et sans avoir besoin d'exécuter une recherche.
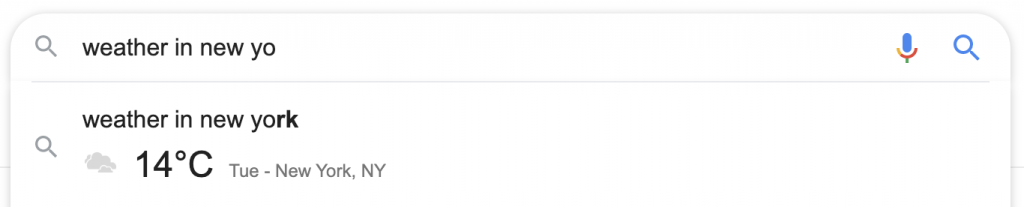
Dans le cas d'une définition, si vous appuyez sur le bouton de recherche, la définition complète, avec le son, les synonymes et d'autres fonctionnalités du SERP, est disponible. Le chercheur n'a pas besoin de visiter le site du dictionnaire Oxford, et l'attribution d'Oxford apparaît en petit texte gris sous la boîte de définition.
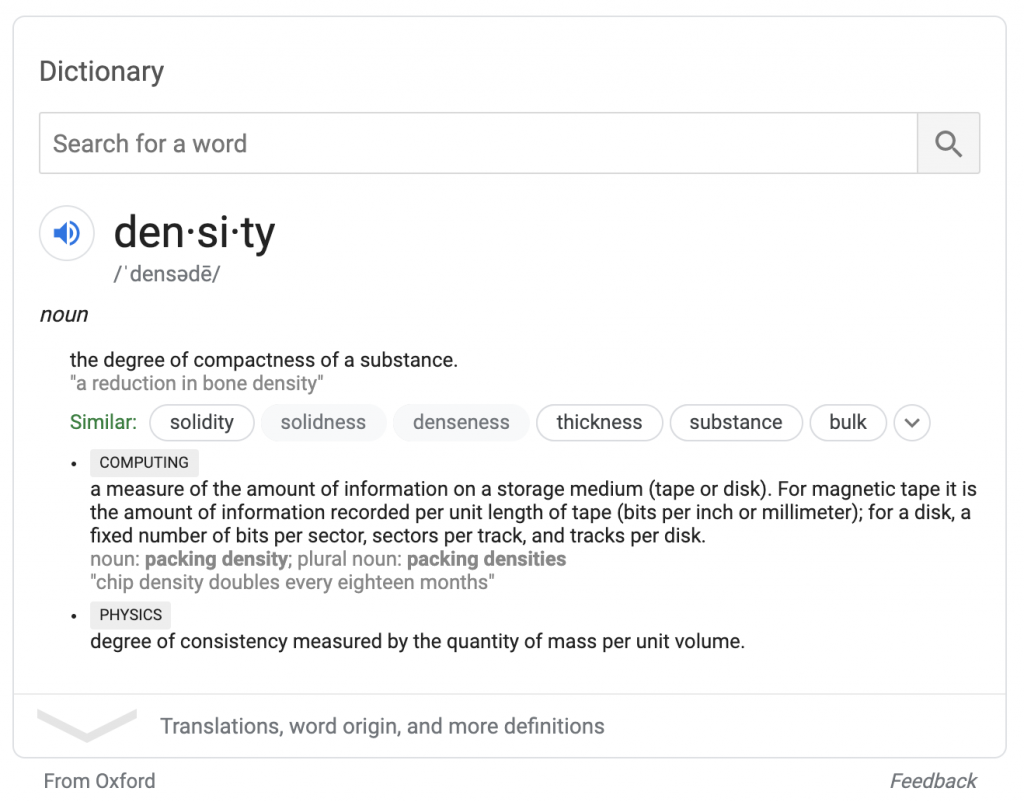
Les recherches météo complètes fournissent une zone de prévision similaire basée sur les données de weather.com. Comme l'attribution d'Oxford, l'attribution de weather.com apparaît sous la case ; les chercheurs peuvent interagir avec les données de la boîte sans jamais visiter weather.com.
