
Comprendre le rapport de couverture de la Search Console
Publié: 2019-08-15Introduction au rapport de couverture et comment interpréter les données
Le rapport de couverture de la Search Console fournit des informations sur les pages de votre site qui ont été indexées et répertorie les URL qui ont présenté des problèmes pendant que Googlebot essaie de les explorer et de les indexer.
La page principale du rapport de couverture affiche les URL de votre site regroupées par état :
- Erreur : la page n'est pas indexée. Il y a plusieurs raisons à cela, les pages répondant avec des pages 404, soft 404, entre autres.
- Valide avec avertissements : la page est indexée mais présente des problèmes.
- Valide : la page est indexée.
- Exclu : la page n'est pas indexée, Google suit des règles sur le site telles que les balises noindex dans robots.txt ou les balises méta, les balises canoniques, etc. qui empêchent les pages d'être indexées.
Ce rapport de couverture donne beaucoup plus d'informations que l'ancienne console de recherche Google. Google a vraiment amélioré les données qu'il partage, mais il y a encore des choses à améliorer.
Comme vous pouvez le voir ci-dessous, Google affiche un graphique avec le nombre d'URL dans chaque catégorie. S'il y a une augmentation soudaine des erreurs, vous pouvez voir les barres et même les corréler avec les impressions pour déterminer si une augmentation des URL avec des erreurs ou des avertissements peut entraîner une baisse des impressions.

Après le lancement d'un site ou la création de nouvelles sections, vous souhaitez voir un nombre croissant de pages indexées valides. Il faut quelques jours pour que Google indexe de nouvelles pages, mais vous pouvez utiliser l'outil d'inspection d'URL pour demander l'indexation et réduire le temps nécessaire à Google pour trouver votre nouvelle page.

Cependant, si vous constatez une diminution du nombre d'URL valides ou des pics soudains, il est important de travailler sur l'identification des URL dans la section Erreurs et de résoudre les problèmes répertoriés dans le rapport. Google fournit un bon résumé des éléments d'action à effectuer en cas d'augmentation des erreurs ou des avertissements.
Google fournit des informations sur les erreurs et le nombre d'URL qui posent problème :

N'oubliez pas que Google Search Console n'affiche pas d'informations précises à 100 %. En fait, il y a eu plusieurs rapports sur des bogues et des anomalies de données. De plus, la console de recherche Google prend du temps à se mettre à jour, il est connu que les données accusent un retard de 16 à 20 jours. En outre, le rapport affichera parfois une liste de plus de 1000 pages dans les catégories d'erreurs ou d'avertissements, comme vous pouvez le voir dans l'image ci-dessus, mais il vous permet uniquement de voir et de télécharger un échantillon de 1000 URL à auditer et à vérifier.
Néanmoins, c'est un excellent outil pour trouver des problèmes d'indexation sur votre site :
Lorsque vous cliquez sur une erreur spécifique, vous pouvez voir la page de détails qui répertorie des exemples d'URL :

Comme vous pouvez le voir sur l'image ci-dessus, il s'agit de la page de détails de toutes les URL répondant avec 404. Chaque rapport comporte un lien "En savoir plus" qui vous amène à une page de documentation Google fournissant des détails sur cette erreur spécifique. Google fournit également un graphique qui montre le nombre de pages affectées au fil du temps.
Vous pouvez cliquer sur chaque URL afin d'inspecter l'URL qui est similaire à l'ancienne fonctionnalité "extraire comme Googlebot" de l'ancienne console de recherche Google. Vous pouvez également tester si la page est bloquée par votre robots.txt
Après avoir corrigé les URL, vous pouvez demander à Google de les valider afin que l'erreur disparaisse de votre rapport. Vous devez prioriser la résolution des problèmes qui sont dans l'état de validation "échec" ou "non démarré".
Il est important de mentionner que vous ne devez pas vous attendre à ce que toutes les URL de votre site soient indexées. Google déclare que l'objectif du webmaster devrait être d'indexer toutes les URL canoniques. Les pages en double ou alternatives seront classées comme exclues car elles ont un contenu similaire à la page canonique.
