
Regroupement sémantique de mots-clés en Python
Publié: 2021-04-19Dans un monde plein de mythes sur le marketing numérique, nous pensons que trouver des solutions pratiques aux problèmes quotidiens est ce dont nous avons besoin.
Chez PEMAVOR, nous partageons toujours notre expertise et nos connaissances pour répondre aux besoins des passionnés de marketing numérique. Ainsi, nous publions souvent des scripts Python gratuits pour vous aider à augmenter votre retour sur investissement.
Notre clustering de mots-clés SEO avec Python a ouvert la voie à l'obtention de nouvelles informations pour les grands projets SEO, avec seulement moins de 50 lignes de codes Python.
L'idée derrière ce script était de vous permettre de regrouper des mots clés sans payer de "frais exagérés" à… eh bien, nous savons qui…
Mais nous avons réalisé que ce script ne suffisait pas à lui seul. Un autre script est nécessaire pour que vous puissiez approfondir votre compréhension de vos mots clés : vous devez être en mesure de " regrouper les mots clés par signification et relations sémantiques". ”
Il est maintenant temps d'aller plus loin avec Python pour le référencement .
Oncrawl Data³
 Apprendre encore plus
Apprendre encore plusLa méthode traditionnelle de regroupement sémantique
Comme vous le savez, la méthode traditionnelle pour la sémantique consiste à créer des modèles word2vec , puis à regrouper les mots-clés avec Word Mover's Distance .
Mais ces modèles demandent beaucoup de temps et d'efforts pour être construits et entraînés. Nous aimerions donc vous proposer une solution plus simple. 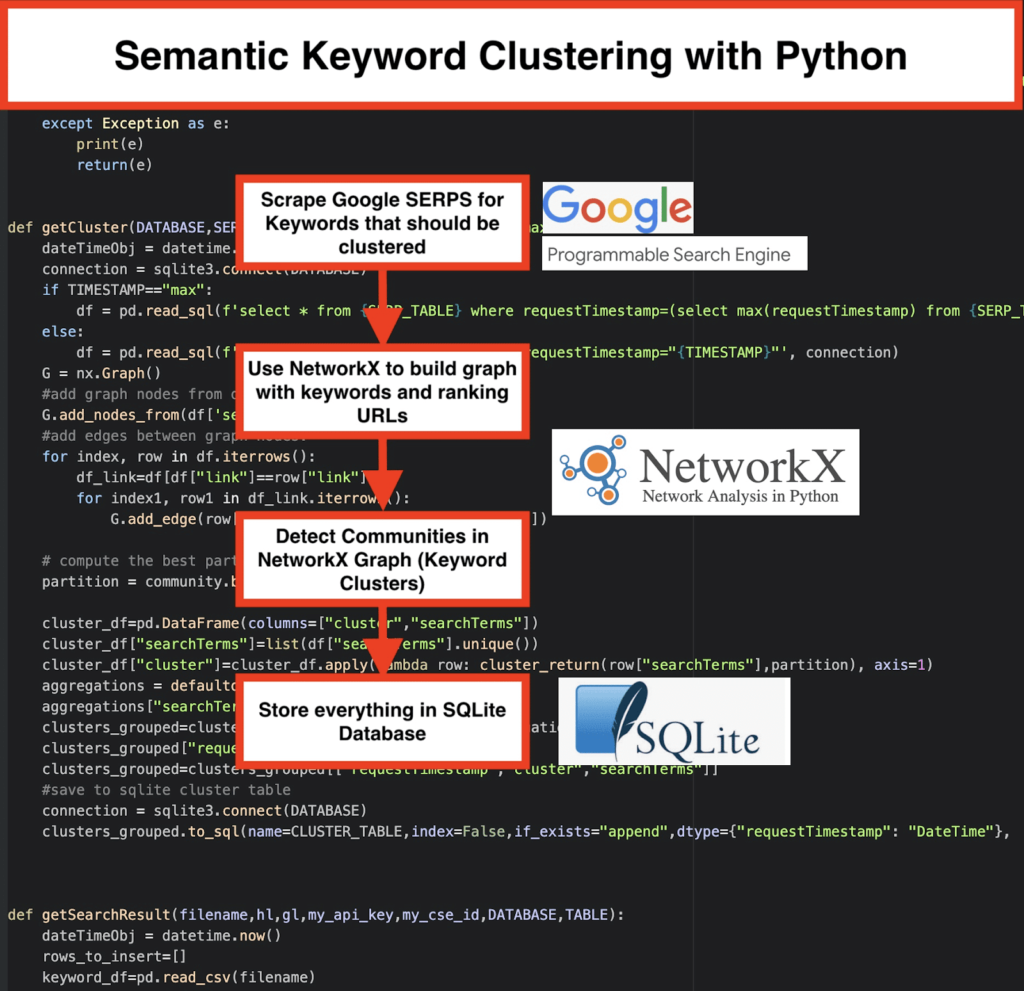
Résultats Google SERP et découverte de la sémantique
Google utilise des modèles NLP pour offrir les meilleurs résultats de recherche. C'est comme la boîte de Pandore à ouvrir, et nous ne le savons pas exactement.
