
Audit technique SEO rapide et sale en 11 étapes pour la santé globale du site Web
Publié: 2020-02-27Le référencement technique est important car c'est le point de départ de tout projet. Du point de vue d'un expert SEO, chaque site web est un nouveau projet. Un site Web doit avoir une base solide afin d'obtenir de bons résultats et d'atteindre les KPI les plus importants en SEO comme les classements.
A chaque fois que je démarre un nouveau projet, la première chose que je fais est un audit SEO technique. La plupart du temps, la résolution de problèmes techniques peut donner des résultats étonnants dès que le site Web est réexploré.
C'est drôle pour moi quand les gens parlent de contenu et plus de contenu, mais ils ne disent pas un mot sur le référencement technique. Une chose est sûre, la santé du site Web et le référencement technique sont deux choses importantes qui seront cruciales en 2020. Je ne veux pas dire que le contenu n'est pas important. C'est le cas, mais sans résoudre les problèmes techniques d'un site Web, je ne pense pas que le contenu puisse apporter des résultats.
J'ai vu des cas où des pages importantes ont été bloquées par des directives dans le fichier robots.txt, ou les pages de catégories ou de services les plus importantes sont cassées ou bloquées par des méta-robots comme noindex, nofollow. Comment est-il possible de réussir sans prioriser en résolvant ces problèmes ?
Il peut être surprenant de voir le nombre de référenceurs qui ne savent pas identifier les problèmes techniques à signaler aux spécialistes du développement Web pour qu'ils soient corrigés. Je me souviens qu'une fois, alors que je travaillais dans le domaine de l'entreprise, j'ai créé une feuille de liste de contrôle d'audit Tech SEO à utiliser par mon équipe. À ce moment-là, j'ai réalisé qu'avoir sous la main une feuille de solution rapide comme celle-ci peut énormément aider une équipe et générer un coup de pouce rapide pour un client. C'est pourquoi je considère qu'il est de la plus haute importance d'investir dans un outil/logiciel qui peut vous aider avec un diagnostic SEO technique et des recommandations.
Commençons le processus pratique sur la façon de mener un audit SEO technique rapide qui fera une grande différence. Il s'agit d'un exercice rapide qui vous prendra environ une heure à faire même si vous n'êtes pas un pro. Pour moi, utiliser un outil Tech SEO comme OnCrawl pour avancer rapidement toutes les choses en cinq minutes sans avoir à faire tout le travail manuel me facilite la vie.
Je passerai en revue les éléments les plus importants à vérifier lors de la réalisation d'un audit SEO technique. Il y a plus de choses que nous pouvons vérifier pour les problèmes sur la page, mais je veux me concentrer uniquement sur les choses qui créeront des problèmes d'indexation et un gaspillage de budget. Donner la priorité à cela est le moyen de s'assurer que les pages les plus importantes seront explorées par Googlebot.
- Indexation
- Fichier robots.txt
- Balise méta robots
- erreurs 4xx
- Plans de site
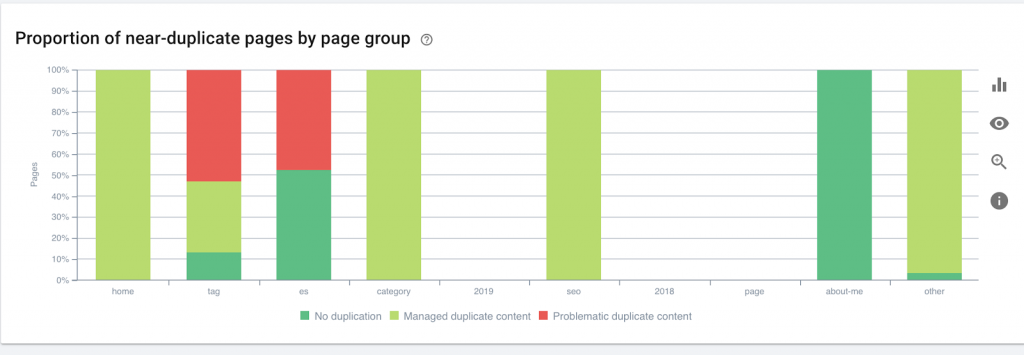
- HTTP/HTTPS (sécurité du site Web, problèmes de contenu mixte et de contenu dupliqué)
- Pagination
- 404 pages
- Profondeur et structure du site
- Longues chaînes de redirection
- Implémentation des balises canoniques
1) Indexation
C'est la première chose à vérifier. Souvent, l'indexation peut être affectée par la configuration d'un plug-in ou par une erreur mineure, mais l'impact sur la facilité de recherche peut être énorme, car il existe aujourd'hui plus de 6,16 milliards de pages Web indexées. Vous devez comprendre que tout moteur de recherche fait des efforts et même Google doit prioriser la page la plus pertinente pour l'expérience utilisateur. Si vous n'envisagez pas de faciliter les choses pour Googlebot, vos concurrents le feront et gagneront beaucoup plus en confiance avec un site Web sain.