Il est normal que les sites aient plusieurs pages incluses dans la catégorie exclue. La plupart des sites Web auront plusieurs pages sans balises méta d'index ou bloquées via le fichier robots.txt. Lorsque Google identifie une page en double ou alternative, vous devez vous assurer que ces pages ont une balise canonique pointant vers l'URL correcte et essayer de trouver l'équivalent canonique dans la catégorie valide.
Google a inclus un filtre déroulant en haut à gauche du rapport afin que vous puissiez filtrer le rapport pour toutes les pages connues, toutes les pages soumises ou les URL dans un sitemap spécifique. Le rapport par défaut inclut toutes les pages connues qui incluent toutes les URL découvertes par Google. Toutes les pages soumises incluent toutes les URL que vous avez signalées via un sitemap. Si vous avez soumis plusieurs sitemaps, vous pouvez filtrer par URL dans chaque sitemap.
[Étude de cas] Augmenter le budget de crawl sur les pages stratégiques
 Lire l'étude de cas
Lire l'étude de casErreurs, avertissements, URL valides et exclues
Erreur
- Erreur de serveur (5xx) : le serveur a renvoyé une erreur 500 lorsque Googlebot a tenté d'explorer la page.
- Erreur de redirection : lorsque Googlebot a exploré l'URL, une erreur de redirection s'est produite, soit parce que la chaîne était trop longue, soit parce qu'il y avait une boucle de redirection, soit parce que l'URL dépassait la longueur maximale de l'URL, soit parce qu'il y avait une URL incorrecte ou vide dans la chaîne de redirection.
- URL soumise bloquée par robots.txt : les URL de cette liste sont bloquées par votre fichier robts.txt.
- URL soumise marquée « noindex » : les URL de cette liste ont une balise meta robots « noindex » ou un en-tête http.
- L'URL soumise semble être une erreur Soft 404 : une erreur Soft 404 se produit lorsqu'une page qui n'existe pas (a été supprimée ou redirigée) affiche un message "page introuvable" à l'utilisateur mais ne renvoie pas de code d'état HTTP 404. Les Soft 404 se produisent également lorsque des pages sont redirigées vers des pages non pertinentes, par exemple une page redirigeant vers la page d'accueil au lieu de renvoyer un code d'état 404 ou de rediriger vers une page pertinente.
- L' URL soumise renvoie une demande non autorisée (401) : la page soumise pour indexation renvoie une réponse HTTP 401 non autorisée.
- URL soumise introuvable (404) : la page a répondu avec une erreur 404 introuvable lorsque Googlebot a tenté d'explorer la page.
- L'URL soumise a un problème d'exploration : Googlebot a rencontré une erreur d'exploration lors de l'exploration de ces pages qui n'appartiennent à aucune des autres catégories. Vous devrez vérifier chaque URL et déterminer quel aurait pu être le problème.
Avertissement
- Indexé, bien que bloqué par robots.txt : la page a été indexée car Googlebot y a accédé via des liens externes pointant vers la page, mais la page est bloquée par votre robots.txt. Google marque ces URL comme des avertissements, car ils ne savent pas si la page doit réellement être bloquée pour ne pas apparaître dans les résultats de recherche. Si vous souhaitez bloquer une page, vous devez utiliser une balise méta "noindex" ou utiliser un en-tête de réponse HTTP noindex.
Si Google a raison et que l'URL a été bloquée par erreur, vous devez mettre à jour votre fichier robots.txt pour permettre à Google d'explorer la page.
Valide
- Soumis et indexés : URL que vous avez soumises à Google via sitemap.xml pour indexation et qui ont été indexées.
- Indexé, non soumis dans le sitemap : l'URL a été découverte par Google et indexée, mais elle n'a pas été incluse dans votre sitemap. Il est recommandé de mettre à jour votre sitemap et d'inclure toutes les pages que vous souhaitez que Google explore et indexe.