Cependant, plutôt que de construire nos modèles, nous pouvons utiliser cette boîte pour regrouper les mots-clés selon leur sémantique et leur signification.
Voici comment nous procédons :
️ Tout d'abord, établissez une liste de mots-clés pour un sujet.
️ Ensuite, scrapez les données SERP pour chaque mot-clé.
️ Ensuite, un graphique est créé avec la relation entre les pages de classement et les mots-clés.
️ Tant que les mêmes pages se classent pour différents mots clés, cela signifie qu'elles sont liées entre elles. C'est le principe de base derrière la création de clusters de mots clés sémantiques.
Il est temps de tout assembler en Python
Le script Python offre les fonctions ci-dessous :
- En utilisant le moteur de recherche personnalisé de Google, téléchargez les SERP pour la liste de mots-clés. Les données sont enregistrées dans une base de données SQLite . Ici, vous devez configurer une API de recherche personnalisée.
- Ensuite, utilisez le quota gratuit de 100 requêtes par jour. Mais ils proposent également un plan payant à 5 $ pour 1000 quêtes si vous ne voulez pas attendre ou si vous avez de gros ensembles de données.
- Il est préférable d'opter pour les solutions SQLite si vous n'êtes pas pressé - les résultats SERP seront ajoutés au tableau à chaque exécution. (Prenez simplement une nouvelle série de 100 mots clés lorsque vous avez à nouveau le quota le lendemain.)
- En attendant, vous devez configurer ces variables dans le Python Script .
- CSV_FILE=”keywords.csv” => stocker vos mots clés ici
- LANGUE = "fr"
- PAYS = "fr"
- API_KEY=" xxxxxxx"
- CSE_ID="xxxxxxx"
- L'exécution
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)écrira les résultats SERP dans la base de données. - Le clustering est réalisé par networkx et le module de détection de communauté. Les données sont extraites de la base de données SQLite - le clustering est appelé avec
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - Les résultats du clustering se trouvent dans la table SQLite - tant que vous ne modifiez pas, le nom est "keyword_clusters" par défaut.
Ci-dessous, vous verrez le code complet :
# Regroupement sémantique de mots-clés par Pemavor.com # Auteur : Stefan Neefischer ([email protected]) à partir de la construction d'importation googleapiclient.discovery importer des pandas en tant que pd importer Levenshtein à partir de la date et de l'heure d'importation de la date et de l'heure depuis fuzzywuzzy import fuzz à partir de urllib.parse importer urlparse depuis l'importation tld get_tld import langid importer json importer des pandas en tant que pd importer numpy en tant que np importer networkx en tant que nx communauté d'importation importer sqlite3 importer des mathématiques importer io à partir des collections importer defaultdict def cluster_return(searchTerm,partition): partition de retour[searchTerm] def language_detection(str_lan): lan=langid.classify(str_lan) retour lan[0] def extract_domain(url, remove_http=True): uri = urlparse(url) si remove_http : nom_domaine = f"{uri.netloc}" autre: nom_domaine = f"{uri.netloc}://{uri.netloc}" retourner nom_domaine def extract_mainDomain(url): res = get_tld(url, as_object=True) retour res.fld def fuzzy_ratio(str1,str2): retourner fuzz.ratio(str1,str2) def fuzzy_token_set_ratio(str1,str2): retourner fuzz.token_set_ratio(str1,str2) def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): essayer: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() retour res sauf exception comme e : imprimer(e) retour(e) def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs): essayer: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute() retour res sauf exception comme e : imprimer(e) retour(e) def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max") : dateTimeObj = datetime.maintenant() connexion = sqlite3.connect(DATABASE) si TIMESTAMP=="max": df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp=(select max(requestTimestamp) from {SERP_TABLE})', connection) autre: df = pd.read_sql(f'select * from {SERP_TABLE} where requestTimestamp="{TIMESTAMP}"', connexion) G = nx.Graph() #ajouter des nœuds de graphique à partir de la colonne de dataframe G.add_nodes_from(df['searchTerms']) #ajouter des arêtes entre les nœuds du graphe : pour index, ligne dans df.iterrows() : df_link=df[df["lien"]==ligne["lien"]] pour index1, row1 dans df_link.iterrows() : G.add_edge(ligne["searchTerms"], row1['searchTerms']) # calcule la meilleure partition pour la communauté (clusters) partition = communauté.best_partition(G) cluster_df=pd.DataFrame(columns=["cluster","searchTerms"]) cluster_df["searchTerms"]=list(df["searchTerms"].unique()) cluster_df["cluster"]=cluster_df.apply(ligne lambda : cluster_return(ligne["searchTerms"],partition), axe=1) agrégations = defaultdict() agrégations["searchTerms"]=' | '.rejoindre clusters_grouped=cluster_df.groupby("cluster").agg(agrégations).