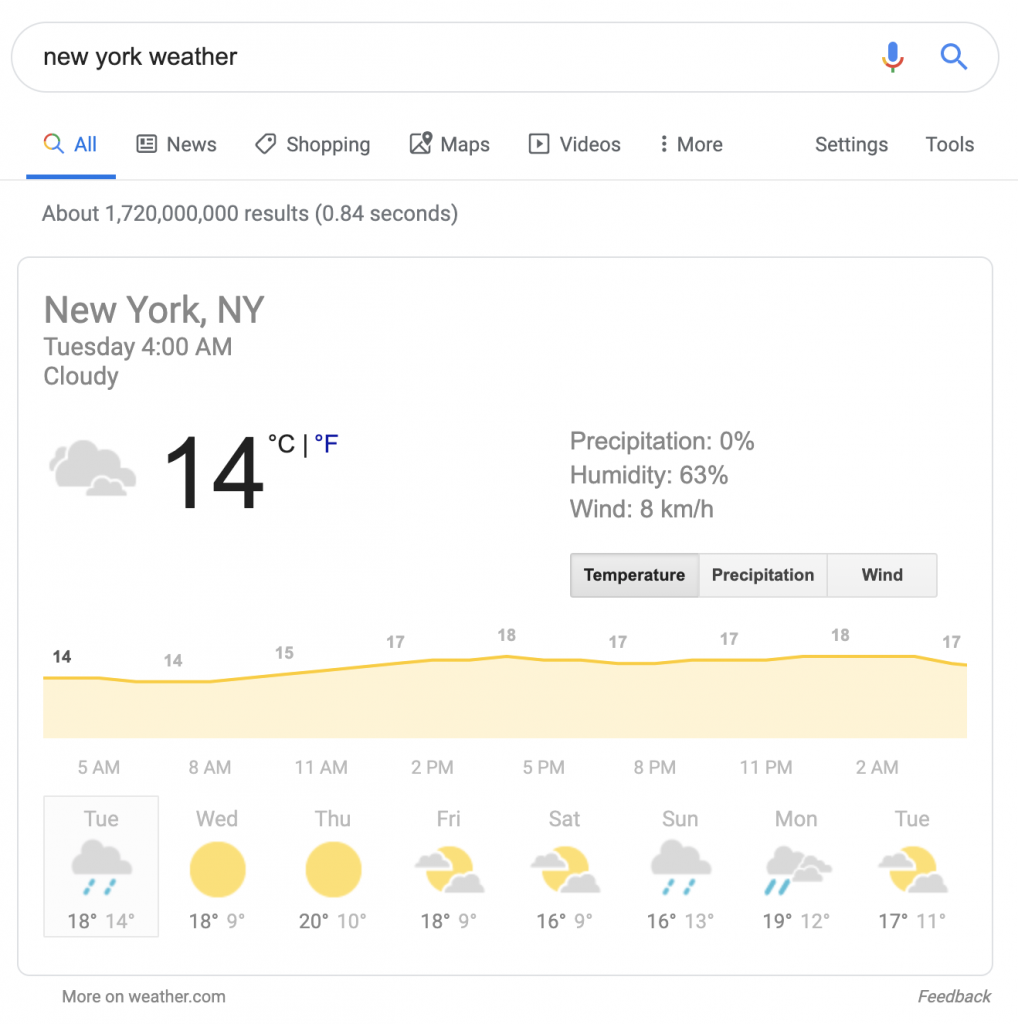
Un autre résultat de recherche similaire concerne les faits nutritionnels et la composition des aliments :
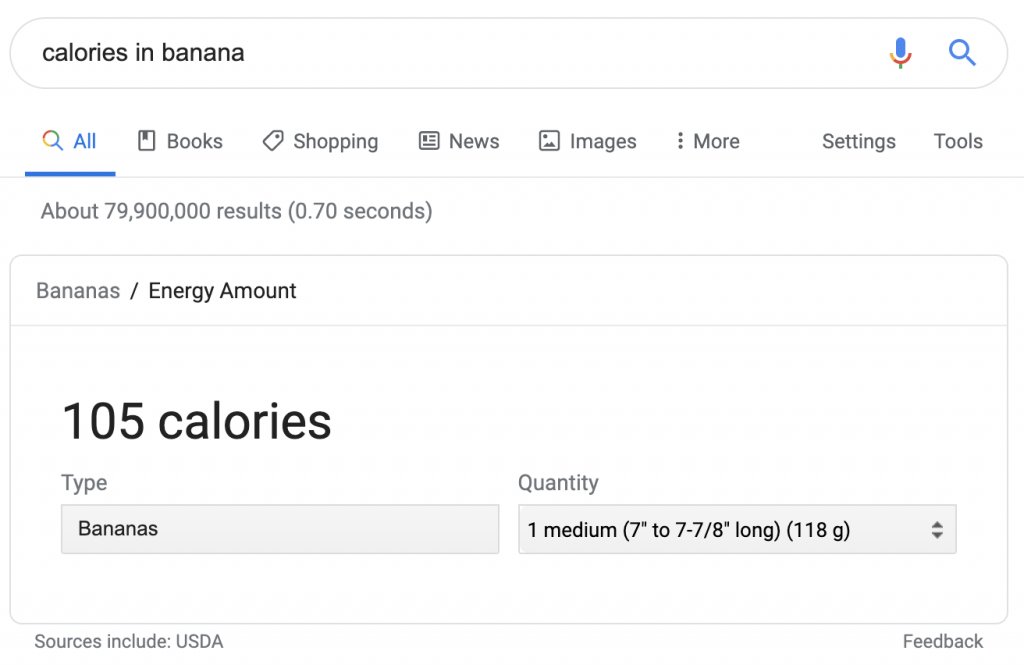
Cependant, dans ce cas, l'attribution est répertoriée comme "les sources incluent". Si d'autres sources sont utilisées, elles ne sont ni visibles ni accessibles.
