
Pourquoi nous sommes passés à l'informatique sans serveur pour déployer des versions personnalisées
Publié: 2018-11-22
Photo de panumas nikhomkhai provenant de Pexels
Dans le cadre de notre engagement à donner aux spécialistes du marketing de performance les moyens d'en faire plus, avec moins et sans souci , les équipes de TUNE sont toujours à la recherche de nouvelles façons de servir nos clients. Dans ce cas, notre équipe d'ingénierie des solutions a découvert une technologie qui simplifie le déploiement et la prise en charge des versions personnalisées sur notre plate-forme. Par conséquent, ils peuvent désormais consacrer plus de temps (et moins d'argent) à travailler avec davantage de clients pour créer les solutions dont ils ont besoin.
Chez TUNE, nous sommes fiers de fournir une plate-forme de marketing à la performance flexible et complète qui permet aux réseaux et aux annonceurs de gérer leurs campagnes de marketing numérique, leurs relations avec les éditeurs, leurs paiements, etc., directement prêts à l'emploi, sans avoir à écrire une seule ligne de code. . Mais parfois, comme avec d'autres systèmes SaaS entièrement gérés, nos clients ont besoin de configurations, de fonctionnalités ou d'intégrations personnalisées qui ne peuvent être obtenues qu'en retroussant nos manches et en lançant l'ancien éditeur de code. Récemment, nous sommes passés à une nouvelle technologie qui change la façon dont nous concevons ces solutions : l'informatique sans serveur.
Dans cet article, je vais passer en revue les problèmes que nous avons rencontrés avec le développement personnalisé, les étapes que nous avons suivies pour configurer notre processus de construction sans serveur et comment cette nouvelle méthodologie résout les problèmes de coût et d'échelle.
Défi : répondre à la demande de solutions personnalisées
Lorsque nous avons créé l'équipe d'ingénierie des solutions chez TUNE, nous avons traité chaque version client personnalisée comme une version distincte. La plupart de ces versions avaient un composant frontal, qui était généralement déployé en tant que page personnalisée sur notre plate-forme, et un composant principal composé d'un serveur, d'une base de données et de toute autre infrastructure nécessaire pour maintenir les serveurs à jour. -date et opérationnel.
Au début, cette méthodologie a fonctionné pour nous. En ayant une petite équipe allégée avec quelques versions personnalisées complexes, notre méthode de provisionnement et de configuration d'un serveur différent pour chaque version a fonctionné pour nous. Cela nous a permis de créer des expériences incroyables pour nos clients.
Mais au fur et à mesure que le nombre de builds augmentait, nous commencions à rencontrer des problèmes :
- Trop de serveurs ! Comme vous pouvez l'imaginer, le provisionnement d'un minimum de deux boîtes par build nous a conduit à avoir trop de serveurs. Le grand nombre de serveurs et toutes les difficultés qui les accompagnent (telles que les mises à jour de sécurité et les sauvegardes) nous coûtaient plus de temps que nous ne voudrions l'admettre.
- Gardez ces serveurs en place. Chaque serveur étant sa propre entité, nous étions chargés de nous assurer que chaque serveur était toujours opérationnel et opérationnel.
- PHP n'est pas pour moi. La plupart de nos versions sont créées à partir d'une image Docker PHP de base. Mais au fur et à mesure que notre équipe grandissait, nous savions que forcer les gens à écrire leurs versions client en PHP 5.0 alors qu'ils étaient des assistants Python n'avait aucun sens.
- Cela devient cher. Avec tous nos serveurs déployés sur ec2/RDS, nous commencions à constater un coût mensuel important.
- La sécurité d'abord. Comme ces services traitaient des données clients sensibles, nous avons dû fournir une méthode d'authentification pour nos URL publiques afin d'assurer la sécurité de ces données.
- Les crons sont durs. De nombreux services back-end consistaient en des scripts cron, et nous n'avions aucun moyen efficace de les gérer.
Face à ces défis, nous savions que nous devions trouver un moyen plus simple et plus rentable de fournir des fonctionnalités back-end aux builds de nos clients. Mais après de nombreux débats et aucun précurseur clair pour une solution, nous commencions à manquer d'idées. (De plus, avec la demande croissante de nouvelles versions personnalisées, le temps n'était définitivement pas de notre côté.)
Solution : l'informatique sans serveur à la rescousse
Si vous n'avez pas entendu parler de l'informatique sans serveur , vous vous demandez peut-être la même chose que nous lorsque nous en avons entendu parler pour la première fois. Comment exécuter du code sans serveur ? (Ne vous inquiétez pas, votre compréhension fondamentale de la programmation est toujours correcte, et non, nous n'avons pas abusé de l'happy hour avant d'écrire ceci.)