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]] #enregistrer dans la table de cluster sqlite connexion = sqlite3.connect(DATABASE) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connection) def getSearchResult(filename,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE): dateTimeObj = datetime.maintenant() rows_to_insert=[] keyword_df=pd.read_csv(nom_fichier) mots-clés=mot-clé_df.iloc[:,0].tolist() pour la requête dans les mots-clés : si hl=="par défaut": résultat = google_search_default_language (requête, my_api_key, my_cse_id, gl) autre: result = google_search(query, my_api_key, my_cse_id,hl,gl) if "items" dans result et "queries" dans result : pour la position dans la plage (0, len (résultat ["éléments"])): résultat["éléments"][position]["position"]=position+1 result["items"][position]["main_domain"]= extract_mainDomain(result["items"][position]["link"]) result["items"][position]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["title"],query) result["items"][position]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][position]["snippet"],query) result["items"][position]["title_matchScore_order"]=fuzzy_ratio(result["items"][position]["title"],query) result["items"][position]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][position]["snippet"],query) result["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"]) pour la position dans la plage (0, len (résultat ["éléments"])): rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"], "displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"], "position":result["items"][position]["position"],"snippet":result["items"][position]["snippet"], "snipped_language":result["items"][position]["snipped_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], "snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"], "title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][position]["title_matchScore_token"], }) df=pd.DataFrame(rows_to_insert) #enregistrer les résultats de serp dans la base de données sqlite connexion = sqlite3.connect(DATABASE) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connexion) ################################################# ################################################# ########################################## #Lisez-moi : # ################################################# ################################################# ########################################## #1- Vous devez configurer un moteur de recherche personnalisé Google. # # Veuillez fournir la clé API et le SearchId. # # Définissez également votre pays et votre langue dans lesquels vous souhaitez surveiller les résultats SERP. # # Si vous n'avez pas encore de clé API ni d'identifiant de recherche, # # vous pouvez suivre les étapes de la section Prérequis de cette page https://developers.google.com/custom-search/v1/overview#prerequisites # # # #2- Vous devez également entrer les noms de la base de données, de la table serp et de la table de cluster à utiliser pour enregistrer les résultats. # # # #3- entrez le nom du fichier csv ou le chemin complet contenant les mots-clés qui seront utilisés pour serp # # # #4- Pour le regroupement des mots-clés, entrez l'horodatage des résultats Serp qui seront utilisés pour le regroupement. # # Si vous avez besoin de regrouper les derniers résultats de recherche, entrez "max" pour l'horodatage. # # ou vous pouvez entrer un horodatage spécifique comme "2021-02-18 17:18:05.195321" # # # #5- Parcourez les résultats via le navigateur DB pour le programme SQLite # ################################################# ################################################# ########################################## Nom de fichier #csv contenant des mots-clés pour serp CSV_FILE="mots clés.csv" # déterminer la langue LANGUE = "fr" #detrmine ville PAYS = "fr" Clé API json de recherche personnalisée #google API_KEY="ENTREZ LA CLÉ ICI" #Identifiant du moteur de recherche CSE_ #nom de la base de données sqlite DATABASE="keywords.db" #nom de la table pour y enregistrer les résultats de la recherche SERP_TABLE="mots clés_serps" # lancez le serp pour les mots-clés getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) #nom de la table que les résultats du cluster y enregistreront. CLUSTER_TABLE="keyword_clusters" #Veuillez entrer l'horodatage, si vous souhaitez créer des clusters pour un horodatage spécifique #Si vous avez besoin de créer des clusters pour le dernier résultat de serp, envoyez-le avec la valeur "max" #TIMESTAMP="2021-02-18 17:18:05.195321" HORODATAGE="max" #exécutez des clusters de mots-clés en fonction des réseaux et des algorithmes communautaires getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

Résultats Google SERP et découverte de la sémantique
Nous espérons que vous avez apprécié ce script avec son raccourci pour regrouper vos mots-clés en clusters sémantiques sans vous fier à des modèles sémantiques. Étant donné que ces modèles sont souvent à la fois complexes et coûteux, il est important de rechercher d'autres moyens d'identifier les mots clés qui partagent des propriétés sémantiques.
En traitant ensemble des mots clés liés sémantiquement, vous pouvez mieux couvrir un sujet, mieux lier les articles de votre site entre eux et augmenter le classement de votre site Web pour un sujet donné.