En cas de problèmes d'indexation, les problèmes de santé de votre site Web se traduiront par une perte de trafic organique. Le processus d'indexation signifie qu'un moteur de recherche parcourt une page Web et organise les informations qui les proposent plus tard dans SERP. Les résultats dépendent de la pertinence pour l'intention de l'utilisateur. Si une page Web ne peut pas ou a des problèmes avec l'exploration, cela favorisera d'autres pages dans le même créneau pour avoir un avantage.
Utilisation des opérateurs de recherche par exemple :
Site : www.abc.com
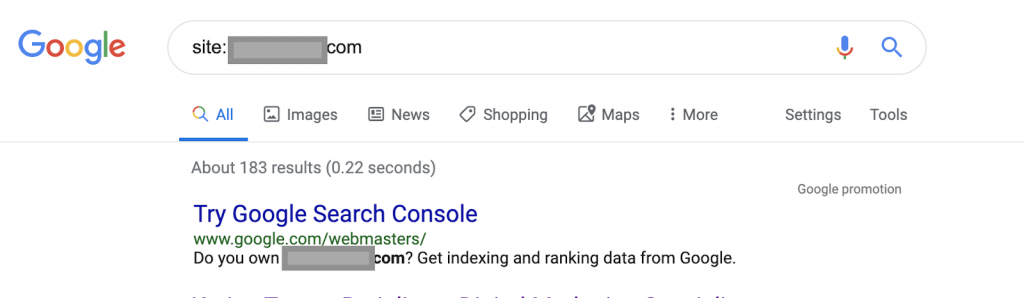
La requête renverra 183 pages indexées par Google. Il s'agit d'une estimation approximative du nombre de pages indexées par Google. Vous pouvez vérifier Google Search Console pour le nombre exact.
Vous devez également utiliser un robot d'exploration Web comme OnCrawl pour répertorier toutes les pages auxquelles Google a accès. Cela montre un nombre différent comme vous pouvez le voir ci-dessous:
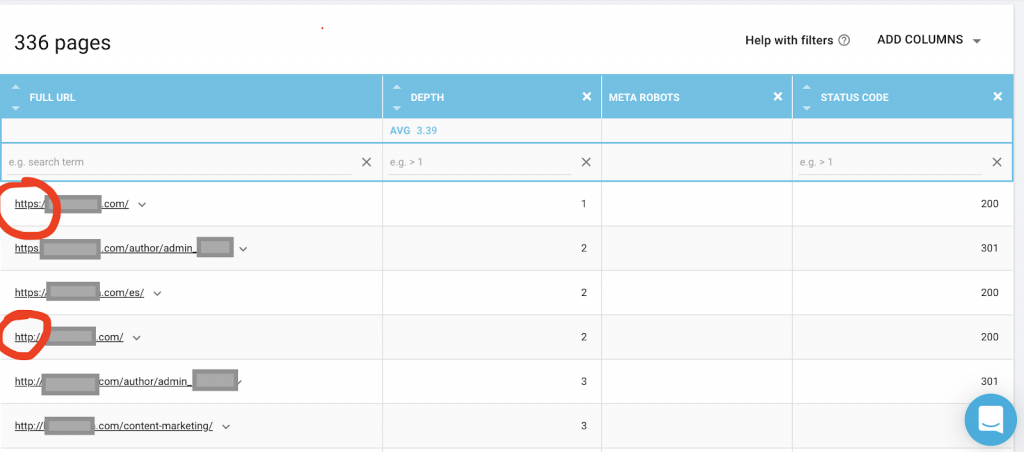
Ce site Web compte près de deux fois plus de pages explorables que de pages indexées.