Exclu
- Exclu par la balise 'noindex' : lorsque Google a essayé d'indexer la page, il a trouvé une balise meta robots 'noindex' ou un en-tête HTTP.
- Bloqué par l'outil de suppression de page : quelqu'un a envoyé une demande à Google pour ne pas indexer cette page en utilisant la demande de suppression d'URL dans la console de recherche Google. Si vous souhaitez que cette page soit indexée, connectez-vous à la Search Console de Google et supprimez-la de la liste des pages supprimées.
- Bloqué par robots.txt : le fichier robots.txt contient une ligne qui exclut l'exploration de l'URL. Vous pouvez vérifier quelle ligne fait cela en utilisant le testeur robots.txt.
- Bloqué en raison d'une demande non autorisée (401) : identique à la catégorie Erreur, les pages ici reviennent avec un en-tête HTTP 401.
- Anomalie de crawl : il s'agit d'une sorte de catégorie fourre-tout, les URL ici répondent avec des codes de réponse de niveau 4xx ou 5xx ; Ces codes de réponse empêchent l'indexation de la page.
- Exploré - actuellement non indexé : Google ne fournit aucune raison pour laquelle l'URL n'a pas été indexée. Ils suggèrent de soumettre à nouveau l'URL pour indexation. Cependant, il est important de vérifier si la page a un contenu fin ou dupliqué, si elle est canonisée sur une autre page, si elle a une directive noindex, si les métriques montrent une mauvaise expérience utilisateur, un temps de chargement de page élevé, etc. Il peut y avoir plusieurs raisons pour lesquelles Google ne veut pas indexer la page.
- Découverte - actuellement non indexée : la page a été trouvée mais Google ne l'a pas incluse dans son index. Vous pouvez soumettre l'URL pour indexation afin d'accélérer le processus comme nous l'avons mentionné ci-dessus. Google déclare que la raison typique pour laquelle cela se produit est que le site a été surchargé et que Google a reprogrammé l'exploration.
- Page alternative avec une balise canonique appropriée : Google n'a pas indexé cette page, car elle contient une balise canonique pointant vers une URL différente. Google a suivi la règle canonique et a correctement indexé l'URL canonique. Si vous vouliez que cette page ne soit pas indexée, il n'y a rien à corriger ici.
- Dupliquer sans canonique sélectionné par l'utilisateur : Google a trouvé des doublons pour les pages répertoriées dans cette catégorie et aucune n'utilise de balises canoniques. Google a sélectionné une version différente comme balise canonique. Vous devez examiner ces pages et ajouter une balise canonique pointant vers l'URL correcte.
- En double, Google a choisi un canonique différent de celui de l'utilisateur : les URL de ces catégories ont été découvertes par Google sans demande de crawl explicite. Google les a trouvés via des liens externes et a déterminé qu'il existe une autre page qui fait un meilleur canonique. Google n'a pas indexé ces pages pour cette raison. Google recommande de marquer ces URL comme des doublons de l'URL canonique.
- Non trouvé (404) : lorsque Googlebot tente d'accéder à ces pages, il répond par une erreur 404. Google déclare que ces URL n'ont pas été soumises, ces URL ont été trouvées via des liens externes pointant vers ces URL. C'est une bonne idée de rediriger ces URL vers des pages similaires pour tirer parti de l'équité des liens et s'assurer également que les utilisateurs atterrissent sur une page pertinente.
- Page supprimée en raison d'une plainte légale : quelqu'un s'est plaint de ces pages en raison de problèmes juridiques, tels qu'une violation des droits d'auteur. Vous pouvez faire appel de la réclamation légale soumise ici.
- Page avec redirection : ces URL sont des redirections, elles sont donc exclues.
- Soft 404 : comme expliqué ci-dessus, ces URL sont exclues car elles devraient répondre avec un 404. Vérifiez les pages et assurez-vous que si elles contiennent un message "introuvable", elles doivent répondre avec un en-tête HTTP 404.