« Sans serveur » est un terme très déroutant pour une nouvelle technologie, car - ne soyons pas idiots - il y a toujours un serveur exécutant du code. Alors, qu'est-ce que le sans serveur ?
L'informatique sans serveur est un modèle d'exécution du cloud computing dans lequel le fournisseur de cloud agit en tant que serveur, gérant de manière dynamique l'allocation des ressources de la machine. – Wikipédia
Les solutions cloud sans serveur vous permettent de créer et d'exécuter des applications et des services sans vous soucier des tracas associés aux serveurs. Essentiellement, l'informatique sans serveur vous permet de faire ce que vous faites le mieux : écrire du code.
Le processus de configuration sans serveur
Pour vous montrer l'essentiel du fonctionnement de la technologie sans serveur, je vais parcourir les étapes que nous avons utilisées pour configurer cette fonctionnalité.
Remarque : Il existe de nombreux fournisseurs de cloud avec une fonctionnalité sans serveur. Dans cet exemple, nous utilisons AWS Lambda .

- Tout d'abord, créez une nouvelle fonction Lambda et sélectionnez « Blueprints ». Ensuite, tapez « http » dans le champ du mot clé, puis sélectionnez le point de terminaison Python ou Node microservice-http. (Les Blueprints sont des blocs de code préfabriqués destinés à accélérer le développement. N'est-ce pas génial ?) Une fois que vous avez fait une sélection, cliquez sur " Configurer ".
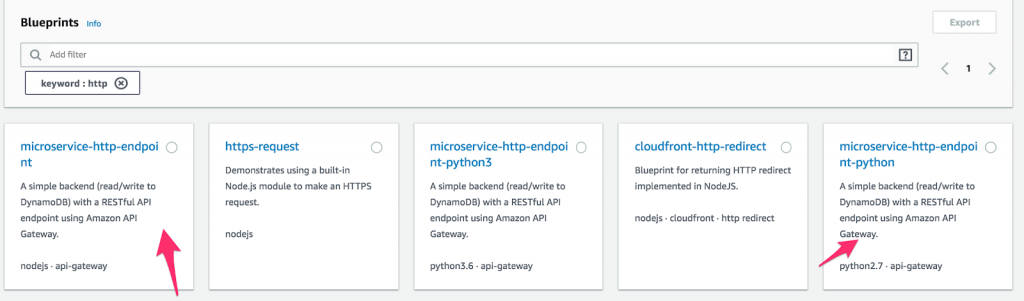
Comment configurer une fonction sur AWS Lambda.
- Ajoutez un nom de fonction et un rôle. Sélectionnez ensuite un déclencheur API Gateway avec l'option de sécurité " Ouvrir avec la clé API ". Cette passerelle API fournira une URL publique qui déclenchera votre fonction Lambda. L'ajout de la clé API fournit une méthode d'authentification, ce qui est fortement recommandé.
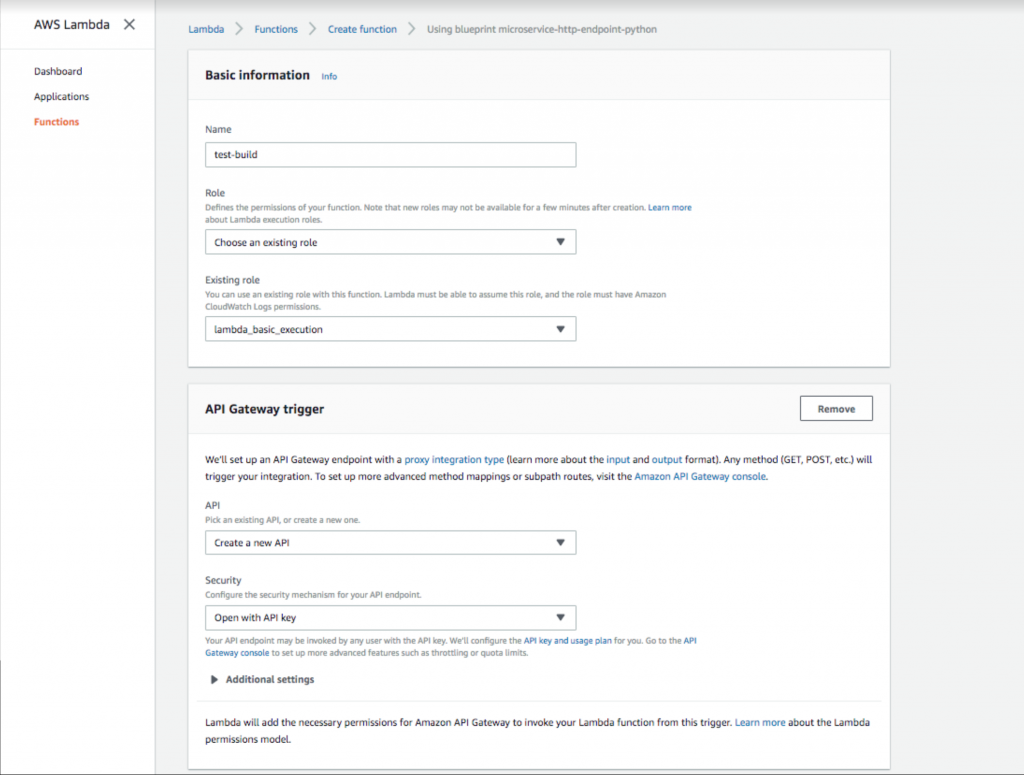
Configuration d'une clé de passerelle d'API ouverte dans AWS Lambda.