Cela peut révéler un problème de contenu en double ou même un problème de version de sécurité du site Web entre le problème HTTP et HTTPS. J'en parlerai plus loin dans cet article.
Dans ce cas, le site Web a été migré de HTTP vers HTTPS. On peut voir dans OnCrawl que les pages HTTP ont été redirigées. Les versions HTTP et HTTPS sont toujours accessibles à Googlebot, et il peut explorer toutes les pages en double, au lieu de donner la priorité aux pages les plus importantes que le propriétaire souhaite classer, ce qui entraîne un gaspillage du budget d'exploration.
Un autre problème courant parmi les sites Web négligés ou les grands sites Web comme les sites de commerce électronique sont les problèmes de contenu mixte. Pour faire court, les problèmes surviennent lorsque votre page sécurisée contient des ressources telles que des fichiers multimédias (le plus souvent : des images) chargées à partir d'une version non sécurisée.
Comment le réparer:
Vous pouvez demander à un développeur Web de forcer toutes les pages HTTP vers la version HTTPS et de rediriger les adresses HTTP vers HTTPS une fois à l'aide d'un code d'état 301.
Pour les problèmes de contenu mixte, vous pouvez vérifier manuellement la source de la page et rechercher les ressources chargées en tant que "src=http://example.com/media/images", ce qui est presque insensé, en particulier pour les grands sites Web. C'est pourquoi nous devons utiliser un outil de référencement technique.
2) Fichier robots.txt :
Le fichier robots.txt indique aux agents d'exploration les pages qu'ils ne doivent pas explorer. Le guide des spécifications Robots.txt indique que le format de fichier doit être du texte brut d'une taille maximale de 500 Ko.
Je recommanderai d'ajouter le plan du site à robots.txt.file. Tout le monde ne le fait pas, mais je pense que c'est une bonne pratique. Le fichier robots.txt doit être placé sur votre serveur hébergé dans public_html et va après le domaine racine.
Nous pouvons utiliser des directives dans le fichier robots.txt pour empêcher les moteurs de recherche d'explorer des pages inutiles ou des pages contenant des informations sensibles, telles que la page d'administration, les modèles ou le panier (/cart, /checkout, /login, des dossiers comme /tag utilisés dans les blogs) , en ajoutant ces pages sur le fichier robots.txt.
Conseil : Assurez-vous de ne pas bloquer le dossier de fichiers multimédia car cela exclura vos images, vidéos ou autres médias auto-hébergés de l'indexation. Les médias peuvent être très importants pour la pertinence des pages ainsi que pour le classement organique et le trafic des images ou des vidéos.
3) Balise Meta Robots
Il s'agit d'un morceau de code HTML qui indique aux moteurs de recherche s'il faut explorer et indexer une page, avec tous les liens de cette page. La balise HTML va dans l'en-tête de votre page Web. Il existe 4 balises HTML courantes pour les robots :
- Pas de suivi
- Suivre
- Indice
- Aucun indice
Lorsqu'il n'y a pas de balises meta robots présentes, les moteurs de recherche suivront et indexeront le contenu par défaut.
Vous pouvez utiliser n'importe quelle combinaison qui correspond le mieux à vos besoins. Par exemple, en utilisant OnCrawl, j'ai découvert qu'une « page auteur » de ce site Web n'avait pas de méta-robots. Cela signifie que par défaut la direction est ("follow, index")
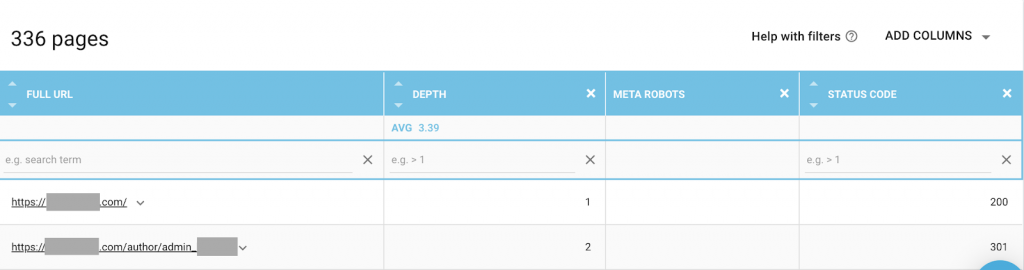
Cela devrait être ("noindex, nofollow").