- URL soumise en double non sélectionnée comme canonique : semblable à "Google a choisi une URL canonique différente de celle de l'utilisateur", cependant, les URL de cette catégorie ont été soumises par vous. C'est une bonne idée de vérifier vos sitemaps et de vous assurer qu'il n'y a pas de pages en double.
Comment utiliser les données et les éléments d'action pour améliorer le site
Travaillant dans une agence, j'ai accès à de nombreux sites différents et à leurs rapports de couverture. J'ai passé du temps à analyser les erreurs signalées par Google dans les différentes catégories.
Il a été utile de trouver des problèmes avec la canonisation et le contenu dupliqué, mais parfois vous rencontrez des divergences comme celle signalée par @jroakes :

Il semble que Google Search Console > URL Inspection > Live Test signale de manière incorrecte tous les fichiers JS et CSS comme Crawl autorisé : Non : bloqué par robots.txt. Testez environ 20 fichiers sur 3 domaines. pic.twitter.com/fM3WAcvK8q
— JR%20Oakes ???? (@jroakes) 16 juillet 2019
AJ Koh, a écrit un excellent article peu de temps après la mise à disposition de la nouvelle console de recherche Google, dans lequel il explique que la valeur réelle des données est de les utiliser pour brosser un tableau de la santé de chaque type de contenu sur votre site :
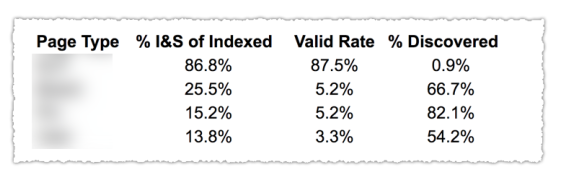
Comme vous pouvez le voir dans l'image ci-dessus, les URL des différentes catégories du rapport de couverture ont été classées par modèle de page tel que blog, page de service, etc. L'utilisation de plusieurs sitemaps pour différents types d'URL peut vous aider dans cette tâche puisque Google autorise vous permet de filtrer les informations de couverture par sitemap. Ensuite, il a inclus trois colonnes avec les informations suivantes : % de pages indexées et soumises, taux valide et % de découvertes.
Ce tableau vous donne vraiment un excellent aperçu de la santé de votre site. Maintenant, si vous souhaitez approfondir les différentes sections, je vous recommande de consulter les rapports et de revérifier les erreurs présentées par Google.
Vous pouvez télécharger toutes les URL présentées dans différentes Catégories et utiliser OnCrawl pour vérifier leur statut HTTP, balises canoniques, etc. et créer une feuille de calcul comme celle-ci :
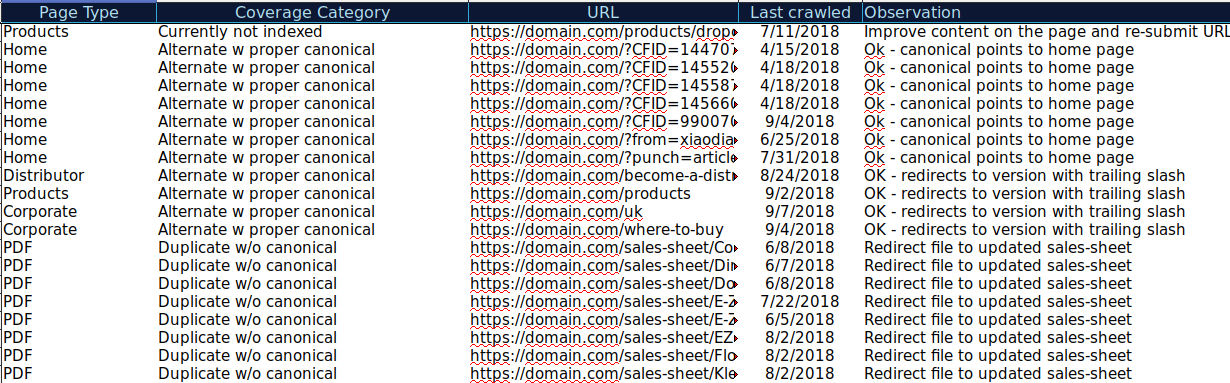
Organiser vos données de cette manière peut vous aider à suivre les problèmes et à ajouter des éléments d'action pour les URL qui doivent être améliorées ou corrigées. En outre, vous pouvez cocher les URL qui sont correctes et aucun élément d'action n'est nécessaire dans le cas de ces URL avec des paramètres avec une implémentation de balise canonique correcte.