Des résultats orientés locaux
De nombreux résultats liés aux activités locales proviennent également de diverses sources pour créer un SERP qui fournit une variété d'informations agrégées et rassemblées. Au lieu de visiter différents sites Web, un chercheur peut, par exemple, voir la liste des films qui passent actuellement à proximité, rechercher les horaires des séances dans différents cinémas et trouver des détails - critiques, synopsis, etc. - sur des films individuels. À aucun moment, le chercheur n'a besoin de quitter le SERP organisé par Google.
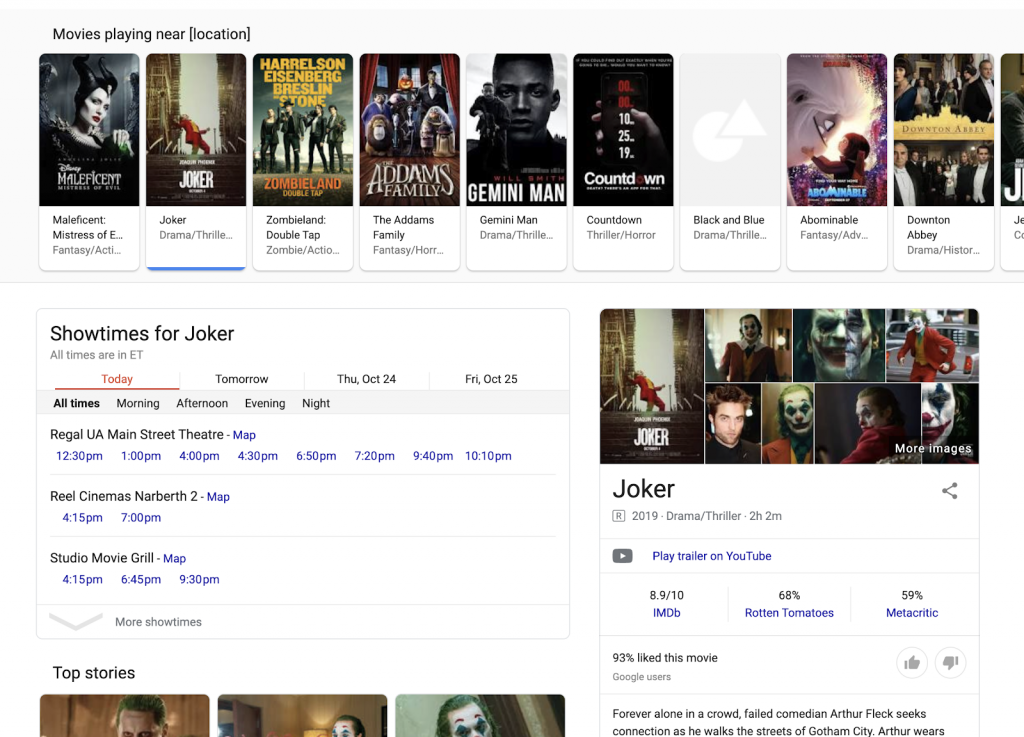
Ce type de SERP se développe dans de nombreux domaines différents, y compris les voyages.