Pourquoi?
Chaque cas est différent, mais ce site est un petit blog personnel. Il n'y a qu'un seul auteur qui publie sur le blog, et le domaine est le nom de l'auteur. Dans ce cas, la page « auteur » ne fournit aucune information supplémentaire même si elle est générée par la plateforme de blogs.
Un autre scénario peut être un site Web où les catégories du blog sont importantes. Lorsque le propriétaire souhaite classer les catégories sur son blog, les méta-robots doivent être ("suivre, indexer") ou par défaut sur les pages de catégorie.
Dans un scénario différent, pour un grand site Web bien connu où de grands experts en référencement écrivent des articles suivis par la communauté, le nom de l'auteur dans Google agit comme une marque. Dans ce cas, vous souhaiterez probablement indexer certains noms d'auteurs.
Comme vous pouvez le constater, les méta-robots peuvent être utilisés de différentes manières.
Comment le réparer:
Demandez à un développeur Web de modifier la balise meta robot selon vos besoins. Dans le cas ci-dessus pour un petit site Web, je peux le faire moi-même en accédant à chaque page et en la modifiant manuellement. Si vous utilisez WordPress, vous pouvez modifier cela à partir des paramètres RankMath ou Yoast.
4) Erreurs 4xx :
Ce sont des erreurs côté client, et elles peuvent être 401, 403 et 404.
- 404 Page non trouvée:
Cette erreur se produit lorsqu'une page n'est pas disponible à l'adresse URL indexée. Il se peut qu'elle ait été déplacée ou supprimée, et que l'ancienne adresse n'ait pas été correctement redirigée à l'aide de la fonction 301 du serveur Web. Les erreurs 404 sont une mauvaise expérience pour les utilisateurs et représentent un problème technique de référencement qui doit être résolu. C'est une bonne chose de vérifier souvent les 404 et de les corriger, et de ne pas les laisser être essayés encore et encore pour les agents rampants qui gaspillent leur budget.
Comment le réparer:
Nous devons trouver les adresses qui renvoient des 404 et les corriger à l'aide de redirections 301 si le contenu existe toujours. Ou, s'il s'agit d'images, elles peuvent être remplacées par de nouvelles en conservant le même nom de fichier.
- 401 Non autorisé
Il s'agit d'un problème d'autorisation. L'erreur 401 se produit généralement lorsqu'une authentification est requise, comme un nom d'utilisateur et un mot de passe.
Comment le réparer:
Voici deux options : la première consiste à bloquer la page des moteurs de recherche à l'aide de robots.txt. La deuxième option consiste à supprimer l'exigence d'authentification.
- 403 Interdit
Cette erreur est similaire à l'erreur 401. L'erreur 403 se produit parce que la page contient des liens qui ne sont pas accessibles au public.

Comment le réparer:
Modifiez l'exigence dans le serveur pour autoriser l'accès à la page (uniquement s'il s'agit d'une erreur). Si vous souhaitez que cette page soit inaccessible, supprimez tous les liens internes et externes de la page.
- 400 Mauvaise demande
Cela se produit lorsque le navigateur ne peut pas communiquer avec le serveur Web. Cette erreur se produit généralement pour une mauvaise syntaxe d'URL.
Comment le réparer:
Trouvez des liens vers ces URL et corrigez la syntaxe. Si cela n'est pas réparable, vous devrez contacter le développeur Web pour le réparer.