- Une fois la fonction créée, vous pouvez désormais configurer votre code. Comme vous pouvez le constater, le plan directeur vous a déjà fourni un crochet de point d'entrée sympa qui vous permet d'interagir avec une table Dynamo (si vous cherchez à ajouter une base de données). Tout ce qui se trouve sous lambda_handler sera exécuté lorsque l'URL publique sera chargée. Puisque nous ajoutons également une base de données, allons dans Dynamo et créons-en une.
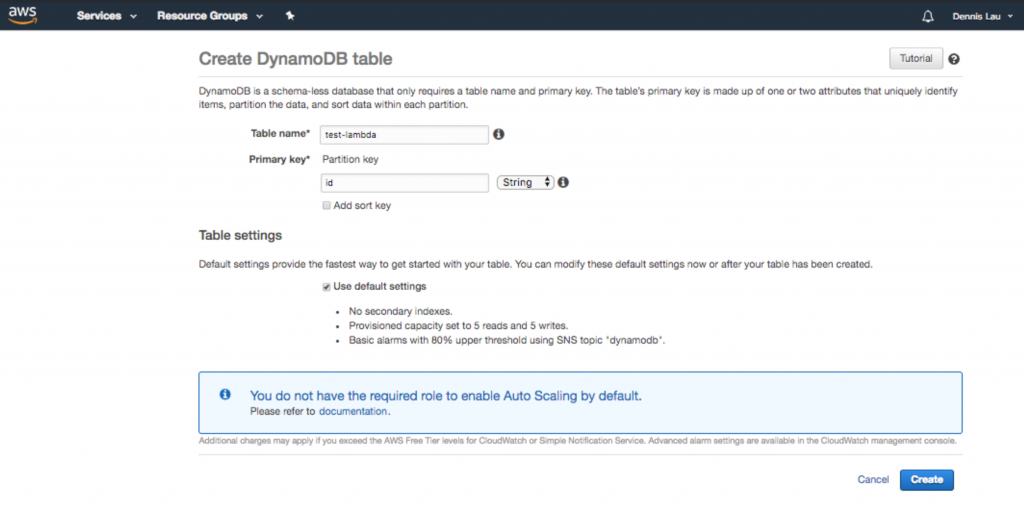
Création d'une table de base de données Dynamo dans AWS Lambda.
- Une fois la table Dynamo créée, appelons cette fonction Lambda à partir d'une URL publique. Revenez à votre fonction et cliquez sur l'icône " API Gateway " en haut. Vous devriez voir que le point de terminaison et la clé API ont déjà été créés pour vous.