Histoires AMP
Les histoires AMP offrent un mode "axé sur l'histoire" pour la "consommation d'actualités sur mobile". Ils sont un exemple de la façon dont l'indexation basée sur les entités a amélioré la capacité de Google à tirer du contenu de différentes sources et à le remixer. Dans certaines histoires créées par Google pour des apparitions de célébrités, Google a associé une image d'une source avec du texte d'une autre, par exemple.
Panneaux de connaissances
Les panneaux de connaissances sont des "boîtes d'informations qui apparaissent sur Google lorsque vous recherchez des entités" qui font partie du Knowledge Graph de Google. Les informations affichées dans ces panneaux sont tirées de plusieurs sources, que Google répertorie comme :
- partenaires de données qui fournissent des données faisant autorité sur des sujets spécifiques comme les films ou la musique
- sources Web ouvertes
- entités vérifiées qui ont suggéré des modifications aux faits sur leurs propres panneaux de connaissances
- un aperçu des résultats Google Images pour l'entité
Google a précédemment indiqué que son Knowledge Graph s'appuie sur des sources telles que Wikipedia/Wikidata, le CIA World Factbook, des données structurées sur le Web public, Google My Business, etc.
Ils peuvent également afficher des entités associées, permettant aux utilisateurs de la recherche de naviguer dans le Knowledge Graph sans quitter le site Web du moteur de recherche.
Autres fonctionnalités SERP
D'autres fonctionnalités SERP incluent des éléments de prédiction de requête qui tentent de répondre ou de rediriger l'activité de recherche sans envoyer l'utilisateur de la recherche vers un autre site Web. Les exemples incluent les réponses sans résultat dans la recherche mobile ou la saisie semi-automatique, ainsi que les cases "Les gens demandent aussi" (PAA).


Exemple de recherche sans résultat (mobile), qui s'affiche comme réponse directement dans la case de saisie semi-automatique sur ordinateur
Gestion de contenu dans les résultats de recherche
Balisage Schema.org
Avec peu de contrôle direct sur les autres éléments qui forment une liste de recherche, les référenceurs se sont massivement appuyés sur la puissance des extraits enrichis via le balisage Schema.org pour faire ressortir leurs listes sur les SERP.
Cependant, Google a réprimé l'utilisation abusive du balisage riche, y compris les étoiles de révision et le balisage de la FAQ :
Les étoiles d'avis Google dans les résultats de recherche ont chuté de 14 % depuis la mise à jour :
— Sites de financement en baisse de 46 %
— Sites immobiliers en baisse de 46%
— Sites juridiques et gouvernementaux en baisse de 28 %Nouvelles données via par @dr_pete https://t.co/DdlrCFIrsm pic.twitter.com/w2lj9WzpLR
– Cyrus (@CyrusShepard) 24 septembre 2019
Pour éviter d'avoir des SERP pleins de résultats #FAQ, #Google semble avoir fixé le plafond à 3 résultats FAQ #SEO @brodieseo @sengineland https://t.co/V8vSiKwrrv pic.twitter.com/A0Spmu9iMg
– AJ Ghergich (@SEO) 8 octobre 2019
Indications explicites du contenu qui ne peut pas être utilisé
Cette semaine, Google déploie des balises de gestion des extraits qui peuvent être utilisées pour indiquer à Google quelques limites sur ce qui peut être utilisé pour créer l'extrait de page dans les SERP.
Les nouvelles balises de gestion ont deux limitations principales :
- Elles ne s'appliquent pas aux données structurées (balisage Schema.org) de la page . Les données structurées de Schema.org prises en charge par Google peuvent toujours être affichées dans les résultats de recherche.
- Ils peuvent empêcher l'utilisation de votre page dans certaines "fonctionnalités spéciales" des SERP, y compris les extraits de code, s'ils ne respectent pas les longueurs minimales requises par la fonctionnalité SERP. Étant donné que la longueur varie selon la langue, Google ne publie pas les longueurs minimales des extraits optimisés. Insead, "[c]eux qui ne souhaitent pas que le contenu apparaisse en tant qu'extraits en vedette peuvent expérimenter avec des longueurs d'extraits maximales inférieures."
Les propriétaires de sites Web ont deux options pour mettre en œuvre ces balises :
1. Balises méta robots
À partir de fin octobre, dans le monde entier, ces balises méta robots peuvent être ajoutées à la page <head> ou dans l'en-tête HTTP x-robots.
- <meta name="robots" content=" nosnippet "> – ne pas afficher le texte de l'extrait pour cette page. Une vignette d'image peut toujours être utilisée.