Remarque : Nous pouvons trouver 400 erreurs avec des outils ou dans Google Console

5) Plans du site
Le plan du site est une liste de toutes les URL que contient le site Web. Le fait d'avoir un ou plusieurs sitemaps améliore la facilité de recherche, car il aide les robots d'exploration à trouver et à comprendre votre contenu.
Nous avons différents types de plans de site et nous devons nous assurer qu'ils sont tous en bon état.
Les sitemaps que nous devrions avoir sont :
- Plan du site HTML : il se trouvera sur votre site Web et aidera les utilisateurs à naviguer et à trouver les pages de votre site Web.
- Plan du site XML : il s'agit d'un fichier qui aidera les moteurs de recherche à explorer votre site Web (en tant que meilleure pratique, il devrait être inclus dans votre fichier robots.txt).
- Plan du site vidéo XML : comme ci-dessus.
- Plan du site XML des images : C'est aussi le même que ci-dessus. Il est recommandé de créer des sitemaps distincts pour les images, les vidéos et le contenu.
Pour les grands sites Web, il est recommandé d'avoir plusieurs sitemaps pour une meilleure crawlabilité car les sitemaps ne doivent pas contenir plus de 50 000 URL.
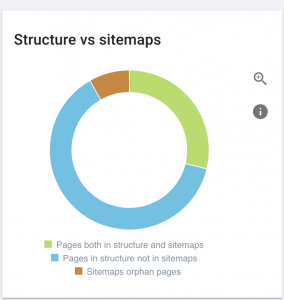
Ce site Web a des problèmes de sitemap.
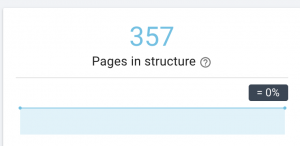
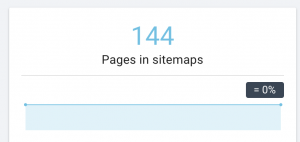
Comment nous le réparons :
Nous corrigeons cela en générant différents sitemaps pour : le contenu, les images et les vidéos. Ensuite, nous les soumettons via la console de recherche Google et créons également un sitemap HTML pour le site Web. Nous n'avons pas besoin d'un développeur Web pour cela. Nous pouvons utiliser n'importe quel outil en ligne gratuit pour générer des sitemaps.
6) HTTP/HTTPS (contenu dupliqué)
De nombreux sites Web ont ces problèmes à la suite de la migration de HTTP vers HTTPS. Si tel est le cas, le site Web affichera les versions HTTP et HTTPS dans les moteurs de recherche. En raison de ce problème technique commun, les classements sont dilués. Ces problèmes génèrent également des problèmes de contenu dupliqué.
![]()

Comment le réparer:
Demandez à un développeur Web de résoudre ce problème en forçant tout HTTP à HTTPS.
Note : Ne redirigez jamais tout le HTTP vers la page d'accueil HTTPS car cela générerait une erreur soft 404. (Vous devriez le dire au développeur Web ; rappelez-vous qu'il ne s'agit pas de référenceurs.)
7) Mise en page
Il s'agit de l'utilisation d'une balise HTML ("rel = prev" et "rel = next") qui établit des relations entre les pages, et qui montre aux moteurs de recherche que le contenu qui est présenté dans différentes pages doit être identifié ou lié à une seule. La pagination est utilisée pour limiter le contenu pour l'UX et le poids d'une page pour la partie technique, en les gardant sous les 3Mo. Nous pouvons utiliser un outil gratuit pour vérifier la pagination.
La pagination doit avoir des références auto-canoniques et indiquer « rel = prev » et « rel = next ». Les seules informations en double seront le méta-titre et la méta-description, mais cela peut être modifié par les développeurs pour créer un petit algorithme afin que chaque page ait un méta-titre et une méta-description générés.
Comment le réparer:
Demandez à un développeur Web d'implémenter des balises HTML de pagination avec une balise auto-canonique.
Robot d'exploration SEO Oncrawl
 Découvrir
Découvrir8) Page personnalisée 404 introuvable
Une réponse 404 est, comme nous l'avons déjà mentionné, une erreur « Introuvable » qui amène les utilisateurs vers un lien brisé ou une page inexistante. C'est l'occasion de rediriger les utilisateurs au bon endroit. Il existe d'excellents exemples de pages 404 personnalisées. C'est quelque chose qu'on se doit d'avoir.