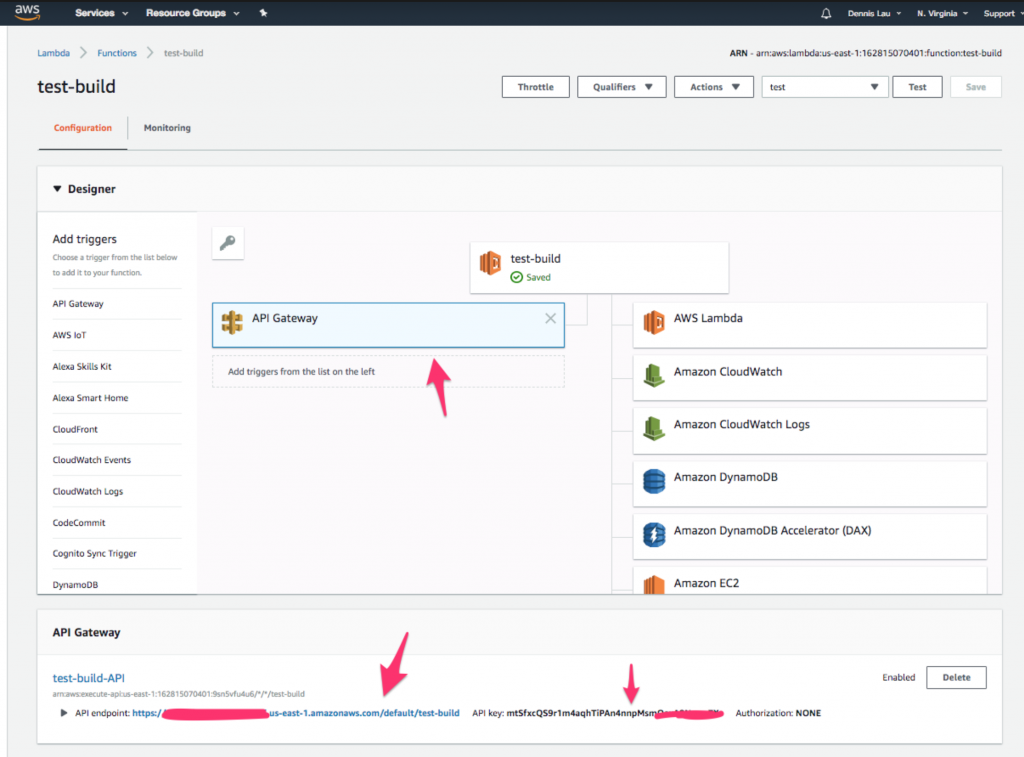
Où trouver l'icône API Gateway dans les fonctions AWS Lambda.
- Ouvrez maintenant le terminal et ajoutez la clé API sous l'en-tête " x-api-key" , puis ajoutez le nom de la table que vous avez créée sous le paramètre de chaîne de requête TableName .

Entrez votre clé et le nom de la base de données dans le terminal pour terminer.
- Tout d'abord, créez une nouvelle fonction Lambda et sélectionnez « Blueprints ». Ensuite, tapez « http » dans le champ du mot clé, puis sélectionnez le point de terminaison Python ou Node microservice-http. (Les Blueprints sont des blocs de code préfabriqués destinés à accélérer le développement. N'est-ce pas génial ?) Une fois que vous avez fait une sélection, cliquez sur " Configurer ".
C'est ça! Vous avez maintenant un back-end fonctionnel et sécurisé connecté à une base de données. Tout ce qu'il a fallu, c'est cinq étapes faciles.
Comment l'informatique sans serveur a relevé nos défis
Maintenant que nous vous avons montré comment configurer des versions sans serveur, jetons un coup d'œil et voyons comment ce modèle basé sur le cloud se comporte par rapport à notre liste de contrôle des problèmes.
- Trop de serveurs ! Sans serveur… ce qui signifie plus de serveurs, n'est-ce pas ?
- Gardez ces serveurs en place. Étant donné que l'informatique sans serveur est gérée par le fournisseur de cloud, vous bénéficiez de ces fournisseurs (ainsi que de leurs méthodes éprouvées et éprouvées) pour surveiller vos serveurs. Pour ceux d'entre vous qui veulent jouer à Sherlock Holmes, vous pouvez également voir tous les journaux de serveur générés par votre fonction sur Cloudwatch .
- PHP n'est pas pour moi. Les modèles sans serveur vous permettent d'écrire en C#, Python, NodeJS, Go et même Java.
- Cela devient cher. Avec les solutions sans serveur, les coûts sont mesurés en fonction du temps d'exécution (par 100 millisecondes) et de la quantité de données transférées. Contrairement au paiement mensuel, qui inclut le temps d'inactivité de vos serveurs, vous ne payez que ce que vous utilisez. Avec des coûts aussi bas que 0,000000208 $ par 100 ms d'exécution, l'informatique sans serveur pourrait vous faire économiser beaucoup d'argent.
- La sécurité d'abord. Le sans serveur est-il sûr ? Avec un système d'authentification par clé API intégré, vous pariez que c'est le cas.
- Les crons sont durs. Avec un système de gestion cron construit nativement sur Cloudwatch, définissez simplement une fenêtre de temps et oubliez-la. Cloudwatch gère toute la journalisation et l'exécution.
Dernières pensées
Pour l'équipe d'ingénierie des solutions de TUNE, le passage à l'informatique sans serveur a changé la donne. Sa facilité d'utilisation, ses économies de coûts et ses fonctionnalités agiles ont changé la façon dont nous gérons toutes les nouvelles versions de nos clients. Les solutions cloud sans serveur sont destinées à changer le monde de l'informatique côté serveur. Je ne sais pas pour vous, mais une chose est sûre : l'équipe TUNE Solutions Engineering est prête.
Pour en savoir plus sur la plate-forme TUNE et les services de développement personnalisés que nous fournissons, visitez notre page Services professionnels .