- <meta name=”robots” content=” max-snippet: 50″> – définit la longueur maximale en nombre de caractères pour l'extrait. Une longueur d'extrait de "0" est l'équivalent de "nosnippet" ; une longueur d'extrait de "-1" est interprétée comme signifiant qu'il n'y a pas de limite à la longueur de l'extrait.
- <meta name=”robots” content=” max-video-preview: 3″> – définit la durée maximale, en secondes, pour un aperçu vidéo. Une durée de vidéo de « 0 » empêchera l'affichage des aperçus vidéo ; une longueur de vidéo de "-1" est interprétée comme signifiant qu'il n'y a pas de limite à la longueur de l'aperçu vidéo.
- <meta name=”robots” content=” max-image-preview: standard”> – définit la taille d'image maximale pour les images de cette page. Les options sont : "aucun", "standard" ou "grand".
Vous pouvez utiliser plusieurs opérateurs de gestion d'extraits de code dans la même balise meta robots. Séparez chaque opérateur par une virgule.
2. Attribut HTML data-nosnippet
Fin 2019, un nouvel attribut HTML sera reconnu par Google : data-nosnippet . Il peut être appliqué aux balises <span>, <div> ou <selection>.
L'attribut data-nosnippet empêche le texte de la balise à laquelle il est appliqué de s'afficher dans l'extrait de la page.
Autorisation explicite de réutilisation des contenus pour la presse européenne en France
Le remixage et la republication du contenu d'actualités de Google effleurent déjà les limites de la loi sur le droit d'auteur dans certains endroits. La France a récemment été à l'honneur :
En raison des modifications apportées à la législation sur le droit d'auteur en France, la recherche Google n'affichera pas d'extraits de texte ni de vignettes d'image pour les publications de presse européennes concernées en France, sauf si le site Web a mis en place des balises META pour permettre les aperçus de recherche. (La source)
En d'autres termes, Google exclura des résultats de recherche en France toute publication européenne ne lui permettant pas explicitement de republier et éventuellement de remixer des contenus.
Ironiquement, les moyens d'accorder l'autorisation ne sont pas particulièrement clairs : la seule balise meta robots explicitement permissive est « tous », qui « est la valeur par défaut et n'a aucun effet si elle est explicitement répertoriée », sauf, désormais, sur les SERP françaises.
Sinon, les éditeurs peuvent uniquement indiquer une absence de limite sur la longueur des aperçus de texte et de vidéo via une convention non incluse dans l'annonce sur la gestion des extraits, ou ils peuvent imposer des limites arbitraires afin de signaler qu'ils ne veulent pas interdire les aperçus de recherche. .
Marcher sur la corde raide
Chaque site Web devra trouver le juste équilibre entre la protection de son contenu et l'élaboration de sa présence sur les SERP de Google.
Comme Google se comporte de plus en plus comme un éditeur de contenu, nous pouvons nous attendre à plus de fonctionnalités SERP avec des attributions minimales, ainsi qu'à plus de pays où la loi sur le droit d'auteur - destinée à protéger les propriétaires et les créateurs de contenu - a un impact sur ce que Google peut et ne peut pas afficher.
Ce que je pense être intéressant, cependant, ce sont les implications sur le droit d'auteur de cela… Les gens se plaignent du fait que G prend du contenu sans autorisation - les balises d'extrait de code seront une autorisation tacite. Cela prendra-t-il longtemps avant qu'ils ne soient requis?
– Jenny Halasz (@jennyhalasz) 15 octobre 2019
Heureusement, les nouveaux outils de gestion des extraits de code fournissent aux propriétaires de sites Web les prémices d'une boîte à outils pour déterminer quelles parties et quelle quantité de leur contenu peut être réutilisée par Google sur les SERP.
Pour l'instant, je pense qu'il sera sage d'implémenter des balises de gestion d'extraits de code sur les sites Web avec un contenu original substantiel, même si je crains que les balises qui ne sont que restrictives ne soient pas utiles pour tous les sites Web. Malgré cette mise en garde, il existe toujours des moyens de les utiliser pour optimiser l'expérience sur les SERP et gagner plus de trafic.
Je pense que les gens adopteront les nouvelles balises. Je pense qu'il existe de nombreuses opportunités de "façonner" un extrait avec ces balises pour offrir une meilleure expérience que ce que Google tire automatiquement et optimiser les CTR.
– Kevin_Indig (@Kevin_Indig) 16 octobre 2019
J'ai hâte de voir l'expérimentation dans différentes verticales pour trouver ce qui fonctionne le mieux.