Voici un exemple d'une excellente page personnalisée 404 :

Comment le réparer:
Créez une page 404 personnalisée : pensez à quelque chose d'incroyable à ajouter dessus. Faites de cette erreur une opportunité pour votre entreprise.
9)Profondeur/structure du site
La profondeur de page est le nombre de clics sur lesquels votre page est localisée à partir du domaine racine. John Mueller de Google a déclaré que "les pages plus proches de la page d'accueil ont plus de poids". Par exemple, imaginons que la page ici nécessite la navigation suivante pour être atteinte :

La page « tapis » est à 4 clics de la page d'accueil. Il est recommandé de ne pas avoir de pages situées à plus de 4 clics de la maison, car les moteurs de recherche ont du mal à explorer les pages plus profondes.
Ce graphique montre le groupe de pages par profondeur. Cela nous aide à comprendre si la structure d'un site Web doit être retravaillée.
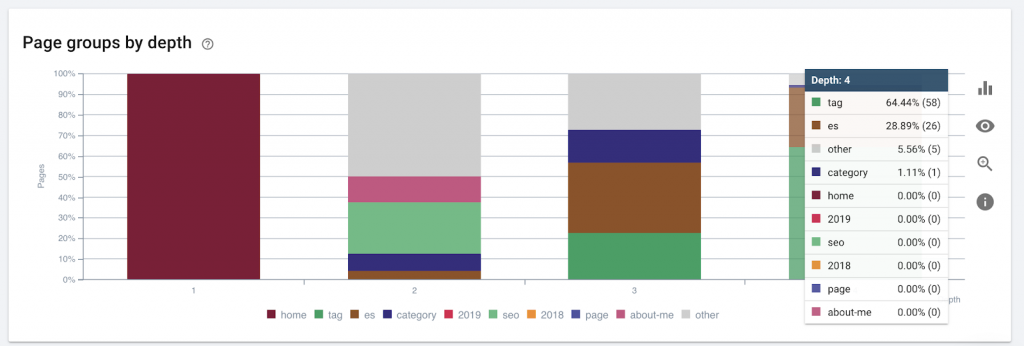
Comment le réparer:
Les pages les plus importantes doivent être les plus proches de la page d'accueil pour UX, pour un accès facile par les utilisateurs et pour une meilleure structure du site Web. Il est très important d'en tenir compte lors de la création d'une structure de site Web ou de la restructuration d'un site Web.
10. Chaînes de redirection
Une chaîne de redirection se produit lorsqu'une série de redirections se produit entre des URL. Ces chaînes de redirection peuvent aussi créer des boucles. Cela pose également des problèmes à Googlebot et gaspille le budget de crawl.
Nous pouvons identifier les chaînes de redirections en utilisant le chemin de redirection de l'extension Chrome, ou dans OnCrawl.