Commencez votre essai gratuit de 14 jours
 Commencez votre essai
Commencez votre essaiVous pouvez même ajouter plus d'informations à cette feuille de calcul à partir d'autres sources telles que ahrefs, Majestic et Google Analytics avec les intégrations OnCrawl. Cela vous permettrait d'extraire des données de lien ainsi que des données de trafic et de conversion pour chacune des URL dans Google Search Console. Toutes ces données peuvent vous aider à prendre de meilleures décisions quant à ce qu'il faut faire pour chaque page, par exemple si vous avez une liste de pages avec des 404, vous pouvez la lier avec des backlinks pour déterminer si vous perdez l'équité des liens des domaines liés à pages cassées sur votre site. Ou vous pouvez vérifier les pages indexées et le volume de trafic organique qu'elles reçoivent. Vous pouvez identifier les pages indexées qui n'obtiennent pas de trafic organique et travailler à leur optimisation (amélioration du contenu et de la convivialité) pour aider à générer plus de trafic vers cette page.
Avec ces données supplémentaires, vous pouvez créer un tableau récapitulatif sur une autre feuille de calcul. Vous pouvez utiliser la formule =COUNTIF(plage, critères) pour compter les URL dans chaque type de page (ce tableau peut compléter le tableau suggéré par AJ Kohn ci-dessus). Vous pouvez également utiliser une autre formule pour ajouter les backlinks, visites ou conversions que vous avez extraits pour chaque URL et les afficher dans votre tableau récapitulatif avec la formule suivante =SUMIF (plage, critères, [sum_plage]). Vous obtiendriez quelque chose comme ceci :
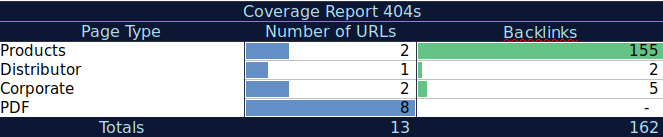
J'aime beaucoup travailler avec des tableaux récapitulatifs qui peuvent me donner une vue résumée des données et peuvent m'aider à identifier les sections sur lesquelles je dois me concentrer en premier.
Dernières pensées
Ce à quoi vous devez penser lorsque vous travaillez sur la résolution de problèmes et que vous examinez les données de ce rapport est : mon site est-il optimisé pour l'exploration ? Mes pages indexées et valides augmentent-elles ou diminuent-elles ? Les pages avec des erreurs augmentent-elles ou diminuent-elles ? Est-ce que j'autorise Google à passer du temps sur les URL qui apporteront plus de valeur à mes utilisateurs ou trouve-t-il beaucoup de pages sans valeur ? Avec les réponses à ces questions, vous pouvez commencer à apporter des améliorations à votre site afin que Googlebot puisse dépenser son budget de crawl sur des pages qui peuvent apporter de la valeur à vos utilisateurs au lieu de pages sans valeur. Vous pouvez utiliser votre fichier robots.txt pour améliorer l'efficacité de l'exploration, supprimer les URL sans valeur lorsque cela est possible ou utiliser des balises canoniques ou noindex pour éviter le contenu en double.
Google continue d'ajouter des fonctionnalités et de mettre à jour la précision des données dans les différents rapports de la console de recherche Google. Nous espérons donc que nous continuerons à voir plus de données dans chacune des catégories du rapport de couverture ainsi que d'autres rapports dans la console de recherche Google.