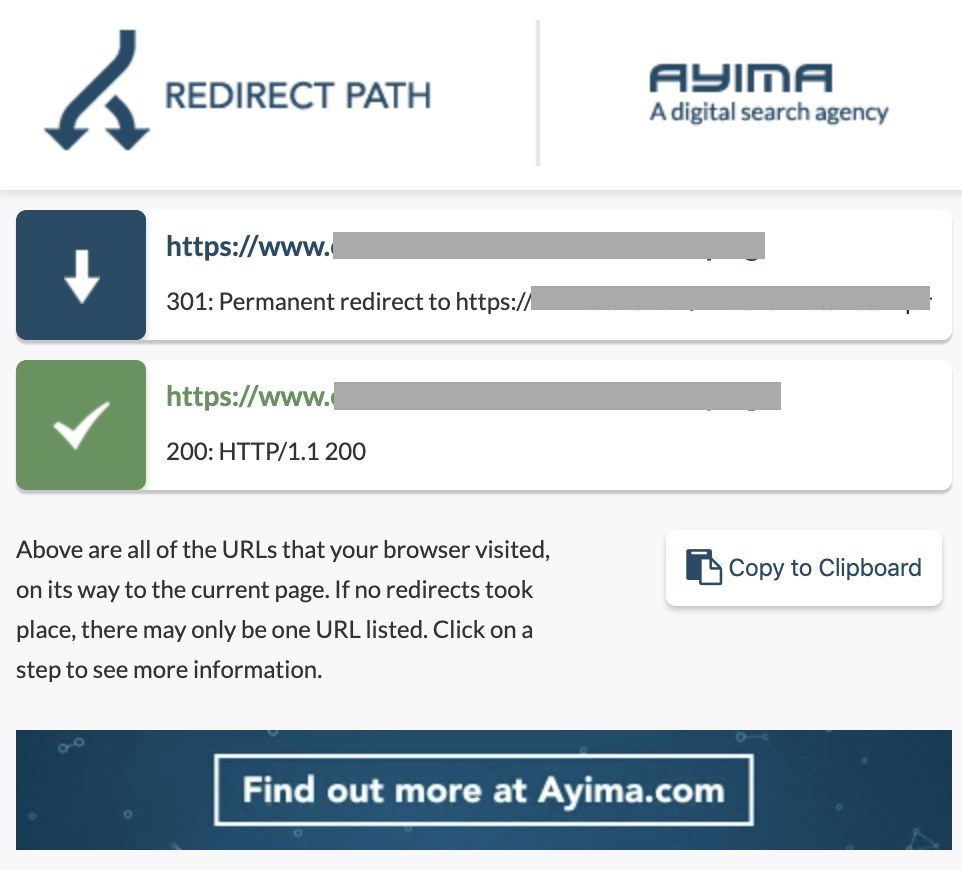
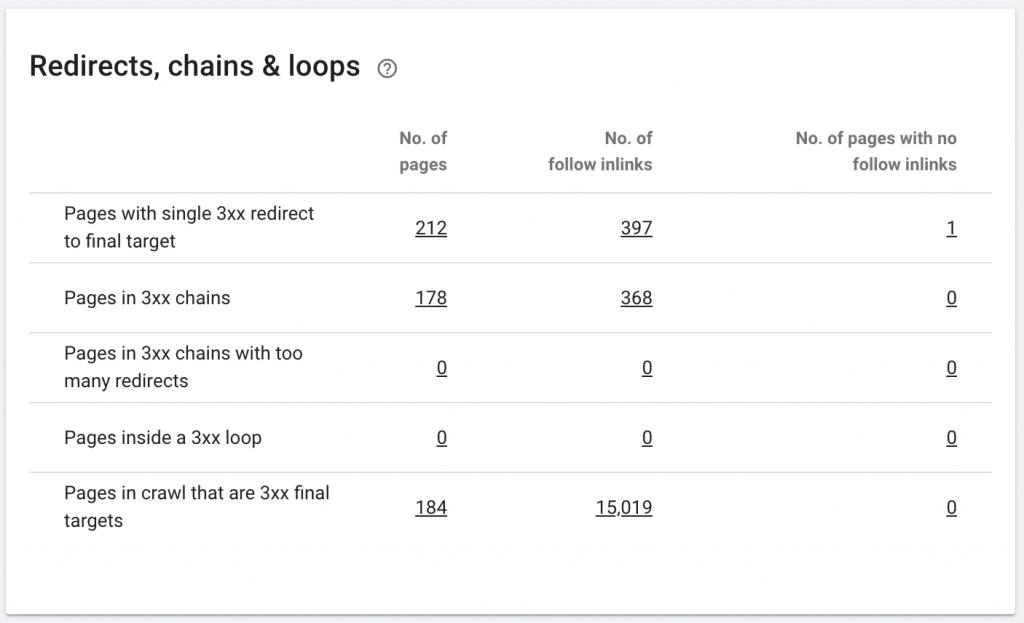
Comment le réparer:
Il est très facile de résoudre ce problème si vous travaillez avec un site Web WordPress. Allez simplement à la redirection et recherchez la chaîne - supprimez tous les liens impliqués dans la chaîne si ces changements se sont produits il y a plus de 2-3 mois et laissez simplement la dernière redirection vers l'URL actuelle. Les développeurs Web peuvent également vous aider en apportant toutes les modifications requises dans le fichier .htacces, si nécessaire. Vous pouvez vérifier et modifier les longues chaînes de redirection dans vos plugins SEO.
11) Canoniques
Une balise canonique indique aux moteurs de recherche que l'URL est une copie d'une autre page. C'est un gros problème qui est présent sur de nombreux sites Web. Ne pas mettre en œuvre les canoniques de la bonne manière, ou ne pas les mettre en œuvre du tout, créera des problèmes de contenu en double.
Les canoniques sont couramment utilisés dans les sites Web de commerce électronique où un produit peut être trouvé plusieurs fois dans différentes catégories telles que : taille, couleur, etc.

Vous pouvez utiliser OnCrawl pour savoir si vos pages ont des balises canoniques, et si elles sont correctement implémentées ou non. Vous pouvez ensuite explorer et corriger les problèmes.
Comment nous le réparons :
Nous pouvons résoudre les problèmes canoniques en utilisant Yoast SEO si nous travaillons dans WordPress. Nous allons dans le tableau de bord WordPress puis dans Yoast -setting – advanced.
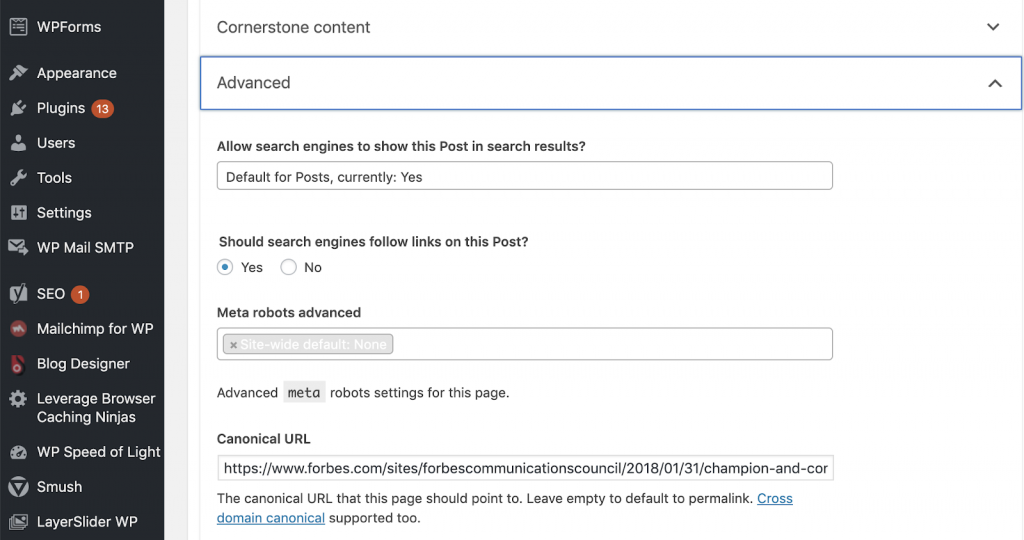
Exécution de votre propre audit
Les référenceurs qui souhaitent commencer à plonger dans le référencement technique ont besoin d'un guide d'étapes rapides à suivre pour améliorer la santé du référencement. Parler de référencement technique avec John Shehata, vice-président de la croissance de l'audience chez Conde Nast et fondateur de NewzDash lors de la journée mondiale du marketing à New York en octobre 2019.
Voici ce qu'il m'a dit :
"Beaucoup de gens dans l'industrie du référencement ne sont pas techniques. Maintenant, tous les référenceurs ne comprennent pas comment coder et il est difficile de demander aux gens de le faire. Certaines entreprises, ce qu'elles font, c'est qu'elles embauchent des développeurs et les forment pour qu'ils deviennent des référenceurs afin de combler le vide technique en matière de référencement.
À mon avis, les référenceurs qui n'ont pas la connaissance complète du code peuvent quand même faire du bien à Tech SEO en sachant comment exécuter un audit, identifier les éléments clés, créer des rapports, demander aux développeurs Web de les mettre en œuvre et enfin tester les changements.
Prêt à commencer? Téléchargez la liste de contrôle pour ces principaux problèmes.
